 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库eLight | 超表面实现高度可扩展机器视觉
 Banner
Banner本文由论文作者团队撰稿

导读
光学神经网络(ONN)为低延迟、高能效人工智能(AI)计算提供了有效途径。然而,其扩展至主流AI模型参数规模面临两大关键瓶颈:大规模ONN的训练计算成本极高,且数百万光学元件的实现与调控对制造缺陷和对准误差高度敏感。近日,香港中文大学电子工程系黄超然教授团队提出了基于光学超表面的光学学习机(MOLM),成功突破了上述障碍。该系统通过集成4千万个光学参数的光学超表面构建超宽ONN,搭配仅含102-104个可训练参数的紧凑型数字后端,实现了无需重新训练或重新制造超表面即可灵活适配各类视觉任务的目标。实验表明,该系统在六项视觉任务中实现了可扩展的机器视觉性能,准确度与ResNet、Vision Transformer等先进深度学习模型相当。该方法对制造缺陷和对准误差非常鲁棒,并可在相干与非相干照明条件下工作,为大规模、高性能光学人工智能计算提供了切实可行的新路径。
相关研究成果以"Highly scalable machine vision enabled with meta-optics-based ultra-wide neural network"为题发表于eLight(影响因子32.1,入选两期卓越计划)。本文通讯作者为香港中文大学电子工程系黄超然教授,第一作者为黄超然教授课题组博士研究生罗明成。合作作者包括黄超然教授课题组博士研究生熊建民和王东亮以及研究助理郭文飞,香港中文大学计算机科学与工程系窦琪教授及其博士研究生姜美锐,香港中文大学生物医学工程系周仁杰教授及其博士研究生周楠森,香港中文大学电子工程系许正德教授,以及加拿大皇后大学物理系Bhavin J. Shastri教授。该工作得到了香港信兴高等工程研究所、香港创新科技署、香港研究资助局、香港中文大学等的资助。
随着深度学习模型规模的快速增长,数据传输和处理的能量消耗已成为制约AI发展的主要因素。光学神经网络(ONNs)凭借其固有的高度并行性、超高速传输能力和低能耗优势,被视为突破这一计算瓶颈的有效方案。ONNs通过利用光子作为信息载体,在光学域内直接执行矩阵乘法等核心计算操作,有望显著提升计算效率并大幅降低系统延迟。然而,ONNs的实际应用部署面临两大核心挑战:其一,大规模ONN的训练计算成本极高,需要海量的迭代优化步骤;其二,传统ONNs的物理实现与参数调谐需要对大量光学元件进行精确控制,对制造精度和对准误差极为敏感,这严重制约了ONNs向现代AI模型参数规模的扩展。现有ONN架构,如基于马赫-曾德尔干涉仪阵列(MZI)或衍射光学元件(DOE)的系统,在可扩展性、鲁棒性和能耗效率之间存在难以调和的矛盾。因此,开发既能实现大规模参数集成、又具备高容错性和低能耗特性的新型光学神经网络架构,是当前光子AI领域亟待解决的关键科学问题。
本研究创新地提出并实现了一种基于光学超表面的光学-数字混合学习机器(MOLM)。该MOLM的光学前端是一个由6400 × 6400共4100万个硅基纳米柱超原子构成的光学超表面(如图1所示)。每个超原子经过精心设计,可在整个工作波长范围内实现精确的相位和振幅调制。这一固定、无源的光学前端利用其庞大的光学自由度高效地执行特征提取和维度压缩,其后接一个仅包含102-104个可训练参数的紧凑数字神经网络后端。这种光学-数字混合架构的关键优势在于:超过99.99%的计算量由光学前端以无源、超低延迟的方式完成,而数字后端则负责补偿光学前端的残余不匹配并针对特定任务进行自适应微调。这一设计范式实现了"一次制造,多任务适应"的突破性转变,避免了在任务变更或模型更新时重新制造或重新训练光学系统的需求。
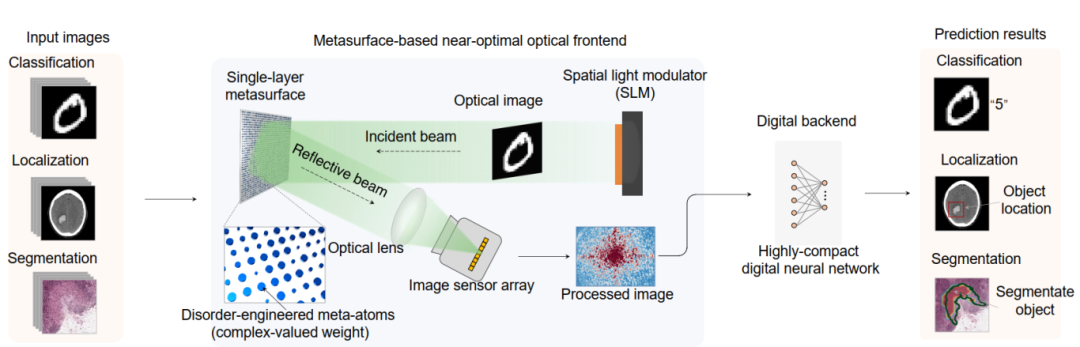
图1:基于超表面的光子学习机(MOLM)工作示意图。空间光调制器(SLM)将光学图像投射至由大量圆柱形硅超原子组成的单层超表面;经超表面反射后,由光学透镜收集光场并聚焦;再通过图像传感器阵列采集焦平面光场信息;最终将采集到的图像输入数字神经网络,完成任务预测
通过这种光学-数字混合的计算架构,MOLM系统不仅有效规避了传统ONNs在训练和制造上的难题,更在多个维度上展现出卓越的性能和普适性。以下将详细阐述其关键技术创新和实验成果:
1. 超高准确率的基准测试集性能
研究团队实验验证了MOLM在图像分类基准任务中的优异性能。MOLM的分类准确度与光学超表面集成的参数规模呈现显著的正相关关系(如图2a所示)。当超表面参数达到4100万量级时,该系统仅需搭配含3000个可训练权重的紧凑型数字后端,即可使未经训练的超表面光学前端在MNIST数据集上达到99.2%的分类准确率,接近端到端完全训练超表面(99.6%)的性能水平。在更具挑战性的CIFAR-10图像数据集上,系统实现了91.6%的实验准确率(如图2b所示),该性能与包含数千万参数的传统深度学习模型ResNet-50相当,且在目前所有报道的光学神经网络系统中处于领先水平。这些结果说明:通过在光学域集成大规模参数,固定的、无源的光学超表面能够近似实现与复杂深度学习模型相当的图像特征提取能力。
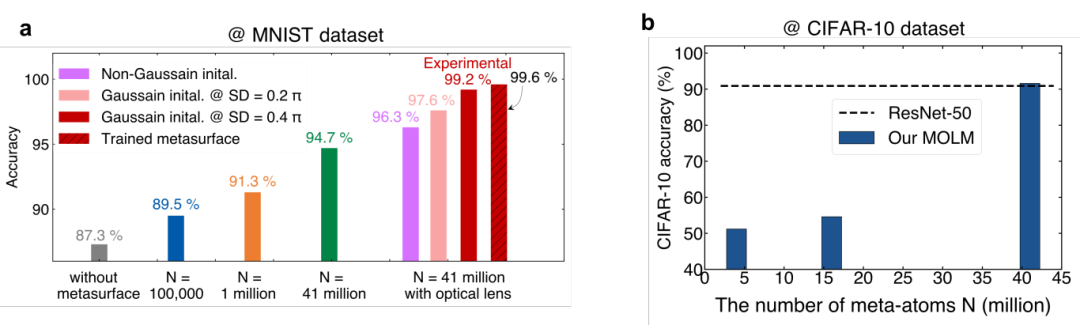
图2:(a) 不同配置MOLM的MNIST精度。(b) 实验CIFAR-10准确度与超原子数量的关系
2. 可扩展至多类型视觉任务处理
利用同一超表面芯片,MOLM无需任何物理重构或光学参数调整,即可灵活适配六种不同类型的视觉任务。这些任务不仅涵盖基础的MNIST和CIFAR-10图像分类,更拓展至具有重要实际应用价值的医学影像分析领域,包括:COVID-19胸部CT图像检测、颅内出血(ICH)检测和NIH数据集疾病分类(如图3所示)。在这些真实临床应用场景的数据集上,该系统的分类准确率与ResNet、Vision Transformer(ViT)和SAM等先进深度学习模型相当,但其数字参数规模少了103至105倍。进一步扩展其网络架构,该系统也被证实可有效处理基于视频的人体动作识别任务,并表现出色(详见第3节)。此外,该系统已被实验验证可用于加速基于数十亿像素级全玻片图像(WSI)的癌症检测应用(详见第4节)。这种多任务处理能力凸显了该光学-数字混合架构在任务可扩展性和模型通用性方面的显著优势。
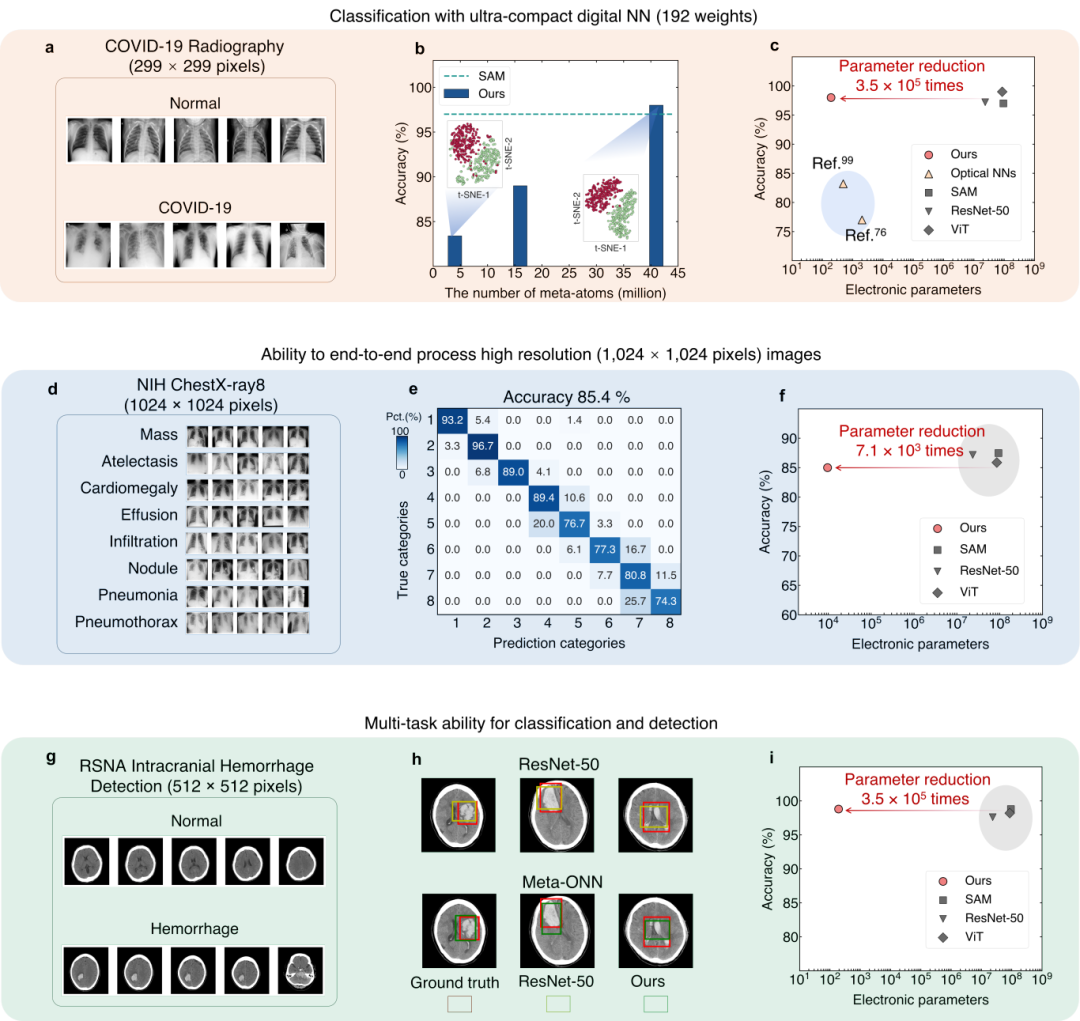
图 3:(a)、(d) 和 (g) 分别展示了 COVID-19 放射成像 (a)、NIH ChestX-ray8 (d) 和 RSNA 颅内出血检测任务 (g) 的数据集图像。(b) MOLM 模型在 COVID-19 放射成像任务中的准确率与光学神经元数量的关系。虚线代表 SAM 模型的准确率,作为对比。彩色散点图代表 t-SNE 分析的结果。(e) NIH ChestX-ray8 预测结果的混淆矩阵。(h) MOLM 模型(下图)和数字 ResNet-50 模型(上图)预测的脑内出血区域。(c)、(f) 和 (i) MOLM 模型与其他光学方法和数字模型在 COVID-19 放射成像 (c)、NIH ChestX-ray8 (f) 和 RSNA 颅内出血检测任务 (i) 中的准确率和电子参数比较
3.可扩展至复杂的神经网络架构
本研究所提出的光学超表面展现出卓越的网络架构兼容性与扩展潜力。尽管MOLM在基础应用中主要用作前馈网络执行图像分类任务,但其光学处理单元具备与循环神经网络(RNN)架构的无缝集成能力。如图4a所示,通过将MOLM视作动态处理单元的隐藏层并引入时间反馈机制,可构建基于超表面的循环神经网络(meta-RNN),从而赋予系统处理视频帧序列的能力。该光学-数字混合循环框架在KTH人体动作识别数据集上得到充分验证。实验结果表明,meta-RNN仅需9180个可训练权重,即可同时实现97.5%的帧级准确率和99.1%的动作分类准确率(如图4b和4c所示)。利用光学计算固有的低延迟和并行处理优势,meta-RNN在NVIDIA RTX 3090硬件平台上仅需4.01秒即可完成整个训练过程,远少于传统纯数字神经网络通常需要的数小时训练时间。在实际视频推理应用中,该系统可达到每秒1968帧的处理速率。
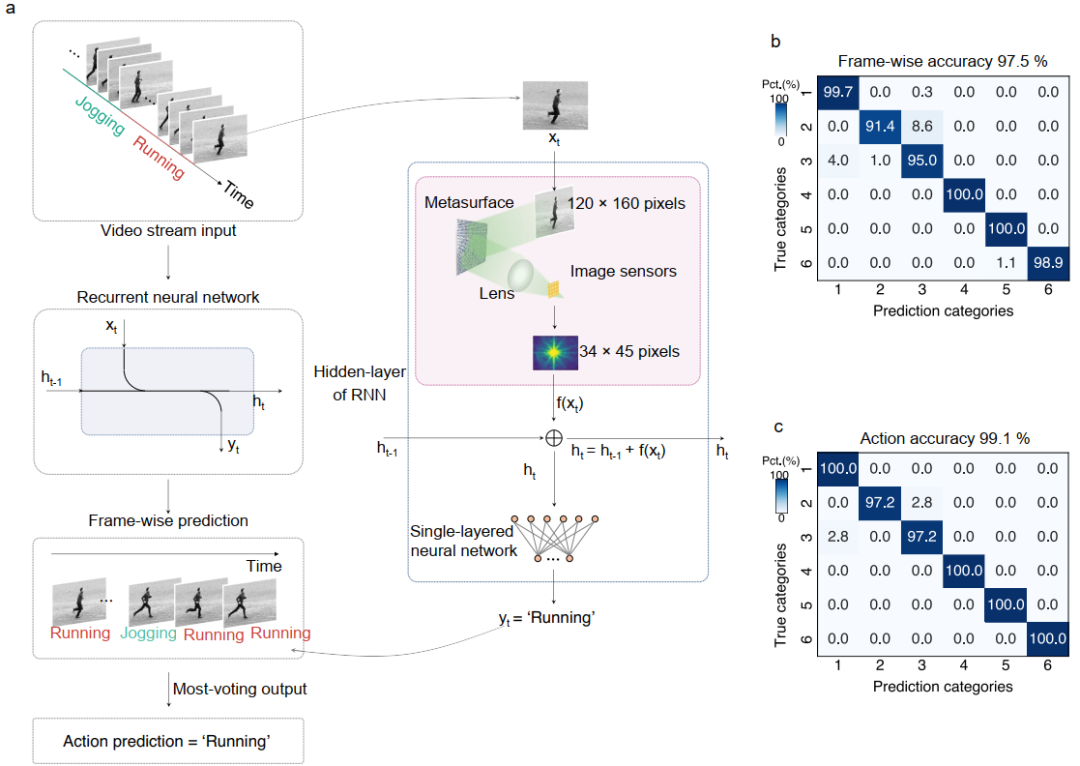
图4:(a) 基于视频人体动作识别的meta-RNN工作流程;(b) 逐帧预测结果混淆矩阵;(c) 动作预测结果混淆矩阵
4. 基于真实临床场景的癌症检测应用
MOLM在计算密集型临床应用场景中也展现出独特优势。本研究选取乳腺癌淋巴结转移的自动检测与精准定位作为典型临床验证任务—该任务在传统临床工作流程中高度依赖经验丰富的病理学家进行耗时的人工阅片:单张全玻片图像(WSI)的分辨率通常超过百亿像素,病理学家需逐一审阅数千张百万像素级的局部切片图像,诊断效率极为有限。如图5中病灶预测概率热图所示,MOLM能够从百亿像素级WSI中精准分割并定位三处独立肿瘤区域,其交并比(IoU)与参数量达数亿级别的基准分割模型SAM相当。值得注意的是,MOLM在推理效率方面实现了重大突破。对单张WSI的完整推理仅需1.02秒,而SAM完成同等任务需耗时1.48小时。这一效率优势在实际临床部署中具有极其深远的意义:在12小时工作日内,MOLM可完成超过4.2万例患者样本的诊断分析,而SAM在相同时间窗口内仅能处理8例。
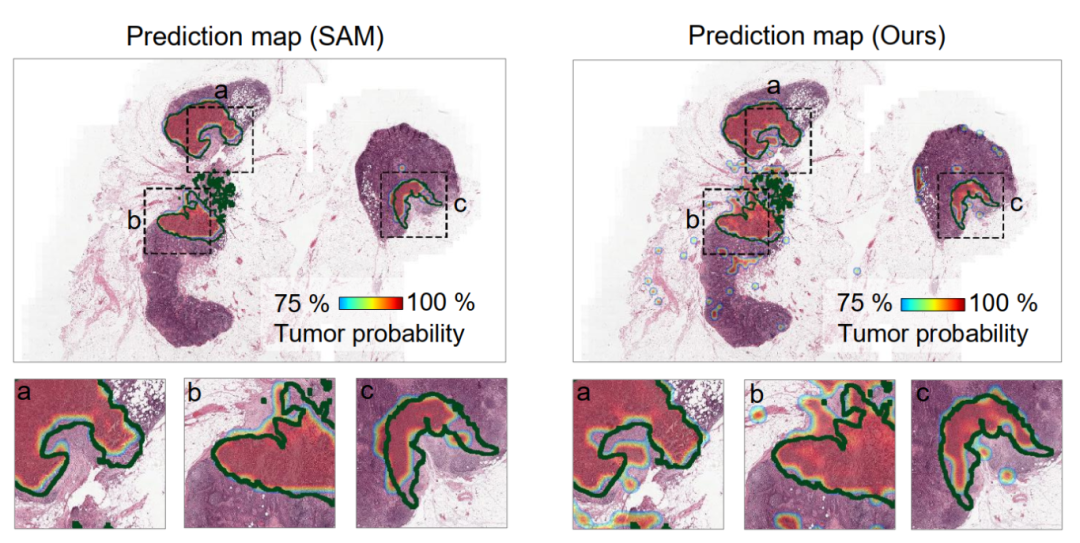
图5:MOLM 和最先进的分割模型 (SAM) 的预测概率热图
5. 对制造误差的强鲁棒性与宽谱非相干光工作能力
MOLM在工程实现方面展现出两大关键优势。
其一,通过采用随机光学超表面与数字后端的光电协同设计策略,该系统对制造工艺偏差与光学对准误差表现出极强的鲁棒性。为系统地验证这一关键特性,研究团队测试了三个不同制造批次的芯片样品。制造的超原子结构直径范围为92 nm至413 nm,相比设计目标值(100 nm至400 nm)存在约±6%的制造误差。尽管芯片存在明显的工艺制造误差,实验测得的不同器件间MNIST分类准确率的波动仍小于1%,表明该光学-数字混合架构通过数字后端的自适应补偿机制能够有效消除光学前端的制造偏差影响。
其二,与传统光学神经网络(ONN)系统普遍依赖窄带相干激光光源的方案不同,该MOLM具备在宽谱非相干光照条件下稳定工作的能力。实验验证表明,在光谱宽度范围为20 nm至100 nm的LED光源照射下,系统在MNIST推理任务上的分类准确率仍稳定保持在98.3%以上,准确率下降幅度仅为∼1%,波动极小。以上两大优势使得系统无需配备昂贵复杂的激光器与精密光学准直系统,可直接在普通LED照明或自然环境光下运行,从而大幅降低硬件成本与系统复杂度。
总结与展望
本文实验验证了高性能超表面光学学习机(MOLM),成功实现了前所未有的实验准确率与系统可扩展性。这一卓越性能源于创新融合光学超表面(充分释放光学并行计算潜力的核心器件)与无限宽神经网络(适配超表面神经网络的理论计算框架,可灵活扩展至任意宽度、深度和复杂度)的协同设计,成功构建了高度可扩展的大规模光学计算系统。实验发现:一枚集成4100万个无序工程超原子的单层光学超表面芯片,搭配轻量级数字神经网络,即可媲美ResNet、Vision Transformer等顶尖深度学习模型的性能。本工作标志着光学神经网络研究的重大突破,使其超越基准测试的局限,真正具备应对现实世界复杂应用挑战的能力,为光子AI的实际部署开辟了新的前景。
论文信息
Luo, M., Jiang, M., Shastri, B.J. et al. Highly scalable machine vision enabled with meta-optics-based ultra-wide neural network. eLight 6, 10 (2026).
https://doi.org/10.1186/s43593-026-00127-y

编辑:赵阳
审核:孙婷婷
监制:郭宸孜
欢迎课题组投宣传稿
请扫码联系值班编辑







