 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库对话刘子鸣:从MIT回到清华,给AI找一套“务实的理论”

如果你关注过深度学习圈,大概率 2024 年时听过一个三个字母的缩写——KAN。这篇叫做 Kolmogorov–Arnold Networks(柯尔莫哥洛夫–阿诺德网络) 的论文在 arXiv 挂出后,几天之内席卷了各路技术社群,有人宣称 MLP(多层感知机)这个统治了深度学习几十年的基础砖块可能要被改写,也有人质疑它只是又一个“看起来很美”的架构。近两年之后,KAN 的 GitHub 仓库已经攒下了超过 1.6 万颗星,相关的跟进论文从生物物理到金融建模,铺了一大片。
这篇论文的第一作者叫刘子鸣,当时还是 MIT 物理系的博士生,导师是以“数学宇宙假说”闻名的 Max Tegmark。几个月前,他和合作者关于表示叠加(Superposition)的工作又拿下了 NeurIPS 2025 最佳论文亚军。如今他 MIT 博士刚毕业,在斯坦福做了一段短暂的博士后回到国内,即将入职清华大学人工智能学院担任助理教授。
有意思的是,如果你翻他的主页,会发现他给自己挂的标签既不是“深度学习研究者”,也不是“大模型研究者“,而是三个交错的方向:Science of AI(AI 的科学)、Science for AI(服务于 AI 的科学)、AI for Science(AI 服务于科学)。在这之上,他最想推动的事情有一个更具体的名字,叫 Physics of AI(AI 的物理学)。
用他自己的话说,今天的 AI 处境有点像大航海之前的天文学,大家仰着头看到很多东西,但连把这些观测整理成一张像样星图的“研究语言”都还没有,连第谷(Tycho Brahe)的阶段都还没到,更别提开普勒和牛顿。
最近他在闭关,想做的事正是把 Physics of AI 本身自动化。
以下是 DeepTech 和他的对话。
从物理到 AI:一路试错之后的转向
DeepTech:你本科在北大读物理,去 MIT 也是读物理,后来怎么走到 AI 这条路上来的?
刘子鸣:其实挺早的,大二下我就开始转向 AI 了,不过当时做的还是 AI 和物理的结合。
触发点是我了解到了 GAN(生成对抗网络)。当时就觉得,这玩意好像也没有多难,但它的 formulation(问题构建方式)非常巧妙。我那时就觉得,这就是一个研究的“重点”,我就想做这样的工作。
再一个,那个时候我在物理上的探索,说实话也不太顺利。一方面,理论觉得挺难的,另一方面,做实验、动手也挺难的。所以我当时考虑过计算物理,反正不管计算物理还是 AI,都是在电脑上搞,但觉得 AI 的问题和机会更多一点,就开始往 AI 上看。不过形式上我仍然挂在物理学院,找的也是物理学院的老师做 AI 和物理的交叉,主要是 AI for Physics。
后面读博跟 Max Tegmark,他早就在做 AI for Physics 和 Physics for AI,所以我们早期主要也是 AI for Physics,比如用 AI 去找物理系统中的守恒量、对称性这些东西。到 2022 年底 ChatGPT 出来之后,我们就觉得,AI 好像不再只是一个工具了,它本身变成了研究对象。从那时候起,我们开始把更多精力花在“理解 AI”上。
DeepTech:你这个路径让我想到杨振宁先生,他当年是因为实验不顺利才转去做理论物理,然后找到了自己擅长的方向。
刘子鸣:我可能要更惨一点(笑),理论和实验物理都不顺利,连数论也试过。数论后来觉得太理论了,也放弃了。
DeepTech:你博士跟的 Max Tegmark 是一位典型的 polymath(通才),他的思维方式对你最大的影响是什么?
刘子鸣:Max 是那种什么都懂的人。
之前 Freeman Dyson 把数学家和科学家分成两类,一类叫 bird person(鸟人),一类叫 frog person(蛙人)。鸟人飞得很高,能看到整片山河的图景,喜欢能把不同领域串起来的宏大概念;蛙人则扎在泥里,看得到花朵的细节,一次解决一个具体问题。而 Max 就是绝对的鸟人。
不管是物理、AI、神经科学,还是各种应用领域,他懂的都非常多。他本科其实学的是经济学,在斯德哥尔摩经济学院读的。所以我们经常聊着聊着一个话题,他就能延伸到别的在一般人看来毫不相关的地方。他能看到那些表面不同的问题底下共通的结构,这对我的 research taste(研究品味)影响非常大。
另外还有一点,他特别擅长把一个很难理解的东西解释给别人。这背后其实就是费曼技巧的那个核心判断,如果你不能用简单的话向一个外行讲清楚一件事,说明你自己也没真正理解它。传播学上也是一样,你要让别人知道一个东西,它至少得是一个你能讲清楚的东西。这个也是我跟他学得比较多的。
DeepTech:博士后去斯坦福跟 Andreas Tolias,从物理又转到了神经科学。为什么做这个决定?
刘子鸣:两方面。一方面是我也想做鸟人。神经网络最开始其实就是神经科学那一拨人搞起来的,我想了解一下那帮人的脑洞到底是什么样的。另一方面是有一个具体的项目,我之前做 AI for Physics 时搞过一个找守恒量的工具,他们说有一个神经科学的数据集很合适。虽然后来发现其实也没那么合适,但至少是合作的一个起点。
DeepTech:这么看,你的整个学术路径其实可以概括为在研究“智能的底层原理”?
刘子鸣:对,而这种底层原理需要从非常多角度去触摸和理解,有点像盲人摸象,所有学科都只是摸它的一部分。
关于 Science of AI、Science for AI、AI for Science
DeepTech:能不能用最简单的话说说,这三个方向各自在回答什么问题?
刘子鸣:看研究的主体是什么。前面是工具,后面是研究对象。
Science for AI 和 Science of AI 都是以 AI 为研究对象,science 是研究方法。两者挺像的,但还是要做个区分。Science of AI 更被动,研究的是现有的那些 AI 模型;Science for AI 更主动、野心更大,是用 science 去重构现在的 AI 模型,祈求能造出下一代的 AI 模型。AI for Science 大家已经讲得比较多了,就是用 AI 去推动科学发现。
DeepTech:KAN 应该算 Science for AI?
刘子鸣:我自己很喜欢 KAN 的原因就是它同时包含这三个方面。它主体是 Science for AI,用 science 去重构 AI,但也有 Science of AI 的部分。比如我们解释了为什么 MLP(多层感知机)的 scaling law(缩放律)没有达到理想值,而 KAN 可以比 MLP 更快,所以这个工作也包含对 MLP 的某些理解。同时它也是 AI for Science,因为 KAN 工具做出来之后,最适合它的场景往往是那些你期待背后有某种动力学、有紧凑规律的任务,而不是大语言模型那种你不太指望背后会有紧凑规律的任务。
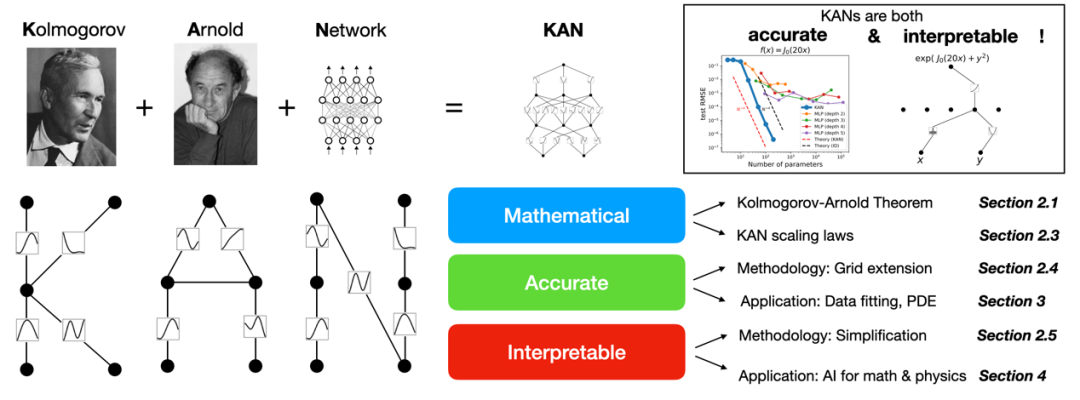
图丨KAN 的架构(来源:arXiv)
DeepTech:你最初因为 GAN 进入 AI,后来 KAN 又引起那么大关注,这么看似乎有点呼应。
刘子鸣:某种意义上确实是一次 call back。从高层次上看,我的一些代表作(除了 KAN,还有 Poisson Flow 等)它们跟 GAN 的风格都很像,技术上没有多难,工程上也不需要多少算力,但能找到一个比较巧妙的 formulation(问题构建方式),或者说找到一种合适的语言。一旦你找到了合适的语言、合适的结构,问题就变得非常简单。有点像爱因斯坦研究广义相对论的时候找到了黎曼几何,当语言对了,很多东西就自然而然通了。
DeepTech:回头看,KAN 对你意味着什么?是一个架构创新,还是一种思维方式的创新?
刘子鸣:我的很多工作,有些人看着觉得乱七八糟、东搞一下西搞一下,但背后其实是同一个逻辑,我想在神经(neural)和符号(symbolic)这两个世界之间架一座桥。现在的 AI 主要是神经的,而科学主要是符号的。
KAN 对我来说很特别的地方在于,它是第一个让我觉得存在一种类似波粒二象性的东西。在量子力学里,粒子既是波也是粒子。而 KAN 同时是网络,也同时是符号公式,同时是神经的东西,也同时是符号的东西。在它之前,没有这种例子,要么就是神经的,要么就是符号的,要么是 neural-symbolic(神经符号方法),但那往往是用某种比较硬的方法强行把两者拼接起来,不是那么兼容。KAN 很优雅地体现了这种二象性。
正因为这样,我现在思考的另一些问题是沿着这个逻辑继续走。KAN 说的是符号公式和神经网络的二象性,但符号公式本身仍然是一类比较局限的结构。
比如经典算法,像排序这种算法,跟神经网络之间能不能构建二象性?再往前一步,大家现在都在说的 world model(世界模型),它背后可能有物理引擎或物理模拟器,这种东西又该怎么和神经网络之间构建二象性?所以 KAN 其实只是第一步,后面第二步、第三步、第四步都会按照这条逻辑发展下去。
DeepTech:也有一些人觉得 KAN 在大规模任务上可能用处没那么大。你怎么看这种评价?
刘子鸣:这是 no free lunch theorem(没有免费午餐定理))没有一个模型能在所有任务上都比另一个更好。所以对待模型的正确态度,是找到它的应用场景,然后在它有优势的场景下诚实地发挥这个优势。
具体一点,如果你关心可解释性,尤其是想拿符号形式的表达,你就应该用 KAN;如果你有大量数据,又关心高精度的预测,那你也应该用 KAN。什么时候不应该用?数据量特别小的时候别用,因为 KAN 的 Spectral Bias 更弱,更容易过拟合。大规模大模型场景下,努力调参的话工程上都是能做到的,也许能调得比 Transformer 更好,但我不会一开始就预设 KAN 有一个很强的理由一定比传统 Transformer 更好。
DeepTech:作为 KAN 的提出者,你怎么看它现在的生态?
刘子鸣:我昨天还看到一篇文章,用 KAN 去学生物物理(biophysics)里的一个动力系统,这是我想象中比较“小而美”的理想应用场景。也有一些场景是我一开始没预料到的,比如金融和医疗,这些场景特别需要可解释性,大家就自然用上了 KAN。一个东西对现实世界到底能产生什么影响,作为创造者,很多时候你在创造的时候是想象不到的。
DeepTech:你们去年的 Superposition 论文拿了 NeurIPS 2025 Best Paper Runner-up,核心发现是什么?
刘子鸣:核心发现是,当模型宽度变宽的时候,它的 loss(损失)和宽度之间是一个反比关系。
为什么这个发现令人意外?因为在我们这篇论文之前,甚至包括我自己之前一篇 paper,大家主流的看法是,scaling law 和数据分布有很强的关系。你的数据本身遵循某种幂律(power law),所以是幂律进、幂律出,数据幂律决定了模型幂律。但我们这篇文章打破了这个观点,我们发现,即使你的数据不是幂律、是任意分布,输出仍然呈现出一个类似物理学里“普适类(universality class)”的东西,它把数据的细节全部抹掉,模型永恒地给你一个 1/宽度 的缩放律。
解释这个结果用的是非常简单的理论。方法论上有一点我自己觉得比较独特,也是 Physics of AI 区别于其他理论方法的地方,它是一种“务实的理论”。它的目的是解释甚至改进实验,所以会特别紧贴实验结果,这是形式化(formal)理论做不到的。但同时我们又构建 toy model(玩具模型)去解释背后的机理,这又是纯做实验做不到的。我们在两者中间找到了平衡,而且在玩具模型上的分析,竟然可以迁移到大模型上。
这篇文章的主要贡献其实是来自一作、MIT 的合作者刘逸舟。我的角色差不多就是每周跟他约一次啤酒,一边喝一边在白板上写写画画,讨论实验结果。逸舟最近也准备博士毕业,在考虑下一步计划了。
DeepTech:另一篇《Neural Thermodynamic Laws》把热力学语言用到了大模型训练上,这个想法是怎么来的?
刘子鸣:这篇我个人觉得偏课程项目一点,因为没有太多特别新奇的发现,但作为J人,总是喜欢能有一个统一的框架把很多小而繁琐的观察给整理清楚。出发点是一个非常简单的观察,现在训大模型,大家会用学习率调度(learning rate schedule),先 warm up(升温)、再 stable(稳定)、再 decay(衰减)。我们发现一个事情,最终的 loss 和它最终衰减到哪个学习率,存在一个线性关系。
这个线性关系特别像物理里“热容”的概念。当一个物体有恒定热容的时候,你要升多高的温度,就得吸多少热。这里 loss 类似于“热”,学习率类似于“温度”。一开始观察到这个事情的时候,我就意识到,这可以和物理里的能均分定理(equipartition theorem)建立联系。
从这个对应出发做下去,越做越发现很多东西都能映射到热力学。比如你在一个陡峭的河道里走,在峭壁上弹射的过程中会产生某种“熵力(entropic force)”,算了一下,和物理里的熵力形式是一模一样。这可能不是巧合。物理中的很多理论,本身就是在寻找简单而普遍的东西,很多看起来不同的体系经过一定抽象之后,会变成同一个东西。我们这篇文章就是把优化动力学和热力学,做了一个更显式的联系。
DeepTech:这种视角对训练策略有什么用?
刘子鸣:我们推导出了一个最优的衰减策略,是 1/t(关于训练步数 t 的倒数)。我们没在大模型上试过,但有一些别的文章经验上找出来的最优策略,其实跟我们理论上算出来的 1/t 非常像。可能不严格相同,但至少特征是一致的,一开始掉得快,后面慢慢停掉。
Physics of AI:什么是一种“务实的理论”
DeepTech:你经常说 Physics of AI,但不同人对这个词的理解很不一样。有人觉得是用物理的数学工具分析神经网络,有人觉得是找 AI 版的牛顿定律,还有人觉得是机制可解释性(mechanistic interpretability)换了个马甲。你自己说的 Physics of AI 到底指什么?
刘子鸣:这里需要区分两件事。第一,我们最终的目标是什么?第二,我们用什么方法到达这个目标?
最终的目标(我们的“North Star”)是,我要为 AI 找到一种“务实的理论”。这和传统的理论是有区别的。传统的理论可能是自下而上的,类似数学,从一些第一性原理出发,去推演出东西来。这种做法的坏处是,可能跟现实没那么相关。但另一方面,我也不相信现在的 AI 背后是没有理论的,就是无脑调参。所以我追求的是一种务实的理论。
那怎么达到这个目标?我觉得物理学的方法论本身就是这样一种务实的理论。物理最终是要描述和预测实验现象,所以是务实的。但同时它又是理论,可以定量地预测。要兼顾两者,物理采取的方式是,对真实系统做抽象和简化,研究这个简化后的模型,它可能仍然很复杂,但至少把无关的变量简化掉了。
先在一个更小的模型上研究清楚,再把它迁移回更大的模型,中间肯定有 gap(差距),再一步一步解释这个 gap 是怎么加上来的。不管是机制派、现象学派,还是 Physics of LLMs 那派,目的其实都是找到一种务实的理论。
DeepTech:那你和朱泽园(Zeyuan Allen-Zhu)做的 Physics of LLMs、Anthropic 做的机制可解释性,具体差别在哪?
刘子鸣:大家目的都差不多,硬说区别的话,我比他们更关心训练动力学(training dynamics),他们可能更关心模型最后的结果。朱泽园更关心的是相图,即改这些超参数,最后的指标怎么依赖于这些超参数。Anthropic 关心的是,给我一个模型,我去理解它内部怎么工作。
我关心的层面稍微不一样,比朱泽园稍微更微观一点,但比 Anthropic 又更宏观一点。我关心的是,当我们训练一个模型的时候,它的各种观测量,比如 loss,比如权重的范数,是怎么随着训练演化的?所以有点像是一种“关于曲线的科学”,你训练一个东西,可以同时画 100 条曲线,从曲线里获得洞察,再根据这些洞察去迭代。
但最终,我不会觉得做 Physics of AI 就不认可别人的做法。我的态度是八仙过海、取其精华去其糟粕,不同的叫法、不同的方法,只要能为我所用,我就把它吸纳进来。
DeepTech:你在博客里说 AI 目前还处在“第谷阶段”,有大量的观测数据,但没有开普勒定律,更没有牛顿力学。你觉得 AI 领域积累的“认知债务”有多严重?
刘子鸣:首先纠正一下,那篇博客是我几个月前写的。我现在的认知更悲观一点,可能连第谷阶段都还没到。
虽然互联网上有大量文章、数据,但我现在想做的一件事,是把 Physics of AI 本身自动化,这也跟我闭关的项目有关,因为人做研究还是太慢了。开始做之后我才意识到,我没有太多数据可用。
肯定会有人反问,互联网上那么多文章,为什么说没数据?因为我真正需要的数据,是一种人脑子里的结构化数据,它应该比自然语言更结构化,但往往我们并不会把这种东西写下来,甚至不知道怎么写下来。
什么数据对研究是有价值的?比如我自己写代码的时候,会不断跟自己对话、自言自语,有时候甚至不用语言,脑子里潜意识在做某种判断和取舍,这些数据都没有。再比如老师和学生讨论一个项目,老师建议这样做、学生怎么回应、为什么,这些过程的数据也没有。
综合来看,其实我们连“第谷阶段”的数据都还没凑齐。我现在闭关就是要做这件事,先把自己推到第谷阶段。而且我们需要先定义一门新的语言。研究本身是一门新的语言,自然语言只是我们用来交流研究的一种方式。日报仍然是自然语言,我需要把每篇日报结构化成这门新语言,才能开始有这门语言的数据,才能进行训练。
DeepTech:这笔认知债务短期内可能还不会影响 AI 发展,但什么时候它会开始阻碍 AI 迈入下一个阶段?
刘子鸣:认知债务是一个连续的东西。你解决得越多,短期风险越大,长期回报也越大。所以我不觉得它是一个相变,而是一个逐渐的过程。
四个月前我写博客的时候,我更极端一点,觉得需要一个相变式的解决方式。现在务实多了,一步步解决。我现在的目标是,在 2 到 3 年内解决掉 10% 的认知债务,而这 10% 可能能产生 90% 的效益。剩下的债务,我觉得得靠新的赛道,否则你就算继续解决,也只能再多拿到 10% 的效益了。
一方面,大家慢慢开始意识到有“认知债务”这件事。另一方面,有没有意义去解决它,是一个路线选择问题。我赌的是,要解决掉这 10%,才能掘到下一个金矿层。再往下掘、把整层凿穿,可能付出的努力又不值得了,除非你能找到新的机会。
DeepTech:你在博客里还提了一个挺尖锐的观点。AI 的现象学(phenomenology)之所以发展不起来,主要是“发表文化”在阻挡,只有能提升性能、或能讲成完整故事的研究才能发表,而很多你觉得有意思的现象,因为包装不成论文就被扔掉了。这个文化需要怎么改变?
刘子鸣:又是那句话,这个领域发展太快了。四个月前你问我,我会说我们需要建一个社区来做这件事。但现在我觉得,做一个 agent(智能体)就可以了,根本不用发表。
我之前的思路是集体智能(collective intelligence),我观察到一件事,别人观察到另一件事,把这些观察汇聚起来,这个领域有一天会出现类似渗流相变(percolation phase transition)的东西。但我现在意识到,这种相变往往是在一个人的脑子里产生的。我需要一个智能体,能日以继夜不停地去做这些小发现。我之前做日报,其实就是在手动做这件事。
现在我的判断是,第一,这件事 90% 可以被自动化。第二,我可以做得更暴力一点。之前我依赖人的直觉去决定“测什么观测量”,但现在我意识到,我可以一次测 100 万个观测量,暴力地测,再根据结果反推哪个观测量是重要的。
这是超越人类的做法。人脑有一些特别的地方,但可能没有我原来想象的那么特别。至少在“测什么”这件事上,人可能真不如机器。因此,我并不反对 scaling,但在 scale 什么的问题上,我希望我们能更多地去 scale up understanding。
我现在觉得,我们应该造一个机器,它甚至不必像智能体那么聪明,就在搜索空间里暴力搜。这件事不需要社区,因为这个过程对人来说太无聊、太耗时间了。
DeepTech:那人在其中扮演什么角色?
刘子鸣:具体说,人和机器的区别在哪?人能够提出“分布外(out-of-distribution)”的想法(训练数据里压根不存在的新点子),而机器是在“分布内”做排列组合,这是机器特别擅长的。
这也联系到我招学生的标准,我要招能提出分布外想法的人。因为分布内的部分,机器就能代替。
DeepTech:可解释性是你很多工作的核心关切。KAN 是为了可解释,BIMT 也是,Superposition 的研究也建立在 Anthropic 的玩具模型之上。在大家都在拼命追求更大、更强模型的当下,可解释性的优先级应该放在哪?
刘子鸣:这还是回到刚才“认知债务”的问题。现在主流路线是关心 0% 的可解释性,追求更强的模型。我关心 10% 的可解释性,目标是在 2 到 3 年内建出更强的模型。所以作为一种务实的理论,最终还是要建更强的模型,只是把时间尺度拉长了一点。
可能有人选择另一种押注,我要理解 50%,那目标可能是 5 到 10 年,或者 100%,目标是 100 年。但作为一种务实的理论,还是要做一些及时的事情。
DeepTech:听说你最近在闭关搞一个项目,说需要连续的时间进入心流。能透露一下在做什么吗?
刘子鸣:其实做的就是刚才说的,创造研究这门语言。
我之前写过一篇日报,说研究不应该以论文为目标,它应该以知识图谱(knowledge graph)为目标。而这个知识图谱本身就是一种语言。人类的自然语言是线性的,但像电影《降临》里外星人的语言,它是图像化的、环形的。我现在想创造的,就是这样一门图像化的语言,而做研究其实就对应着去改这张图。就先透露这些吧。
关于在清华建组和 AI 的“开普勒定律”
DeepTech:你现在正在招 2027 年秋入学的博士生。你想招什么样的人?
刘子鸣:能提出分布外想法的人。而好奇心驱动是这件事的一个必要条件。
你需要一直保持探索,因为很可能你前 100 个想法都已经被别人想过了。这意味着你不仅要理解知识本身,还要理解人脑是怎么思考知识的,然后找到一个东西,它既是某种意义上“人脑的分布外”,又对现实世界是有意义的问题。这需要很强的好奇心,加上韧性(resilience),因为前 100 次你可能都失败了,如果没有好奇心,你就没有动力坚持。
DeepTech:高校系统内的学术环境相对更强调传统意义上的“有用”和实用主义。如果用你的这套标准,好奇心驱动、分布外研究、甚至用博客代替论文,会不会太理想化?你怎么保护学生的好奇心?
刘子鸣:如果学校有硬性的发表规定,我的学生要达到这种基本的规定是很容易的事情。
我觉得做研究的第一性原理,是拓展自己的知识图谱。这个过程需要好奇心驱动,而发文章只是第二性的,是一个自然而然的副产物。当你知识图谱拓展到一定程度,大到溢出的时候,你发现了一些东西,非常想跟别人分享,不得不把它写下来,这个时候自然会出现文章。博客转文章其实也不是太难的事。
我承认自己做研究确实比较理想主义,我感兴趣、学生感兴趣的东西,我就觉得值得研究。但我逐渐觉得,实用主义的思维方式也不一定是坏事。其实两种可以在一个项目的不同阶段交替使用。第一阶段用理想主义的方式去探索,好奇驱动,定义问题。第二阶段当问题定义清楚、拆解成了工程问题之后,就要用实用主义的态度把工程推起来。否则效率太低。所以一句话就是,像科学家一样问有趣的问题,但像工程师一样把它解决掉。
DeepTech:你提到要在清华开一门 Physics of AI 的课,这门课打算怎么教?
刘子鸣:这门课和一般 AI 理论课最大的区别是,我更关心“做实验”。
理想化一点说,我希望让学生感受到牛顿那句话,“我就像一个在沙滩上玩耍的小孩,捡起这些贝壳”。我可能对之前的人发现了什么一无所知,但我仍然能够通过和这个世界的交互去发现一些美。
常规的 AI 理论课是去教“之前的人发现了什么现象、提出了什么理论”,但这样太像教科书了,好像所有东西都定死了。我会反过来,从一些很小的实验出发。我只告诉你这个模型是什么、我们在干什么,然后我给你画一些观测量,让你自己观察,你不需要先有任何先验知识,就去看这些曲线,你会自己意识到背后可能有什么规律。以这个为引子,我再去介绍前人在这上面做过哪些理论解释。
这也是我博客一直想做的事,就是把所有现象都简化成一个玩具模型。这个玩具模型可以在个人电脑上用一块 CPU、5 分钟之内就跑出这个现象,不需要多少算力就能复现大家关心的现象。
这完全是物理学家研究世界的方式。先做实验,先观察,甚至可以先“当民科”,在玩耍的过程中做一些自己的归纳总结,然后再回过头看前人怎么解释。这样学生对知识的印象会更深刻,因为他是真的动手做了一个东西。如果你直接灌输,他就只能被动接受。
受众方面,本科生和研究生都可以上。开这门课我最主要的目的,是推广 Physics of AI 这种方法论。你不一定要在纸上推公式,也不一定要有 1 万张卡去训大模型,你可以在自己电脑上很快训一个小模型,发现里面的有趣现象,而且这些现象还能和现实建立联系。
DeepTech:如果让你预测,5 年之后我们对 AI 的理解会到什么水平?会有 AI 版的“开普勒定律”吗?
刘子鸣:首先像我刚才说的,我们可能还需要 1 到 2 年去收集“第谷的数据”,因为还没到第谷阶段。
开普勒定律什么时候出现,取决于当前的 scaling 范式什么时候停滞(plateau)。我现在瞄准的是 10% 的可解释性,已经算比较深入的了,绝大多数研究可能只做到 0.1%,这是因为现在 scaling 还没停滞,大家没有动机去做更深的理解。
所以一个更近期的问题是,现在的范式什么时候会停滞?我觉得可能是一年内的事情。一年之后我们进入“第谷阶段”,数据也准备好了,人才也开始转向。可能会有一个延迟,一年后大家意识到 scaling 的机会没那么多了,才会开始转,真正的转向可能是第二年的事情。第二年结束之后,数据收集好了、人也有了,就可以开始“理解规模化(scale up understanding)”。
我们现在是规模化模型和数据,但接下来要规模化理解,当然,这个理解也只是 10%。

图丨开普勒模型与牛顿模型(来源:刘子鸣播客)
如果把“从第谷到开普勒”定义为这 10% 的理解,我觉得三年就够了。但从开普勒到牛顿,才是最难的。这又取决于我们这个范式什么时候会到头,大家什么时候意识到 10% 不够,什么时候开始追求更深的理解。
追到 100% 的时候,牛顿级别的东西才会发生。所以我对这一段时间的估计非常长,甚至有可能 AI 这一波过去之后会进入一个冷静期,有才华的人都去做下一个热点了。
所以开普勒可能三年,牛顿可能要一百年。
DeepTech:最后几个快问快答的小问题,你觉得 AI 研究者最该读的一本非 AI 书是什么?
刘子鸣:《人类简史》,对我启发挺大。这也是结合 Max 给我的启发。我之前会觉得“硬核就是一切”,越难、越不接地气,就越显得厉害。但《人类简史》讲的是,人类社会是由故事驱动的,所以你没法否认故事的重要性。
当然现在大家有时候会过度讲故事。你讲出来的价值减去实际的价值,如果这个差值太大,那杠杆就加太多了,这次别人听你的,下次就不信你了。做影响力的工作,不仅要理解技术本身,还要理解人性。这是我作为一个 nerd 理工男活了这么多年,最近才领悟到的事情。
DeepTech:如果没做 AI,你可能在做什么?
刘子鸣:我申博之前跟留学老师聊天,定的方向其实是量子力学理论。那个时候我也是觉得,量子力学非常高深,越硬核越不接地气,越能显得厉害。不过现实是,我认识很多做量子的朋友都在往 AI 转。所以我猜可能 10% 的平行宇宙里我还在坚守量子理论,另外 90% 的宇宙里,最终都会转去 AI,只是迟早问题。
DeepTech:用一句话形容你理想中实验室的文化?
刘子鸣:Netflix的那句,“极致的自由,前提是极致的人才密度”。招到最有才的同学,给他们足够的自由和资源,让他们自己去碰撞、去探索。就像 OpenClaw 之父 Peter Steinberger 说的,你打不过一个用游戏心态做事的人。当然,在早期同学们还没有太多研究经验的时候,我可能还是会多微操一点(笑)。这种务实是为了更长久的理想主义,只有先存活下来才能再谈理想。
运营/排版:何晨龙





