 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库谷歌第八代TPU双舰齐发,终结AI推理延迟,让智能体真正实现随叫随到

今天,谷歌在 Cloud Next '26 峰会上发布了其第八代 TPU 架构(TPU 8t 与 TPU 8i),TPU 8t 主攻训练,TPU 8i 主攻推理,将在 2026 年晚些时候上市。第八代 TPU 采用申请制,Google Cloud 用户如需使用,需要在官网提交登记需求。原生 PyTorch 对于 TPU 的支持等软件栈功能,目前也处于 Preview 阶段。眼下,谷歌是在小范围内开放给特定合作伙伴和早期客户进行测试,旨在管理早期算力资源的分配。
TPU 8t 凭借 SparseCore 核心与 Virgo 网络拓扑,将大规模预训练效能推向极致,以 2.7 倍的单位成本算力改写了模型训练版图。
TPU 8i 专为实时推理与复杂决策而生,其通过 CAE 加速引擎与新型 Boardfly 拓扑结构,在一定程度上击碎了长上下文推理的延迟瓶颈,让 AI 从单一的下一个词预测进化到场景模拟和深度逻辑推理,AI 回应将变得更及时、更连贯。在谷歌自研 Arm Axion 架构 CPU 的算力支持下,这套架构还实现了两倍的能效飞跃。
第八代 TPU 将开放给所有谷歌云客户使用。TPU 8t 和 TPU 8i 支持主流的 AI 框架比如 PyTorch 和 JAX。开发者不需要学习新的编程语言,使用自己熟悉的工具就能直接调用 TPU 算力。谷歌还提供了开源的参考模型代码,让用户可以快速上手。

(来源:谷歌)
我们可能都遇到过 AI 反应很慢的情况,要转好几圈才给出答案,很多时候问题不在于网速,其实是处理请求的芯片距离太远。我们的声音数据要跑到远处的数据中心,在那里排队、计算、再传回来,一来一回时间就过去了,此次第八代 TPU 正是为解决这个问题而来。
当前,AI 训练和 AI 推理对于芯片的要求越来越不一样。训练需要极致的算力,这要求芯片之间能够高效地协同工作。推理则需要极低的延迟,这要求芯片能够快速处理多个请求,并且还得尽可能地省电。于是,第八代 TPU 分成了 TPU 8t 和 TPU 8i。
TPU 8t:专为大规模 AI 训练设计
TPU 8t 主要负责训练,它被设计得可以成千上万个连在一起工作。谷歌用一个名为 3D Torus 的网络把其连接起来,组成了一个超级计算集群。一个单独的超级计算单元里就装了 9600 颗 TPU 8t 芯片,一起共享高达 2PB 的内存,总共能够提供高达 121 ExaFlops 的算力。
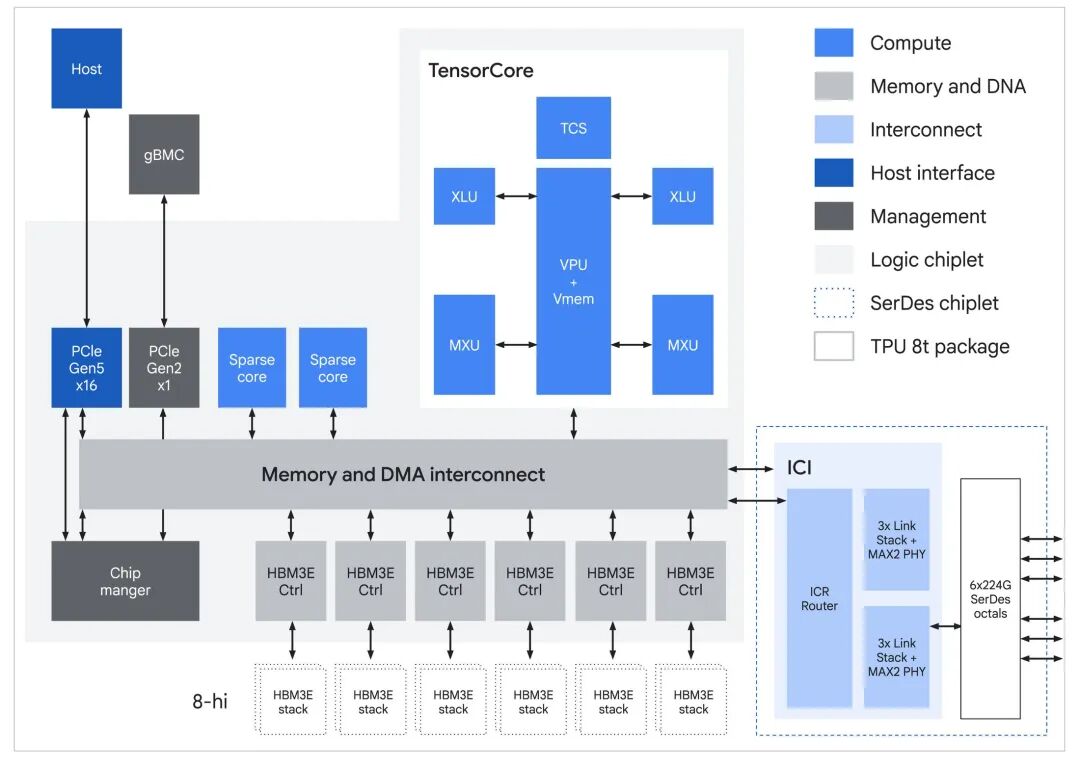
图 | TPU 8t ASIC 框图(来源:谷歌)
TPU 8t 还用到了 SparseCore 这一技术。现在的很多大模型用的是混合专家技术,每次计算只激活一小部分参数,混合专家技术虽然能效高,但是会产生大量不规则的内存访问,这让普通芯片招架不来。
而谷歌此次使用的 SparseCore 技术专门负责处理这种任务,比如它可以让负责核心数学运算的矩阵乘法单元专心做自己擅长的事情,通过这样互相配合的方式,芯片就不会闲置,始终保持满负荷运转的状态。
TPU 8t 还改进了数据传输方式,用上了谷歌自研的 Virgo 网络,把芯片之间的通信带宽翻了一倍,把连接到外部数据中心的带宽提升了四倍。TPU 的 Direct Storage 技术允许芯片直接从高速存储里读取数据,从而能够绕开 CPU 这个“中间人”。
这样一来,喂给芯片的数据流就不会断,训练速度能提升十倍。在能耗上,TPU 8t 相比上一代的每瓦性能提升了两倍。训练超大模型时,它的性价比提升了 2.7 倍。对于需要训练几百甚至上千亿参数模型的团队来说,这意味着能够节约大量的时间和电费。
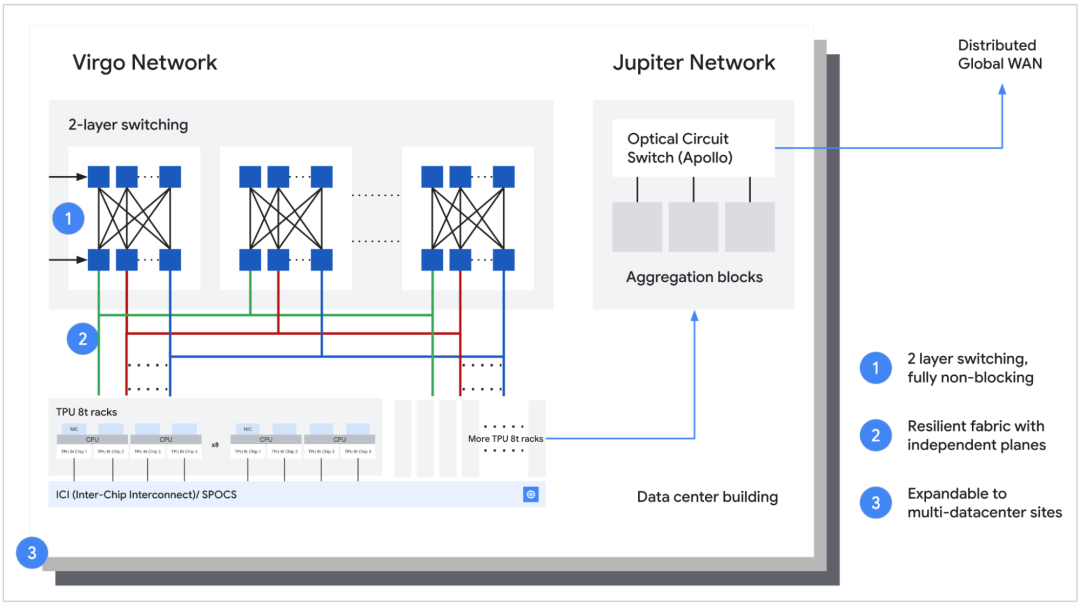
图 | TPU 8t 机架级与 Virgo 光纤通道的连接(来源:谷歌)
TPU 8i:能快速响应需求和处理长上下文推理
相比之下,TPU 8i 主打一个反应极快,它专门为那些复杂的、需要多步推理的问题而生。当你和 AI 聊一个很长的上下文,比如讨论一个复杂的心理问题,那么 AI 需要记住之前所有的对话内容。
上述对话记忆被存放在一个叫 KV Cache 的地方,而 TPU 8i 配备了 288GB 的高带宽内存和 384MB 的超大片上 SRAM,后者比上一代多了三倍,因此它可以把整个对话的上下文都装进芯片内部,不用频繁地去外面拿数据,处理速度自然也就变快了。
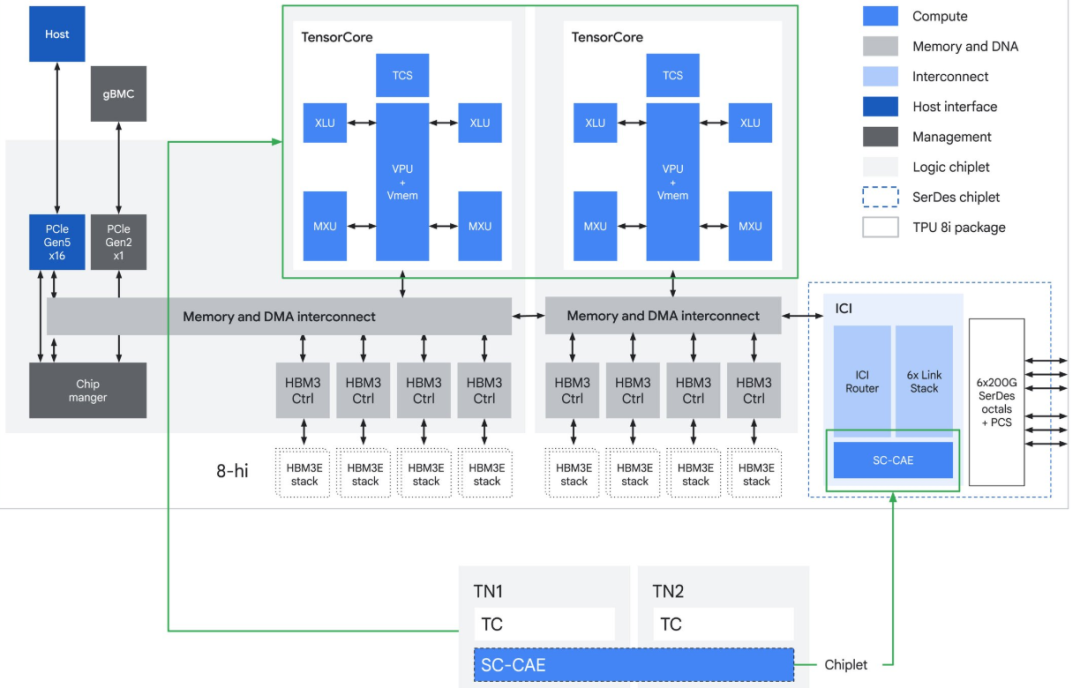
图 | TPU 8i ASIC 框图(来源:谷歌)
TPU 8i 的另一项关键创新是集体通信加速引擎。当大模型进行推理的时候,尤其是在处理混合专家模型时,芯片之间需要频繁地同步数据和汇总结果,这个过程叫做集体通信。要是做得不好,芯片的大部分时间都在干等。
TPU 8i 的 CAE 专门负责加速这个环节,把延迟降低了五倍。它还把芯片之间的互联带宽翻了一番,达到了 19.2 Tb/s。
与此同时,谷歌还为 TPU 8i 设计了一种名为 Boardfly 的全新网络连接方式。传统的 3D Torus 网络在连接大量芯片时,数据包在芯片之间传输时需要经过很多跳。Boardfly 通过借鉴 Dragonfly 拓扑的思想,利用增加长距离直连链路的方式,把由 1024 颗芯片组成的系统里的最远的两个芯片之间的通信距离从 16 跳减少至 7 跳,降低了 56%,让任何两颗芯片之间都能更快地交换信息,助力更好地处理复杂的推理任务。
这些改进让 TPU 8i 在推理任务上的性价比比上一代提升了 80%。对于一家企业用户来说,将能用同样的成本服务将近两倍的客户。谷歌还为 TPU 8i 搭配了自研的 Axion ARM 架构 CPU,并做了针对性优化,让系统运行得更顺畅。
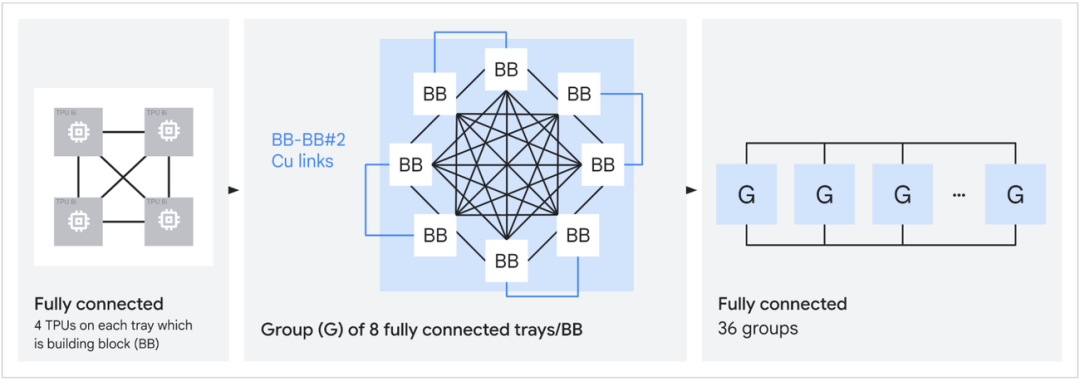
图 | TPU 8i 分层式 Boardfly 拓扑结构(来源:谷歌)
众所周知,谷歌这套 TPU 体系已经运行了很多年,谷歌的 Gemini 正是跑在 TPU 之上。如前所述,他们这次将第八代 TPU 开放给了所有云客户,旨在为全球开发者构建一座通往更高 AI 想象力的算力基石。总的来说,在智能体时代这种芯片设计上的精细化分工,将有利于打造一个随叫随到、反应灵敏的 AI 应用。
参考资料:
https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/eighth-generation-tpu-agentic-era/
https://cloud.google.com/blog/products/compute/tpu-8t-and-tpu-8i-technical-deep-dive/
https://www.bloomberg.com/news/articles/2026-04-22/google-cloud-releases-new-tpu-chip-lineup-in-bid-to-speed-up-ai
https://x.com/patrickmoorhead/status/2046928498292412771
排版:胡巍巍





