 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库DeepSeek V4来了:在喧哗众声中,按自己的节奏讲开源故事

4 月 24 日,DeepSeek 在 Hugging Face 上传了 V4 系列的预览版本。这一代分两个型号,旗舰 V4-Pro 总参数 1.6 万亿、激活 490 亿,V4-Flash 总参数 2,840 亿、激活 130 亿,两款均支持 100 万 tokens 上下文,均为 MoE 架构、纯文本模型。与模型一同放出的还有 58 页的技术报告,标题为《DeepSeek V4:迈向高效的百万 token 上下文智能》。
1.6T 的参数规模比年初泄露的 1T 传闻高出 60%,一周前 DeepGEMM 算子库的更新放出时,社区就已经反推出了这个数字。技术报告里还有一个此前没有的细节:V4-Flash 训练了 32T tokens,V4-Pro 训练了 33T tokens,都比 V3 的 14.8T 高了一倍多。
把账算在注意力机制上
V4 最核心的架构改动是一个分层的混合注意力机制。DeepSeek 这次设计了两个模块:Compressed Sparse Attention(CSA)和 Heavily Compressed Attention(HCA),在各层之间交替使用。CSA 先把每 4 个 token 的 KV cache 压成 1 个 entry,再在压缩后的序列上跑稀疏注意力(V3.2 引入的 DSA 机制的延续),每个查询只和 top-k 个压缩块做注意力;HCA 则更激进,直接把每 128 个 token 压成 1 个 entry,但保持稠密注意力。
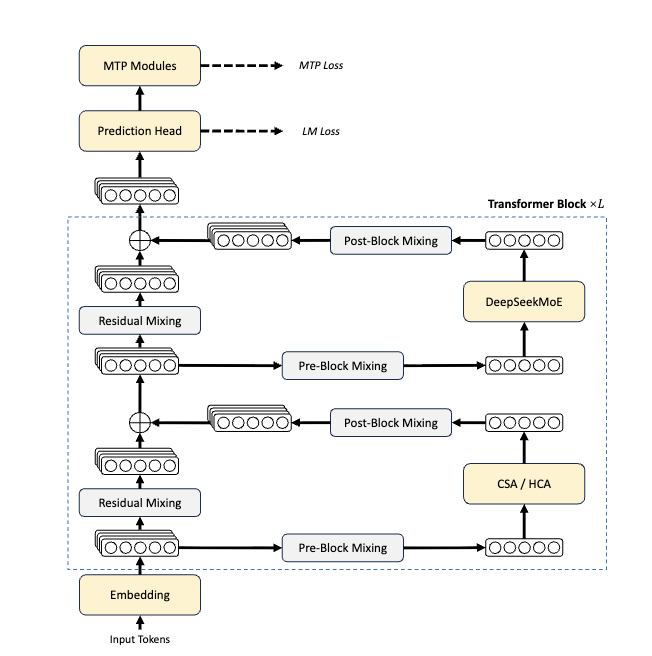
图丨DeepSeek-V4 系列的整体架构(来源:DeepSeek)
两者配合的结果是:在 100 万 tokens 上下文下,V4-Pro 的单 token 推理 FLOPs 只有 V3.2 的 27%,KV cache 只有 10%;V4-Flash 更极端,FLOPs 是 V3.2 的约 10%,KV cache 是 7%。和传统 BF16 GQA8 的基线对比,V4 在 1M 场景下的 KV cache 可以压到基线的约 2%。
这条路线和 V3.2 是一脉相承的。V3.2-Exp 去年 9 月第一次引入 DSA 的时候就把推理成本腰斩过一次,并且当时 DeepSeek 就明确说这是“面向下一代架构的中间步骤”。现在我们终于看到了那个“下一代”是什么样子:不是把稀疏换成别的激进方案(比如此前外界广泛押注的 Engram 条件记忆),而是把稀疏和压缩再组合一层。
不走运的训练,和两个救命的土办法
DeepSeek 在技术报告里花了不短的篇幅承认 V4 训练并不顺利。万亿参数 MoE 有经典的 loss spike 问题,简单回滚救不回来。团队最后找到两个经验性的技巧把训练压住了,而且在报告里直说“它们背后的原理目前还不清楚,公开出来希望社区一起研究”。
第一个叫 Anticipatory Routing(预测性路由)。常规做法是每一步训练时主干网络和路由网络同步更新;DeepSeek 发现把这两者解耦能显著压住 loss spike,做法是在第 t 步用当前参数做前向计算,但路由决策用历史参数 θ_{t-Δt}。为了不让这个设计拖慢训练,他们还加了一个自动检测机制,只在真的出现 loss spike 的时候才切到这个模式,整体额外开销被控制在训练时间的 20% 以内。
第二个更简单粗暴,叫 SwiGLU Clamping:直接把 SwiGLU 的线性输出钳制到 [−10, 10]、门控上界也限到 10。这个 trick 最早出现在 OpenAI 今年的 gpt-oss 技术报告里,DeepSeek 发现它能有效抑制 MoE 层里出现的 outliers,就直接用了。
除此之外,V4 用 Muon 替代了 AdamW 作为主优化器(embedding、prediction head、RMSNorm 仍用 AdamW),并设计了一套 hybrid Newton-Schulz 迭代来做权重正交化。另一项底层改动是流形约束超连接(mHC),把残差映射矩阵约束在 Birkhoff 多面体上,保证它的谱范数不超过 1,从而让信号在深层传播时不会爆炸。在工程侧,mHC 的 wall-time 开销被控制在 1F1B 流水线阶段的 6.7%。
Post-training:放弃 mixed RL,换成多教师蒸馏
真正让 V4 和 V3.2 在方法论上分岔的,是 post-training。技术报告中提到,V3.2 的 mixed RL 阶段在 V4 被整体替换成了 On-Policy Distillation(OPD)。
新的流水线分两段。先分别训练几十个领域专家模型,覆盖数学、代码、Agent、指令跟随,每个专家都跑一遍 SFT + GRPO 强化学习,产出一个在自己领域内极强的“偏科生”。
然后在第二阶段,把十几个 teacher 模型的 logits 蒸馏到一个 student 模型里,学生在自己产生的 trajectory 上对每个 teacher 优化 reverse KL loss。这种“先分头培养专家、再合并成通才”的路线,DeepSeek 在报告里直接点名参考了 Thinking Machines Lab 今年 10 月的 on-policy distillation 工作。
为了绕开 mixed RL 常见的能力冲突和权重合并时的性能退化,OPD 把各领域的专业能力在 logits 空间对齐到同一组参数里。配套的工程细节是:teacher 模型权重全部卸载到分布式存储按需加载,每个 teacher 的 last-layer hidden states 单独缓存,训练时再投一次 prediction head 重构 logits,从而规避 100k+ 词表直接物化 logits 的显存灾难。
另外,V4 引入了新的工具调用 schema,用特殊 token |DSML| 配 XML 格式替代 V3.2 的 JSON,技术报告里的原话是 XML 能“有效减少转义错误和调用失败”。
还有一个不起眼但对实际产品有用的改动叫 Quick Instruction:在输入序列里追加若干特殊 token,让 intent 识别、搜索查询生成、是否需要读 URL 等辅助任务直接复用已经算好的 KV cache,不用再起一个小模型做前置判断,这对 TTFT(首 token 延迟)有直接影响。
跑分:代码登顶,知识仍差一截
V4-Pro-Max(V4-Pro 的 Max reasoning 模式)和当前第一梯队的 Claude Opus 4.6 Max、GPT-5.4 xHigh、Gemini 3.1-Pro High 对比,优势集中在代码和数学,短板集中在纯知识。
代码和数学竞赛是 V4 的主场:Codeforces 3206 Elo,超过 GPT-5.4 的 3,168 和 Gemini 3.1-Pro 的 3052,在真实 Codeforces 人类选手排行榜上相当于第 23 名;LiveCodeBench Pass@1 93.5,领先 Gemini 的 91.7;Apex Shortlist 90.2、HMMT 2026 Feb 95.2 也都拿下第一。形式化数学上,V4 在 Putnam-2025 上以 120/120 达成完美证明,追平 Axiom,超越 Aristotle 和 Seed-Prover。
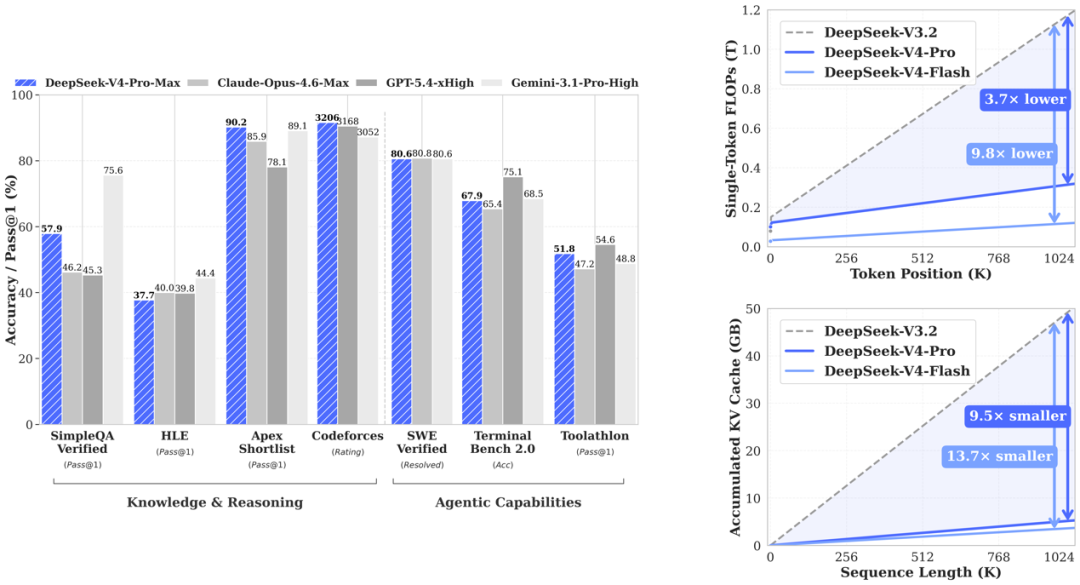
图丨基准测试结果(来源:DeepSeek)
但纯知识和最难的通用推理,V4 离前沿闭源还有明显距离。SimpleQA-Verified 57.9% 相对 Gemini 3.1-Pro 的 75.6% 差了 17 个百分点;HLE(Humanity's Last Exam)Pass@1 只有 37.7%,落后 Gemini 的 44.4。团队在 Summary 部分很坦诚地表示:V4-Pro-Max 的推理能力“超过 GPT-5.2 和 Gemini-3.0-Pro,但略低于 GPT-5.4 和 Gemini-3.1-Pro,对应大约 3 到 6 个月的发展差距”。
V4-Flash-Max 的定位也被明确:推理任务上能打到 V4-Pro-Max 的水准,但知识密度和最复杂的 agentic workflow 上,小尺寸依然吃亏,这本来也是 MoE 结构的预期表现。
真实任务:超 Sonnet 4.5,追 Opus 4.5
技术报告还专门评测了几项 DeepSeek 自己用户最常用的真实场景。
中文写作测试里,V4-Pro 在功能性写作上以 62.7% 对 34.1% 胜 Gemini 3.1-Pro(理由是 Gemini“经常用自己的风格偏好覆盖用户要求”);创意写作的指令跟随 60% 对 40%、写作质量 77.5% 对 22.5% 也都压过 Gemini。但换到最难的任务,比如高复杂度约束、多轮对话,Claude Opus 4.5 还是以 52.0% 对 45.9% 反超 V4-Pro。
内部的 30 个中文白领任务评测里,V4-Pro-Max 整体非输率 63%,单项得分在任务完成和内容质量上显著高于 Opus-4.6-Max,但在格式审美和指令遵循上略输。报告给出的解释是 V4 更擅长长段叙事和主动补全用户潜在意图,而 Opus 更擅长精确执行具体格式约束和简洁摘要。
在代码 Agent 方面,DeepSeek 从 50 多位内部工程师那里收集了 200 多个真实 R&D 任务,筛选出 30 个作为评测集,覆盖 PyTorch、CUDA、Rust、C++ 的功能开发、bug 修复、重构等场景。
通过率分布如下:Claude Haiku 4.5 13%、Sonnet 4.5 47%、V4-Pro-Max 67%、Opus 4.5 70%、Opus 4.5 Thinking 73%、Opus 4.6 Thinking 80%。V4 把 Sonnet 4.5 甩开 20 个百分点,但还差 Opus 系列一个身位。配套的 85 人内部调研里,52% 的开发者说 V4-Pro 可以作为日常编程的主力模型,另有 39% 表示“倾向于可以”。
率道而行
一个礼拜前,X 平台上普林斯顿博士生 Yifan Zhang 放出的 V4 完整规格单和今天的报告大部分对得上:Muon 优化器、纯文本、每层 384 个专家激活 6 个(Pro 版配置)、GRPO。但两个关键点和爆料有偏差。一是 DeepSeek 最终把注意力机制命名成了 CSA + HCA 混合,而不是此前流传的 “DSA2(NSA + DSA)”。二是此前多个爆料反复暗示的"原生多模态"并没有出现,V4 依旧是纯文本,略有遗憾。
另一个被传了很久但没出现的是 Engram 条件记忆。去年底到今年初,中文圈普遍押注 V4 会引入 Engram 作为核心,把静态知识检索从 attention 里独立出去。
V4 最终没走这条路,而是在既有的稀疏注意力框架内做得更深:CSA 的压缩+稀疏两步组合,是对 V3.2 DSA 的连续演进。值得一提的是,DeepSeek 在报告最后的 Future Directions 里留了一手,下一步要探索“更稀疏的 embedding 模块”,并点名引用了 2026 年 1 月的 Conditional Memory via Scalable Lookup 论文。
过去几个月,关于 DeepSeek 的叙事从“神话”滑到“跌下神坛”再到“已经掉队”;关于 V4 的技术猜测从 1T 到 1.6T、从 DSA2 到 Engram、从原生多模态到纯文本之间来回切换。V4 发布这天,官方推文没有回应这些猜测中的任何一条,没有反驳,也没有比较,只引了一句《荀子·修身》:“不诱于誉,不恐于诽,率道而行,端然正己。”
参考资料:
1.https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
运营/排版:何晨龙
注:封面/首图由 AI 辅助生成





