 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库面向大数据、AI时代的光网络片上光交换集成技术 | “北京邮电大学建校70周年” 纪念专辑亮点文章



随着人工智能、大数据等引领新一轮技术革命,其对海量数据交换与光电转换的需求日益突出。在北京邮电大学建校70周年之际,杨辉教授团队面向智能时代光网络发展需求,对片上光交换集成技术展开系统性综述,详细梳理了光交换芯片的三种核心开关单元、三类拓扑结构设计及优化路径,并深入探讨了该技术在智算数据中心(AIDC)中的应用演进与发展前景,为构建超高速率、超大容量、超大规模、超高可靠的智能时代光网络提供关键技术支撑。相关论文被选为《光学学报》“北京邮电大学建校70周年”纪念专辑亮点文章。

链接: 杨辉, 冯俊基, 孟大清, 姚秋彦, 梁毅杰, 赵晨. 面向智能时代光网络片上光交换集成技术综述(特邀)[J]. 光学学报, 2026, 46(7): 0700010.
随着人工智能、机器学习、大数据等技术的快速发展,全球数据流量呈现出爆炸性增长的趋势。预计到2030年,全球数据流量将接近400ZB(图1)。这种持续攀升的数据需求对现有的网络基础设施造成前所未有的挑战,特别是在AIDC内万卡级GPU集群的分布式协同训练中,对海量数据的低延迟交互提出了更高需求。
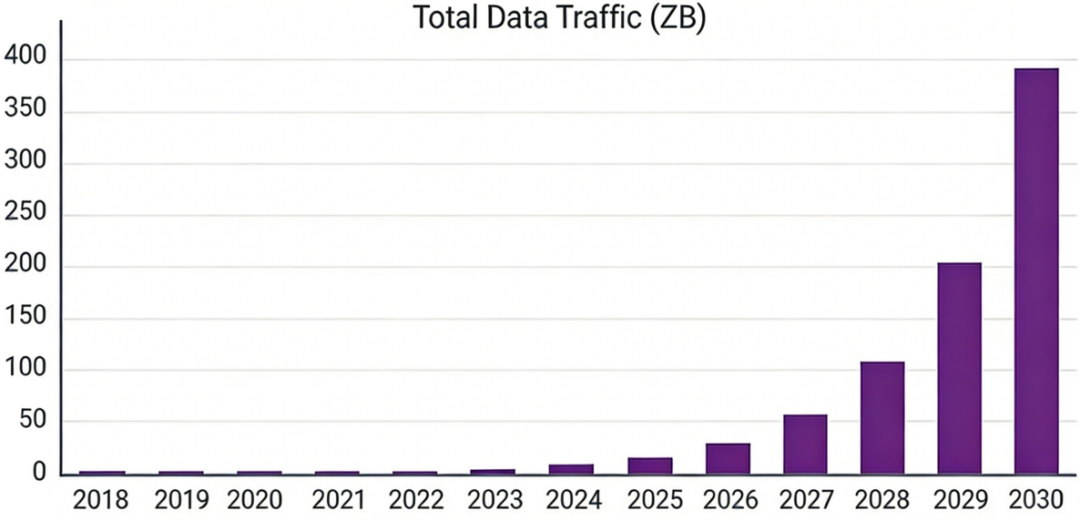
图1 到2030年的总数据流量预测
在传统的网络基础设施中,机架与计算节点间的通信高度依赖“光-电-光”转换模式。然而,随着通道传输容量的不断提升,电交换处理能力难以与信道容量相匹配,不仅存在严重的电子瓶颈,其高昂的通信功耗也严重制约了算力效率的提升。
相比之下,片上光交换集成技术通过以光信号的形式、在芯片上直接实现数据的无损传输和高速交换,避免了光电转换带来的损耗和信号损伤。该技术具备高速率、高带宽、高集成度和低功耗等优势,正逐渐成为构建智能时代光网络的关键技术。
片上光交换集成技术的核心载体是光交换芯片,其整体性能主要由底层的光开关单元与网络的拓扑结构共同决定。研究团队系统梳理其核心单元、拓扑结构设计及优化路径,探讨并分析片上光交换集成技术在智算数据中心的应用演进趋势。
(1)核心单元:构建光交换芯片的“底层基石”
光开关单元直接决定了芯片的带宽、串扰和响应速度,研究团队梳理了目前主流的三种结构,依托不同物理机制实现差异化性能适配。
基于马赫-曾德尔干涉仪(MZI)的光开关通过调控两臂相位差实现光路切换,天然具备大带宽和高稳定性。相关研究表明,通过优化波导相移臂设计、引入热光/电光双模式切换等手段,能够实现纳秒甚至皮秒级超高速切换,是高速大容量场景的核心选择(图2)。
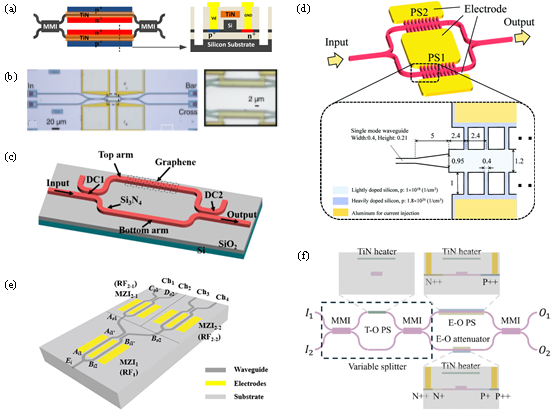
图2 基于MZI结构的光开关优化方法。(a)双模式切换开关单元;(b)宽波导相移臂开关单元;(c)基于石墨烯-氮化硅的全光开关;(d)TO-MZI光开关;(e)超快高消光比光开关;(f)超低串扰开关单元
基于微环谐振器(MRR)的光开关具有结构紧凑、易于高密度集成的特点,尤为擅长波长、偏振等多维度选择性调控。相关研究表明,通过引入相变材料(如GST)辅助、级联微环等设计,实现了高消光比及“零静态功耗”的非易失性光开关,可大幅提升片上集成密度,在混合复用光网络中展现出极强的适配能力(图3)。
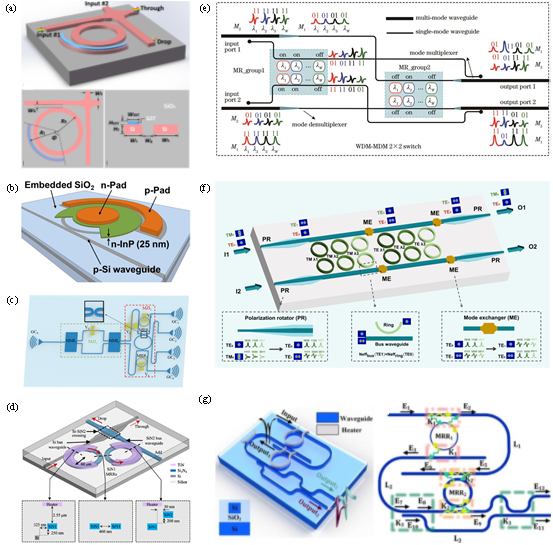
图3 基于MRR结构的光开关优化方法。(a)基于GST辅助MRR的波长选择性光开关;(b)基于III-V/Si混合MOS光学移相器的MRR光开关;(c)基于MZI与MRR耦合的硅基光开关;(d)基于Si₃N₄-on-SOI平台的MRR光开关单元;(e)WDM-MDM 2×2光开关单元;(f)偏振和波长选择开关;(g)双级联MRR的STS器件
基于半导体光放大器(SOA)的光开关利用半导体材料的增益饱和等非线性效应工作,可同时完成光信号切换与放大,直接补偿芯片损耗,实现无损光交换。相关研究表明,通过异质集成、MZI耦合架构优化,可覆盖C/L/O多波段传输,适配智算数据中心多场景通信需求(图4)。
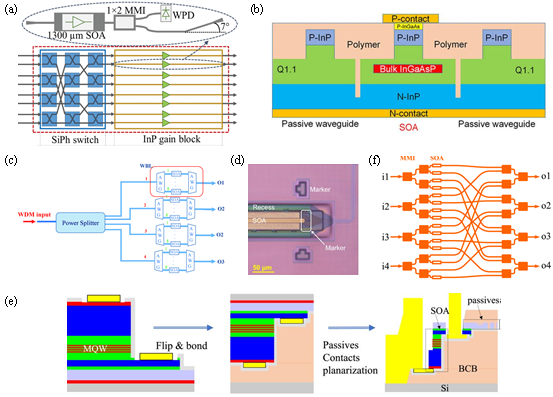
图4 基于SOA结构的光开关优化方法。(a)基于SiPh/InP SOA混合光开关;(b)对接耦合波导与无源波导共集成的SOA;(c)SOA与AWG共集成波长选择开关;(d)微转印后的SOA结构;(e)基于IMOS平台的SOA光开关双面制造工艺流程;(f)4×4广播选择型SOA光开关
三种光开关结构在性能与功能上的互补性,为光交换芯片的多元化设计与场景化适配提供了丰富可能,共同推动其向更高集成度、更低功耗、更优性能的方向发展。
(2)拓扑结构:支撑数据高效传输的“网络骨架”
要将成百上千的光开关单元组合成高效的交换矩阵,必须依赖精妙的拓扑结构。研究团队梳理了目前主流的三类拓扑结构,针对性分析不同场景适配的拓扑结构。
阻塞型拓扑因结构简单、硬件复杂度低得以广泛应用,但存在固有阻塞问题。现有研究主要通过拓扑级联、优化路由算法和融合多维度调控技术等方式,在缓解链路阻塞的同时提升交换效率与性能(图5)。
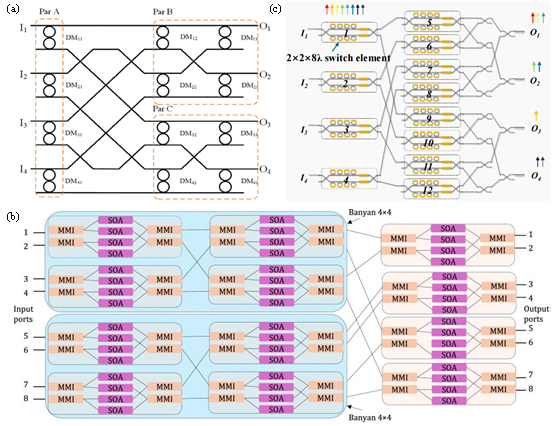
图5 阻塞型拓扑结构优化方法。(a)基于Butterfly拓扑的双MRR光开关;(b)8×8 Banyan模块化交换结构;(c)基于改进扩展Banyan拓扑的4×4×8λ光开关
重排无阻塞型拓扑在任意状态下均能通过重排算法建立新连接,其优势是所需驱动单元少、损耗极低。现有研究主要通过路由算法优化和混合复用提升可扩展性,同时利用自动校准技术降低控制复杂度,以适配中等规模光交换场景(图6)。
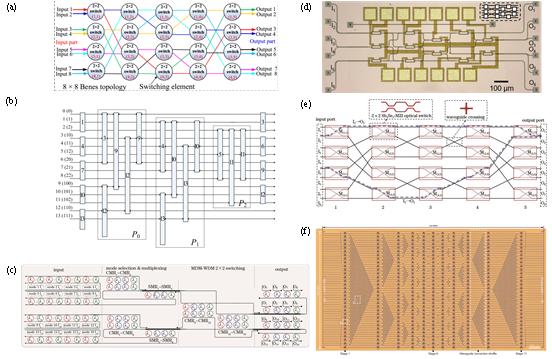
图6 重排无阻塞型拓扑结构优化方法。(a)O-Star中的8×8 Benes拓扑结构;(b)A2-Benes网络;(c)基于波长和模式混合复用的16×16片上光交换网络;(d)基于Spanke-Benes拓扑的MZS光交换芯片;(e)基于Sb2Se3-MZI的Benes光交换网络;(f)基于Benes拓扑的64×64光交换芯片
完全无阻塞型拓扑包含Crossbar、PILOSS、S&S、DLN四种架构,无需调整已有连接即可新建光路,是智算数据中心的理想选择。现有研究主要通过3D波导交叉、端口重布局、多层集成等方面优化设计,解决大规模集成时的链路损耗与串扰难题(图7)。

图7 完全无阻塞型拓扑结构优化方法。(a)8×8 Crossbar拓扑结构及双向传输路径;(b)Dilated Crosspoint拓扑结构;(c)输入输出端口相邻的PILOSS拓扑;(d)32×32 PILOSS拓扑中最差串扰路径;(e)8×8 PA-SAS拓扑结构;(f)32×32 S&S光开关及层间交叉结构;(g)基于8×8 DLN拓扑的ONRAMPS光开关;(h)DLN拓扑及开关单元
光交换芯片的拓扑结构设计是实现高性能光交换的核心,现有研究主要围绕阻塞型、重排无阻塞型和完全无阻塞型三类拓扑展开优化,三者共同推动了光交换芯片向更大规模、更低损耗和更高可靠性的方向发展。
(3)在智算数据中心的应用演进
面向智算时代万卡级GPU超算集群的发展趋势,光交换芯片在高密度、高带宽算力互联场景中,展现出极强的适配潜力与应用价值。
目前可用于AIDC的光交换芯片规模已从8×8稳步扩展至32×32,部分设计正向128×128端口迈进。在驱动模式上,既涵盖了用于长时长任务调度的微秒级(μs)热光开关,也包含了处理突发流量的纳秒级(ns)电光开关。依托先进的光电混合封装技术,这些交换芯片能够以极小的面积,支撑超百G速率的无损信号传输,全面赋能智算中心的高效算力协同(图8)。

图8 光交换芯片在智算数据中心的应用(a)8×8 SOA光交换芯片;(b)8×8 DLN光交换芯片;(c)8×8 O波段PILOSS光交换芯片;(d)基于SOA光开关的纳秒级光交换与控制系统;(e)基于3D双耦合MRR的8×8光交换芯片;(f)32×32 S&S光交换芯片;(g)4×4×4λ空间-波长选择交换芯片;(h)32×32 O波段光交换芯片;(i)基于三层SiN-on-Si平台的 8×8 TO/EO光交换芯片;(j)193 nm深紫外光刻的8×8 TO/EO光交换芯片
目前,片上光交换集成技术正处于快速发展与挑战并存的阶段。随着智算中心对超万卡级集群互联需求的不断增加,光交换芯片向更大规模拓展时,在封装边缘I/O密度受限、异质集成良率以及高密度热管理等方面仍面临诸多挑战。
结合快速发展的芯粒(Chiplet)技术与光电共封装(CPO)技术,将光交换系统解耦为负责信号传输的光交换芯粒与驱动配置的电控制芯粒,再依托CPO技术将它们在同一基板上进行高密度共封装,将是突破现有瓶颈的重要发展方向。这不仅能将互连距离缩短至微米级、极大降低信号损耗,还能通过共享散热系统有效解决多芯片协同的热管理难题。
未来,随着异质集成和先进封装技术的进一步成熟,超大规模、超高可靠性的片上光交换集成技术有望在智能计算光网络中获得规模化落地应用。

杨辉,北京邮电大学电子工程学院院长,信息光子学与光通信全国重点实验室主任助理,教授,博士生导师。发表ESI高被引和特邀期刊论文等SCI论文70余篇,出版专著入选国家出版基金,授权国内国外发明专利50余项。获得国家科学技术进步奖二等奖1项,获中国通信学会科学技术奖一等奖等省部级和社会力量奖10余项。获得北京市杰出青年中关村奖、中国通信学会青年科技奖等,8次获得国际学术会议最佳论文奖。

END
点在看联系更紧密





