 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库大模型为什么按照Token计费?
随着智能体的火爆推行,大家都在买Token。很多人都会有一个很自然的疑问:同样一句长度差不多的话,“1+1等于几?”和“请分析近30年的GDP变化趋势”,显然后者复杂得多,按理说也应该更耗算力。
那为什么大模型平台普遍不是按“问题复杂度”收费,而是按 Token 收费?
这个问题看似简单,背后其实涉及大模型最核心的运行方式。
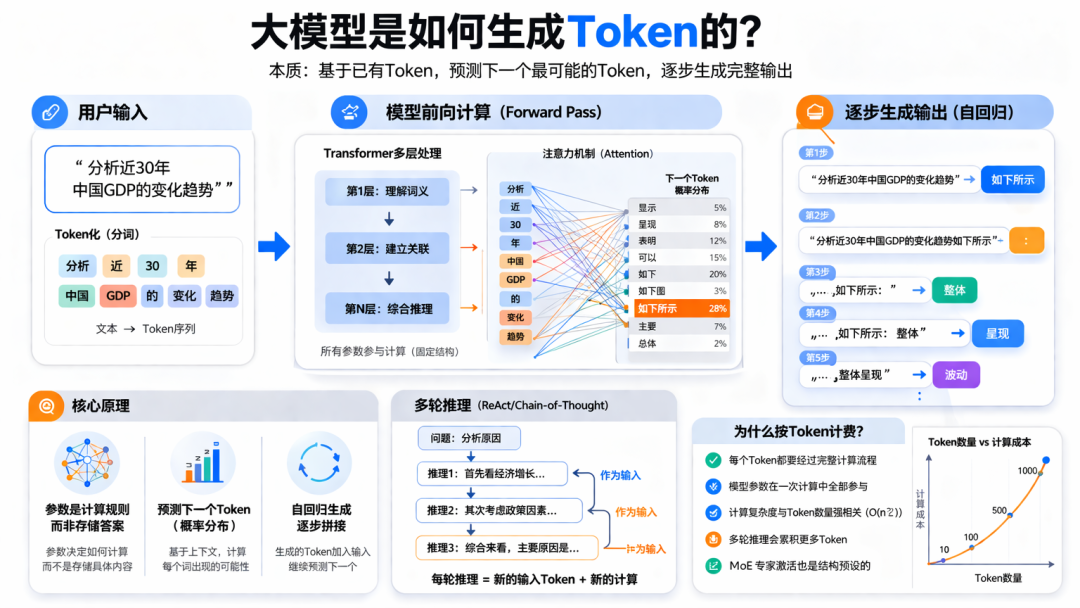
注释:大模型生成Token示意图
可以把 Token 理解为模型处理文本时使用的基本单位。
一句话输入给模型后,会先被拆成一个个 Token;模型输出答案时,也是一段段 Token 逐步生成出来的。
所以,一次调用的消耗通常就是:
输入 Token 数 + 输出 Token 数
再乘以对应单价,就是这次请求的费用。
也就是说,平台计费时首先看到的,不是“这道题难不难”,而是:
你输入了多少内容
模型输出了多少内容
直觉上,大家会这样想:
“1+1等于几”很简单
“分析30年GDP变化趋势”很复杂
既然复杂问题需要更多分析,似乎就应该调用更多算力,因此按复杂度收费才更合理。
但问题在于:大模型并不是按人类理解的“思考难度”来工作的。
它的真实机制,和我们的直觉差别很大。
这是理解整个问题的关键。
很多人以为,大模型像在庞大知识库里“查答案”。
其实不是。
更准确地说,大模型在做的事情是:
根据已有 Token,预测下一个最可能出现的 Token。
比如你输入一句话,模型不是先找到一个完整答案再吐出来,而是这样工作的:
已有内容
→ 预测下一个 Token
→ 拼上去
→ 再预测下一个
→ 再拼上去
→ 一步一步生成完整回答
所以,大模型更像是在做一种极其强大的“文字接龙”,而不是“数据库检索”。
如果想再往底层理解一步,就绕不开一个概念:前向计算。
所谓前向计算,可以简单理解为:
把输入丢进模型,从头到尾算一遍,得到输出结果。
流程大致是这样的:
输入文本
→ 切分成 Token
→ 转成数字向量
→ 进入模型多层计算
→ 得到“下一个 Token 的概率分布”
→ 选出一个 Token
→ 再继续下一轮生成
这里要特别注意一点:
模型参数里并不“存着答案”。
参数更像是一套经过训练形成的计算规则。
它们的作用不是把现成答案拿出来,而是根据上下文,计算“下一个 Token 最可能是什么”。
所以更准确的说法不是“从参数里提取答案”,而是:
模型利用参数,对输入进行计算,逐步预测并生成答案。
这就是最容易让人误解的地方。
我们的直觉是:
简单问题少想一点,复杂问题多想一点。
但对普通大模型来说,并不是这样。
1. 一次前向计算,走的是同一套模型结构
无论你问的是:
“1+1等于几?”
“分析近30年GDP变化趋势”
只要输入长度接近,模型都会按同样的结构跑一遍。
在这个过程中,模型并不会因为问题“更难”,就自动多开几层、多调几套参数、多思考几轮。
也就是说,不是难题就多用一部分模型,简单题就少用一部分模型。
在标准模型里,一次推理通常都是同一个模型结构、同一套参数在工作。
2. 真正更影响成本的,是 Token 长度
模型最吃算力的部分之一,是 Attention 机制。
它可以粗略理解为:
每个 Token 都要和其他 Token 计算关系。
如果 Token 数量记作 n,那么计算量大致和 n² 相关。
比如:
10 个 Token,需要处理的大约是 10×10 的关系
1000 个 Token,需要处理的大约是 1000×1000 的关系
这就是为什么:
长文本、长上下文、长输出,往往比“问题难不难”更直接影响成本。
所以,从工程角度讲,按 Token 计费是有现实基础的,因为 Token 数量和真实计算成本高度相关。
如果只是单轮回答,模型通常是:
输入一次 → 计算一次 → 输出答案
但如果涉及多轮推理,情况就不一样了。
多轮推理的本质,并不是模型在内部“默默多想了几步”,而是:
把上一轮输出,再作为下一轮输入,重新跑一遍模型。
例如:
第1轮:输入问题,得到中间结果
第2轮:输入“问题 + 第1轮结果”,继续计算
第3轮:输入“问题 + 前两轮结果”,得到最终答案
这意味着什么?
意味着每一轮新的推理,都会带来两件事:
输入上下文变长
模型要重新做一次完整前向计算
而前面说过,计算成本和 Token 数量强相关。
所以一旦进入多轮推理,Token 会持续累积,成本自然上升。
这也是为什么很多 Agent 系统、复杂推理系统特别“费 Token”。
因为它们不是只算一次,而是在不断地:
输出中间结果 → 再喂回去 → 再计算
这里可以补充一个常见疑问。
确实,有一类模型叫 MoE(Mixture of Experts,混合专家)。
这类模型不会每次都激活全部专家模块,而是会根据路由机制只激活其中一部分。
但即便如此,也不能简单理解为:
“问题越复杂,就自动调用越多专家,因此按复杂度收费更合理。”
因为 MoE 激活哪些专家,主要是由模型内部的路由机制和结构设计决定的,并不是按照人类主观理解的‘任务难度’动态分配的。
所以从整体上看,计费逻辑依然更适合围绕 Token,而不是围绕“复杂度”来定义。
把前面的内容收拢起来,其实答案就很清楚了。
大模型的核心机制不是“按难度思考”,而是:
把文本切成 Token
基于已有 Token 预测下一个 Token
按固定模型结构完成前向计算
在多轮推理中,把前一轮结果继续作为输入重复计算
因此,平台更容易测量、也更接近真实成本的,不是“这道题有多难”,而是:
这次一共处理了多少 Token。
所以:
从工程实现上看,按 Token 计费是合理的
从用户直觉上看,它未必完全公平
但至少在今天,这是最清晰、最可量化、也最可执行的方式
大模型不是按“题目难度”收费,而是按“处理了多少内容”收费。
它不是在按思考量计费,而是在按计算过程中经过的 Token 数量计费。
这,就是为什么大模型普遍按照 Token 收费,而不是按照推理复杂度收费。





