 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库机器学习、深度学习、大模型是什么关系?
这几年,机器学习、深度学习、大模型、监督学习、自监督学习、强化学习、Transformer这些词反复出现。有的在说模型怎么学,有的在说模型用什么结构学,还有的在说大模型是怎么一步步练出来的,先把整体关系放到一张图里看。
一、先看全局:一张图把关系理顺
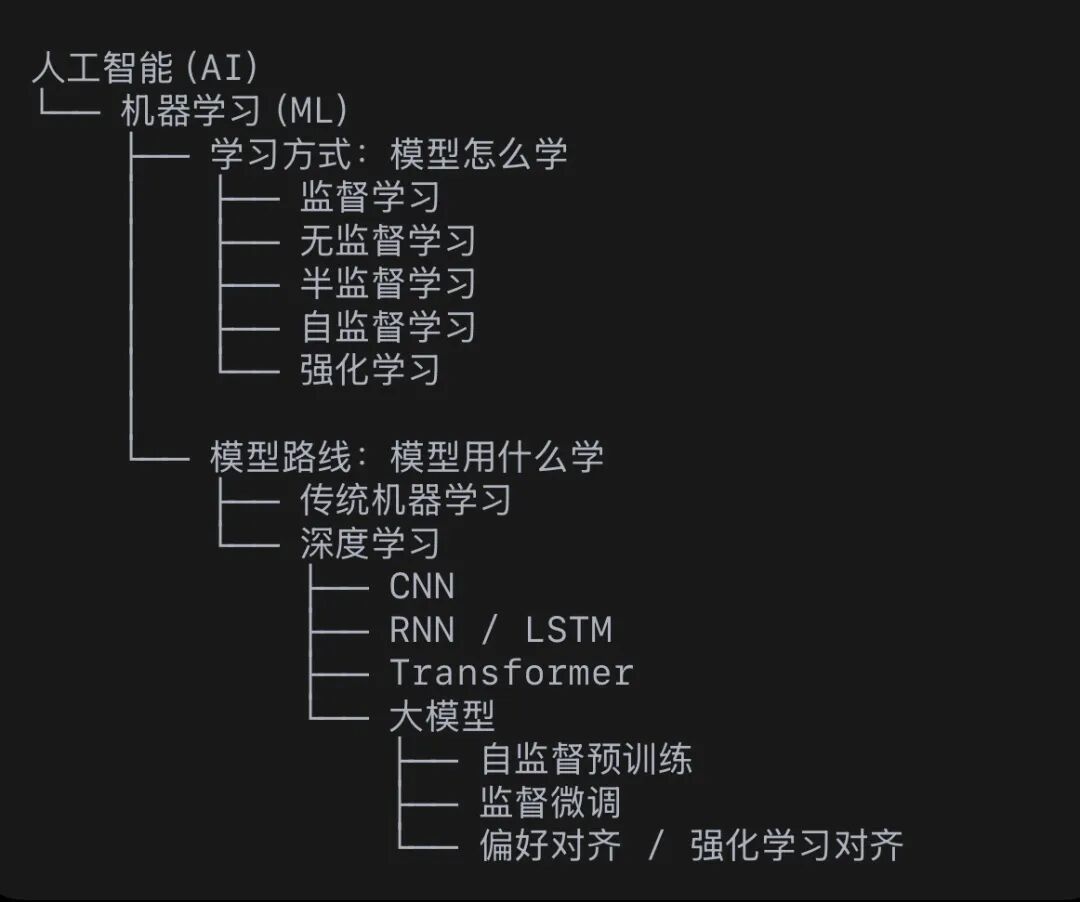
这张图里最关键的一句话是:
监督学习、自监督学习、强化学习,讲的是模型怎么学(学习范式);传统机器学习、深度学习、Transformer,讲的是模型用什么结构学(模型结构);大模型则是深度学习发展出来的大规模通用模型。
如果这句话顺了,后面很多概念就不会再缠在一起。
二、概念解释:每个概念只记一句话
人工智能(AI)
人工智能是最大的概念。凡是让机器表现出某种“智能行为”的方法,都可以放在这个框架里。机器学习只是其中最重要的一条路线。
机器学习(ML)
机器学习的核心,不是人把规则全部写死,而是让机器从数据中自己学规律。比如识别垃圾邮件、预测房价、判断风险等级,这些都属于机器学习。
传统机器学习
传统机器学习是机器学习里比较经典的一类方法,比如线性回归、逻辑回归、决策树、随机森林、SVM。它们往往更依赖人工设计特征,在表格数据、中小样本、可解释性要求高的场景里仍然很好用。
深度学习(DL)
深度学习是机器学习中的一条重要路线,特点是用多层神经网络自动学习特征和映射关系。图像识别、语音识别、自然语言处理这些方向近十几年的突破,深度学习是核心原因。
Transformer
Transformer 是一种深度学习模型结构。它不是一种学习方式,而是一种网络架构。今天主流的大模型,基本都建立在 Transformer 之上。
大模型
大模型本质上是深度学习发展出来的大规模通用模型。它通常基于 Transformer,用海量数据和大规模参数训练而成,不是独立于深度学习之外的一套新东西。
监督学习
监督学习的特点是训练数据里有人工标注好的答案。可以简单理解为:人先把题库做好,模型照着学。比如“这张图是猫”“这封邮件是垃圾邮件”“这条数据是高风险”。
无监督学习
无监督学习没有人工标签,模型只能从数据本身去找结构。比如聚类、降维、异常检测。它不是在学“标准答案”,而是在学“数据本身有什么规律”。
半监督学习
半监督学习是少量有标签数据,加大量无标签数据一起训练。本质上是一种折中,因为现实里原始数据很多,但人工标注很贵。
自监督学习
自监督学习没有人工标签,但能从原始数据中自动构造训练目标。比如一句话“今天青岛有大风”,可以改成“今天青岛有大”去预测“风”;也可以把其中一个词遮住,让模型去猜被遮住的词。说得直白一点:人设计规则,答案从数据本身提取出来。
强化学习
强化学习不是看标准答案来学,而是在环境中不断试错,根据奖励和惩罚学习策略。它更像在学“怎么决策”,而不是学“这道题标准答案是什么”。适合路径规划、机器人控制、调度优化这类连续决策问题。
大模型的训练流程
把大模型训练过程压缩来看,通常可以理解成三步:先用自监督学习做预训练,再用监督学习做微调,最后再做偏好对齐,让模型回答得更符合人类期待。
偏好对齐
偏好对齐的目标,是让模型不仅会回答,还要回答得更像一个“好助手”。比如更有帮助、更清楚、更安全、更少跑偏。
三、难点解析:最容易混淆的几个问题
深度学习属于监督学习吗?
不属于。
因为深度学习和监督学习不是一个维度的概念。深度学习说的是模型结构路线,监督学习说的是训练方式。深度学习可以用来做监督学习,也可以做自监督学习,还可以和强化学习结合。
Transformer 是自监督模型吗?
不是。
Transformer 是一种模型结构,不是一种学习方式。它之所以经常和自监督学习一起出现,是因为今天很多自监督预训练任务喜欢用它,但这不代表它本身就是“自监督模型”。
自监督学习属于监督学习吗?
严格来说,通常不算传统意义上的监督学习。
因为监督学习强调人工标签,而自监督学习的目标是从原始数据中自动构造出来的。更准确地说,自监督学习在训练形式上有“输入—目标”的监督味道,但它没有人工标签。
强化学习属于监督学习吗?
不属于。
监督学习靠“标准答案”学,强化学习靠“奖励反馈”学。一个是老师直接告诉你答案,一个是老师只告诉你这次做得好不好。
大模型是不是主要靠自监督学习练出来的?
是,但不止这一步。
更完整地说,大模型通常先靠自监督学习完成预训练,学会一般规律;再靠监督学习微调,学会按指令完成任务;最后再通过偏好对齐,让回答更符合人类期待。
偏好对齐和强化学习是什么关系?
偏好对齐说的是目标,强化学习是其中一种实现手段。比如 RLHF(人类反馈强化学习),就是先收集人类偏好反馈,再把这种偏好转成奖励信号,用强化学习去优化模型。
大模型能取代强化学习吗?
不能简单这么说。
大模型擅长理解任务、规划步骤、语言表达和高层推理,更适合做高层决策。强化学习更擅长动态环境中的连续决策和长期收益优化,更适合做控制和策略问题。更现实的未来,不是谁取代谁,而是分工协同。
为什么具身智能特别强调强化学习?
因为具身智能天然就是“感知—动作—反馈—再决策”的闭环。比如机器人抓取、行走、避障、平衡,这些都不是做一次判断就结束,而是在动态环境里连续行动。这种问题和强化学习的范式高度一致。
最后,把这套关系再压缩成一句话:
监督学习、自监督学习、强化学习,讲的是模型怎么学(学习范式);
传统机器学习、深度学习、Transformer,讲的是模型用什么结构学(模型结构);
大模型则是建立在深度学习尤其是 Transformer 结构之上,通过预训练、微调和对齐一步步练出来的。
把这几层关系分开看,原来那些缠在一起的概念,基本就顺了。真正值得关注的,也不是谁会取代谁,而是每一种方法到底擅长解决什么问题,又会在未来的系统里承担什么角色。





