 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库海洋论坛▏基于深度学习的水下声光图像目标检测综述

水下目标检测技术是现代海洋工程和军事战略领域的核心支撑技术,在军事侦察、海洋资源勘探、水下机器人作业等领域具有不可替代的应用价值。然而,相较于陆空环境,水下检测受复杂水体环境影响,传统方法鲁棒性欠佳。因此,当前水下目标检测的核心需求是平衡精度与速度,确保模型在不可预测环境下的可靠运行。
水下检测主要依赖光学和声呐2种模态。光学图像凭借高分辨率、丰富纹理与色彩信息,适用于近距离精细识别,但水体对光的吸收与散射导致其传播距离短、易出现颜色失真和高噪声。相比之下,声呐图像(包括前视、侧扫、合成孔径)利用声波在水中传播距离远的优势,突破了低能见度与远距离探测的限制。然而,声呐图像存在分辨率低、强斑点噪声、特征稀疏及数据稀缺的问题,且不同类型声呐成像特性差异较大,制约检测性能提升。两者的对比如表1所示。鉴于这种互补性,声光图像联合检测成为构建高鲁棒性水下探测系统的必然趋势——通过声呐辅助定位、光学提供细节,结合自主水下航行器(AUV)位置信息实现目标精准锁定。但深度融合需克服异构数据匹配、配准与融合的技术难题。近年来,深度学习的快速发展为单模态检测优化及声光数据深度融合提供了有效路径,因此,对基于深度学习的水下目标检测研究进展进行综述,明确当前技术瓶颈与未来方向,对推动该水下检测的发展具有重要理论与实践意义。
表1 水下光学图像与声呐图像的对比

本综述旨在系统性梳理基于深度学习的水下声光图像目标检测的研究进展,遵循算法发展、单模态的挑战与对策、多模态融合、挑战与展望的递进逻辑。
⒈基于传统方法的视觉目标检测
目标检测技术经历了从依赖手工设计特征的传统方法到以深度学习为核心的转变。其发展脉络如图1所示,主要划分为3个阶段:传统方法、基于卷积神经网络(CNN)和基于Transformer。
深度学习兴起前,目标检测依赖手工特征提取与传统分类器。核心流程为3步:候选区域选取−特征提取−分类检测。
Viola-Jones检测器是早期高效的检测器,它通过Haar-like特征与自适应增强(AdaBoost)级联结构实现快速检测,但特征原始,泛化能力有限。
方向梯度直方图(HOG)检测器通过捕捉局部边缘梯度结构表征目标形状,对光照变化与几何形变具备一定鲁棒性,但难以处理目标形变与遮挡。
可变形部件模型(DPM)检测器在HOG的基础上进行改进,作为传统方法的巅峰,将目标建模为全局模板与可变形部件模板的集合,既适配物体弹性形变,又具备较快运算速度,但对目标旋转敏感,性能已被深度学习模型超越。
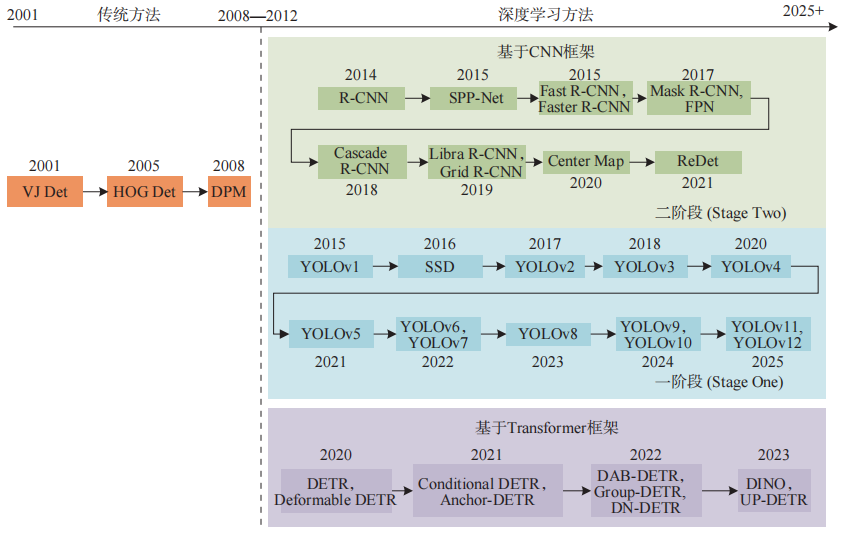
图1 目标检测发展脉络图
传统方法的核心局限是依赖人工特征设计,在复杂水下场景中难以提取抽象信息,但部件分解、多尺度检测等思想,为后续深度学习提供了启发。
⒉基于CNN的视觉目标检测
2012年ALEXNET提出后,CNN凭借自动特征学习能力彻底改变了目标检测领域。基于CNN的目标检测根据检测流程是否包含显式的候选区域提取过程,分为1阶段检测和2阶段检测。
⑴2阶段目标检测
2阶段检测如图2所示,先通过网络生成若干候选区域,再对这些区域进行目标分类和精确的边界框回归。图1总结了其发展历程。
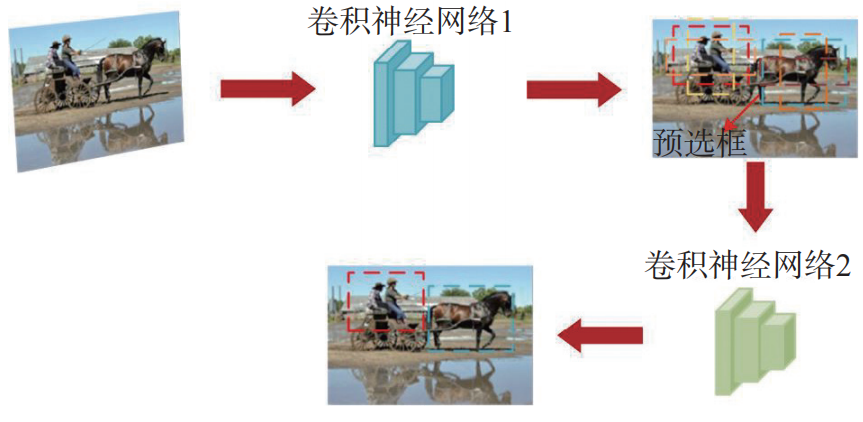
图2 2阶段检测
区域卷积神经网络(R-CNN)首次将CNN应用到目标检测领域,通过选择性搜索生成候选区域,再进行分类和边界回归,但重复特征计算导致检测速度较慢。随后,空间金字塔池化网络(SPP-Net)通过引入空间金字塔池化解决重复计算问题,但仍存在流程分离、参数微调不充分等问题。FastR-CNN利用感兴趣区域(ROI)池化与多任务损失,整合检测流程,优化了检测效率,但其仍采用选择性搜索进行候选区域生成,限制了整体的检测速度。FasterR-CNN的提出,解决了FastR-CNN的主要瓶颈。它引入区域生成网络,提升了检测框的生成速度,实现了真正的端到端训练。以上研究主要围绕R-CNN及其加速的优化,后续研究则转向多尺度特征融合与定位精度改进。MaskR-CNN在FasterR-CNN的基础上增加目标掩码输出分支,提升目标定位精度。FPN解决了多尺度检测中对小目标的检测适应性差的问题,通过自顶向下融合深层和浅层特征。CascadeR-CNN提出了多级级联检测头部,系统性地提高了整体检测精度。
2阶段检测通过分步骤精细化处理获得高精度,但牺牲了速度,难以适配水下实时部署需求。
⑵1阶段目标检测
1阶段检测如图3所示,其摒弃了显式候选区域生成步骤,通过单一网络端到端完成特征提取、目标分类和位置回归,成为水下目标检测场景的主流选择。1阶段检测核心代表为YOLO系列,发展历程如图1所示。

图3 1阶段检测
YOLOv1于2015年被提出,其首创性地将目标检测视为回归问题,实现了端到端训练和高速检测,但小目标召回率低。单次多边框检测(SSD)通过多尺度默认框适配不同尺寸目标,弥补YOLOv1缺陷,但存在重复检测问题。REDMON团队在YOLOv1的基础上提出YOLOv2,引入锚框机制,通过K-means聚类优化先验框尺寸,还结合Passthrough层融合细粒度特征,实现精度与速度的平衡,但小目标检测性能欠佳。为增强对小目标的检测能力,YOLOv3借鉴特征金字塔网络(FPN)思想,在3个不同尺度的特征图上进行边界框预测,显著提升了小目标检测效果。YOLOv4整合CSPDarknet53骨干网络、空间金字塔池化(SPP)附加模块与PANet颈部模块,结合Mosaic数据增强、完全交并比损失函数(CIoU)损失,实现速度与精度最优平衡。YOLOv5采用先进的Mosaic数据增强技术及Focus,CSP等精细网络结构调整,进一步提升检测速度。YOLOv6采用无锚框设计,侧重更高效的实时检测。YOLOv7引入高效层聚合网络(E-ELAN)网络优化层间连接,提升学习效率,但架构的复杂性增加部署成本。
YOLOv8抛弃传统的锚框机制,采用无锚框架构和解耦头,完成了范式转换。之后,YOLOv9,YOLOv10和YOLOv11相继被提出。YOLOv9引入程序化梯度信息(PGI)减少信息损失,降低参数量与计算量。YOLOv10通过一致性双重分配实现不需要NMS(NMS-Free)训练,消除对非极大值抑制(NMS)后处理的依赖,降低推理延迟。YOLOv11新增C3k2模块与C2PSA组件,增强特征提取和多任务处理能力。YOLOv12转向以注意力为中心的架构,引入区域注意力模块与残差高效层聚合网络,实现快速推理与高精度检测,达到当前先进水平。
整体而言,1阶段检测以高速为核心优势,精度相对适中,更适配水下实时检测场景。
⒊基于Transformer的视觉目标检测
Transformer架构凭借自注意力机制,高效捕捉图像全局信息与长距离依赖关系,将目标检测视为集合预测问题,消除NMS与锚框依赖,成为继CNN后的全新技术范式。核心代表为检测Transformer(DETR)系列算法,发展脉络如图1所示。
DETR首次将Transformer引入目标检测,通过编码器−解码器架构与二分匹配损失函数,实现了推理过程无需NMS,但训练周期长、计算成本高。DeformableDETR引入多尺度可变形注意力模块,仅在参考点周围关键采样点计算注意力,解决收敛慢与计算量大的问题。WANG等人提出AnchorDETR,将查询编码为锚点坐标,赋予显式空间先验,加速收敛。ConditionalDETR通过条件空间查询(CSQ)机制,提升目标四极点的定位精度。
之后DETR系列的改进主要围绕查询优化与训练加速。DAB-DETR基于AnchorDETR,提出4D动态锚框,提高了查询的可解释性。DN-DETR针对DETR训练过程中二分匹配的不稳定性,通过查询去噪训练稳定二分匹配过程,提升了收敛速度。改进去噪锚框DETR(DINO)是DETR系列的集大成之作,融合了去噪训练、动态锚框与查询选择机制,在ResNet-50骨干网络下实现了49.4AP的高性能。
水下场景中,Transformer的高计算成本限制了其直接部署,因此多与CNN结合构建混合架构,如YOLOv7和TPH-YOLOv5等采用该混合架构,通过引入Transformer预测头(TPH)等模块,增强了模型在处理尺度变化和密集目标时的能力。
水下目标检测不仅需要应对通用目标检测的挑战,还需克服光学衰减、声学噪声等特有问题,因此研究重点集中在模型轻量化、鲁棒性及小目标适配性优化。
⒈水下目标检测数据集
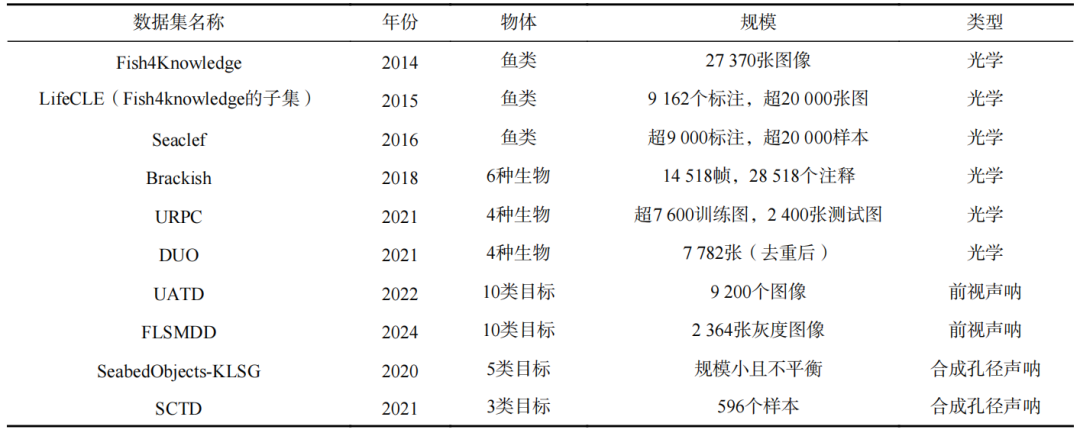
数据集是深度学习模型训练与性能提升的核心支撑。但水下环境复杂、声呐数据涉密等因素,导致大规模高质量公开数据集稀缺。本节对部分水下数据集进行了汇总,如表2所示。
表2 水下数据集
⒉水下光学图像目标检测
图4展示了水下同一目标的光学和声呐图像对比。相较于声呐图像,光学图像具有高分辨率、信息直观的优势。然而,水体对光线的吸收和散射会导致图像普遍存在颜色失真、细节丢失等问题。因此,水下光学目标检测主要围绕图像质量鲁棒性提升、多尺度小目标适配与轻量化部署展开。

图4 同一目标在光学与声呐图像中的对比
传统预处理方法是水下图像增强的重要路径。IQBAL等人在红、绿、蓝(RGB)和色相、饱和度、明度(HSV)颜色空间拉伸动态像素范围,提升对比度与饱和度。FU等人基于Retinex理论分离反射与光照分量,通过消除光照干扰实现图像增强。除了传统预处理方法的结合,深度学习集成与多任务学习也成为水下图像增强与目标检测结合的重要方向,研究者探索将图像增强与复原作为多任务学习集成到检测网络中。林森等人指出,将水下恢复卷积神经网络(URCNN)和水下图像复原网络(UIRNet)用于估计和计算透射率图和背景光,可一定程度上复原图像。LI等人提出Water-Net,通过门控融合卷积神经网络,预测融合权重图整合多源处理结果,在UIEB数据集上实现有效增强。但需注意,图像增强效果与检测性能存在复杂耦合,需结合具体场景针对性优化。
针对水下目标易丢失的现象,相关研究集中于通过改进网络结构来增强多尺度特征的提取能力。其中,多尺度特征融合被广泛采用。通过在网络架构中使用FPN、路径聚合网络(PANet)等颈部模块,使模型能融合深层高语义信息和浅层的高分辨率信息,提升不同尺寸目标的捕获能力。合成融合金字塔网络(S-FPN)通过捷径连接改进多尺度融合策略,弥补下采样过程中丢失的空间位置信息,强化小目标检测精度。此外,注意力机制的应用也有效强化了目标区域的特征提取能力。KNAUSGARD等人在YOLOv3中加入通道注意力和空间注意力模块,突出边缘、纹理的高频信息。ZHANG等人在SSD算法中将注意力模块和多尺度特征融合,显著提升小目标的检测性能。
水下检测还需满足AUV等嵌入式平台的高精度与实时性需求,YOLO系列具备高实时性优势,成为水下目标检测的首选。早期研究将YOLO直接应用于水下鱼类检测,其检测性能显著优于传统算法。在此基础上,各类模型压缩与轻量化策略不断涌现:王岳川等人提出基于YOLOv12s的轻量化算法,通过GhostNet模块优化主干网络减少参数量,结合LAMP剪枝算法压缩模型规模,保持精度的同时降低计算量。CAI等人以MobileNetv1作为YOLOv3的骨干网络,实现了水下鱼类检测的轻量化。
⒊水下声呐图像目标检测
声呐图像是水下远距离搜索和低能见度环境下的核心探测手段,其成像如图4(b)所示。可观察到,声呐图像存在强斑点噪声、边缘模糊、特征稀疏等问题。因此,水下声呐检测需要解决2大痛点:1)强斑点噪声与稀疏特征导致特征提取困难;2)数据采集成本高、样本稀缺导致的模型训练受限。
针对噪声与特征稀疏问题,通过专用模块设计与架构优化强化特征表达。汤瑞等人利用空频卷积替换YOLOv5s的普通卷积,抑制了侧扫声呐的散斑噪声。黄靖等人提出了基于生成对抗网络(GAN)的多尺度特征融合(MSFF)模块,用于生成高质量声呐图像,以解决噪声干扰和细节缺失问题。张子怡提出RTDETR-EGA算法,将Canny边缘引导注意力模块嵌入Transformer,提升了小目标轮廓特征提取能力。张旭阳等人在YOLOv8的C2F-FLS模块中嵌入卷积块注意模块(CBAM),删除冗余模块,兼顾了弱特征目标检测性能与实时性。陈启北等人用改进空间坐标卷积替换2D卷积,增强模型对小目标的空间关注度。
围绕数据采集难、样本少的痛点,核心策略包括迁移学习、数据合成与开放集识别优化。陈友淦等人采用参数迁移学习,将轻量化AlexNet在ImageNet上预训练后,在声呐数据集上微调,解决小样本分类问题。赵桁等人将样本扩增与迁移学习结合使用,先通过增加标签、调整尺寸等方法进行样本扩增,然后进行迁移学习,提升了小样本下模型的检测性能。陈健等人提出基于声传播模型与点云模型的样本仿真方法,模拟射线追踪、多路径反射效应和海底背景,生成多样化的目标声呐图像,并用于训练YOLOv8模型,提升了小目标检测精度。夏梓淇等人采用Openmax分类器代替Resnet网络最后的Softmax层,有效降低了未知类别带来的误识风险。
⒋水下声光图像联合目标检测
单一模态检测难以适配水下复杂的场景,通过深度学习架构实现声光的多模态联合检测,是克服单模态缺陷、构建全流程高鲁棒性探测系统的核心突破口。然而,光学数据为高密度、结构化数据,声呐数据为低密度、依赖灰度与阴影特征的数据,两者融合的核心挑战在于解决异构数据之间的匹配、配准和融合问题。
声呐图像自带到达时间(TOA)和到达角度(AOA)信息,可用于辅助定位:在声光图像匹配的基础上,将TOA信息与AUV位置信息结合,实现目标精准锁定,同时利用光学图像进行细节探索。深度学习框架成熟前,匹配主要依赖传统方法,包括图像增强预处理和尺度自适应,但这类方法对复杂水下环境的适配性有限。深度学习凭借强大的特征提取与非线性映射能力,为声光深度融合提供了技术路径。目前研究聚焦多模态特征融合与协同推理。基于自蒸馏机制的单步全域目标识别(YOLO-UOD)模型,将光学与声呐图像的特征深度融合,在水下数据集上实现了比单模态更高的检测精度;利用特征金字塔与Transformer架构,解决异构数据匹配与配准难题,以强化特征表达能力。
水下声光检测具有互补性,多模态信息融合是构建全域探测系统的必然方向,需进一步突破异构数据特征对齐与协同推理技术壁垒,结合多源信息,提升目标检测、定位与跟踪的鲁棒性和准确性。
⒈数据瓶颈与鲁棒性
水下数据采集成本高、军事敏感性强,导致大规模高质量公开数据集稀缺,且存在目标单一、类别不均衡等问题。同时,现有模型泛化能力与鲁棒性不足,易受复杂水下环境干扰。未来需聚焦高质量数据集建设与合成,深化GAN、扩散模型等数据合成技术及风格迁移方法,缓解数据稀疏困境;探索无监督、弱监督或自监督学习范式,减少对人工标注的依赖;通过迁移学习与少样本学习策略,实现陆地到水下的知识迁移,提升模型适应能力。
⒉模型架构与实时性优化
水下检测需适配AUV等嵌入式平台,此类平台计算资源有限、功耗约束严格,而高性能深度学习模型的高计算开销与存储需求,给部署带来挑战。此外,水下小且密集的目标分布,对模型多尺度适配与快速推理能力提出更高要求。未来需持续优化网络架构,开发轻量化、高效率、低功耗检测模型,通过减少参数冗余、压缩模型规模实现部署适配;采用NMS-Free端到端架构消除推理后处理延迟,结合无锚框检测器提升检测效率。
⒊跨模态融合
声光图像在信噪比、分辨率、几何结构及信息维度上存在显著异构性,如何实现高精度特征配准与深度融合是当前核心挑战。未来需重点研究基于Transformer自注意力机制的端到端多模态融合模型,解决异构数据特征表示与对齐问题,实现优势互补;开展声呐、光学、惯性导航等多传感器信息融合研究,构建声光−位姿多源融合体系,全面提升目标定位与识别的鲁棒性。
本文系统梳理了基于深度学习的水下声光图像目标检测技术,从算法演进、数据支撑、单模态适配及多模态融合等维度,全面呈现领域研究现状与发展趋势。
深度学习已成为水下目标检测的核心驱动力,算法实现了从传统手工特征方法到CNN、再到Transformer新范式的跨越。CNN一阶段算法因实时性优势成为水下嵌入式平台主流选择,Transformer则以全局注意力突破长距离依赖限制,两者融合架构实现精度与速度的平衡。数据层面,水下高质量数据集稀缺且存在类别失衡、样本单一问题,数据增强与合成技术成为关键支撑。单模态检测中,光学检测聚焦图像增强与检测一体化和多尺度优化,声呐检测侧重噪声抑制与小样本学习,分别应对各自模态特有挑战。声光多模态联合检测是构建高鲁棒性水下探测系统的必然趋势,核心难点在于异构数据配准与融合,基于自蒸馏的融合模型已展现初步优势,但仍需突破特征对齐与协同推理壁垒。
未来,需重点攻克3大核心问题:突破数据稀缺与分布不均瓶颈,探索无监督等学习范式;推进模型轻量化与实时性优化,适配嵌入式平台;深化跨模态融合并结合多源信息,最终推动全流程高可靠水下智能探测系统落地。
1
END
1
【作者简介】文/陈俞志 王嘉 赵兵 潘汉 邱周静子,分别来自上海交通大学船舶海洋与建筑工程学院、武汉第二船舶设计研究所、上海交通大学航空航天学院、水下智能系统技术湖北省重点实验室、电子科技大学(深圳)高等研究院。第一作者陈俞志,1998年出生,男,博士生,主要从事目标检测、力学研究;通信作者潘汉,副教授,主要从事目标探测跟踪与识别、信息融合、黎曼流形优化研究。本文受基金项目赞助,国家自然科学基金“空间连续型机器人跟踪非合作目标过程视觉伺服方法研究”(62203480);水下智能系统技术湖北省重点实验室开放基金项目“基于多智能体的水下目标集群探测成像与识别系统技术”(ZHJ250262);空天飞行器技术航空科技重点实验室基金项目“面向在轨服务和应用的自主智能操控技术研究”(J2025-STAV-03-001)。文章来自《数字海洋与水下攻防》(2026年第1期),用于学习与交流,参考文献略,版权归作者及出版社共同拥有,转载也请备注由“溪流之海洋人生”微信公众平台编辑与整理。






公众号
溪流之海洋人生
微信号▏xiliu92899

用专业精神创造价值
用人文关怀引发共鸣
您的关注就是我们前行的动力
投稿邮箱▏2705319347@qq.com







