 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库具身大模型:先对齐评测,再对齐世界

过去两年,我们见过太多丝滑的机器人Demo,除了跳舞、打球等动作秀,还有端茶倒水、叠衣服、做饭等日常任务。
但这些视频的共同特点是,发布完论文或视频,就销声匿迹,你永远不知道,它在现实中到底是什么样。
这就是具身智能现在的核心矛盾:网上炒得火热,但还停留在“视频时代”。
最近,随着宇树科技IPO持续升温,这个问题也越来越受到重视。特别是宇树在招股书中提到,拟募资 42 亿人民币,其中半数资金砸向“智能机器人模型研发项目”,也就是俗称的具身模型。
宇树的成功,本质上是硬件工程能力的胜利。成本控制、运动控制、量产能力,这些都已经被验证。
但行业已经进入一个阶段,市场真正想要的,是另一件事:谁能做出通用的具身模型?

01.
具身模型“关公战秦琼”
如果你熟悉 AI 相关的最新研究,就会发现每隔一段时间,就会有来自公司或高校的研究团队,号称在具身模型、VLA(视觉-语言-动作模型)上取得了突破。
它们在 Isaac Gym 或 ManiSkill 等仿真环境里,在一些任务上,展现出了惊人的成功率,达到 90% 甚至是 95%。模型在虚拟实验室里动作优雅、逻辑无瑕,好像具身智能的 ChatGPT 时刻已经不远了。
这些研究当然很有价值,但它们有一个根本性问题:仿真环境与真实世界之间存在巨大的现实差距(Sim2Real Gap)。
在仿真环境中,物体材质、摩擦系数、传感器噪声、物体摆放方式等,都是可控的,而现实世界是不可控的。

这也是为什么,很多模型在论文里 SOTA,一上真机就崩。这种现象在机器人领域非常普遍,也是具身智能迟迟无法大规模落地的重要原因之一。
Demo 视频越来越多,论文越来越多,但大家很难真正比较不同模型之间的能力差异,就像是“关公战秦琼”。
问题不在模型数量,而在缺乏 Benchmark。
02.
RoboChallenge:具身智能的评测基础
行业迫切需要一个类似 ImageNet、GLUE、Arena 这样的真实世界统一评测标准,让不同模型可以在同一环境下进行横向比较。
正是在这样的背景下,RoboChallenge出现了。
RoboChallenge 由原力灵机与 Hugging Face 联合发起,被认为是全球首个大规模、多任务的真实机器人评测基准平台。

与传统机器人竞赛不同,RoboChallenge 的核心思想是建立一个类似大语言模型 LMSYS Arena 的评测体系:
统一机器人硬件(UR5、Franka、ALOHA 等)
统一任务
统一评测指标
模型远程提交
在真实机器人上执行
公开排行榜
可复现结果
研究人员即使没有机器人,也可以通过远程调用真实机器人测试算法,这大幅降低了具身智能研究的门槛。
这解决了一个核心问题:不同模型可以横向比较,模型好不好,直接上机跑。
更关键的是,RoboChallenge不仅给分数,还给失败轨迹。这点极其重要,因为传统的机器人竞赛,通常只关注最终的成功率,但对于具身模型来说,知道怎么失败的,更有价值。开发者可以通过分析失败环节,来进行针对性的微调和优化。
RoboChallenge 的目标不是做一次比赛,而是建立一个长期的评测基础设施,推动具身智能从实验室智能,走向现实世界智能。
截至目前:RoboChallenge 已执行超过4万次真机测试,单日提交达到181次,就像是机器人的工业级测试流水线。
03.
具身智能的残酷真相
RoboChallenge 在2025年下半年才推出,但已经暴露出了当前具身模型的很多问题和真相。
RoboChallenge 包括名为 Table30 桌面操作基准测试集,其中有 30 个精心设计的日常情境任务(一般竞赛或评测的任务仅有 3-5 个),例如整理物品、抓取物体、插线、摆放物品等。
从表面上看,这些任务似乎只是简单的桌面操作,但从能力结构来看,这类任务实际上覆盖了具身智能最核心的能力组合:视觉理解、语言理解、任务规划、精细操作、长时序决策、泛化能力等等。
换句话说,Table30 是在测试具身模型是否具备通用操作能力。
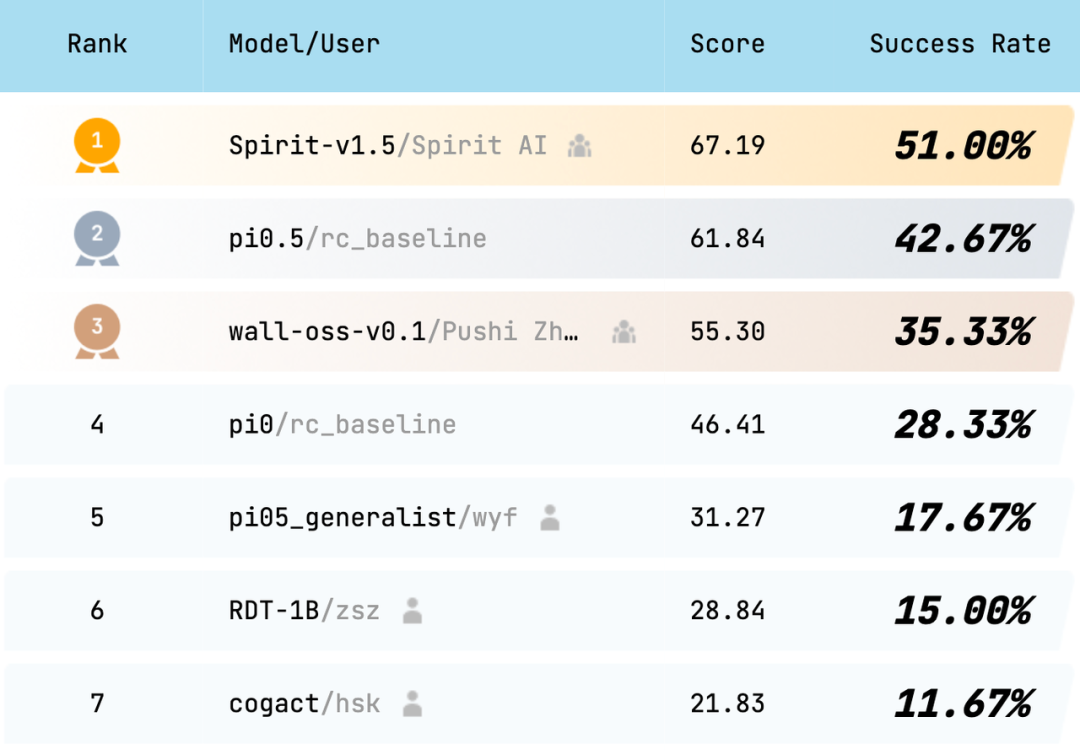
RoboChallenge 前不久发布了年度报告。结论概括来说:
榜首模型成功率约 50%。
模型在基础抓取任务上的成功率比较高,但在精细操作和长任务链任务上,成功率明显下降,比如“制作三明治”这个任务还没有模型能完成。
这说明什么?我们距离“通用操作智能”,还差很远。
有了客观的评测体系,才能真正衡量模型的水平。
04.
具身智能不缺模型,缺排行榜
如果回顾人工智能过去十几年的发展,会发现一个非常清晰的规律:几乎所有重大技术突破,都伴随着公开基准测试与排行榜竞争。例如:
ImageNet 推动了深度学习视觉模型的发展
GLUE / SuperGLUE 推动了 NLP 模型发展
LMSYS Arena 推动了大语言模型竞争
公开 Benchmark 的作用不仅仅是比较模型性能,更重要的是,它能统一技术目标、提供可复现的评测方法、加速技术路线收敛、吸引更多研究者参与。
具身智能领域长期没有类似大语言模型领域的 benchmark,因此技术路线非常分散,很多团队做的是 Demo,而不是可复现系统。
RoboChallenge 的意义,可能正是在这里。
很多人讨论具身智能时,往往只关注模型本身,但实际上,具身智能是一个典型的系统工程,其进步也要依靠完整的基础设施。
除了算力、算法、数据、硬件等环节,评测体系是连接模型与应用的关键环节。如果没有统一评测体系,就无法判断模型是否真的进步,也无法形成行业共识。
从这个角度看,具身智能行业目前最缺的反而不是模型,而是一个公正的排行榜。
在今年的 AI 国际顶会 CVPR 上,还将举行 RoboChallenge CVPR 2026 机器人比赛。到时,Table30 V2 的预览版也将上线发布。

Table V2会从任务升级、评测升级到系统升级三个维度深度重构,也会对具身模型进行了全方位的极限压测。
如果你正在做具身智能、VLA、机器人控制,不要只做Demo,只做视频,应该去参与打榜比赛。
未来几年,具身智能领域真正的技术突破,很可能会首先体现在 RoboChallenge 的排行榜上。
END


工业机器人企业
埃斯顿自动化 | 埃夫特机器人 | 法奥机器人 | 越疆机器人 | 节卡机器人 | 松灵机器人 | 珞石机器人 | 阿童木机器人 | 极智嘉 | 海康机器人
服务与特种机器人企业
亿嘉和 | 晶品特装 | 七腾机器人 | 史河机器人 | 普渡机器人 | 施罗德机器人 | 库犸科技MAMMOTION
人形机器人企业
优必选科技 | 宇树 | 云深处 | 星动纪元 | 伟景机器人 | 逐际动力 | 乐聚机器人 | 大象机器人 | 魔法原子 | 众擎机器人 | 帕西尼感知 | 赛博格机器人 | 数字华夏 | 傅利叶智能 | 天链机器人 | 开普勒人形机器人 | 灵宝CASBOT | 清宝机器人 | 浙江人形机器人创新中心 | 动易科技 | 智身科技 | PNDbotics | 卓益得机器人 | 鹿明机器人 | 擎朗智能| 伽利略GALILEO
具身智能企业
跨维智能 | 银河通用 | 千寻智能 | 灵心巧手 | 睿尔曼智能 | 微亿智造 | 推行科技 | 中科硅纪 | 枢途科技 | 灵巧智能 | 星尘智能 | 穹彻智能 | 方舟无限 | 科大讯飞 | 北京人形机器人创新中心| 国地共建人形机器人创新中心 | 戴盟机器人| 视比特机器人| 星海图 | 月泉仿生 | 零次方机器人 | 中科深谷 | 智平方 | 大咖机器人 | 灏存科技| 具识智能 | Xynova曦诺未来 | 非夕科技 |未来动力 | 博登智能 | 千诀科技 | 灵生科技 | 集萃智造 | 欣佰特科技 | 晨昏线科技 | Dexmal 原力灵机 | 优理奇
医疗机器人企业
元化智能 | 天智航 | 思哲睿智能医疗 | 精锋医疗 | 佗道医疗 | 真易达 | 术锐®机器人 | 罗森博特 | 水木东方|康诺思腾 | 迪视医疗
上游产业链企业
绿的谐波 | 因时机器人 | 坤维科技 | 脉塔智能 | 青瞳视觉 | 本末科技 | 鑫精诚传感器 | 蓝点触控 | BrainCo强脑科技 | 宇立仪器 | 极亚精机 | 思岚科技 | 神源生 | 非普导航科技 | 因克斯 | 巨蟹智能驱动 | 凌云光 元客视界 | 璇玑动力| 意优科技| 瑞源精密 | 灵足时代 | HIT华威科 | 星汇传感 | 凌迪科技 | 泉智博






