 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库智元机器人发布Genie Envisioner 2.0,让机器人在“模型世界”中学习与进化




2025 年,智元发布了行业首个世界模型开源平台 Genie‑Envisioner。彼时,我们的目标是让机器人 “理解世界”—— 通过视觉、语言与动作的统一建模,让机器感知环境、读懂指令、做出反应。而今天,一次更深刻的进化正在发生:我们不再满足于让机器人理解世界,而是要让它在世界中学习、成长、进化。哪怕这个世界,并非真实存在,而是由模型构建。
在智元的技术路径里,世界模型一直沿着两条主线生长:一条是世界动作模型(World Action Model),专注于动作表征的深度建模;另一条是世界模拟器(World Simulator),负责打造一个可交互、可推演、可训练的完整环境。从 “世界动作模型” 到 “世界模拟器”,世界模型正在完成一次本质升级:从描述世界,进化为成为世界。
当这个由模型构建的世界足够真实、足够稳定、足够高效,能像现实一样响应机器人的每一个动作,机器人就可以在模型世界里完成大规模训练、试错、迭代,大幅降低真实世界的试错成本。这是从 “世界的表征” 走向 “世界本身” 的关键一步。
沿着这条路径持续探索。智元AI发布周Day4,我们正式带来世界模型的全新成果:Genie Envisioner World Simulator 2.0(GE‑Sim 2.0),一个真正可训练、可交互、可决策的可操作世界,一个属于具身智能的物理进化引擎。
01/
双向进化:World Action Model 与 World Simulator
回到问题的起点。机器人面对的世界是连续变化的,动作不仅是输出,更是影响环境演化的核心变量。
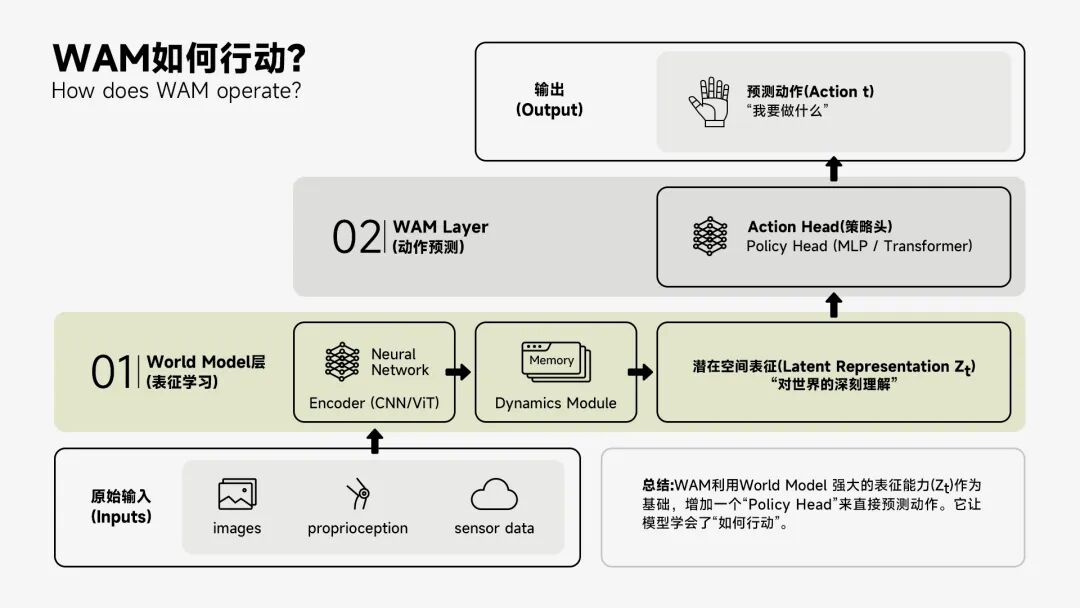
因此,在传统世界模型仅建模“状态”(state)的基础上,智元提出并推进了世界动作模型(WAM)的方向,其关注的核心问题是:如何让世界模型理解“动作”这一变量。机器人做了什么动作?动作如何改变世界?世界又如何反馈给策略?我们将“状态—动作—状态演化”作为统一建模对象,使世界模型能够成为策略学习与动作生成的基础表示层。
围绕这一方向,我们始终在展开探索。首先构建了 EnerVerse,将具身场景拓展为可计算的 4D 世界模型;而后推出 Genie Envisioner Act(GE-Act),实现从世界的表征能力(world representation) 到动作轨迹的生成;并通过 Act2Goal,让机器人实现目标驱动的长程控制。这些探索,使得世界模型首次具备了承载动作策略的能力。
但在真实应用中,我们逐渐发现,仅仅引入底层的动作建模(WAM),依然不足以支撑一个完整的机器人系统。策略训练仍然高度依赖真实环境,评估成本高昂且效率有限,高质量数据的获取与扩展始终是关键瓶颈。
我们意识到,真正的突破,不止在于强化世界模型的表征能力(representation),更在于世界模拟器(simulator)的能力。换句话说,世界模型不只是描述世界,而是要成为一个可以被使用、被交互、被训练的世界本身。如果一个足够高质量的世界模型被构建,那么在这个生成的世界中行动的策略也可以被更有效地训练。
02/
从动作模型到模拟器:让世界可以被“运行”
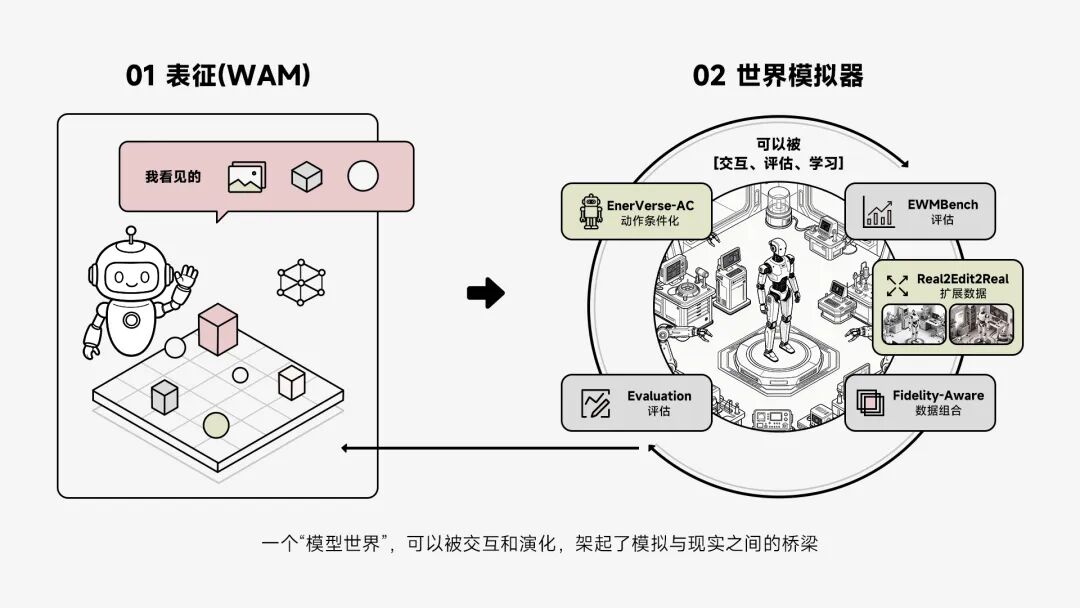
基于此,我们在强化世界动作模型(WAM) 建模能力的同时,同步推动世界模型走向可交互的模拟器能力(World Simulator)。
通过EnerVerse-AC,引入 action-conditioned world modeling,使模型能够基于动作进行未来推演;
通过Genie Envisioner Sim(GE-Sim 1.0),构建可用于策略闭环评估的神经模拟器;
并通过EWMBench,从场景一致性、动作正确性与语义对齐等多个维度,对 world model 的模拟能力进行系统评估。
更重要的是,一套全新的数据与训练范式也随之建立。在Fidelity-Aware Data Composition 中,真实数据与生成数据被精细组合,使策略训练既具备真实性,又拥有更强的泛化能力;而后我们提出Real2Edit2Real 流程,真实数据不再只是被动采集,而是成为可被模型扩展与编辑的基础,从而显著提升数据规模与多样性。
至此,世界模型完成了一次本质跃迁——从表征模型,演进为具备环境级能力的系统基础设施。
03/
Genie Envisioner 2.0:
具身智能的物理进化引擎
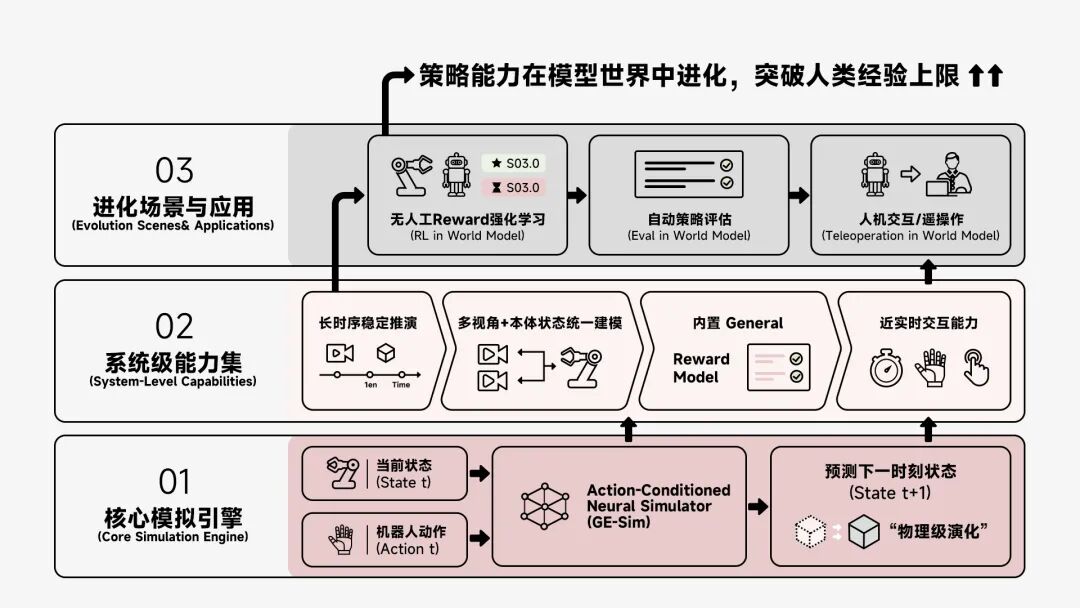
在这一系列演进之上,Genie Envisioner World Simulator 2.0 (GE-Sim 2.0) 正式发布。它不再只是一个生成模型,而是一个可以被使用的系统——一个真正意义上的“可操作世界”。
世界,开始由动作驱动
GE Sim 2.0 能够严格响应机器人动作信号,生成高保真的环境变化,并严格遵循物理与语义逻辑。世界不再是被想象的、无法被干预的,而是被行动不断推进的过程。
时间,被拉长为完整任务
模型支持分钟级长时序稳定推演,从零散视频片段,走向完整任务过程的连续生成。
空间,被统一为具身体验
多视角视觉、跨视角3D一致性与机器人本体状态(proprioception)被统一建模。进一步让机器人面对的不再是“画面”,而是一个完整、可交互的具身世界。
模型,开始拥有“判断能力”
内置激励模型(General Reward Model),使模型首次具备自评估能力。它可以基于文本对生成状态自动评估与优化,无需人工激励的训练,可以完成强化学习(RL in World Model)。这意味着,训练闭环第一次真正被内嵌进模型世界本身。
系统,从离线走向实时
随着推理效率的提升,GE 2-Sim 已经可以接近实时运行,支持 Eval in WM、RL in WM、以及Teleoperation in WM都可以直接在模型世界中完成。世界模型不再是一个离线工具,而是一个可以实时交互的系统环境。
04/
范式跃迁:当模型成为世界
当这一切能力汇聚,具身智能迎来了一次真正的范式革新 —— 它不再只是 “用模型理解世界”,而是真正走进 “模型世界”,在其中自主学习、自主决策、自主成长。一方面,世界动作模型(WAM)与视觉 - 语言 - 动作模型(VLA)深度融合,让机器人的策略彻底升级:从被动响应环境的 “反应式控制”,变成能预判未来、规划全局的 “生成式决策”;另一方面,世界模拟器(World Simulator)搭建起一个无限延伸的虚拟训练场,让机器人可以在这里大规模试错、反复优化,不再被真实数据的稀缺性束缚,其能力上限,从此由模拟的真实度与高效性决定。
当这两条路径交汇,机器人不再是机械复现人类经验的 “执行者”,而是能在模型世界中不断探索、修正、突破的 “学习者”—— 它的能力边界,正被重新定义,而这正是 Genie Envisioner 2.0 为具身智能铺就的未来方向。
具身智能的长远未来,在于拥有自主学习与持续进化的能力,这份进化,既来自对真实世界的观察与沉淀,更来自模型世界里无限的推演、试错与成长可能。当模型成为可交互、可训练、可进化的完整世界,现实就不再是机器人唯一的训练场。
我们希望这一技术升级能成为具身智能发展史上的重要基础设施 —— 推动机器人彻底跳出 “复现经验” 的局限,真正走向自主探索、持续进化的新阶段,为具身智能通往 AGI 的长远征程,构建关键的能力基石。
>>> END <<<


# 扫描上方二维码,添加小编微信 #
# 申请请备注公司+姓名+职位





