用好灵巧手,比会走路更重要?
发布时间:2026-04-26来源:人形机器人洞察研究

温馨提示:扫描文末二维码,加入知识星球,免费下载2800+行业报告(包含海外投行报告);商务和研究咨询合作请联系16620948826(同微信)过去,人形机器人最容易被关注的是“走得稳不稳、跑得快不快、动作像不像人”。但真正进入产业场景后,双腿只是解决“到达现场”的问题,双手才决定机器人能否真正完成工作。无论是工厂里的装配、搬运、检测,还是家庭中的开门、取物、整理和清洁,最终都离不开高精度、高可靠性的手部操作。英伟达GR00T N1.7、银河通用LDA-1B共同指向一个趋势:人形机器人正在从“会移动”走向“会操作”,灵巧手正在成为下一阶段的核心门槛。人形机器人之所以被期待,并不是因为它拥有人的外形,而是因为它有机会进入人类已经设计好的工作空间。工厂、仓库、办公室和家庭中的门把手、工具、货架、按钮、餐具和设备,几乎都默认由人的手来操作。因此,人形机器人如果只会行走和避障,本质上仍然只是一个移动平台;只有当它能够稳定使用工具、抓取不同形态的物体、完成接触复杂的动作,才真正接近“劳动力”。这也是为什么英伟达在 GR00T N1.7 中强调 finger-level control,也就是手指级控制能力。它并不是为了让机器人完成更好看的演示动作,而是为了让机器人能够处理小零件装配、物料搬运、包装、检测等更贴近真实产业场景的任务。银河通用参与的最新研究也体现了这一点。论文中的真实世界实验,不只测试简单抓取,而是覆盖了翻转、擦拭、清扫、拔钉、翻面包、双手开盖等任务,并展示了Galbot G1搭载Sharpa灵巧手、Unitree G1搭载BrainCo灵巧手,以及两指夹爪等不同末端执行器的对比。这说明,行业的验证重点正在从“机器人能不能抓住东西”,转向“机器人能不能像人一样完成复杂操作”。GR00T N1.7 最值得关注的地方,不只是模型参数达到3B,也不只是它采用了 VLA架构,而是它提出了一个非常关键的判断:人类数据是机器人智能最可规模化的来源。GR00T N1.7 使用 Action Cascade 架构,把高层任务理解和底层运动控制拆开:一个系统负责视觉语言理解、任务分解和高层动作 token,另一个扩散 Transformer 则负责把这些信息转换为实时电机控制指令。这种架构设计背后,有一个非常现实的考虑:灵巧操作任务太复杂,不能只靠端到端地模仿一个动作。机器人不仅要知道“做什么”,还要知道“先做什么、后做什么、什么时候接触、什么时候发力、什么时候调整”。因此,高层推理和低层控制需要分工协作。更重要的是,GR00T N1.7 的研究基础来自 EgoScale。NVIDIA 介绍称,EgoScale 使用 20854 小时人类第一视角视频进行预训练,覆盖制造、零售、医疗、家庭等20多类任务;它的核心直觉是,人类和人形机器人共享相似的具身结构,包括双手、第一视角和充满可操作物体的世界。过去机器人模型主要依赖机器人遥操作数据,但遥操作数据昂贵、采集慢、规模有限,而且每换一个机器人本体、末端执行器或工作环境,数据都可能需要重新积累。相比之下,人类第一视角视频天然包含大量“手—物体—环境”的交互信息。人类每天都在开门、拿杯子、折纸、装配、清洁、使用工具,这些行为构成了一个巨大的灵巧操作数据源。NVIDIA 进一步提出,更多人类第一视角数据能够可预测、稳定地提升机器人灵巧操作能力,从1000小时扩展到20000小时后,平均任务完成度提升超过一倍,并将这种scaling law与22自由度灵巧手执行接触丰富任务联系起来。这意味着,未来机器人灵巧操作的竞争,可能不只是“谁的机械手更强”,也不是“谁的模型更大”,而是谁能把人类手部行为数据转化为机器人可执行的动作先验。银河通用等:机器人不能只学动作,还要学动作的物理后果手
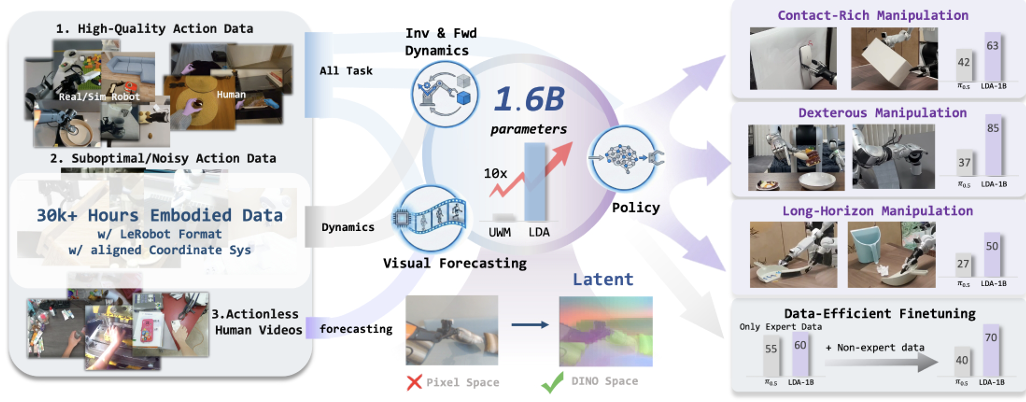
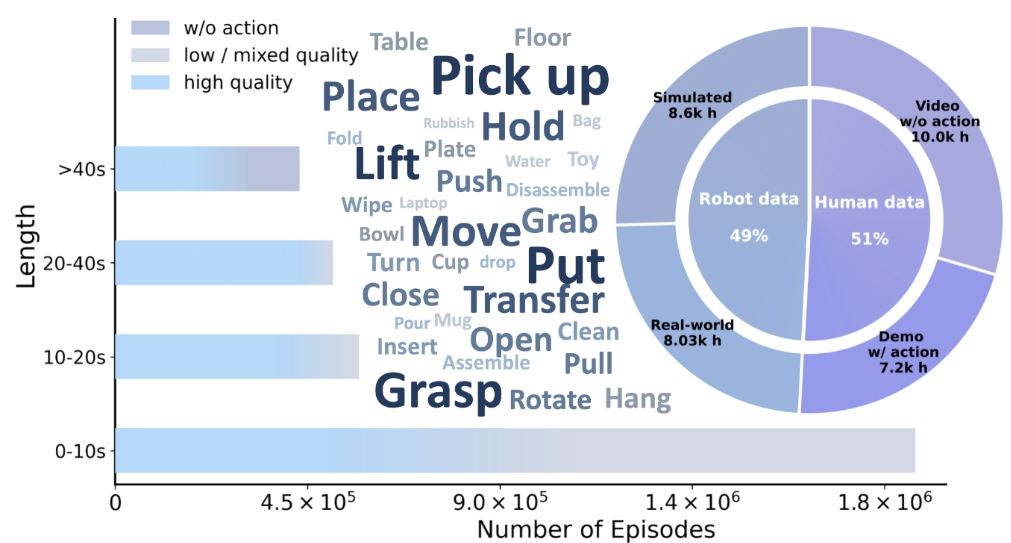
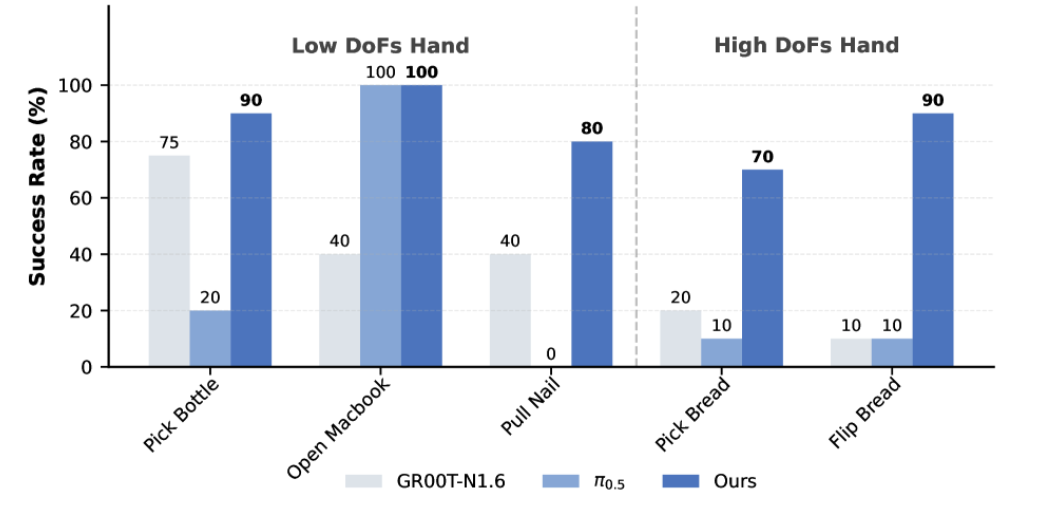
如果说英伟达的GR00T N1.7 代表了“从人类视频中学习灵巧操作”的路线,那么 银河通用等最新的研究成果LDA-1B则进一步把问题推向了“机器人如何理解动作改变世界”。LDA-1B是一个1.6B参数的机器人基础模型,它基于超过30k小时异构具身数据训练,并在结构化DINO潜在空间中统一学习policy、dynamics 和 visual forecasting。报告强调,除了高质量数据,噪声数据和无动作视频也能为动态学习提供视觉和物理先验。真实世界中,机器人光模仿动作是不够的。因为同一个动作在不同物体、不同位置、不同摩擦、不同接触状态下,结果可能完全不同。真正有用的机器人模型,必须理解这些动作背后的思考,如“如果我这样推,杯子会怎么动;如果我这样夹,物体会不会滑;如果我这样翻,面包会不会掉”等。LDA-1B正是在尝试学习这种“动作—状态变化”的关系。论文中提到,它通过通用具身数据摄取,把不同质量的数据分配给不同任务:高质量机器人和人类示范用于策略学习和动态建模,低质量轨迹用于动态学习和视觉预测,无动作人类视频用于视觉预测。这说明,机器人数据不再只有“专家演示”才有价值。失败动作、低质量轨迹、非最优动作、人类视频,都可能帮助模型理解物理世界的变化规律。这一点对灵巧手尤其关键。因为灵巧操作中的大量知识并不是“标准答案”,而是来自反复试错和接触经验。比如,捏住一个柔软物体需要多大力,翻转一个薄片应该从哪个边缘切入,用锤子拔钉时如何保持稳定接触,这些都不是单纯看图就能解决的问题,而是需要模型理解动作背后的物理后果。在真实世界实验中,LDA-1B在低自由度和高自由度灵巧手任务上都表现出优势。论文现精确运动方向控制;在Flip Bread这类高自由度任务中,模型需要处理高维控制、连续接触和腕部协调。论文给出的结果显示,LDA-1B在Pull Nail 任务达到80%成功率,在Flip Bread任务达到90%成功率,而对比模型在高自由度任务中明显受限。这就是为什么“会用手”比“会走路”更能代表人形机器人智能水平。因为手部任务会逼迫模型真正理解物体、接触、力、时序和环境变化,而不是只输出一个看似合理的动作。SharpaWave:逐步成为数据模型与现实世界的优质接口
如果说大模型解决的是“如何理解任务”,那么灵巧手解决的就是“如何把理解转化为真实接触”。在人形机器人进入具身智能阶段后,手不再只是末端执行器,而是模型能力落地的最后一厘米。SharpaWave的意义也正是在这里显现出来:它正在从一只高性能灵巧手,逐步变成连接数据、模型与现实物理世界的关键接口。SharpaWave首先具备足够接近人手的硬件形态,采用1:1人手尺寸,具备22个主动自由度,并集成高响应触觉传感能力(每个指尖拥有超过1000个触觉像素),在动态范围、空间分辨率、帧率和纹理识别方面具有较强性能,同时强调耐久性设计。 这意味着它不仅能完成简单抓取,还具备处理细小物体、柔性物体、工具交互和接触丰富任务的基础条件。SharpaWave的核心价值不只是外形和运动能力接近人手,而是能够降低人类操作数据向机器人动作迁移的难度,逐步成为模型连接现实世界的关键接口。英伟达GR00T N1.7强调,人类第一视角视频是机器人智能最可扩展的数据来源,而SharpaWave凭借1:1人手尺寸、22自由度和触觉能力,可以更好承接这类数据中关于接近物体、调整姿态、接触修正等手部操作先验。银河通用的LDA-1B研究也验证了这一点,Galbot G1搭载22自由度Sharpa灵巧手后,被用于拔钉、翻面包等需要精细力控、手指协同和连续物理闭环的任务,说明SharpaWave已经不只是一个末端执行硬件,而是在帮助模型理解和执行真实世界中的复杂物理交互。Sharpa在CES 2026展示的North机器人也体现了这种思路。根据Sharpa官方介绍,其人形机器人North的自主演示包括打乒乓球、拍照、发牌、完成 30 多步纸风车制作等任务,并强调这些能力依赖神经网络模型、运动学和动力学优化,以及SharpaWave这只量产灵巧手。从这个角度看,SharpaWave的真正意义并不只是“性能更强的灵巧手”,而是它正在成为具身智能模型的现实接口。没有这样的接口,模型学到的操作能力很容易停留在视频、仿真或策略输出层面;有了这样的接口,数据中的动作先验、模型中的动态预测、现实中的触觉反馈,才可能被统一到同一个执行闭环中。未来人形机器人的竞争,不会只停留在谁的模型参数更大、谁的步态更稳定,而会进入一个更难的阶段:谁能把人类数据、机器人模型和真实世界接触更高效地连在一起。SharpaWave正在切入的,正是这个关键位置。免责声明
1、我们整理、翻译和转载此文出于传播更多资讯之目的,不代表本号观点,亦不构成任何投资观点,由此做出的投资决策与本人本文无关!2、本文所用的视频、图片、文字如涉及作品版权问题,请第一时间联系小编:16620948826(同微信),我们将立即删除,无任何商业用途!
# 扫描上方二维码,添加小编微信 #
# 申请请备注公司+姓名+职位
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库