 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库ETH苏黎世让机器人学会"想象":零样本部署四足和人形机器人!

ETH苏黎世的研究团队训练了一个神经网络模拟器,让机器人在"脑海"里预演动作,然后直接部署到真实硬件上。ANYmal D四足机器人和Unitree G1人形机器人都实现了零样本迁移。

这套名为RWM(Robotic World Model)的框架,核心是让机器人通过神经网络精确预测未来几秒内的运动轨迹、关节状态、接触力等物理量。论文展示的视频显示,模型预测的轨迹和真实仿真环境几乎完全重合,误差小到肉眼难辨。
01.
双重自回归机制,让模型长期预测不再跑偏!
传统世界模型有个致命问题,训练和测试方式不一致。训练时每一步都用真实数据喂给模型(teacher forcing),但测试时却要自己预测,这种不匹配导致误差像滚雪球一样越积越大。预测一两秒还行,时间一长就彻底崩了。

RWM的解决方案是双重自回归机制。训练时就让模型吃自己的预测结果——先用真实观测预测未来一步,然后把这个预测结果当作下一步的输入,继续预测,一直滚动下去。这样训练出来的模型,在长时间预测时不会因为小误差而彻底崩盘。
架构上用的是GRU(门控循环单元)而不是Transformer。GRU在自回归训练时显存占用可控,而且推理速度快。论文测试了MLP、RSSM、Transformer等多种架构,结果显示GRU配合自回归训练的效果最稳定。模型的输入包括机器人的基座速度、重力向量、关节位置、速度、力矩等45维(ANYmal D)或96维(Unitree G1)的观测数据。
还有个关键设计是特权信息(privileged information)。这些信息在仿真里能拿到,但真实硬件上不一定有,比如膝盖和脚掌的接触力、足端高度等。RWM用这些特权信息做辅助训练目标,强迫模型隐式学习这些物理约束,提升长期预测的准确性。
论文做了个消融实验,测试不同历史窗口M和预测窗口N的组合。历史窗口M越长,模型能捕捉的动态信息越多,但超过一定长度后收益递减。预测窗口N的影响更关键——训练时预测得越远,模型在长期预测时的表现就越好。代价是训练时间变长,因为自回归过程必须串行计算。当N=1(纯teacher forcing)时训练最快,但自回归性能最差,这直接证明了自回归训练的必要性。
02.
MBPO-PPO框架在想象环境里训练策略!
有了靠谱的世界模型,下一步就是用它来训练控制策略。团队提出的MBPO-PPO框架,本质上是把PPO算法搬到了模型预测的"想象环境"里。
具体流程:先在真实仿真器里收集一批数据,用这些数据训练RWM。然后策略网络在RWM预测的虚拟环境里跑PPO,不断优化动作选择。每隔一段时间,再用真实仿真器验证策略效果,收集新数据更新世界模型。这个循环往复的过程,让策略既能高效学习,又不会因为模型误差而学偏。
论文对比了三种方法:SHAC(基于梯度的短视野优化)、DreamerV3和MBPO-PPO。SHAC的模型误差一直居高不下,因为它直接通过世界模型反向传播梯度,对模型精度要求极高。DreamerV3虽然样本效率不错,但在长时间预测任务上表现不如MBPO-PPO。

关键数据:在ANYmal D的速度跟踪任务上,MBPO-PPO训练2000次迭代后,模型误差降到5以下,策略奖励稳定在30左右。Unitree G1的任务更复杂,但10000次迭代后同样达到了可部署的水平。训练硬件是单张NVIDIA RTX 4090,ANYmal D的世界模型训练大约需要12小时,策略训练需要6小时。
奖励函数的设计也很讲究。速度跟踪任务的奖励包括线速度跟踪、角速度跟踪、垂直速度惩罚、关节力矩惩罚、关节加速度惩罚、动作变化率惩罚等十几项。每一项都有对应的权重,这些权重是经过大量实验调出来的。比如线速度跟踪的权重是1.0,垂直速度惩罚是-2.0,关节力矩惩罚是-2.5e-5。
03.
零样本硬件部署和15个任务的泛化测试
把在RWM里训练的策略直接扔到真实机器人上,不做任何微调。ANYmal D是一台重约50公斤的四足机器人,12个自由度。Unitree G1是人形机器人,29个自由度,控制难度更高。论文展示的实验视频显示,两台机器人都能稳定执行速度跟踪任务——给定前进、转向的速度指令,机器人能精确跟随,误差控制在可接受范围内。

团队没有在真实硬件上做在线学习。策略训练过程中,机器人平均会摔20多次。在仿真里摔无所谓,真机摔一次就是事故。而且要实现在线学习,还需要一个恢复策略让机器人自己站起来,这对ANYmal D和G1这种大型平台来说技术难度不小。

所以采用的策略是:在仿真里训练时,故意引入域随机化(domain randomization),模拟真实世界的不确定性。比如随机改变地面摩擦系数、机器人质量、执行器延迟等参数。这样训练出来的策略,对真实环境的适应性更强。实验结果证明这个策略有效。ANYmal D在实验室地面上跑了多组测试,前进、后退、转向都很流畅。Unitree G1的表现同样稳定。

为了验证RWM的通用性,团队在15个不同的机器人任务上做了测试,涵盖操作和运动两大类。操作任务包括:UR10和Franka机械臂的到达任务、Franka的抓取和开抽屉任务、Allegro灵巧手的物体重定位任务。运动任务更丰富:Unitree A1、Go1、Go2三款四足机器人,ANYmal B、C、D三代四足机器人,波士顿动力的Spot,双足机器人Cassie,以及宇树的H1和G1人形机器人。
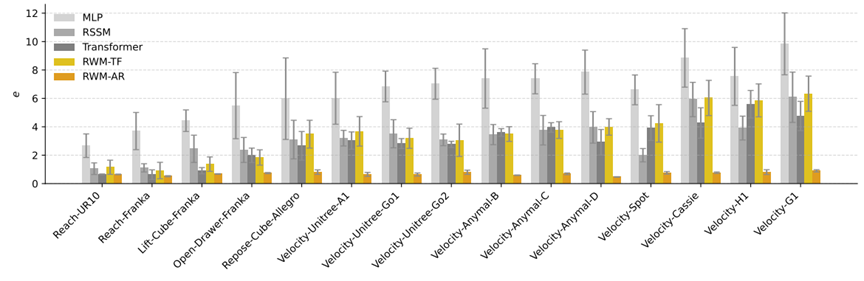
测试指标是自回归预测误差——让模型预测未来6秒的轨迹,然后和真实仿真结果对比。RWM-AR(自回归训练版本)在所有任务上的误差都是最低的,平均误差在2到12之间。相比之下,MLP的误差普遍在20以上,RSSM和Transformer也都在10到30之间波动。RWM-TF(teacher forcing训练版本)的误差明显高于RWM-AR,这直接证明了自回归训练的必要性。
04.
RWM框架的价值到底在哪儿?
RWM的价值不只是在几个机器人上跑通了实验,更重要的是它证明了一件事:不依赖领域知识的通用世界模型是可行的。过去很多机器人学习方法都需要精心设计状态表示、手工调整网络结构、针对特定任务优化算法。RWM用同一套架构和训练流程,在操作和运动两大类、15个不同任务上都取得了最优效果。
从工程角度看,RWM的训练成本也在可接受范围内。单卡4090就能搞定,不需要大规模集群。这意味着中小型研究团队和创业公司也能用上这套方法。零样本硬件迁移的成功,给sim-to-real问题提供了一个新的解决思路。不是通过系统辨识去精确建模真实世界,而是通过域随机化和鲁棒的世界模型,让策略自然具备泛化能力。
论文也坦诚讨论了当前方法的局限。最大的问题是无法在真实硬件上做在线学习——策略训练过程中的频繁失败在真机上不可接受。团队提到,未来可能会引入不确定性感知的世界模型,让策略在探索时更保守,避免危险动作。另一个问题是特权信息的依赖。虽然RWM在训练时用了接触力、足端高度等信息,但这些信息在真实硬件上需要额外的传感器或估计算法。未来可能会研究如何从纯视觉或本体感觉信息中隐式学习这些物理量。
论文链接:https://arxiv.org/pdf/2501.10100
项目地址:https://sites.google.com/view/roboticworldmodel
END


工业机器人企业
埃斯顿自动化 | 埃夫特机器人 | 法奥机器人 | 越疆机器人 | 节卡机器人 | 松灵机器人 | 珞石机器人 | 阿童木机器人 | 极智嘉 | 海康机器人
服务与特种机器人企业
亿嘉和 | 晶品特装 | 七腾机器人 | 史河机器人 | 普渡机器人 | 施罗德机器人 | 库犸科技MAMMOTION
人形机器人企业
优必选科技 | 宇树 | 云深处 | 星动纪元 | 伟景机器人 | 逐际动力 | 乐聚机器人 | 大象机器人 | 魔法原子 | 众擎机器人 | 帕西尼感知 | 赛博格机器人 | 数字华夏 | 傅利叶智能 | 天链机器人 | 开普勒人形机器人 | 灵宝CASBOT | 清宝机器人 | 浙江人形机器人创新中心 | 动易科技 | 智身科技 | PNDbotics | 卓益得机器人 | 鹿明机器人 | 擎朗智能| 伽利略GALILEO | 天机智能 | 卧安机器人
具身智能企业
跨维智能 | 银河通用 | 千寻智能 | 灵心巧手 | 睿尔曼智能 | 微亿智造 | 推行科技 | 中科硅纪 | 枢途科技 | 灵巧智能 | 星尘智能 | 穹彻智能 | 方舟无限 | 科大讯飞 | 北京人形机器人创新中心| 国地共建人形机器人创新中心 | 戴盟机器人| 视比特机器人| 星海图 | 月泉仿生 | 零次方机器人 | 中科深谷 | 智平方 | 大咖机器人 | 灏存科技| 具识智能 | Xynova曦诺未来 | 非夕科技 |未来动力 | 博登智能 | 千诀科技 | 灵生科技 | 集萃智造 | 欣佰特科技 | 晨昏线科技 | Dexmal 原力灵机 | 优理奇
医疗机器人企业
元化智能 | 天智航 | 思哲睿智能医疗 | 精锋医疗 | 佗道医疗 | 真易达 | 术锐®机器人 | 罗森博特 | 水木东方|康诺思腾 | 迪视医疗
上游产业链企业
绿的谐波 | 因时机器人 | 坤维科技 | 脉塔智能 | 青瞳视觉 | 本末科技 | 鑫精诚传感器 | 蓝点触控 | BrainCo强脑科技 | 宇立仪器 | 极亚精机 | 思岚科技 | 神源生 | 非普导航科技 | 因克斯 | 巨蟹智能驱动 | 凌云光 元客视界 | 璇玑动力| 意优科技| 瑞源精密 | 灵足时代 | HIT华威科 | 星汇传感 | 凌迪科技 | 泉智博| CubeMars






