 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库88天登录193次!顶级证据+循证医学,让500万中国医生拥有「神助攻」

凌晨 1 点,某三甲医院急诊科,一位 62 岁的男性被紧急送入,他正经历急性 STEMI 并发急性心衰。血压飙至 185/105 mmHg,血氧仅 91%。护士已推来除颤仪,催促医生「心电捕手」确认替格瑞洛剂量。
患者肾功能受损,标准剂量极易引发致命脑出血,而减量又担心支架再被血栓堵塞。在浩瀚的指南与文献中寻找剂量调整条款,医生只有短短 3 分钟——对他而言,这三分钟漫长得仿佛一个世纪。
深夜,珠江医院胸外科主任乔贵宾仍伏案办公,为一位罕见肺病患者设计后续方案。对身兼胸外科主任、主任医师和博导的他来说,每天平均工作超过 10 小时,加班处理疑难病例几乎成为常态。
「没有哪个国家的医生承受这样的超级压力。」纪录片《中国医生》总导演在专访中说过的一句话,高度概括了医生们的日常工作现实。
公开数据显示,2024 年,全国医疗卫生机构总诊疗人次达到101.5 亿,其中三级医院诊疗量为 28.7 亿,病床使用率接近九成。而全国 508.2 万执业(助理)医师,却要支撑这百亿级的诊疗需求。每一次开处方、下医嘱、做检查、规划手术方案,几乎都需医生决策。
更复杂的是,医学知识更新速度很快。以 PubMed 为例,已收录超过 4000 万条生物医学文献,每年仍新增百万级条目。对医生而言,压力不仅来自患者与诊疗数量,更来自高负荷工作中不断追赶最新证据与指南的挑战。
在这种结构性困境下,医疗的核心问题并非「撮合就诊」,而是医生的决策供给——互联网医疗可以提升就诊效率,却触及不到这一结构性痛点。而这,正是医学 AI 能够真正放大的空间。
DeepSeek们,
为什么一进医疗科研就翻车?
过去一年,大模型几乎席卷了各行各业,医疗领域也不例外。行业对医学 AI 的期待迅速升温,中国医生成为拥抱大模型最为积极的群体之一。但与此同时,一个越来越明显的困境也摆在了大家面前:一旦通用大模型进入严肃医学场景,它的能力往往迅速塌陷。
最让医生头疼的是「幻觉」问题。比如,它会虚构文献。当你想查看原文、复核数据时,即使明确要求提供准确的 DOI 号(类似文本的身份证号),也经常发现链接是错的,点开完全是另一篇文章。
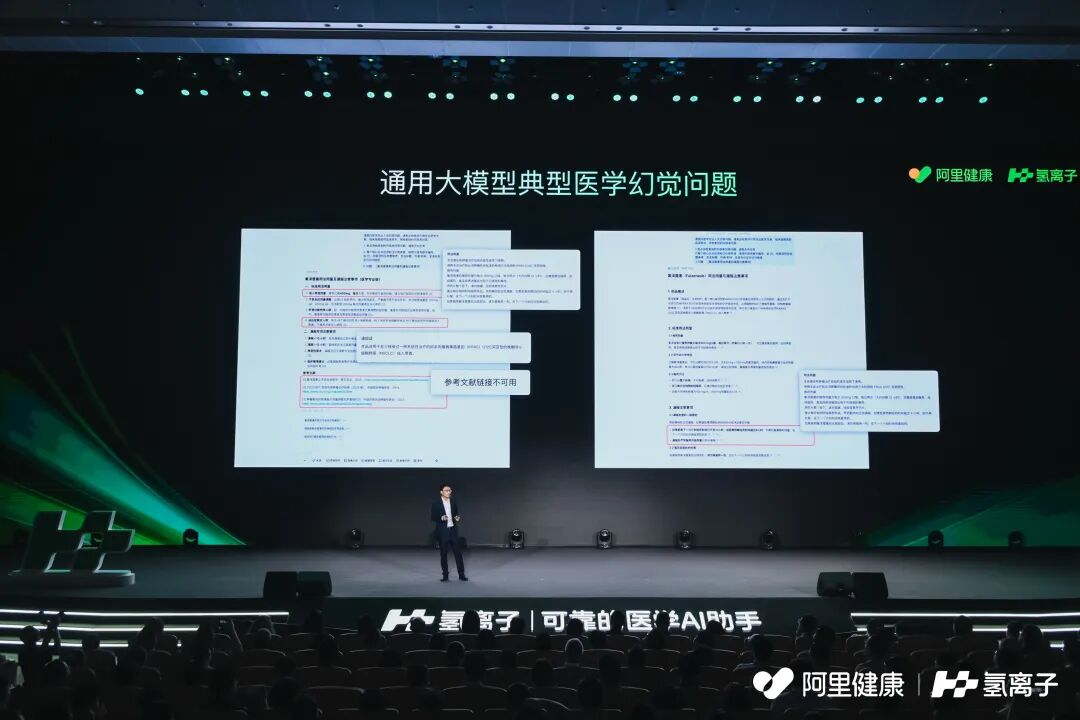
通用大模型的高幻觉率,始终是个棘手的困扰。
乔贵宾和同事都在工作和私底下用过通用大模型,高幻觉率始终是个棘手的困扰。像胸外科这样极度硬核的诊室,一个杜撰的结论,危害不亚于误诊。
最近,一项发表在英国皇家外科医学院官方期刊上的研究【1】,也进一步印证了医生们的担忧:某些主流人工智能平台生成的医学参考文献中,超过三分之一可能是伪造的。例如,Grok 3 的引用幻觉率高达 33.6%,DeepSeek DeepThink 为 25%。
这些「幻觉引用」看起来非常真实,甚至带有虚构的 Mayo Clinic (梅约诊所)链接或极具误导性的学术标题。
研究还发现,近半数顶尖模型在回答医学问题时,默认并不会清晰披露信息来源。
而这些,恰恰与医生日常工作的核心相悖:循证(基于证据做决策)——我如何知道我的推理和决策是有理可据的,是权威的,是准确的?尤其是那些涉及到我知识盲区的证据。
这时候,能快速、准确地找到权威依据来支撑判断,最刚需、也最头疼的事。而本质上基于概率文本生成的通用大模型,并不天然具备这种场景下的「循证」能力。

从多个维度测试国内某头部通用大模型在回答医学科研问题时是否可靠,结果让人担忧。
为了解决这一难题,业界普遍将检索增强生成(RAG)奉为圭臬,认为它能通过检索外部患者病历来纠正大模型的信口雌黄。最常采用的方案就是将病历、指南、论文切片后灌进向量数据库,再通过检索增强生成,让模型「带着资料回答」。
至于效果?最新研究给出了一个相当反直觉的结论。
这份发表于权威医学预印本平台 medRxiv 的论文显示,在医学临床文本生成中,加入 RAG 技术后,大模型的无依据声明率(Unsupported claim rate,即幻觉率)从基线状态下的 5.0% 剧烈飙升至 43.6%。这意味着 RAG 让医学 AI 犯下事实性错误的概率增加了整整 8.7 倍。【2】
为什么会这样?因为临床文本并不是普通知识库。
它高度非结构化,充满上下文依赖、时间敏感信息和相互冲突的证据。不同患者、不同时间点的医学术语重叠度极高。RAG 很容易检索出「语义上高度相似,但实际上属于其他患者,或对应错误时间点」的病历片段。
也就是说,它找到了「看起来相关」的资料,却未必找到了「真正适用」的证据,而大模型会以此为据、凭空捏造当前病人的虚假医学叙事。
如何确保模型找到的是对的证据、用的是对的上下文、给出的是能被医生复核的判断?如何让每一次回答都绑定在可信证据链上?
这正是深耕医学健康十多年的阿里健康,想要破局的地方。
一切为了可靠,「氢离子」破局关键一环
5 月 13 日,阿里健康把「氢离子」正式推到了台前。这是一款面向临床和科研医生的医学 AI 产品。发布会上,阿里健康同时宣布,氢离子与国家级医学顶刊达成独家内容合作。

产品设计上,AI被放在了最后,而定语首先是证据、循证。

氢离子与国家级医学顶刊达成独家内容合作。
按照官方定位,「氢离子」想解决的是「中国 500 万医生的一切医学问题」。 「低幻觉、高循证」是它最核心的能力标签:所有回答均提供权威出处,支持一键溯源、直达信源。

「在严重幻觉率上,我可以给大家一个定性的结论,我们比国内的竞品领先2-3倍。」阿里健康 CTO 祥志说。
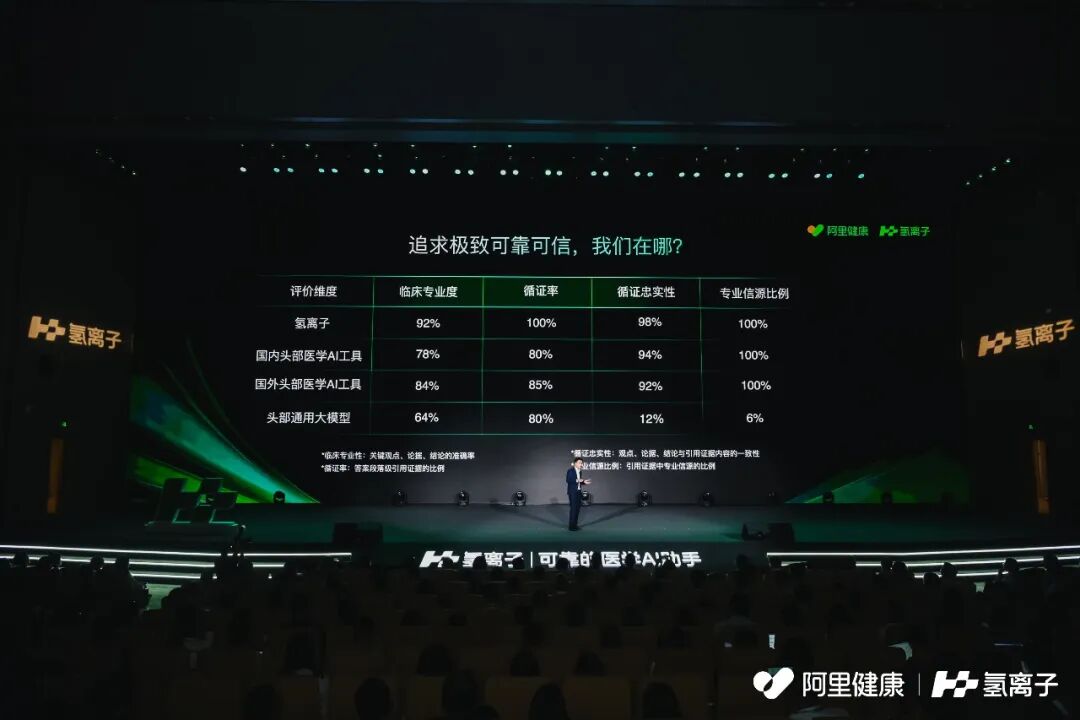
这很容易让人联想到医学界的「神器」UpToDate,也就是 UTD。很多医生在查房、开药、处理疑难病例或准备科研资料时,都会依赖 UTD 这类循证医学决策支持系统,快速找到权威、可靠的决策依据。
但与传统工具相比,「氢离子」使用门槛要低得多。医生可以通过自然语言、多轮对话,甚至语音和图片等多模态方式提问,就像和同事讨论病例一样,把问题直接抛给 AI,它会结合上下文持续理解和回应。
在正式发布前,氢离子已完成内测并开放下载。医生的反馈最集中的关键词是「可信」和「可靠」,尤其是对「循证问答」评价极高。一位三甲急诊科主任医师试用后,在 88 天内登录已高达 193 次。
为了确认替格瑞洛剂量,急诊室医生「心电捕手」打开「氢离子」,飞快输入「急性 ST 段抬高型心梗合并急性心衰,PCI 术后替格瑞洛剂量调整(eGFR65)」。
 |  |
「心电捕手」在某医疗社区的发言。
AI 不仅明确推荐负荷剂量 180mg,维持剂量 90mg bid,还加粗标注了依据来源——中华医学会 2025 年最新治疗指南。点击后,可以直接查看电子化指南原文,不再需要翻找笨重的 PDF 文件。
更关键的是,「氢离子」不是简单高亮一整段文本,而是定位到真正决定结论的「关键三行」。医生看到的不只是「这篇文章可能相关」,而是「依据具体在哪里」。
与此同时,回答还引入了两个更重要的维度:时效性(「2025年」)和权威性(「中华医学会的指南」),强调对全球权威指南和文献进行日更级追踪与筛选,并基于这些动态证据生成回答。
这背后,考虑到是一个基本现实:医学证据每天都在变化。
新指南、新药物、新疗法、新临床试验层出不穷,尤其是在肿瘤、感染、心血管等领域,顶刊上的一个新结果,可能直接改变第二天的治疗策略。一旦证据没跟上影响判断,代价可能是患者动了没必要的刀子,或错过最佳手术时机。
为了杜绝低质信源的「污染」,模型在生成答案时会优先「定位」权威等级更高来源,自动降权低质量个案报道。
某种程度上,这些也构成了「氢离子」与传统医学搜索工具、乃至其他「AI 医生」产品之间最大的区别——医生看到的每一个观点,都经得起三个问题的追问:精准吗?权威吗?够新吗?
但在临床现场,可信之外,医生还需要它足够快。
「心电捕手」提到,确认替格瑞洛剂量时,「没想到 3 秒就出了结果」。过去遇到类似疑难问题,往往需要在 PubMed、指南、药品说明书等多个平台之间来回切换,整个过程可能耗费十几甚至二十分钟。
很多医生手机里常年装着 5~6 个医学 App,因为它们大多只是单点工具。而「氢离子」试图把这些「搬运成本」压缩成一次提问:快速给出有依据的用药方案和剂量建议,同时联动药品说明书,标注禁忌症与注意事项。
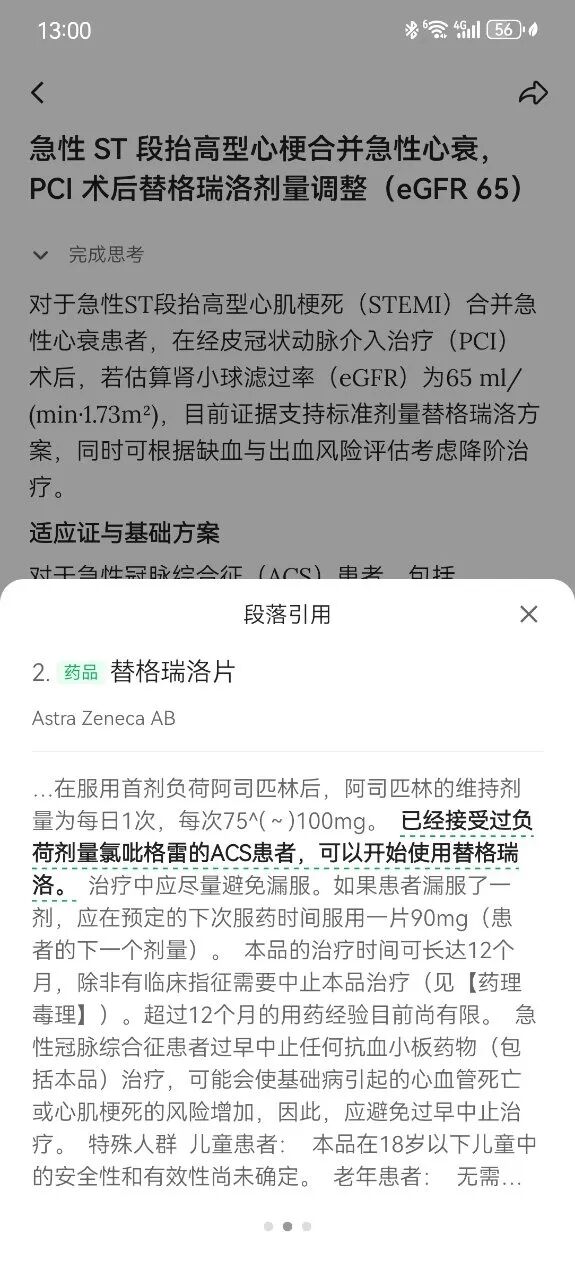
医生「心电捕手」在医疗社区中指出,AI返回的结果还联动了相关药品说明书,标注了用药禁忌和注意事项,比急诊室医生之前同时翻指南和说明书高效太多。
对医生而言,这不只是「少打开几个页面」,而是在争分夺秒的临床环境里,缩短关键决策时间。
把「医学证据」写进 AI:
四层循证架构首次揭晓
在发布会上,团队首次披露了「低幻觉、高循证」背后的「四层循证架构」——从医学证据结构化、循证检索、模型对齐,到专家闭环反馈,试图把「循证医学」真正写进 AI 的底层逻辑。

第一层:充分理解医学证据。
不是直接「读文字」,而是把医学文本转化为可结构化、可评估、可追溯的证据单元。
这里最核心的是 PICO 与 GRADE 两套经典循证框架。
PICO 本质上是一套医学问题结构,它要求 AI 像临床医生一样,拆解文本的核心要素:针对什么人群(P)?采用何种干预(I)?与什么方案对照(C)?最终结果如何(O)?
例如,针对一项减肥药研究,自动生成精确的证据链:
18~50 岁、体重超过 200 斤、无严重心脏病的成年人; 每天服用一种新型减肥药 A; 另一组服用外观相同的安慰剂; 三个月后,A 组平均减重 10 斤,对照组仅减重 2 斤。
这样的解读不仅解决语义匹配问题,更强调「证据适配」——只有 PICO条件完全匹配,后续建议才有临床价值。
GRADE 则为这些证据贴上「可信度」的等级标签。
在循证医学中,文献的含金量千差万别。所谓值不值得信?不是「我觉得」,而是基于一套可量化的评价体系。 GRADE 是全球循证医学最核心的证据评级体系之一,目前已被 World Health Organization 等全球 100 多家权威医学机构广泛采用。
根据这一标准,大型随机对照试验(RCT)通常属于高等级证据;Meta-analysis 往往拥有更强的综合可信度;个案观察、经验分享,则属于较低等级证据。

针对「铂耐药复发卵巢癌」的最新文献检索结果。文献按时效性(2025 年)、权威性(高影响因子 TOP 期刊)及证据等级(RCT、临床研究)呈现, 甚至列出了JCR分区、中科院分区及IF分值,可以一眼看到文献的质量和参考价值。来源:王伟强博士公众号文章。
第二层:将 PICO 注入 RAG,从「关键词检索」走向「结构化降维」。
基于 PICO 框架,检索逻辑从「搜词」升级为「搜结构」,彻底解决了传统 RAG 检索容易失效的问题。
例如,「布洛芬能不能比对乙酰氨基酚更快让儿童退烧?」通过 PICO 拆解后,系统不会简单搜「布洛芬 退烧 儿童」,而是自动转化为标准循证问题——「在发热儿童(P)中,布洛芬(I)相较于对乙酰氨基酚(C),在退热速度和副作用(O)上有何临床证据?」
这样检索出来的文献,更像是在回答一个临床问题,而不是凑关键词。反过来说,RAG 也只有在文档结构化程度高、检索逻辑符合循证范式时才更可靠。
有了证据理解和精准检索,问题来了:AI 会正确使用证据吗?
第三层:强化与对齐,规训模型「像医生一样使用证据」。
氢离子在后训练阶段加入了 Reward 模型与 Rubrics 评分体系。Reward 模型负责让 AI 学会「什么是好答案」,而 Rubrics 则把循证医学中的质量要求,进一步工程化成可训练、可评测的标准。
模型最终学习的,不再只是语言风格,而是如何生成低幻觉、可追溯、符合循证规范的回答。
然而, 在瞬息万变的医学领域,单纯依赖静态的模型训练无法消除所有长尾边缘案例,也无法实时同步最新的指南、药物与疗法。因此,架构的最后一环交给了 Experts-in-the-Loop(专家闭环反馈)。
真正有价值的数据,需要长期专家标注,需要持续更新,需要明确证据等级,还需要知道不同研究之间的关系与冲突。
目前氢离子构建了由超过 300 位资深医生组成的医学 AI 专家委员会。他们扮演着「主治医生」与「首席出题官」的角色,持续对 AI 的输出进行高强度的「找茬、打分与修正」。
专家的评测不是为了得出一个安全分数,而是为了反哺前三层。例如:发现某处回答不佳,立刻倒推是不是第一层的 PICO 拆解粒度不够细?或是第三层的 Rubrics 评分标准过于宽松?
最终,通过这四层由浅入深的循证架构,理解、检索、训练与评测形成了一个完美的「可追溯、可验证、可信赖」的闭环。AI 彻底摆脱了「静态工具」的局限,演变为一个能够随着医学证据实时更新、基于临床反馈不断自我纠错的「进化型系统」。
从一款高效的生产力产品,真正成长为医生在临床与科研中不可或缺的可信赖伙伴。
本土权威+国际前沿:
数据壁垒,夯实循证底座
要把「高循证」做到极致,光靠算法和工程创新是不够的,AI 最硬的门槛,其实在于数据源。高质量的医学数据库,不只是功能底座,更是临床安全的护栏。
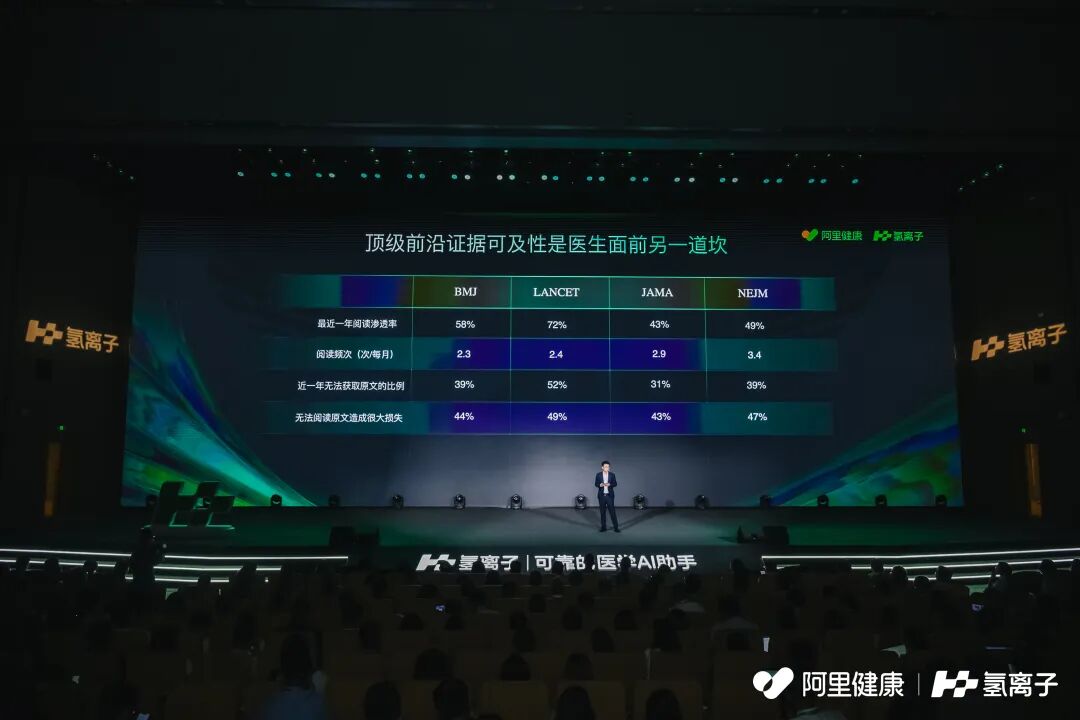
中国医生普遍存在世界顶级研究获取困难的问题。
此前,氢离子已经与中华医学会、人民卫生出版社等国内医学出版巨头深度合作,奠定了本土权威基础。而这次官宣的国际顶刊合作,意味着76% 的医生不再受困于顶级前沿证据的难以触达。
通过这种「强强联合」,氢离子构建起多层级的专业医学知识谱系,进一步夯实了在医学 AI 领域的底层数据壁垒。
目前,氢离子汇聚了来自 PubMed、Google Scholar 等国际数据库以及国内核心期刊的千万级顶尖文献,为科研和疑难病例提供稳固支撑。
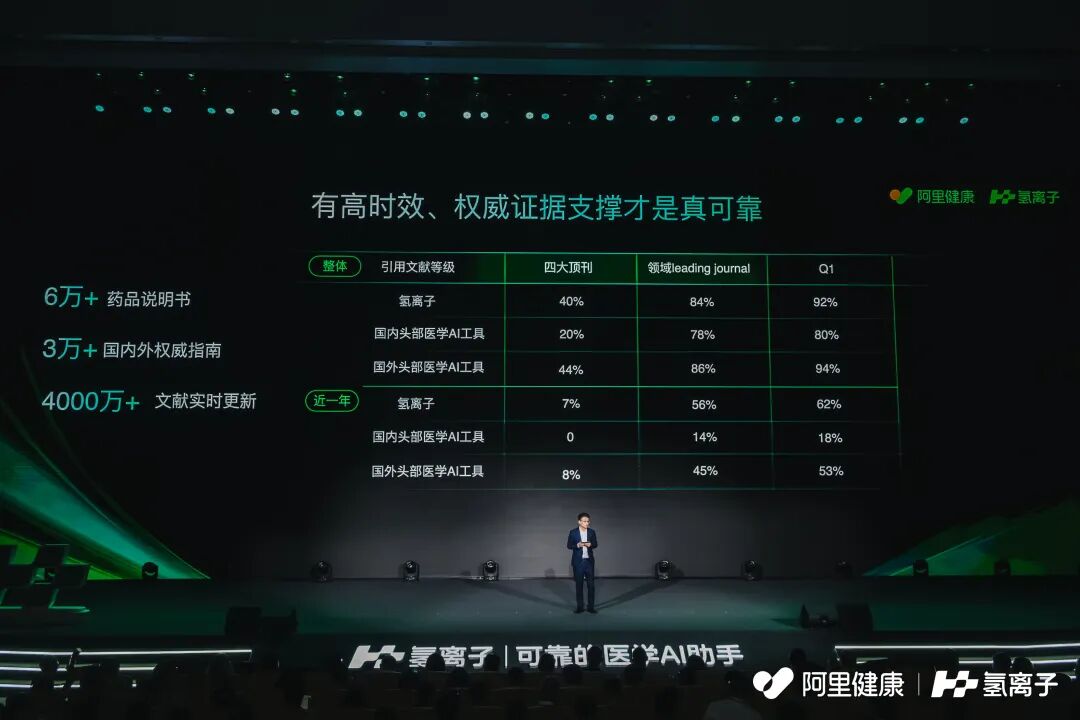
同时,系统整合了三万余部国内外权威临床指南与专家共识,以中华医学会等机构发布内容为主,使 AI 在复杂临床环境中能够迅速锁定标准方案,大幅提升诊疗效率与安全性。
药品说明书及活性成分信息超过六万份,从适应症、禁忌症、用法用量,到不良反应及特殊人群用药,实现临床开方与用药风险的全面掌控。
这些不仅保障了 AI 在临床辅助中的极致安全,也让「氢离子」在医学 AI 赛道上形成短期难以逾越的核心竞争力。

过去两年,行业习惯把医学 AI 理解成参数规模竞争、问答能力竞争。但真正进入临床与科研场景后,发现准确性、可追溯性、稳定性与决策一致性,远比「会不会回答」更重要。
「氢离子」用实践证明,严肃医学 AI 的真正护城河不是参数规模,而是「从高等级证据到临床答案」的全链路工程能力。 缺少了顶级信源与循证架构的严苛规训,再庞大的参数,最终也会碎成「通用模型+医学语料」的平庸组合。
正如乔贵宾所言:「这才是医学 AI 该有的样子。它不替你做判断,而是帮你更快找到做判断的依据,并且让你看清它是从哪儿找来的。」医生不需要一个擅长模糊应答的「聊天花瓶」,而需要一个能在临床与科研中并肩作战的「硬核战友」。
当繁重的循证检索被 AI 降维打击,医生们偶尔也会和学生们聊起,如果所有循证的工作都被 AI 代劳了,医生还需要什么?
大家的答案很一致,向本源的回归——练就临床判断力。因为敲定最终方案,还要取决于医生的综合评估。
这也应验了那句在圈子里广为流传的话:能够给出治疗方案的,叫「智能( Intelligence )」,真正理解眼前的患者,才是「智慧( Wisdom )」。
参考链接
1、Trust, truth and transparency: analysing the references underpinning AI-generated surgical information
https://publishing.rcseng.ac.uk/doi/10.1308/rcsann.2026.0021
2、Representation Before Retrieval: Structured Patient Artifacts Reduce Hallucination in Clinical AI Systems
https://www.medrxiv.org/content/10.64898/246256v1.full.pdf
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com





