 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库越懂你,越危险?MemPrivacy揭示AI记忆下一站

AI 记忆时代 ,Agent 越来越像一个真正的私人助理。
它记得你的习惯,知道你的日程,理解你的健康状态,甚至能在长期对话中逐渐形成一套关于你的「个人画像」。但问题也随之而来:如果这些记忆都要上云,隐私还安全吗?
4 月 22 日,OpenAI 开源了一个名为 privacy-filter 的轻量级隐私过滤模型,试图解决大模型系统中的 PII 检测与脱敏问题。

OpenAI Privacy Filter 地址:https://openai.com/zh-Hans-CN/index/introducing-openai-privacy-filter/
仅仅两周后,记忆张量 MemTensor 团队拿出了一个更激进的答案。该方案由记忆张量 MemTensor 与荣耀 HONOR 团队联合研发,同济大学也参与其中 —— 这也是端侧厂商与记忆基础设施团队首次在「Agent 隐私」这件事上深度合作。
他们正式开源了面向端云协同 Agent 的隐私保护框架与系列模型 MemPrivacy。更令人意外的是,在同样的真实对话隐私提取任务上,MemPrivacy 的 F1 分数最高比 OpenAI privacy-filter 高出 50.47 %。
这并不是一次临时跨界。
在此之前,记忆张量已经推出 MemOS,把 Agent 记忆从向量库或 RAG 插件,提升为可管理、可调度、可演化的系统资源:记什么、怎么检索、如何更新、如何治理,都被放进一套「记忆操作系统」里。
MemPrivacy 更像是 MemOS 往端云协同场景自然长出的隐私层 —— 当 Agent 开始长期记住用户偏好、健康状态、账号凭证和工作上下文时,问题就不只是「能不能记住」,而是「能不能安全地记住」。这也让记忆张量做 MemPrivacy 显得顺理成章:它不是从通用 PII 打码出发,而是直接从 Agent 长期记忆的真实使用场景出发,重新定义隐私类型、保护级别和占位符机制。
发布当天,MemPrivacy 即上榜 Hugging Face Daily&Weekly Papers TOP1。
这不是一个简单的「隐私打码工具」。
它瞄准的是下一代个性化 Agent 最核心、也最棘手的问题:如何让云端大模型继续拥有长期记忆和个性化能力,同时又不让用户的敏感数据真正离开本地?
换句话说,MemPrivacy 想做的事情是:让 Agent 可用,但不可见。

论文标题:MemPrivacy: Privacy-Preserving Personalized Memory Management for Edge-Cloud Agents
论文地址:https://arxiv.org/pdf/2605.09530
代码仓库:https://github.com/MemTensor/MemPrivacy
模型仓库:https://huggingface.co/collections/IAAR-Shanghai/memprivacy
OpenAI 入局
但 8 个标签撑不起 Agent 的长期记忆
OpenAI 的 privacy-filter 思路很简单:扫描文本,识别隐私片段,然后替换成语义标签。
比如,把用户输入中的人名「Maya」替换成 [PRIVATE_PERSON]。
这套模型拥有 1.5B 参数,其中激活参数约 50M,采用双向 Token 分类架构,支持 128k 上下文,主打高吞吐量 PII 检测与掩码。
相比传统一律替换成 *** 的打码方式,这当然已经进了一步:它至少保留了一部分语义。
但放到端云 Agent 的长期记忆场景里,问题很快暴露出来了。
OpenAI privacy-filter 只提供 8 类基础隐私标签。对于普通表单脱敏,这也许够用;但对于一个需要理解用户、长期记忆用户、甚至调用工具替用户执行任务的 Agent 来说,这个粒度太粗了。
银行卡号、社保编号、项目档案号,可能都会被塞进同一个 [ACCOUNT_NUMBER]。登录密码、数据库凭证、API Key、内部密钥,也可能统统变成 [SECRET]。
这就像把所有危险物品都贴上「危险」两个字。
安全是安全了一点,但语义也被抹平了。
真正的问题在于,Agent 不是数据库清洗脚本。它需要理解上下文、保留关系、形成记忆,并在未来的对话中继续使用这些信息。
当用户说「我的血压今天是 160/110」时,这不是普通数字,而是健康指标;当用户说「这是我公司数据库的连接串」时,这也不是普通文本,而是高危凭证。粗粒度标签一旦识别不到,就会漏;一旦识别错,就会毁掉语义。
于是,隐私过滤进入了一个两难局面:
漏判,用户隐私裸奔;误判,Agent 当场失忆。
这正是下一代个性化 Agent 最难绕开的矛盾。
MemPrivacy 登场
不是抹掉隐私,而是给隐私换一张「本地身份证」
记忆张量 MemTensor 团队提出的 MemPrivacy,核心思路叫做:本地可逆伪匿名化。
它不是把隐私信息简单删除,也不是替换成无意义的星号,而是在端侧完成一次更精细的「偷梁换柱」。
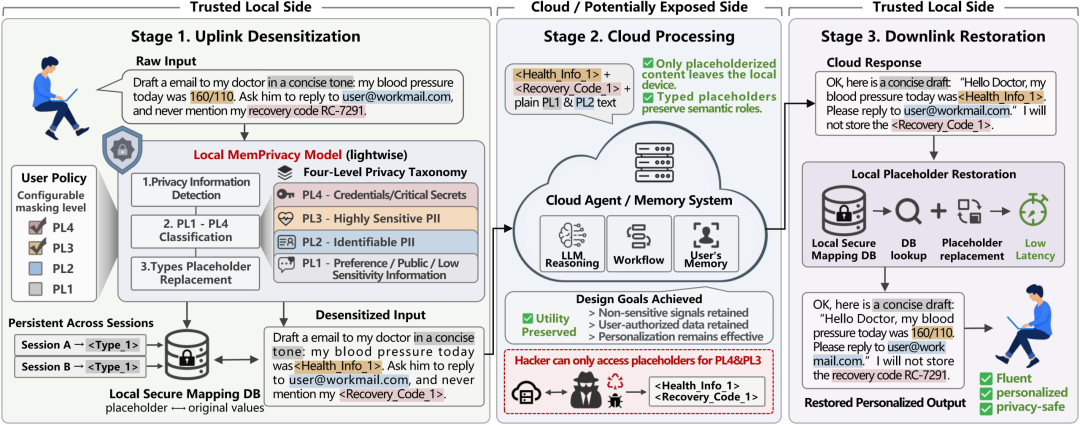
整个流程可以拆成三步。
第一步,端侧上行脱敏。
用户在手机、PC 等边缘设备上与 Agent 对话时,本地会先运行一个轻量级 MemPrivacy 模型。它负责识别对话中的隐私片段,并根据用户设置的保护等级进行处理。
如果文本里出现「我的血压今天是 160/110」,MemPrivacy 不会直接把它变成 ***,而是替换为类似 <Health_Info_1> 这样的细粒度类型化占位符。
真实血压值与占位符之间的映射关系,只保存在本地数据库里。
第二步,云端安全处理。
云端大模型看到的是:「我的血压今天是 <Health_Info_1>。」
它看不到 160/110 这个明文敏感数据,但依然知道这里是一个健康指标,因此可以继续进行推理、生成建议、形成记忆,甚至调用相关工具。
第三步,端侧下行恢复。
当云端回复「您的血压 <Health_Info_1> 偏高」时,本地系统再把占位符恢复成真实数值,最终呈现给用户。
在用户体验上,这个过程几乎是透明的。
但在系统架构上,关键敏感数据从未真正离开本地。
这就是 MemPrivacy 最重要的设计:让云端看懂结构,但看不到明文。
三种路线对比
无保护裸奔,全过滤失忆,MemPrivacy 保留智商
在端云 Agent 场景里,传统隐私保护大致有两种极端方案。
第一种是无保护。
用户原始数据直接上云。云端模型当然可以完整理解上下文,个性化效果最好,但健康数据、私人邮箱、家庭住址、账号凭证等敏感信息也会完整暴露。
在数据合规越来越严格的今天,这几乎是在走钢丝。
第二种是完全过滤。
所有隐私内容都被替换成 *** 或直接删除。看起来很安全,但代价是 Agent 彻底失去关键语义。用户想让它记住健康状况、财务约束、工作上下文,它却只能看到一片空白。
这类 Agent 看似安全,实际上已经丧失了「长期个性化」的基础。
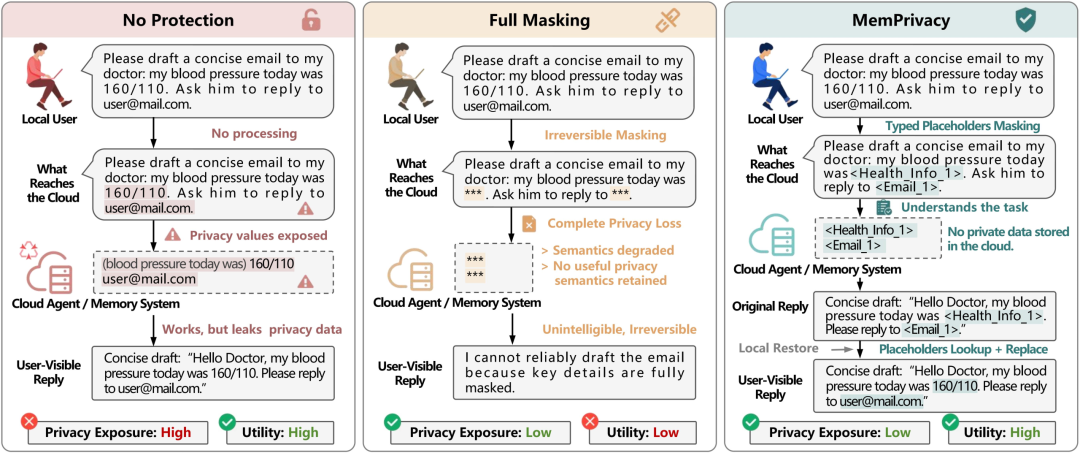
MemPrivacy 选择的是第三条路:细粒度类型化占位符。
云端不知道你的真实血压是多少,但知道这是一个健康指标;不知道你的私人邮箱是什么,但知道这里有一个邮箱;不知道你的 API Key 明文,但知道这里是一个高危凭证。
这种设计保住了两个东西:一是隐私边界,二是语义结构。
也正因如此,MemPrivacy 才有机会在隐私保护和 Agent 效用之间取得平衡。
硬核实力
F1 分数甩开 OpenAI 超 50 点,完爆 GPT-5.2
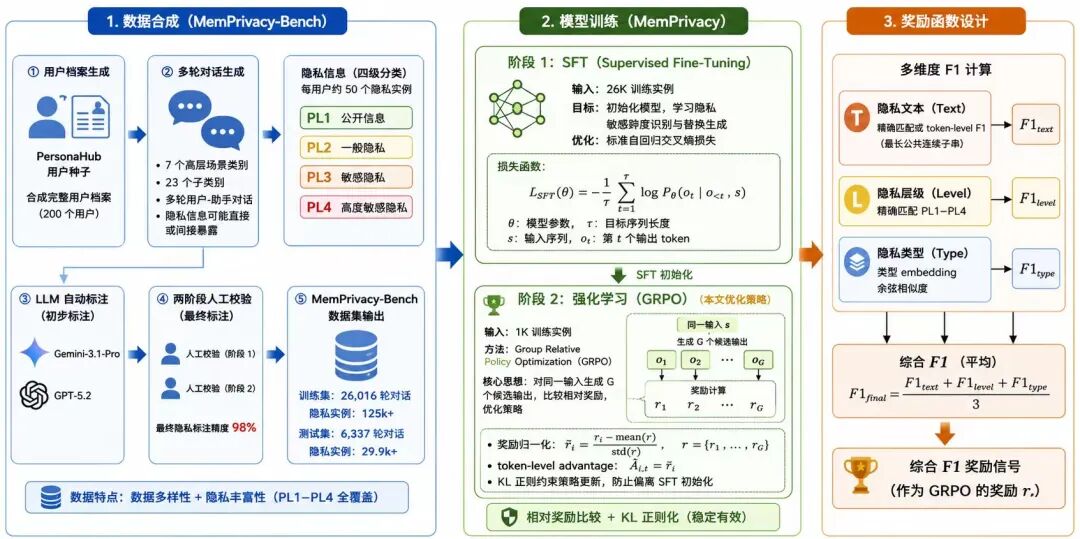
为了验证 MemPrivacy 的能力,研究团队构建了一个新的评测基准 MemPrivacy-Bench。这个基准覆盖 200 个用户的对话历史,包含超过 15.5 万个隐私项,并支持中英双语隐私信息检测。
此外,为了测试泛化能力,团队还在外部个性化长文本对话数据集 PersonaMem-v2 上进行了 OOD 交叉测试。
在这两大基准的提取准确率(隐私文本、级别、类型的综合 F1 分数)较量中,MemPrivacy 均展现出了碾压级的优势:
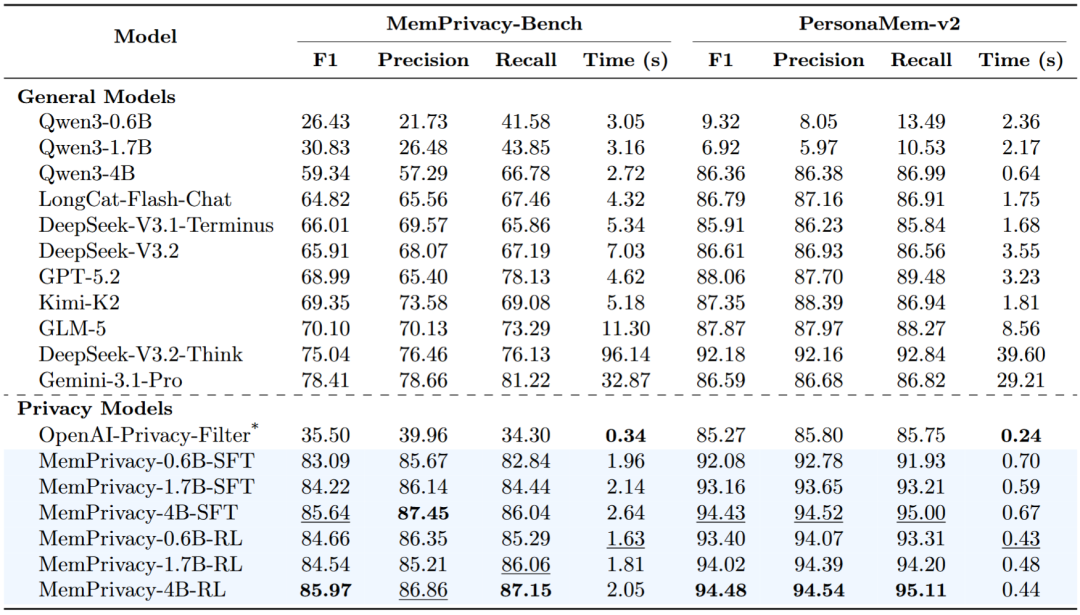
远超 OpenAI 专项模型:
在 MemPrivacy-Bench 上,OpenAI privacy-filter 的综合 F1 分数只有 35.50%。
而 MemPrivacy-4B-RL 达到了 85.97%,两者差距高达惊人的 50.47%!即使是在跨分布的 PersonaMem-v2 数据集上,MemPrivacy 依然领先 OpenAI 近 9%。
原因也很清楚:OpenAI privacy-filter 的优势在速度,非自回归 Token 分类架构带来了很高吞吐量;但它的问题在于标签覆盖窄、颗粒度粗,对复杂上下文和中文场景的适配不足。
MemPrivacy 则针对 Agent 长记忆场景重新定义了隐私类型、保护级别和训练目标,因此在真实对话中更接近实际需求。
更有意思的是,MemPrivacy 不只是赢了 OpenAI 的专项小模型。
越级挑战通用大模型:
即使面对参数量极其庞大的最强通用模型 GPT-5.2、Gemini-3.1-Pro 以及 DeepSeek-V3.2-Think,MemPrivacy-4B 乃至仅有 0.6B 的微型版本在两个数据集上均实现了碾压。
这说明,隐私提取不是简单堆大参数就能解决的问题。
它更像一个高度结构化、强约束、强边界感的任务。真正重要的不是模型有多大,而是它是否理解「什么信息该被保护、该保护到什么程度、保护后还能不能继续被 Agent 使用」。
不让 Agent 变傻
系统效用损失最低不到 1%
隐私保护还有一个更现实的问题:保护得再好,如果 Agent 变傻了,也是白搭。
这也是很多粗暴脱敏方案的死穴。
用户说:「我最近血压偏高,帮我记住,以后安排运动计划时注意一点。」
如果系统把血压、健康状态、运动偏好全部抹掉,云端模型当然安全了,但它也没法再提供真正个性化的服务。
MemPrivacy 的类型化占位符真的能保留记忆系统的效用吗?
团队在业界几个主流记忆系统平台上进行了端到端测试。所有底座均采用统一的 GPT-4.1 模型。
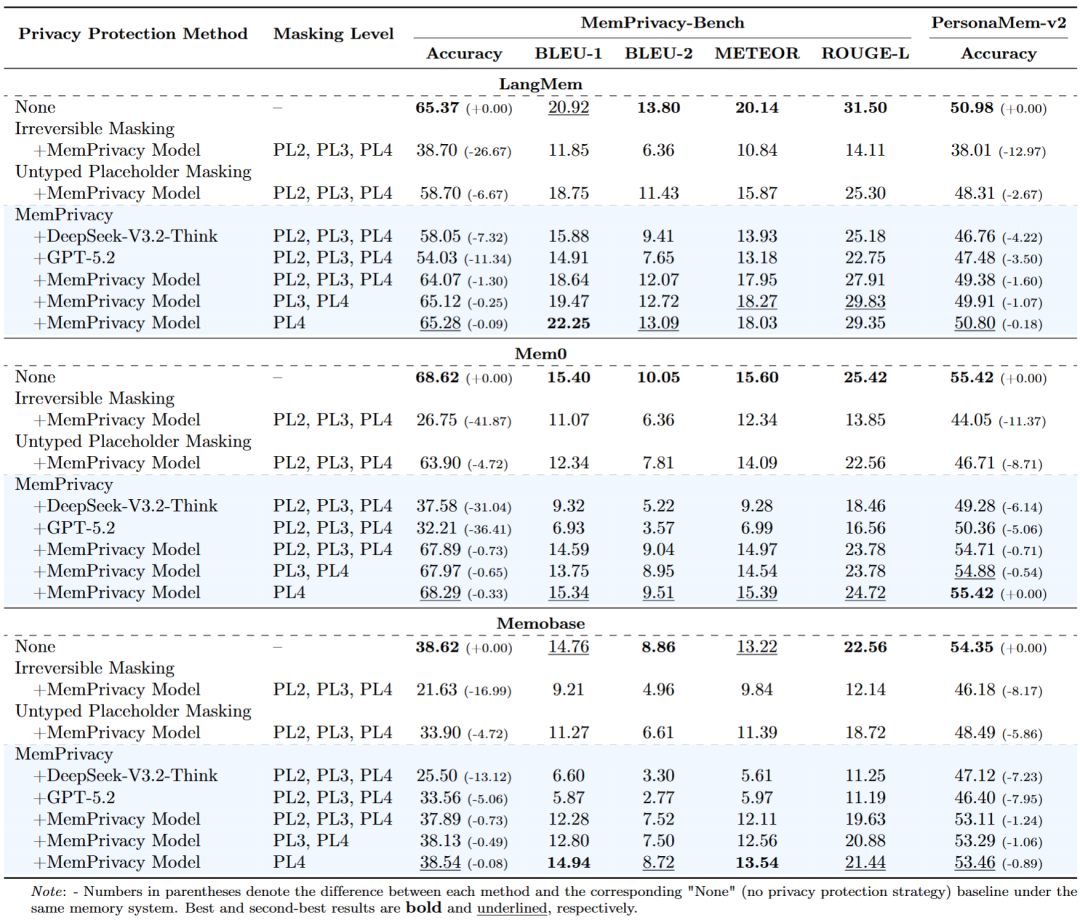
实验结果令人振奋:
当采用传统的不可逆掩码(Irreversible Masking)时,三大记忆系统的准确率分别暴跌了 26.67%、41.87% 和 16.99%,模型几乎处于失忆的瘫痪状态。
而在 MemPrivacy 保护下(最高防御级别 PL4+PL3+PL2 全开),系统效用损失被死死控制在 0.71% ~ 1.60% 之间。如果用户仅选择保护最高风险的凭证级隐私(PL4),准确率下降甚至不到 0.89%。
这意味着,MemPrivacy 真正做到了在不伤害智能体智商的前提下,把隐私泄漏风险降到了最低。
这正是 MemPrivacy 的关键价值:它不是在「安全」和「智能」之间二选一,而是试图把两者拆开 —— 明文不上云,但语义仍然可用。
四级隐私树
终于把「什么是隐私」讲清楚了
MemPrivacy 能做到这一点,背后一个重要原因是:它没有把隐私当作一个简单的二分类问题。
传统隐私过滤常常是「要么脱敏,要么全明文」。但真实世界远比这复杂。
MemPrivacy 引入了以可识别性、潜在危害性与可利用性为准绳的四级隐私分类法 (PL1-PL4),从而支持用户根据需求自由调控脱敏阈值:
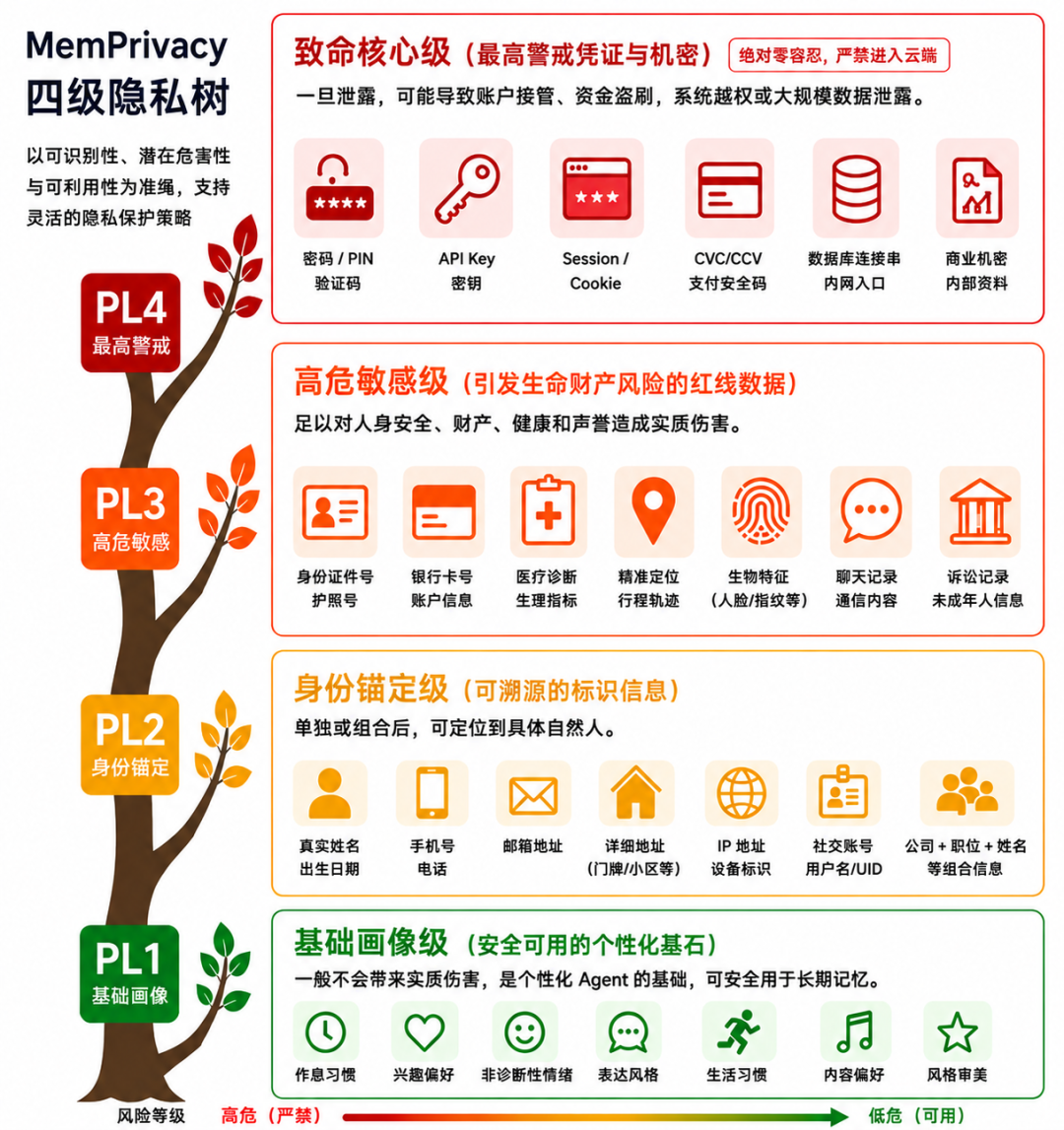
PL4 致命核心级(最高警戒凭证与机密)
这一层包括明文密码、验证码、Session、Cookie、API Key、内部商业机密等。一旦泄露,就可能导致账户接管、资金盗刷、系统越权或大规模数据泄露。
这类数据一旦检测到,系统将实行 “绝对零容忍” 拦截,严禁进入云端上下文。
PL3 高危敏感级(引发生命财产风险的红线数据)
包括身份证件号、详细医疗诊断、生理指标、精准轨迹定位、生物特征、敏感消费记录等。它们不一定直接等于账号权限,但足以对人身安全、财产、健康和声誉造成实质伤害。
PL2 身份锚定级(可溯源的标识信息)
包括真实姓名、详细地址、手机号、私人邮箱、IP 地址、社交账号等。单独或组合起来,可以定位到具体自然人。尤其是「公司 + 职位 + 姓名」这类组合,在真实场景中也具备很强的可识别性。
PL1 基础画像级(安全可用的个性化基石)
包括作息习惯、兴趣偏好、非诊断性情绪、表达风格等。这类信息是个性化 Agent 的基础,一般不会带来实质伤害,因此可以安全用于长期记忆。
这套分层设计的意义在于 —— 它让隐私保护不再是一把锤子。
同样是消费记录,「在超市花了 86 块钱」可能只是日常偏好;但某笔带有明确医疗属性的消费,则可能进入 PL3。
同样是数字,有些只是普通计数,有些却是血压、身份证号、验证码或 API Key。
这就是细粒度隐私识别真正困难的地方:模型必须理解语义、上下文、风险和用途。
两阶段训练
让模型真正理解隐私边界
在模型训练上,MemPrivacy 采用了 Qwen3 系列作为基座,覆盖 0.6B、1.7B、4B 多个规格。
训练过程分为两个阶段。
第一阶段是 SFT。
团队使用 26K 高质量多轮对话数据进行监督微调,让模型掌握基础的隐私定位、类型识别和占位符替换能力。
第二阶段是 GRPO 强化学习。
团队引入基于结构化 Reward 的策略优化,用提取结果的 F1 分数直接反馈模型表现。
这一步的意义在于,隐私识别最难的往往不是显而易见的手机号或邮箱,而是边界模糊、依赖上下文的细粒度信息。
比如一句「我最近压力很大」是否需要脱敏?
一句「我的血压今天 160/110」又该被划到什么级别?
某个字符串到底是普通 ID,还是内部凭证?
GRPO 让模型在这些模糊边界上进一步优化召回率与精确率的平衡,最终带来了 MemPrivacy 在多个测试集上的明显优势。
结语
端云 Agent 的下一块基础设施
在万物皆可 Agent 的未来,大模型比你更懂你自己是必然趋势,但比你更懂你,不代表让云端看光你。
OpenAI privacy-filter 的发布敲响了数据清洗和隐私合规的发令枪;而记忆张量与荣耀 AI 联合发布的 MemPrivacy,则为下一代云边协同架构(Edge-Cloud Agents)提供了一套直接可用、高精度、低损耗的标杆级工程解法。无论是对于开发个人 AI 助理的 AI Builders,还是对于需要满足严苛数据合规(如 GDPR)的企业级出海应用,MemPrivacy 都展现出了不可估量的商业与技术价值。
在这件事上,荣耀并不是一个偶然出现的合作方。从 MagicOS 到 YOYO,荣耀一直在尝试把更多 AI 能力真正放进设备本身。这也是为什么 MemPrivacy 的方案会和荣耀的端侧 AI 路线天然契合。
MemPrivacy 在荣耀终端设备上的落地,则是这次合作的进一步延伸:0.6B 到 4B 的多档模型本身就是为端侧部署设计的。当越来越多人开始习惯通过 YOYO 这样的 Agent 完成健康、出行、工作甚至财务相关的任务时,用户真正需要的,其实是一个 “既懂你、又不会看光你” 的 AI。
对端云 Agent 来说,“可记忆” 之后,“可安全记忆” 正在成为下一阶段真正的基础设施问题。
目前,MemPrivacy 的模型权重与评测基准已全部开源。隐私与长期记忆之间那道过去几乎无法兼得的墙,也第一次开始出现了被打通的可能。
论文地址:https://arxiv.org/pdf/2605.09530
代码仓库:https://github.com/MemTensor/MemPrivacy
模型仓库:https://huggingface.co/collections/IAAR-Shanghai/memprivacy
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com





