 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库AWS与哈佛大学等新成果,量子“数字孪生”实现97比特纠错模拟!


容错量子计算需要量子纠错技术(QEC),即将一个逻辑量子比特编码为多个物理量子比特,从而在低于某一阈值错误率的情况下,逻辑错误率会随着代码规模的增大而迅速下降。
实际工程中的问题在于,代码的规模必须达到何种程度,硬件的可靠性必须有多高,才能达到实用的逻辑量子比特水平?
可靠的答案是需要建立能够捕捉设备真实错误机制(包括相干性和关联效应)的模型,同时这些模型还需具备足够快的运行速度,以支持迭代设计。这些要求推动了用于量子纠错编码(QEC)的硬件校准数字孪生的设计。
作为实现这一目标的一步,Quantum Elements、南加州大学、哈佛大学与AWS联合发布的一项研究,基于实时量子蒙特卡洛算法与云端高性能计算,完成了97物理比特、码距7旋转表面码的全开放系统量子主方程模拟,在单计算节点约1小时内,精准复现了真实硬件中相干噪声、串扰、退相干等复杂错误特征,构建出适配实验级规模的量子纠错硬件校准数字孪生系统。

数字孪生
“数字孪生”(Digital Twin)最早起源于工业制造领域,其核心思想是为物理系统构建一个高度一致的虚拟映射,从而在不干扰真实系统的前提下进行预测、优化与测试。在航空发动机、智能制造等领域,这一技术已经被广泛应用。而在量子计算领域,数字孪生的引入,则意味着一种全新的工程方法论。
AWS及其合作团队提出的量子数字孪生,本质上是一个能够精确复现量子硬件噪声行为的仿真系统。它不仅模拟量子电路的理想演化,更关键的是能够嵌入真实设备中的噪声参数,包括弛豫时间、退相干时间、控制误差以及量子比特间的耦合效应等。这些参数通常来源于实验校准,因此数字孪生可以被视为“带有真实物理特征的虚拟量子计算机”。

这一模型带来的直接价值在于,它可以生成与真实硬件一致的综合征数据。在传统方法中,解码器往往依赖简化噪声模型进行训练,而这些模型无法反映真实误差的统计结构。通过数字孪生,可以构建高保真数据集,用于训练更具表现力的解码器,尤其是近年来兴起的机器学习解码器。
更进一步,数字孪生还可以用于“压力测试”纠错协议。真实硬件中,多种错误机制相互耦合,难以单独分离,传统实验无法针对性测试解码器的鲁棒性。数字孪生可以自由调控噪声参数,单独放大某一种错误(如ZZ串扰、频率失谐),极端场景下验证解码协议的可靠性,找到性能短板并优化。
最后,数字孪生还可以指导量子系统协同设计。基于校准后的噪声模型,数字孪生能预测不同QEC电路、芯片布局、硬件参数的性能表现,实现“软件解码、硬件参数、电路架构”的联合优化,避免硬件制造后才发现设计缺陷,缩短研发周期。
但量子数字孪生的实现,有一个核心前提,那就是,模拟必须足够“真实”,同时足够“快速”。既要完整捕捉相干、关联噪声等复杂效应,又要能在经典算力上高效运行,支持迭代设计。这正是此次AWS及其合作团队突破的核心。他们用实时量子蒙特卡洛(QMC)算法,解决了真实性与可扩展性的矛盾。

关键技术突破
尽管数字孪生的理念十分清晰,但其实现却面临一个根本性挑战:量子系统的状态空间随量子比特数量呈指数级增长。对于一个n量子比特系统,其密度矩阵规模为4ⁿ,这表明,即使是几十个量子比特,也会超出经典计算机的处理能力。
基于此,研究团队引入了实时量子蒙特卡洛(QMC)算法。该方法通过随机采样的方式,用一组“步行者”(walkers)来近似表示密度矩阵的演化过程,从而避免直接存储完整的状态信息。与传统确定性方法相比,QMC以引入统计误差为代价,大幅降低了计算复杂度。
具体而言,QMC方法将量子系统的演化转化为多个随机轨迹的平均结果。每个轨迹代表一种可能的系统演化路径,而通过增加采样数量,可以逐步提高结果精度。这种方法在统计物理中已有广泛应用,而其在量子电路仿真中的引入,则为处理大规模开放量子系统提供了新的工具。
更重要的是,QMC算法具有良好的并行性。每个“步行者”的演化可以在不同计算节点上独立进行,这使其非常适合部署在云计算平台上。AWS团队正是利用EC2高性能实例和ParallelCluster调度系统,实现了大规模并行仿真。
与现有方法相比,QMC数字孪生具有明显优势。Clifford模拟器虽然速度极快,但只能处理特定类型的噪声;张量网络方法可以扩展到更复杂系统,但依赖近似截断,可能丢失关键物理信息。而QMC方法在保持较高真实性的同时,实现了可扩展性,为量子纠错研究提供了一个全新的工具层。

实验验证
研究团队模拟了码距为7的旋转表面码,包含49个数据量子比特、48个测量量子比特,总计97个物理比特。这一规模已经接近当前实验系统的前沿水平,例如Google量子AI在近年来的表面码实验中,也处于类似量级。
在具体实现中,该电路包含228个单量子比特门和168个双量子比特门,并引入了多种现实噪声机制,包括T1/T2退相干、控制误差以及量子比特间的ZZ串扰。整个仿真在AWS EC2 Hpc7a实例上运行,单次计算时间约为75分钟,使用96个vCPU完成。这一结果表明,即使是接近百比特规模的系统,也可以在合理时间内完成高保真仿真。
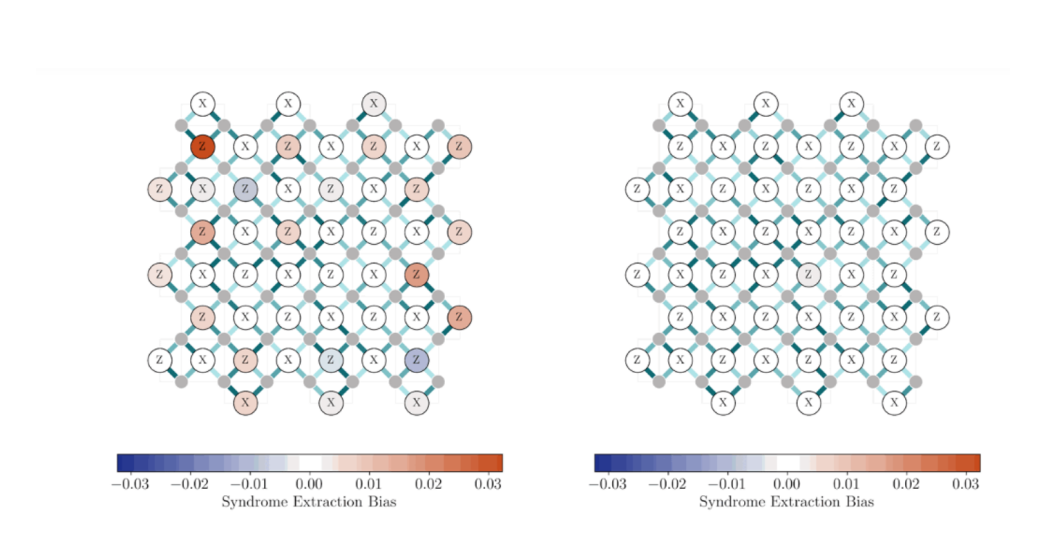
图:灰色节点是数据量子比特,带标签的圆是测量邻近数据量子比特的X型或Z型校验的辅助圈。边缘颜色编码剩余的ZZ串扰强度(深色边表示串扰更强)。在图形分辨率下,误差条可以忽略不计。
模拟结果极具说服力。通过对比标准克利福德模拟器(Stim),数字孪生清晰捕捉到频率失谐引发的空间结构化综合征偏差,暴露了硬件对控制参数误校准的敏感性;而简化模拟器只能给出均匀响应,完全忽略这些关键特征。
这直接证明,数字孪生能揭示传统模型遗漏的噪声信息,为解码器设计、硬件校准提供更精准的指导。

量子计算新范式
近两年,全球量子纠错领域迎来密集突破,如谷歌Willow实现了码距7的表面码的容错运行,中国科大潘建伟团队基于“祖冲之3.2号”超导处理器,采用全微波控制架构,也实现了码距7表面码纠错。

图:“祖冲之三号”芯片示意图
来源:中国科学技术大学
这些硬件突破,验证了量子纠错的可行性,但也暴露了共同痛点:硬件研发成本极高、迭代周期长、噪声调控难度大。而数字孪生的价值,正是在硬件制造前,完成所有优化与验证,让硬件落地直接达到最优性能,大幅提升研发效率。
此次研究是量子纠错数字孪生的基础性演示,下一步要做的就是:
第一,丰富错误模型,将更多硬件噪声机制纳入数字孪生,包括非马尔可夫噪声、动态串扰、测量误差等,让虚拟模型与真实硬件的匹配度进一步提升。
第二,优化解码软件,基于数字孪生生成的真实综合征数据,开发更具表现力的解码器,结合人工智能技术,实现自适应、高效率的错误修正,提升逻辑错误抑制能力。
第三,硬件性能闭环,将数字孪生的优化结果落地到物理硬件,通过校准、架构调整,实现虚拟与现实的性能匹配,完成“仿真-优化-验证-迭代”的完整闭环。
长期来看,数字孪生有可能成为量子计算研发的基础设施,就像今天的EDA软件之于芯片设计、CAE软件之于工业制造。从硬件设计到算法优化,再到系统部署,每一个环节都将依赖这一“虚拟镜像世界”进行验证与迭代。
当然,这项研究的实际意义远远超出了学术兴趣。首先,它为量子处理器设计提供了实用的仿真工具。硬件制造商可以使用数字孪生技术在实际制造之前测试和优化量子芯片设计,大幅降低开发成本和时间。
其次,对于量子算法开发者,真实的噪声模型使得他们能够开发出更鲁棒的量子算法,充分考虑实际硬件噪声特性。特别是在量子纠错领域,高质量的解码器训练数据将加速逻辑量子比特的实现。
此外,该技术为量子计算云服务提供商提供了新的服务可能性。AWS等云服务商可以集成QMC仿真工具,为客户提供更准确的量子计算仿真环境,推动量子计算的实际应用。
总之,QMC方法不仅为量子纠错代码的设计和优化提供了新工具,也为更广泛的量子算法和量子系统研究开辟了新途径。数字孪生技术可能正是帮助我们加速迈向实用化量子计算的关键突破。
[1]https://aws.amazon.com/cn/blogs/quantum-computing/decoding-realistic-quantum-error-syndrome-with-quantum-elements-digital-twins/
[2]https://arxiv.org/abs/2502.18929











