 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库开销骤降138倍!Q-CTRL异构架构重塑容错量子计算

随着量子计算硬件的快速发展,行业正从拥有数百个物理量子比特的系统,迈向未来十年内包含数十万甚至更多量子比特的容错量子计算系统。
然而,这一规模的扩张遭遇了重大的架构瓶颈。
Q-CTRL团队近期提出了一项革命性的异构量子计算架构Q-NEXUS及其配套的编译器Q-CHESS。这项研究不仅成功在特定基准测试中将算法逻辑错误率降低高达551倍,并将物理量子比特的开销大幅减少138倍,更在破解RSA-2048等实用级任务上展现了惊人的降本潜力。
这一突破标志着量子计算正从单纯的规模扩张走向精密复杂的系统集成。
相关研究以“Heterogeneous architectures enable a 138x reduction in physical qubit requirements for fault-tolerant quantum computing under detailed accounting”为题提交至Arxiv。

01. 量子硬件的“数量暴政”与资源闲置
在经典计算机发展史中,20世纪50年代曾出现过“数量暴政”危机,即布线和互连的复杂性随着离散元件数量的增加呈线性增长,最终促成了集成电路和异构架构的诞生。
如今,量子硬件正在面临相同的困境。在传统的单片(Monolithic)架构中,增加量子比特数量意味着控制布线、读出通道以及低温制冷负载的成比例疯狂扩张。
更为致命的是系统资源的严重浪费。Q-CTRL的分析揭示了一个惊人的事实:在执行如RSA-2048质因数分解这样的高价值算法时,每个量子比特在约96%至97%的逻辑时钟周期内都处于闲置状态。
在传统的同构架构中,这些闲置的量子比特被放置在极其昂贵、需要持续进行主动纠错(QEC)的计算硬件中,从而导致了海量的资源消耗和错误累积。
02. Q-NEXUS、Q-CHESS 的异构革命
为了解决上述问题,Q-NEXUS架构摒弃了“在单一量子比特阵列上完成所有任务”的传统思路,将系统解耦为功能专一的独立模块:
量子处理单元 (QPU):类似于经典计算机中的ALU,QPU专注于执行通用的容错量子逻辑运算。它被设计为固定且较小的尺寸(例如仅包含3个逻辑量子比特的计算核心),采用超导量子比特等能够实现微秒级快速门操作的物理媒介。由于不承担长期存储任务,这极大缓解了大型单片芯片中常见的良率和串扰问题。
量子存储器 (QM):专门用于存放闲置的量子数据,分为两级层次结构。一是静态横向量子存储器 (STQM),利用稀土离子等超长相干时间的介质,在不进行主动纠错的情况下实现短时间的低延迟数据缓冲。二是随机存取量子存储器 (RAQM),采用中性原子或捕获离子等相干时间较长的媒介,以较低的纠错频率进行高密度的长期数据存储。
量子态工厂 (QSF):专门用于高速生成和提纯非克利福德(non-Clifford)资源态(如魔术态或CCZ态),消除容错计算中的性能瓶颈。
特定应用加速器 (ASQPU):针对算法中高频出现的特定子程序(如RSA破解中的Adder加法器)定制的协处理器,可极大提升执行效率。
量子总线 (QB):利用光子通道及容错传输协议(如隐形传态或晶格手术),实现各异构模块之间的长距离数据路由和通信。
面对量子硬件的异构化带来的控制层面的微秒级时钟周期的超导QPU与毫秒级时钟周期的存储器之间存在巨大的速度鸿沟,Q-CTRL开发了微架构感知编译器Q-CHESS。
它并非将硬件视作单一的设备图,而是作为一个分布式系统来进行精确编排。
Q-CHESS能够通过插入“空闲缓冲区”以及利用乱序执行技术,完美掩盖跨模块传输的延迟,从而使系统的整体吞吐量由高速处理核心主导,而非受限于较慢的存储模块。它采用成本函数路由机制,智能判断量子态是应留在QPU中等待,还是被传送到QM中以规避闲置误差。
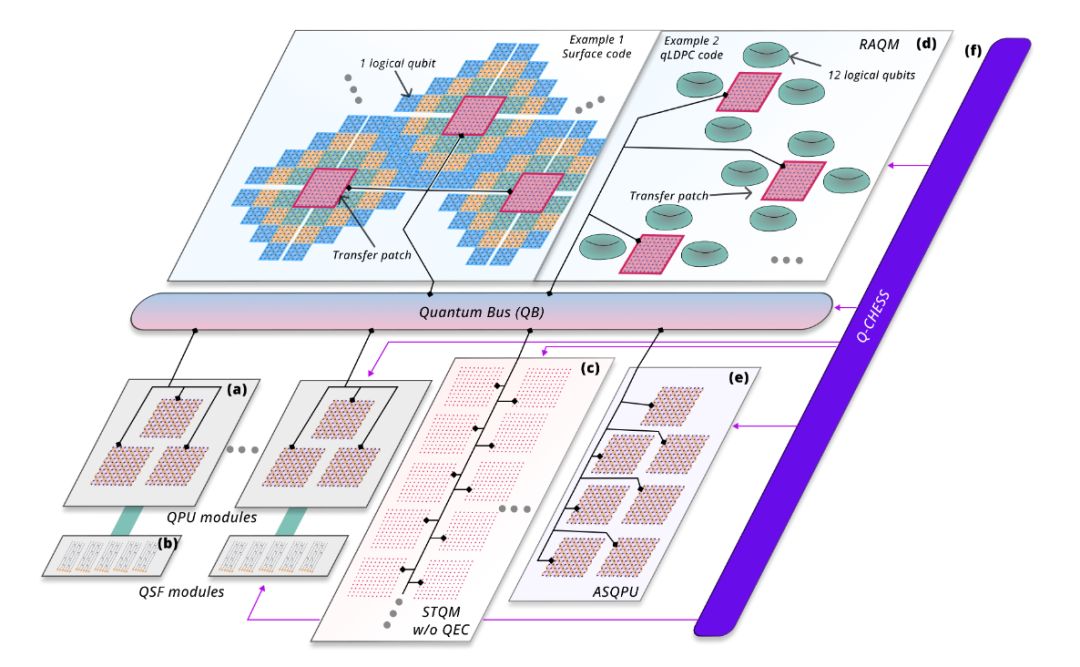
图|Q-NEXUS概览:一个由专用功能模块组成、通过互连总线连接的异构架构,其编译和执行编排由Q-CHESS提供(来源:Arxiv)
03. 极致压缩的理论极限
在将架构应用于完整实战前,Q-CTRL团队在1000个逻辑量子比特的中等规模基准测试中,测算出了该架构对特定算法和高频子程序的极限优化能力。
在运行近似量子傅里叶变换(AQFT)算法时,传统的同构基准架构需要极其庞大的表面码阵列,消耗约4914万个物理量子比特。
而在引入RAQM后,通过将闲置数据转移到更低距离的纠错码和高密度存储器中,物理量子比特的需求量被极其显著地压缩到了约35.4万个,实现了高达138倍的资源缩减。
在运行量子加法器(Quantum Adder)子程序时,Q-CHESS编译器精准识别了漫长的闲置期,并将非活跃状态的量子态“卸载”到量子存储器中,从根本上抑制了闲置引起的指数级错误暴增,测得了高达551倍的逻辑错误率降低。
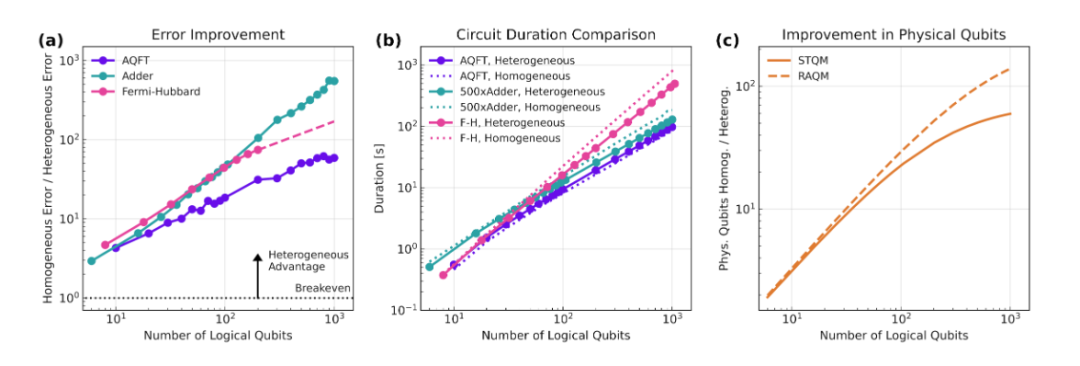
图|两种架构之间的比较。在(a)和(b)中,使用STQM作为存储器,而在(c)中,绘制了STQM和RAQM两者的数值。 (a) 保真度提升对比: 针对三种不同的量子算法(AQFT、量子加法器和二维费米-哈伯德模型动态模拟),与基准模型相比的保真度提升。 (b) 线路持续时间与算法规模的对比。 (c) 物理量子比特数量的改进:估计的物理量子比特总数取决于架构设计,而与算法类型无关。在1000个逻辑量子比特的规模下,使用STQM的改进系数达到60倍,而使用RAQM则达到了惊人的138倍。(来源:Arxiv)
04. 以极低代价攻克RSA-2048
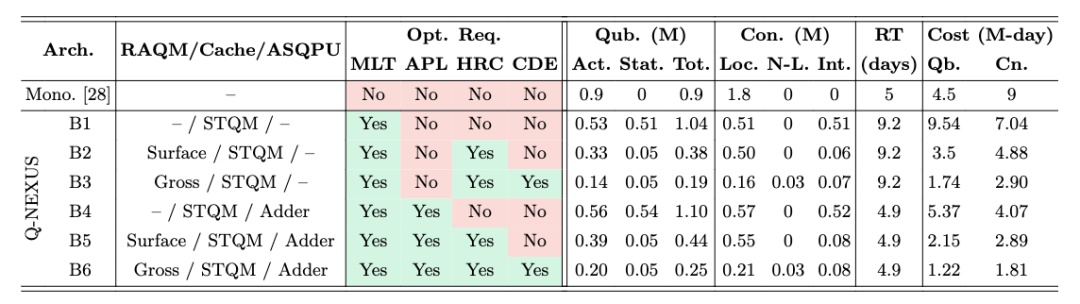
需要注意的是,138倍和551倍是特定子程序的极限优化值。当这种架构应用于结构极其复杂、包含海量混合指令的完整实用级任务时,虽然优化倍数会有所收敛,但依然展现出了决定性的优势。
在传统的同构基准模型下,破解RSA-2048大约需要100万个物理量子比特。而在Q-NEXUS异构架构下,即使仅使用实验已验证的网格拓扑结构,物理量子比特的需求量也被大幅削减至38.1万个,耗时仅需9.2天。
更为惊人的是,如果架构中引入专为Adder设计的ASQPU加速模块,虽然硬件开销小幅增加至43.9万个量子比特,但分解时间将被锐减近一半,仅需4.9天。
此外,如果未来能够实现长程耦合器并使用高密度的qLDPC码作为RAQM存储,整个系统破解RSA-2048的资源将进一步下探至19万个物理量子比特。这代表着近5倍的整体系统资源压降。
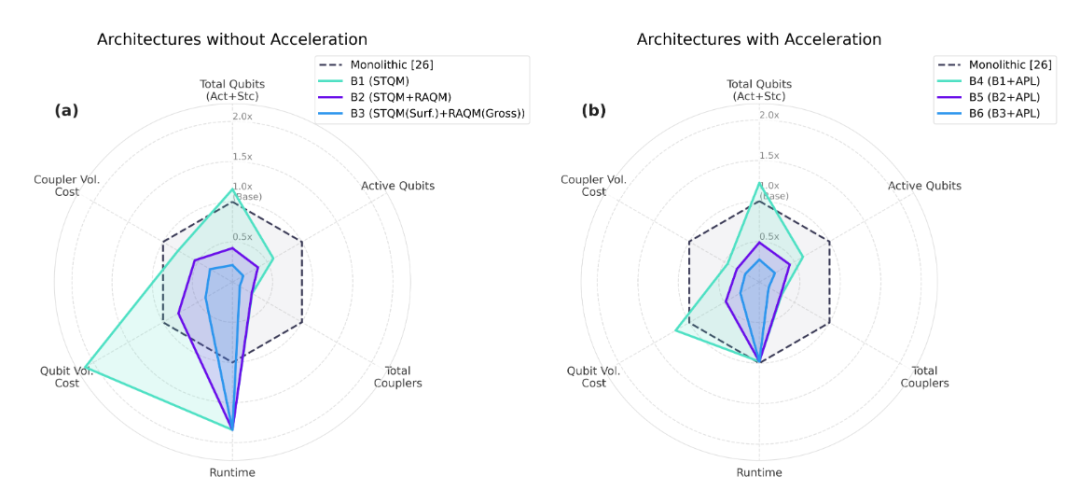
图|Q-NEXUS模块化架构的归一化性能对比。图中实心多边形代表各异构架构,黑色虚线六边形代表最先进的单片表面码基准模型(其各指标被标准化为1.0倍),突出了算法加速在推动净性能提升方面的关键作用。雷达图的径向轴代表物理硬件需求和执行指标,数值越靠近原点代表效率越高。 (a) 无算法加速的候选架构性能: B1架构仅依赖短期的STQM存储,B2架构增加了使用表面码的RAQM存储,B3架构则引入了高密度的qLDPC码作为RAQM。 (b) 采用算法加速的架构性能: 架构B4、B5和B6分别在B1、B2、B3的基础上,增加了一个专门用于加速加法器(Adder)子程序的特定应用加速器(ASQPU)。(来源:Arxiv)
05. 实现容错量子计算的新途径
Q-CTRL提出的异构量子计算架构为量子计算行业指明了新的发展方向。整个行业将不再需要寻找一个在计算速度、相干时间、可扩展性上完美平衡的量子比特。
相反,未来的量子计算机将通过整合各种物理介质的固有优势来构建:利用超导量子比特进行极速逻辑运算,利用中性原子或离子阱进行长效记忆存储。
通向实用级、具有密码学威胁的量子计算机的道路,已经从单纯的硬件规模扩展,转变为一项极具挑战的系统工程与集成任务。其中,量子总线(Quantum Bus)的稳定性和模块间通信的可靠性,将成为决定这场多模态技术革命成败的最终关键。
引用:
[1]https://arxiv.org/abs/2604.06319
[2]https://quantumcomputingreport.com/q-ctrl-proposes-heterogeneous-architecture-to-optimize-fault-tolerant-resource-requirements/

联系与爆料: Qtumist_info@163.com

延 伸 阅 读





