IBM 完成 1.2 万原子蛋白质模拟,量子计算首次逼近真实生物分子复杂度
发布时间:2026-05-07来源:量子前哨
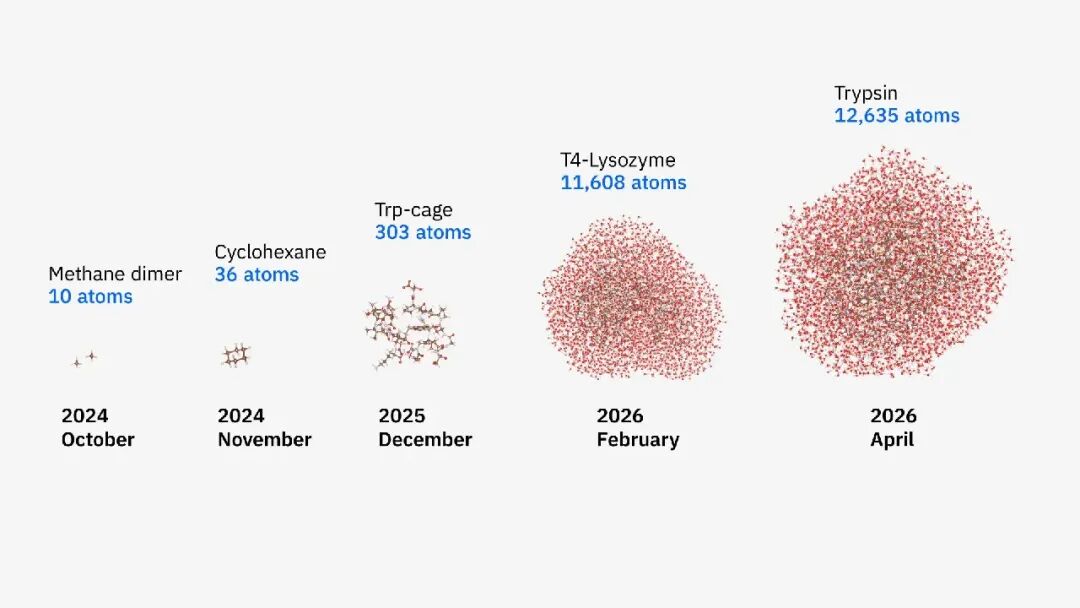
IBM、克利夫兰医学中心(Cleveland Clinic)与日本理化学研究所(RIKEN)近日联合宣布,研究团队基于“以量子为中心的超级计算”架构,成功完成了一个包含 12,635 个原子的蛋白质体系模拟,为目前已知规模最大的量子相关生物分子模拟之一。
更重要的是,此次研究不仅涉及超过 1.2 万个原子,还处理了约 30,000 个电子轨道,意味着量子计算开始接触真实生命体系中的复杂电子结构问题:研究对象包括包含 11,608 个原子的 T4 溶菌酶,以及包含 12,635 个原子的胰蛋白酶。
但真正值得关注的,并不只是规模本身。
因为这些蛋白并非孤立存在,而是被置于接近真实生理环境的水溶液中,并模拟了其与自然界中互作分子(ligands)的结合状态,标志着研究逼近现实药物研发中的真实分子环境。
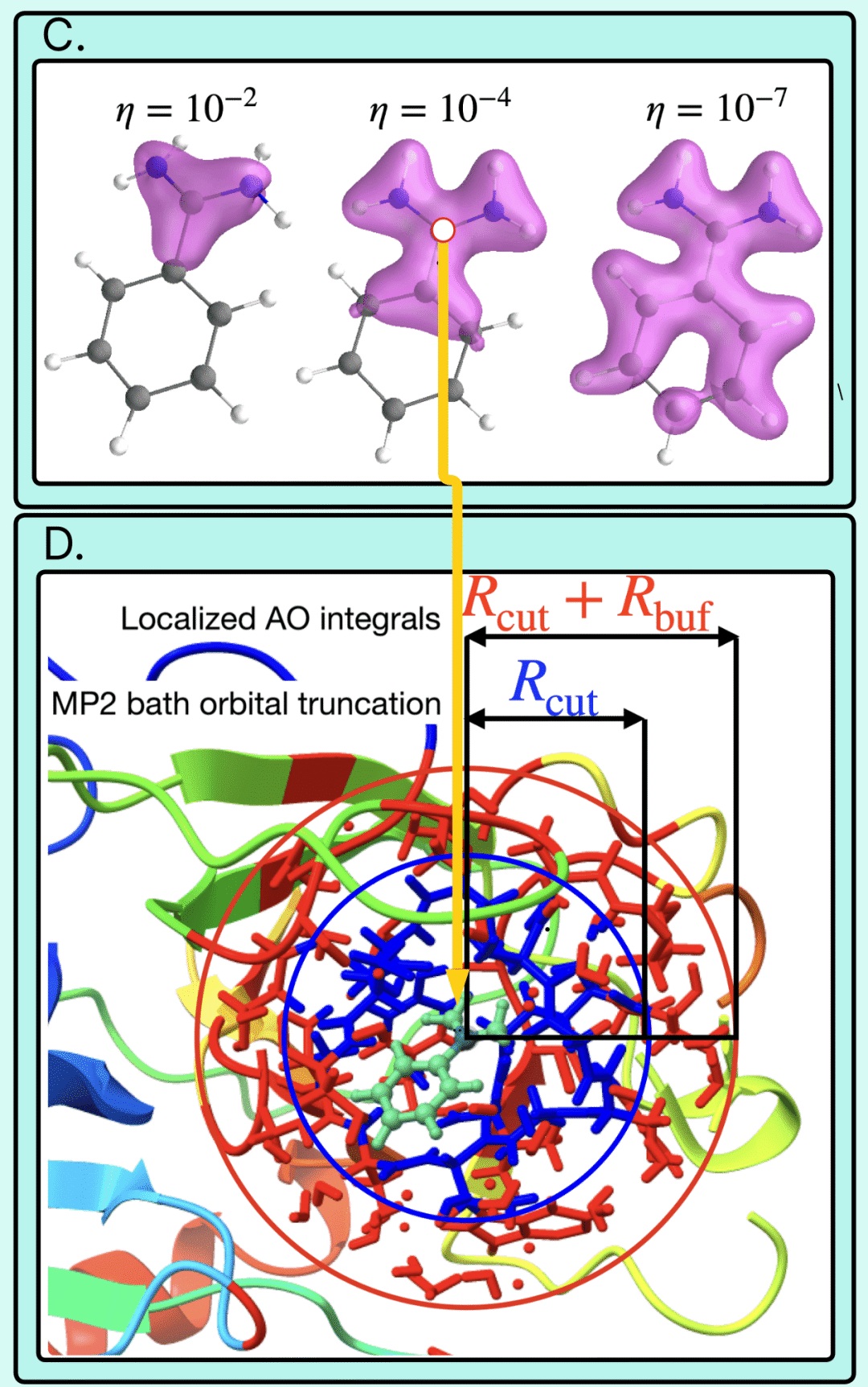
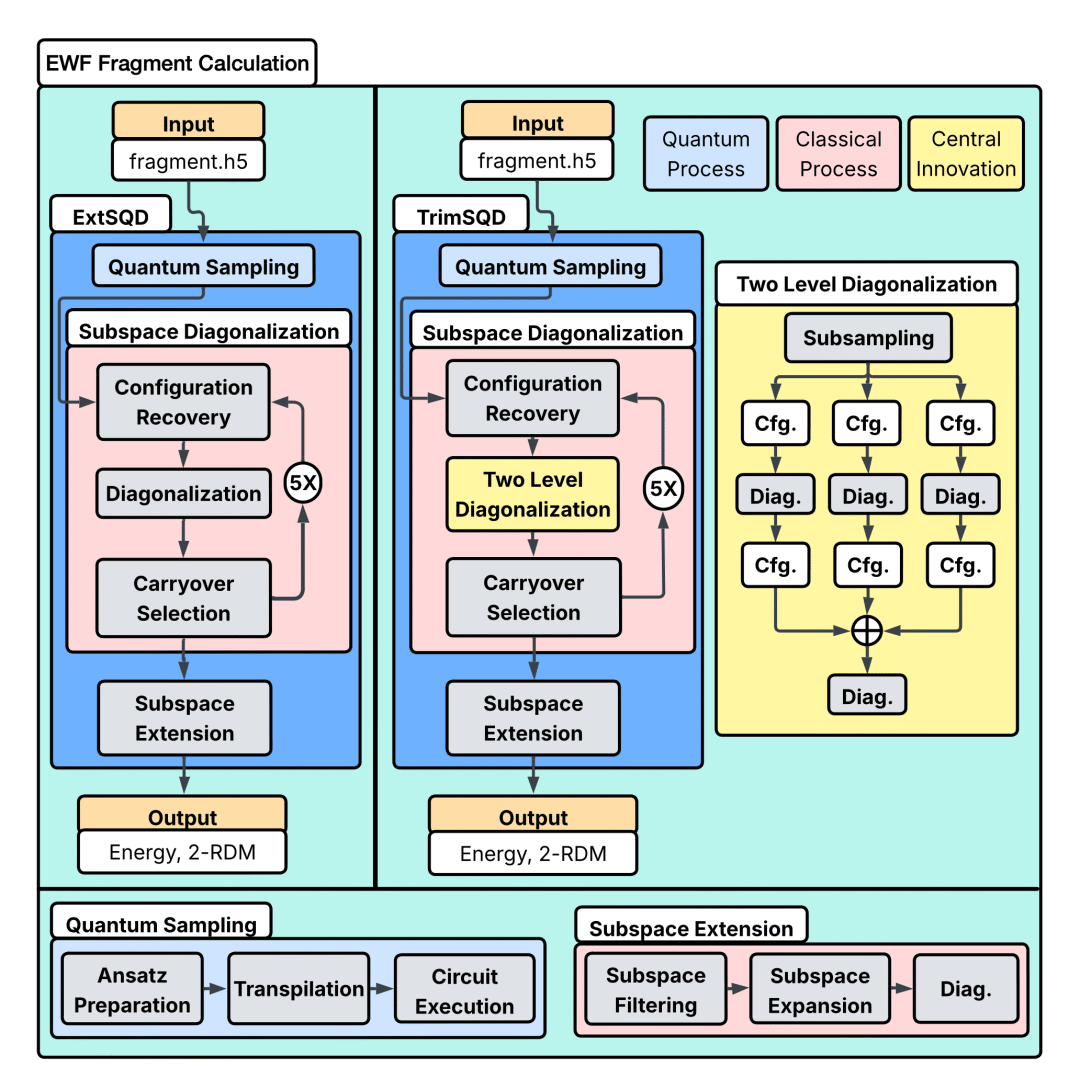
蛋白质模拟之所以困难,本质上是因为电子结构问题过于复杂。蛋白质中的化学反应、分子结合、能量变化,最终都取决于电子之间的量子相互作用。而电子结构计算的复杂度,会随着体系规模扩大迅速失控。几十个原子的体系尚且能够精确处理,一旦进入真实蛋白质尺度,经典计算方法的资源消耗便会呈指数级增长。这也是量子计算长期被视为未来关键科学工具的原因。电子本身就是量子系统,量子计算机天然适合描述电子波函数与量子态演化。从理论上说,它并不是“模拟”量子过程,而是在用另一个量子系统直接表达量子行为。但问题同样现实:今天的大部分量子硬件仍处于 NISQ(含噪声中等规模量子)阶段,量子比特有限、误差率较高,尚不足以独立完成完整的大规模科学计算。故而,一个越来越清晰的行业共识开始出现:真正可行的路线并非“量子计算机替代超级计算机”,而是两者协同。在这套“量子中心超级计算”架构中,经典超级计算机负责体系拆分、任务调度与大规模数据处理,量子处理器则专门承担最困难的电子关联问题计算。研究团队调用了部署于美国克利夫兰与日本神户的 IBM Quantum Heron r2 处理器,具体运行设备分别为 ibm_cleveland 与 ibm_kobe,并与全球顶级超级计算平台协同运行,包括 RIKEN 的“富岳”(Fugaku)以及东京大学和筑波大学运营的 GPU 超算 Miyabi-G。而真正体现“量子中心超级计算”精妙之处的,并不只是量子处理器本身,而是不同计算体系之间的任务拆分。量子处理器负责生成与采样复杂量子态,Fugaku 与 Miyabi-G 则承担了对子空间数据进行对角化(diagonalizing)的任务,通过 GPU、CPU 与 QPU 之间的深度协作,完成整个混合工作流。这意味着,量子计算真正被嵌入现实科研体系之中。某种意义上,这比单纯提升量子比特数量更重要,因为行业竞争的重点正在发生变化。过去,量子公司比拼的是量子比特、相干时间与门保真度;而现在,真正决定科研价值的,开始变成谁能建立完整的软件栈、经典—量子协同架构,以及适配真实问题的系统级能力。真正让这项联合研究工作跨越“实验展示”阶段的,还有其背后的工程与算法突破。此次研究中,团队在关键计算环节中动用了多达 94 个量子比特,运行了约 9200 个量子线路、近 6000 次量子操作,整个任务持续超过 100 小时,并累计收集 13 亿次测量结果。这已经成为目前资源消耗最庞大的量子化学执行任务之一。而更深层的突破,其实发生在经典计算瓶颈上:研究团队采用了一种名为 EWF-TrimSQD 的新型混合算法。首先,EWF(Embedding Wave Function)方法利用电子相互作用的“局域性”特征,将复杂分子拆分为多个可处理“碎片”。相比之下,传统 EWF 方法本身存在严重计算瓶颈:为了构建碎片环境(Fragment bath),通常需要进行 MP2(二阶莫勒-普雷塞特扰动理论)计算,而 MP2 资源消耗会随着分子规模增长迅速失控:分子规模翻倍,资源需求可能增加约 25 倍。通过改进基于波函数的嵌入技术(EWF),令其仅考虑那些最重要的局部相互作用,可使在胰蛋白酶这种规模上实现该算法变得切实可行。图源IBM团队通过引入线性缩放方法(Linear-scaling methods),成功绕开了这一经典计算瓶颈,使系统规模首次能够进入上万原子级别。随后,TrimSQD(修剪样本化量子对角化)则进一步剔除大量无效计算,从海量电子构型中筛选出真正影响能量状态的关键部分。研究团队将这一过程形象地比喻为筛除“deadwood(枯木)”,保留“livewood(活木)”,这一说法源自理论化学家 Klaus Ruedenberg 提出的理论化学语境。TrimSQD 能够更精准地识别出量子计算机需要重点关注的“有用碎片”(即显著影响能量状态的电子构型),原理是将搜索区域划分为多个子空间,从而可以对每个子空间进行独立搜索。图源IBM这种方法的价值在于,它并没有试图“暴力求解”整个蛋白质,而是在经典计算与量子计算之间建立一种新的分工机制,恰好符合当下量子计算最现实的发展路径。相比四个月前 IBM 模拟的 303 原子 Trp-cage 微型蛋白,此次系统规模已经扩大约 40 倍,关键工作流精度提升约 210 倍。IBM 指出,这项工作虽然展示了量子计算作为科学工具的现实潜力,但目前尚未真正超越最先进的纯经典计算方法。换句话说,这并非是聚焦“量子优越性”的证明,更像是一次关于未来科研体系形态的提前演练。这恰恰可能比“量子优越性”本身更重要。IBM 这次证明的并不是“量子计算已经比经典计算更强”,而是量子计算已经值得被纳入现实科研工作流。前者是性能竞赛,后者则意味着一种新基础设施开始获得资格。这项成果最深层的意义,并不只是“1.2 万个原子”。从产业视角出发,我们不难看出,面对行业长期存在的困境,量子计算如今的脱身姿态越来越明显:它过去总在证明自己“未来可能很强”,却始终难以真正参与现实世界。它本身就是药物研发、生命科学与材料科学最核心的问题之一,药物如何与蛋白结合、酶如何催化、分子如何发生反应,都直接决定新药研发效率与材料创新速度。长期以来,药物开发最大的瓶颈之一,就是人类无法提前准确预测这些分子行为,很多候选药物需要经过漫长实验筛选,致使研发周期往往长达十年以上,且成本极其高昂。如果未来能够更精准地计算蛋白质电子结构,就意味着科研人员有机会在实验之前提前预测药物行为,从而缩短研发周期、降低失败率,并重新定义药物开发流程。而 IBM、RIKEN 与克利夫兰医学中心此次展示的,也已经不再只是药物研发路线。研究团队明确提到,这套混合工作流未来同样可以迁移至材料科学、酶催化,以及能源与基础设施相关的大规模化学计算场景。这项工作的背后,体现出量子计算正在成为一种全球科研基础设施。此次整个项目由美国与日本研究团队联合完成,并获得日本 NEDO(新能源产业技术综合开发机构)以及日本文部科学省相关项目支持。无论是硬件稳定性、误差纠正,还是系统调度能力,距离真正的大规模产业化仍有很长距离。IBM 也明确将未来路线指向预计于 2029 年前后推出的容错量子系统“Quantum Starling”。只是,比起过去执着于“什么时候超越经典计算”,今天的量子行业显然走向的是另一条更现实的道路。
1、https://newsroom.ibm.com/2026-05-05-cleveland-clinic,-riken,-and-ibm-model-a-12,635-atom-protein-the-largest-known-to-be-simulated-with-quantum-computers2、https://www.ibm.com/quantum/blog/cleveland-clinic-riken-chemistry
WAIC 2025 对未来智能的深刻拷问:从辛顿的 AI 洞见,到玻尔兹曼机的量子新生
海外量子股狂热上涨!产业、生态齐发力,一场全球 AI+ 量子算力融合战已打响
10 亿澳元投光量子路线!史上最全面分析澳大利亚政府为何最爱 PsiQuantum
量子计算“拐点”已至!英伟达的未来不止GPU,黄仁勋指向了一个新“Q”
播客访谈实录|量子计算今天就已经能够为客户创造可量化的商业价值
光子芯片新时代即将到来!专访上海交通大学陈险峰教授
移动正谋划一盘量子计算的大棋?中国移动集团级首席专家钱岭谈算力网络
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库