五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库北京量子院、清华大学龙桂鲁教授团队联合移动云提出神经预解码器观象,模型参数量仅为英伟达的30%!

要让量子计算机真正可用,每秒钟都要纠正成千上万次错误——而留给纠错的时间,只有微秒级。为了解决这个问题,近期,北京量子信息科学研究院、清华大学龙桂鲁教授团队与移动云联合提出面向大规模量子纠错的神经预解码器系列模型——观象(Quantispect Neural Pre-Decoder),延续神经预解码的技术路线,在保留后端匹配解码器结构化优势的前提下,通过前端快速、高质量的错误分布估计,在逻辑错误率、推理速度、模型规模与后处理延迟四项关键指标上形成协同优化。
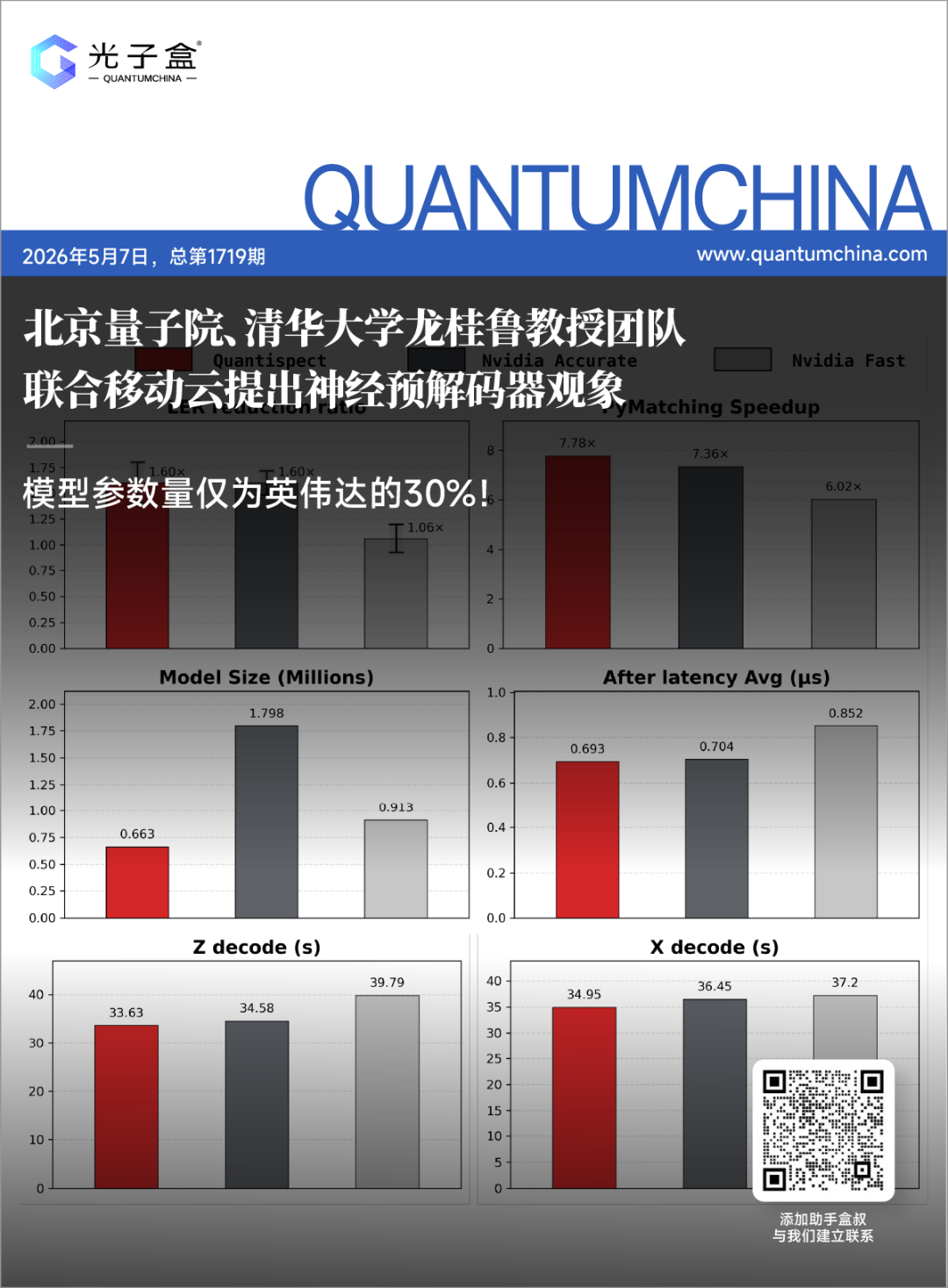
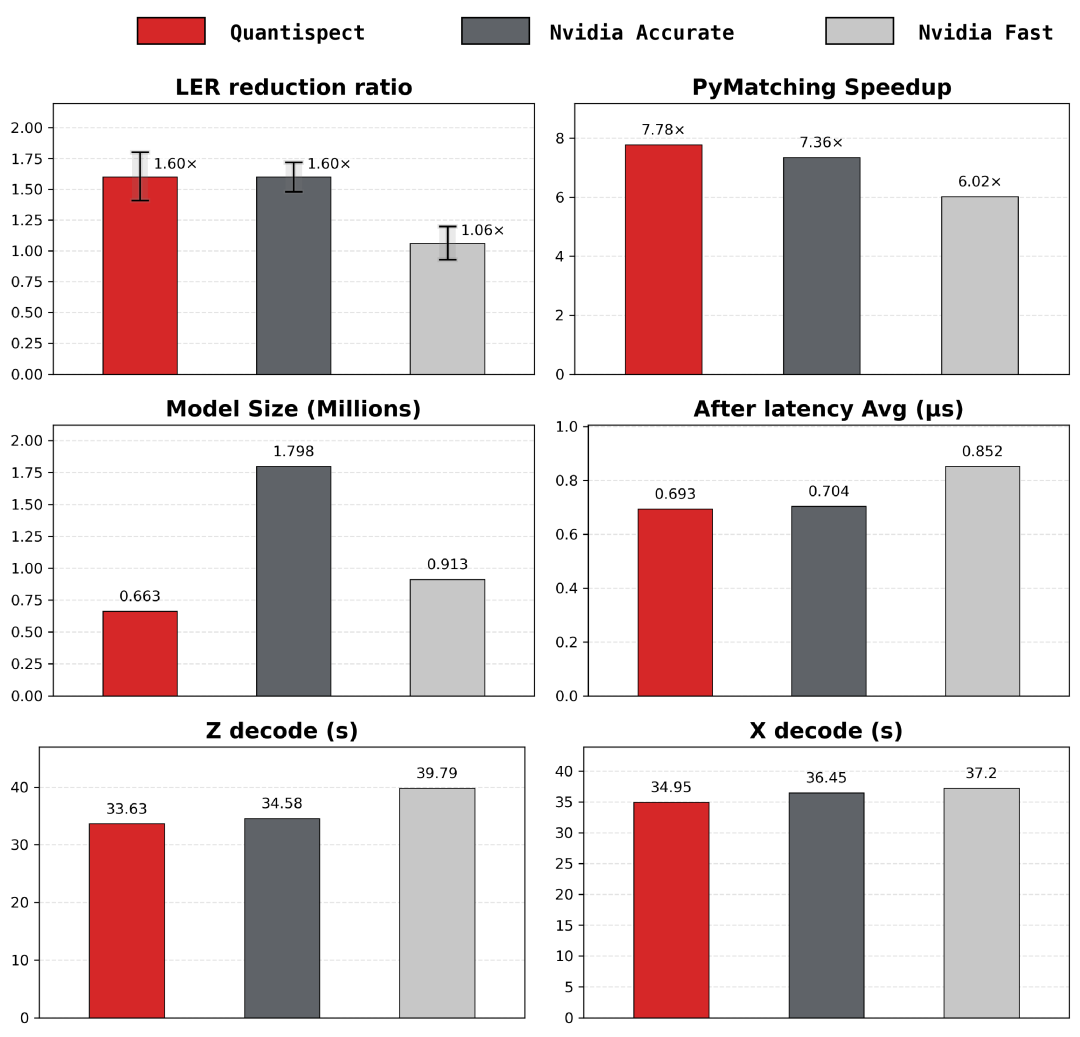
具体而言,在统一的8卡A100服务器环境下,“观象”将逻辑错误率相比传统方法降低约1.60倍,整体推理加速最高达7.78倍,模型参数量仅为0.663 M(约为英伟达的30%),平均后处理延迟约0.693 μs。模型现已上线Hugging Face。

解码延迟:大规模表面码纠错工程化的核心瓶颈
在标准表面码纠错流程中,量子电路运行后,系统通过辅助量子比特的重复测量获得错误综合信息,再经由经典解码器基于最小权完美匹配等方法推断最可能的错误链,并据此更新泡利框架或执行相应纠正;随着量子比特规模扩大和纠错循环频率提升,解码过程须在毫秒量级内持续完成,传统解码方法面临的实时性压力持续加剧。
引入神经网络后,神经预解码器作为前端模块先对错误综合信息的历史变化与噪声特征进行快速估计,形成初步错误判断,再将结果传递给后端匹配解码器完成最终推断,兼顾神经网络对复杂时空相关错误的学习能力与传统结构化方法的稳定性。英伟达(NVIDIA)开源的Ising Decoder系列模型已沿这一方向将AI与物理启发建模相融合,代表了该技术路线的阶段性进展。“观象”在AI方法与物理启发建模融合的基础上,进一步面向工程部署约束优化资源消耗,探索了更具实用价值的低延迟解码路径。

架构:三分支三维卷积神经网络融合空间局域性、时间相关性与物理先验
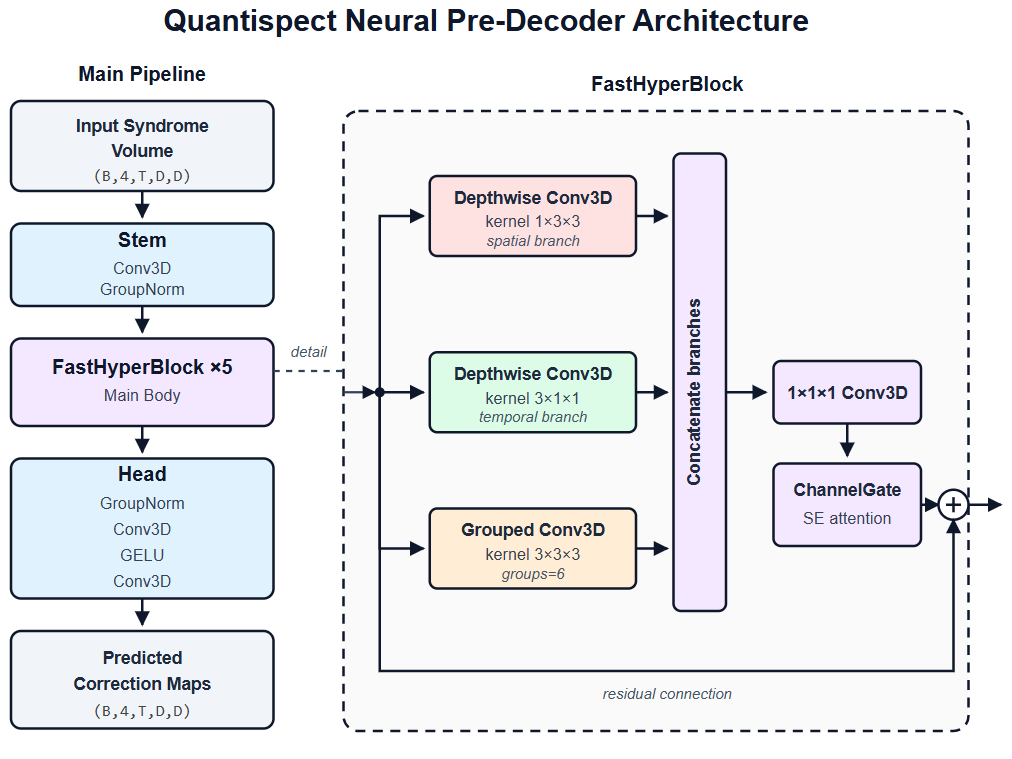
观象的创新点主要是利用一种面向量子纠错时空结构优化的三维卷积神经网络,模型输入为形状(B, 4, T, D, D)的五维张量——B为批量大小,T为纠错轮次时间维度,D为与码距相关的空间尺寸,四个输入通道同时编码X/Z错误综合信息及其先验信息,将空间结构、时间演化与物理先验统一编码至同一输入表示。
模型主体由多个快速超块(FastHyperBlock)堆叠构成,每块采用三分支结构:空间分支以1×3×3深度卷积刻画同一纠错轮次内错误综合信息在二维码面的空间传播;时间分支以3×1×1深度卷积捕捉相邻轮次间的时间相关性;混合分支以3×3×3分组卷积建模空间维度与时间维度之间的跨维耦合关系,三条分支在结构层面引入明确的归纳偏置,使模型贴合表面码错误在时空格点上的传播规律。
通过深度卷积与分组卷积压缩计算复杂度,这种结构化设计使”观象“在0.663 M(约为英伟达的30%)参数规模下同时保留对空间局域性、时间相关性与跨维耦合的建模能力。轻量结构,工程优先。

性能:四项指标协同优化,推理加速最高达7.78倍
在统一的8卡A100服务器环境下,观象围绕纠错性能、解码效率、模型规模与后处理延迟进行了系统评测(各项取多次测试均值;英伟达开源模型在本测试环境下的实测性能优于官方宣传口径)。
纠错性能方面,观象的逻辑错误率相比基线方法降低约1.60倍,说明前端神经预解码器能有效提升对错误综合信息背后错误分布的刻画精度,为后端匹配解码器提供更可靠的错误初判,而非仅压缩计算流程。
解码效率方面,X/Z基底解码时间分别降至约34.95 s与33.63 s,整体推理加速最高达7.78倍;对于需要伴随纠错循环持续运行的表面码纠错系统而言,推理速度的改善直接关系到系统能否进入实时工程闭环。
此外,平均后处理延迟约0.693 μs,进一步提升了其在端到端量子纠错系统中的实际部署价值。四维指标协同优化,为大规模低延迟量子纠错提供了更具工程可行性的神经预解码方案。

工程意义与未来方向:
AI、物理信息模型与匹配解码三路融合的解码体系
观象”在四维指标上的协同优化,体现了AI for AI的模型设计思路,即由大模型辅助分析解码器瓶颈并指导网络结构改造,面向工程现实实现更高效的智能设计。改成观象”在四维指标上的协同优化,体现了AI辅助模型结构优化,实现更高效的智能设计。
模型现已开源,可访问Hugging Face查阅详情。
模型参考:
https://huggingface.co/quantispect/QuantiSpect-V1