 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库IBM团队首次实现高速率量子LDPC码与代数码级联,杀入teraquop区间


关注并熟悉IBM路线图的朋友,肯定听过gross码([[144,12,12]]双变量自行车码)。它用144个量子物理比特存12个量子逻辑比特,编码效率极高。
但是,在优势突出之余,其也存在缺点。逻辑比特之间错误高度相关,如果一个模块出错,那么,它里面的12个量子逻辑比特可能就全“坏”了,这就导致传统表面码的拼接方式失去效果。
近日,IBM Quantum团队在预印本平台arxiv发表题为“Concatenating Algebraic Codes over High-Rate Quantum LDPC Codes”(高速率量子LDPC码上的级联代数码)的研究论文。研究团队将代数外码连接到高速量子LDPC内码上,并证明该组合可以在操作相关的错误率下工作。
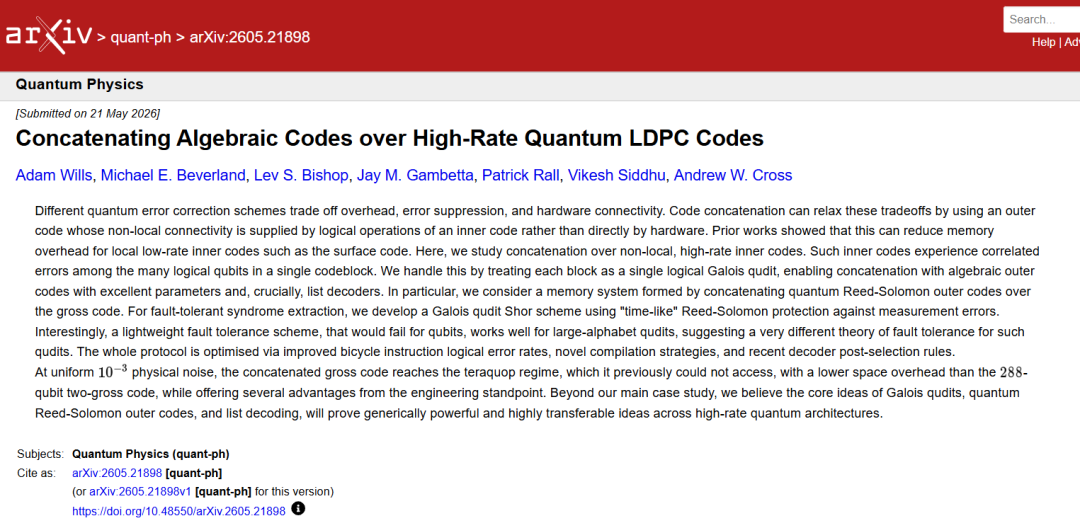
通俗来说,就是把两种不同性质的量子码叠加起来,不仅可以控制物理比特数量,又可以降低逻辑错误率。这也是之前研究领域从未尝试过的研究方向。
本研究使用[[144,12,12]]双变量自行车“gross”代码,即IBM模块化自行车架构核心的相同代码,并将其包装在量子里德-所罗门外码。在10⁻³物理噪声下,级联系统达到teraquop状态(可以理解为操作错误率需要低至10-12),这是独立总代码无法达到的阈值。与较大的288量子比特“two-gross”代码相比,它的空间开销更低,逻辑错误率低至4.10×10⁻¹⁵。
当然,上述成果并不局限于IBM硬件。伽罗瓦量子、量子里德-所罗门外码和列表解码的核心思想可以转移到任何高速量子纠错方案。

表面码太贵,LDPC码太难连
量子纠错应该是我们比较熟悉的技术之一。其中,表面码是目前最成熟的纠错方案之一,它对硬件连接要求低,只需要近邻相互作用就可以。不过,其虽连接要求低,但开销是巨大的,一个逻辑比特需要上千个物理比特来保护,这很难实现实用化量子计算机。
量子LDPC码则是另一个不错的选择。它具有极高的编码效率,理论上可以用更少的物理比特实现同样的纠错能力。更直观来看,与表面码相比,它能在同样物理比特数下编码10倍以上的逻辑比特,且具备不错的距离和阈值。
但是,LDPC码的硬伤在于,它们天然就需要长程连接。在超导硬件里,这种跨芯片的长程连接不光难做,而且会拖慢速度。同时,单个码块内部的逻辑量子比特会出现强关联错误,成为阻碍LDPC码与外码结合的因素之一。
那么,有什么办法可以把两者的优点结合起来呢?这里的连接编码不失为一个好办法。
具体表现为,我们可以在底层用一个更容易工程实现的码,比如表面码或者像gross码这种连接需求相对可控的LDPC码,在顶层再叠一个高速率的代数外码。底层负责处理局域错误,顶层负责处理那些跨块的关联错误。

把12个逻辑比特打包成一个“超级比特”
本研究引入了伽罗瓦量子多维态(Galois qudit)这一数学工具。
上述提到的方案核心技巧之一,就是把一个gross码块里的12个逻辑比特中的11个(留一个作辅助)打包成一个高维量子态。这个高维量子态的状态空间是GF(211)(伽罗瓦域),共2048个态。
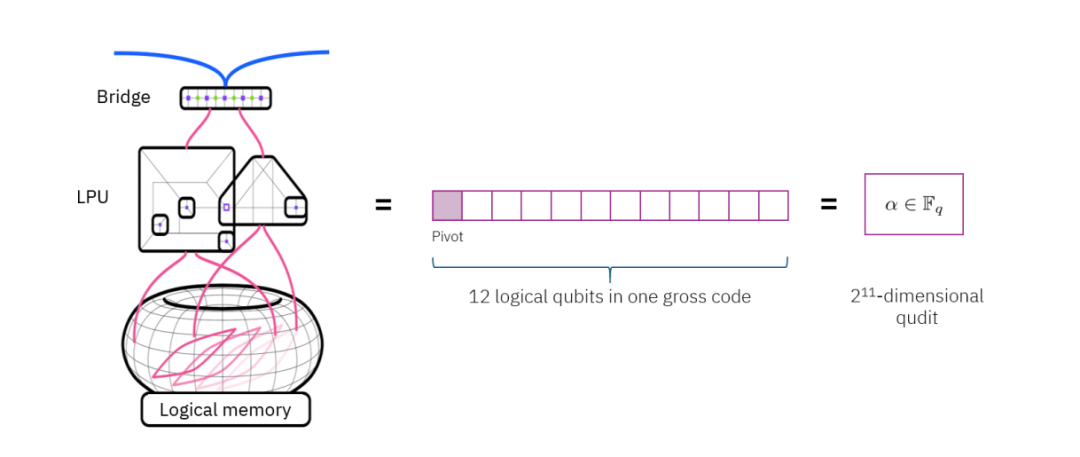
图:将一个gross码块内的12个逻辑比特进行分工
基于此,错误的衡量单位就从一个物理比特变成一个码块。比如,外码的距离等于6,就意味着至少要有3个不同的gross码块同时出错,才会导致整个系统纠不过来。
在打包好的量子多维态之上,外码选用量子里德-所罗门码(Reed-Solomon码)。
这类码的参数[[n,n−2(d−1),d]]2048满足量子单例界限,对于任何给定的距离,它们在信息理论上都是最优的。此外,它还支持大字母表下的列表解码。也就是说,在大字母表量子多维态体系中,绝大多数超过半纠错距离的随机错误依然可以被高概率纠正。
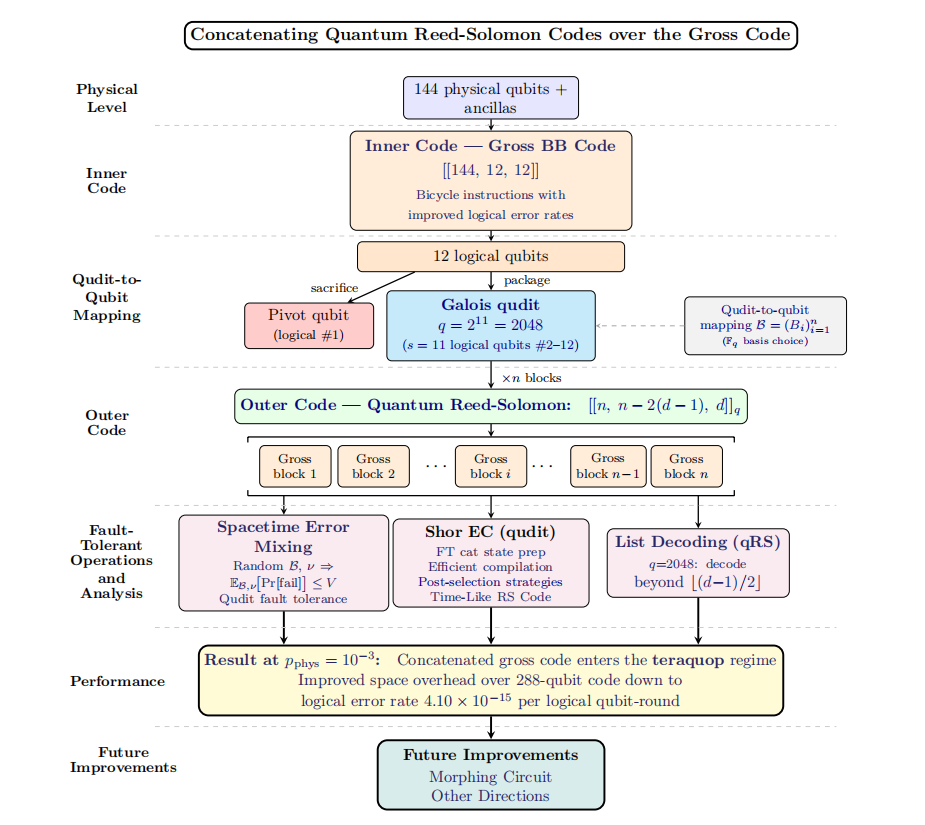
图:方案与分析的“零件”概览
这里的“大字母表”指的是每个量子比特有2048种可能的状态,而不是普通量子比特的2种。字母表一大,随机错误就很难恰好凑成那些不可纠正的模式。
用论文里的例子说,在距离为6的码上,一个随机的权重3错误变成不可纠正的概率大约跟n³/q²成正比,当q远大于n时,这个概率小得可以忽略。

猫态制备与“类时间”保护
有了外码和内码的框架,下一步就是进行综合症提取。该团队开发了一种适用于伽罗瓦量子多维态的Shor式纠错方案。
研究人员先离线制备“qudit cat states”并使用它们来测量外部代码的稳定器。
cat state本身也是由gross码的逻辑比特构成的,制备过程要容错。该团队设计了一套方案,先非容错地快速制备,再用多轮容错测量去检验。如果哪次检验发现不对,就扔掉重来。这套流程里还用上了后选择策略——解码器觉得某个结果“可疑”就直接丢弃,相当于用时间换精度。
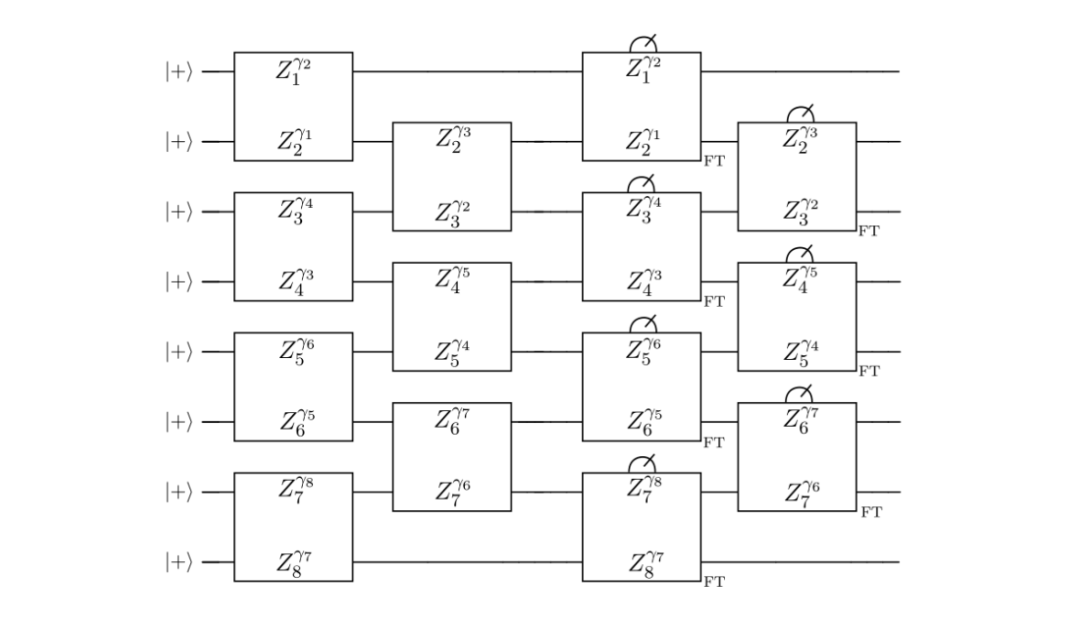
图:量子比特cat state的容错制备与校验电路
此外,为了防止测量错误,研究人员测量稳定器的超完备基础并检查一致性,使用“类时间”里德所罗门码来检测故障。

理论上的“混合参数”和实际中的性能
这里有一个很现实的问题,研究团队无法精确知道gross码上每一种逻辑错误的发生概率,但他们能知道总体的逻辑错误率。
研究人员将量子比特到量子比特的映射视为自由参数。通过对这些映射进行均匀随机选择,研究表明,每个量子比特上的错误分布变得均匀。然后,研究人员可以仅使用他们可以测量的聚合统计数据(例如空闲总代码的总逻辑错误率)来限制故障概率,而不是使用他们无法测量的完整错误分布。
这是一种证明技术,而不是协议要求。在具有实时解码功能的真实硬件上,我们可以访问有关错误分布的更详细信息,并可以做出更有针对性的映射选择。混合参数保证了无论实际的误差分布如何,总是存在好的选择,并且随机搜索将很快找到它。

进入teraquop区间,比two-gross还省空间
实验结果表明,在均匀10⁻³物理噪声下,不连接的话,普通的gross码根本无法进入teraquop区间(一般认为是每个逻辑量子比特轮错误率10⁻¹³到10⁻¹⁵)。但连上量子里德-所罗门码外码之后,它完全可以进入teraquop区间,且在逻辑错误率低于4.10×10⁻¹⁵时,空间开销比two-gross码还小。
这里说的空间开销是每个逻辑量子比特占用多少物理量子比特。在10⁻³噪声下,最优方案基本不用后选择,因为制备cat state本身已经很慢了,再用后选择只会让闲置时间更长。但在10⁻⁴噪声下,后选择就变得非常关键——用了之后逻辑错误率能直接压低两到四个数量级。
研究还对比了一维和二维轭式表面码。虽然二维轭式表面码在极低错误率下空间开销更优,但它的逻辑算子散布在两个维度上,读写都很慢,只适合做“冷存储”。而这套连接gross码的方案布局跟一维轭式表面码一样,逻辑信息更容易访问,在实用场景里反而更有优势。
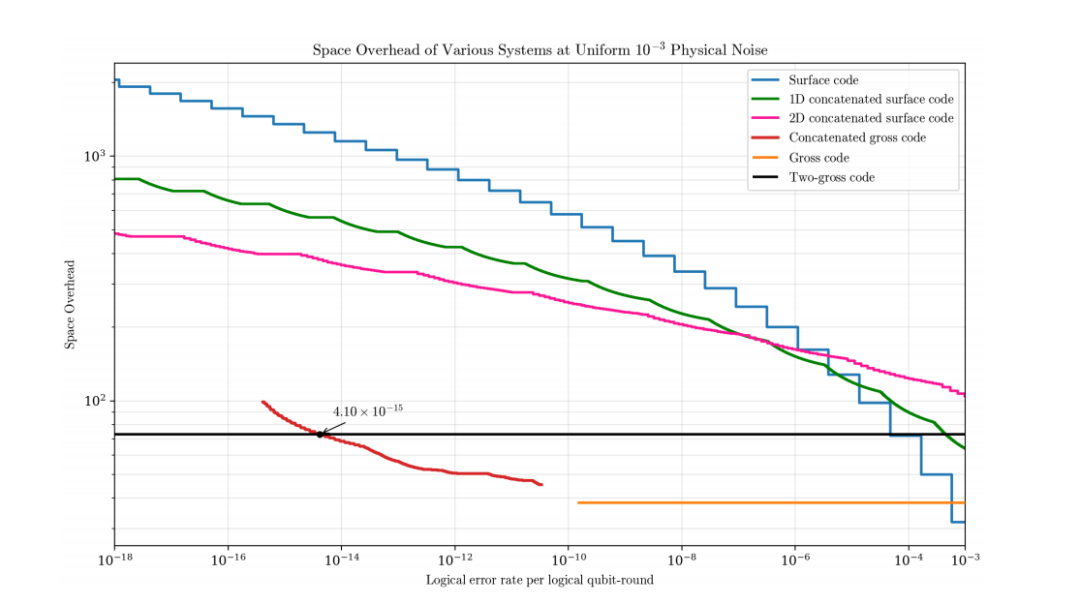 图:不同纠错方案的空间开销对比(物理量子比特上限50万个)
图:不同纠错方案的空间开销对比(物理量子比特上限50万个)
研究团队还试了一个基于morphing技术的改进版闲置电路,把idling的逻辑错误率从10⁻⁸.⁸压到了10⁻¹¹量级。如果未来能把手术指令也升级到同样水平,空间开销还能再降一个数量级。

不只是gross码,这条路可以走得更远
IBM研究团队的价值不只是一个具体的gross码内存方案。研究真正告诉我们的是,伽罗瓦量子比特+代数外码+列表解码这套组合拳,可以移植到很多高速率架构上。尤其是大字母表带来的容错特性——很多在量子比特上行不通的轻量级方案,放到量子比特上反而效果很好。
这也启示我们,量子比特的容错理论可能需要重新思考,不能简单套用量子比特的那套东西。
当然,离真正的容错计算还有距离。目前这个方案只做了内存,要扩展到通用计算,还得解决外码周期慢、提取器设计、软信息利用等一系列问题。但至少,这个方向给出了一条在有限硬件资源下压低逻辑错误率的可行路径。
[1]https://arxiv.org/abs/2605.21898
[2]https://postquantum.com/quantum-research/ibm-concatenated-gross-code-teraquop/










