 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库小米 MiMo-V2 三张牌:1T 参数旗舰、全模态 Omni、情感 TTS,分别在解决什么

上周,OpenRouter 上悄悄出现了两个没有任何介绍的匿名模型:Hunter Alpha 和 Healer Alpha。没有宣发,没有官方认领,只有调用量在持续攀升——多天冲上日榜前列,开发者社区开始炸锅。
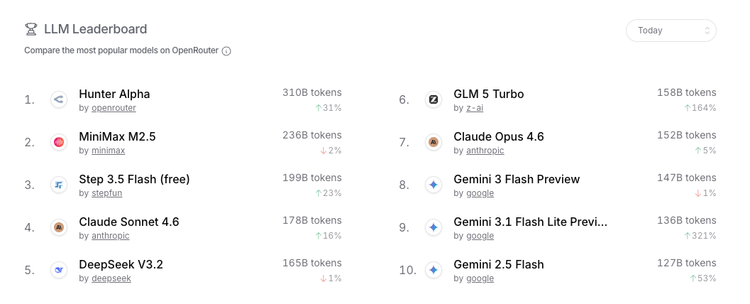
有人猜这是 DeepSeek V4,参数规格高度吻合,连 OpenClaw 创始人 Peter Steinberger 也忍不住在 X 上公开发帖打听身份。
3 月 19 日凌晨,谜底揭晓:Hunter Alpha 是 MiMo-V2-Pro 的早期测试版,Healer Alpha 是 MiMo-V2-Omni 的早期测试版。两个模型的主人,是小米。

当天,小米 MiMo 官方同步正式发布三款新模型:MiMo-V2-Pro、MiMo-V2-Omni、MiMo-V2-TTS。只看名字可能会觉得这又是一轮常规迭代;把三者放在一起看,小米这次真正想讲的是"我已经开始搭一整套 Agent 能力底座"。官方给 Pro 的定位是旗舰基座模型,给 Omni 的定位是全模态 Agent 模型,给 TTS 的定位是给 Agent 补上"声音、情绪和表达力"。三个模型覆盖了从"大脑"到"感知与执行"再到"输出层"的完整链路。
MiMo-V2-Pro 负责想,MiMo-V2-Omni 负责看、听、做,MiMo-V2-TTS 负责说。 这波发布最值得看的,也正是这条清晰的路线:小米在把 AI 从"对话框里的回答机器",往"能调用工具、理解界面、处理真实任务、自然表达"的系统层智能体方向推进。
一、MiMo-V2-Pro:对标 Claude 去的 Agent 旗舰,偏偏只卖五分之一的价
先看 MiMo-V2-Pro。按照官方说法,这是面向真实世界 agentic workload 的旗舰基座模型,目标是去完成任务。模型总参数超过 1T,激活参数 42B,支持 1M token 上下文;架构上延续上一代 Hybrid Attention,混合比例从 5:1 提升至 7:1,同时保留轻量级 MTP 层以提升生成效率。官方强调的关键词很明确:complex workflows、production engineering tasks、tool-call stability、multi-step reasoning。
跑分上,MiMo-V2-Pro 是这次三款里官方公开数据最完整的。小米在官方页直接标注:按 Artificial Analysis Intelligence Index,MiMo-V2-Pro 全球第 8、中文大模型第 2。
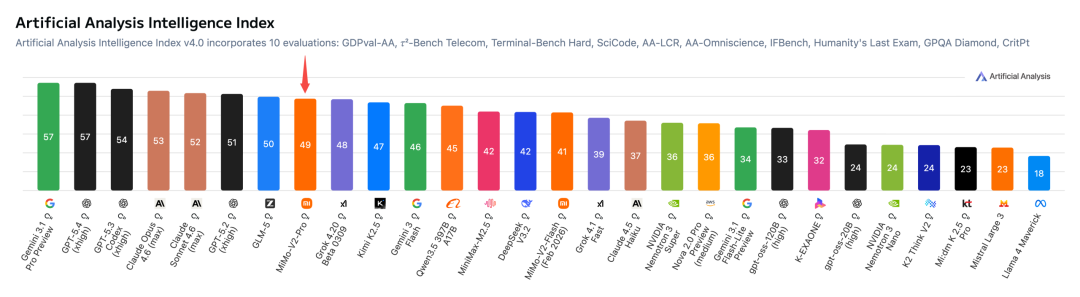
Agent 相关 benchmark 上,它在 PinchBench 拿到 84.0,在 ClawEval 拿到 61.5,两项均为全球第 3,官方明确标注"接近 Claude Opus 4.6"。对照数据:PinchBench 上 Claude Sonnet 4.6 为 86.9、Claude Opus 4.6 为 86.3、Gemini 3 Pro 为 70.7;ClawEval 上 Claude Opus 4.6 和 Sonnet 4.6 均为 66.3,Gemini 3 Pro 为 51.9,GPT-5.2 为 50.0。这两个评测考的是工具调用、多步规划、复杂任务链上的稳定性——Agent 场景里最核心也最难做的部分。MiMo-V2-Pro 在这个维度上,已经和 Claude Opus 4.6 基本站在同一梯队。
验证方式上,小米没有只放几张实验室对比图。Hunter Alpha 在 OpenRouter 上跑了一周盲测——总调用量超过 1T tokens,多天登顶日榜。官方展示的调用来源几乎全是 coding/agent 工具,尤以 OpenClaw、Kilo Code、Roo Code 为主。开发者对它的感知,从一开始就落在"能干活"上。
案例上,官方给了两个方向。一个是前端开发:在 OpenClaw 里,MiMo-V2-Pro 可以根据一条 prompt 直接生成完整网页,官方展示的例子是一个 90 年代印刷杂志风格的网页,版式、字体、噪点和翻页感这些细节都有覆盖。
用同样的提示词在 MiMo Claw 实测了一下,生成的网页有目录交互、完整页面元素、整体排版也算得上美观,图片渲染稍有瑕疵,但完成度已经相当不错。
不到三分钟,一次性生成的版本,无抽卡
另一个官方案例更直接:让它做一个 3D 塔防游戏,要求使用 Three.js 或 Babylon.js,实现 3D 渲染、关卡模式、敌人波次、升级路径、动态背景和完整控制逻辑。官方想传达的很清楚——这个模型瞄准的是端到端工程交付,代码补全只是其中最基础的一层。
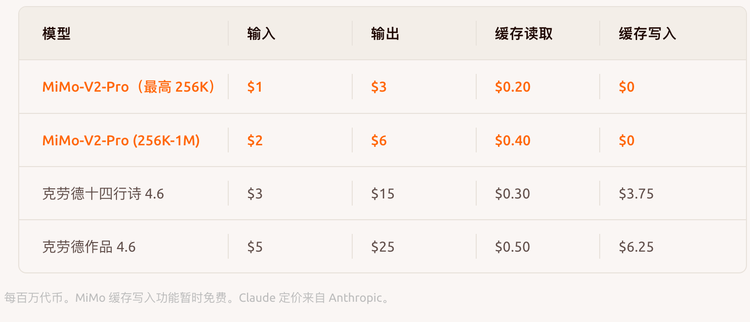
价格是 MiMo-V2-Pro 另一个值得单独说的点。官方页把 API 价格和 Claude 4.6 系列并排列出:256K 以内,输入/输出分别为 $1/$3 每百万 tokens;256K 到 1M 为 $2/$6。 Claude Sonnet 4.6 是 $3/$15,Claude Opus 4.6 是 $5/$25。同等 Agent 能力梯队,价格约为五分之一——这个价差对大规模调用的 agent 框架来说,是实质性的成本差异,也是小米最直接的市场切入点。
二、MiMo-V2-Omni:感知与行动原生绑定,最有想象空间的那款
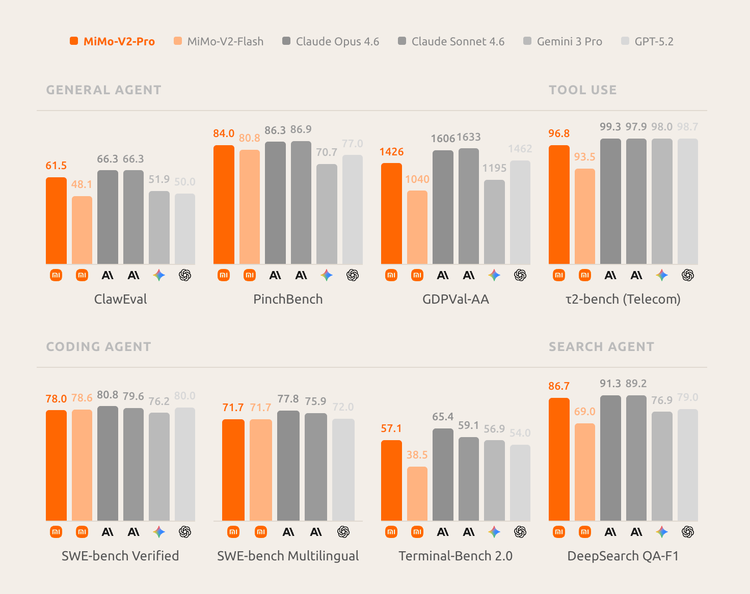
如果说 Pro 是"大脑",MiMo-V2-Omni 才是这次最有未来感的东西。官方对它的定义是 omni foundation model:把图像、视频、音频编码器直接融合进同一个共享 backbone,形成一条统一感知流。更关键的是训练目标——这个模型从一开始,就同时学三件事:场景是什么、接下来会发生什么、现在该做什么。感知和行动在架构层就是绑定的。
官方公开的 benchmark 数据,感知侧六个分数:MMAU-Pro 69.4、BigBench Audio 94.0、MMMU-Pro 76.8、CharXiv RQ 80.1、Video-MME 85.3、FutureOmni 66.7。从对照表可以直接读出:MMAU-Pro 69.4 高于 Gemini 3 Pro 的 67.0;CharXiv RQ 80.1 高于 Claude Opus 4.6 的 77.4;FutureOmni 66.7 高于 Gemini 3 Pro 的 62.9 和 Claude Opus 4.6 的 60.3。官方总结:音频理解整体超过 Gemini 3 Pro,图像理解超过 Claude Opus 4.6,视频理解支持原生音视频联合输入,并具备 future reasoning 能力。
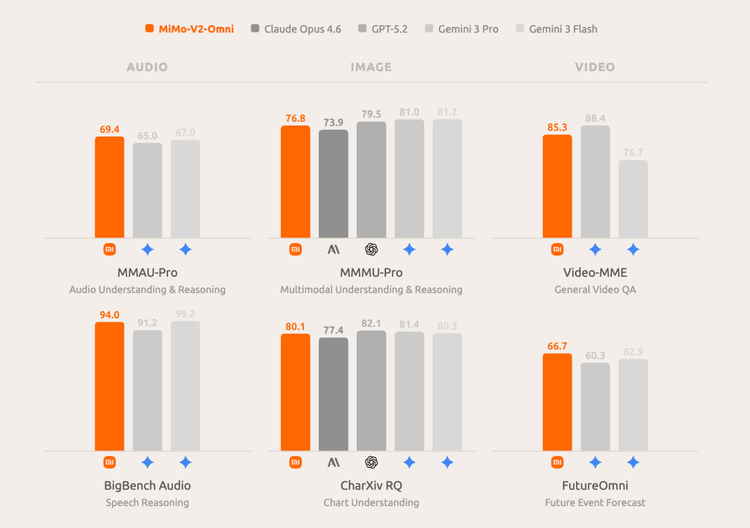
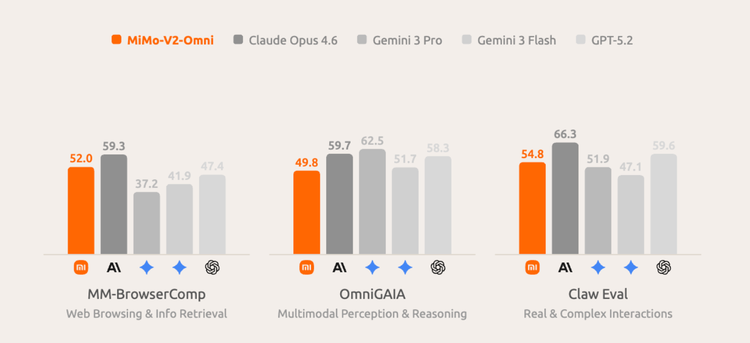
行动侧数据更值得关注:MM-BrowserComp 52.0、OmniGAIA 49.8、ClawEval 54.8、PinchBench 85.6。其中 MM-BrowserComp 52.0 明显高于 Gemini 3 Pro 的 37.2 和 GPT-5.2 的 47.4;PinchBench 85.6 高于 Gemini 3 Pro 的 70.7、Gemini 3 Flash 的 75.0 和 GPT-5.2 的 77.0,非常接近 Claude Opus 4.6 的 86.3。MM-BrowserComp 测的是模型在真实浏览器环境里完成任务的能力,这个分数比两个主要对手高出 5-15 个百分点,是执行维度上相当显著的差距。
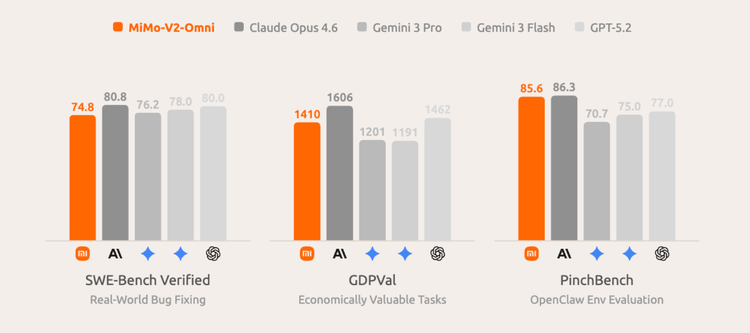
代码与任务能力上还有 SWE-Bench Verified 74.8、GDPVal 1410。
官方给了三个案例,每个都指向一类具体场景。
第一个是自动驾驶视觉大脑:给它一段海边小镇的行车记录仪视频,让它实时识别潜在风险。模型的输出是"并线风险、盲区、行人横穿、车道收窄、街边双排停车带来的侧向风险"——已经接近驾驶决策层的信息,目标检测只是基础。
第二个是跨平台购物 Agent:任务是扮演一个喜欢旅行摄影的学生,在小红书上搜三款小米 17 的选购建议,整理推荐,再去京东下单,并尽量和客服谈到更低价格。整个流程里,MiMo-V2-Omni 在 OpenClaw 配合下自主浏览帖子、比较卖家、与客服自然语言谈价、加购并走到结算,期间还处理了非标准 DOM、多标签页上下文管理、平台反自动化打断后的恢复,全程没有人工干预。任务链结构——跨平台、跨模态、遇到干扰后自主恢复——已经非常接近真实电商和办公场景里 Agent 工作流的复杂度。
第三个案例更极端:从零做一个 15 秒介绍视频,然后上传到 TikTok。模型先自己设计 4 个镜头,再合成低频 bass、电子音、转场 whoosh 和 glitch 细节音效;渲染中碰到中文字体报错,自己诊断并修复;打开 TikTok 上传页后,发现描述输入框不是标准文本元素,自行分析 DOM、找到正确交互方式,填完文案、发布、点赞、评论,最后确认视频通过审核公开上线。这个案例想说明的是:Omni 已经开始展现出闭环自主完成任务的能力——从内容生成到平台发布,中间出了问题,自己解决。
三、MiMo-V2-TTS:给 Agent 装上情感,被低估最久的那层体验
第三个模型 MiMo-V2-TTS,表面看起来最不"炸",但可能是最容易直接走进产品的那一个。行业这两年几乎所有讨论都集中在推理能力、工具调用、代码质量上,但真正到产品里,用户接触到的是最后那层——它怎么说话,有没有情绪,是否自然,是不是像一个真实存在的智能体。这层体验长期被当成锦上添花,但在终端产品里,它直接影响用户粘性。MiMo-V2-TTS 要做的,就是把这层认真填上。官方的说法很直接:给 Agent 一个声音,甚至给它"灵魂"。
您的浏览器不支持 audio 元素。
技术上,MiMo-V2-TTS 建在小米自研的 Audio Tokenizer 和 multi-codebook joint speech-text modeling 架构上,预训练数据超过 1 亿小时语音数据,后续做了多维度强化学习。重点在三件事:多粒度风格控制、自然韵律还原、唱歌能力。它可以理解自由文本风格描述,比如"刚睡醒、略微沙哑"、"几乎是耳语式的深情表达"、"愤怒但尽量克制",而不是只能从 happy/sad/angry/neutral 的下拉菜单里选。
更细的一层,是它可以在生成时同步输出非语言事件——咳嗽、停顿、迟疑、叹气、笑声等,强调的是这些信号在建模阶段就和上下文一并处理,而不是后期拼进去的音效。它还支持方言和角色音色,包括东北话、四川话、粤语、台湾普通话,以及孙悟空、林黛玉这类角色风格。目标是把一段文本表演出来,而不只是念出来。
最值得单独说的是唱歌。官方明确写明支持 singing voice synthesis,并表示这可能是当前首个在商业可用 API 中原生同时支持说话和唱歌的 TTS 能力。同一套架构,既能做耳语式对话,也能生成带音高和节奏的演唱,中间不用切模型、不用切模式。对内容生产、虚拟人、陪伴型 Agent、AI 主播和短视频工具来说,这是非常直接的能力补充。
需要说明的是,目前官方公开页里,MiMo-V2-TTS 没有像 Pro 和 Omni 那样给出一套完整的 benchmark 排名表,更多展示的是能力样例和产品方向。TTS 的质量本身就很难量化,最终检验只能靠真实产品里的用户体验。这个模型的核心命题只有一个:能不能把人机交互的体验往上拉一个台阶。
四、写在最后
把这三款模型放在一起看,小米在推进的目标已经超出了"能对话、会回答的大模型"范畴,落点在 Agent 时代的系统层底座。MiMo-V2-Pro 负责规划、推理、长上下文和复杂工具链;MiMo-V2-Omni 负责多模态理解、界面感知和跨环境执行;MiMo-V2-TTS 负责把这一切变成自然、可持续交互的产品体验。
有意思的是,小米这次挑的案例——自动驾驶、电商谈价、短视频生成上传、3D 游戏搭建、方言情绪语音——几乎全是小米自己生态里能直接落地的场景。
至于最终效果怎样,网址在此:
https://mimo.xiaomi.com/zh






