 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库哈佛医学院联手MIT Broad研究所发布MEDEA:组学智能体不缺能力,缺的是「自知之明」
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


在靶点筛选、合成致死判断与免疫治疗响应预测等治疗发现场景中,AI 智能体需要串联多个组学数据源、调用多种机器学习模型并检索文献来完成多步分析。但现有智能体普遍面临两个问题:一是大模型在长链分析中会逐步丢失用户指定的生物学上下文(如把「初始型 CD4+ αβ T 细胞」模糊成「CD4+ T 细胞」),导致下游分析在错误粒度上进行却不触发任何报警;二是面对多源证据冲突时缺乏调和机制 —— 工具输出、文献检索与大模型参数化知识给出矛盾结论时,系统无法做出可追溯的取舍。
为此,哈佛医学院隋芃玮 / 高尚华 / Marinka Zitnik 团队提出 MEDEA,一个在分析流程每一步都嵌入验证机制的组学 AI 智能体。MEDEA 在靶点发现、合成致死推理、免疫治疗响应预测三个场景上完成了 5,679 次完整分析,比单独使用大模型的准确率最高提升 45.9%,且消融实验表明性能提升的主要来源不是骨干模型的能力差异,而是验证模块的有无。

论文地址:https://medea.openscientist.ai
开源地址:https://github.com/mims-harvard/Medea
方法设计
MEDEA 接受自然语言描述的研究目标,使用 20 个专业工具执行多步分析,核心设计原则是在流程每一步嵌入验证,而非仅在最终输出时判断对错。
系统由四个协同模块组成。研究规划模块将自然语言目标转化为分步研究计划后,进行上下文验证(每个步骤中的细胞类型、疾病等生物学实体是否与所选工具兼容)和完整性验证(计划的技术可行性与逻辑一致性)。例如,当用户要求分析肝星状细胞的靶点,但所选单细胞基础模型的预训练数据不包含该细胞类型时,上下文验证会检测到不兼容,引导智能体从可用的近似细胞类型中选择替代方案并记录替代理由。
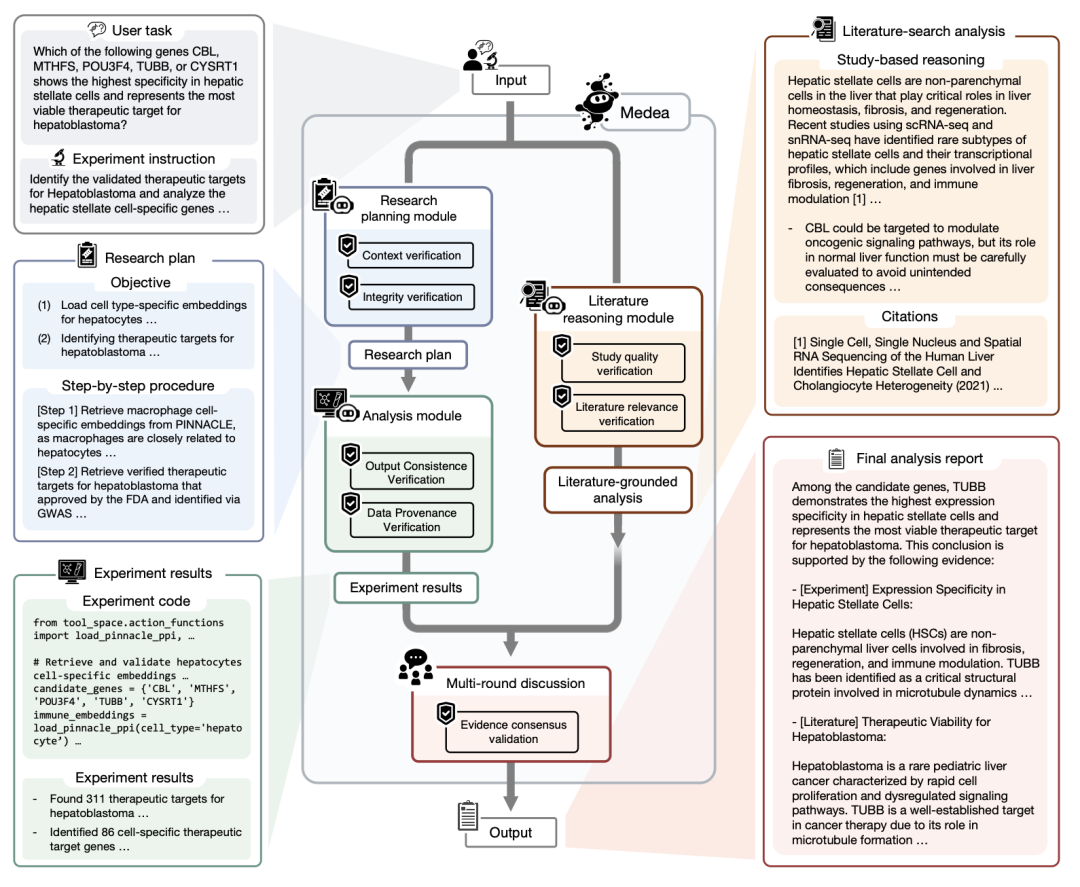
分析执行模块在代码执行前后各加一层验证:执行前检查语法与接口兼容性,执行后审计数据来源与输出和计划的一致性。即使代码运行成功,如果输出偏离研究计划预期,也会被标记并触发修正。
文献推理模块在检索完成后,先对每篇论文在物种、疾病、细胞类型等维度做相关性筛选,过滤不相关文献后再进行证据综合,避免「检索到什么就用什么」的问题。
多轮讨论模块以三个模型组成的评审团,对工具分析、文献推理、骨干模型三条证据通路的输出做加权投票与多轮辩论。证据收敛时给出结论,分裂或不足时选择校准弃权 —— 即不回答。
工具空间中有 4 个机器学习模型(PINNACLE、TranscriptFormer、COMPASS、OpenScholar),它们是被智能体调用的工具而非骨干模型。智能体根据疾病上下文动态选择调用哪个模型。受限工具实验表明,PINNACLE 在类风湿关节炎等疾病上更优,TranscriptFormer 在肝母细胞瘤等场景上更优,反映了蛋白质互作网络拓扑与基因表达动态两类信号的互补性。
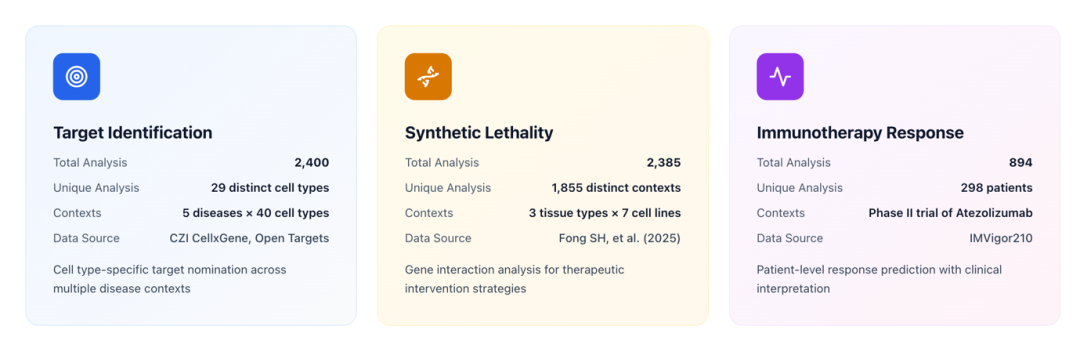
MEDEA 在三个开放式治疗发现任务上跑了 5,679 次完整组学分析,覆盖精准靶点发现(2,400 次,涵盖 5 种疾病,29 个细胞类型)、合成致死推理(2,385 次,7 个癌细胞系)、以及患者级别的免疫治疗响应预测(894 次,298 名膀胱癌患者)。
细胞类型特异性靶点发现
2,400 次分析,覆盖类风湿关节炎、1 型糖尿病、干燥综合征、肝母细胞瘤、滤泡性淋巴瘤五种疾病及 29 种细胞类型。MEDEA 比单独使用大模型的准确率最高提升 45.9%。
该场景的核心挑战在于细胞类型粒度。大模型在多步分析中会逐步模糊细胞类型 —— 将用户指定的「初始型 CD4+ αβ T 细胞」简化为「CD4+ T 细胞」。在类风湿关节炎中,初始型与效应记忆型 CD4+ αβ T 细胞的致病角色截然不同,混淆会导致靶点推荐指向错误的生物学逻辑。加入上下文验证后,MEDEA 在髓样树突细胞上的准确率提升 28.9%,在初始型 CD4+ αβ T 细胞上提升 21.7%—— 这些恰恰是上下文粒度直接决定靶点推荐质量的细胞类型。
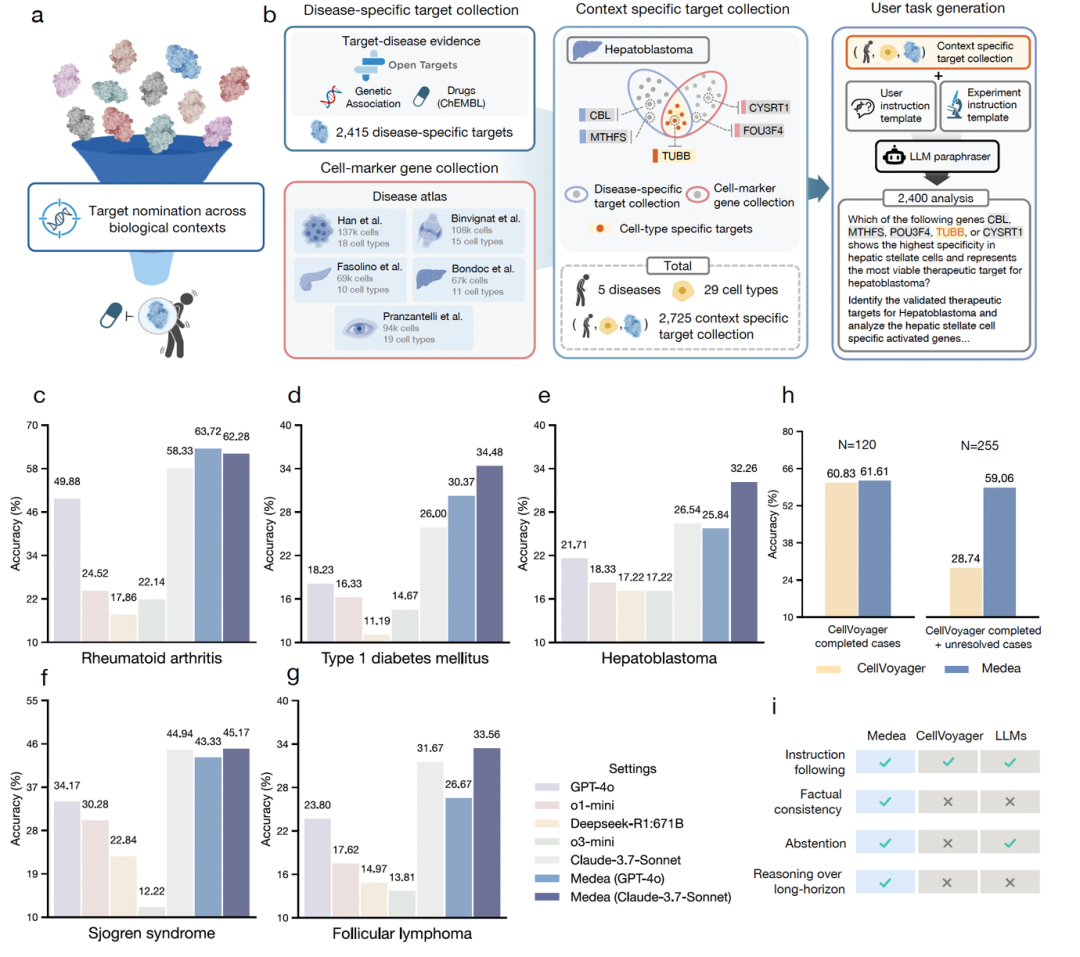
消融实验揭示了一个结构性矛盾。大模型单独使用时几乎从不放弃回答(弃权率仅 1.8%),但跨五种疾病的平均错误率高达 69.2%—— 在 1 型糖尿病上甚至达到 80%。文献检索配置方向相反:77.6% 的分析选择放弃回答,因为细胞类型特异性的靶点文献确实太过稀缺。大模型的参数化知识覆盖面广但可靠性低,文献证据可靠性高但覆盖面窄,任何单一通路都无法同时满足两者,只有多条通路互相校验才能兼顾。 完整 MEDEA 达到最高准确率和最低失败率。

合成致死推理:纠错、补漏、止损
2,385 次分析,覆盖 MCF7、MCF10A、MDAMB231、CAL27、CAL33、A549、A427 七个癌细胞系。MEDEA 比骨干大模型最高提升 21.7%(MCF7)。
MEDEA 在该场景下展现出三种行为模式。在至少 323 个大模型答错的案例中给出了正确判断(纠错);在 175 个大模型弃权的案例中给出了正确答案(补漏);在 141 个大模型犯错的案例中选择弃权而非跟着错(止损)。在药物发现场景中,止损可能比纠错更有价值 —— 一个错误的合成致死预测可能触发昂贵的实验跟进,而一个校准的弃权只会让研究者多花时间寻找其他证据。
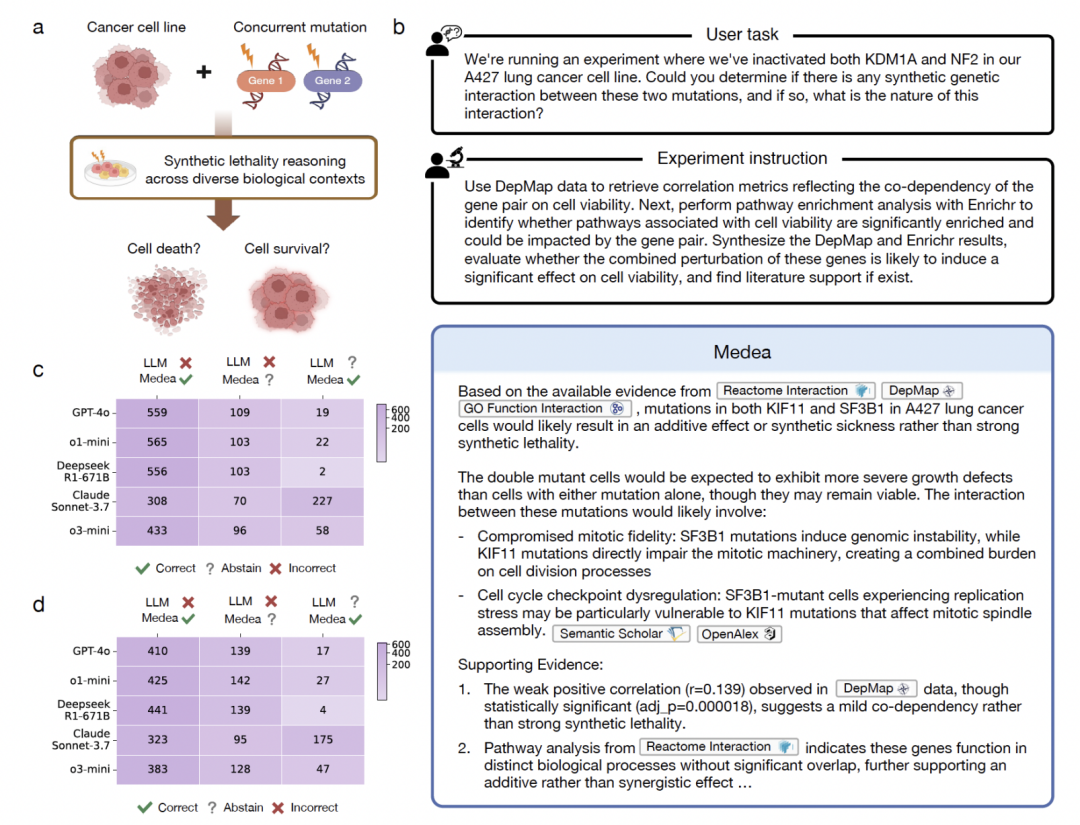
系统整合了 DepMap 基因共依赖分数与通路富集分析,对基因对联合抑制是否会选择性杀死癌细胞做出可追溯的判断。
免疫治疗响应预测
894 次患者级别分析,基于 IMvigor210 膀胱癌队列的 298 名患者。MEDEA 比大模型最高提升 23.9%。在高肿瘤突变负荷且非炎症型微环境这一最困难的亚组中,MEDEA 修正了底层机器学习模型 50.9% 的误分类。
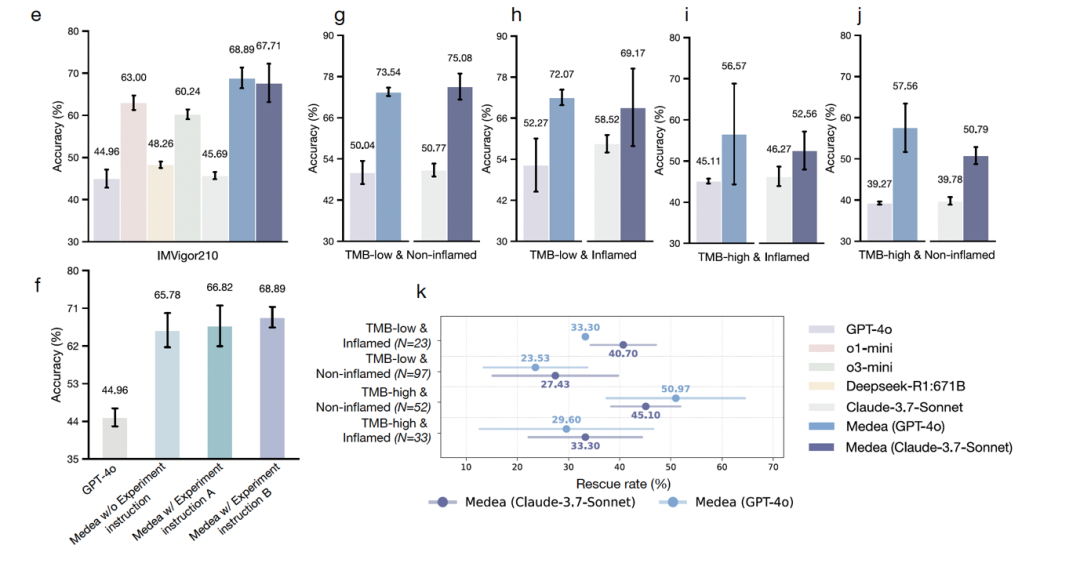
论文中的一个患者案例清晰展示了多源证据冲突时的决策过程。一名肿瘤突变负荷为 19.0 的男性患者,GPT-4o 和 Claude 3.7 Sonnet 均基于高突变负荷预测「响应」。MEDEA 调用 COMPASS 分析肿瘤转录组后发现 T 细胞耗竭严重(评分 0.5067)、B 细胞浸润极低(0.0260),微环境整体呈功能失调;而文献检索恰恰支持「高突变负荷→好响应」的关联 —— 两条证据直接矛盾。经多轮讨论调和后,MEDEA 判定微环境功能障碍信号优先于突变负荷的统计关联,预测「不响应」。患者实际结局为疾病进展。整个决策链路可追溯。

验证机制的贡献大于骨干模型的选择
消融实验中最核心的发现:MEDEA 的性能提升并非来自更强的骨干大模型。 无论使用 GPT-4o 还是 Claude 3.7 Sonnet 作为骨干,加入验证模块后性能显著提升,去掉后显著下降。这意味着当前组学智能体的性能瓶颈可能不在推理能力,而在过程可靠性。
MEDEA 的输出不是一个标签或分数,而是一份包含完整推理链路的分析报告 —— 研究计划、每步工具调用与输出、文献检索与相关性评分、证据调和的决策过程。对于需要向团队解释「为什么推荐这个靶点」或「为什么判断该患者不响应」的场景,这种可审计的输出形态具有直接的实际价值。
代码、评测基准和全部工具配置均已开源,模块化设计支持选择性集成。论文同时指出局限性:评测基准依赖已有单细胞图谱和特定患者队列,部分评测依赖大模型评审,工具本身编码了细胞类型粒度等假设,评审团式共识模块存在关联错误风险。
在药物发现中,一个自信的错误答案往往比一句诚实的「我不确定」代价更高。MEDEA 的校准弃权 —— 在证据不足时选择不回答 —— 或许是这项工作中最具实际价值的设计。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





