 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库中国开源首超美国:Hugging Face发布全球AI开源现状报告
中国首次超越美国,成为Hugging Face平台月下载量最大的模型来源国。

而且这一巨变,发生在短短一年之间。
Hugging Face这篇报告,将带你看清开源AI生态的真实面貌,从全球竞争格局的重塑、地区力量的崛起,到机器人与科学领域的新战场,呈现一幅完整而清晰的开源AI版图。
中国登顶与生态裂变
2025年对开源AI而言是分水岭式的一年。
Hugging Face平台用户数攀升至1300万,公开模型突破200万个,数据集超过50万个,这些数字较上一年几乎翻了一番。
增长背后藏着一个更深层的变化,用户不再只是模型的消费者,越来越多人开始创建衍生作品,微调模型、适配器、基准测试和应用层出不穷。
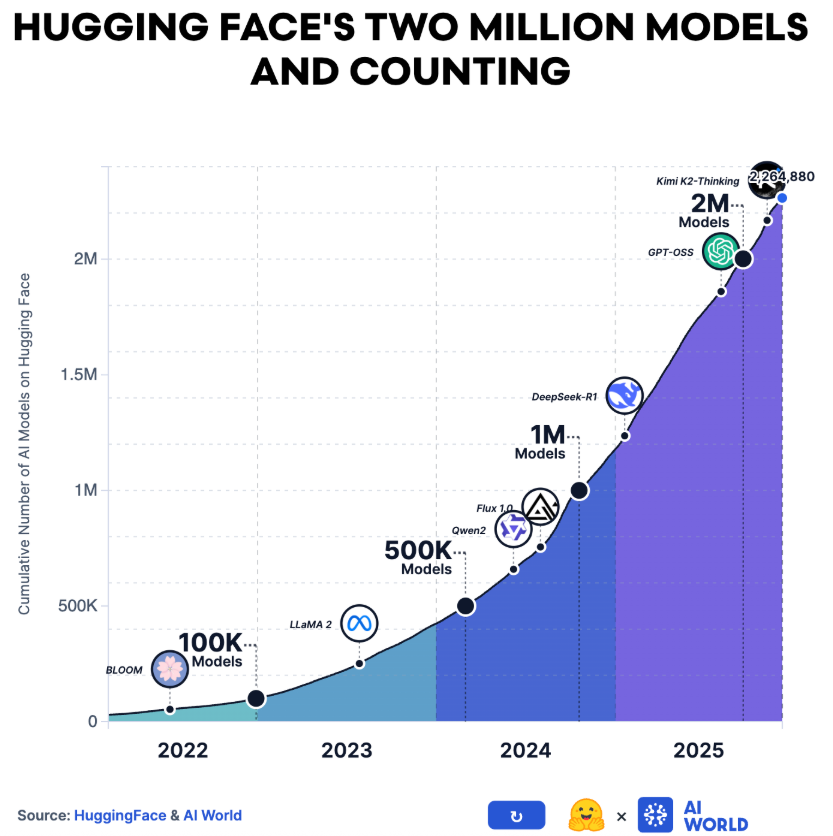
生态的繁荣并没有掩盖集中度的问题。
约一半的模型下载量不足200次,而排名前200的模型,仅占总量的0.01%,却拿走了49.6%的下载份额。
开源AI更像是由多个重叠的子生态组成,每个子生态围绕特定领域、语言或问题领域形成自己的社区,即使整体下载量不高,也能保持持续的参与和复用。
竞争格局正在经历深刻调整。
财富500强企业中超过30%已在Hugging Face建立认证账户。
初创公司把开源模型当作默认组件,Thinking Machines的Tinker模型完全基于开源权重构建,VSCode和Cursor等主流IDE同时支持开源和闭源模型。
Airbnb等老牌美国企业也在加大对开源生态的投入,Hugging Face看到更多传统公司在2025年期间升级其组织订阅。
大型科技公司的动作更值得关注。
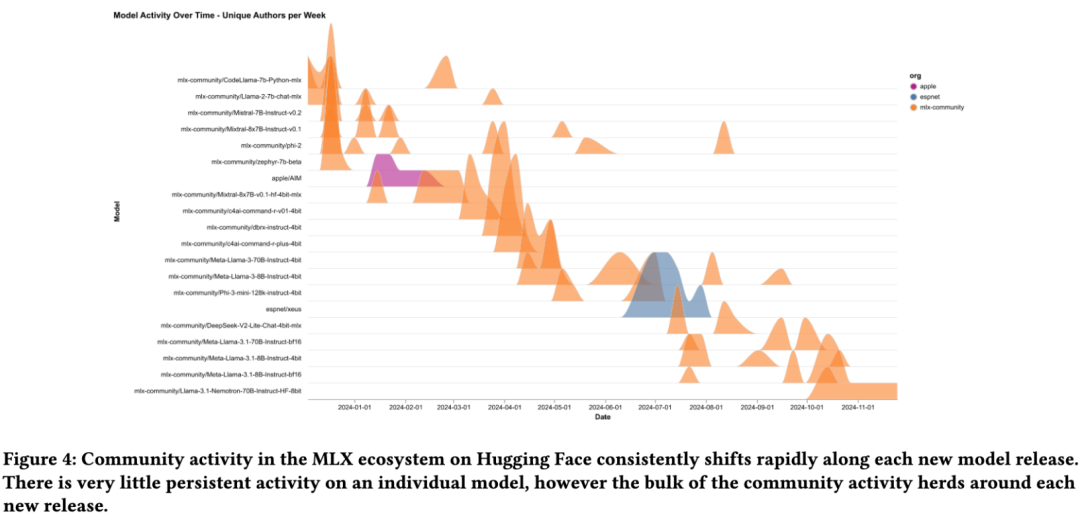
NVIDIA已成为最活跃的贡献者,各大科技公司纷纷在Hugging Face Hub上创建新仓库,仓库增长曲线清晰地显示出持续的投入。
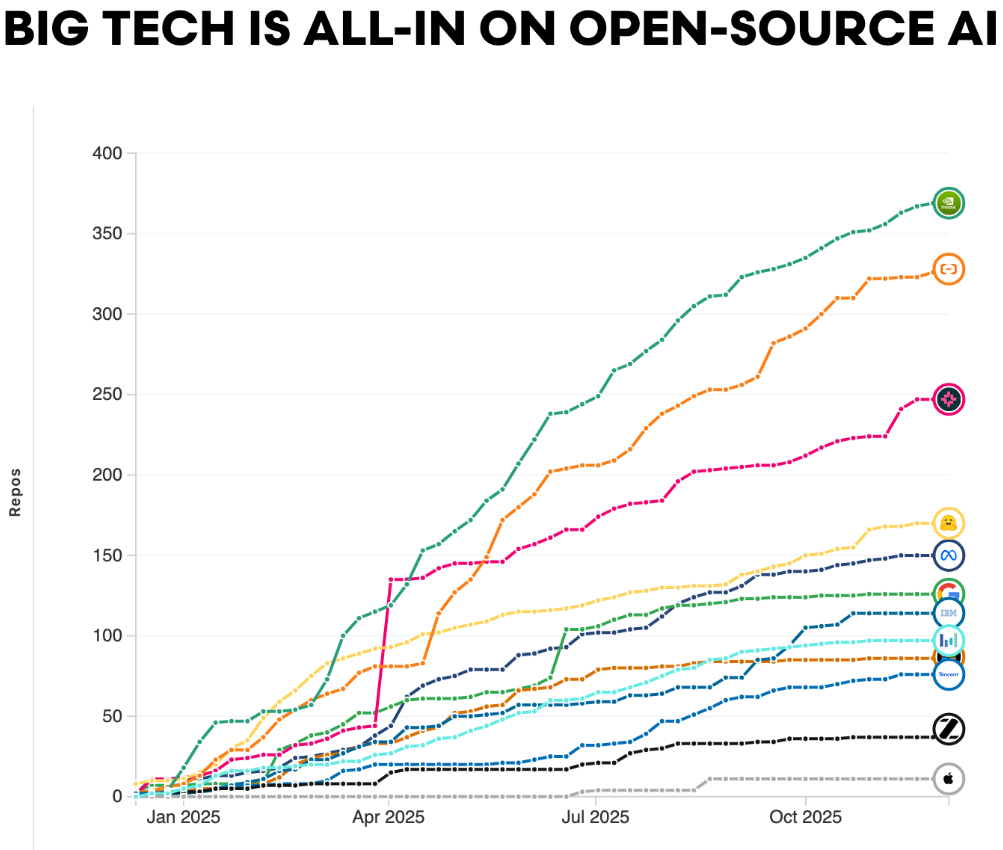
开源软件领域的研究表明,开源产物的下游价值远超其生产成本,类似规律正在AI领域显现。
开源模型被数千个下游应用复用、适配和专业化,仅依赖闭源系统的组织往往面临更高成本,在部署和定制化方面的灵活性也受限。
地缘格局的变化最为剧烈。
过去四年累计下载量的数据显示,美国和中国一直是领先的贡献者,英国、德国和法国紧随其后。
模型开发者如果是个人用户或分布式组织,没有明确地理归属,约占平台总下载量的一半。

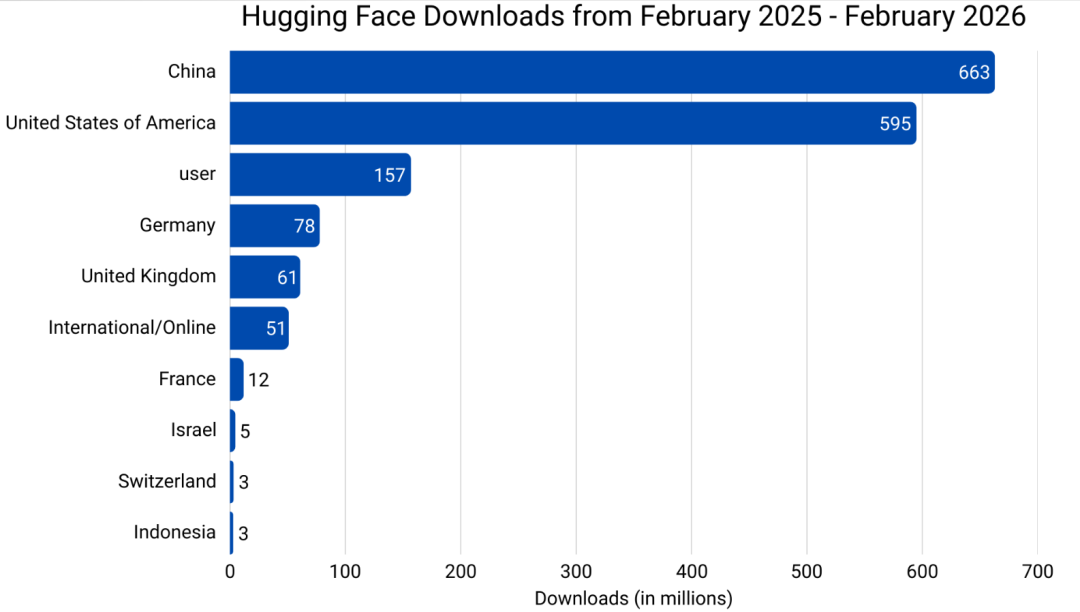
但2025年情况发生了根本性转变。
Hugging Face数据显示中国超越美国,在月下载量和总下载量上都处于领先地位。过去一年,中国模型迅速占据41%的下载份额。
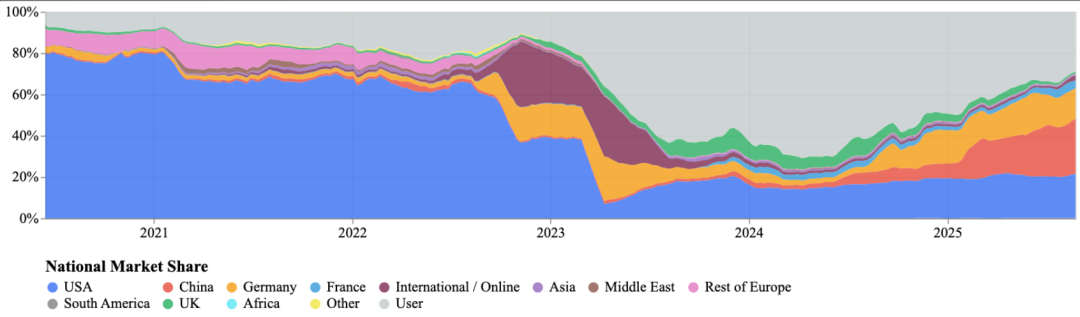
工业界在整体开发中的份额从2022年前的约70%降至2025年的37%。
同期独立或无附属开发者从17%升至39%,有时甚至占到总使用量的一半以上。
个人和小型集体专注于量化和适配基础模型,这些中间人群体现在引导着相当一部分用户能运行什么,以及创新如何在生态中传播。
不同地区以不同方式参与生态。
美国和西欧历史上通过大型工业实验室主导,如谷歌、Meta、OpenAI、Stability AI,中国则在发布和采用两方面都日益领先。
法国、德国和英国继续通过研究机构、国家AI计划和专业化模型家族做出贡献。支持多种贡献者和组织形式的生态,往往能产生更广泛采用的成果。
初创公司的热门模型传播更广。有竞争力的国家包括法国和韩国。
值得注意的是,开发新热门模型的第四大实体是个人用户,而非组织。在用户层面创建有竞争力的模型比以往任何时候都更容易。
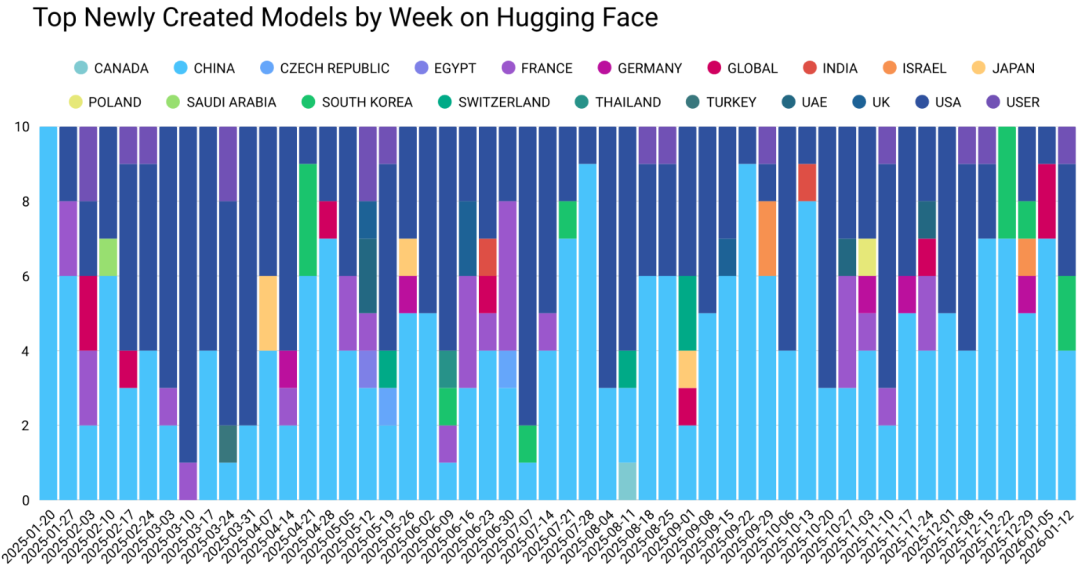
DeepSeek R1模型在2025年1月的病毒式传播成为中国开源浪潮的标志性事件。
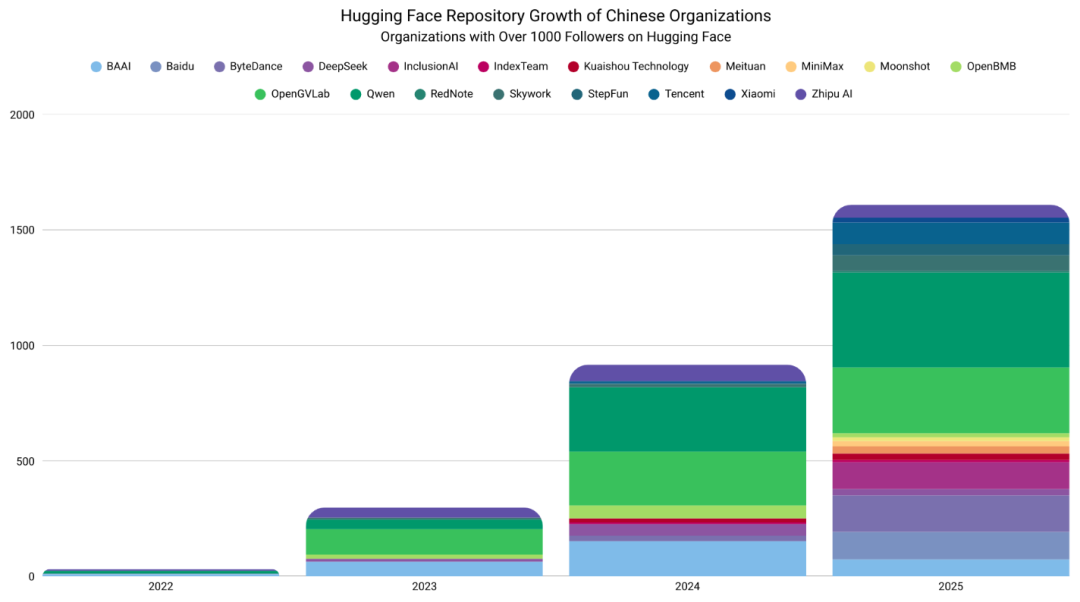
此后,有竞争力的中国组织数量和在Hugging Face上的仓库数量都呈爆发式增长。
百度从2024年在Hub上零发布激增到2025年的100多个仓库。
字节跳动和腾讯的发布量增长8到9倍。
此前倾向闭源策略的百度和MiniMax等组织,都果断转向开源发布。
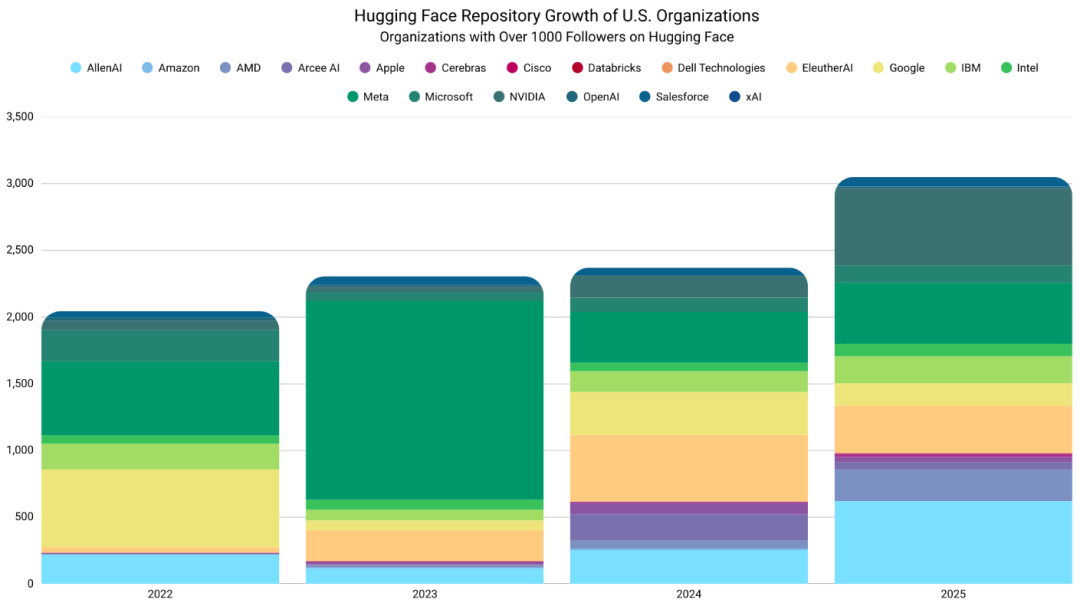
美国方面,数量相近的热门组织一直持续贡献更高数量的仓库。Meta及其前身Facebook研究组织贡献了相当比例的开源发布,谷歌也有一定贡献,但程度较低。
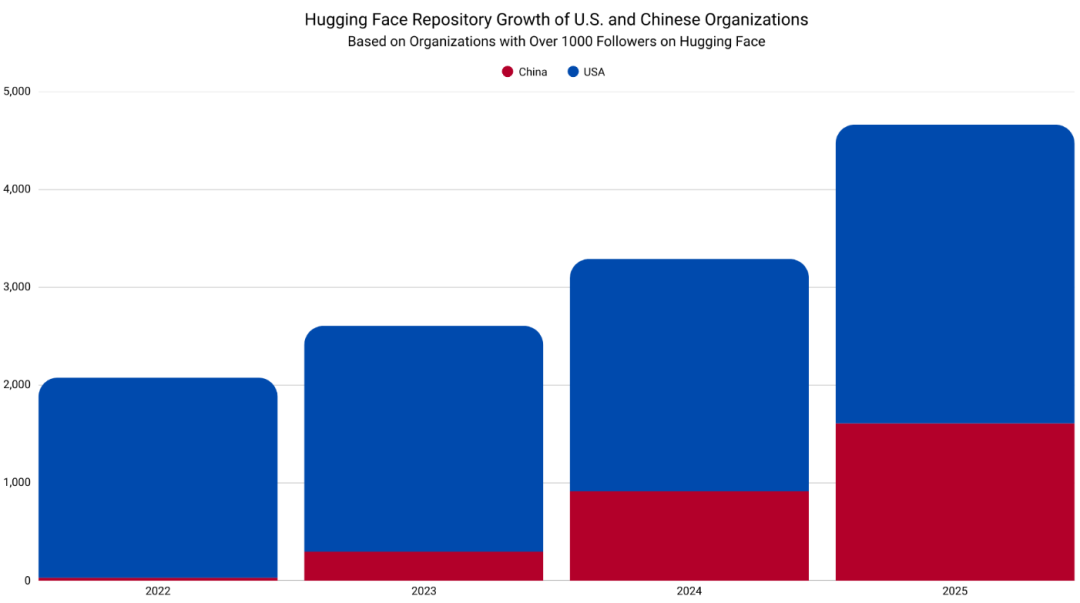
两者放在一起,热门中国组织仓库增长的陡峭上升轨迹显示出关键的战略差异。
主权AI与硬件版图
开源AI正日益与主权问题交织在一起。
开源权重模型允许政府和公共机构在国家法律框架下,用本地数据微调系统。
可部署在本土硬件上的模型减少了对海外控制的云基础设施的依赖。模型架构、训练过程和评估的透明度支持监管审查和公众问责。
各国政府已开始行动。
韩国国家主权AI计划于2025年中期启动,指定LG AI Research、SK Telecom、Naver Cloud、NC AI和Upstage为国家冠军企业,生产有竞争力的本土模型。
2026年2月,三个韩国模型同时登上Hugging Face热榜。
2026年3月,韩国与美国初创公司Reflection AI宣布数据中心合作,将前沿开源权重模型引入韩国。
瑞士AI计划和多项欧盟资助项目反映了类似优先级,英国公共资金、公共代码的原则影响了多个政府支持的AI倡议。
投资正在产生回报。模型和数据集通常在开发地区使用最多,开发者往往选择最能代表其语言、反映类似技术和应用需求的模型。
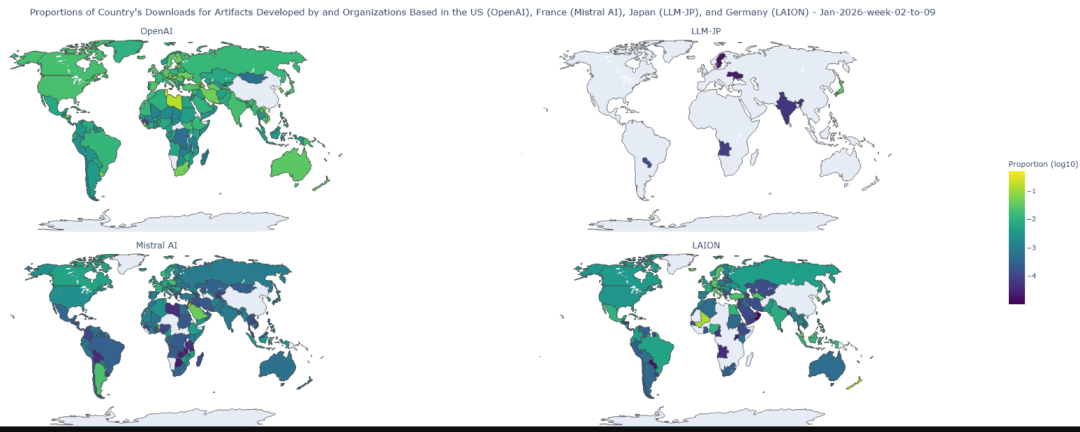
最受欢迎的模型榜单也在变化。
一年前,最受喜爱的模型主要来自美国的Meta Llama家族。
一年后,榜单呈现国际化混合格局,中国的DeepSeek-R1位居榜首。这一指标不一定反映使用量,但积累的关注度能显示兴趣信号。

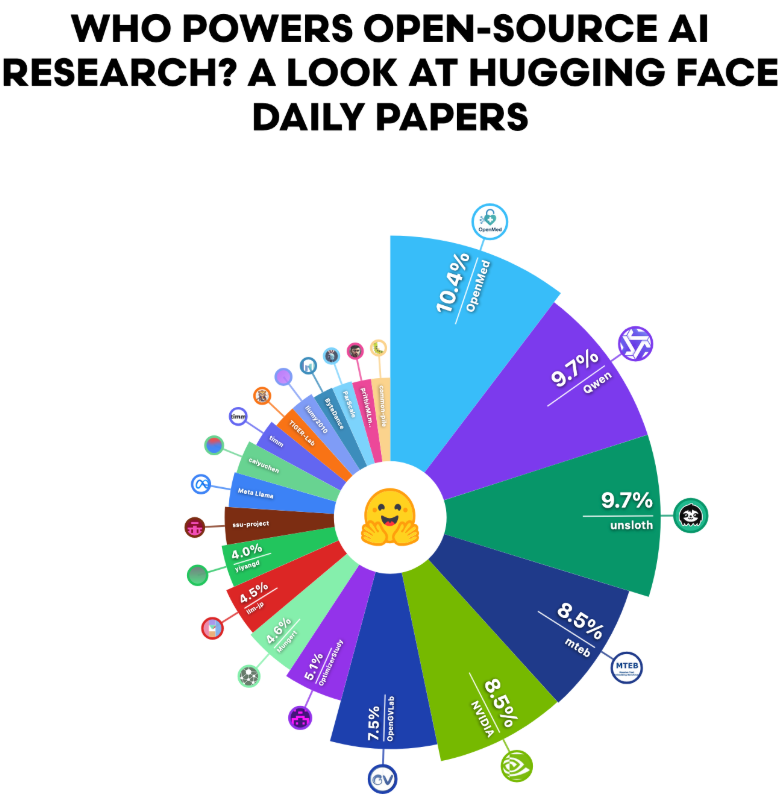
论文和科学贡献方面,Hugging Face Daily Papers数据显示,大型AI组织的论文受到社区成员广泛认可。
最受推崇的论文主要来自美国和中国的头部组织。
中国大型科技公司占多数,字节跳动分享了大量高影响力论文。
另一角度看,涉及模型和数据集创建的论文显示出更多样化的开源采用,医学论文影响力突出,大型科技公司的影响反而分散。
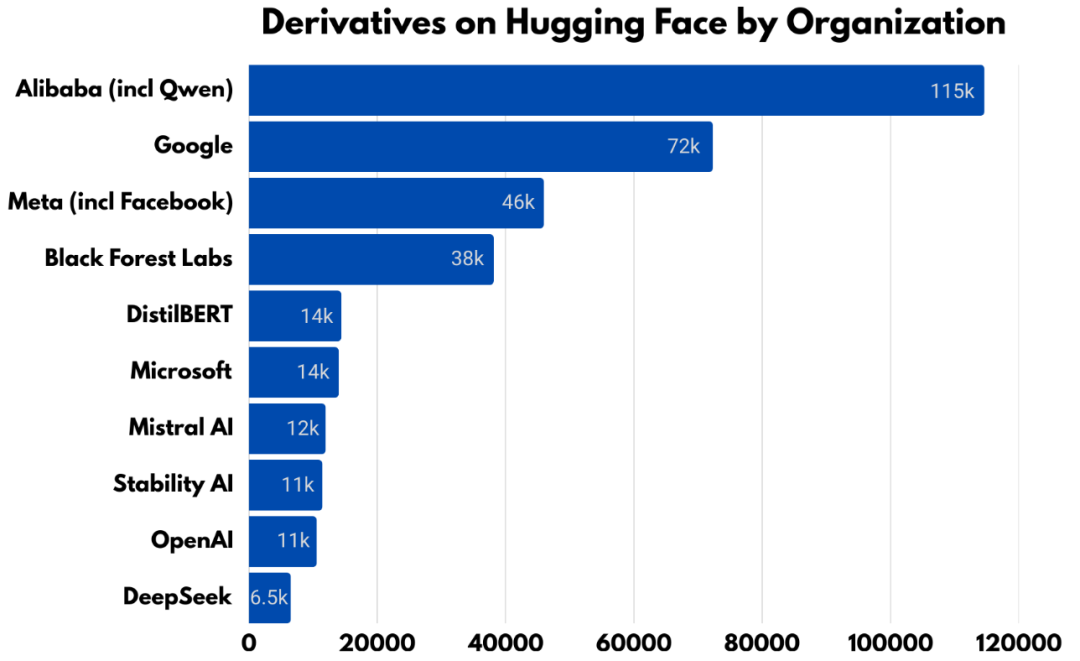
衍生模型的数据揭示了一个有趣现象。
阿里巴巴作为组织,其衍生模型数量超过谷歌和Meta的总和,Qwen家族构成超过113000个衍生模型。计入所有标注Qwen的模型,数字膨胀到超过200000个。
模型开发越来越强调可访问性。
小模型的下载和部署率远高于超大型系统,反映出成本、延迟和硬件可用性的现实约束。
小模型主导部分原因在于发布数量更多,但即使归一化处理,ATOM项目的相对采用指标显示,1至90亿参数的中位数前10模型下载量仅比1000亿以上参数的模型高约4倍。
自动化系统和CI流水线进一步推高了小模型下载计数,但向小型可部署模型发展的趋势是真实的。
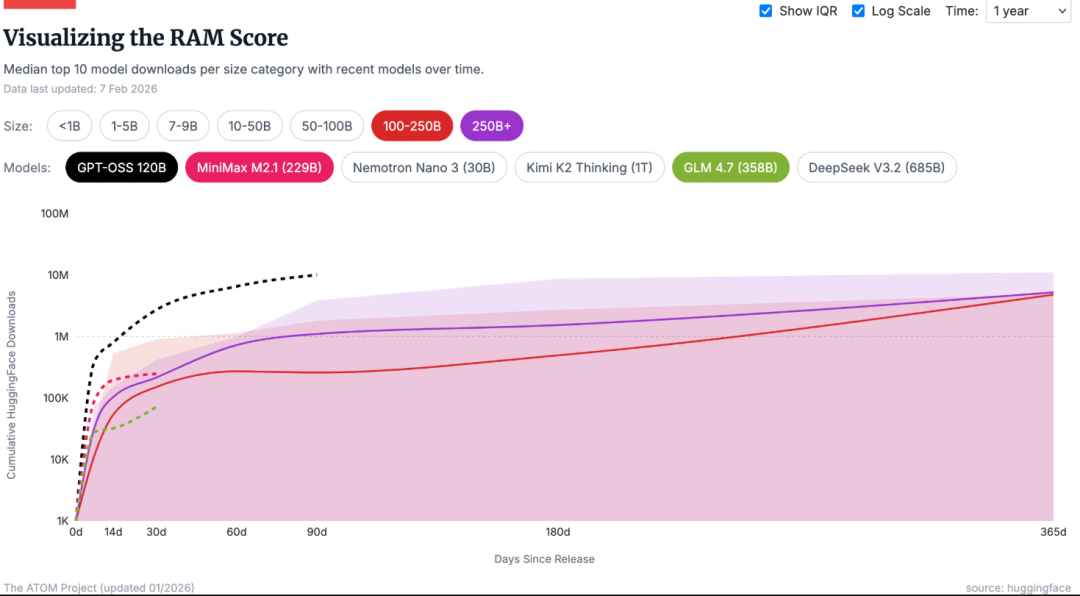
用户对开源模型的参与通常在发布后迅速达到峰值,然后放缓。平均参与持续时间约6周。持续改进和频繁更新对保持相关性至关重要。
DeepSeek的连续发布,V3、R1、V3.2,使其在挑战者涌现时仍保持竞争力。开发停滞的组织往往迅速失去份额,输给频繁更新或领域微调的竞争者。
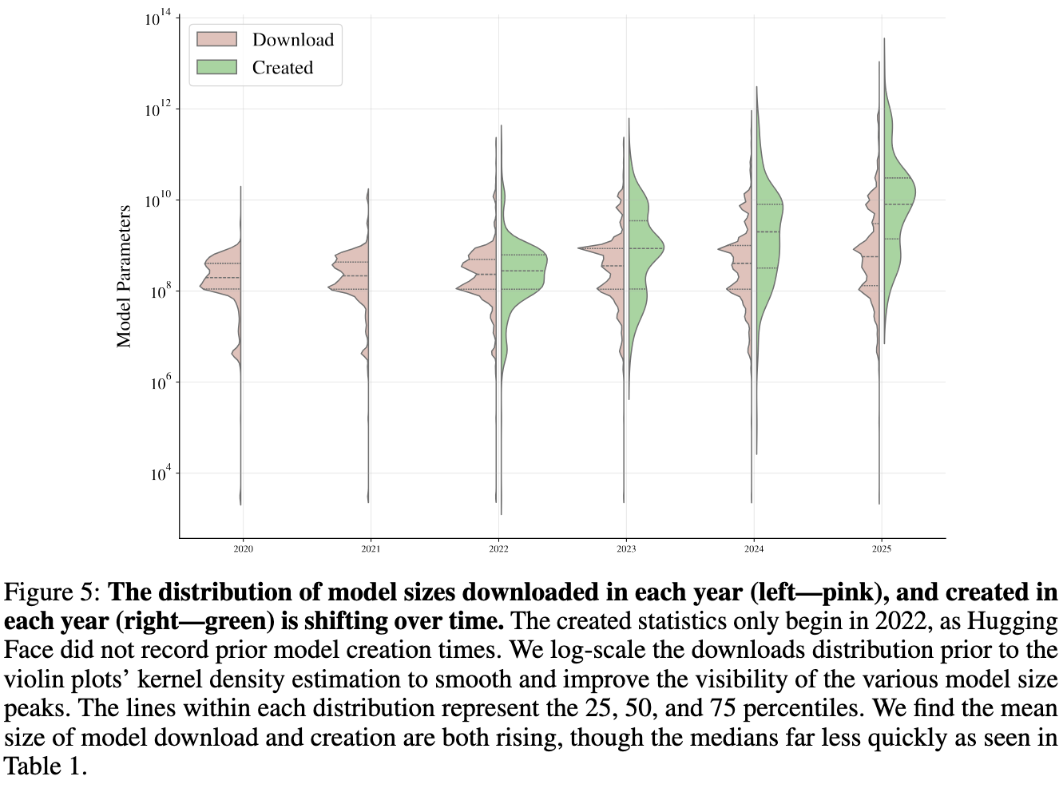
下载模型的大小也在变化。2023年下载模型平均参数量为8.27亿,2025年升至208亿,主要由量化和混合专家架构推动。
中位数则仅小幅增长,从3.26亿升至4.06亿。这种分化表明,高端大语言模型用户拉高了均值,而底层小模型使用保持稳定。
前沿模型与小型系统的性能差距往往通过微调和任务适配迅速缩小。
在Hugging Face Hub上,数亿参数的模型支持搜索、标注和文档处理工作流,个位数十亿参数的模型广泛用于编码、推理和多模态任务。
大多数主要模型开发商现在发布覆盖不同尺寸的模型家族。有能力的小型模型将自主权推向边缘,减少对集中式云提供商的依赖。
开源AI开发与硬件趋势紧密相连。
大多数模型针对NVIDIA GPU优化,但AMD硬件支持持续扩展。
Stability AI模型集合现在同时针对NVIDIA和AMD平台优化。库越来越多地面向两者,工具改进使跨硬件部署更直接。
2025年Hugging Face推出Kernel Hub,加载和运行为NVIDIA和AMD GPU优化的内核。
中国开源模型开始明确支持国产芯片。
阿里巴巴投资推理专用芯片架构,旨在让中国数据中心配备能够在本地运行开源模型的硬件。
对开源权重模型而言,计算资源仍是开发和部署的核心需求,但它们正在帮助打破一个生态系统,使其不再是全部和终结。各性能层级都有模型推出,效率比最大开发者的旗舰AI模型低10到1000倍成本。
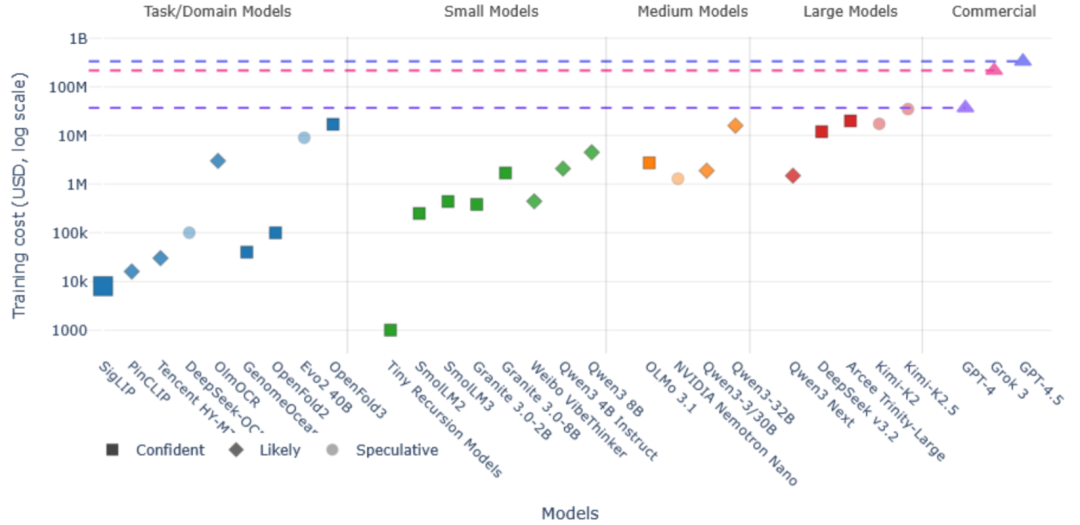
开源基础设施投资问题仍然紧迫。能够训练和服务开源模型的公共资金数据中心已成为日益增长的政策讨论话题,尤其在欧洲和英国。
大型闭源模型公司可用的计算资源与开源社区可获取资源之间的差距,持续塑造着开源开发的可行性边界。
机器人与科学的新疆域
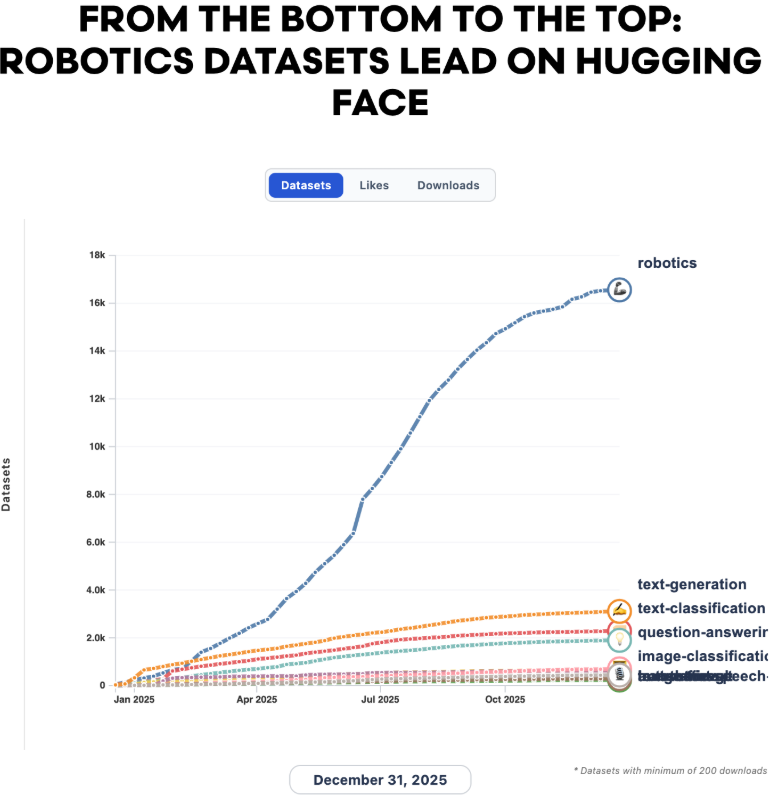
机器人学成为Hugging Face增长最快的子社区之一。
数字令人瞩目,机器人数据集从2024年的1145个增长到2025年的26991个,三年内从第44位攀升至数据集类别的第一名。
作为对比,第二大类别文本生成在2025年仅有约5000个数据集。
社区贡献的数据集涵盖家庭操作任务到自动驾驶。最大的空间智能多模态数据集Learning to Drive由LeRobot与Yaak合作发布。
RoboMIND等数据集提供超过107000条真实世界轨迹,覆盖479个不同任务和多种机器人形态,为训练可泛化的机器人策略提供了所需的规模和多样性。
Hugging Face收购Pollen Robotics,将开源机器人销售扩展到工业实验室、学术实验室和普通爱好者。
LeRobot是Hugging Face的开源机器人库,提供真实世界机器人的模型、数据集和PyTorch工具,涵盖模仿学习、强化学习和视觉语言动作模型,过去一年GitHub仓库星标接近三倍。
科学研究是另一个活跃领域。开源模型和数据集越来越多地用于蛋白质折叠、分子动力学、药物发现和科学数据分析。所有前沿AI公司现在都有专门的科学团队,虽然当前重点仍是文献发现而非直接实验。
社区主导的项目围绕共同研究目标形成,通常涉及跨机构和学科的数百名贡献者。这些努力凸显了开源作为大规模跨学科工作协调机制的角色,这类工作很难仅通过传统学术或企业结构组织。
展望未来,开源AI生态正通过全球参与、技术专业化和制度采纳持续演进。几个趋势可能定义下一阶段。
地理权力再平衡正在加速。西方组织日益寻求中国模型的商业可用替代品,OpenAI的GPT-OSS、AI2的OLMo和谷歌的Gemma等努力更显紧迫,旨在提供来自美国和欧洲开发者的有竞争力开源选项。这些努力能否匹配Qwen和DeepSeek的采用势头,将成为2026年的决定性问题。
机器人和科学子社区的增长表明,开源AI正从语言和图像生成扩展到物理和实验领域。围绕文本和图像模型开发的基础设施、规范和协调机制正在适应新的模态和用例。
对于研究人员、开发者、公司和政府,开源仍是构建、评估和治理AI系统的基础层。
随着智能体部署增加,开源及其互操作性将成为智能体蓬勃发展的关键。
过去一年的轨迹清晰地表明,开源生态是AI开发、适配和部署实践工作大量发生的地方,其对更广泛AI格局的影响力持续增长。
参考资料:
https://huggingface.co/blog/huggingface/state-of-os-hf-spring-2026
END
点击图片立即报名👇️










