 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库为蛋白质宇宙「编目」——DIAMOND DeepClust实现190亿序列的超快聚类
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯

编辑丨&
地球上的生命到底编码了多少种蛋白质?随着测序技术的飞速发展,我们正以前所未有的速度积累着答案:目前已知的蛋白质序列已超过 190 亿条,而地球生物基因组计划(Earth BioGenome Project)的目标——对180万个真核物种进行测序——将把这个数字推至 270 亿。
聚类——将相似的序列归为一组——是建设有效组织的核心步骤。通过将相似序列归入同一簇,可以构建蛋白家族、提取进化信息,并为结构预测等任务提供关键输入。但现有方法,如 CD-HIT 或 MMseqs2 ,在面对跨物种、低相似度的大规模数据时,要么速度无法承受,要么敏感性显著下降,成为整个流程的计算瓶颈。
来自德国马克思·普朗克研究所等的团队带来了一个突破性的解决方案:DIAMOND DeepClust。它通过级联聚类架构、多节点并行和创新的线性模式,首次实现了在合理时间内对 190 亿条蛋白质序列进行敏感聚类,将数据压缩至原来的 1/56,并在此过程中发现了超过 1 亿个未被现有数据库覆盖的新蛋白质家族。
相关研究以「Clustering the protein universe of life using DIAMOND DeepClust」为题,于 2026 年 3 月 24 日发布在《Nature Methods》。

论文链接:https://www.nature.com/articles/s41592-026-03030-z
如何重新定义「聚类」
论文提出的方法名为 DIAMOND DeepClust,其本质是一种级联式(cascaded)的深度聚类算法,建立在高敏感蛋白比对工具 DIAMOND v2 之上。与传统方法不同,它并不是简单地做全局聚类,而是通过一个明确的计算流程来压缩蛋白空间。
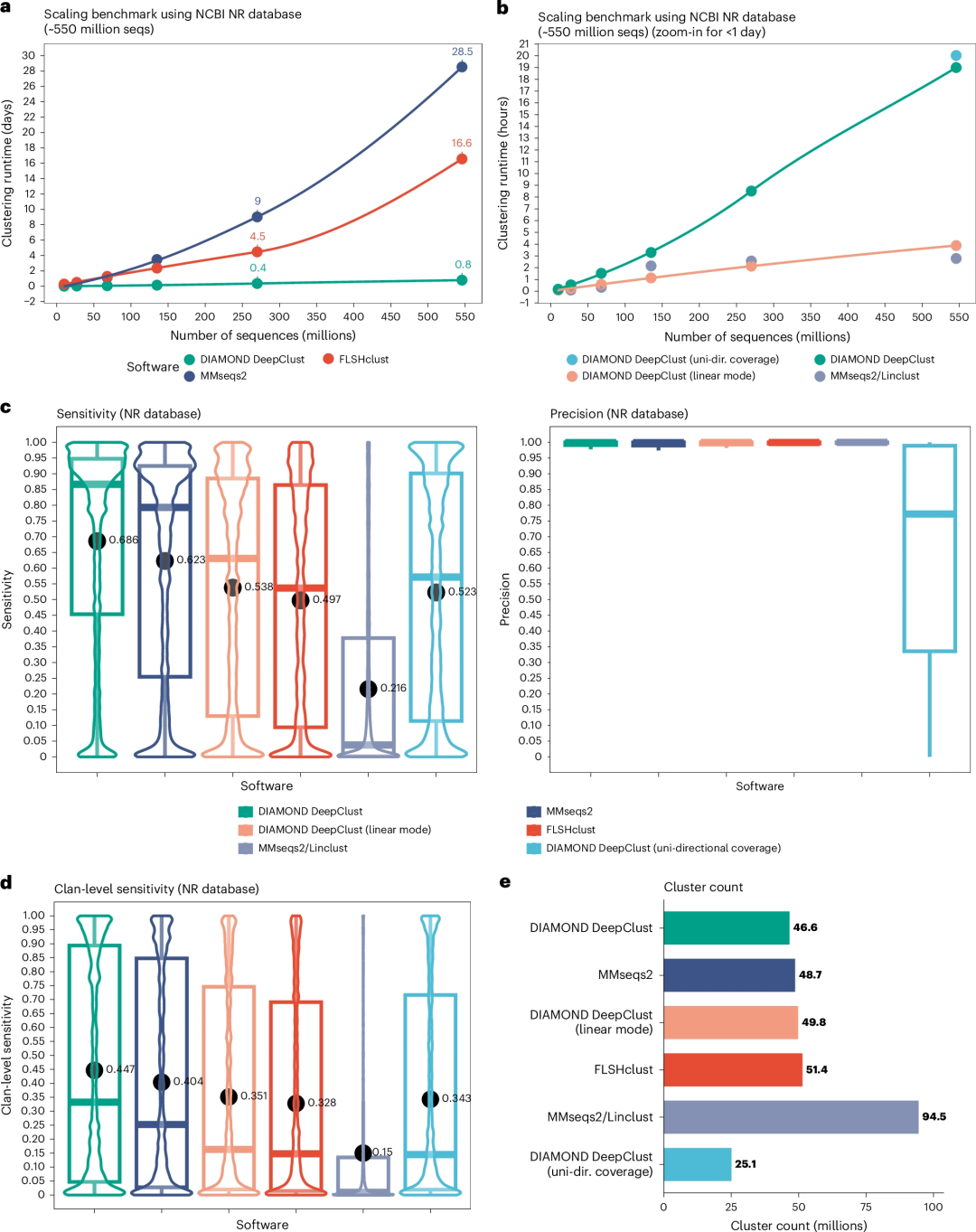
图1:DIAMOND DeepClust、MMseqs2 和 FLSHclust 聚类性能的基准测试。
算法首先基于序列比对构建一个图结构,其中每个节点代表一个蛋白序列,边表示满足阈值的相似性关系。随后,通过一种「代表序列机制」,将聚类问题转化为寻找一组最小覆盖节点集合,使每个序列都能被某个代表序列覆盖。
团队利用双向覆盖标准对国家生物技术中心(NCBI)非冗余(NR)数据库(含约 5.46 亿条序列)进行了聚类。DIAMOND DeepClust 在单台 64 核心服务器上,在 19.0 小时内解决了深度聚类问题,相较于 MMseqs2 快了 36 倍。
为了进一步提升规模能力,DeepClust 引入了多项关键优化,包括在种子搜索阶段采用 multiple spaced seeds 并通过真实比对数据学习其模式,在保证特异性的同时提升敏感性,并通过序列长度排序与覆盖约束提前剪枝,大幅减少无效比对计算 。此外,算法被设计为可在多节点环境下并行运行,从而突破单机内存与计算限制。
百万到百亿级的跨越
在实验中,研究团队对约 19亿(去冗余后约19.4 billion)蛋白序列进行了聚类分析,并在27个计算节点上完成整个计算流程,总计约25万CPU小时。
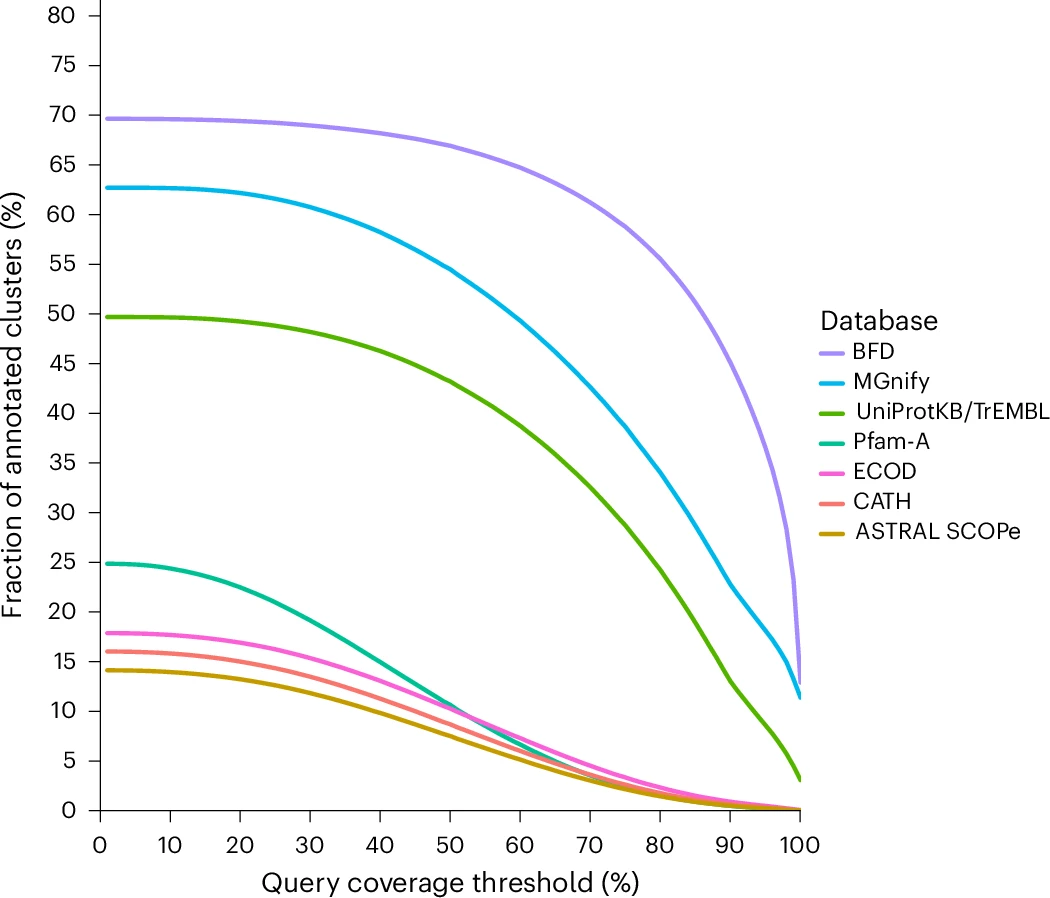
图 2:DIAMOND DeepClust 在现有数据库中对蛋白质群集的特征分析。
结果显示,这些序列被组织为约 17亿个聚类,其中仅 544百万个非单元素簇就覆盖了约94%的序列空间,表明蛋白宇宙可以被大幅压缩为更小的代表集合 。进一步分析表明,仅约 3.35亿代表序列即可覆盖92%的蛋白序列
团队利用双向覆盖标准对国家生物技术中心(NCBI)非冗余(NR)数据库(含约 5.46 亿条序列)进行了聚类。DIAMOND DeepClust 在单台 64 核心服务器上,在 19.0 小时内解决了深度聚类问题,相较于 MMseqs2 快了 36 倍。
在线性模式下,DIAMOND DeepClust 的线性模式运行时间为 3.9 小时,计算速度可进一步提升至百倍量级,同时仍维持可用的敏感性水平。
更重要的发现来自聚类结果本身。研究显示,大规模聚类后可以识别出大量此前未被数据库覆盖的蛋白家族。例如,在与现有数据库对比中,约有 1.18 亿个蛋白簇无法映射到已有资源,提示存在大量「未知蛋白空间」。
与此同时,这一聚类数据库还可以直接提升结构预测性能。当将DeepClust生成的数据用于 AlphaFold2 的输入时,可以为低覆盖序列提供更丰富的进化信息,从而改善预测质量 。这说明聚类不仅是压缩工具,更是下游 AI 模型性能的关键基础。
蛋白组学的「底层重建」
DeepClust 为未来打开了诸多可能。它能支持地球生物基因组计划,促进 AI 驱动的结构生物学,还可以催化比较基因组学。该算法通过对算法架构、并行策略和计算资源进行极致优化,将已有技术的边界推向了前所未有的远方。
DeepClust 提供的更大、更敏感的聚类数据库,有望成为下一代结构预测模型的「燃料」。当数万亿条序列即将涌入科学家的硬盘时,这样的工具正是当下迫切需要的基础设施。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





