 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库2026年3月中文大模型基准测评结果发布!小米MiMo-V2、美团LongCat上榜

SuperCLUE团队
2026/03

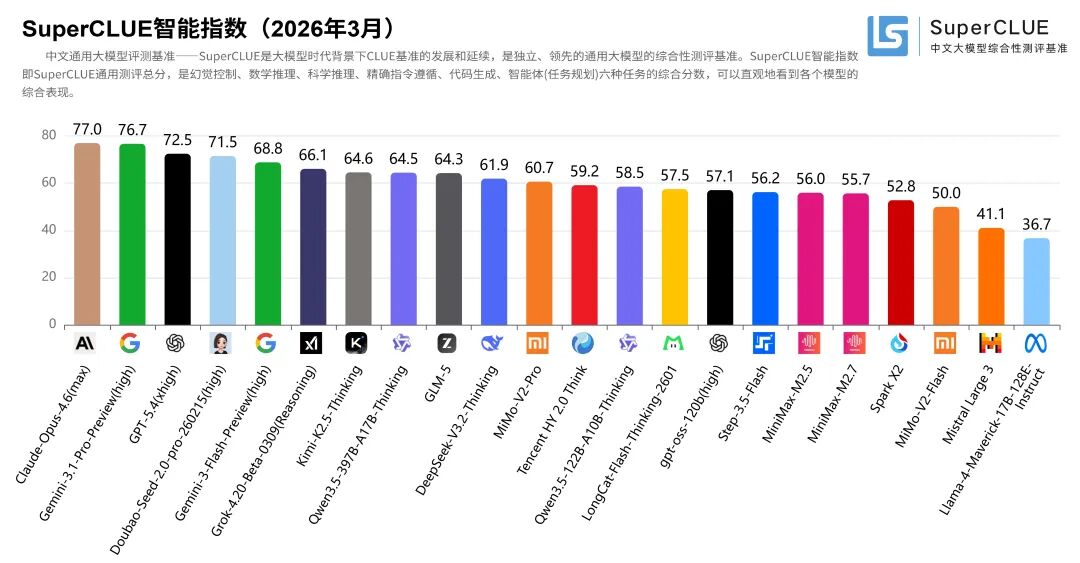
一、SuperCLUE智能指数(2026年3月)

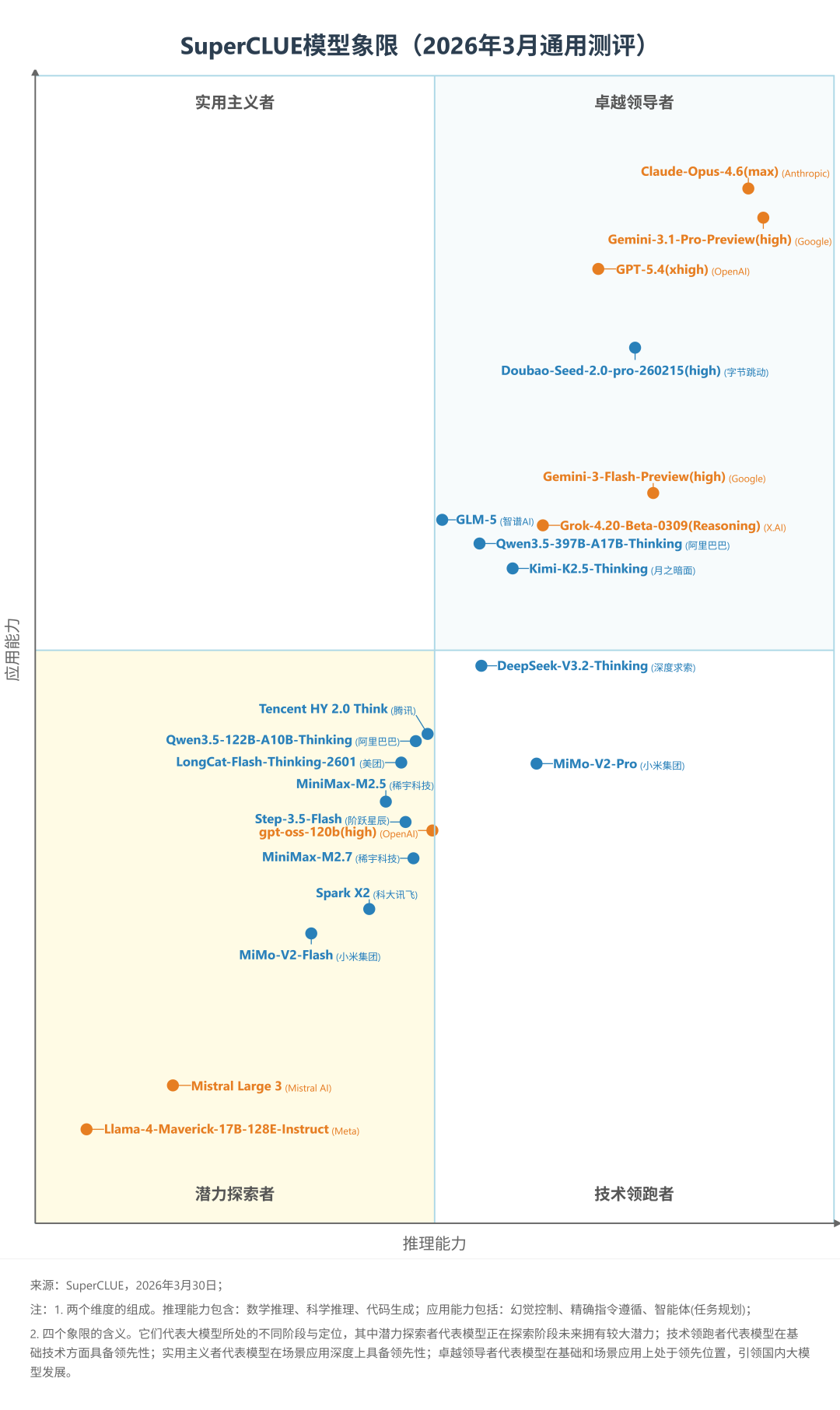
四、SuperCLUE通用测评性价比区间分布(2026年3月)
五、SuperCLUE通用测评推理效能区间分布(2026年3月)
测评摘要
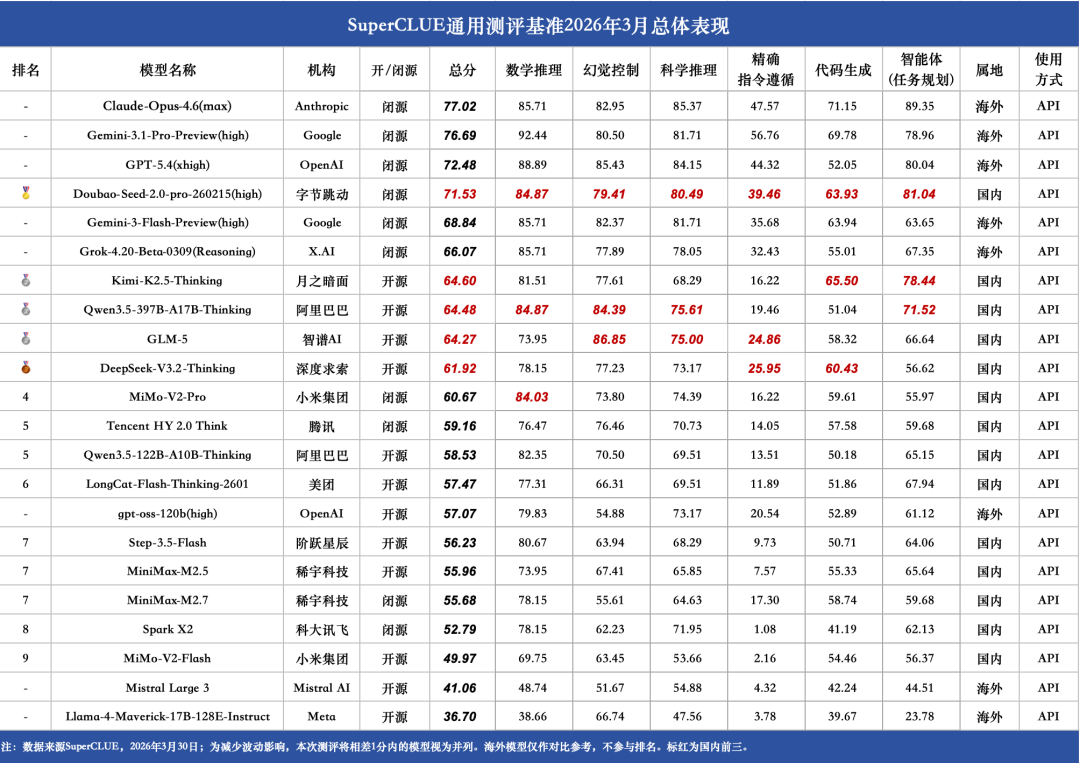
在本次2026年3月中文大模型通用基准测评中,海外闭源模型占据总分第一梯队,Anthropic的Claude-Opus-4.6(max)以77.02分位居榜首,Google的Gemini-3.1-Pro-Preview(high)和OpenAI的GPT-5.4(xhigh)分别以76.69分和72.48分紧随其后,在数学推理、科学推理等核心维度保持领先。国产头部模型Doubao-Seed-2.0-pro-260215(high)以71.53分拿下国内第一,总分仅与GPT-5.4相差0.95分,实现全方位追赶,多项核心指标跻身全球第一梯队。
测评要点2. 国内开源模型全面领先海外开源。
本次测评中,国内开源模型依旧显著领先海外开源模型,开源榜单前列均为国内模型。其中,Kimi-K2.5-Thinking(64.60)、Qwen3.5-397B-A17B-Thinking(64.48)与GLM-5(64.27)并列开源第一,领先海外开源模型gpt-oss-120b(high)(57.07)超过7分,优势明显。
测评要点3. 国内模型性价比突出。
国产模型在高性价比区形成绝对主导优势,仅Gemini-3-Flash-Preview(high)进入该区域。Doubao-Seed-2.0-pro-260215(high)、GLM-5、Qwen3.5-397B-A17B-Thinking、Kimi-K2.5-Thinking以极低的API价格实现了顶尖/中高推理质量,在得分与成本的平衡上表现突出。海外头部模型虽推理顶尖但价格远超国产,落入低性价比区;低价海外模型(如Mistral Large 3)因推理得分偏低,同样位于低性价比区。
测评要点4. 海外模型效能比突出。
海外模型在高效能区形成垄断,Gemini-3.1-Pro-Preview(high)、Gemini-3-Flash-Preview(high) 和 Grok-4.20-Beta-0309(Reasoning) 三款模型包揽了这一区域。中低效能区则以国产模型为主,其中中效能区仅有 MiMo-V2-Pro、Qwen3.5-122B-A10B-Thinking 和 Tencent HY 2.0 Think 三款国内模型入围,其余模型均集中在低效能区。整体来看,国产模型在推理质量与速度的平衡方面仍有提升空间。
中文大模型测评基准SuperCLUE持续对国内外大模型的发展趋势和综合效果进行实时跟踪,本次2026年3月通用基准测评共有22个国内外模型参与,测评集包括六大任务:数学推理、科学推理、代码生成、智能体(任务规划)、精确指令遵循、幻觉控制,共702题。
点击下方阅读原文查看完整测评内容:
SuperCLUE排行榜地址:www.superclueai.com

总体测评结果与分析
一、SuperCLUE2026年3月通用测评总体表现
二、SuperCLUE2026年3月通用测评开源模型榜单

测评分析:
国产开源模型全面领跑开源榜单,海外开源模型整体竞争力不足
从 SuperCLUE2026 年 3 月开源模型总分对比来看,国产开源模型包揽开源榜头部位置,全面领跑开源赛道。Kimi-K2.5-Thinking(64.60 分)、Qwen3.5-397B-A17B-Thinking(64.48 分)、GLM-5(64.27 分)三款国产开源模型位列开源榜前三,总分均超 64 分,大幅领先海外开源最高水平 gpt-oss-120b (high)(57.07 分),分差超 7 分;海外开源模型中仅 gpt-oss-120b 一款突破 50 分,Mistral Large 3(41.06 分)、Llama-4-Maverick-17B-128E-Instruct(36.70 分)均处于榜单尾部,与国产开源模型形成明显断层,国产开源模型在通用能力上实现对海外开源的全面超越。
三、海内外大模型对比分析
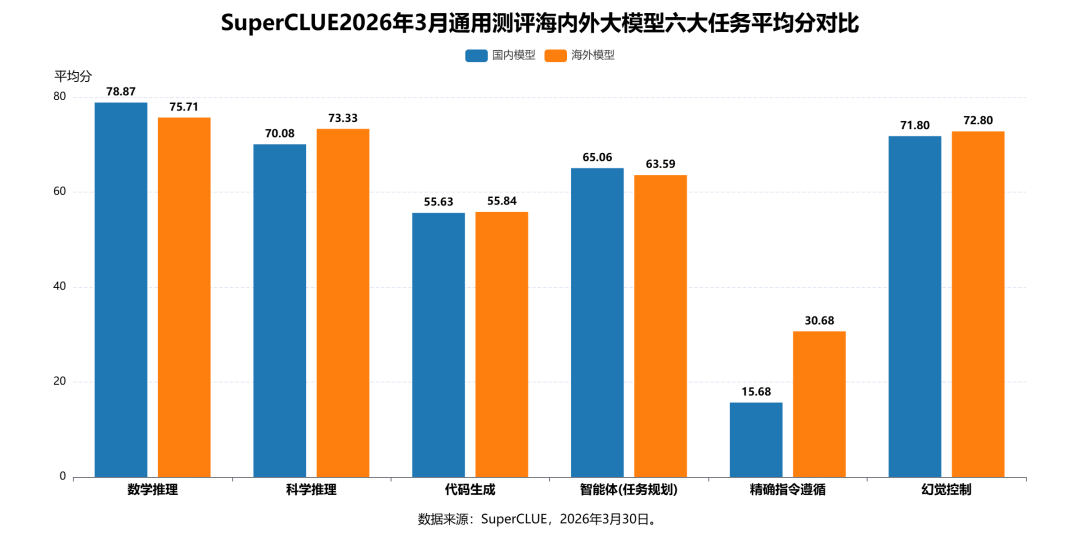
1. 六大任务平均分对比
测评分析:
(1)国内模型在数学推理、智能体任务规划两大核心维度实现对海外模型的反超
国内模型在数学推理、智能体(任务规划)两大核心能力维度实现对海外模型的反超,成为国内大模型的核心优势赛道。数学推理维度,国内模型平均分达78.87分,较海外模型的75.71分领先3.16分,是全维度国内领先幅度最大的赛道;智能体(任务规划)维度,国内模型平均分65.06分,较海外模型的63.59分领先1.47分,在智能体这一新兴核心能力上实现反超,展现出国内大模型在任务规划能力上的突出进步。
(2)多数维度海内外模型差距极小,仅精确指令遵循维度存在显著断层
从六大任务的分数差距来看,海内外模型在多数维度的能力高度接近,仅精确指令遵循维度存在极端差距。科学推理维度,国内模型平均分70.08分,海外模型73.33分,分差仅3.25分;代码生成维度,国内模型55.63分、海外模型55.84分,分差仅0.21分,几乎完全持平;幻觉控制维度,国内模型71.80分、海外模型72.80分,分差仅1分,能力高度趋同。仅精确指令遵循维度存在显著断层:海外模型平均分30.68分,是国内模型15.68分的近2倍,成为国内模型当前最大的能力短板,也是后续迭代的核心突破方向。
(3)国内模型呈现“长板突出、短板明显”的非均衡结构,海外模型能力更稳健均衡
从能力结构来看,国内模型与海外模型呈现出截然不同的特征:国内模型呈现“长板突出、短板明显”的非均衡结构,数学推理以78.87分成为全维度最高分,长板优势突出,但精确指令遵循仅15.68分,与自身长板分差超63分,能力结构极度不均衡;海外模型各维度分数分布更均衡,最高分75.71分(数学推理)、最低分30.68分(精确指令遵循),分差约45分,无极端短板,在精确指令遵循等维度形成绝对优势,整体能力结构更稳健,适配更广泛的通用场景需求。
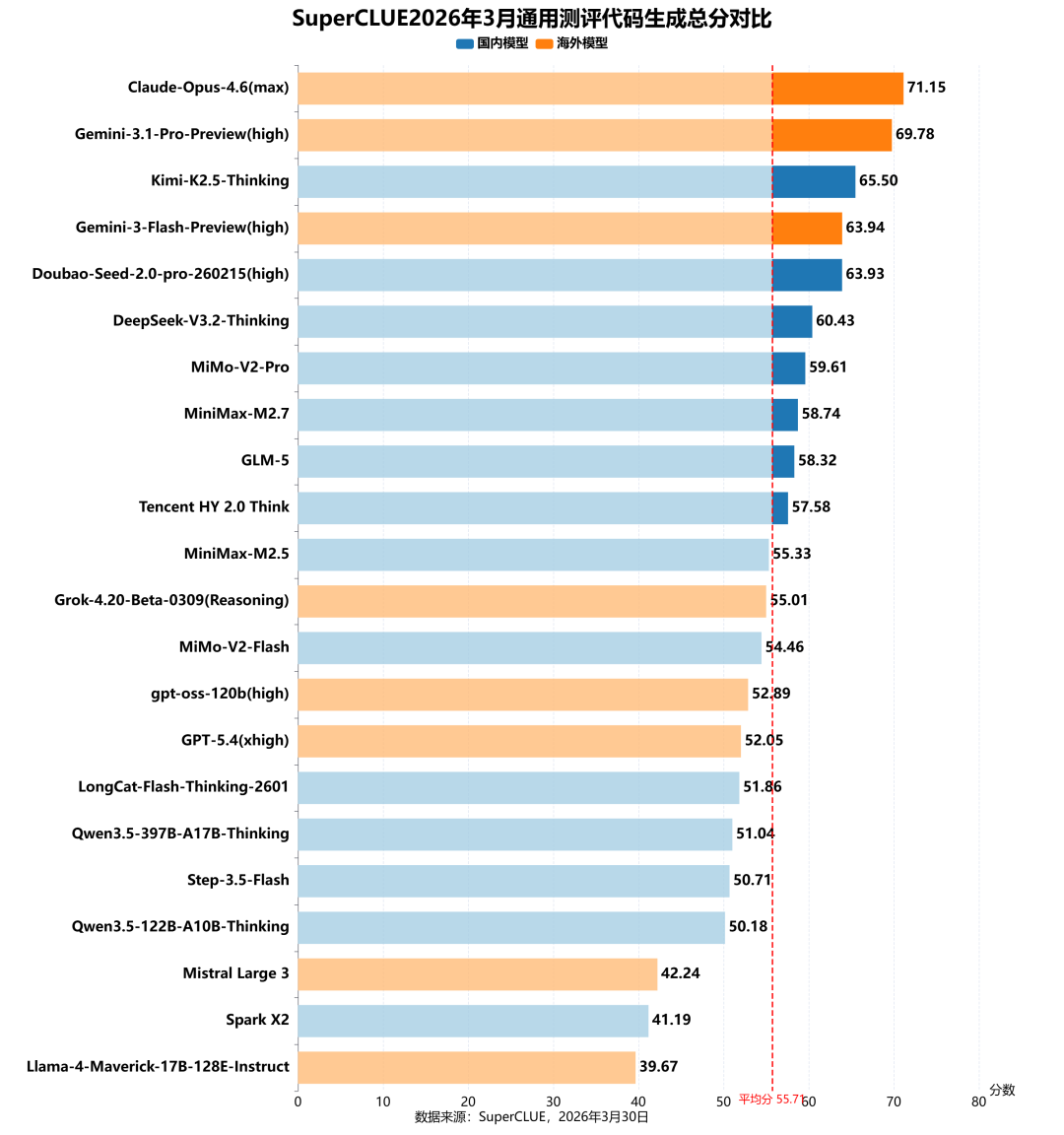
2. 代码生成任务榜单
测评分析:
海外头部模型领跑,国内模型紧随其后
在代码生成任务中,海外模型Claude-Opus-4.6(max)和Gemini-3.1-Pro-Preview(high)包揽前两名,分数分别为71.15分和69.78分。国内模型表现强劲,Kimi-K2.5-Thinking以65.50分位居全球第三,Doubao-Seed-2.0-pro-260215(high)跻身Top5,媲美国际顶尖模型Gemini-3-Flash-Preview(high),体现出国内头部模型在代码生成领域的强劲竞争力。
代码生成各子任务加权得分对比
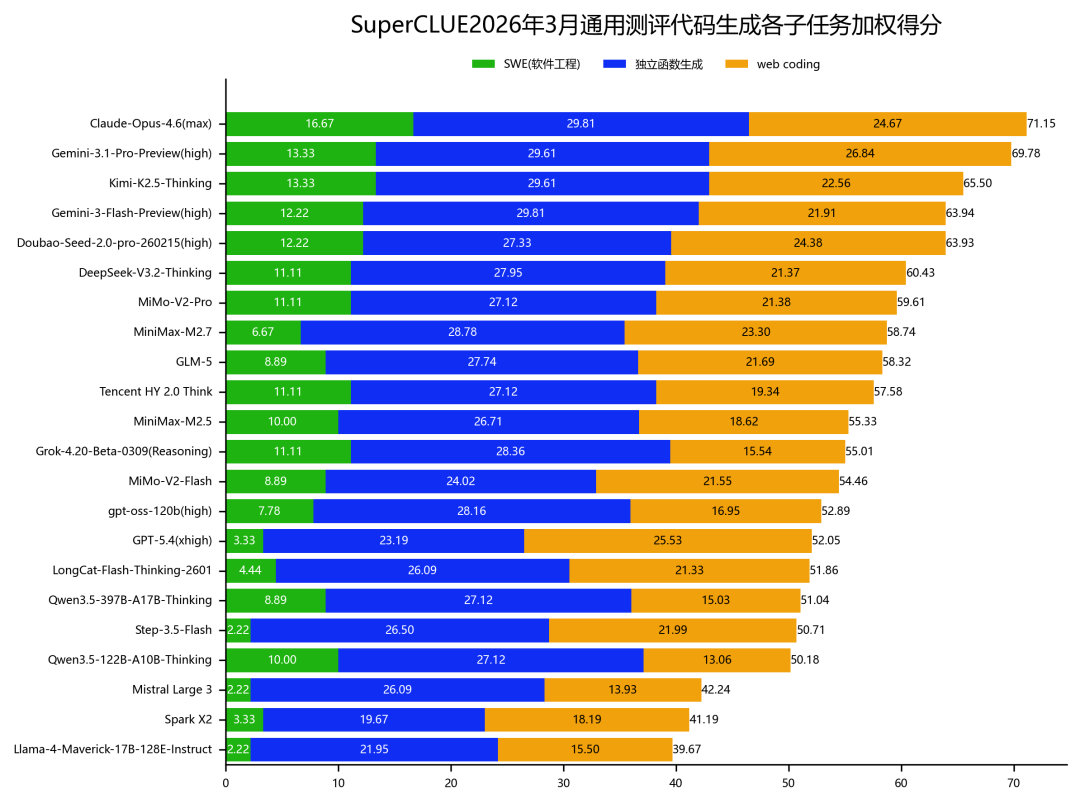
数据来源:SuperCLUE, 2026年3月30日。
注:
1. 代码生成任务最终得分由SWE(软件工程)、独立函数生成任务、Web Coding任务三大子任务求平均后得到,总分=(SWE得分 + 独立函数生成得分 + Web Coding得分)/ 3 ;
2. 绿色条形中间的数字为SWE(软件工程)任务加权后的分数,蓝色条形中间的数字为独立函数生成任务加权后的分数,橙色条形中间的数字为Web Coding任务加权后的分数,条形图最右边的数字为三大子任务加权求和得到的总分;
3. 图中展示时子任务的分数会保留两位小数,因为求和时会产生累计误差,但总分按照(SWE得分 + 独立函数生成得分 + Web Coding得分)/ 3 进行计算,不会产生累计误差。
测评分析:
(1)海内外头部模型在独立函数生成任务上旗鼓相当,趋于成熟
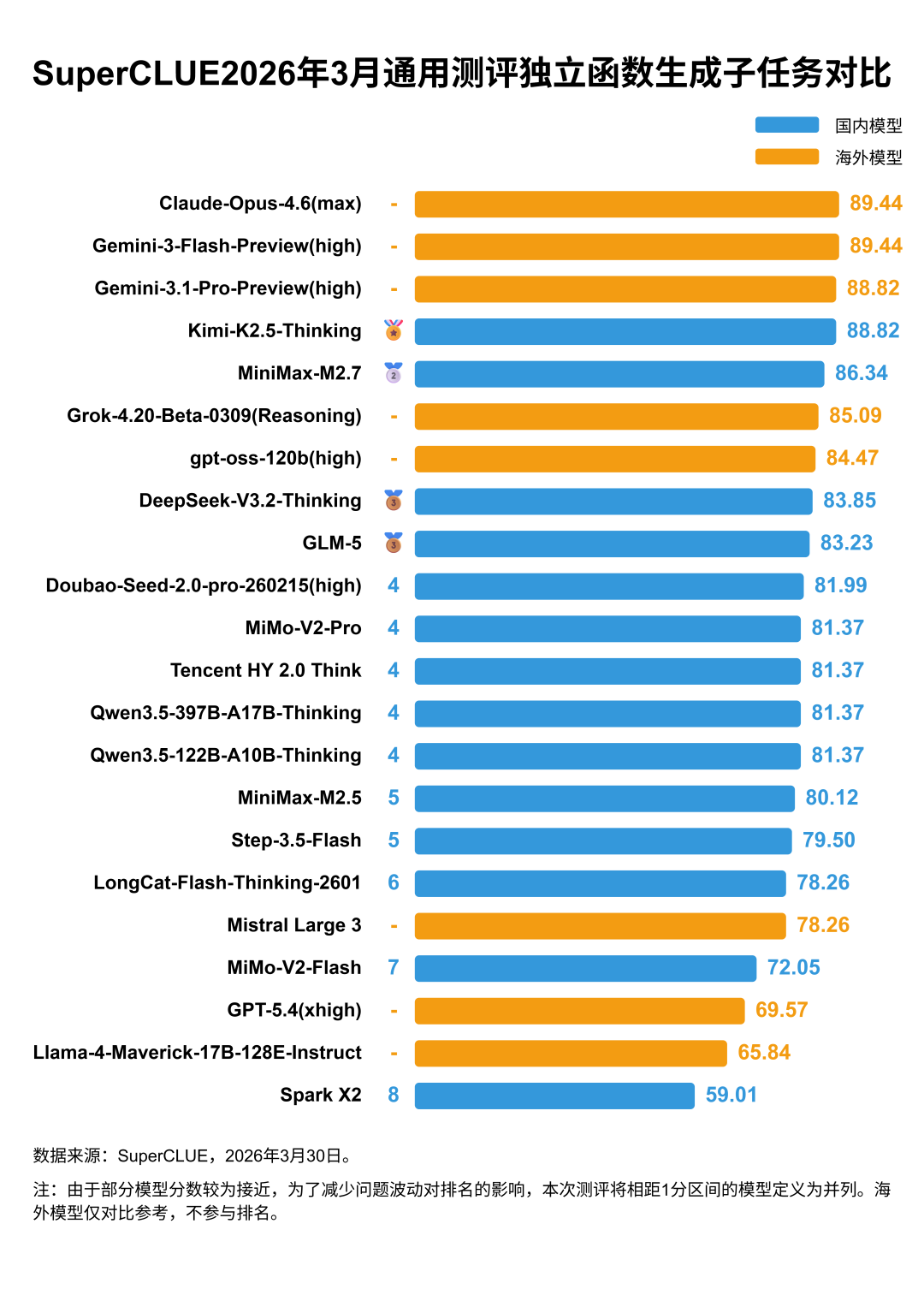
(2)Web Coding:海外头部模型占据前三,国内模型紧追不舍
海外头部模型表现更突出,Gemini-3.1-Pro-Preview(high)、GPT-5.4(high)、Claude-Opus-4.6(max)、分别取得80.53分、76.58分、74.02分,国内模型Doubao-Seed-2.0-pro-260215(high)在该子维度上取得73.14分,位居国内第一,表现亮眼,MiniMax-M2.7和Kimi-K2.5-Thinking分别以69.89分和67.69分跻身国内Top3。
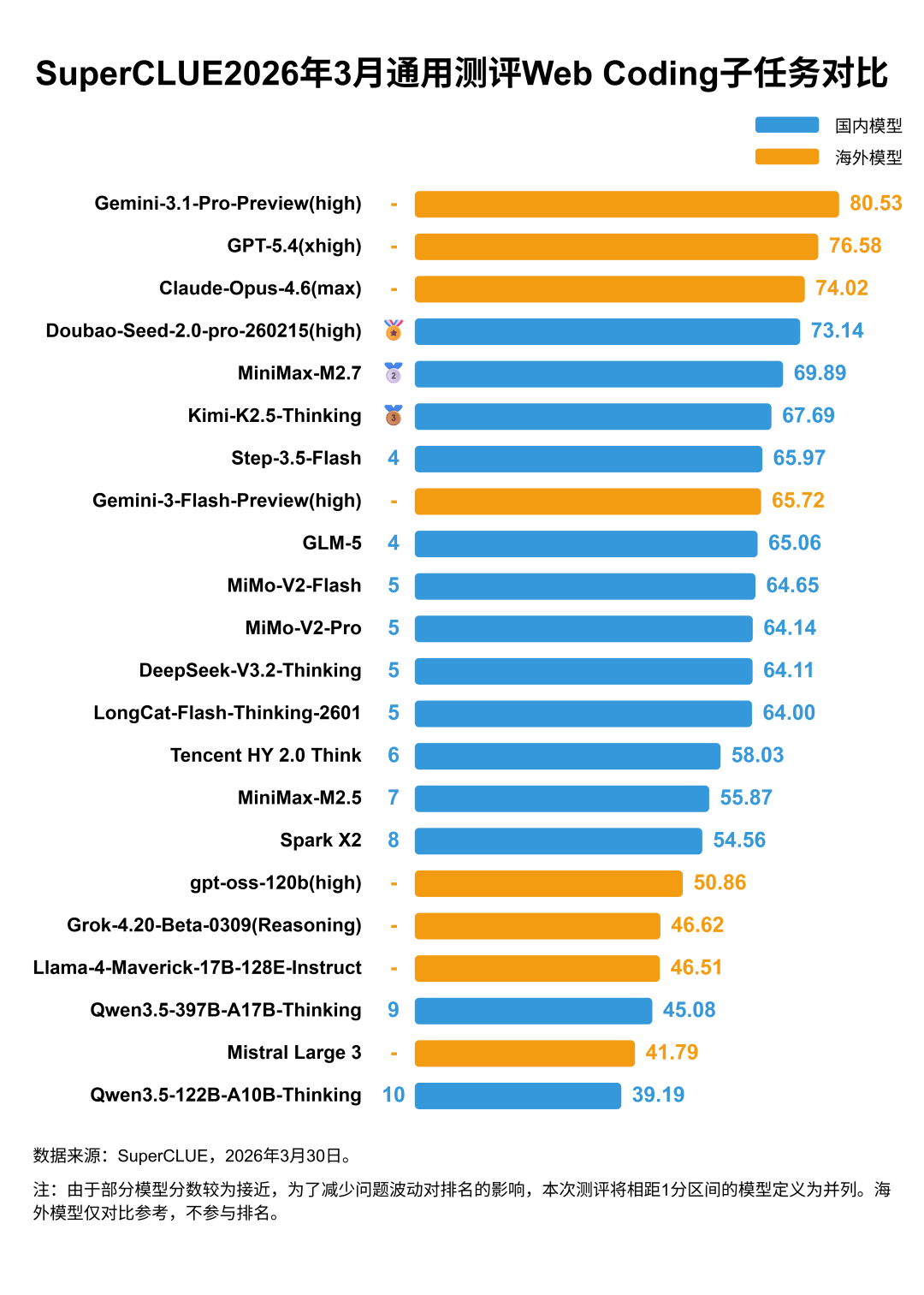
(3)SWE(软件工程):整体分数偏低,是拉开模型总分差距的核心因素
在SWE(软件工程)子任务中,海外模型Claude-Opus-4.6(max)以50.00分遥遥领先,国内模型Kimi-K2.5-Thinking以40.00分与Gemini-3.1-Pro-Preview(high)并列第二;榜单前10名中,国内模型占据7席,在中高分段形成密集分布,整体厚度显著优于海外模型,同时该子任务整体分数偏低,是代码生成中难度最高、拉开模型总分差距的核心环节。
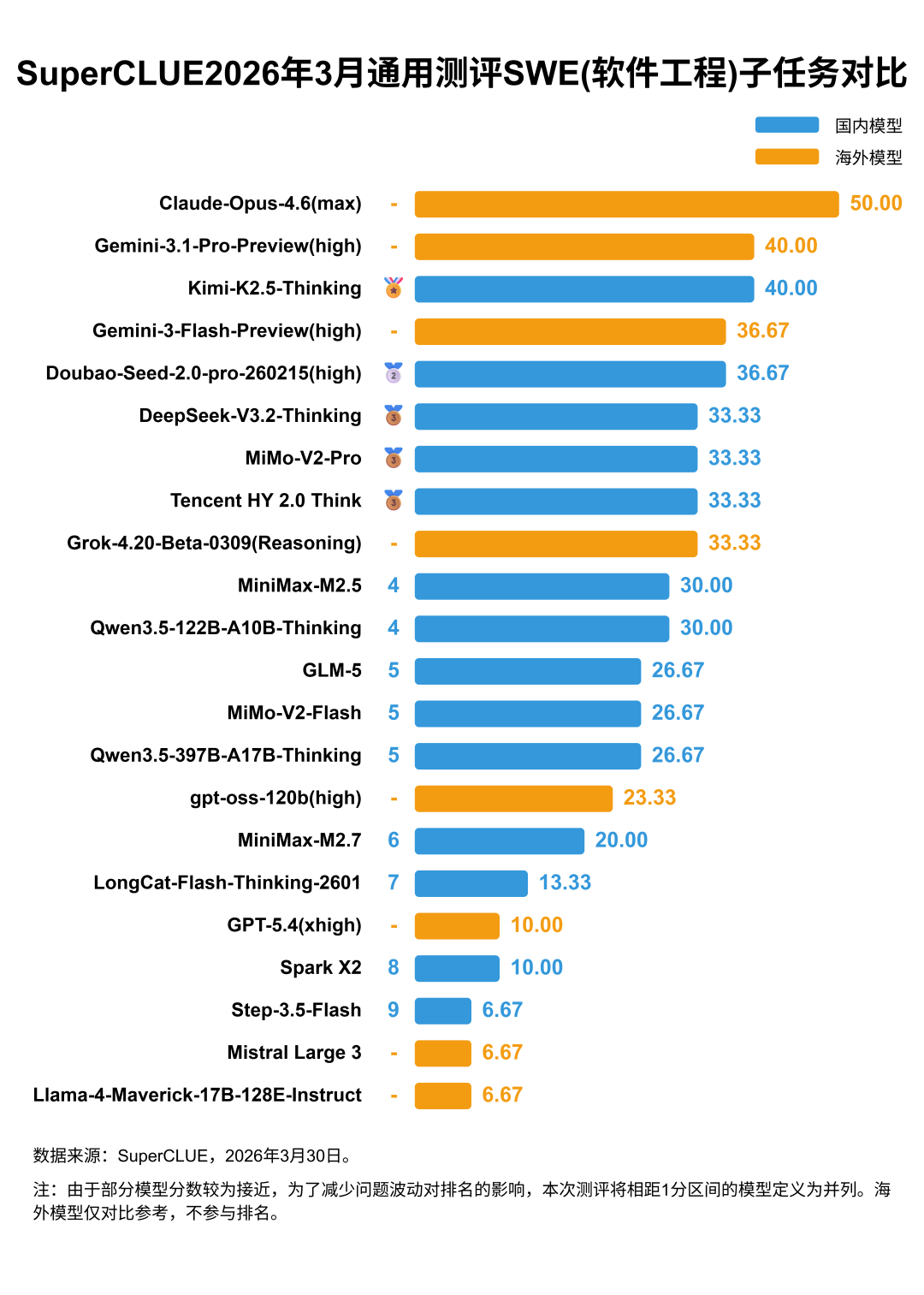
(4)SuperCLUE2026年3月通用测评代码生成各子任务平均分及标准差对比
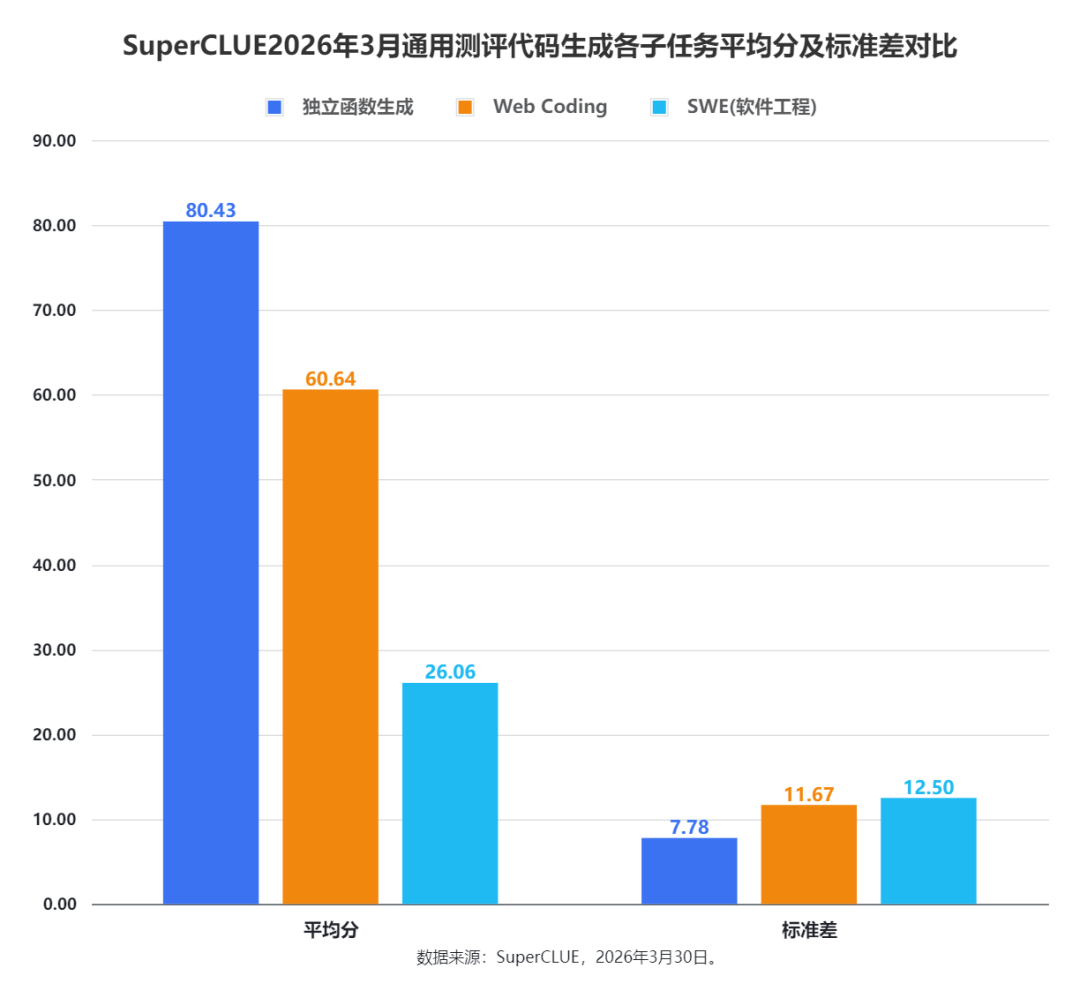
1)三大代码子任务平均分呈显著梯度,任务难度与模型整体表现负相关
从平均分维度看,三个子任务的模型整体表现呈现清晰的层级:独立函数生成以 80.43 分的平均分遥遥领先,Web Coding以 60.64 分位居中间,SWE (软件工程) 仅 26.06 分,为三个维度最低。这一梯度完全对应任务复杂度的提升:独立函数生成是单模块、规则明确的基础代码任务,模型普遍具备稳定的基础能力,因此整体平均分最高;Web Coding 是多模块、场景化的前端工程任务,对模型的场景适配、工程整合能力要求更高,平均分有所下滑;SWE 是全流程、复杂系统的软件工程任务,对模型的系统设计、工程思维要求最高,因此模型整体平均分最低,充分体现 “任务难度越高,模型整体表现越差” 的规律。
2)三大子任务标准差与平均分反向对应,任务难度越高模型能力分化越显著
结合平均分与标准差来看,三个子任务呈现 “平均分越高,标准差越低;平均分越低,标准差越高” 的反向对应关系:独立函数生成以 80.43 分的最高平均分,搭配 7.78 的最低标准差,说明模型在该任务上普遍表现优异,且能力高度趋同,差距极小;Web Coding 以 60.64 分的中等平均分,对应 11.67 的中等标准差,模型能力分化程度中等;SWE (软件工程) 以 26.06 分的最低平均分,对应 12.50 的最高标准差,说明该任务中模型能力分化最极致,头部模型可达到较优表现,但尾部模型仅能拿到个位数,充分印证 “任务难度越高,模型间能力差距越显著” 的核心规律。
3. 数学推理任务榜单
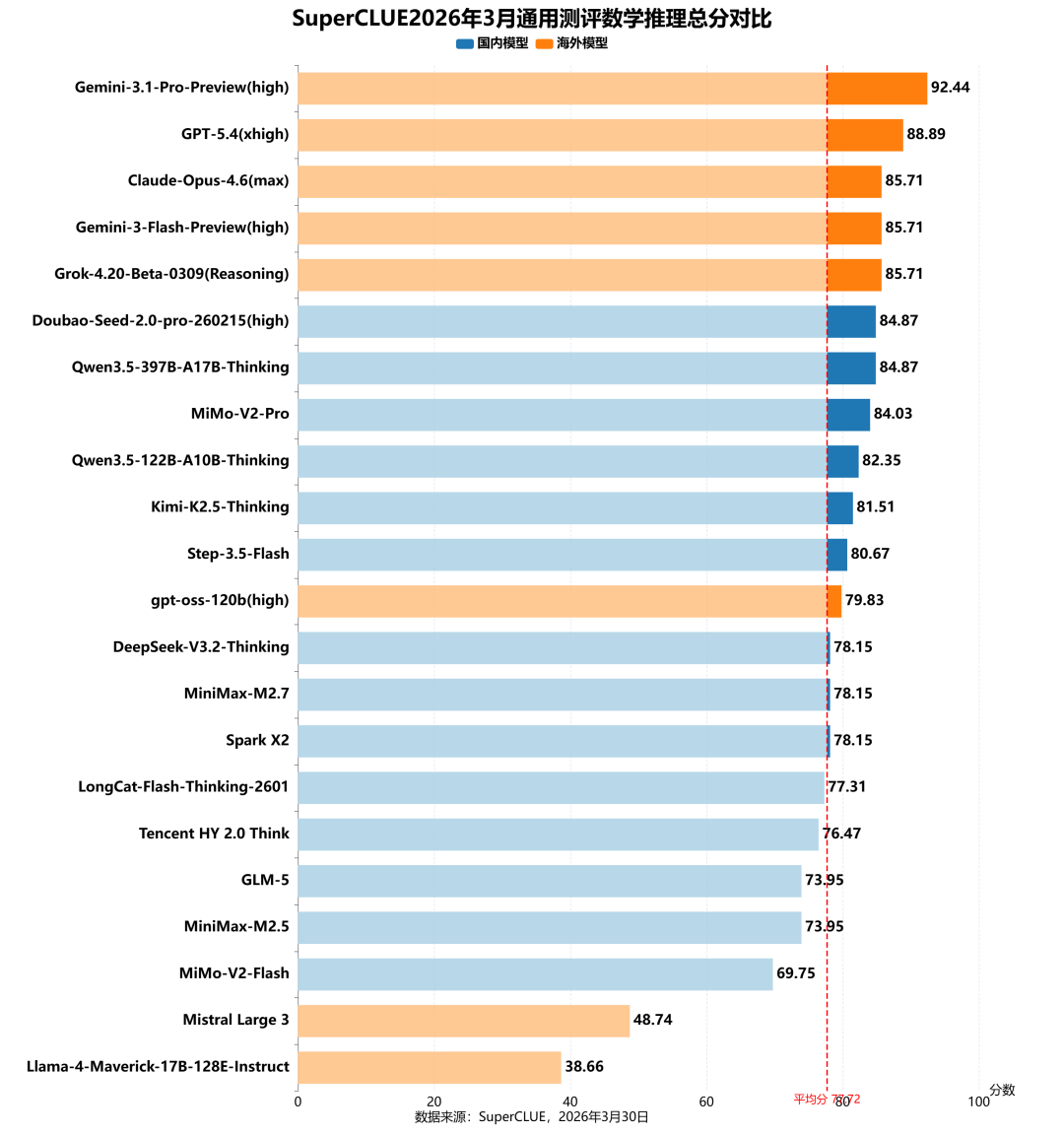
测评分析:
海外顶尖模型占据绝对领先优势,国内头部模型继续追赶
在数学推理任务中,海外模型包揽前三名:Gemini-3.1-Pro-Preview(high)以92.44分登顶,GPT-5.4(xhigh)、Claude-Opus-4.6(max)等模型紧随其后,分数均超过85分,形成了明显的第一梯队。
国内模型中,Doubao-Seed-2.0-pro-260215(high)和Qwen3.5-397B-A17B-Thinking均取得84.87分,并列全球第4;MiMo-V2-Pro(84.03)、Qwen3.5-122B-A10B-Thinking(82.35)、Kimi-K2.5-Thinking(81.51)也进入全球前10,与海外头部模型具备一定的竞争力。
4. 科学推理任务榜单
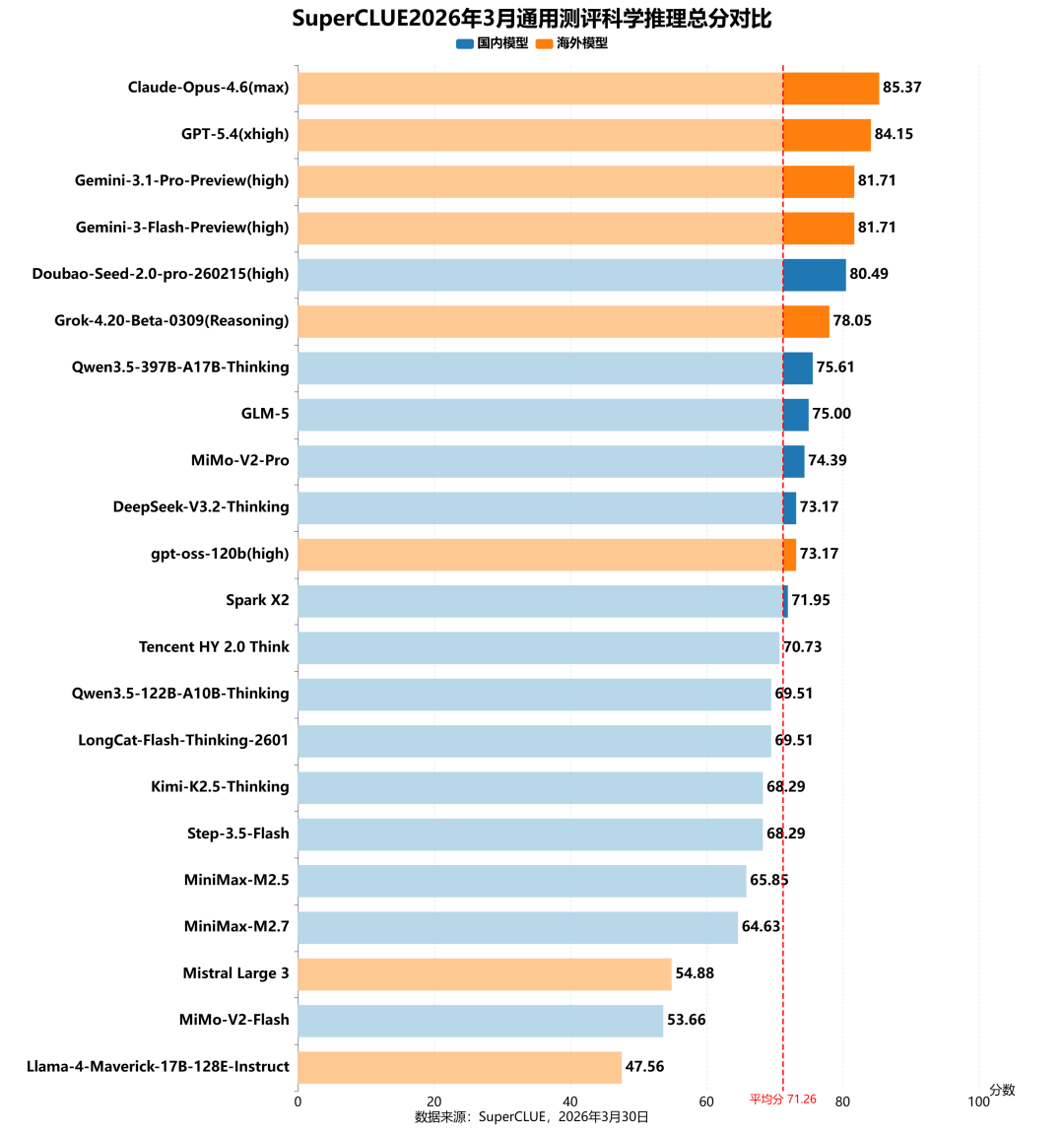
测评分析:
海外头部模型处于领先地位,国产头部紧随其后形成追赶梯队
在科学推理任务中,海外模型包揽前四名,Claude-Opus-4.6(max)以85.37分位居榜首,GPT-5.4(xhigh)、Gemini-3.1-Pro-Preview(high)、Gemini-3-Flash-Preview(high)紧随其后,分数均超81分。国内仅有Doubao-Seed-2.0-pro-260215(high)以80.49分跻身前五,展现出国产模型在科学推理领域的强劲追赶势头。国内多数模型(如Qwen3.5系列、GLM-5、MiMo-V2-Pro等)分数集中在68-76分区间,紧贴平均线上下分布,整体呈现稳健的中部梯队特征。
5. 智能体(任务规划)榜单
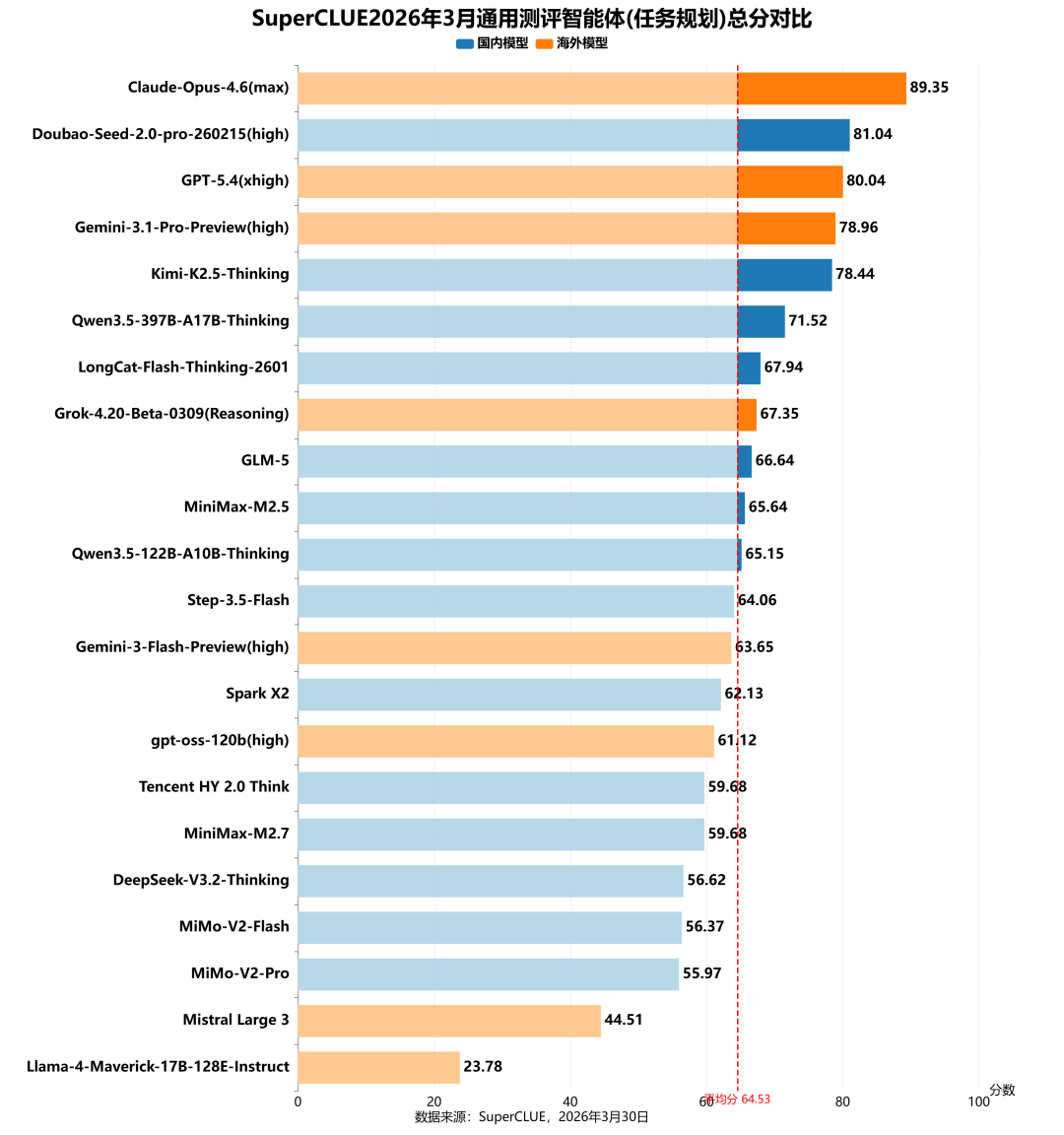
测评分析:
智能体(任务规划)维度中,海外模型 Claude-Opus-4.6 (max) 以 89.35 分位列第一,占据榜单首位。国产头部模型 Doubao-Seed-2.0-pro-260215 (high) 以 81.04 分位列第二,反超 GPT-5.4 (xhigh)(80.04 分)、Gemini-3.1-Pro-Preview (high)(78.96 分),Kimi-K2.5-Thinking 以 78.44 分位列第五,国产模型在该维度实现关键突破,成为核心优势赛道。
6. 精确指令遵循任务榜单
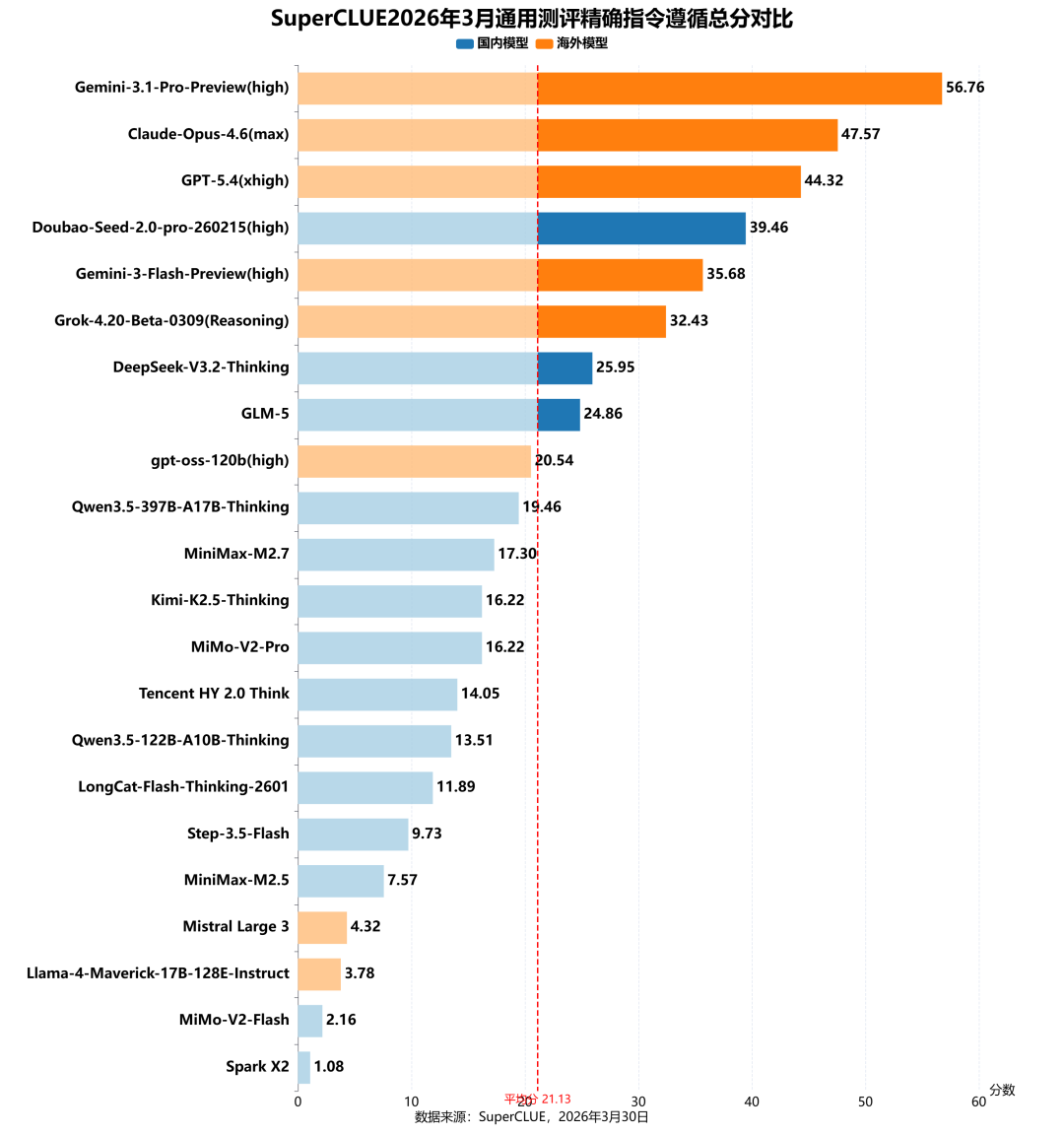
测评分析:
(1)海外模型精确指令遵循能力断层领先,国产模型差距显著
从精确指令遵循维度榜单来看,海外模型展现出断层式领先优势,与国产模型形成明显鸿沟。Gemini-3.1-Pro-Preview (high) 以 56.76 分位列第一,分数远超其他模型;Claude-Opus-4.6 (max)(47.57 分)、GPT-5.4 (xhigh)(44.32 分)分列二三位,三款海外模型分数均超 44 分。国产最高得分 Doubao-Seed-2.0-pro-260215 (high) 仅 39.46 分,与海外头部分差超 17 分,海外模型在该维度的绝对优势极为突出;国内模型平均分约19.2分,海外模型平均分约30.7分,整体差距接近11.5分,提升空间巨大。
(2)整体表现有待提升,多数模型未达平均线
精确指令遵循任务整体难度偏高,该任务的平均分仅为21.13分,超过半数模型分数低于平均线,且尾部模型得分极低(如Spark X2仅1.08分、MiMo-V2-Flash仅2.16分),两极分化严重,体现出该任务对模型指令理解与执行精度的极高要求,是当前大模型的核心短板之一。
SuperCLUE2026年3月通用测评精确指令遵循任务各难度等级平均分对比
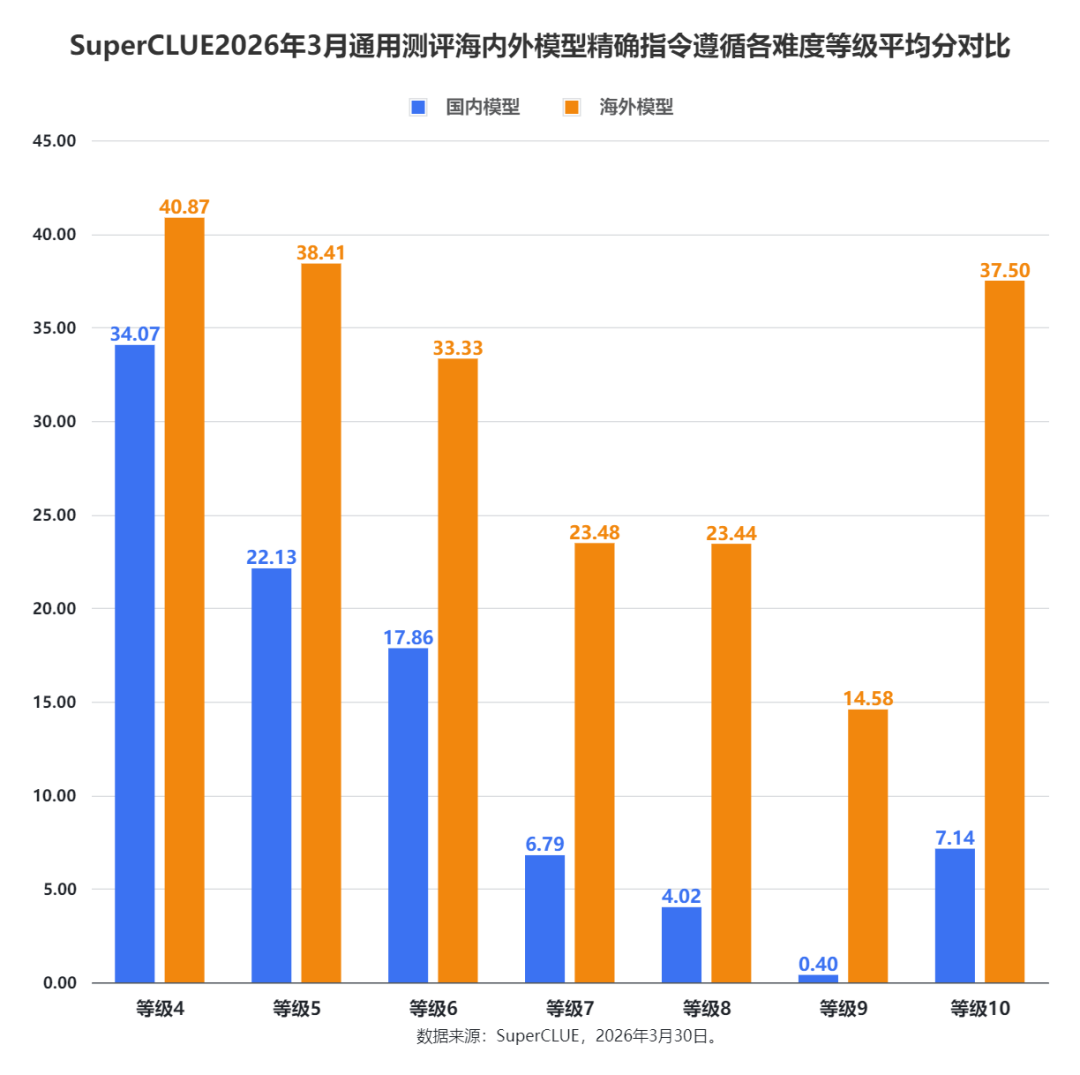
测评分析:
(1)海外模型在全难度等级实现全面领先,高难度场景优势呈指数级放大
从各难度等级的平均分来看,海外模型在精确指令遵循维度实现了全难度覆盖的绝对领先,且难度越高,优势幅度越显著。等级 4(低难度)海外 40.87 分,领先国内 34.07 分 6.8 分;等级 5-8(中高难度)海外平均分稳定在 23-38 分区间,国内仅 4-22 分,分差维持在 15-19 分;等级 9-10(极限高难度)海外优势呈指数级放大:等级 9 海外 14.58 分,是国内 0.40 分的 36 倍;等级 10 海外 37.50 分,是国内 7.14 分的 5 倍以上,高难度场景下海外形成绝对垄断,国内模型几乎丧失竞争力。
(2)国内外模型均随难度提升呈现分数下滑,国内模型在中高难度出现断崖式能力衰减
海内外模型的平均分均随难度等级提升呈现下滑趋势,但国内模型的能力衰减幅度远大于海外。国内模型从等级 4 的 34.07 分,逐步下滑至等级 6 的 17.86 分,在等级 7(中高难度)出现断崖式下跌,骤降至 6.79 分,等级 8 仅 4.02 分,等级 9 更是跌到 0.40 分,中高难度下几乎完全丧失指令遵循能力;海外模型虽也随难度提升分数下降,但整体保持稳定,等级 7-8 仍维持 23 分以上,等级 9 仍有 14.58 分,高难度下能力衰减幅度远小于国内模型,展现出更稳健的指令遵循能力。
(3)最高难度等级 10 出现特殊反弹,海外模型极限场景能力突出,国内反弹幅度有限
在最高难度等级 10,两类模型均出现分数反弹,但表现差异极大。海外模型从等级 9 的 14.58 分大幅反弹至 37.50 分,分数接近低难度等级 5 的水平,展现出在极限复杂指令场景下的顶尖适配能力;国内模型虽也从等级 9 的 0.40 分反弹至 7.14 分,但反弹幅度远低于海外,且分数仅为海外同等级的 1/5,说明国内模型在极限高难度指令遵循场景下的能力仍有极大提升空间,是后续技术迭代的核心突破方向。
7. 幻觉控制任务榜单
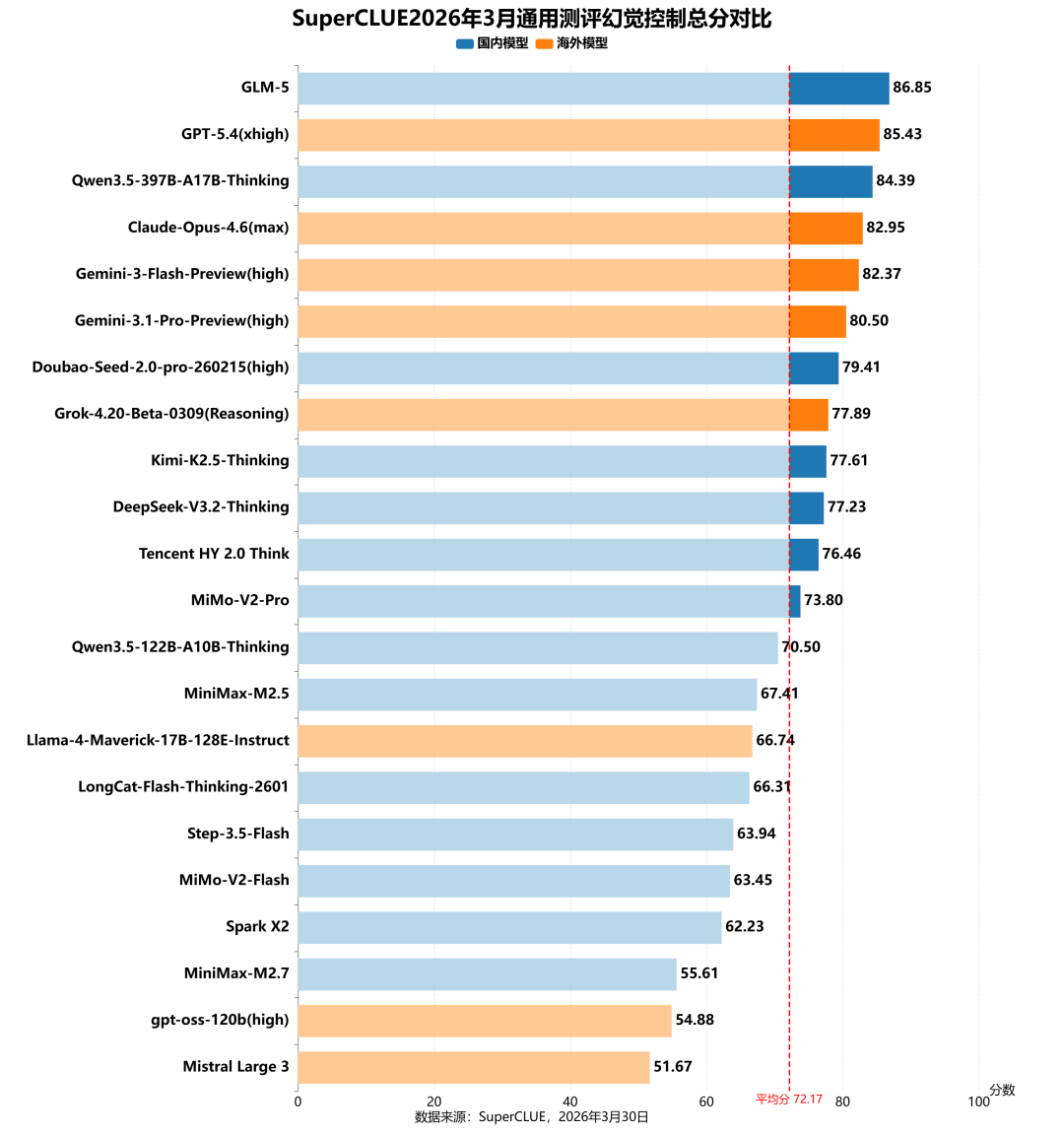
测评分析:
国内头部模型实现领跑,跻身全球顶尖梯队。
国内模型GLM-5以86.85分登顶全球第一,领先海外顶尖模型GPT-5.4(xhigh)(85.43分),展现出国内模型在事实准确性与幻觉抑制上的突破性优势。同时,Qwen3.5-397B-A17B-Thinking(84.39分)、Doubao-Seed-2.0-pro-260215(high)(79.41分)等国内模型也跻身前列,与海外头部模型差距极小。
四、开闭源大模型对比分析
1. 六大任务平均分对比
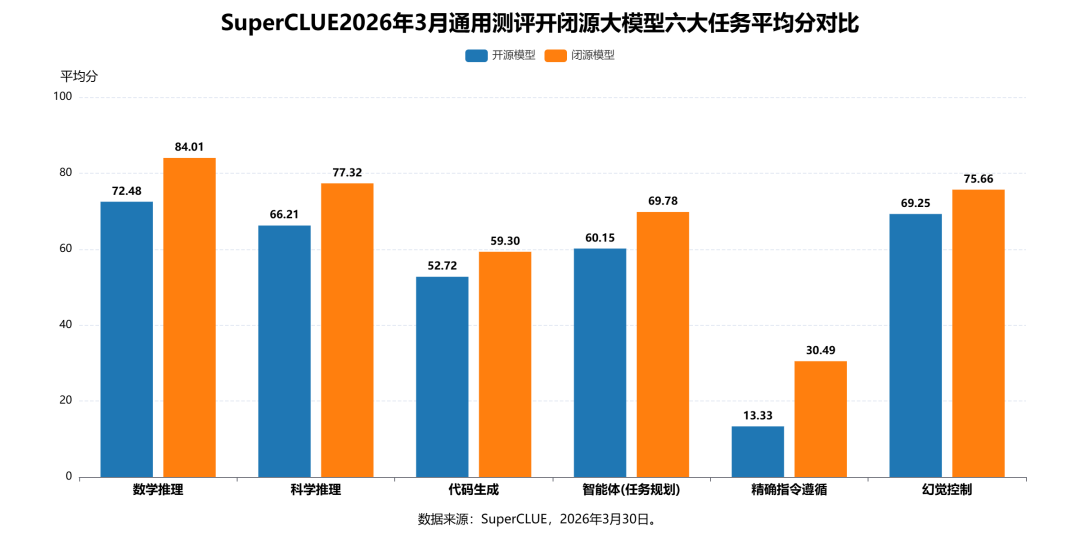
测评分析:
(1)闭源模型在六大任务中全面领先
在本次测评的全部六项任务中,闭源模型平均分均高于开源模型,尤其在精确指令遵循任务上差距最大,闭源模型领先开源模型近17分;数学推理、科学推理、智能体(任务规划)、幻觉控制等任务的分差也均在10分以上,体现出闭源模型在复杂任务与顶尖性能上的稳固优势。
(2)开源模型在代码生成和幻觉控制任务上差距收窄
开源模型在代码生成和幻觉控制领域追赶明显,开源模型在代码生成任务上与闭源模型的差距最小,分差仅约6.58分;在幻觉控制任务上的分差也控制在6.41分左右,相比推理任务和精确指令遵循等任务,开源模型在这些领域的优化成效更突出,追赶态势更为清晰。
2. 数学推理任务榜单
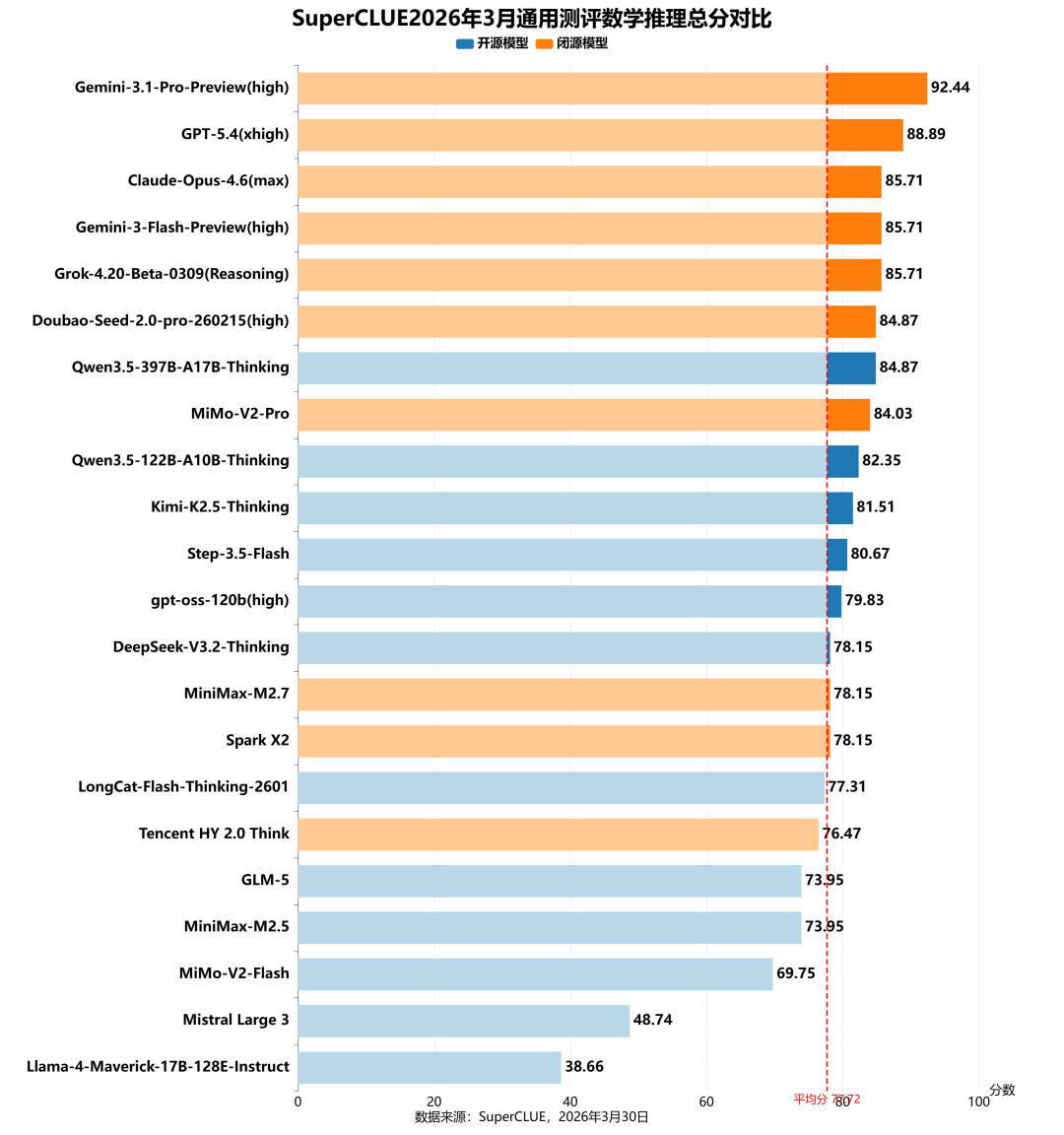
测评分析:
(1)闭源模型占据绝对领先优势
数学推理任务的Top6均为闭源模型,Gemini-3.1-Pro-Preview(high)以92.44分登顶,GPT-5.4(xhigh)(88.89)、Claude-Opus-4.6(max)(85.71)、Gemini-3-Flash-Preview(high)(85.71)、Grok-4.20-Beta-0309(Reasoning)(85.71)紧随其后,分数均超过85分。Top10中闭源模型占7席,开源模型仅占3席,且位置靠后;闭源模型整体平均分(84.01)显著高于开源模型(72.48),在数学推理任务上保持着显著的优势。
(2)国内较小参数量的开源模型具有巨大潜力
国内开源模型表现亮眼:Qwen3.5-397B-A17B-Thinking(84.87)、Qwen3.5-122B-A10B-Thinking(82.35)和 Step-3.5-Flash(80.67)均取得80分以上成绩,紧追参数量数倍于己的海内外顶尖模型,展现出小参数量开源模型在数学推理领域实现突破的巨大潜力。
3. 科学推理任务榜单
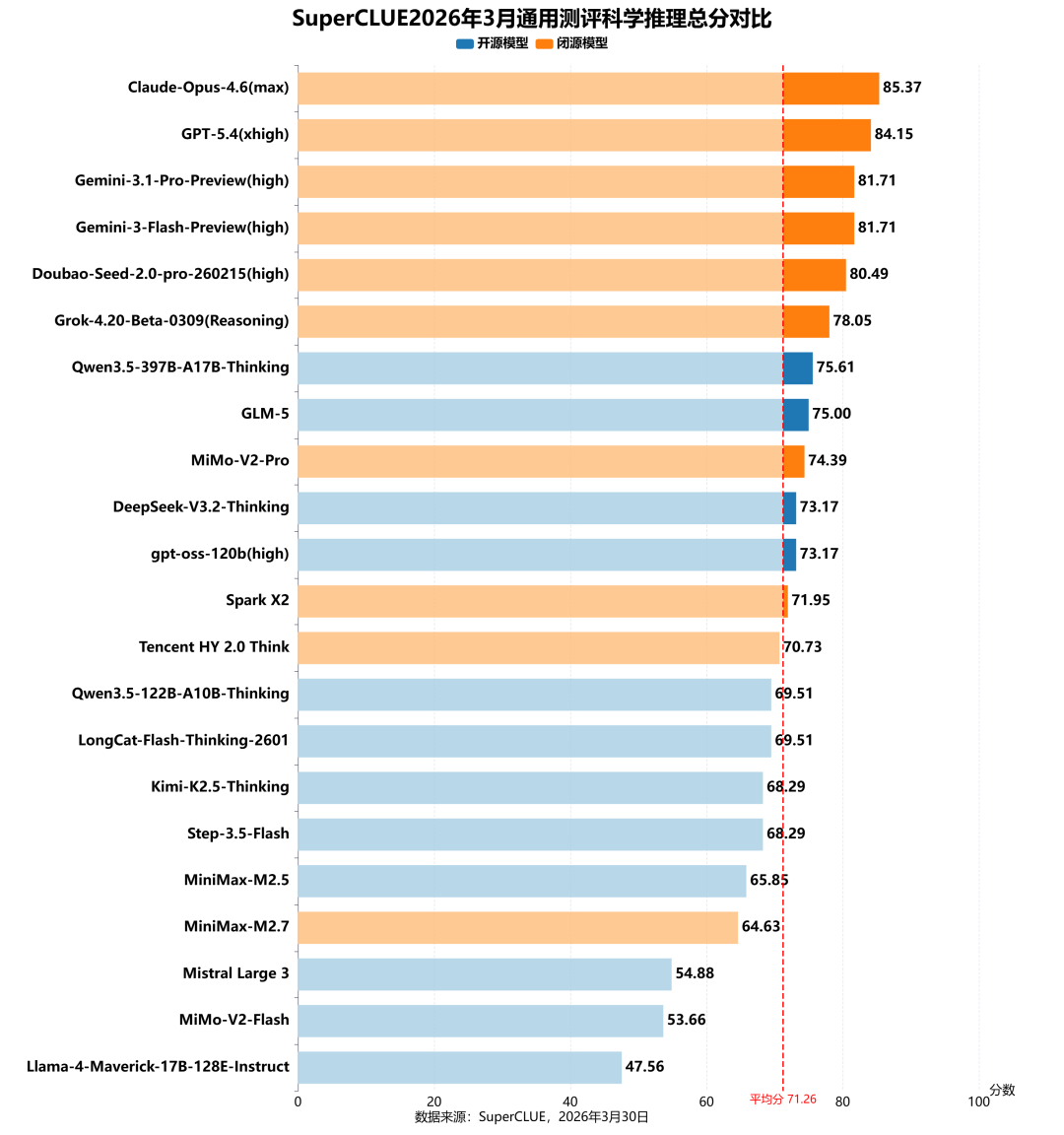
测评分析:
闭源模型优势显著。
前四名均为闭源模型,Claude-Opus-4.6(max)以85.37分领跑,Top6均为海外模型,Top10中闭源模型占7席,闭源模型整体平均分(77.32)也明显高于开源模型(66.21);国产头部开源模型Qwen3.5-397B-A17B-Thinking(75.61)、GLM-5(75.00)、DeepSeek-V3.2-Thinking(73.17)跻身Top10,表现亮眼,但多数开源模型仍处于平均线及以下,整体仍在追赶阶段。
4. 代码生成任务榜单
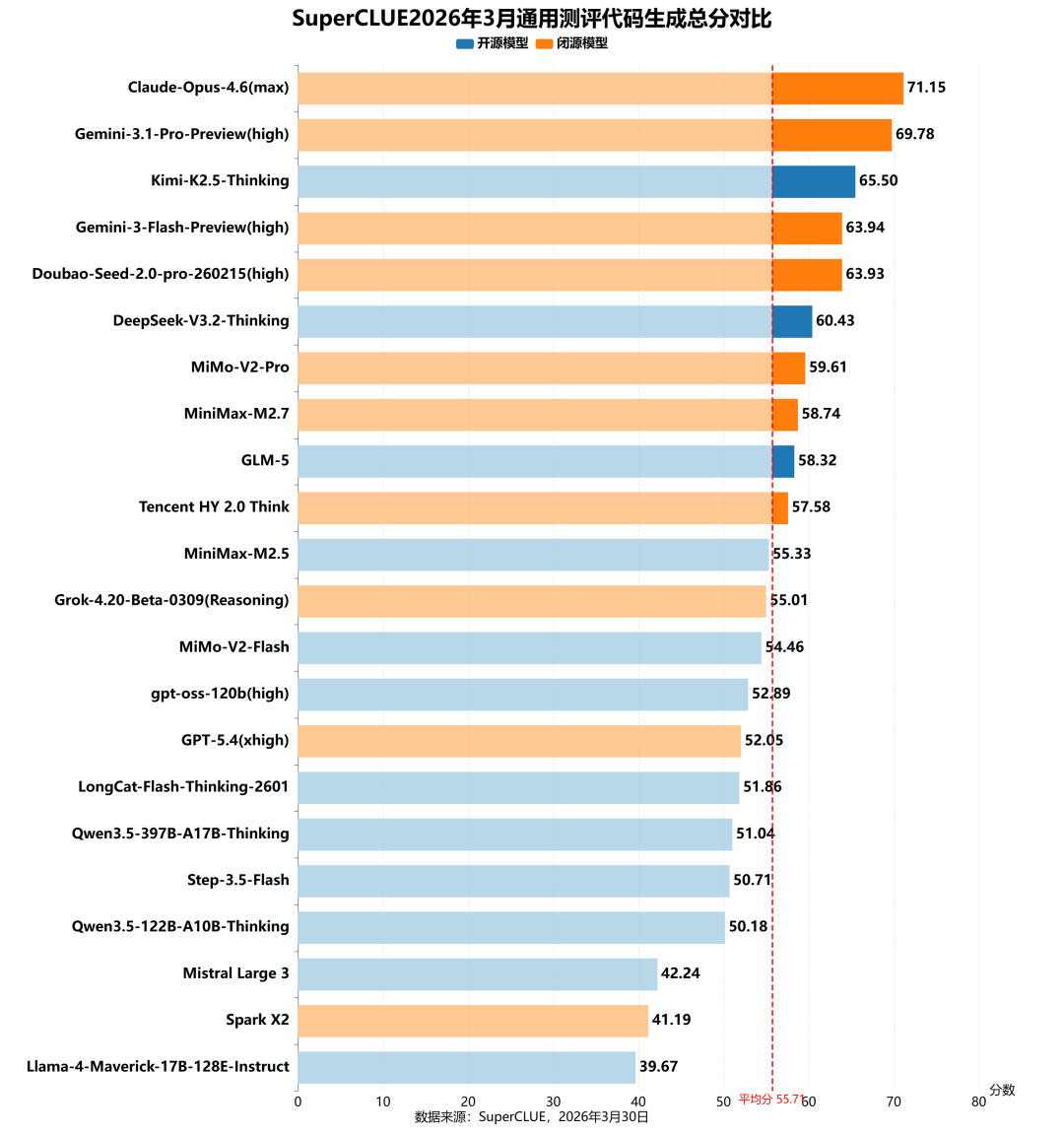
测评分析:
闭源模型占据代码生成头部优势,开源模型紧随其后
代码生成任务的前两名均为闭源模型:Claude-Opus-4.6(max)以71.15分登顶,Gemini-3.1-Pro-Preview(high)以69.78分紧随其后,形成明显的头部领先梯队。开源模型中表现最佳的Kimi-K2.5-Thinking以65.50分位居第三,与榜首闭源模型存在约5.65分的差距;Top10中仅有3个国内开源模型(Kimi-K2.5-Thinking、DeepSeek-V3.2-Thinking、GLM-5),在该任务上闭源模型(平均分59.30)整体领先开源模型(平均分52.72)。
5. 智能体(任务规划)榜单
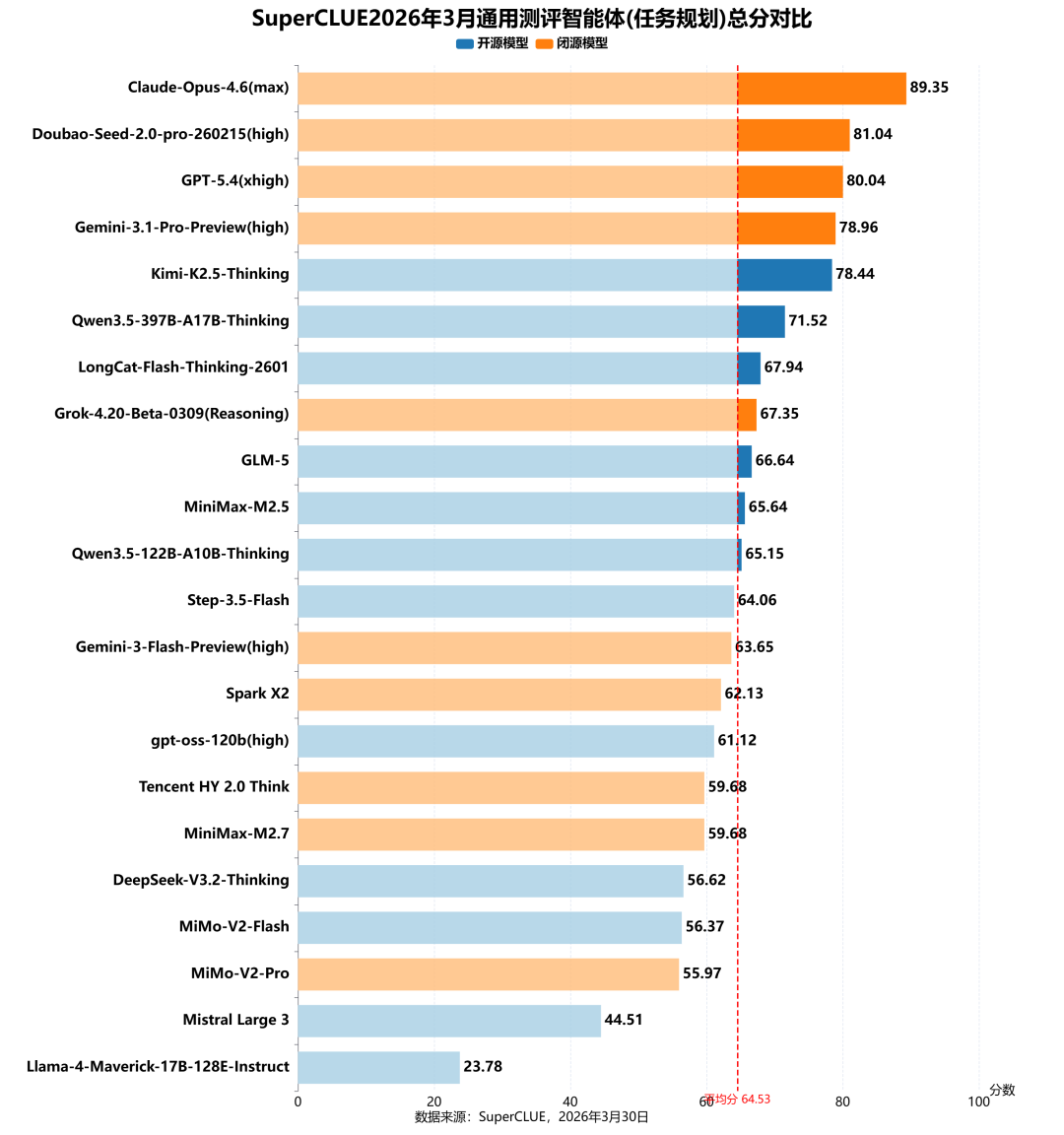
测评分析:
(1)闭源模型牢牢占据智能体任务第一梯队
头部闭源模型表现强势,Claude-Opus-4.6(max)以89.35分领跑,Doubao-Seed-2.0-pro-260215(high)(81.04)、GPT-5.4(xhigh)(80.04)、Gemini-3.1-Pro-Preview(high)(78.96)均超过78分,形成明显的第一梯队,显著领先开源模型。
(2)开源模型头部表现亮眼,整体仍处于追赶阶段
头部开源模型Kimi-K2.5-Thinking以78.44分跻身前五,Qwen3.5-397B-A17B-Thinking(71.52)、LongCat-Flash-Thinking-2601(67.94)、GLM-5(66.64)、MiniMax-M2.5(65.64)进入前十,已接近闭源模型的中上水平;但多数开源模型分数集中在平均线附近,与顶尖闭源模型仍存在明显差距,整体仍在追赶。
6. 精确指令遵循任务榜单
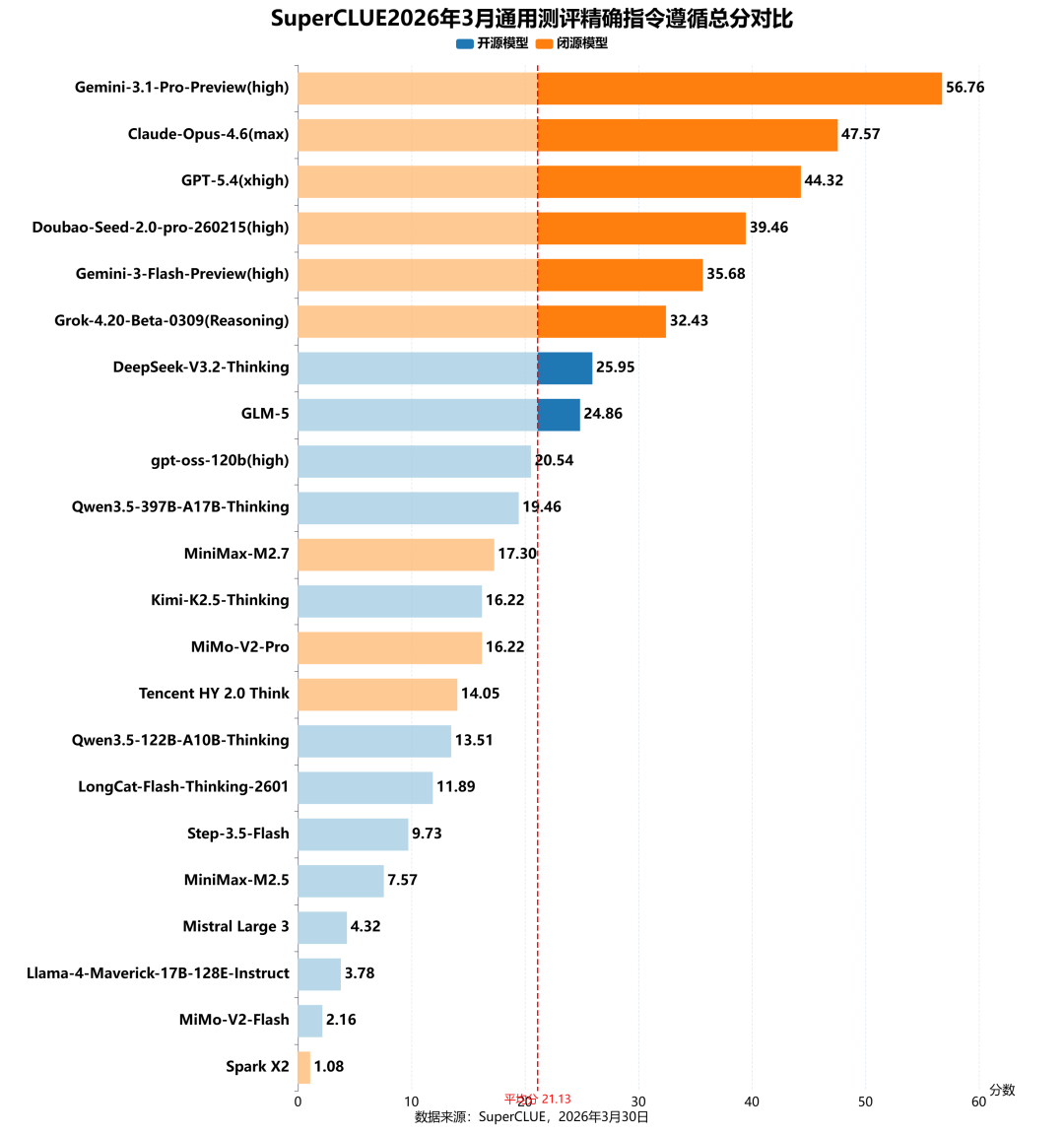
测评分析:
闭源模型在精确指令遵循任务上以绝对优势领先开源,展现出近乎碾压的态势。
精确指令遵循的榜单前五名均为闭源模型,Gemini-3.1-Pro-Preview(high)以56.76分登顶,Claude-Opus-4.6(max)(47.57)、GPT-5.4(xhigh)(44.32)、Doubao-Seed-2.0-pro-260215(high)(39.46)、Gemini-3-Flash-Preview(high)(35.68)、Grok-4.20-Beta-0309(Reasoning)(32.43)紧随其后;开源最佳模型DeepSeek-V3.2-Thinking仅以25.95分位列第七,与第一名闭源模型差距超过30分;开源模型分数普遍偏低,与闭源模型在指令理解与执行精度上存在显著差距。
7. 幻觉控制任务榜单
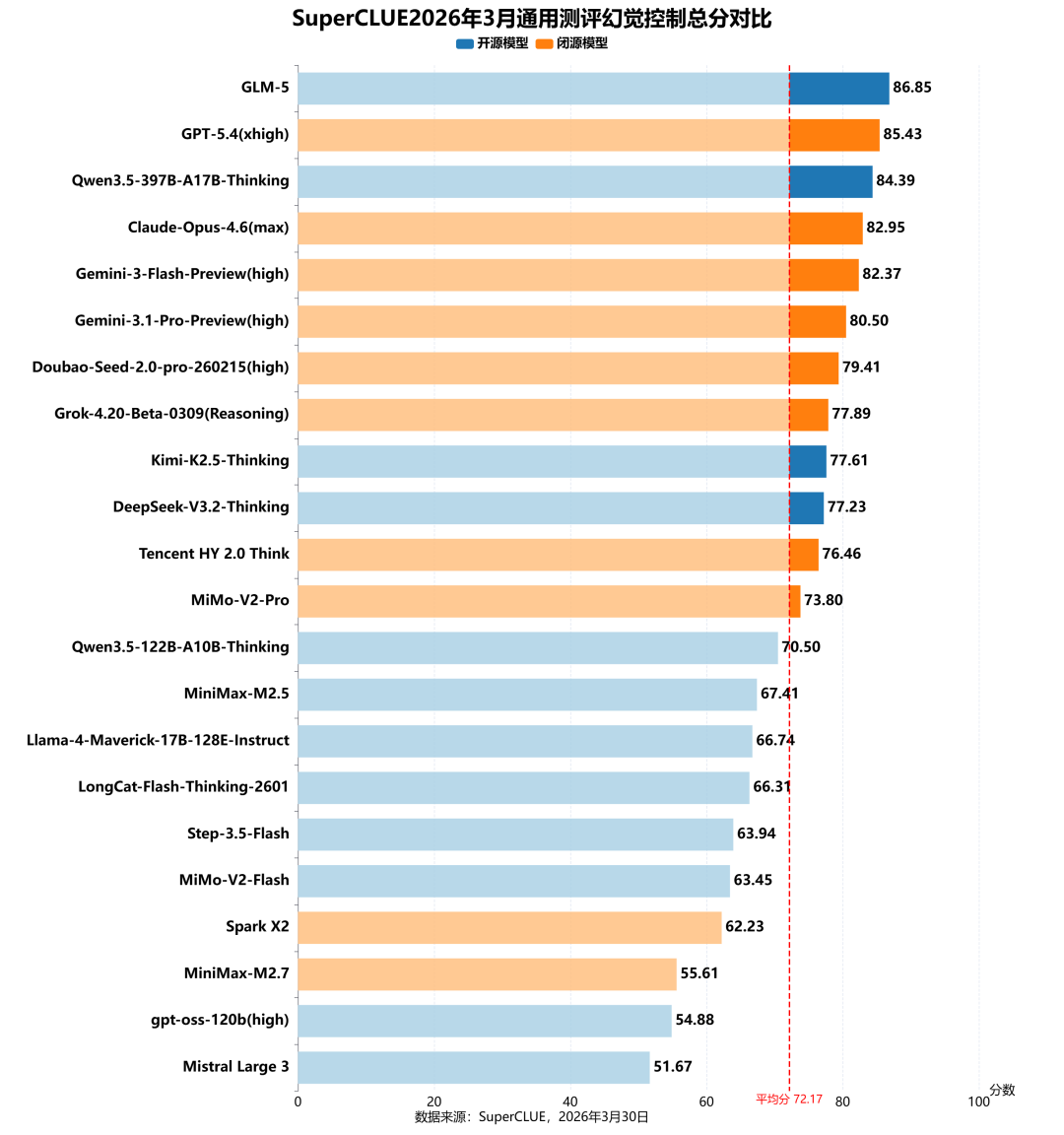
测评分析:
(1)开源模型实现登顶,头部表现亮眼
在幻觉控制任务中,开源模型GLM-5以86.85分登顶全球第一,领先闭源模型GPT-5.4(xhigh);同时Qwen3.5-397B-A17B-Thinking(84.39分)、Kimi-K2.5-Thinking(77.61分)等开源模型也跻身前列,打破了闭源模型对头部位置的垄断,展现出开源模型在事实准确性与幻觉抑制上的突破性优势。
(2)闭源模型聚集头部位置,仍保持整体竞争力
闭源模型在榜单中表现稳健,GPT-5.4(xhigh)(85.43)、Claude-Opus-4.6(max)(82.95)、Gemini系列等闭源模型占据Top10中的6个席位,与头部开源模型差距极小;整体来看,在幻觉控制任务上已形成开闭源模型同台竞争的格局,闭源模型在可靠性与稳定性上仍具备较强竞争力。
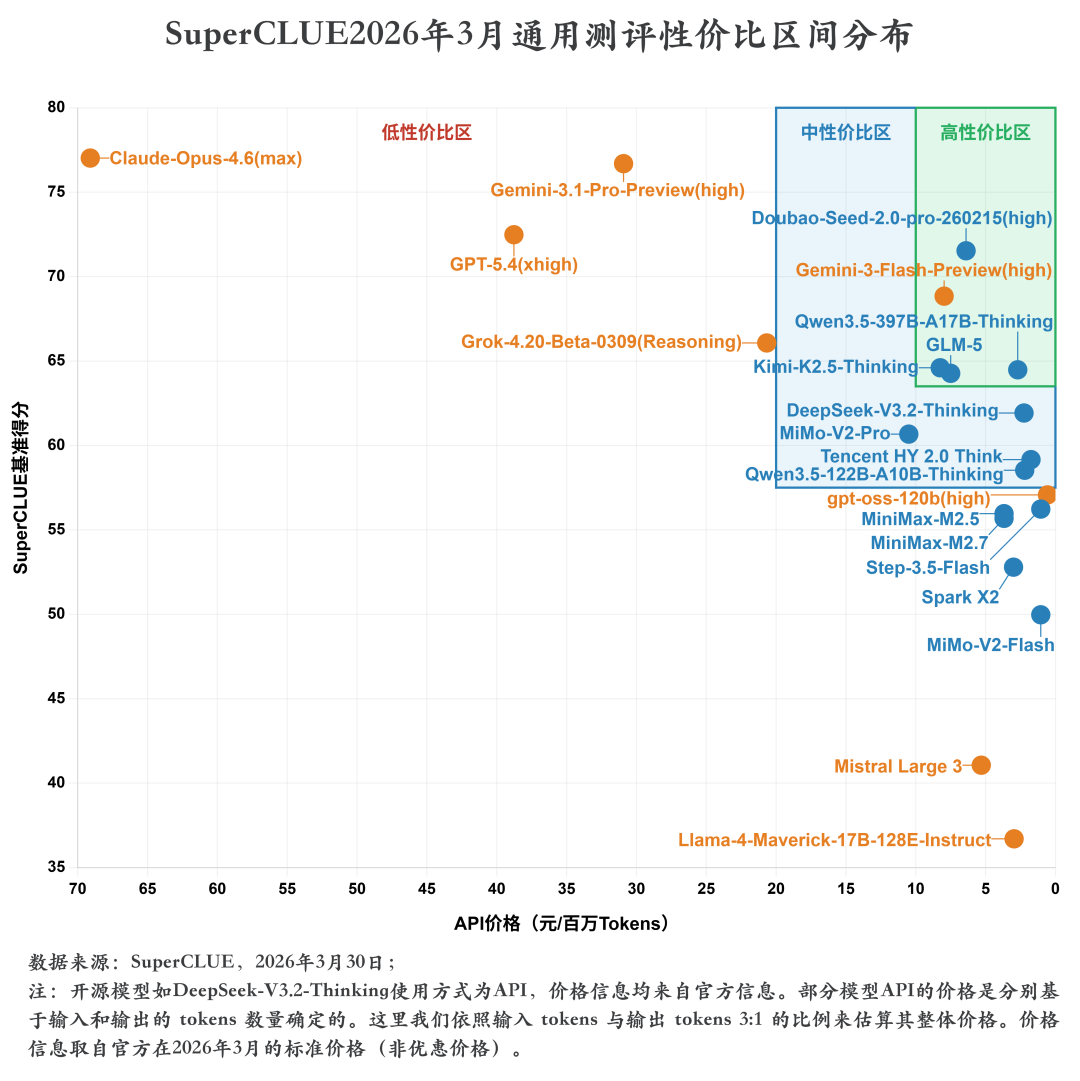
五、SuperCLUE通用测评性价比区间分布(2026年3月)
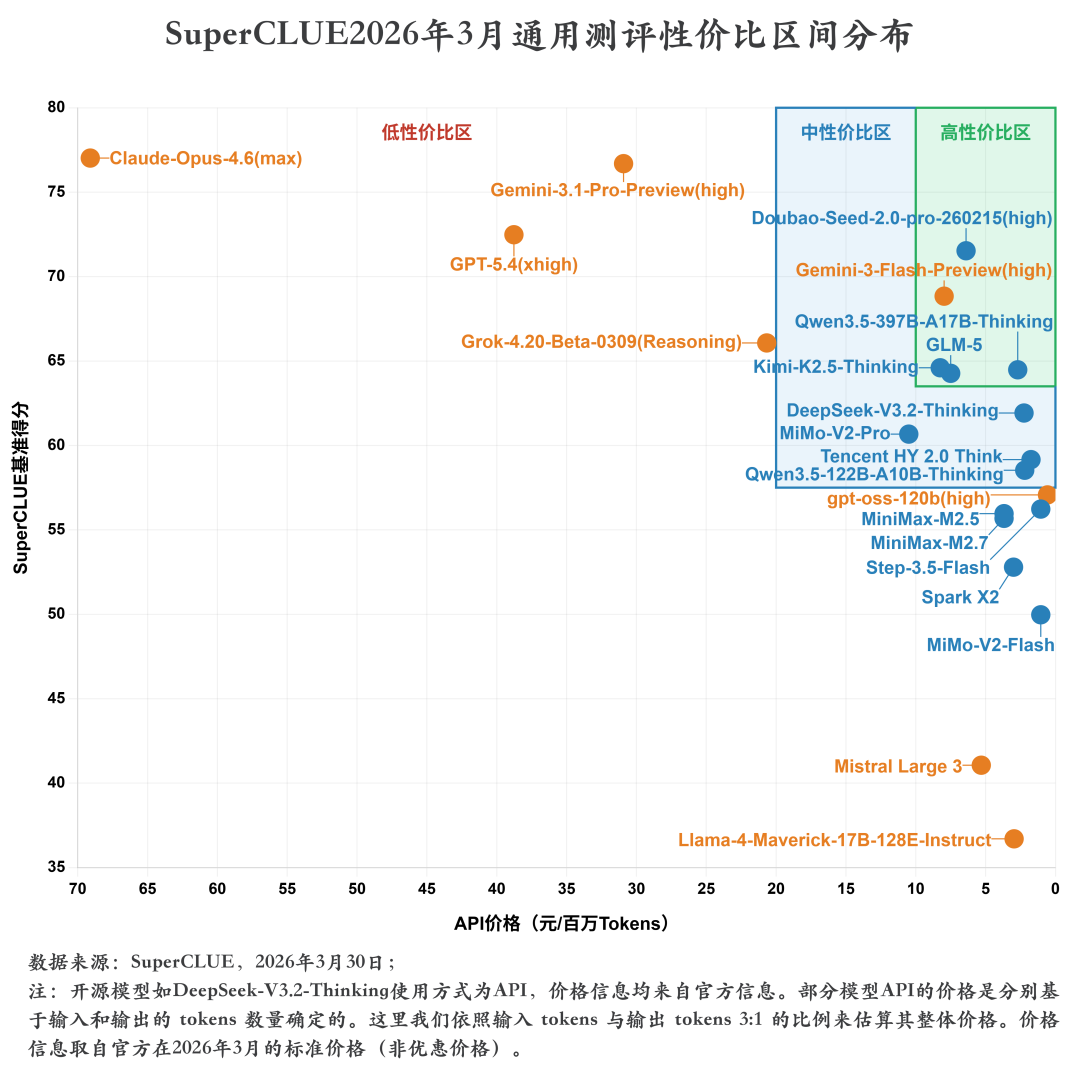
测评分析:
1. 国产模型主导高性价比区,海外模型多集中于低性价比区
国产模型在高性价比区形成绝对主导优势,仅Gemini-3-Flash-Preview(high)一款海外模型进入该区域,其余海外模型多集中于低性价比区。高性价比区中,Doubao-Seed-2.0-pro-260215(high)(总分71.53分,API价格约6.40元/百万Tokens)、GLM-5(总分64.27分,API价格约7.50元/百万Tokens)、Qwen3.5-397B-A17B-Thinking(总分64.48分,API价格约2.70元/百万Tokens)等国产模型,以极低的API价格实现了顶尖/中高推理质量,在得分与成本的平衡上表现突出。
而海外模型中,Claude-Opus-4.6(max)(总分77.02分,API价格约69.10元/百万Tokens)、GPT-5.4(xhigh)(总分72.48分,API价格约38.77元/百万Tokens)、Gemini-3.1-Pro-Preview(high)(总分76.69分,API价格约30.92元/百万Tokens)等头部模型均集中于低性价比区,虽推理质量顶尖,但API价格远超国产模型,性价比优势不足;Mistral Large 3(总分41.06分,API价格约5.31元/百万Tokens)、Llama-4-Maverick-17B-128E-Instruct(总分36.70分,API价格约2.96元/百万Tokens)等低价海外模型则因推理得分偏低,同样落入低性价比区。
2. 国产模型高度集中于中高性价比区间,海外模型分布极度分散
国产模型呈现出极强的集中性,几乎全部扎堆于横轴右侧(API 价格≤10元/百万 Tokens)的中、高性价比区,成本区间高度收敛。Doubao-Seed-2.0-pro-260215 (high)、GLM-5、Qwen3.5-397B-A17B-Thinking、Kimi-K2.5-Thinking、DeepSeek-V3.2-Thinking等主流国产推理模型,API价格均集中在2-8元/百万Tokens区间,得分覆盖60+的中高分段,在中高性价比区形成密集集群。
与之形成鲜明对比的是,海外模型分布极度分散,覆盖全价格、全得分区间:Claude-Opus-4.6 (max)、GPT-5.4 (xhigh) 等头部模型集中在35-70元/百万 Tokens的低性价比高价区;Gemini-3-Flash-Preview (high) 以7.97元/百万Tokens 的价格进入高性价比区;Mistral Large 3、Llama-4-Maverick-17B-128E-Instruct等模型落在3-5元/百万Tokens的低性价比低价区;Grok-4.20-Beta-0309 (Reasoning)、gpt-oss-120b (high)则分散在中低性价比区间连接处,整体无集中趋势,性能与成本的选择差异极大。
3. 整体呈现“得分越高,价格越高”的正相关权衡趋势,高性价比区存在技术突破点
整体符合“推理质量越高,API定价越高”的经典正相关权衡规律。低分段(60分以下)模型多集中于横轴右侧(低价区间,API价格<5元/百万Tokens),如MiMo-V2-Flash(总分49.97分,API价格约1.05元/百万Tokens)、Spark X2(总分52.79分,API价格约3.00元/百万Tokens);中分段(60-70分)模型集中于横轴中部(中价区间,API价格2-20元/百万Tokens),如GLM-5(总分64.27分,API价格约7.50元/百万Tokens)、MiMo-V2-Pro(总分60.67分,API价格约10.50元/百万Tokens);高分段(70分以上)模型除高性价比区外,全部集中于横轴左侧(高价区间,API价格>30元/百万Tokens),如Claude-Opus-4.6(max)、Gemini-3.1-Pro-Preview(high),整体呈现“要高得分,必须高成本”的权衡规律。但右上高性价比区存在明显技术突破:Doubao-Seed-2.0-pro-260215(high)(总分71.53分,API价格约6.40元/百万Tokens)、Gemini-3-Flash-Preview(high)(总分68.84分,API价格约7.97元/百万Tokens)等模型,在保持顶尖/中高推理质量的同时,将API价格压缩到传统高分模型的1/10,彻底打破了“得分越高、价格越高”的固有规律,实现了质量与成本的双优平衡,代表了大模型性价比的技术前沿。
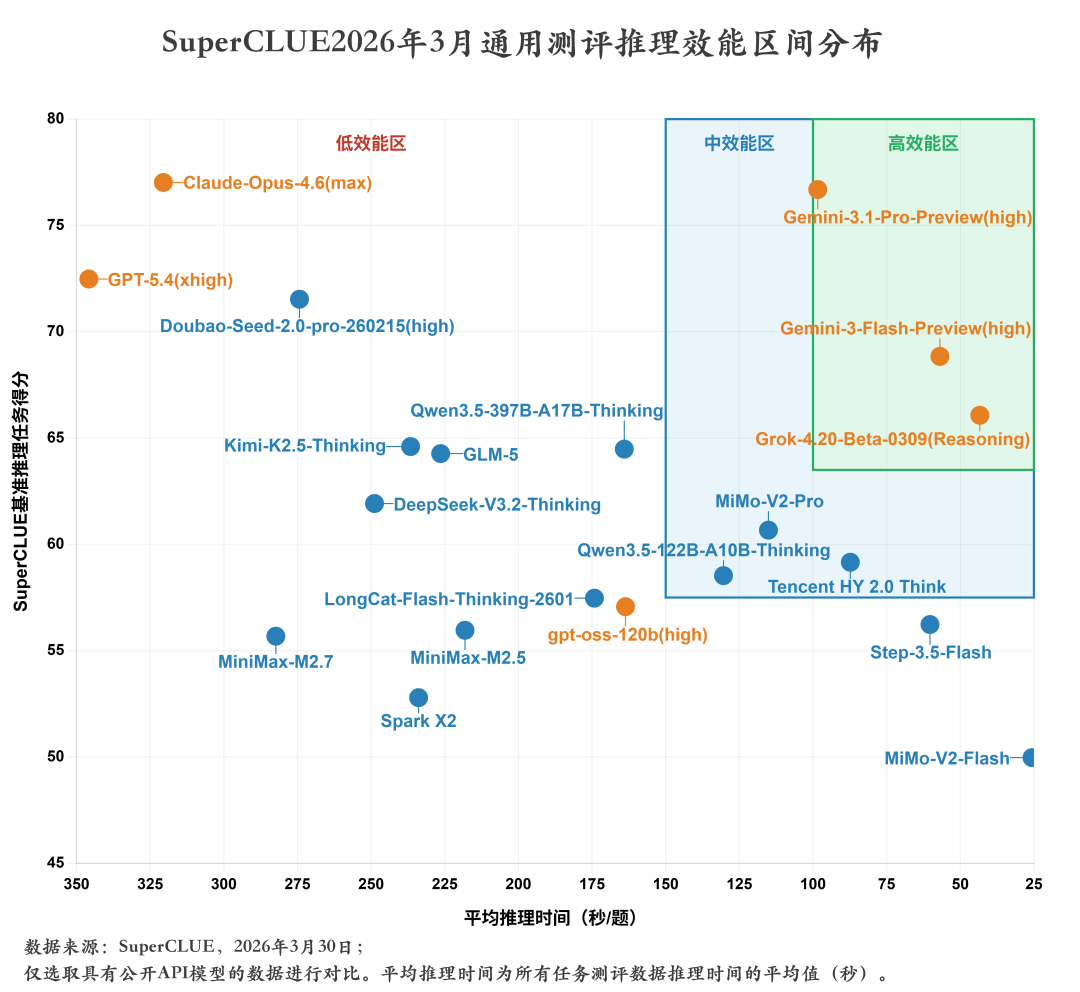
六、SuperCLUE通用测评推理效能区间分布(2026年3月)
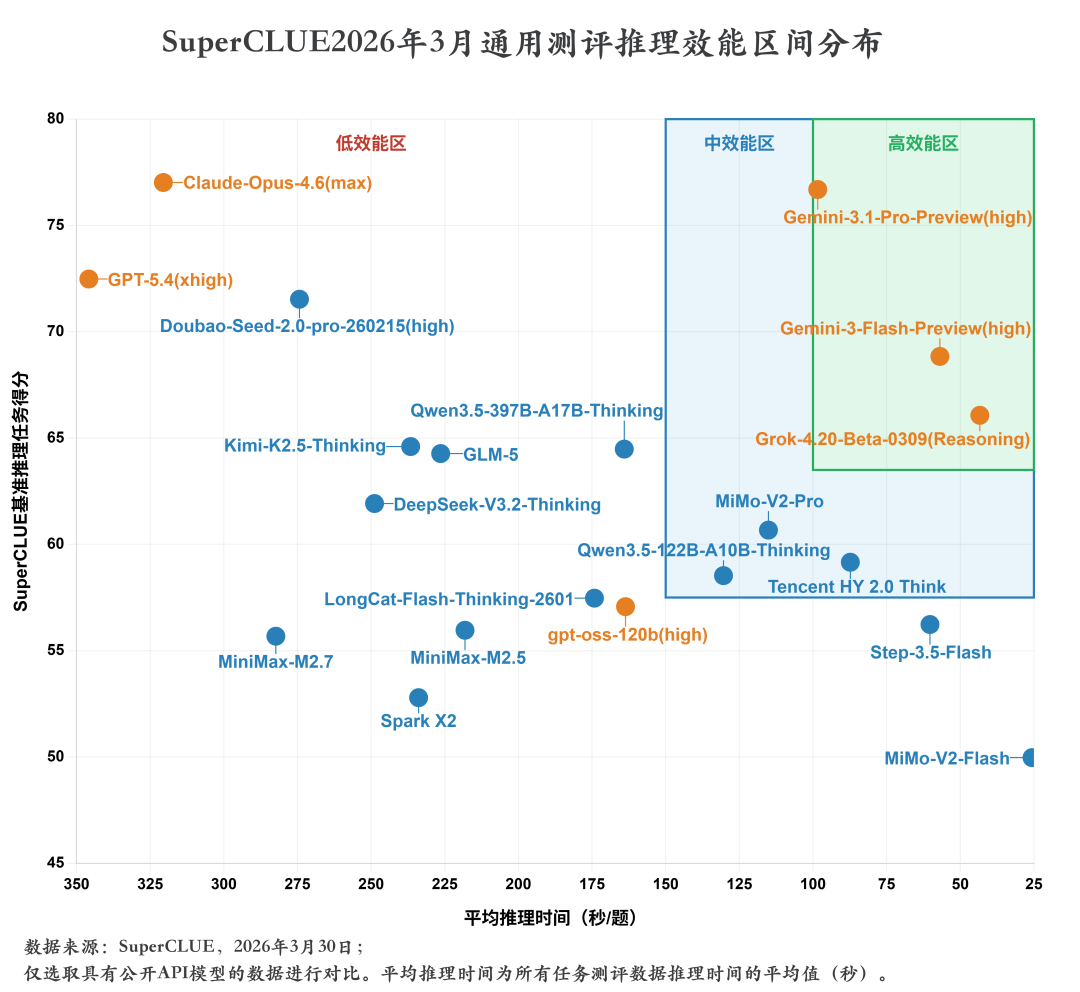
测评分析:
1. 效能分化明显:模型在推理质量与速度两个维度呈现显著离散分布
模型在推理质量与推理速度两个维度呈现出极强的离散性,无集中收敛趋势,性能跨度覆盖全区间。推理质量维度,最高分为 Claude-Opus-4.6 (max)(总分77.02分),最低分为MiMo-V2-Flash(总分49.97分),分差超27分;推理速度维度,最快模型为MiMo-V2-Flash(推理耗时25.64秒/题),最慢模型为GPT-5.4 (xhigh)(推理耗时345.82秒/题),时间差超320秒。同质量层级模型速度差异悬殊:同属70分以上第一梯队,Claude-Opus-4.6 (max) 耗时320.52秒/题,Gemini-3.1-Pro-Preview (high) 仅耗时98.39秒/题,速度差距超3倍;同耗时区间内质量分化显著:100 秒左右耗时区间,Gemini-3.1-Pro-Preview (high) 得分76.69分,MiMo-V2-Pro仅得分60.67分,分差超16分,充分体现了不同模型在推理效能上的显著分化。
2. 反向权衡关系:整体呈现"得分越高,耗时越长"的正相关趋势,但右上象限(高效能区)存在明显技术突破点
模型整体呈现出 “推理得分越高,平均推理耗时越长” 的经典正相关权衡关系。低分段(60分以下)模型多集中于横轴右侧(耗时<150秒/题),如MiMo-V2-Flash(49.97分/25.64秒)、Step-3.5-Flash(56.23分/60.29秒);中分段(60-70 分)模型集中于横轴中部(耗时100-250秒/题),如 Qwen3.5-397B-A17B-Thinking(64.48分/164.06秒)、GLM-5(64.27分/226.39秒);高分段(70分以上)模型除高效能区外,全部集中于横轴左侧(耗时>250秒/题),如GPT-5.4 (xhigh)(72.48分/345.82秒)、Claude-Opus-4.6 (max)(77.02分/320.52秒),整体符合 “质量与速度不可兼得” 的规律。
但右上高效能区存在明显技术突破:Gemini-3.1-Pro-Preview (high)(76.69分 /98.39秒)、Gemini-3-Flash-Preview (high)(68.84分/56.92秒)、Grok-4.20-Beta-0309 (Reasoning)(66.07分/43.37秒)三款模型,在保持顶尖 / 中高推理质量的同时,将平均推理时间极致压缩,彻底打破了 “得分越高、耗时越长” 的固有规律,实现了质量与速度的双优平衡,代表了大模型推理效能的技术前沿。
3. 海外模型主导高效能区,国产模型推理效能差距明显
从推理效能区间分布来看,海外模型在高效能区形成垄断优势。Gemini-3.1-Pro-Preview(high)(总分76.69/耗时98.39)、Gemini-3-Flash-Preview(high)(总分68.84,推理耗时56.92秒/题)、Grok-4.20-Beta-0309(Reasoning)(总分66.07,推理耗时43.37秒/题)三款海外模型独占高效能区。中效能区由MiMo-V2-Pro、Qwen3.5-122B-A10B-Thinking、Tencent HY 2.0 Think三款国内模型占据。低效能区中国产模型扎堆现象突出。Doubao-Seed-2.0-pro-260215(high)、Kimi-K2.5-Thinking、GLM-5、Qwen3.5-397B-A17B-Thinking、DeepSeek-V3.2-Thinking等主流国产推理模型均集中于此,推理质量与推理速度的平衡还有一定提升空间。
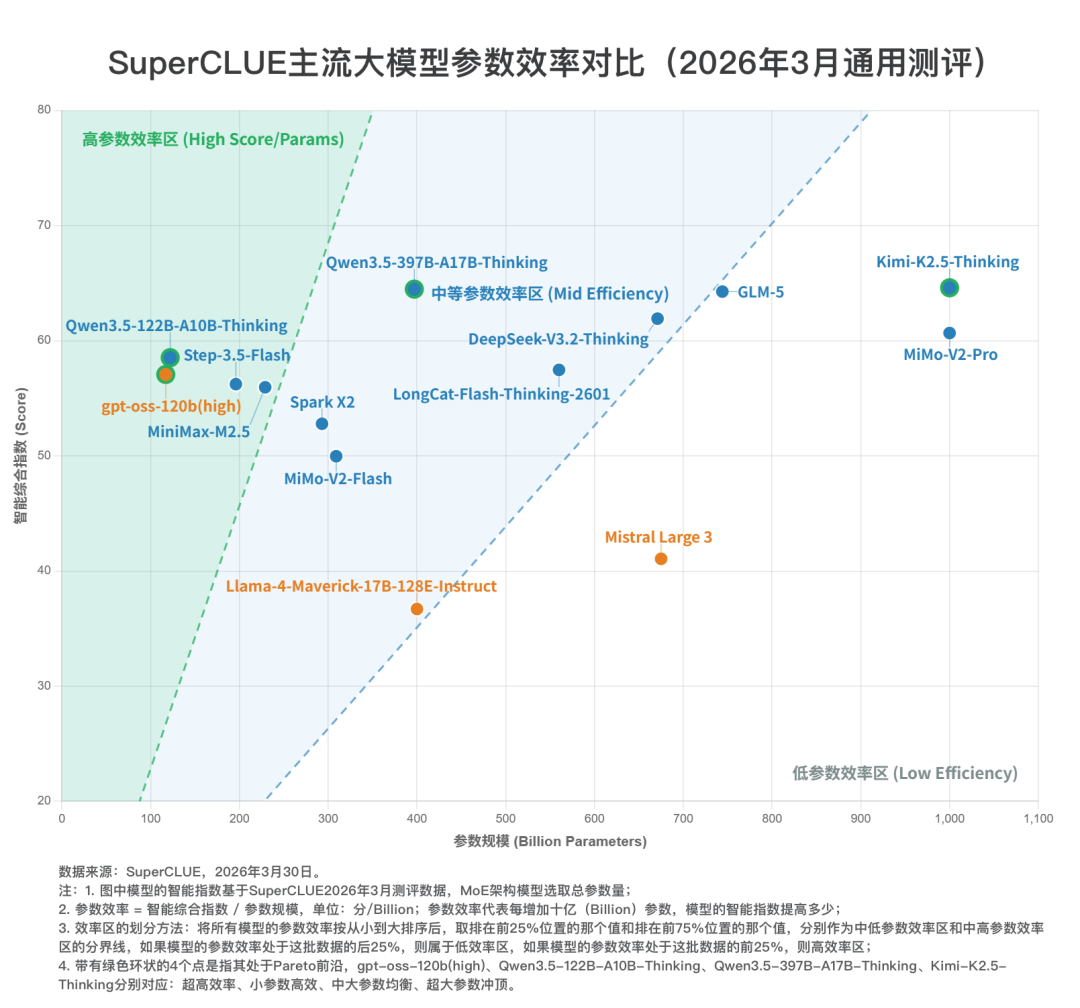
七、SuperCLUE主流大模型参数效率对比(2026年3月通用测评)
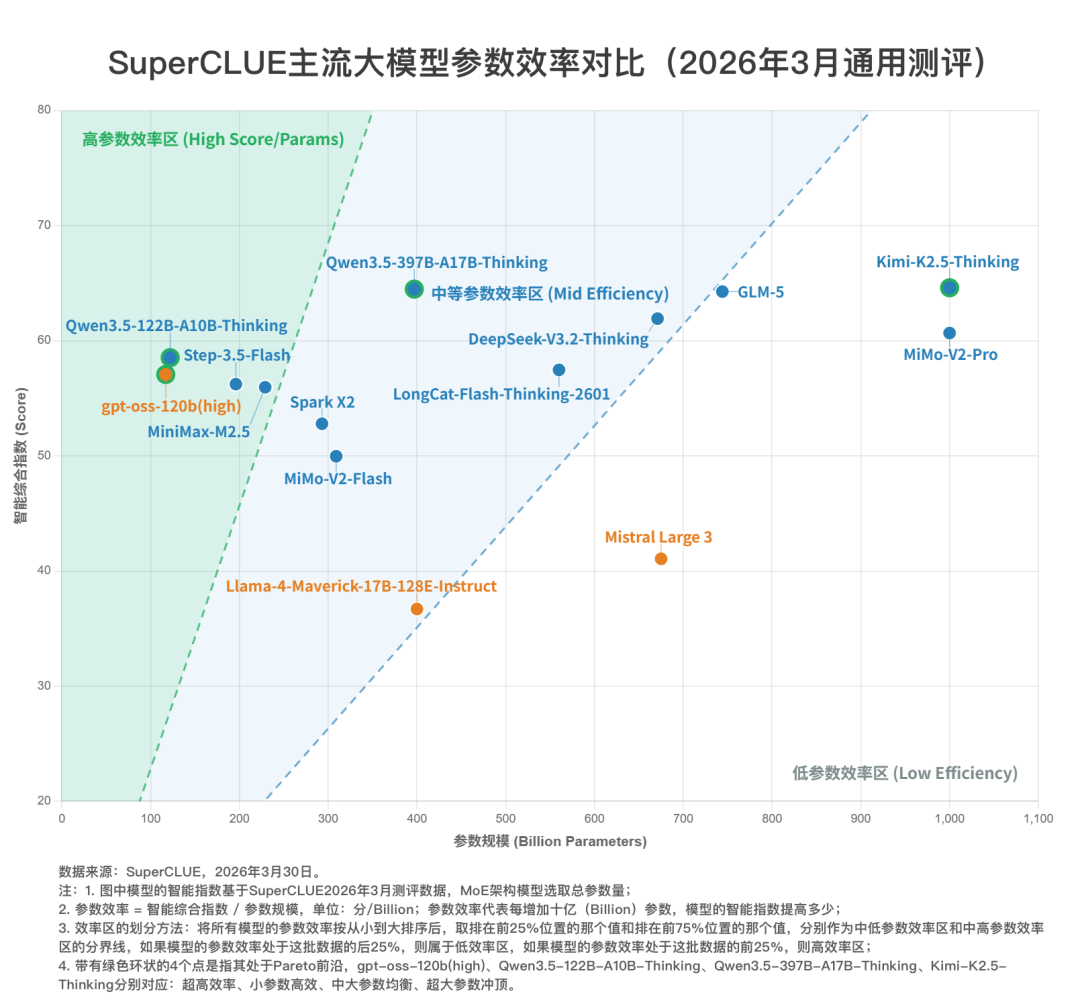
Pareto 前沿:如果一个模型不能被另一个模型“同时用更少参数、拿更高分数”打败,它就在前沿上。比如一个点在本图中如果左上方没有别人能压住它,它就是 Pareto 前沿。
测评分析:
1. 参数越大,分数上限越高,但效率明显下降
按参数段看,参数量大于等于500B的模型平均分为58.33,高于参数量小于200B的模型平均分(57.28),说明参数越大的模型确实更容易拉高上限;但它们的平均参数效率只有0.0779,远低于参数量小于200B的模型的0.4181。这意味着大参数带来的主要是能力上限,并不是参数利用效率。
2. 高参数效率的代表并不是最高分模型
按参数效率来看,前三是:gpt-oss-120b(high)(0.4878)、Qwen3.5-122B-A10B-Thinking(0.4798)、Step-3.5-Flash(0.2869)。这些模型并不是总分最高的,但单位参数产出最强,代表的是“高效率路线”。
3. Kimi-K2.5-Thinking 是“高分但低效率”的典型
Kimi-K2.5-Thinking总分最高(64.60),但其参数量达到了1000B,参数效率为0.0646,在 14 个模型里排 12。所以如果看参数效率,它并不强;但如果看绝对能力,它又是当前样本中的最高点。因此这个点最适合被定义为“高成本换高上限”的代表,而不是“高效率代表”。
4. Pareto 前沿
处于 Pareto 前沿的有:gpt-oss-120b(high)、Qwen3.5-122B-A10B-Thinking、Qwen3.5-397B-A17B-Thinking、Kimi-K2.5-Thinking)。这 4 个点分别对应 4 条路线:超高效率、小参数高效、中大参数均衡、超大参数冲顶。反过来,像GLM-5和DeepSeek-V3.2-Thinking虽然分数高,但因为存在“参数更小且分数更高”的Qwen3.5-397B-A17B-Thinking,所以不在前沿上。
5. 最值得强调的模型
Kimi-K2.5-Thinking:最高分,低效率,高成本冲顶。
Qwen3.5-397B-A17B-Thinking:分数接近最高点,但参数显著更小,是最均衡的前沿点。
Qwen3.5-122B-A10B-Thinking:小参数高效率代表。
gpt-oss-120b(high):全表参数效率第一,是“高效路线”的标杆。
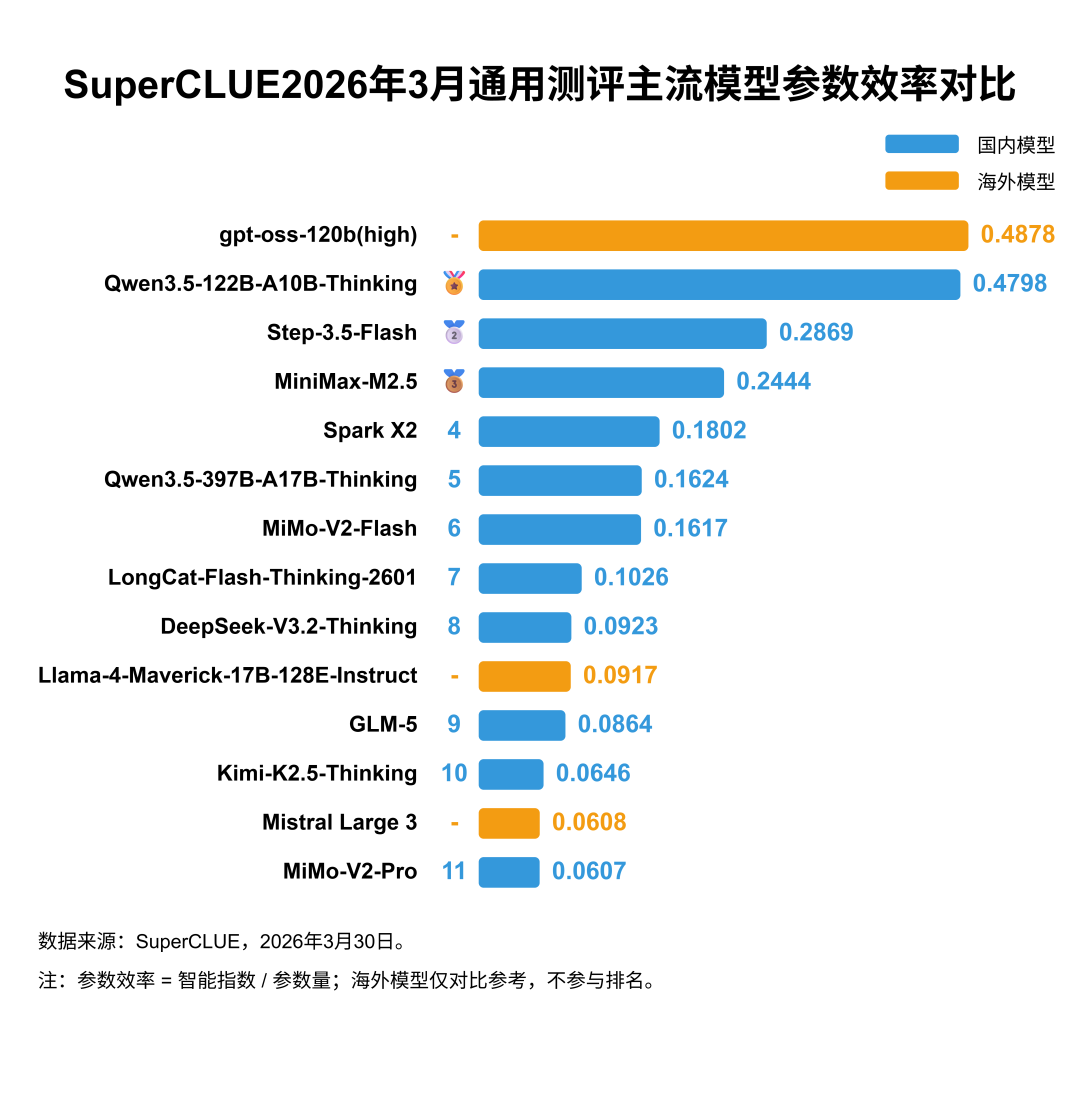
总结
从这批模型数据看,参数规模扩大确实提升了模型能力上限,但并未同步带来更高的参数效率。Kimi-K2.5-Thinking以 64.6 分位列第一,代表当前大参数模型的能力上限,但其单位参数效率仅为 0.0646,并不占优。相比之下,gpt-oss-120b(high)和Qwen3.5-122B-A10B-Thinking在 120B 左右参数规模下实现了更高的单位参数产出,体现出明显的效率优势。若从 Pareto 前沿看,当前前沿点主要集中在 120B、400B 和 1000B 三个层级,说明行业竞争已不再是单一的堆参数路线,而是演化为高分冲顶与高效压缩并行的多路线竞争。
八、评测与人类一致性验证:对比Arena
Arena是当前英文领域较为权威的大模型排行榜,它以公众匿名投票的方式,对各种大型语言模型进行对抗评测。
我们将SuperCLUE得分与Arena得分进行相关性计算,得到:
皮尔逊相关系数:0.865,p<0.001;
斯皮尔曼相关系数:0.935,p<0.001。
说明SuperCLUE基准测评的成绩,与人类对模型的评估(以大众匿名投票的Arena为典型代表),具有较高的一致性。
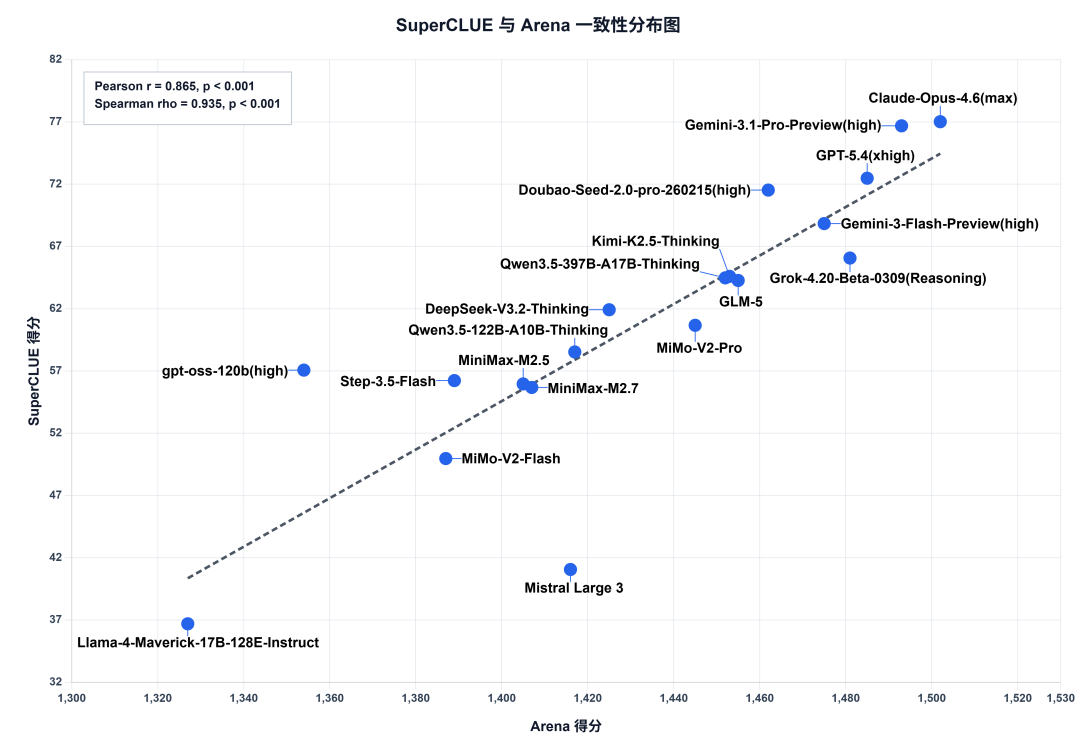
数据来源:SuperCLUE,2026年3月30日。
注:
斯皮尔曼相关系数:用于衡量两个变量之间的单调关系,取值为[-1,1],该系数的绝对值越接近1表示两个变量之间的相关性越强;
皮尔逊相关系数:用于衡量两个连续变量之间的线性相关程度,取值为[-1,1],该系数的绝对值越接近1表示两个变量之间的相关性越强。
附:
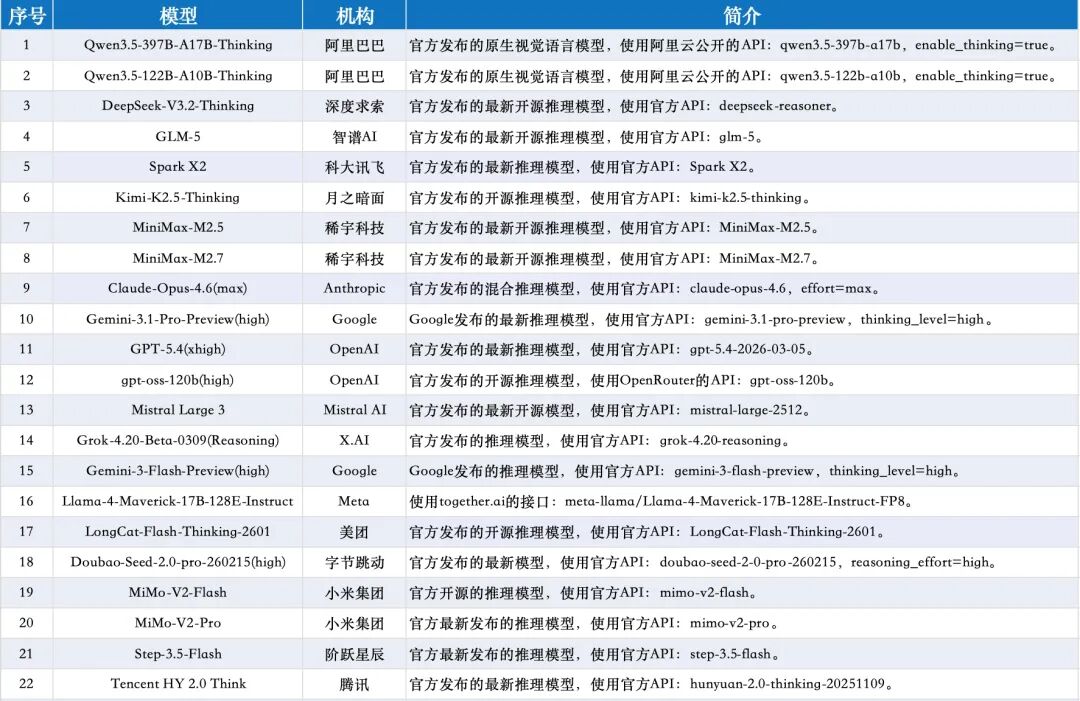
2026年3月通用测评模型列表
测评的更多详细内容,请点击文章下方 阅读原文 或 复制以下链接到浏览器 查看:
https://www.superclueai.com

欢迎加入【通用测评】交流群。


扩展阅读
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE





