具身智能(大脑)桌面操作场景模型统一评测进展快报 | EmbodiedCLUE
发布时间:2026-03-30来源:CLUE中文语言理解测评基准
EmbodiedCLUE-VLA 具身智能大脑测评基准近期在 RoboCasa GR1 Tabletop 场景下,针对六个采用不同技术路线的模型,在统一环境、统一任务集与统一评测规则下完成了首轮标准化评测。该项工作的重点并非针对单一模型进行调优,而在于建立一致、可复用的评测标尺,从而为后续模型对比、性能分析与结论形成提供可靠依据。一、评测环境与评测内容
评测环境简介
RoboCasa GR1 Tabletop场景是一个专为桌面操作任务设计的仿真环境,包含多种家用物体(如杯子、土豆、牛奶、瓶子、易拉罐等)和交互容器(抽屉、微波炉、橱柜等)。该场景以 GR1 人形机器人作为操作主体,强调双手协同与精细操作,适合评估模型在真实复杂桌面场景中的泛化能力。MuJoCo(Multi-Joint Dynamics with Contact)物理引擎以高精度刚体动力学和稳定接触求解著称,被广泛用于机器人仿真研究。它能够准确模拟抓取、滑动、碰撞等物理交互,为策略学习提供接近真实世界的反馈。RoboCasa GR1 Tabletop 评测场景 + MuJoCo 物理引擎覆盖 24 个桌面操作任务,包括抓取、放置,以及关闭抽屉 / 微波炉 / 橱柜等精细动作保证不同模型在相同条件下运行,减少因接口差异带来的“不可比”评测模型
EmbodiedCLUE-VLA具身智能大脑测评基准选取截至目前在RoboCasa GR1 Tabletop上统一训练过且有开源权重的6个模型参与本次评测。目前已完成统一接入的6个模型如下表所示:这六个模型涵盖了starVLA、ABot和GR00T等多条技术路线。二、评测配置及评测指标
评测配置
n_steps(最大步长)= 60;n_envs(并行环境数)= 5;max_episode_steps(最大交互动作数)= 720;n_action_steps(单步推理执行动作数)= 12;
上述参数用以控制评测结果的一致性和可复现性,评测结果输出为统一格式,便于后续批量汇总与对比。核心指标
当前阶段主指标仍为成功率(Success rate 即模型在100次模拟中的成功次数除以总次数的值),辅以:- 平均步长 (Average episode length 即模型在24个任务、100个episode中完成任务所需交互步数的平均值)
- 单步平均奖励 (Average episode reward 即总奖励除以总步长)
- 平均评测耗时 (Average seconds per episode 即单一模型每一个任务每一步长平均评测所需时间,单位为秒)
成功率 直接反映模型在任务级完成能力上的差异,也是后续横向对比的主要依据;平均步长 和 单步平均奖励 则从效率和决策质量两个维度补充评估;平均评测耗时 为实际应用中的资源消耗提供参考。三、阶段性成果
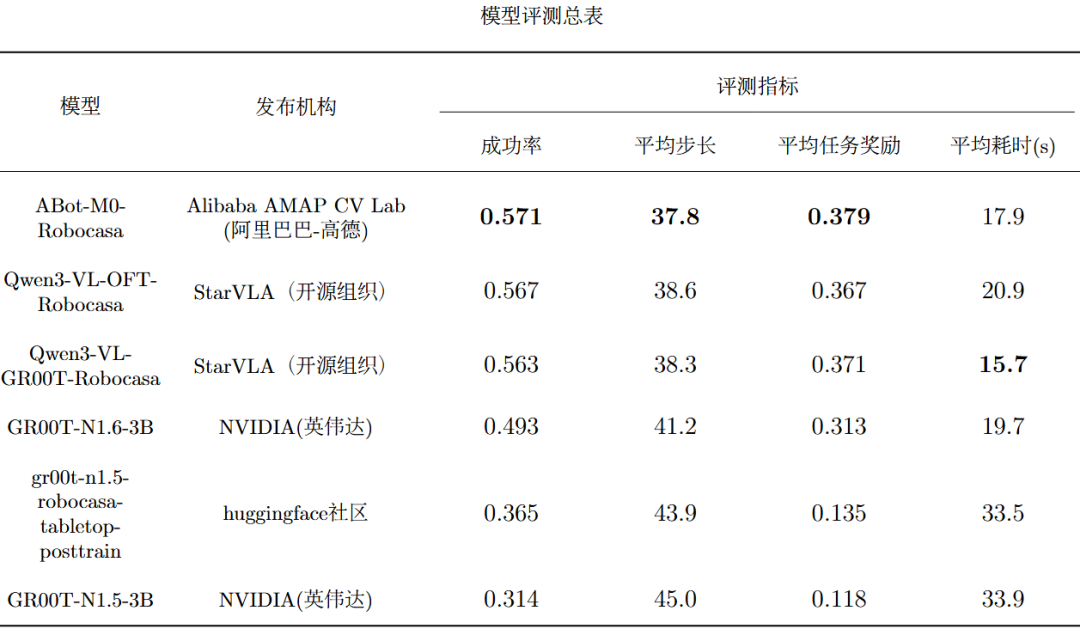
主要指标评测结果
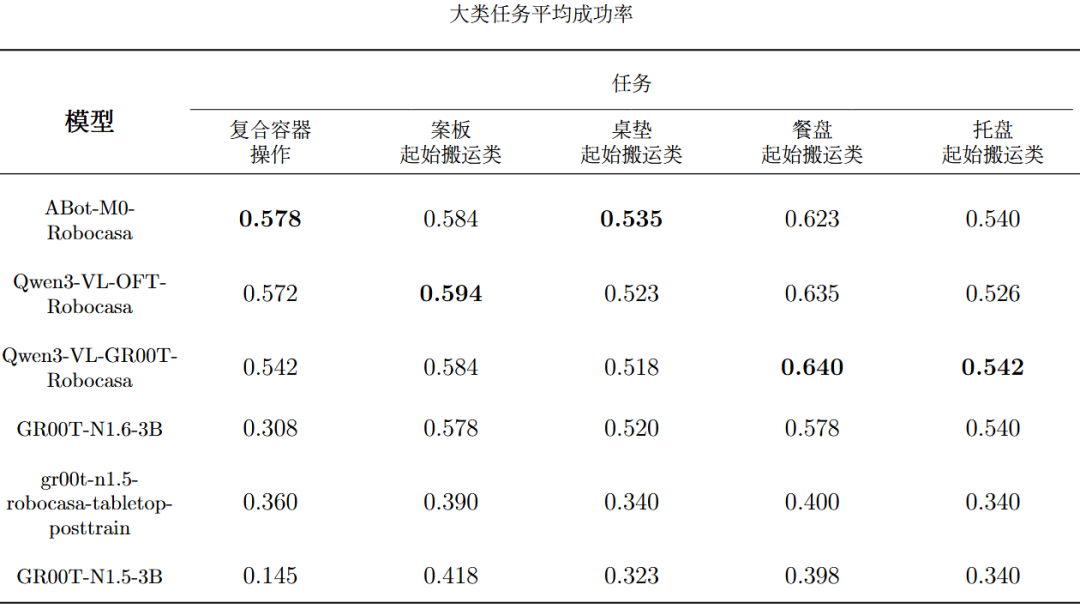
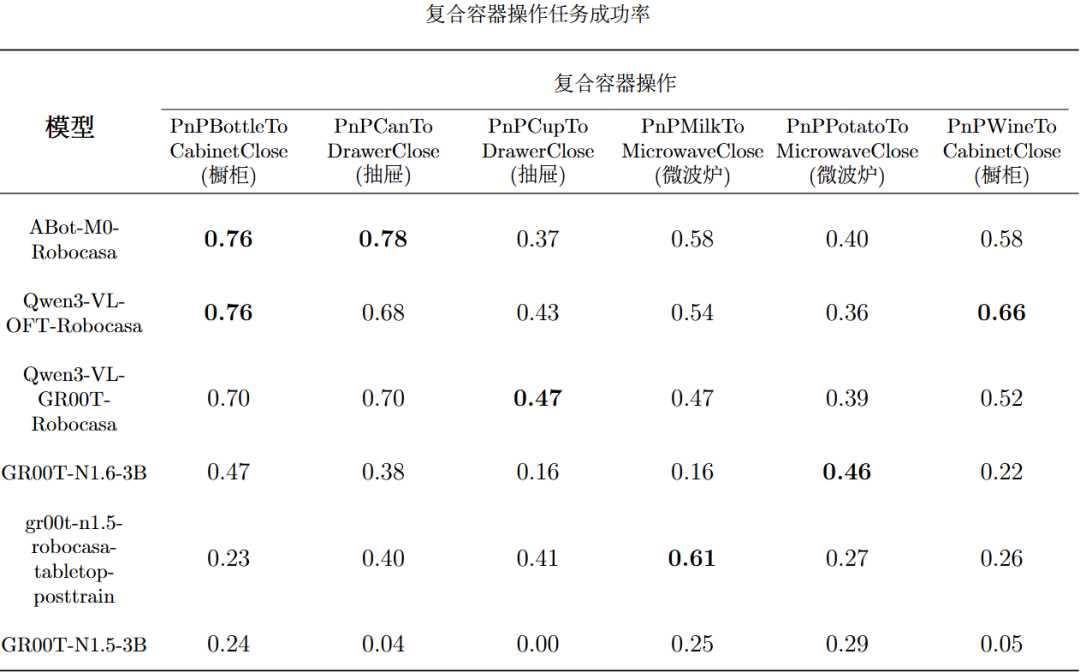
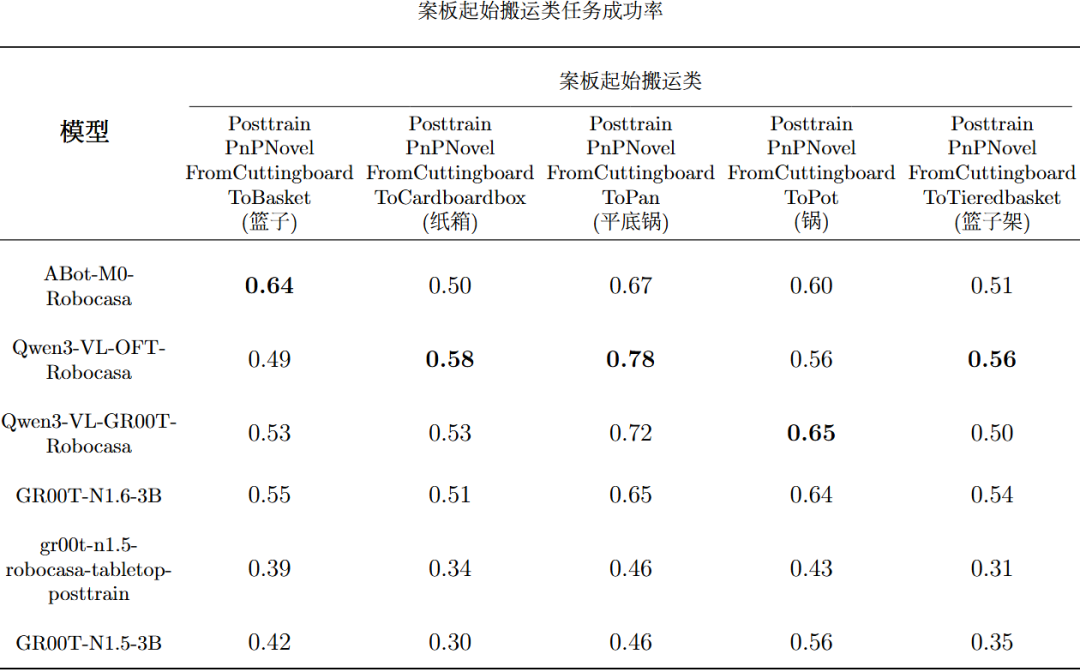
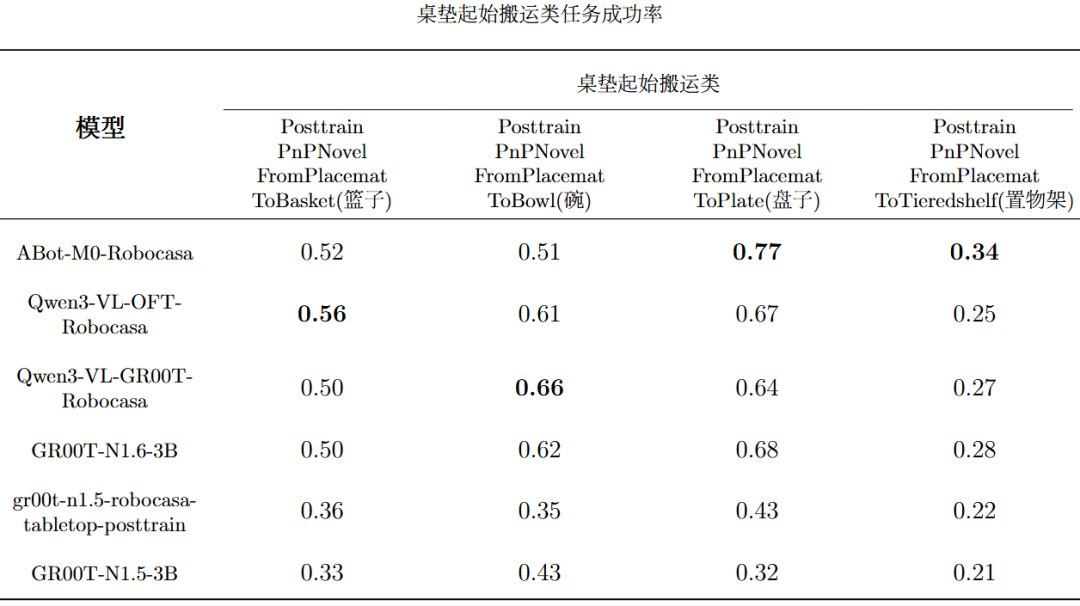
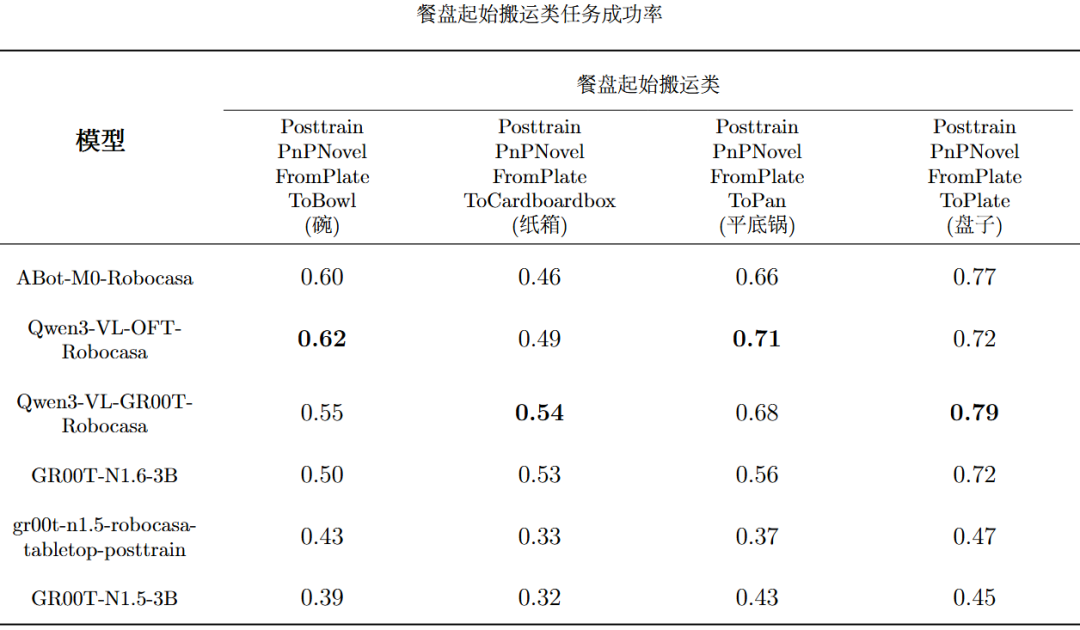
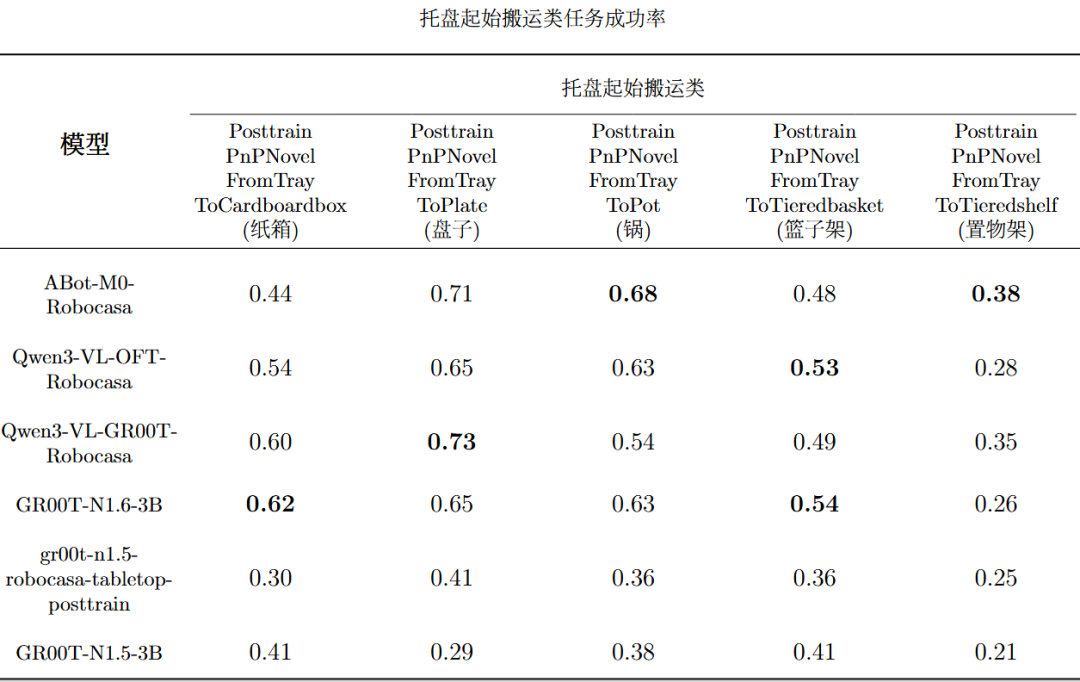
当前EmbodiedCLUE-VLA具身智能大脑测评基准实现了多模型评测链路打通,使得6个模型可以在同一环境、相近配置下稳定运行。而且基于已有模型,基准评测了每个模型在5个大类任务和24个细分任务下的各个主要指标成绩。下表是模型评测总表,表内将每个指标的最佳模型成绩标粗:下表是各个模型在5个主要大类任务上的平均成功率,表内将每个任务的最佳模型成绩标粗:下列5张表是各个模型在24个细分任务上的平均成功率:可视化结果
为了方便可视化,评测后将每个模型的每个episode的任务对应的视频输出为.mp4文件,并从这些文件中选取每一个任务的成功案例合并为可视化动图,用以展示渲染后的模拟场景下的机器人连续动作。下图是ABot-M0中24个任务的成功示例图:由于本次评测是在统一任务场景统一seed设置下进行的,模型评测场景基本相同,当前示例可以很好的反应6个模型的动作输出。下图是在ABot-M0中选取的八个典型任务场景的机器人连续动作:四、下一步规划
接下来EmbodiedCLUE-VLA具身智能大脑测评基准准备:如果你对某个模型的细节、任务定义或评测方式感兴趣,欢迎随时交流~
转载说明:本文系转载内容,版权归原作者及原出处所有。转载目的在于传递更多行业信息,文章观点仅代表原作者本人,与本平台立场无关。若涉及作品版权问题,请原作者或相关权利人及时与本平台联系,我们将在第一时间核实后移除相关内容。
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库