五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库深度丨看完 Claude Code 底层拆解,我打赌国产模型们这一波要赢麻了

今天,Anthropic 真的要麻了。
因为 Claude Code 意外泄露了 source map,这款被无数开发者捧上神坛的最强终端 AI,第一次把自己的内部骨架暴露在聚光灯下。

外网最损的一句评论是:Anthropic 真该改名叫 OpenAI。
但真正值得中国厂商兴奋的,不是看热闹,而是看门道。一款顶级 AI Coding 产品,真正的护城河到底修在哪里。不是单纯卷补全准确率,不是再做一个 IDE 插件,而是围绕模型搭出一整套运行时系统。
对字节、阿里、智谱、Kimi 这批正在往 Agent 和开发者工具纵深走的中国模型厂商来说,这几乎等于白捡了一份“下一代产品路线图”。而在港股 AI 叙事已经持续升温、智谱刚交出高增长年报、月之暗面也仍在推进上市想象空间的当下,这种级别的教学材料,显然只会继续给市场情绪再添一把火。
那么 Claude Code 究竟是怎么做的呢?这篇深度分析文章基于科技博主 Sathwick 对 Claude Code 源码及架构的逆向解剖,为你还原这款产品之所以能降维打击的内幕。
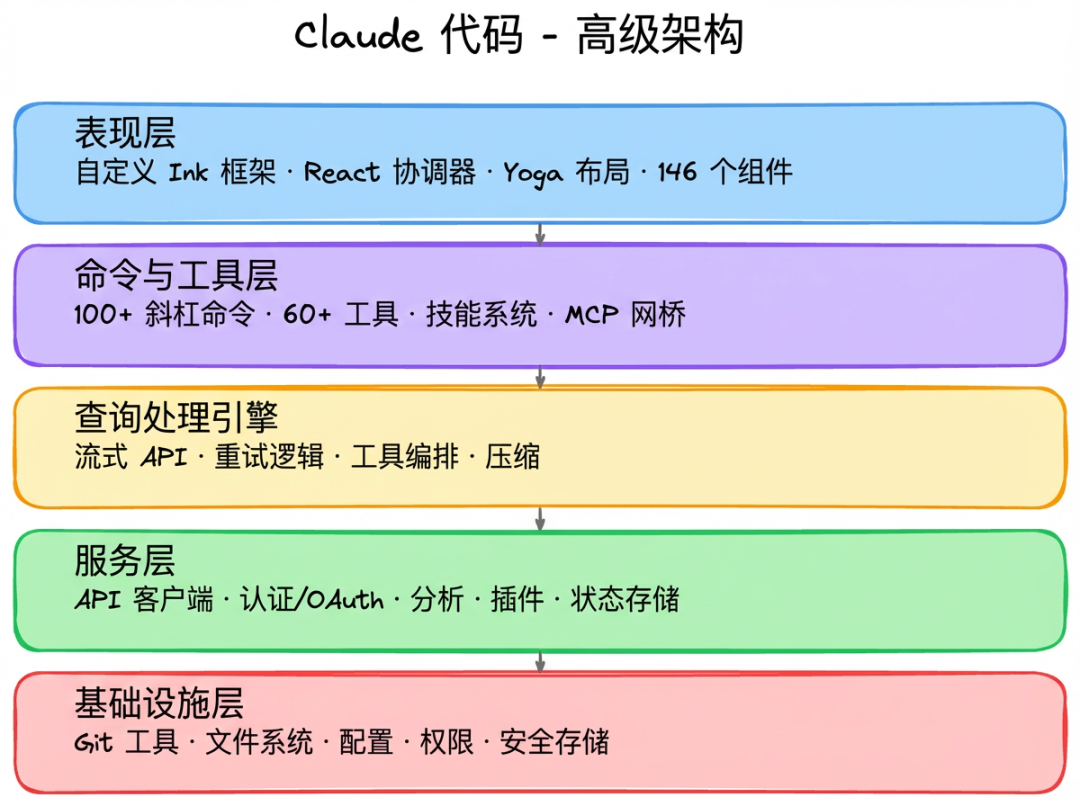
Claude Code 的底层是一整套分层系统
Claude Code 不是一个单纯调用大模型的命令行工具,而是一套分层设计的完整系统。
最上面是用户看到的终端界面,中间是命令和工具层,负责把各种能力暴露给模型;再往下是查询处理引擎,负责流式调用、工具调度、重试恢复和上下文压缩,相当于整个系统的大脑;下面还有服务层,处理认证、插件、状态管理和分析;最底层则是文件系统、Git、配置、权限和安全存储这些基础设施。
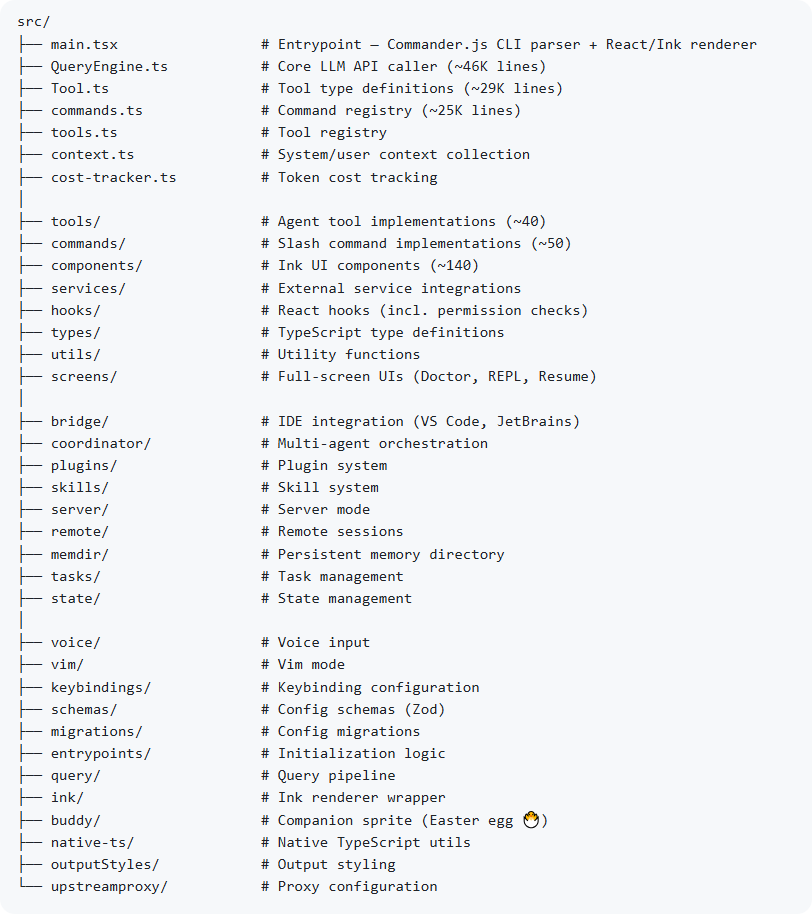
代码目录也非常重:主入口、查询引擎、工具注册表、100 多个 slash commands、146 个 UI 组件、自研 terminal framework、85+ hooks、330+ utils、多智能体协调、远程管理、任务系统、迁移系统,几乎把一个现代复杂应用该有的层全铺齐了。
这意味着,Claude Code 的思路从一开始就是把 AI 作为系统中心,再围绕它重建一套终端交互、执行、安全和扩展框架。
它不是一个 prompt wrapper,而是一个把模型、工具、状态、上下文和 UI 都统一起来的工程产品。
它最先优化的是“启动那一瞬间的体感”
很多人会把 AI 工具的体验问题归结为模型快不快、聪不聪明,但 Claude Code 在源码里首先解决的,是更底层的“第一眼体验”。
为了尽可能缩短首次渲染时间,它在模块导入前就先并行做几件事,比如启动 macOS MDM 策略读取、预取 keychain 里的 OAuth 和 API key。原因很简单:TypeScript 模块执行本身就有顺序耗时,那不如把这些 I/O 操作提前塞进去并行跑,把等待时间重叠掉。
后面的初始化也不是乱序堆起来的,而是一个明确编排过的阶段链:配置校验、安全环境变量、CA 证书、优雅关闭、OAuth 账户填充、IDE 检测、远程托管设置、策略限制、mTLS、代理、API 预连接、shell 检测、LSP 清理、多智能体集群清理。甚至连 --version、--dump-system-prompt、mcp serve 这种快速退出路径,都单独走轻量初始化分支,避免用户为了一个版本号也得把 React 和整套 UI 都启动起来。
这背后体现的是一种非常典型的基础设施思维:
真正成熟的开发者工具,首先要让“等待”这件事尽可能消失。因为对高频工具来说,100 毫秒、200 毫秒,累计起来就是产品质感本身。
核心是一个会自我修复的查询引擎
Claude Code 的真正大脑,是它的 Query Engine。
源码里,这套系统分成两层:QueryEngine.ts 负责会话级编排,query.ts 负责逐回合状态机。前者管理系统上下文、消息持久化、API 调用、权限统计和成本累计;后者则是一个 while(true) 的弹性循环:先并行预取记忆和 skills,再做消息压缩,然后流式调用 API,处理错误,执行工具,再判断要不要 compact、collapse、续 token、或者继续下一轮。
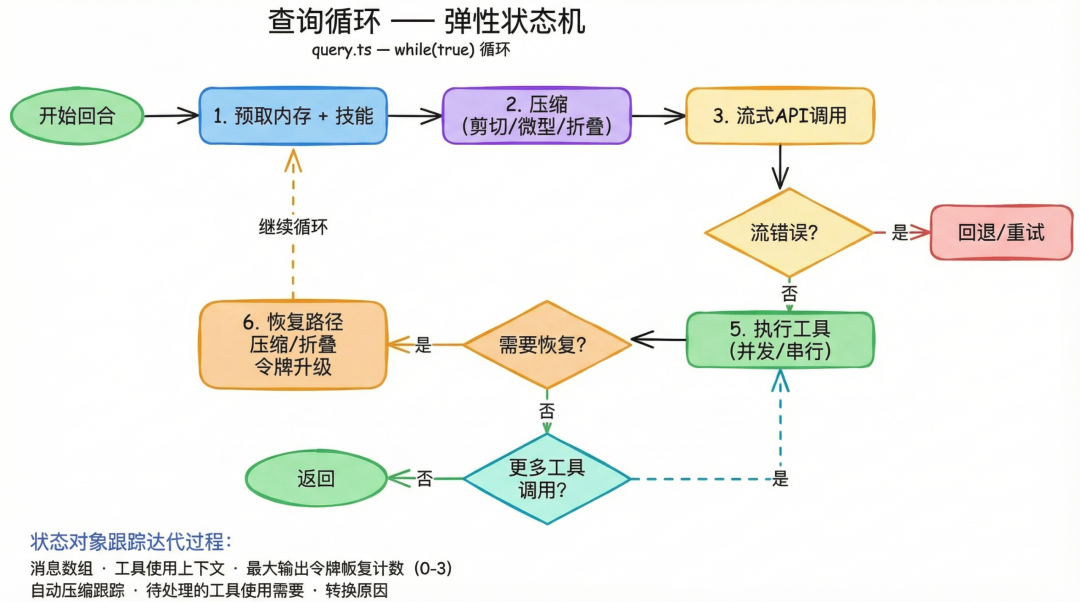
这套设计最有意思的一点是:Claude Code 并不把“一次提问”理解成一次简单请求,而是理解成一个可能不断恢复、转向、补执行、续上下文的长生命周期任务。
也就是说,它不是“问一次、答一次”的模型调用器,而是“任务驱动型回合引擎”。
比如当模型输出 token 快耗尽,但任务还没做完时,它不会粗暴停住,而是注入一条隐形元消息,要求模型“直接继续,不要道歉,不要回顾”,然后把回合自然续下去;如果上下文太长,就先做 staged collapse,不够再 reactive compact;如果流式请求中途挂掉,就尝试退回非流式;如果模型过载,还会回退到备用模型。整个过程的目标都不是“严格遵守单次请求边界”,而是“尽可能让任务完成,而不是把报错抛给用户”。
这其实非常像现代浏览器或数据库的思路:
用户看到的是一个流畅的连续体验,底层则在不停做容错、回退和恢复。
60 多个工具,被统一成一个接口
Claude Code 强的地方是它能把工具系统做成一个一致、可调度、可渲染、可控权限的统一层。
在源码里,每个工具都遵循同一套接口:名字、描述、额外 prompt、输入 schema、调用逻辑、权限检查、输入校验、并发安全判断,以及四层 UI 渲染方法——工具开始、工具进度、工具结果、工具报错。也就是说,在 Claude Code 看来,Bash、文件编辑、grep、LSP、Web 搜索、Agent 调度,本质上都只是统一工具协议下的不同实现。
这种抽象带来的最大好处,是系统可以真正按“工具能力”而不是“工具来源”去调度。
只读工具能并发跑,写工具必须串行跑;大输出会被截断并持久化;输入输出都能被 schema 约束;权限系统也能对所有工具统一生效。
更细一点看,Claude Code 的很多工具设计都很像为 LLM 重新发明了一遍开发环境:
BashTool不是裸 shell,而是带结果长度限制、沙箱感知、后台执行、权限预览的安全命令执行器。文件编辑工具不是暴力全量重写,而是精确字符串替换,并和 git diff、撤销系统打通。
GrepTool是为 LLM 优化过的 ripgrep 封装,默认限制输出、防止上下文爆炸。LSPTool让模型获得goToDefinition、findReferences、hover这类语言智能能力。AgentTool则直接把“再开一个 Claude 去并行处理另一部分任务”做成了一等能力。
换句话说,Claude Code 的真正竞争力,不是“模型知道怎么编程”,而是“模型被接进了一套真正可执行的软件环境”。
不是工具多,而是按需发现工具
一个很容易被忽略、但非常关键的设计,是 Claude Code 并不会在每次请求里,把 60 多个工具全部摊给模型。
它引入了延迟工具发现机制。部分工具会先隐藏,只有当模型明确意识到自己需要某类能力时,才通过 ToolSearchTool 去搜索、拉出对应 schema,然后在同一回合中调用。这种设计把基础 prompt 的体积控制在合理范围内,同时保留了弹性扩展能力。
这件事非常重要,因为它说明 Claude Code 已经开始把“工具系统本身”也当作上下文预算问题来管理。
很多 agent 产品越做越臃肿,一个原因就是恨不得把所有能力一次性塞进系统提示词。Claude Code 反过来做:先收起来,等你真需要时再展开。
这其实是一种很典型的系统优化思路:
别让模型总是背着整座工具仓库上路,而是让它先轻装跑,再按需取件。
权限系统才是 最重、也最像产品护城河的部分
如果说工具系统决定了 Claude Code 能做什么,那么权限系统决定了它敢做什么。
Claude Code 源码里,权限是一个真正的多层防御体系。它有多种模式:默认模式下,破坏性操作需要确认;plan 模式只读;acceptEdits 可以自动批准文件编辑但 shell 仍然受控;bypassPermissions 则近似全开;dontAsk 直接自动拒绝不安全命令。除此之外,还有内部的 auto 和 bubble 模式。
规则本身也不是简单的 yes/no。它有来源优先级,有 glob 匹配,有 allow/deny/ask 三态,还有 pre/post hooks 可以在执行前修改输入,或者直接阻止执行。系统甚至会识别“过于宽泛”的危险规则,比如 python:*、node:*、* 这种本质上等于放弃控制的模式,不会轻易自动放行。
这意味着,Claude Code 并不是在“AI 自动化”和“人工确认”之间二选一,而是在做一套非常细粒度的操作治理系统。
对于企业或重度开发场景来说,这一点比模型多聪明 5% 还重要。因为真正把 agent 引入生产环境时,最大的阻力从来都不是模型回答质量,而是“它会不会误操作”“出了问题谁兜底”“权限边界怎么划”。
很多 AI 编程工具还停留在“让模型更能写”的阶段,Claude Code 已经明显进入“让模型更能被管理”的阶段了。
它甚至重写了终端 UI
Claude Code 另一个非常夸张、也非常能说明工程深度的地方,是它的终端 UI。
它不是用普通 ANSI 输出做一个“看起来像应用”的东西,而是真正重做了一套终端渲染栈:React 组件先经过自定义 reconciler 生成虚拟 DOM,再交给 Yoga 做 flexbox 布局,然后进入 output builder、screen buffer、diff engine,最后才落成 ANSI escape sequences 发给 TTY。
这套系统里,有双缓冲、有 blit 拷贝未变化区域的优化、有二维 cell buffer、有样式池、字符池、超链接池,还有硬件滚动区域、事件捕获和冒泡、文本选择、软换行处理、键盘协议解析。它处理的问题已经不是“怎么把文字打印出来”,而是“怎么在终端里实现接近 GUI 的交互体验”。
从工程视角看,这一层特别值钱。因为当大多数人还把终端当“只要能输出就行”的粗糙界面时,Claude Code 实际上是在把终端重新产品化。
而一旦终端体验被重新产品化,CLI 就不再只是开发者忍受的工作台,而开始变成真正有体验差异的前端。
换句话说,Claude Code 不是在做一个更聪明的 CLI,
它是在证明:CLI 本身,也可以成为一个高复杂度、高完成度的应用平台。
Slash Commands、Skills、Plugins、MCP
Claude Code 之所以不像一个单点工具,另一个原因是它的扩展层已经非常完整。
命令系统里,slash commands 超过 100 个,而且并不是一类命令,而是三类:展开成 prompt 的命令、纯本地文本命令、以及直接用 React 组件渲染到终端的本地 JSX 命令。所有命令还会根据当前运行环境过滤,比如远程模式、桥接模式下,能用的命令集合都不一样。
在这之上,还有 skills、plugins 和 MCP 三层扩展:
Skills 是带 frontmatter 的 Markdown 提示模板,可以来自项目目录、用户目录、内置 bundle、插件甚至 MCP 自动生成器,而且支持 fork 到隔离子代理中执行,避免大技能把当前会话上下文吃爆。
Plugins 则把技能、hooks、MCP server 和用户可配置变量打成一个包。
至于 MCP,更像 Claude Code 对外接世界的总线:本地 stdio、网络 sse/http/ws、SDK、Claude.ai proxy 都支持;配置还分本地、项目、用户、企业、动态等多层来源;接入进来的工具会被统一命名、统一权限检查、统一分析处理。
当这些层叠起来,Claude Code 就不再是“Anthropic 做的一款 AI 编程产品”,而更像一个可被二次开发、可被组织化管理、可接入外部生态的 agent 平台。
这也是它和很多“功能很炫,但体系很薄”的 AI 开发工具最大的差别。
为了对抗上下文极限,压缩成为了一门学问
Agent 产品做到后面,最大的敌人几乎都会变成上下文窗口。
Claude Code 对这件事的处理非常工程化。它不是等上下文爆了再统一报错,而是提前布置了多层机制:自动压缩、微压缩、snip compact、context collapse。
当 token 接近阈值时,它会先去掉旧消息里的图片和文档,再按 API 回合组织消息,调用压缩模型生成摘要,用 compact boundary message 替换历史内容;压缩后还允许重新注入有限数量的重要文件和 skills。
如果只是工具输出太多,那就做更轻量的 microcompact;如果 API 真因为 prompt 太长返回 413,就按 collapse drain → reactive compact → surface error 的顺序逐级恢复。用户大多数时候根本看不到这些机制在工作,只会感觉“这会话怎么聊了这么久还没炸”。
这其实很能代表 Claude Code 的产品哲学:
别把模型限制当成静态天花板,而要把它当成运行时资源去动态调度。
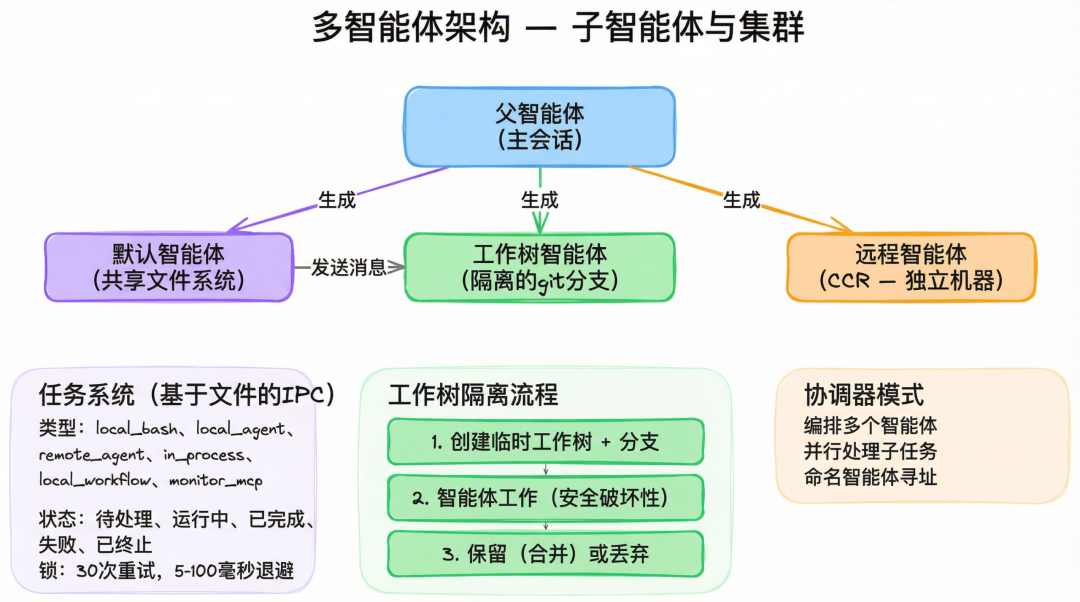
不是单智能体,而是多智能体
源码里,Claude Code 的多智能体架构已经不是“实验性 feature”那种程度,而是相当实用化了。
AgentTool 可以生成子代理,支持共享文件系统、Git worktree 隔离、远程 CCR 运行,还能指定模型、后台执行,并通过命名消息让代理之间互相协作。后台任务系统也不是随便起个进程,而是有 IPC、任务状态、base-36 编码 ID、锁重试机制,能在 tmux 或多个终端窗格之间协调。
尤其是 worktree 模式,很能看出 Claude Code 对“并行干活”这件事的认真程度。
它不是简单地多开几个 agent 让它们同时改代码,而是给它们真正的 Git 级隔离工作区,最后再决定保留还是丢弃。这种设计把多代理从“容易互相踩文件”的 demo,推进到了“可以在真实代码库里更安全地并行”的可用层。
放在 2026 年这个时间点看,这也很重要。因为 agent 的下一阶段竞争,越来越不像“谁回答更好”,而像“谁更会组织一群 agent 一起工作”。Claude Code 很明显已经提前踩进去了。
出了问题也不让你太难看
真正的生产级系统,衡量标准不是“不出错”,而是“出错时怎么表现”。
Claude Code 的错误恢复体系相当完整:
429、529 这种瞬时错误会重试;401 先尝试 OAuth 刷新;413 先走上下文恢复路径;max output tokens 先尝试升到更高 token budget,再注入继续提示;持续 529 还会回退模型;流式中途失败则改用非流式请求继续。
它的目标非常明确:尽可能把复杂性留在内部,把连续性留给用户。
这点其实很容易被低估。很多 AI 产品 demo 时很顺,一进真实环境就暴露出“没有恢复层”的问题:网络抖一下就挂、上下文长一点就崩、工具执行一半断流就只剩一地孤儿结果。Claude Code 在这方面已经明显进入“基础设施级成熟度”的范畴。
最离谱的是它真塞了个 AI 宠物进去
如果前面那些部分体现的是 Anthropic 的工程野心,那 BUDDY 则体现了另一面:
他们显然也很懂,开发者工具不一定非得永远板着脸。
源码里,Claude Code 有一个完整实现的电子宠物 companion。它会出现在输入框边上,按用户 ID 稳定生成,有物种、稀有度、帽子、眼睛、属性、名字和性格,还会说话、显示对话气泡、响应交互,甚至有愚人节预热窗口。
表面上看,这像是个彩蛋。
但往深了看,它其实说明 Claude Code 已经不再只把自己当作一个“冷冰冰的效率工具”,而在尝试把开发者长期使用时的情绪体验也纳入设计里。
这类设计未必决定成交,却经常决定留存。因为一个每天打开十几次的工具,迟早会从“完成任务”演化成“陪你工作”。
KAIROS、记忆系统和持续助手模式
如果说前面的 Claude Code 还是一个非常强的本地 AI 工具,那么 KAIROS 和 Memory System 透露出的,就是它更长期的形态:一个跨会话持续存在的助手。
源码里,记忆系统会把内容按 Markdown 文件加 YAML frontmatter 的方式存下来,分成 user、feedback、project、reference 四类,用一个 MEMORY.md 作为目录索引,再通过相关性选择器在每次对话中只召回最相关的一小部分记忆,而不是把全部历史硬塞进 prompt。系统还明确限制哪些内容不该记,以避免把项目状态可推导出的信息重复固化。
KAIROS 更进一步。它包含“自动做梦”这类后台内存整合机制,会定期扫描会话、日志和记忆目录,整合漂移信息、更新索引、清理陈旧指针,像是在给 Claude 做一种跨会话的“记忆巩固”。同时它还引入持续助手模式、主动 tick、后台任务、仅追加日志等组件。
这说明 Claude Code 的未来方向,已经不只是“帮你完成当前命令”,而是“长期理解你、理解项目、理解组织,并在多个时点持续协作”。
这和单次聊天式 AI 助手完全不是一个层级的产品目标。
这次事件,对 Claude 和国内厂商意味着什么
先说 Anthropic。
短期来看,这当然是一场不小的尴尬。源码被顺着 source map 扒出来,不只是暴露了工程细节,也让外界第一次系统性看见了 Claude Code 的内部组织方式。可从另一个角度看,这件事也反过来证明了一点:Claude Code 已经不再只是 Anthropic 产品矩阵里一个挺好用的功能,它已经成了整个行业观察 Anthropic 产品能力、工程品位和未来方向的窗口。否则,这次事件不会从安全事故迅速升级成行业热议。
但更大的影响,其实在国内。
因为 Claude Code 这次真正抬高的,不是一个模型门槛,而是一整套系统门槛。国内厂商如果还把 AI Coding 理解成“代码补全 + 聊天问答 + IDE 侧边栏”,接下来会越来越被动。你会发现,真正开始争夺的是另一层位置:谁能把 terminal、工具、上下文、权限、记忆和任务调度拼成一个可持续工作的 agent 系统。
这个趋势,其实国内已经有人看见了。
Qwen Code 在官方 GitHub 和文档里的定义就很直接:它是一个 “lives in your terminal” 的开源 AI agent,主打理解大型代码库、自动化重复工作,并且明确优化给 Qwen 系列模型使用。项目文档还写明,它基于 Gemini CLI 做了适配,加入了更适合 Qwen-Coder 模型的能力。也就是说,国内厂商并不是没看见方向,问题只在于,谁能先从“一个 terminal agent”继续往前走,走到真正的系统层。
而一旦竞争进入系统层,国内厂商未必没有自己的机会。
因为这时候,比拼的就不只是“谁模型更强”,而是“谁更懂本地工作流”。中国开发者用的协作工具、代码托管、审批流、知识库、企业 IM、私有化环境,和海外并不完全一样。未来真正有机会跑出来的 AI Coding 产品,未必只是模型最强的那个,也可能是最懂本地工程环境、最懂企业内网、最懂权限和合规边界、最懂如何把 agent 接进中国开发者日常工作流的那个。
谁先占住这层,谁就更可能拿到下一轮主动权。Claude Code 只是比其他人更早,把这个答案写进了产品里。
[1]

稿件经采用可获邀进入Z Finance内部社群,优秀者将成为签约作者,00后更有机会成为Z Finance的早期共创成员。