 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库图灵奖得主Yann LeCun的世界模型路线图:14篇论文梳理JEPA演进史
您想知道的人工智能干货,第一时间送达

 放弃像素重建,绕开自回归:14 篇论文看透 JEPA 世界模型演进。
放弃像素重建,绕开自回归:14 篇论文看透 JEPA 世界模型演进。
放弃像素重建,绕开自回归:14 篇论文看透 JEPA 世界模型演进。
Yann LeCun一直在走一条与主流大语言模型截然不同的路。当行业焦点集中在模型参数规模的暴力扩展时,他将研究重心完全放在了世界模型上。
过去几周,V-JEPA 2.1、LeWorldModel 和 ThinkJEPA 等论文相继发布。
面对主流自回归模型在物理常识和多步规划上的局限,JEPA(联合嵌入预测架构)给出了另一种思路:彻底放弃底层的像素重建,直接在抽象的特征空间中预测未来状态。
这 14 篇关键论文,正是这套架构从理论走向现实的完整记录。
系统从处理单一的静态图像起步,逐步跨越视频与三维几何,最终接入动作变量,构建出一个具备端到端推演和规划能力的完整框架。

核心机制概述

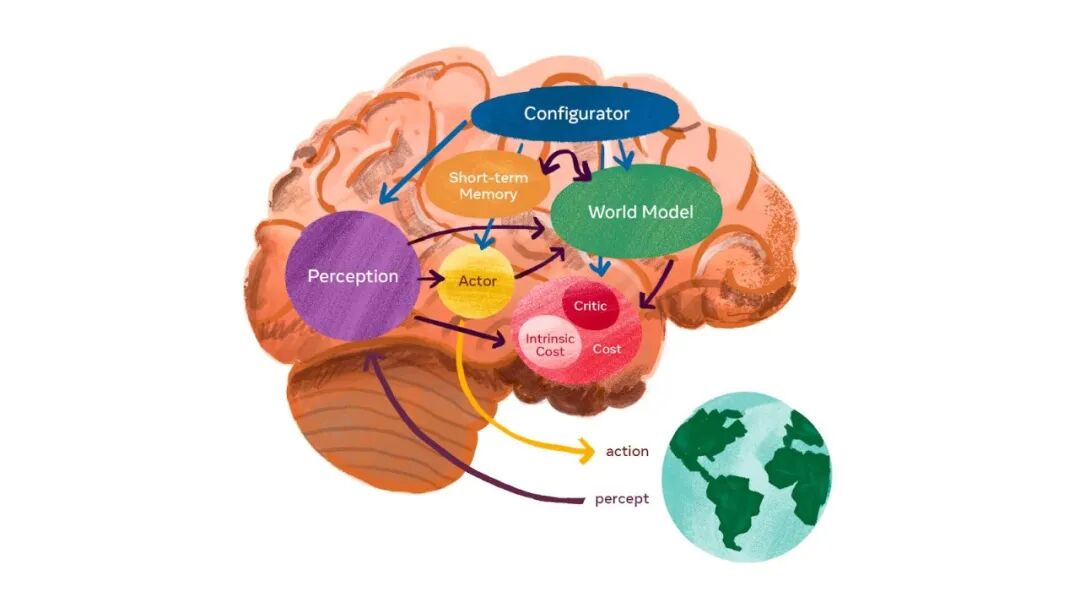

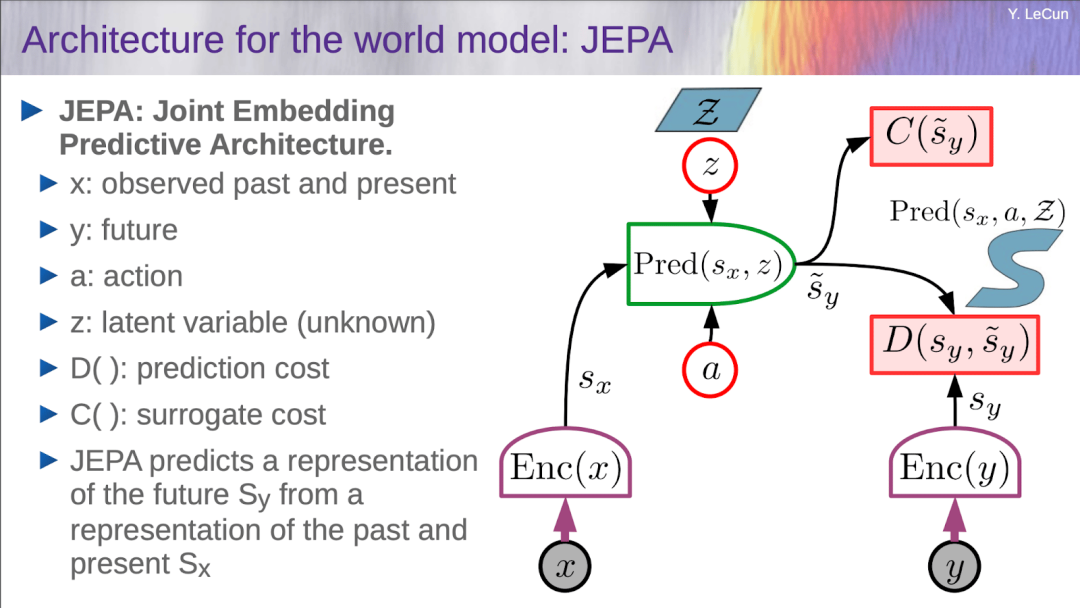


阶段一:从理论到图像验证

I-JEPA:视觉领域的首次落地
I-JEPA(Image-based JEPA)[2] 是将理论转化为工程实现的关键节点。

一个轻量级的预测器接收上下文特征以及对应的掩码 token,在隐空间中预测目标块的表征。整个过程通过最小化预测值与真实目标值之间的 L2 距离来驱动。
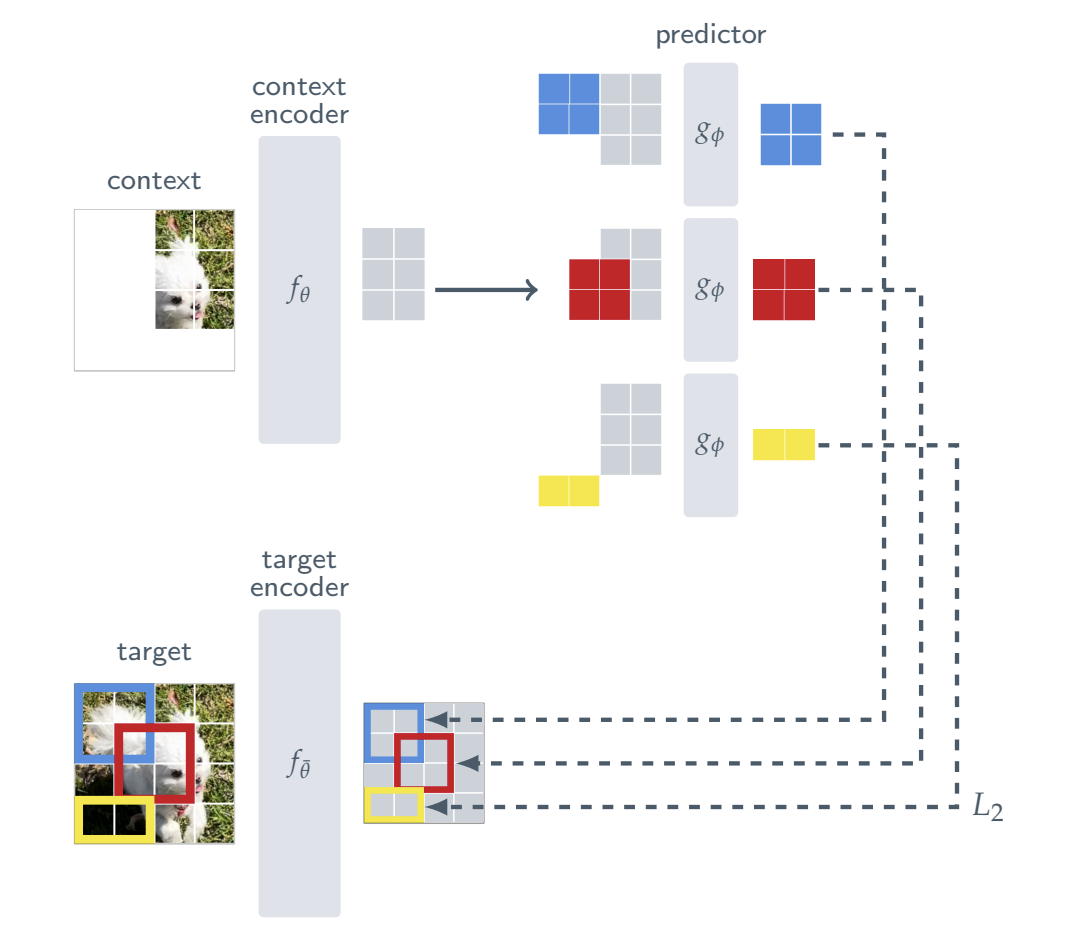


阶段二:走向动态与跨模态

V-JEPA:视频特征预测的验证
V-JEPA(Video-based JEPA)[4] 是架构演进路线上的绝对支柱。

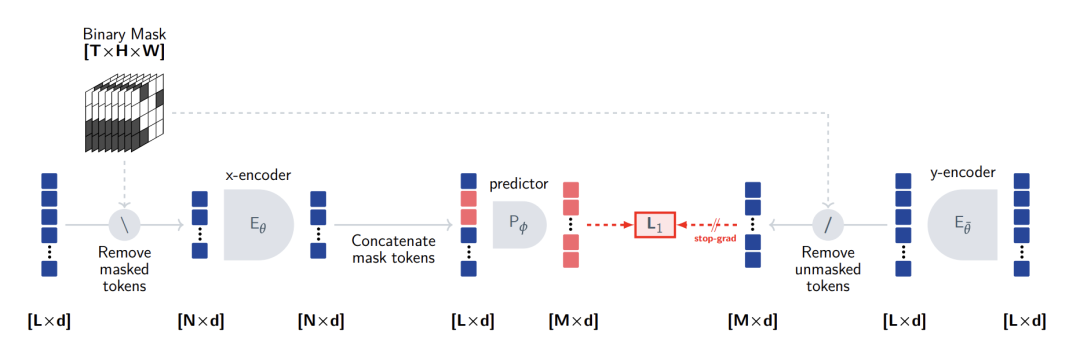



Audio-JEPA:模态通用性的确立


阶段三:深入三维几何

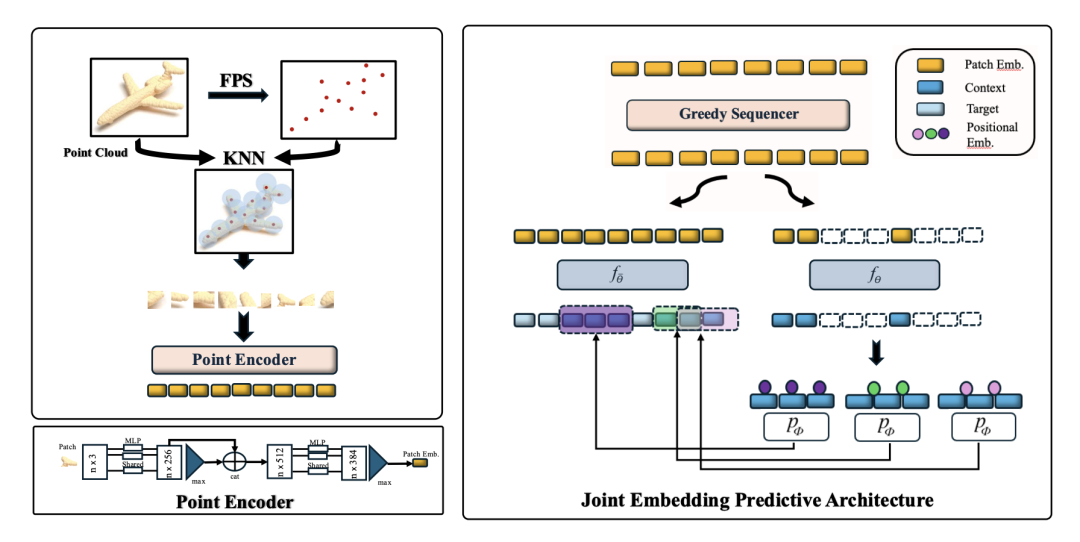
通过这种设计,Point-JEPA 成功绕开了原始点云数据中存在的冗余和噪声,证明了该架构在处理复杂几何表征时依然能够保持极高的效率。
3D-JEPA:更广泛的3D语义重塑
3D-JEPA [7] 进一步拓宽了架构在三维空间的适用范围,将应用场景从单一的点云数据扩展到了更广泛的三维特征学习。它标志着该架构已经成熟,可以作为处理完整 3D 语义的基础框架。
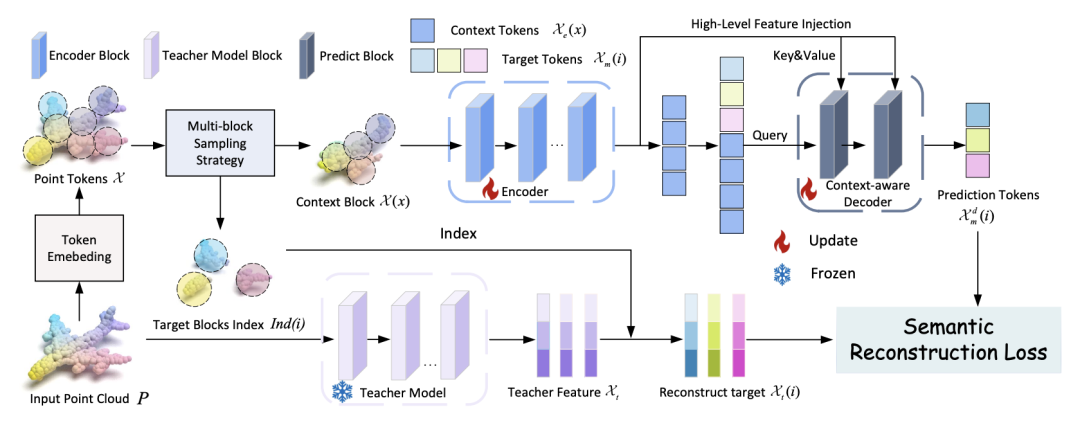
在这个阶段,系统不再满足于提取局部的几何特征,而是致力于理解更宏观的三维空间结构,为构建更复杂的真实世界模型扫清了模态障碍。


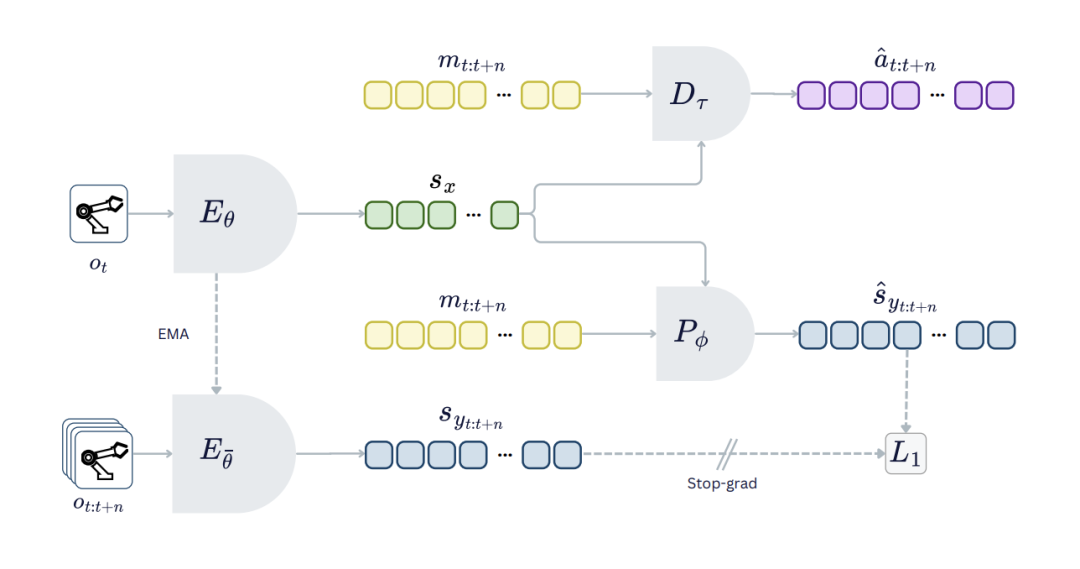
具体实现上,系统不再单一预测未来的观测特征,而是将动作序列与隐式观察序列进行联合预测。
这种联合建模方式不仅让模型理解了环境会如何演变,更理解了特定的动作指令会如何干预并改变环境的走向。
引入动作预测后,世界模型的整体表征质量得到了显著提升,在多项控制任务中表现出了更高的任务成功率。这套机制也为后续更复杂的策略学习搭建了稳固的底层架构。
V-JEPA 2:具备零样本规划能力的显式世界模型
如果说 ACT-JEPA 是控制架构的雏形,V-JEPA 2 [9] 则是该系列中具有决定性意义的里程碑。
在这个节点,JEPA 正式演变为一个能够执行理解、预测与规划的显式世界模型。
V-JEPA 2 的核心突破在于其展现出的零样本机器人规划能力。在未经特定环境数据微调的情况下,模型能够在一个完全未知的物理环境中,利用一系列视觉子目标进行多步动作推演。
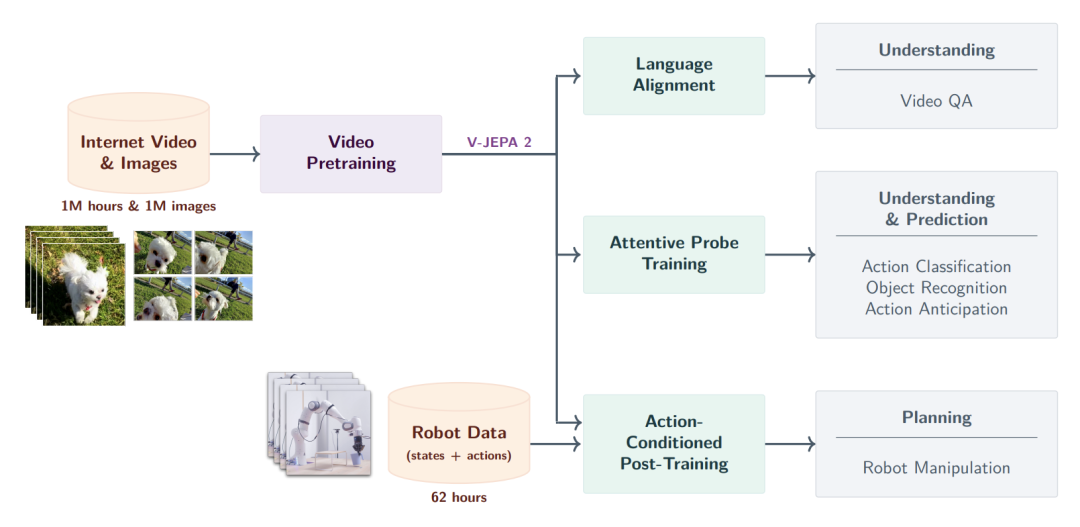
系统在隐空间中模拟出不同动作指令对应的未来状态,并从中筛选出能够达成最终目标的最佳动作路径。这种摆脱对特定场景数据依赖的规划能力,证明了基于隐式预测的世界模型在具身智能领域的巨大潜力。

随着架构在感知和控制领域的验证逐步收网,研究重心开始向两个方向聚拢:一是清理早期工程探索中遗留的冗余设计,回归数学本质;二是向着更复杂的端到端训练和长周期推理发起挑战。
LeJEPA:回归数学本质
早期的联合嵌入架构在很大程度上依赖指数移动平均、停止梯度等启发式技巧来防止模型训练过程中的表示坍塌。
LeJEPA [10] 直接从底层数学逻辑出发,引入了各向同性高斯正则化(SIGReg)。
这种优化目标能够主动约束隐空间的数据分布,彻底移除了复杂的教师学生网络架构和繁琐的超参数调度。整个计算流程被精简,让模型的并行训练变得更加纯粹和稳定。
Causal-JEPA:引入对象级掩码的因果推理
为了让系统超越表层的视觉关联,Causal-JEPA [11] 将掩码机制从基础的图像块升级到了对象级别。在训练过程中,模型必须根据环境中的其他对象来推断被掩盖对象的状态。
这种强制性的交互推理诱发了隐空间中的潜在干预机制。它不仅显著提升了系统在复杂场景下的反事实推理能力,还在智能体控制任务中实现了极高的数据效率——系统仅需极少的隐层特征维度即可完成精准规划。
V-JEPA 2.1:解锁密集特征与深度自监督
在建立动作规划能力后,V-JEPA 2.1 [12] 将重心放回了表征质量的极致打磨,属于该阶段重点拆解的核心工作。
它引入了密集预测损失,让可见的上下文标记和被掩盖的标记共同参与损失计算,从而大幅强化了模型对时空的精确定位能力。
与此同时,系统还在编码器的多个中间层级同步应用了深度自监督机制,迫使网络在较浅的层级就开始理解复杂的物理逻辑。
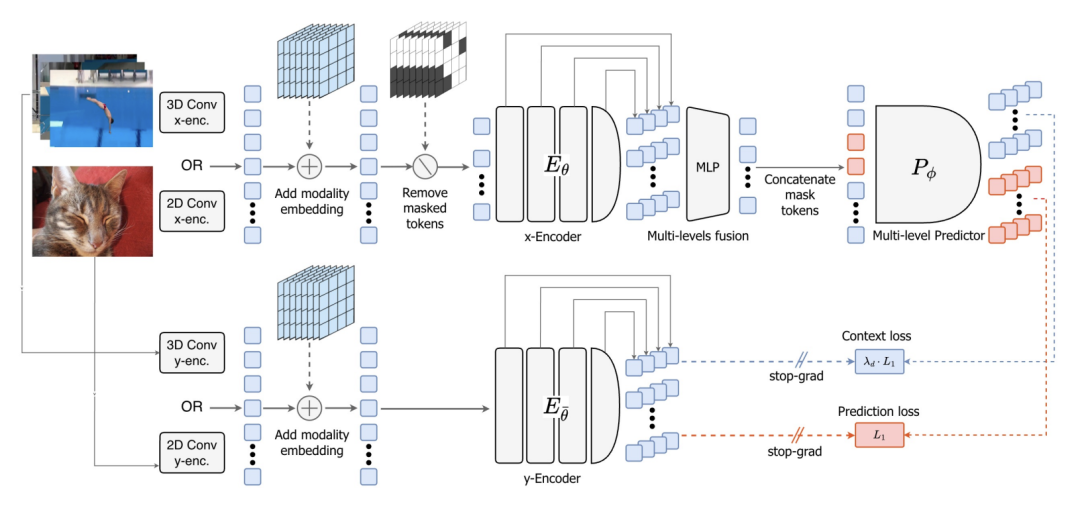
配合能够统一处理图像和视频数据的多模态分词器,该模型在短期动作预测和细粒度场景理解任务上确立了全新的性能基准。
LeWorldModel:纯粹的端到端世界模型
构建世界模型的难点在于如何保持特征空间的稳定,先前的方案往往需要拼凑多项辅助损失或依赖外部预训练的编码器。
LeWorldModel [13] 首次实现了完全从原始像素端到端稳定训练的极简架构。整个系统仅依靠两个目标驱动:下一步特征预测以及高斯正则化。
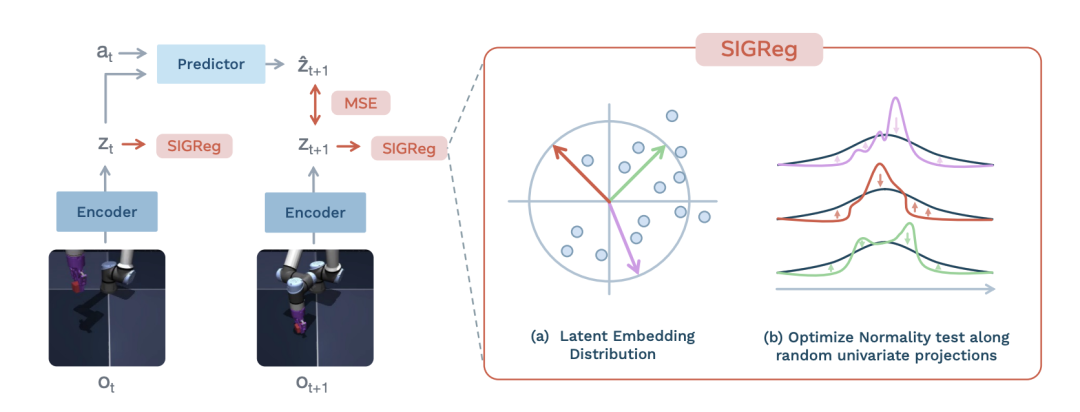
这种轻量级的纯粹设计不仅大幅降低了工程复杂度,更让其在控制任务中的推演规划速度远超庞大的传统基础模型流水线。即使在没有任何辅助监督信号的情况下,系统依然展现出了对物理规律违和事件的敏锐感知力。
ThinkJEPA:融合语义思考的长周期规划
单纯的隐空间预测在处理长视野任务时,容易陷入局部的低级特征外推。作为路线图上的最新节点,ThinkJEPA [14] 代表了向复杂推理进发的探索方向。
它将视觉语言模型中蕴含的深层语义抽象和通用知识,巧妙地编织进隐式世界模型的预测路径中。
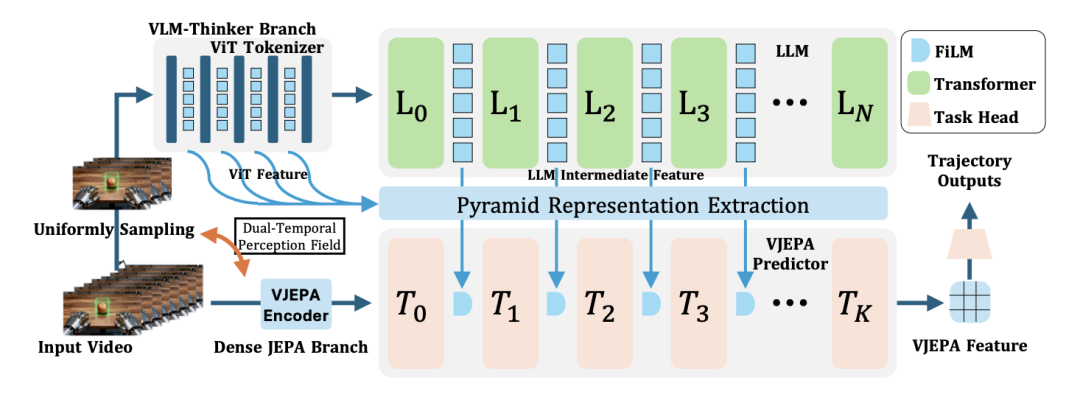
有了语义维度的方向引导,系统不仅能精准捕捉短期的物理动态,更能在长周期的跨度下完成复杂的逻辑链推演与任务统筹。
这为真正意义上具备高级认知和常识推理的通用智能体指明了演进路径。
从图像上的隐空间预测,到扩展至视频与三维空间等多模态数据,再到最终实现端到端的动作规划,JEPA 架构已经走出了早期自监督特征提取的范畴。
面对主流自回归模型在物理常识和长序列规划上的局限,彻底放弃像素重建、直接在抽象空间中推演环境演变,被证明是一条切实可行的路线。
这套机制让系统跳出了单纯的模式匹配,开始真正理解物理世界的运作规律,并具备了执行复杂决策的能力。

参考文献

[2] https://arxiv.org/abs/2301.08243
[3] https://arxiv.org/abs/2307.12698
[4] https://arxiv.org/abs/2404.08471
[5] https://arxiv.org/abs/2507.02915
[6] https://arxiv.org/abs/2404.16432
[7] https://arxiv.org/abs/2409.15803
[8] https://arxiv.org/abs/2501.14622
[9] https://arxiv.org/abs/2506.09985
[10] https://arxiv.org/abs/2511.08544
[11] https://arxiv.org/abs/2602.11389
[12] https://arxiv.org/abs/2603.14482
[13] https://arxiv.org/abs/2603.19312
[14] https://arxiv.org/abs/2603.2228


文章精选:
1.强化学习之父、图灵奖得主 Sutton 隔空回应 图灵奖得主Hinton:目前的 AI “理解不足,调参有余”





