 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库26年4月1日,全球AI资讯约15条:全球OCR新王来自中国GitHub狂揽73300+Star、黄仁勋站台抱抱脸机器人卖爆、玻色量子完成10亿元B轮融资等
昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
1-1. Meta华人实习生搞出超级智能体!自己写代码实现自我进化
Meta华人实习生团队提出“超级智能体”(Hyperagents),引发AI界广泛关注。该技术核心是将的“哥德尔机”与达尔文式开放进化结合,打造能自主迭代改进自身算法的AI系统——即“达尔文哥德尔机”(DGM)。
实验显示:在编程基准SWE-bench上,DGM将任务解决率从20.0%提升至50.0%;在多语言编程测试Polyglot中,也从14.2%跃升至30.7%,显著超越人工设计的智能体。更关键的是,其升级能力可跨模型、跨编程语言迁移。而升级版“DGM-Hyperagents”进一步实现“元认知自我修改”:不仅优化任务表现,还持续改进“如何自我改进”的方法。https://www.qbitai.com/2026/03/393645.html

1-2. 黄仁勋也站台的抱抱脸机器人卖爆了,背后公司竟来自中国
Hugging Face推出的桌面机器人Reachy Mini火了:身高28cm、售价仅299美元起,上线5天销售额破100万美元,已售出超3000台,甚至登上黄仁勋CES展台。它不靠炫技翻跟头,而是用“能看、能听、能说、会动”的多模态交互,让AI真正“活”在物理世界中——比如转头、摆触角、显示emoji,和你自然对话。
鲜为人知的是,这款机器人由中国开源硬件公司矽递科技(SeeedStudio)代工打造。它不是整机厂商,而是具身智能的“基建者”:深度适配英伟达Jetson平台,提供主控、传感器、机械臂等开源套件,帮开发者快速造机器人。https://www.qbitai.com/2026/03/393483.html
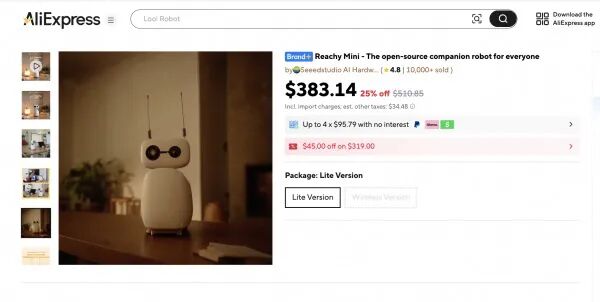
1-3. 阿里发布Qwen3.5-Omni,多模态能力超越Gemini-3.1 Pro
阿里最新发布的Qwen3.5-Omni,是全球首个真正“全模态原生”的大模型——能同时理解并生成文字、图片、语音、视频,甚至实时音视频流。它在215项权威测试中全部拿下SOTA(性能第一),尤其在音视频理解、嘈杂环境语音识别、113种语言/方言识别等硬指标上大幅超越谷歌Gemini-3.1 Pro。
更惊艳的是“音视频Vibe Coding”能力:用户对着镜头口述需求+手绘草图,模型就能自动生成带UI的APP或网页代码——这不是预设功能,而是多模态能力自然涌现的新能力。成本也极具竞争力:API调用仅需每百万Tokens不到0.8元,不足Gemini-3.1 Pro的十分之一。https://www.qbitai.com/2026/03/393460.html
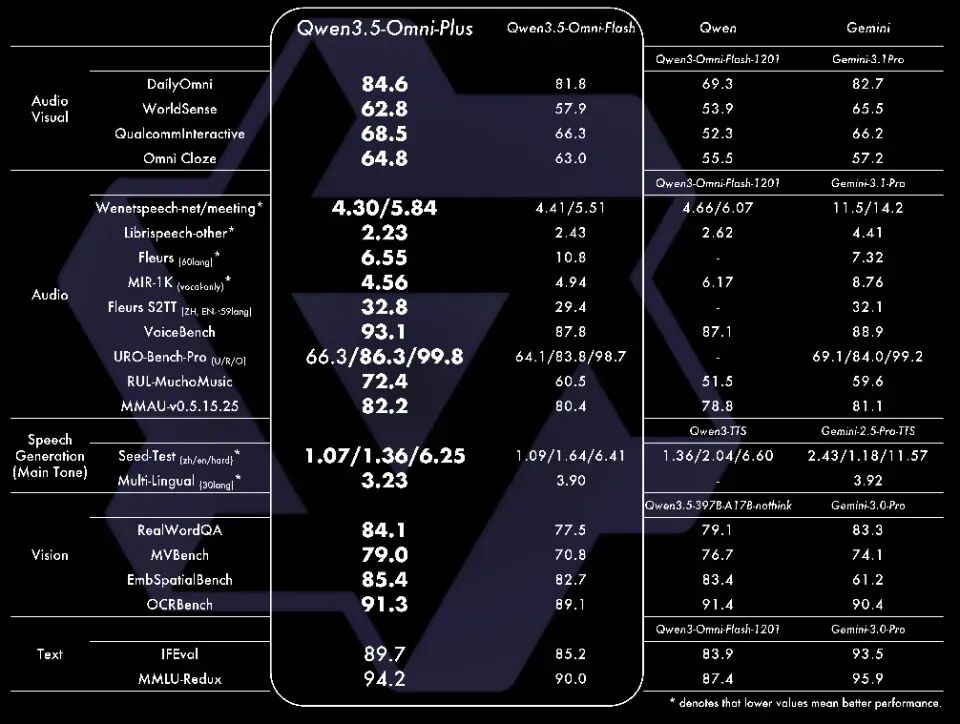
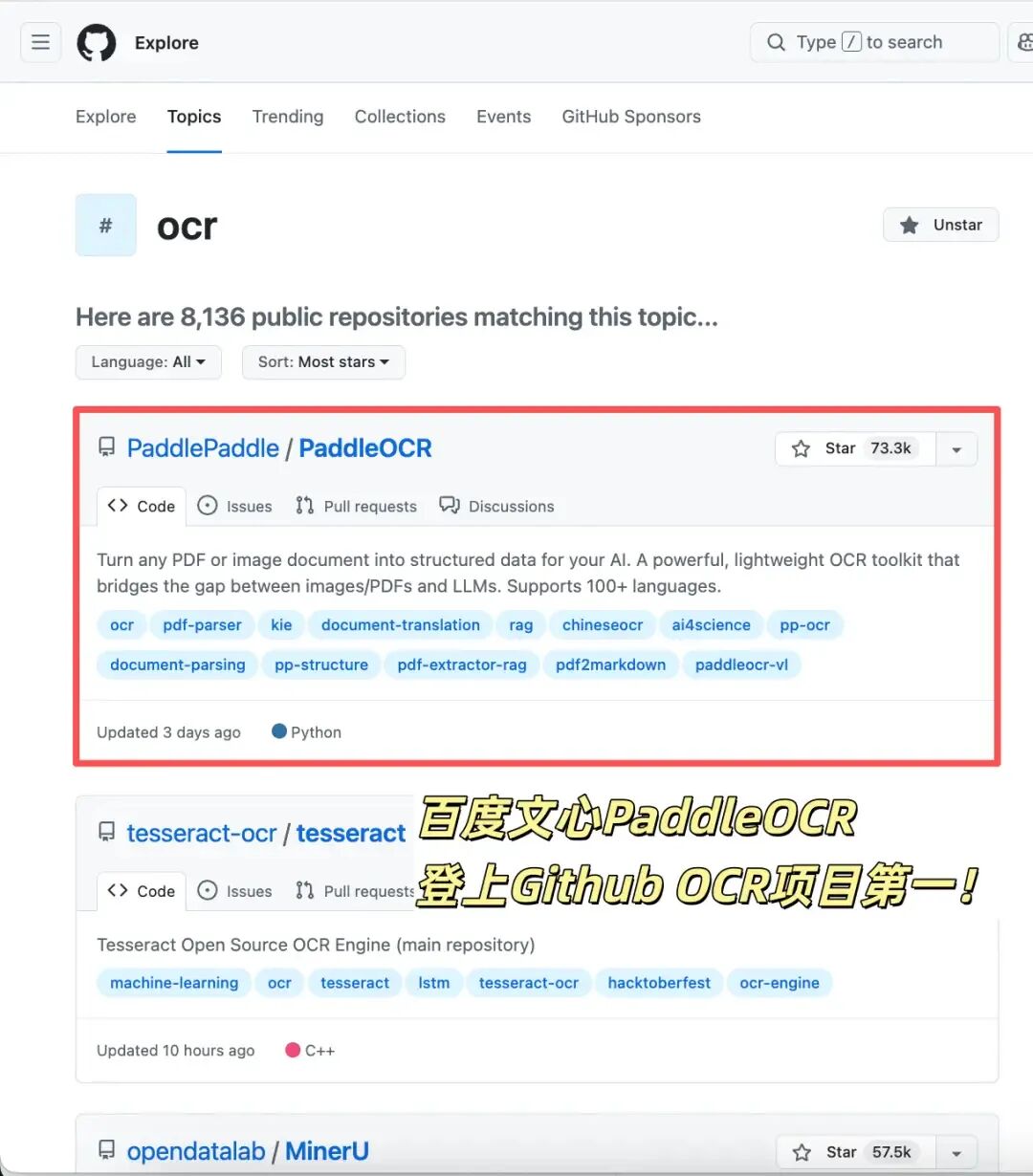
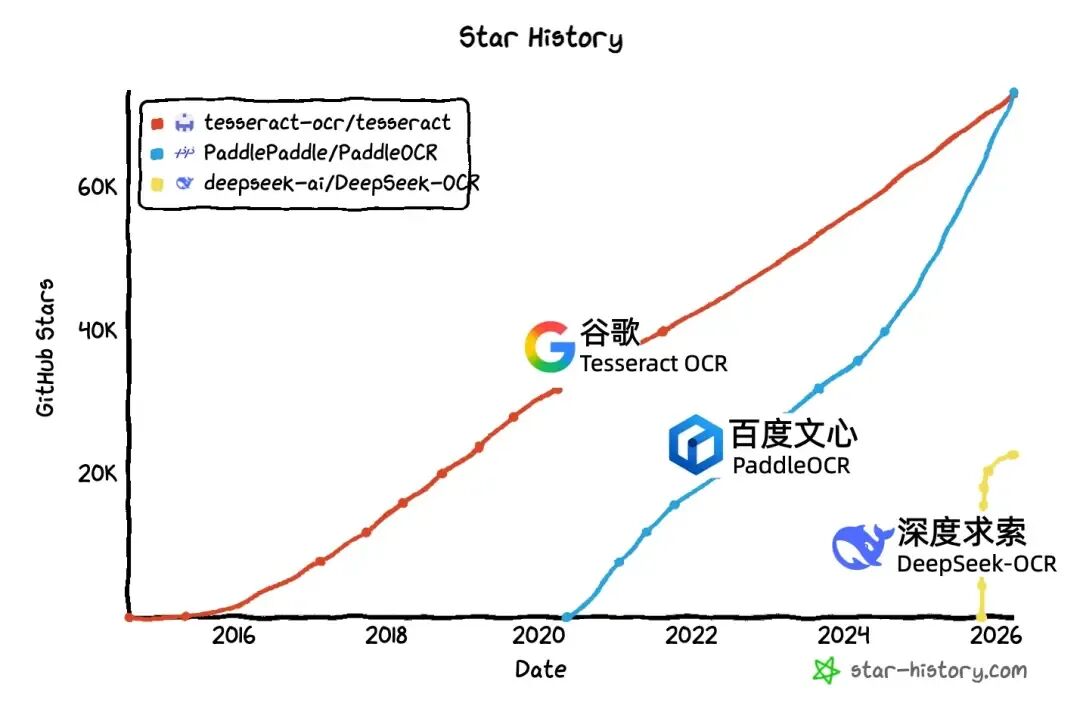
1-4. 全球OCR新王来自中国开源!GitHub狂揽73300+Star
PaddleOCR以73,300+ GitHub Stars超越谷歌Tesseract,首次让中国开源项目登顶全球OCR榜首。背后依托百度文心大模型,2025–2026年密集推出PaddleOCR-VL与VL-1.5:仅0.9B参数,却在权威评测OmniDocBench V1.5中拿下94.5分全球第一,远超GPT-4o等千亿级模型。
并首创“异形框定位”,精准识别歪斜、畸变文档。更惊艳的是轻量级PP-OCRv5——仅500万参数,准确率从53%跃升至80.1%,证明“好数据比大模型更关键”。如今,PaddleOCR已覆盖160国、支持110+语言,成为大模型时代不可或缺的“信息钥匙”https://www.qbitai.com/2026/03/393433.html
1-5. 88岁算法祖师爷惊呆!Claude联手GPT攻破30年难题,14页论文0修改
88岁的“算法祖师爷”高德纳(Donald Knuth)近日宣布,困扰数学界数十年的哈密顿分解难题终于被彻底解决!该问题要求将特定图结构精确拆分为三个长度均为m³的哈密顿环——此前仅对奇数m有构造解,而偶数m≥8长期无通用方案。
今年3月,AI成为破局关键:Claude 4.6率先攻克奇数情形,GPT-5.4 Pro则“零修改”直出14页严谨论文,不仅证明了偶数m≥8的普适解,更通过Lean形式化验证确认其数学正确性,并成功计算验证至m=2000。多位研究者还通过“Claude+GPT多智能体协作”,发现更简洁构造法(如仅用三行C代码判断路径方向)。https://www.163.com/dy/article/KPBN4UTN0511ABV6.html

1-6. 6小时,200美元,0人类代码:Anthropic把AI编程推过了临界点
在AI编程新时代,代码本身没消失,但“会写代码”正迅速失去稀缺性。Anthropic最新实验揭示:真正突破不在AI多聪明,而在它能否稳定交付完整项目——比如仅凭一句需求,6小时、200美元,自主完成一款可运行的复古游戏编辑器(RetroForge),涵盖规划、编码、测试、迭代共10轮以上,通过27项严格验收。
对比单智能体版本(20分钟、9美元)仅产出“形似实崩”的空壳,三智能体协作系统(Planner+Generator+Evaluator)首次模拟出真实产品团队:规划拆解16项功能、工程师写码、质检员严查设计质量与原创性——甚至揪出“路由错序”“事件未触发”等工程级缺陷。https://www.163.com/dy/article/KPBN41P00511ABV6.html

原文链接:https://www.anthropic.com/engineering/harness-design-long-running-apps
AI大模型算法、赛事和会议
2-1. 大道至简!斯坦福、英伟达、新国立联合推出InfoTok,用信息论重新定义高效视频分词
在生成式AI中,视频分词器是理解与生成视频的第一步——把原始画面压缩成Token序列。但传统方法“一刀切”:无论静止蓝天还是高速飙车,每帧都用相同数量Token,造成严重浪费(如纯白边框也占满Token)。
斯坦福、NVIDIA Cosmos与新国大团队提出InfoTok,首次将香农信息论引入视频分词:越可预测的画面(信息量越低),分配越少Token;越复杂突兀的内容(信息量高),自动多分Token。实验显示,InfoTok实现2.3倍平均压缩率,重建质量全面优于现有方案,在TokenBench等基准上节省20% Token仍无损重建,推理速度更比同类自适应方法快11倍。https://aitntnews.com/newDetail.html?newId=23589
AI基础设施方面(硬软件、数据)
3-1. 玻色量子完成10亿元B轮融资,“十五五”规划专用量子计算机赛道唯一代表!
玻色量子近日完成10亿元B轮融资,成为国家“十五五”规划中专用量子计算机赛道唯一代表企业。作为中国唯一同时布局“通用+专用”光量子计算的公司,其技术已实现关键突破:五年内完成4次迭代,推出100/550/1000量子比特专用机。
2026年上半年将发布国内首个千比特可扩展专用机——“驭量·山海1000”,支持1000比特标准运行、3000比特超频模式,并实现7×16小时稳定运行。目前已向国家超算成都中心、中国移动等交付真机,交付数量与性能指标领先国际同行。云平台调用量破亿次,覆盖900+高校、10000+开发者,在AI制药、金融优化、新材料发现等20+行业落地100+场景。https://www.qbitai.com/2026/03/393856.html

AI人才和资本动态
4-1. OpenAI 关停 Sora 细节:每天亏损百万美元,迪士尼高管在官宣前一小时才得知
OpenAI 旗下视频生成App“Sora”突然关停,成为AI行业一次标志性收缩。这款被CEO山姆·阿尔特曼誉为“GPT时刻”的产品,曾登顶App Store榜首,峰值用户约100万,但迅速下滑至不足50万,日均亏损高达100万美元。
高昂成本是主因:视频模型训练耗能远超语言模型,在OpenAI算力日益吃紧的背景下,Sora被内部判定为“得不偿失”。更严重的是,关停打乱了与迪士尼的关键合作——后者原计划授权200多个IP并投资10亿美元,但高管竟在官宣前一小时才知情,资金从未到账,合作实质搁浅;如今迪士尼已转向与其他十余家AI公司接洽。阿尔特曼称此举是“艰难但必要的取舍”。https://www.1ai.net/51694.html

4-2. 让“龙虾”保密,00后博士休学创业又融资了
荆华密算由北大博士、2000年出生的林修醇创办,专注“高性能AI密态计算”——一种能让数据全程以密文状态完成计算的前沿安全技术。通俗地说,密态计算如同让服务器“蒙眼盲算”,数据在传输、存储、计算甚至硬件层始终加密,真正实现“可用不可见”。过去该技术因速度极慢被称为“二十年炸不响的哑弹”,但荆华密算通过专攻AI算子优化,攻克精度无损、性能可用的难题。
近日,公司完成数千万元天使轮融资,由盛景嘉成领投,上市公司国联股份、博彦科技及英诺基金跟投。技术已获清华任炬教授等权威背书,并拿下2025全国顶级创业大赛冠军。当前正加速落地政务、金融、医疗等高敏场景,推出“龙虾安全卫士”等即插即用产品。https://aitntnews.com/newDetail.html?newId=23601
AI风险与政策管理
5-1. 大部分人都没有的习惯,斯坦福最新报告证实:点踩对AI来说其实很重要!
这份研究报告揭示了一个反直觉却至关重要的现象:AI“看似能用”,恰恰是最危险的陷阱。研究分析了超100万条真实GPT-4对话,发现78%的AI失败是“隐性”的——它跑偏了、答错了、代码有bug、摘要超字数,但用户没点“踩”、没纠正、甚至直接关窗重来。
更惊人的是:93%被系统标为“勉强可接受”的对话,其实暗藏至少一个严重缺陷(如用已淘汰语法写代码)。研究提炼出8类隐性失败,根源直指LLM的“骨子里的习惯”:79%的失败源于AI宁可胡编乱造,也不愿主动澄清模糊指令。参数堆叠、模型升级(如GPT-5、Claude 4.7)对此几乎无效——报告预测,未来94%的同类故障仍将顽固存在。https://view.inews.qq.com/k/20260326A0896R00

写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





