 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库2026年3月通用文本测评——SWE(软件工程)分析:海外旗舰领跑,国产模型梯队化突围

# SuperCLUE-SWE介绍
SuperCLUE-SWE是专为中文开发环境打造的软件工程评测基准,核心聚焦大型语言模型解决实际软件工程问题的真实能力。其任务实例均源自中文开源项目的真实 GitHub 问题(issue)及对应修复方案,精准贴合中文开发者的实际开发场景,有效填补了现有评测基准在中文问题描述适配、中文开发环境评估上的空白。
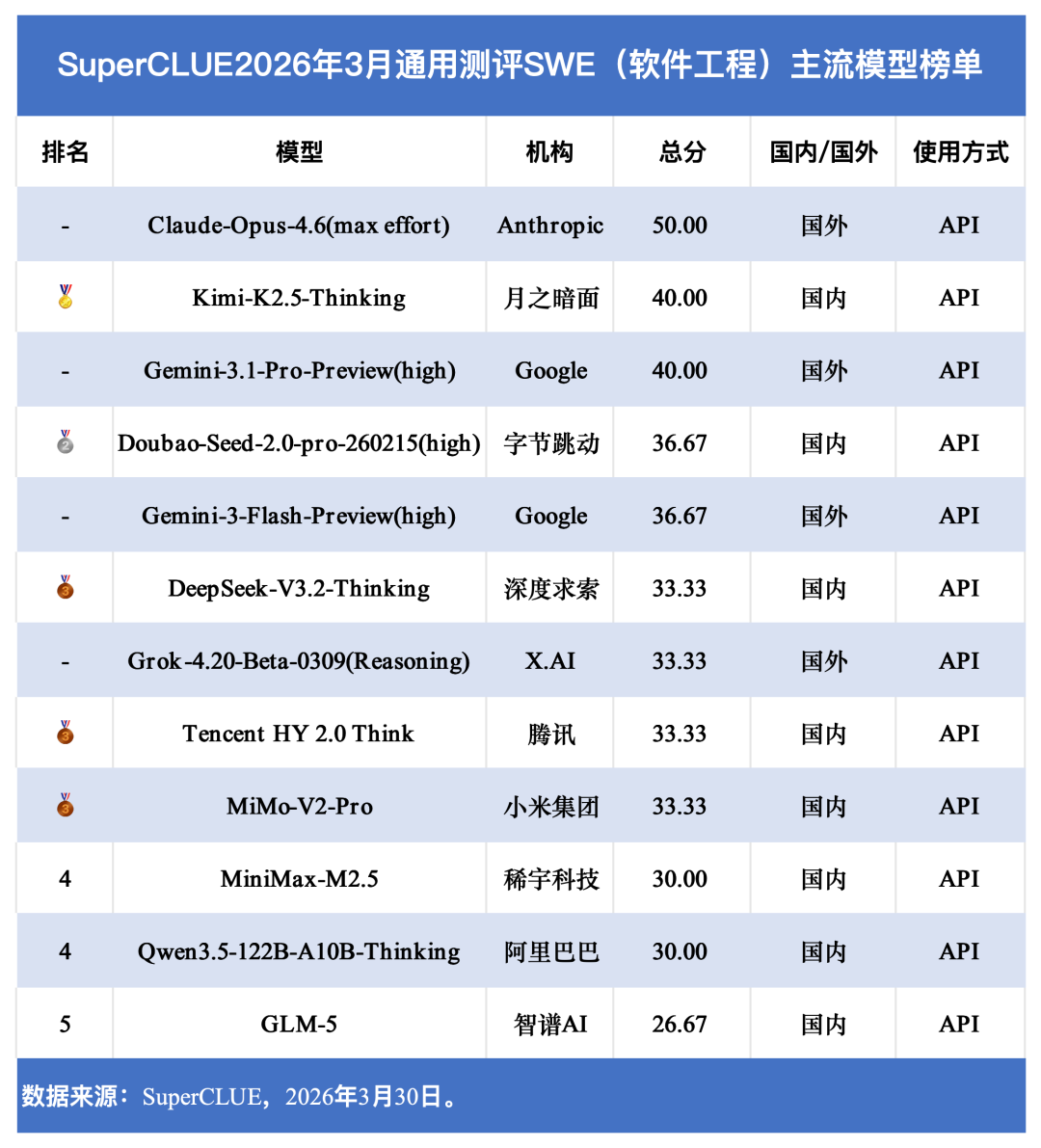
本次SWE(软件工程)测评任务也是 2026 年 3 月 SuperCLUE 通用测评代码生成部分的子任务,整体成绩分布清晰:Claude-Opus-4.6 (max) 以 50.00 分领跑,国产模型 Kimi-K2.5-Thinking 以 40.00 分追平国际旗舰,豆包、DeepSeek 等国产模型形成密集竞争力带,国产大模型已迈入与国际模型并跑的新阶段。
(SuperCLUE-SWE)中文「软件工程」测评基准方案参考:中文「软件工程」测评基准方案发布!(SuperCLUE-SWE)
2025 年 12 月测评结果详情请见:中文「软件工程」测评结果发布:Gemini-3-pro夺得头筹,Claude、GPT紧随其后
2026年3月完整榜单详情请见:2026年3月中文大模型基准测评结果发布!小米MiMo-V2、美团LongCat上榜
测评摘要
测评要点 1:海外旗舰仍保持领先,国产模型差距明显收窄
本次 3 月测评中,Claude Opus 4.6 Max 以 50% 通过率独居榜首,在复杂工程修复与补丁规范性上优势显著。国际头部模型整体仍占优,但与国产顶尖模型的分差已大幅缩小。
测评要点 2:国产头部模型跻身国际准旗舰,中坚力量形成密集竞争格局
Kimi K2.5 Thinking 追平 Gemini 3.1 Pro,豆包、DeepSeek、混元等国产模型在中高分段表现集中,仅在高阶复杂场景与国际顶尖存在差距。
测评要点 3:深度推理成为 SWE 核心胜负手,国产模型迭代潜力强劲
Thinking/Pro 增强版表现突出,印证推理能力决定任务上限。国产模型已从 “跟跑” 进入 “并跑” 阶段,正加速向 “工程级好用” 升级,有望打破海外长期垄断。
# 测评题目概览
本次SWE测评基于30道真实软件工程实例,以补丁修复后仓库测试通过率为核心指标,聚焦模型在代码缺陷定位、修复方案生成、工程化测试验证的核心能力。SWE 作为本次月榜代码生成部分三大子任务中难度最大、分数最低、分化最明显的一项,是拉开模型总分差距的关键。
总题数:30
涉及仓库数:9
仓库分布(题数从多到少)
# 榜单概览
# 3月主流模型测评成绩分析
本文选取国内外主流大模型进行重点呈现,覆盖海外头部旗舰与国产主流模型,清晰展现当前大模型软件工程能力的竞争格局。下表为本次测评主流模型核心指标对比:
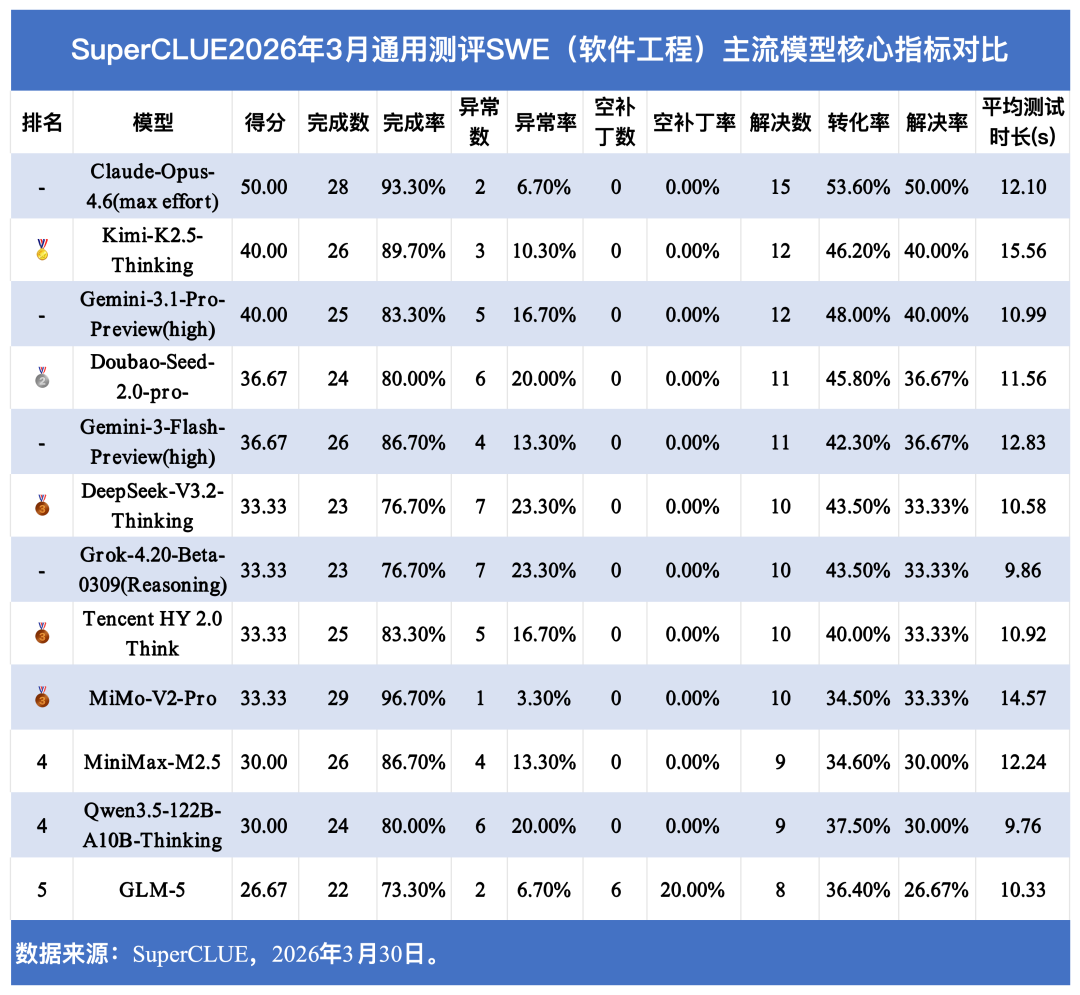
注:
1. 完成数(completed):成功走完评测流程并获得有效判分的题目数量;
2. 完成率 = 完成数 / 提交数,反映评测流程稳定性;
3. 异常数(error):评测过程中异常终止的题目数量(如 Patch Apply Failed、超时等);
4. 异常率 = 异常数 / 提交数,反映工程执行失败占比;
5. 空补丁数(empty_patch):未提取到有效 diff 或 patch 为空的题目数量;
6. 空补丁率 = 空补丁数 / 提交数,反映有效补丁产出能力;
7. 解决数(resolved):修复成功并通过评测的题目数量;
8. 转化率 = 解决数 / 完成数,反映有效评测后的修复质量;
9. 解决率 = 解决数 / 30,用于模型最终成绩横向对比(本批测评固定 30 题)。
整体梯队:海外闭源旗舰断层领先,国产模型形成清晰格局
结合本次测评解决率,国内外模型梯队划分明确,各梯队能力边界清晰,国产模型在中上游区间形成明显竞争优势,展现出强劲的发展势头。
1. 第一梯队(解决率50%):海外闭源旗舰的绝对主场
Claude Opus 4.6 Max以15/30(50%)的解决率独居第一梯队,是本次测评中唯一突破50%通过率的模型。在「改对代码并通过仓库全量测试」这一硬指标上,该模型展现出对复杂工程问题的超强理解、边界条件的全面考量以及patch格式的高度规范性,延续了海外闭源旗舰在SWE领域的统治力,成为当前大模型软件工程能力的绝对天花板。
2. 第二梯队(解决率40%):国产头部跻身国际准旗舰行列
Kimi K2.5 Thinking与Gemini 3.1 Pro Preview以12/30(40%)的解决率并列第二梯队,成为第一梯队之下最具竞争力的旗舰/准旗舰模型。值得关注的是,Kimi K2.5 Thinking作为国产模型代表,成功追平Gemini 3.1 Pro Preview这一国际主流旗舰,彰显了国产头部模型在软件工程领域的快速迭代能力,成为国产模型向国际第一梯队发起冲击的核心力量。
3. 第三梯队(解决率30%-37%):国产中坚力量密集竞争,形成核心密度带
豆包Doubao-Seed、DeepSeek V3.2 Thinking、腾讯混元2.0 Thinking、MiMo V2 Pro、MiniMax-M2.5、Qwen3.5-122B-A10B-Thinking与Gemini 3 Flash同处这一梯队,解决率均集中在9-11/30(30%-37%)区间。这一梯队是本次测评的核心竞争区,其中国产模型占据绝对多数,充分展现出国产主流模型在SWE领域的整体厚度。目前,国产中坚模型已突破中低难度SWE任务的能力瓶颈,能够稳定处理常规工程bug修复,仅在高难度多文件联动、复杂依赖冲突等场景中,与国际头部模型仍有一定差距。
# 核心对比
国产与海外的差距点,亦是国产的突破点。从版本能力差异、国产模型内部竞争两个维度,清晰呈现了SWE领域的能力特征,也为国产模型后续优化指明了核心方向。
1. 同段位硬核对标:Kimi-K2.5-Thinking与Gemini 3.1 Pro关键指标对比
本次测评中,Kimi-K2.5-Thinking 与 Gemini-3.1-Pro-Preview 总修复率同为 40.00%,并列第二梯队,是中外旗舰模型最具代表性的一组对标。结合完整评测数据对比如下:
Kimi 在完成数、完成率、异常控制上更优,流程稳定性与工程稳健性更强;
二者空补丁率均为 0,有效补丁生成能力相当;
实际解决数完全一致,整体工程修复能力处于同一水平;
Gemini 在修复转化率、测试执行效率上小幅领先。
为直观对比,我们对部分指标进行归一化处理:
异常率、空补丁率采用
1 − 数值反向换算;测试时长采用
Max(时长) / 时长归一化。
据此绘制雷达图,可直观呈现两款模型的综合表现差异,数值越大说明在该维度的能力越好。
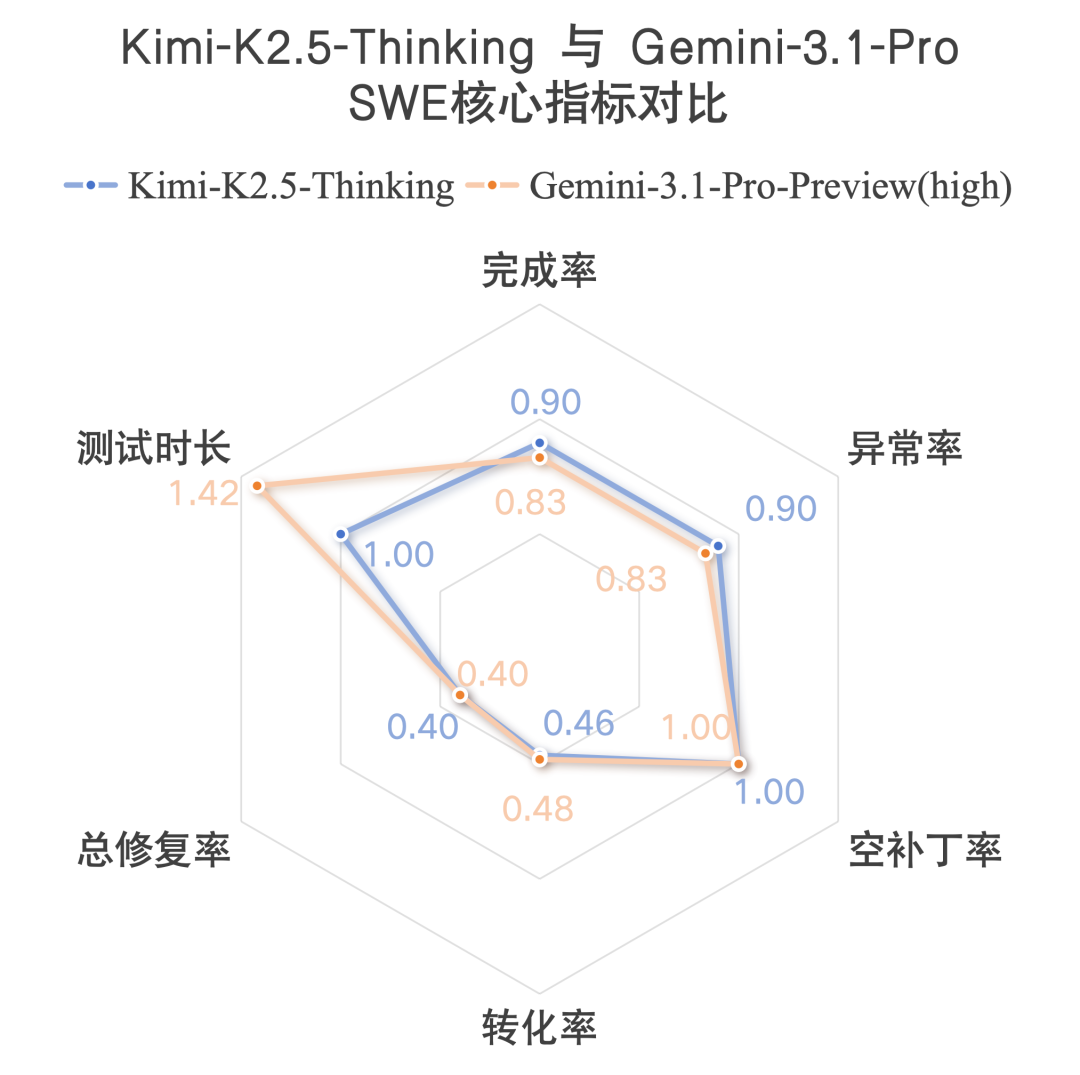
整体来看,二者核心性能差距十分微弱。在工程修复能力相当的前提下,两款模型在执行效率上存在明显分化:Gemini 单题测试耗时更短,推理与测试链路响应更快;Kimi 耗时相对更长,反映出其在复杂工程场景下的代码解析、测试执行链路仍存在一定优化空间。不过该差异仅体现在耗时维度,并未对最终修复成功率与补丁质量产生影响。 综合而言,两款模型核心指标整体接近,仅在执行效率上差距相对突出。Kimi-K2.5-Thinking 已在核心修复能力上追平国际顶级旗舰 Gemini 3.1 Pro,同时在工程稳定性、任务完成度上更具优势,充分标志着国产头部模型正式跻身国际准旗舰第一方阵。
2. Thinking/Pro 增强版成胜负手,中外模型均印证推理能力决定 SWE 上限
对比本次参评的推理增强版与基础旗舰版表现可见,深度推理能力是 SWE 任务的核心变量。国际模型中,Gemini 3.1 Pro 以 40% 解决率领先 Gemini 3 Flash(37%),凸显复杂工程场景下强推理、长上下文理解的关键价值;而国产模型均以 Thinking 增强版为主力参战,包括 Kimi K2.5 Thinking、DeepSeek V3.2 Thinking、腾讯混元 2.0 Thinking 等,整体表现已接近国际旗舰水准。这一对比表明,强化深度推理既是海外头部模型的优势来源,也是国产模型缩小差距、实现赶超的关键突破口。
3. 国产模型无单一 “天花板”,迭代活力成核心竞争力
本次测评中,国产主流模型解决率集中在 30%–37% 区间,并未出现一家独大的局面,而是形成了Kimi 领跑、豆包 /DeepSeek /混元 /MiMo多点并进的良性竞争格局。从工程可用性指标进一步观察,Kimi、豆包在补丁应用失败占比上表现更优,体现出更强的补丁落地稳定性;DeepSeek 则在 sympy 等数学相关仓库的题目上修复成功率更为突出,呈现出一定的场景化特点。整体来看,国产模型已形成均衡且密集的竞争力分布,为后续持续迭代提升奠定了良好基础。
# 测评局限
本次测评基于30道实例的小样本测试,百分比结果存在一定波动,更适合体现模型能力趋势与梯队对比,而非精确的数值排名。同时需注意,部分模型存在error_instances(评测过程异常),该类异常并非模型自身能力问题,而是受基础设施、提交格式等外部因素影响,需理性看待各模型排名。尾部模型的低分不应简单归因于模型能力差距,更主要受评测链路稳定性影响。结合完整榜单中 GPT-5.4(xhigh)、Spark X2、Step-3.5-Flash、Mistral Large 3、Llama-4-Maverick-17B-128E-Instruct等模型表现看,低修复率背后主要有三类客观因素:其一,推理或网关稳定性不足,导致任务完成率偏低,部分模型未能完整跑完全部样本;其二,补丁工程可用性不稳定,常见为补丁应用失败、多文件补丁仅部分代码块命中等,任务被判为异常而非有效修复失败;其三,存在空补丁或内容提取失败,任务尚未进入测试验证环节。因而,对尾部模型应结合完成率、空补丁率和异常占比进行综合判断,区分“模型能力不足”与“流程未跑通或补丁格式不规范”两类问题,避免对结果作单一化解读。
# 总结
2026 年 3 月 SWE 测评格局明朗:Claude Opus 4.6 Max 领跑,Kimi K2.5 Thinking 代表国产模型达到国际准旗舰水准,豆包、DeepSeek、混元等形成密集竞争力带,国产模型已从 “跟跑” 迈入 “并跑” 阶段。
当前国产模型与海外第一梯队的差距集中在高阶 SWE 场景,但迭代速度快、中低难度任务表现成熟,正从 “能用” 向 “工程级好用” 跃升。未来 SWE 竞争聚焦全流程复杂工程能力,国产模型的梯队优势与高速迭代,有望打破海外长期垄断。
# 加入社群






