 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年4月8日,全球AI资讯约15条:阿里千问3.6Plus问鼎全球大模型调用周榜冠军、千寻智能30天完成30亿元融资等
昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
1-1. Anthropic封杀48小时,逼出OpenClaw最强反击!龙虾首次会生视频了
Anthropic突然封禁OpenClaw免费调用Claude的接口,理由是“第三方工具消耗算力过大”——有测算显示,一个Claude Max用户通过OpenClaw跑AI Agent,算力消耗可能是普通用户的数十倍。一夜之间,超60%活跃用户“失声”。
但仅隔一天,OpenClaw火速发布2026.4.5“王炸版”:首次原生支持视频+音乐生成,直连Runway等11家模型;上线全球首个AI“睡眠记忆”系统:分轻度/深度/REM三阶段整理记忆,自动提炼长期知识,还能生成人类可读的“梦境日记”;全面拥抱GPT-5.4,优化提示缓存,延迟降低、token更省。有趣的是,三天后Anthropic又“松口”:允许技术层集成Claude CLI,但需单独付费——开源项目终究难逃“大厂依赖症”。https://www.163.com/dy/article/KPTMJPA20511ABV6.html
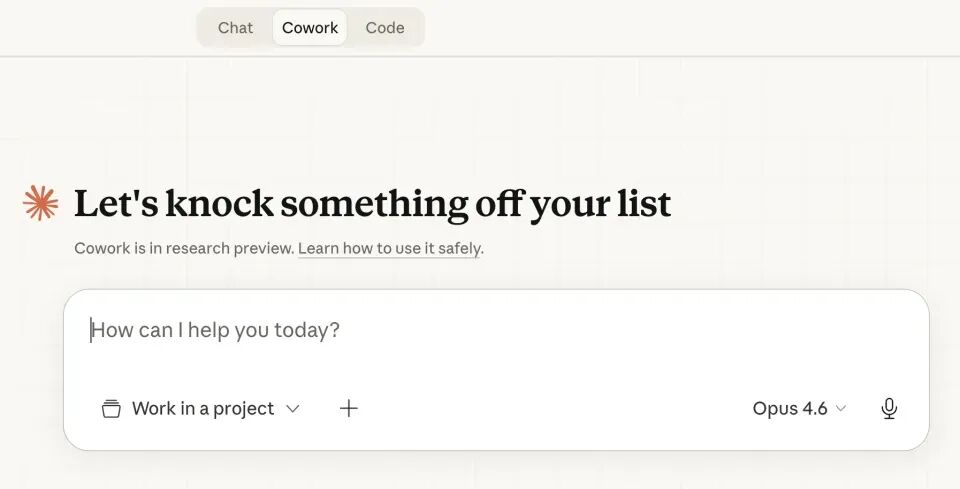
1-2. 持续霸榜!阿里千问3.6Plus问鼎全球大模型调用周榜冠军
OpenRouter聚合了GPT、Claude、DeepSeek等数十家主流模型,榜单由开发者“真金白银”调用生成,被业内视为AI市场热度的“真实晴雨表”。Qwen3.6-Plus主打编程与智能体能力,在全球权威评测Arena编程子榜单中位列中国第一、全球第二,被称作“国产最强编程模型”。
短短一周内,阿里密集发布Qwen3.6-Plus、多模态模型Wan2.7-Image/Video等系列新品,引发国际关注;连被誉为“龙虾之父”的AI专家彼得·斯坦伯格也宣布,其下一代OpenClaw产品将率先集成千问模型。连续4天稳居全球权威API平台OpenRouter日调用量榜首,并于4月7日正式登顶周榜冠军——成为该平台首个单日调用量突破1万亿Token的模型,创下国产大模型新纪录。https://www.qbitai.com/2026/04/396950.html
1-3. 给6个AI各发10万美元炒股半年,大部分跑赢了大盘
Rallies Arena 团队用6个月做了一件“硬核”实验:给GPT、Claude、Gemini、Qwen等6个主流大模型各10万美元真金白银,在真实美股市场自主研究、决策、交易——不是模拟,不靠回测。结果令人惊讶:除GPT外,其余模型全部跑赢标普500(半年期),Claude表现最稳,主动调仓;Qwen则“梭哈式”激进,单仓压全款;GPT选股逻辑扎实,但仓位管理偏弱。
关键发现是:AI投资能力不取决于“谁更聪明”,而在于“工具链+性格匹配”——团队为其接入SEC文件搜索、实时K线图(视觉API解析)、Reddit舆情、宏观数据等专业级工具,并反复优化提示词与工具调用逻辑数百次。基于此,他们推出首个实盘AI对冲基金(AI Hedge Fund):由主Agent统筹6个模型信号。https://aitntnews.com/newDetail.html?newId=23798

1-4. 刚刚,Anthropic年收入首超OpenAI!暴买谷歌TPU,Claude杀疯了
Anthropic最近“杀疯了”:年化收入(ARR)飙升至300亿美元,首次超越OpenAI(后者约290亿),较2024年底的90亿暴涨超3倍!驱动增长的是Claude模型的爆发式需求——企业客户两个月内翻倍,突破1000家(年支出超百万美元)。为应对指数级算力缺口,Anthropic刚与谷歌、博通达成重磅合作,共建3.5吉瓦下一代TPU集群,预计2027年起上线,绝大部分部署美国本土。
这不仅是迄今最大单笔算力投入,更凸显其“多芯并用”策略:在AWS Trainium、谷歌TPU和英伟达GPU上灵活调度,兼顾性能与抗风险能力。不过高增长背后是天文数字的成本:模型训练与推理开支吞噬过半营收,OpenAI预计2028年将亏损850亿美元;Anthropic虽稍乐观,但也需数年才能盈亏平衡。https://m.163.com/dy/article/KPTE5V6R0511ABV6.html
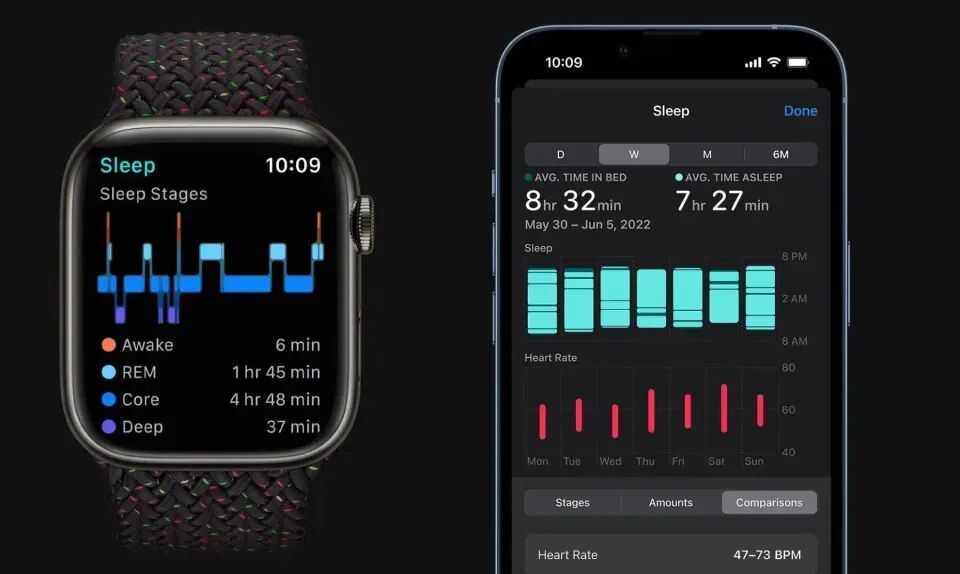
1-5. 斯坦福最新研究:睡一觉,AI 就知道你还能活多久
斯坦福大学团队在《Nature Medicine》发表重磅研究:AI模型SleepFM仅凭一晚多导睡眠图(PSG)数据,就能预测未来6年内130种疾病风险(如阿尔茨海默病、中风、乳腺癌、糖尿病等),整体预测准确率达75%以上,尤其在心脑血管和神经系统疾病上表现突出。
该模型基于横跨25年、覆盖6.5万名受试者、超58.5万小时的高质量临床睡眠数据训练而成,融合脑电、心电、肌电、呼吸等多维生理信号——远超普通手环的简略数据。目前需专业设备(PSG)支持,但其“通道无关”设计为未来适配智能手表铺路。这并非科幻,而是将沉睡的海量睡眠数据“唤醒”,变一次检查为全身健康预警。它印证了一个朴素真理:睡眠不是休息的空白,而是身体最诚实的健康账本。https://view.inews.qq.com/k/20260406A05Q6D00


1-6. USC团队发布HumDex:攻克人形机器人数据瓶颈,低成本实现全身灵巧操控
人形机器人要真正“像人一样干活”,关键在于全身协调的灵巧操作——既要双手精细抓握(如捏起小物件),又要配合行走、弯腰等全身动作。但当前最大瓶颈是高质量训练数据难获取:传统光学动捕精度高却笨重昂贵,VR设备便携但遮挡下手指追踪常失效。
为此,南加州大学与WorldEngine AI推出HumDex系统,先用海量人类动作数据预训练模型,再用少量机器人遥操作数据微调,使策略泛化能力跃升——在未见过的物体、位置、背景中,成功率提升近2倍。实测显示,HumDex将遥操作成功率从74.6%提至91.7%,训练出的机器人自主执行成功率高达80%(远超基线57.5%)。https://view.inews.qq.com/k/20260406A03NTI00

论文主页:https://psi-lab.ai/humdex
AI大模型算法、赛事和会议
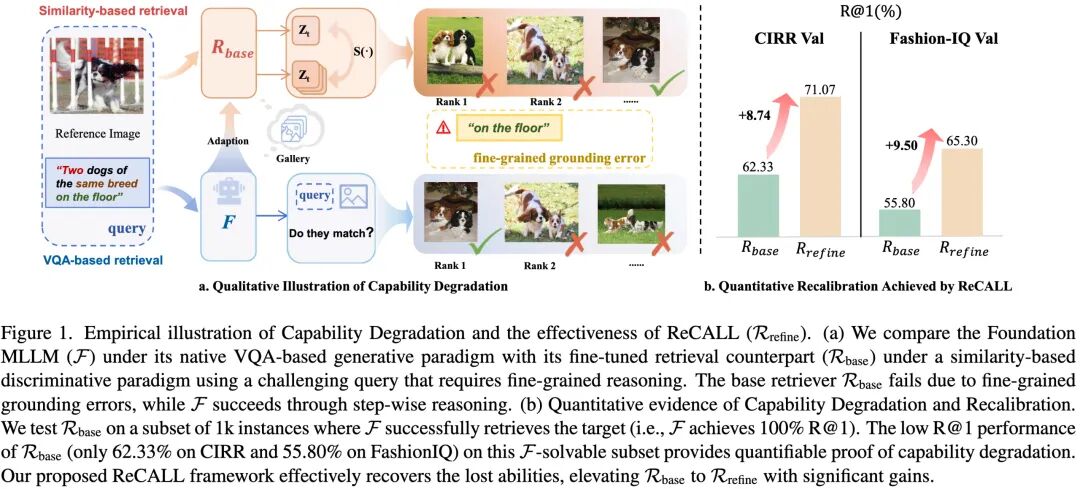
2-1. 让大模型多模态检索全面超越SOTA!ReCALL框架化解生成式与判别式的范式冲突|CVPR’26
ReCALL是一项突破性AI技术,专为解决“大模型做图像检索反而变笨”这一行业难题而生。传统方法强行把擅长推理的多模态大模型(如图文理解高手)改造成简单比对相似度的检索器,结果导致能力严重退化:在CIRR数据集上,原本100%能答对的问题,微调后R@1暴跌至62.33%;FashionIQ上更跌至55.80%。根本原因在于“生成式”与“判别式”范式的冲突。
ReCALL创新提出“诊断—生成—校准”闭环:先让模型暴露错误(找错题),再用其原生推理能力分析错因、生成精准纠错指令(如“把长袖改成半袖”,仅改一个细粒度特征),最后针对性优化向量空间。实测效果显著:在CIRR上R@1达55.52%,刷新SOTA;细粒度子集高达81.49%;FashionIQ平均R@10达57.04%。https://www.qbitai.com/2026/04/396863.html
论⽂链接:https://arxiv.org/abs/2602.01639
2-2. 北大团队改造DeepSeek注意力,速度快四倍还不丢精度
北京大学张牧涵团队提出新型稀疏注意力机制HISA(分层索引稀疏注意力),显著提升大模型处理超长文本的效率。针对现有DeepSeek稀疏注意力(DSA)中“索引器”计算开销随文本长度平方增长(O(L²))的瓶颈,HISA采用两步分层筛选:先按块(如128字符/块)粗筛出高分区块(如前64块),再在选中块内精细挑token。
该设计将索引复杂度降至O(L²/B + L×m×B),实测在64K上下文下提速2–3.75倍,且无需重训练、不改模型结构、即插即用。在LongBench长文本理解和“大海捞针”检索测试中,HISA精度与DSA几乎完全持平(误差<0.3%),部分任务甚至小幅反超。https://www.qbitai.com/2026/04/396841.html
论文地址:https://arxiv.org/abs/2603.28458
AI人才和资本动态
3-1. 3个工程师、0融资、不开会,估值3.5亿美元的Obsidian才是真正的「小而美」
Obsidian 是一款风靡全球的本地化 Markdown 笔记工具,用户超千万,估值达3.5亿美元,却仅靠7名全职员工(含3名工程师)和一只猫运营——堪称硅谷“小而美”的商业奇迹。它诞生于2020年疫情隔离期,由两位滑铁卢校友因不满现有笔记软件而亲手打造:追求极速、离线、纯文本、数据完全自主。
与动辄融资烧钱的SaaS公司不同,Obsidian拒绝风投,100%靠用户付费(Sync同步、商业授权)实现盈利,真正“用户即老板”。团队零会议文化,靠“Ramblings”个人频道替代群聊,用自家软件管理全部工作——代码在GitHub、文档在Obsidian Vault。其强大生态来自开源插件系统:数千款社区插件(含本地AI工具如Ollama),让用户按需定制,而非被动接受。https://m.36kr.com/p/3755031628005892
3-2. 雷军马云罕见握手,千寻智能30天完成30亿元融资
具身智能迎来爆发元年——千寻智能30天内两轮融资共30亿元(2月近20亿、4月10亿),创行业纪录。更引人注目的是:雷军的顺为资本与马云参与创立的云锋基金首次在具身赛道“联手领投”,标志产业巨头共识达成——具身智能正从技术验证迈向商业兑现。
技术上,千寻Spirit v1.5模型在RoboChallenge真机评测中以50.33%成功率登顶全球第一,实现“零样本泛化”;数据上,已积累20万小时多源真实交互数据(含自研可穿戴设备采集,成本降为1/10、精度95%),2026年将突破100万小时,与美国Generalist AI的GEN-1模型路径高度一致。落地更扎实:墨子机器人已在宁德时代产线量产电池近千块,并在京东MALL咖啡场景稳定作业。https://m.163.com/dy/article/KPT8COQH0511DPVD.html


AI风险与政策管理
4-1. 用雨伞「钓」无人机?首个针对自主目标跟踪闭环系统的物理攻击
研究人员发现,一把印有特殊图案的“对抗性雨伞”就能让多款商用无人机“上当”——视觉系统误判目标正在快速远离,导致飞控自动加速追击,最终失控俯冲。这项名为FlyTrap的物理攻击无需干扰信号,仅靠视觉欺骗即可实现。
实验显示,在真实场景中,该方法对大疆Mini 4 Pro等主流无人机的诱导成功率超60%;在仿真测试中,优化后的攻击成功率更达53.6%以上。尤为关键的是,它具备强泛化能力:面对从未见过的新地点、新人物,甚至二者同时更换,成功率仍分别高达61.8%、56.6%和34.0%。这暴露出当前AI视觉跟踪系统的深层隐患——它们过度依赖物体图像大小估算距离,极易被精心设计的物理图案误导。研究警示:视觉安全已成智能设备“阿喀琉斯之踵”。https://www.163.com/dy/article/KPTMHAUL0511ABV6.html


4-2. AI邪修时刻!Meta联手MIT投毒,左脚踩右脚强行升天
Meta最新推出的SOAR方法,用一种“反直觉”策略大幅提升AI推理能力:故意让教师模型生成大量答案错误(67%错误率)、但逻辑结构正确的问题,作为学生模型的训练垫脚石。在极难的Fail@128数据集上,SOAR使模型Pass@32准确率提升至18–22%(MATH)和12–15%(HARP),较基线暴涨9.3%,远超纯硬题训练或无约束生成方案。
核心创新在于“有根奖励”——教师不因题目多漂亮得分,只因学生在真实难题上进步才获奖励,倒逼它精准诊断学生短板、动态生成“恰到好处”中间难度题(如从生活应用题逐步过渡到高等代数)。这不仅绕开了高质量数据枯竭困境,更揭示一个颠覆性认知:错误答案若承载合理推理结构,反而比“正确但平庸”的数据更能锤炼思维路径。https://www.163.com/dy/article/KPTE4K3F0511ABV6.html

论文链接:https://arxiv.org/abs/2601.18778
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





