 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库美团之后,京东也开始自研大模型了
京东发布了JoyAI-LLM Flash模型。

它激活参数小且推理速度快。
只用不到30亿的激活参数,在多项测试里跑赢了同级别的许多老大哥。
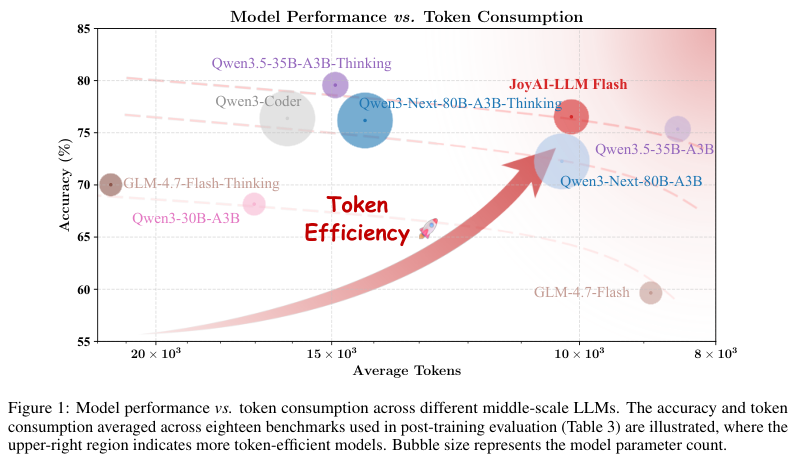
这款模型通过混合专家架构、20万亿Token的预训练、首创的FiberPO强化学习算法以及多Token预测等技术,把模型的算力成本和推理效率做到了极致。
它是怎样在保持高性能的同时做到省时省力的?
基础架构与预训练设计
JoyAI-LLM Flash是一个总参数量为489亿的混合专家(Mixture-of-Experts)模型。
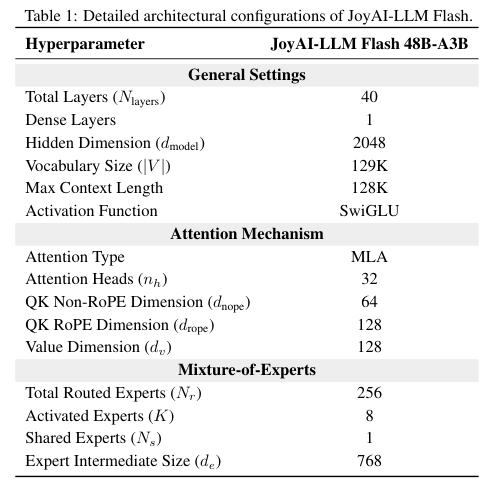
它总共有40层神经网络,第一层是常规的密集网络,剩下39层都是这种专家层。模型里一共包含256个负责具体任务的路由专家和1个兜底的共享专家。
每次处理一个Token时,它只需要激活8个相关的路由专家和那个共享专家。
虽然总参数量接近500亿,但模型每次向前计算只激活了约32.8亿个参数,如果不算词表嵌入层甚至只有27亿。这种设计让它在省电和省算力方面表现突出。
它在微观结构上使用了多头潜在注意力(Multi-head Latent Attention)机制。这是目前业内提升推理效率非常前沿的做法。
在训练阶段,工程师给它喂了多达20.7万亿个高质量Token。
为了让它吸收这些知识,团队放弃了常规的Adam优化器,改用了Muon优化器。以往用Adam训练这么大的模型时,经常会遇到损失值突然飙升的情况,工程师不得不在半夜爬起来手动调整学习率。
Muon优化器通过矩阵正交化的方式进行更新,在整个实验中表现得极其稳定,没有出现过任何明显的数值异常崩溃。
为了让模型能循序渐进地变聪明,预训练被切分成了4个阶段。
一开始是基础阶段,让模型看海量的普通文本打底。接着是代码和数学增强阶段,大幅增加这两类数据的比例来锻炼逻辑能力。随后进入中期训练,专门用极高质量的内容来提升推理水平,并且引入了多Token预测(Multi-Token Prediction)技术,让它学着一次性预测后面的好几个词。最后是长文本阶段,分两步把模型的阅读视野从6.4万个Token拉长到12.8万个Token。
基础模型训练完之后,团队做了一次摸底考试。在通识、数学、写代码和长文本等9个评测榜单上,JoyAI-LLM Flash的基础模型交出了一份优秀的答卷。
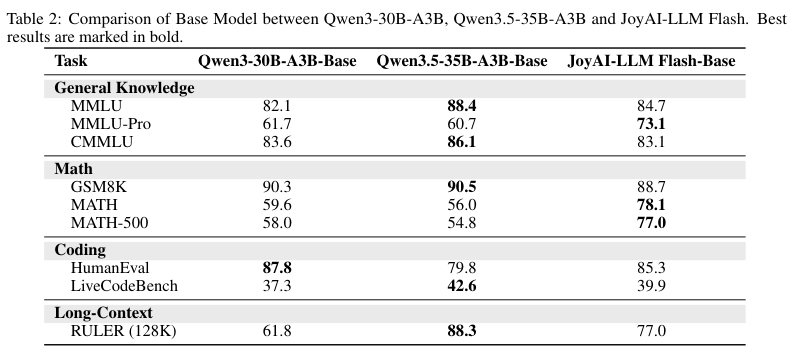
在数学和长文本处理上,它甚至比参数量相近的Qwen系列模型表现得更为强悍。
高质量数据加工
大模型能有多聪明完全取决于它吃进去的数据有多好。为了凑齐这20.7万亿个高质量Token,研发团队建立了一条非常庞大且精细的数据流水线。
在处理网页数据时,他们不仅用了基础的规则过滤掉恶意网站和乱码,还增加了一个专门查重和保护隐私的模块。
为了对付网页里那些总是去不掉的侧边栏菜单和牛皮癣广告,他们直接微调了一个小模型,专门给网页的每一行文本打分,把那些没有营养的废话全删掉。
团队从GitHub等开源社区抓取了大量的代码,按照质量打分并剔除重复项。为了让模型适应超长代码,他们把相关联的文件按照逻辑顺序拼接起来,组成6.4万到12.8万Token长度的代码块。他们还用大模型把很多晦涩的代码重写成更易读的教学格式。
面对高质量学术内容的匮乏,团队解析了上千万份PDF文档。PDF排版非常复杂,直接复制往往会把数学公式和表格弄乱。他们采用先进的文档解析工具,把理工科、医学、社会科学等领域的专业文献完美还原成了干净的文本。
除了真实数据,合成数据在后期训练里起到了挑大梁的作用。
工程师不仅让高级模型改写网页里的客观知识,还让它去解答真实世界的复杂理工科试题,并且要求它在给出最终答案前生成多步的思考过程。
针对软件工程任务,团队搭建了一个自动化验证系统,相当于给大模型建了一个虚拟沙盒。模型在这个沙盒里尝试修改代码或者写测试用例,系统会自动去编译运行。只有那些真正能跑通、能修复系统漏洞的操作记录,才会被保留下来作为训练素材。
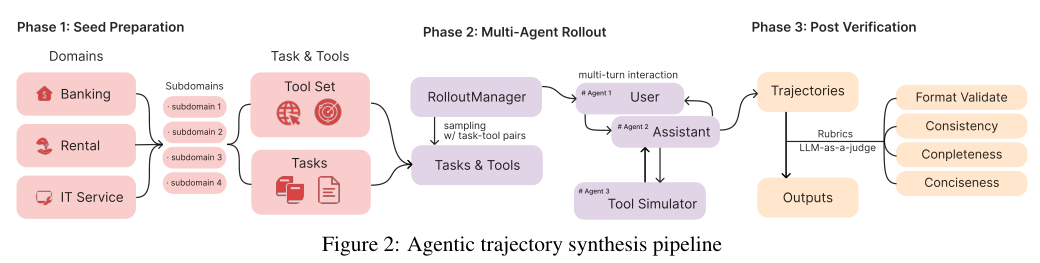
工程师还特意训练模型使用各种外部工具,比如让它学会调用Python解释器来算数学题,或者用搜索引擎去网上查最新的资料。
这种工具集成推理(Tool-Integrated Reasoning)能力,彻底解决了模型因为知识库过时而胡说八道的问题。
强化学习与对齐
在把一个只会接话的半成品变成听指令、会干活的数字员工这个阶段,研发团队投入了极大的算力。
他们将后期训练分为监督微调(Supervised Fine-Tuning)、直接偏好优化(Direct Preference Optimization)和强化学习(Reinforcement Learning)3个连续的步骤。
在监督微调阶段,团队把带思考过程的数据和直接回答的数据混合在一起给模型学习。这种动静结合的做法显著提升了模型的服从能力。
紧接着的直接偏好优化阶段专门用来治疗模型的幻觉问题,通过给模型展示什么是好答案什么是坏答案,迅速把它偏离正确轨道的胡言乱语给纠正过来。
整个后期训练最亮眼的核心,是团队首创的FiberPO强化学习算法。
以前大家训练模型常用的算法比如GRPO,存在一个很头疼的问题。当我们给模型的一长段回答打分时,传统的做法是算一个总分,然后根据总分去奖惩这段话里的每一个词。这就导致了一个现象,当模型整体偏离正确方向时,所有的词都会被同时判定为坏词。
FiberPO算法彻底解决了这个不讲理的牵连问题。
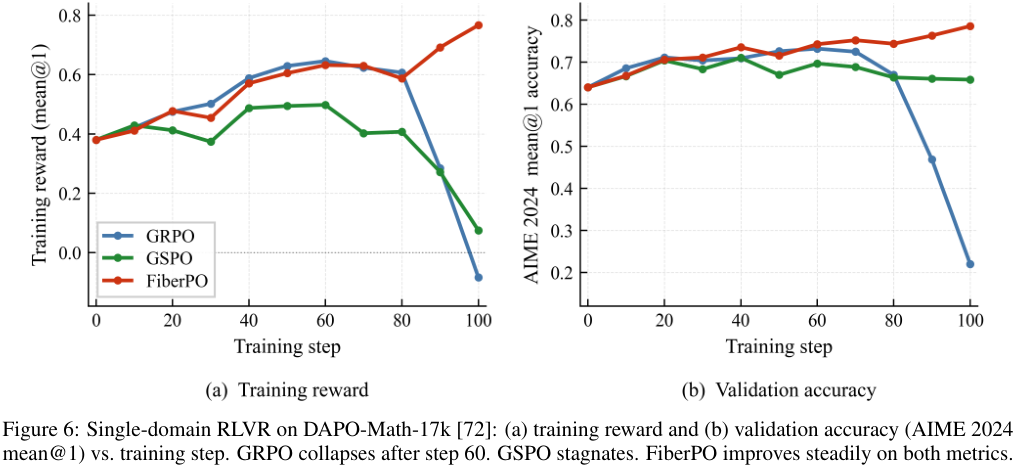
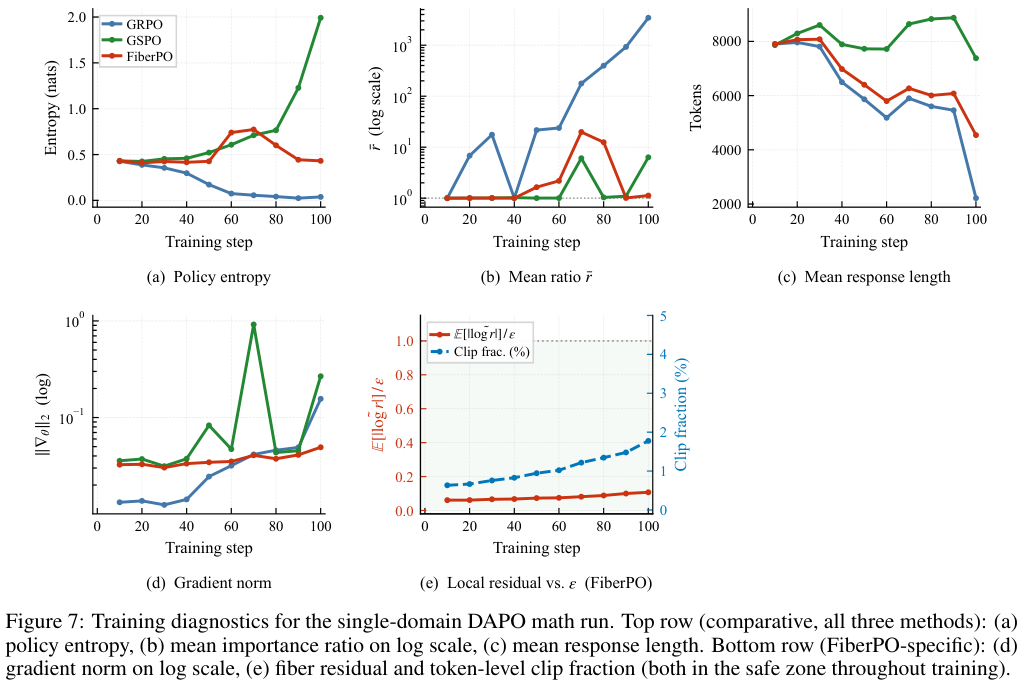
它把奖励机制拆成了宏观和微观两个层面。在宏观层面,它控制一整段回答不能偏离正常人类对话太远,在微观层面,它独立评估每一个词的贡献。有了这个微观保护罩,哪怕整体回答不太符合预期,那些本身用得非常精准的词依然能得到保护和奖励。
这种精细的打分机制带来的最直接好处,就是极高的Token利用效率。老算法一旦在宏观上崩盘,模型就分不清好词和坏词,往往会开始胡乱生成冗长且没有意义的废话。
而FiberPO算法下的模型不仅逻辑清晰,生成的回答更是精简干练,用最少的Token准确切中要害,完全不啰嗦。
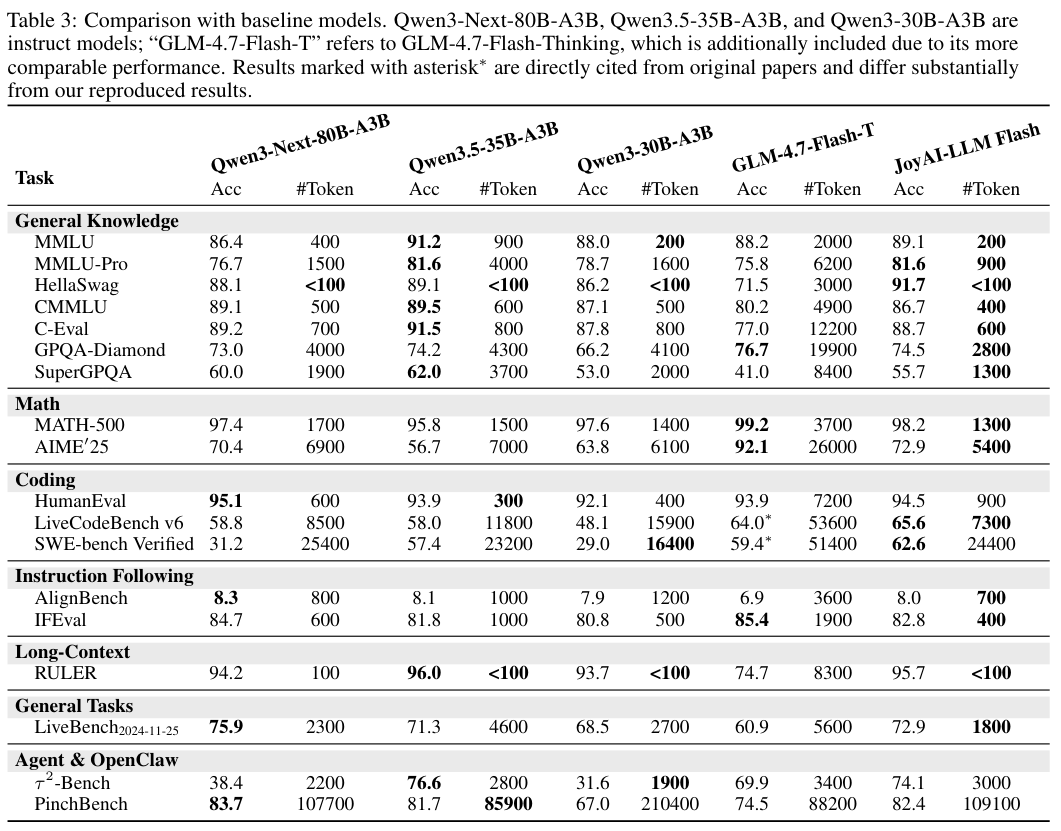
在综合测试中,使用了新算法的JoyAI-LLM Flash在各个维度上都展现出了极其出色的成绩,尤其在代码和工具使用上令人印象深刻。
推理加速与部署
让大模型变聪明只完成了一半的工作,让它能快速便宜地跑在各类服务器甚至普通电脑上,才是工业界最看重的落地能力。
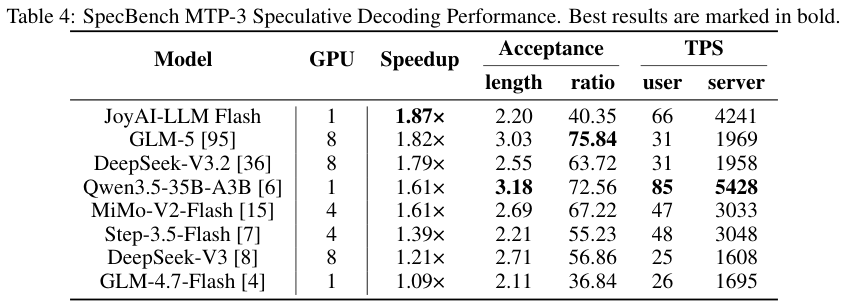
JoyAI-LLM Flash采用了多Token预测的技术。团队给模型额外加了一个轻量级的预测部件,让它在思考当前这个词的时候,把后面两三个词也顺带猜出来。
在测试中,这个小小的改动直接带来了最高1.87倍的生成速度提升。
除了提升输出效率,团队在训练早期就用上了量化感知训练(Quantization-Aware Training)技术,让模型在学习的过程中就习惯低精度运算的误差。
模型发布时配套了一系列量化版本,包括在企业级显卡上跑的FP8,以及适配普通电脑的GGUF格式。
他们甚至发明了一种叫做“双重量化”(DoubleQuant)的压缩方法,把模型切成大块再压缩两遍,做到了体积大幅缩减而智商基本不掉线。
在真机部署时,大模型经常会面临两类极端场景。一类是像客服聊天这样的短对话,用户对响应速度极其敏感。对于这种场景,团队建议把负责吸收上文的节点和负责生成回答的节点放在同一台机器上,省去网络传输的时间。
另一类是让大模型看几十页财报然后再给出几十个字的总结,这就需要跨机器去调配缓存。对于这种长文本处理,采用存储分离和集中管理的方式能大幅减少重复计算。
这些扎实的技术经验,为京东将模型真正铺进各类商业场景扫清了最后的障碍。
参考资料:
https://arxiv.org/pdf/2604.03044
https://huggingface.co/collections/jdopensource/joyai-llm-flash
END
点击图片立即报名👇️










