 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库AutoResearch遇上社会科学:S-Researcher让智能体自主设计实验、模拟被试、撰写报告
将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


Karpathy 3 月初开源 AutoResearch,630 行代码、一块 GPU、睡一觉跑 100 个实验,GitHub 星标直冲 6 万。紧接着,AutoResearchClaw 把这套「睡觉自动科研」的范式拓展到了 23 个阶段的完整论文生成流水线,连 LabClaw 也开始帮生物医学研究者自动跑实验、写记录。
一个自然的问题浮出水面:AI 自动科研在自然科学和 ML 领域已经跑起来了,社会科学呢?
社会科学的难点跟 ML 调参完全不同。你没有一个 loss 函数可以优化,被试是有主观意识的人,实验设计空间极大,而且招 100 个真人做实验就要花几个月。传统的 AutoML 式循环在这里根本不适用。
来自中国人民大学高瓴人工智能学院的团队给出了他们的方案:S-Researcher。不同于 AutoResearch 让 Agent 反复修改训练代码来压低 validation loss,S-Researcher 让 LLM Agent 同时扮演「研究助手」和「模拟被试」两个角色,覆盖社会科学研究从实验设计到报告撰写的全流程。底层是一个支持 10 万并发 Agent 的社会模拟引擎 YuLan-OneSim。在最硬核的验证中,LLM Agent 自主发现的合作机制被 120 人真人实验独立证实。

论文链接:http://arxiv.org/abs/2604.01520
GitHub:https://github.com/RUC-GSAI/YuLan-OneSim
在线平台:https://www.yulan-onesim.cn/
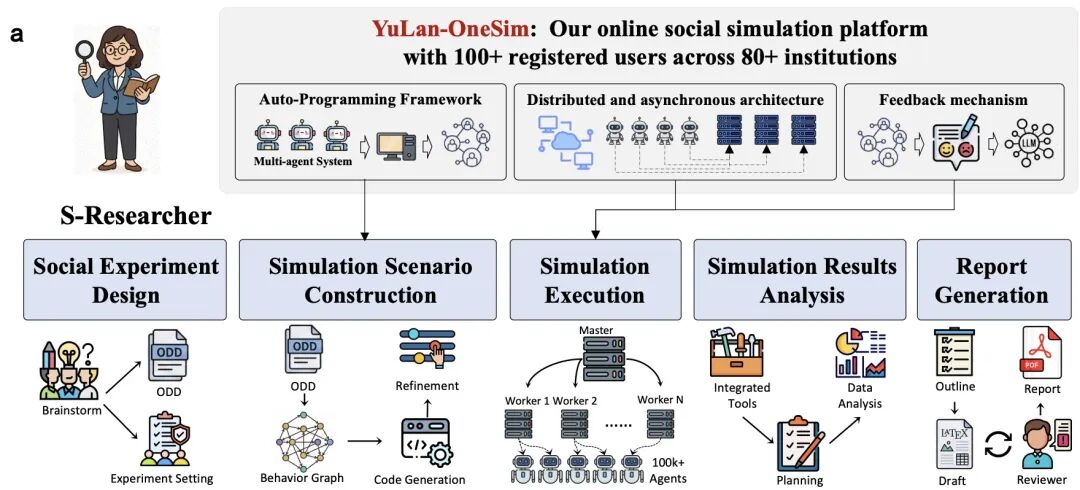
S-Researcher 整体流程:用户输入研究课题后,系统自动完成场景构建、模拟执行和报告生成,研究者可在每个环节介入。
先造一个能「跑」任何社会实验的模拟器
AutoResearch 的成功有一个前提:训练代码只有 630 行,整个系统自包含,Agent 能一次读完全部代码。社会模拟没有这个便利。你需要一个平台,能把千变万化的社会实验场景转化为可执行代码,还得支持成千上万个 Agent 同时交互。
团队开发的 YuLan-OneSim 围绕三个核心能力进行设计。
通用性:让 AI 理解五花八门的社会实验。 用户只需要用自然语言描述实验场景,系统就会按照 ODD(Overview, Design Concepts, Details)协议将其结构化,然后自动生成行为图和可执行的模拟代码。团队在 8 个社科领域的 50 个场景上测了一圈,专家给行为图打了接近满分的 5.0,生成代码拿了 4.2 分。考虑到这些代码几分钟就能出来,而手写可能要好几个小时,这个分数相当能打。
消融实验揭示了一个重要结论:行为图是整个流程的灵魂。去掉它,代码质量直接掉了 35.8%,比去掉任何其他模块的影响都大。给 Agent 一个结构化的中间表示,比让它直接从自然语言生成代码要靠谱得多。
可扩展性:让几万、十几万个 Agent 同时跑。YuLan-OneSim 用了一套事件驱动的异步架构,配合 Master-Worker 分布式设计。实测下来,从 1k 到 100k 个 Agent 都能平滑扩展。10 万 Agent 跑一轮大约需要 3538 秒;在万级规模时,分布式部署比单机快了 3-4 倍。
可靠性:让通用 LLM 输出可信的模拟行为。 直接拿通用 LLM 来模拟社会行为,效果确实不稳定。为此团队设计了 VR²T 反馈框架(Verifier-Reasoner-Refiner-Tuner),先让验证者打分,推理者分析错因,修复者纠正输出,最后用这些数据微调骨干模型。在 Qwen2.5-1.5B 上用 DPO 迭代 4 轮后,可靠性提升了 27.4%。这个思路和 AutoResearch 的 ratchet 机制异曲同工:跑一轮,评估,保留改进,丢弃退化,反复迭代。
目前 YuLan-OneSim 已经作为在线平台运行(yulan-onesim.cn),吸引了 80 多家机构的 100 多位注册用户。
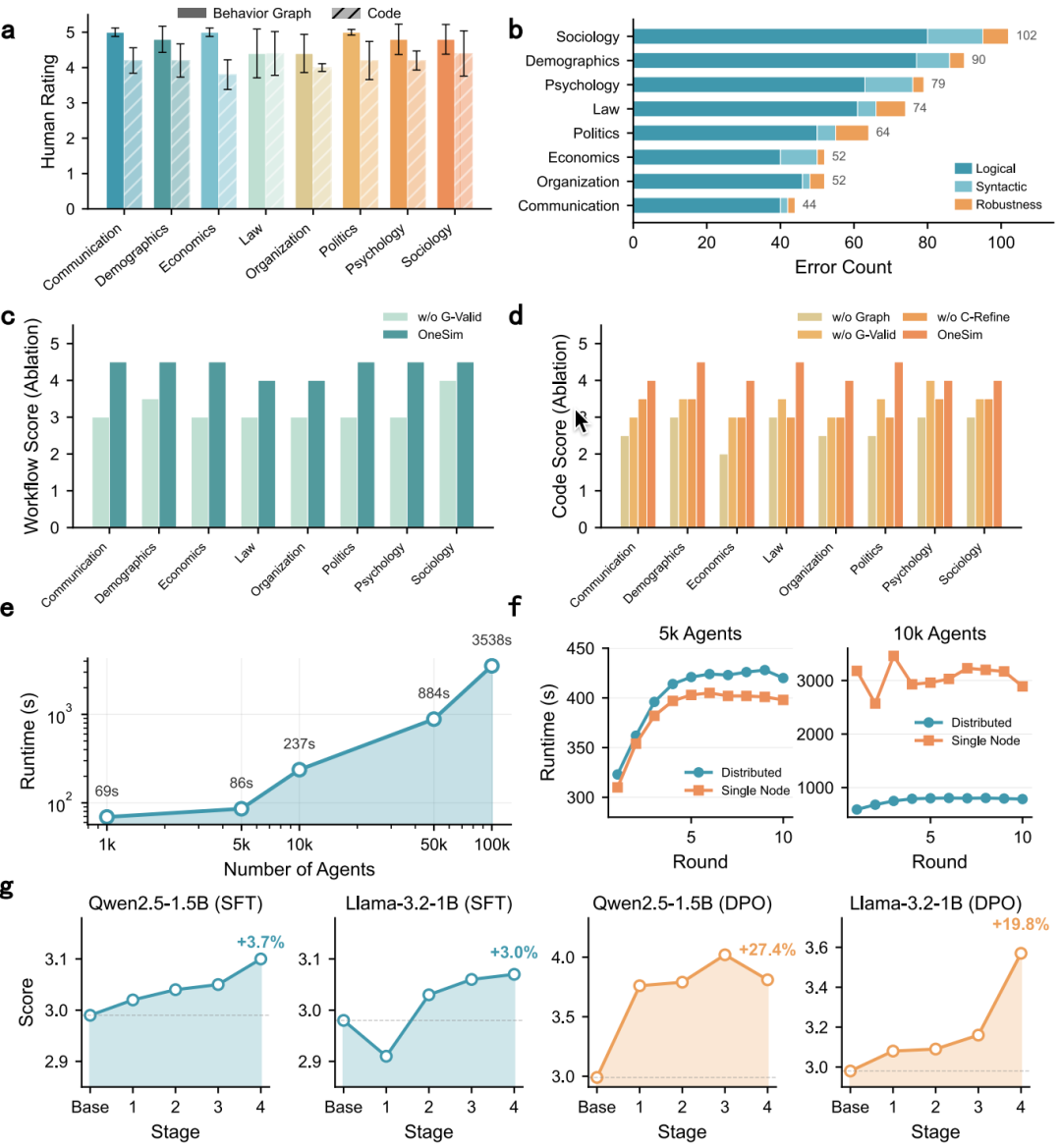
YuLan-OneSim 平台能力验证:(a)专家评分,(b)错误类型分布,(e)规模扩展性测试,(g)反馈微调效果。
S-Researcher:一个研究问题进去,一份研究报告出来
S-Researcher 把研究工作流组织成三种经典推理模式:归纳(从数据中发现规律)、演绎(检验竞争假说)、溯因(追溯因果机制)。整个 pipeline 包含实验设计、模拟执行、结果分析和报告生成四个模块。
但与全自动路线不同,S-Researcher 从设计之初就把人机协作作为核心原则。研究者可以在每个阶段介入:修改系统自动生成的实验设计、上传自定义的 Agent 画像数据、调整模拟参数,甚至只使用其中某个模块 —— 比如你手上已有实验数据,可以跳过模拟阶段,直接用结果分析和报告生成模块。
团队用三个案例验证了这套系统。
归纳:给定研究问题,AI 自己复现了经典结论
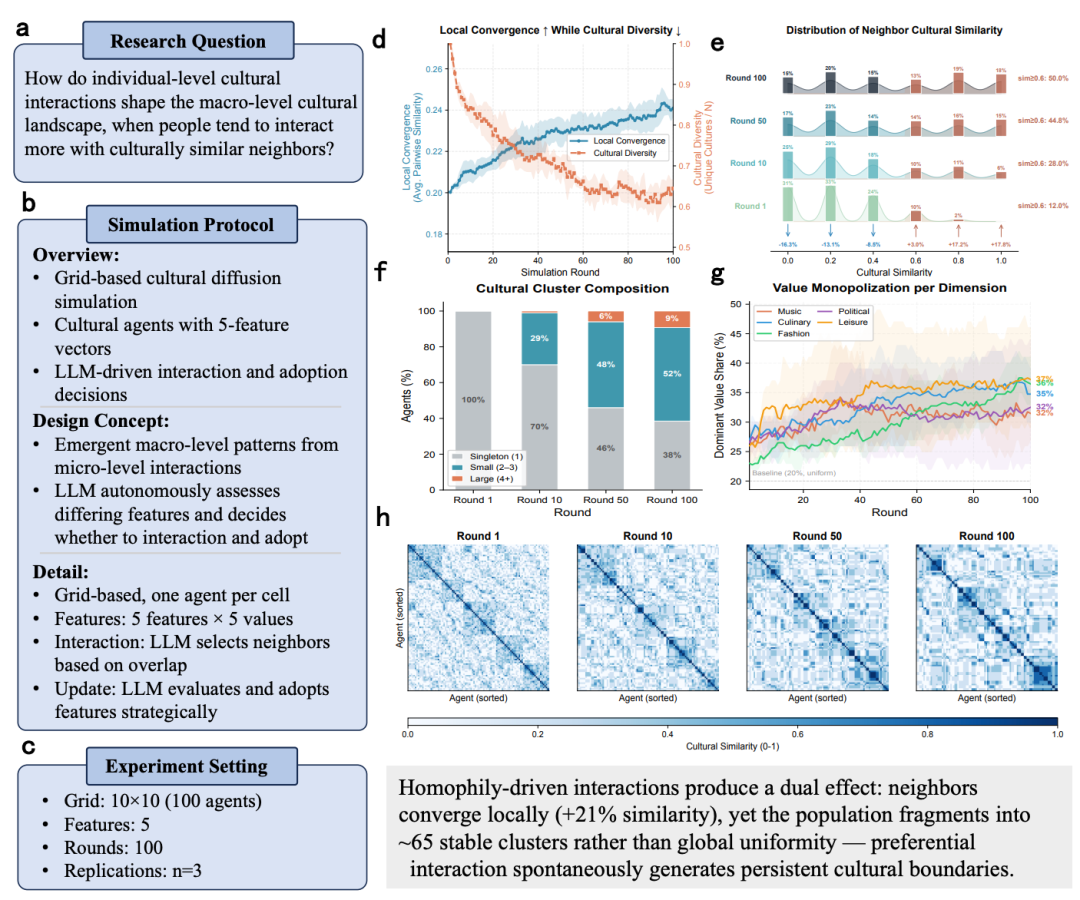
研究问题很简单:当人们更愿意和文化相似的邻居互动时,整个社会的文化格局会怎样演变?
S-Researcher 自主设计了完整实验:在 10×10 网格上放 100 个 LLM Agent,每人 5 个文化特征维度(音乐、饮食、时尚、政治、休闲),跑 100 轮。
系统发现了一个有趣的悖论:邻居之间越来越像(平均相似度 + 21%),但全局并没有走向统一,而是稳定在大约 65 个文化「小岛」上 —— 形成「组内趋同、组间分化」模式。这恰好是 Axelrod 文化传播模型的核心预测,而动态完全来自 LLMAgent 的自主交互涌现。
演绎:三个假说同时 PK,5525 个学生 Agent 模拟中国课堂
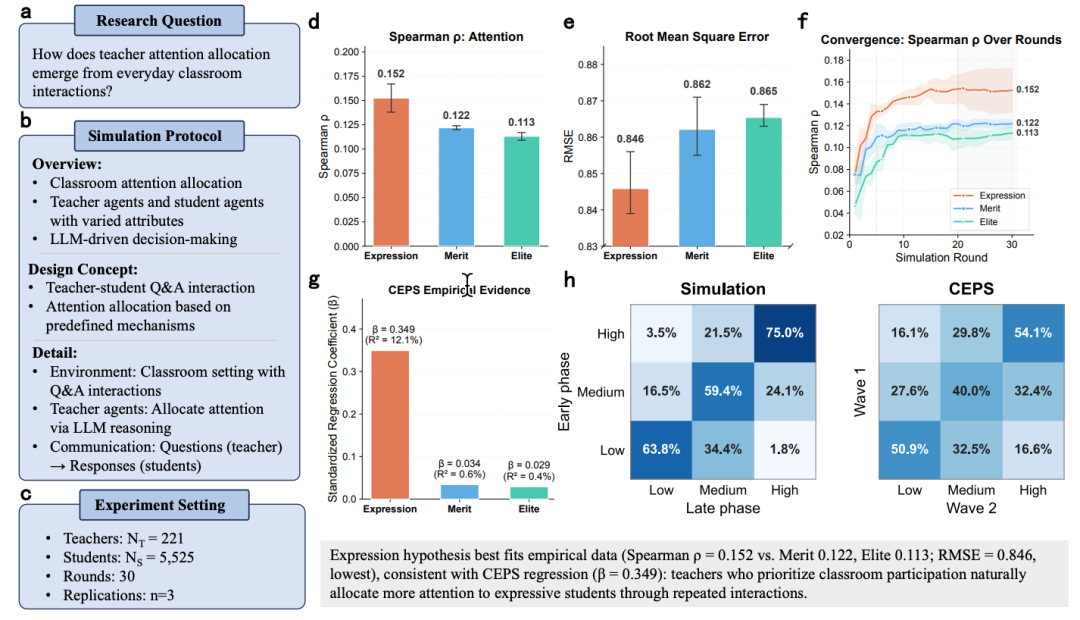
第二个案例瞄准教育公平领域的核心问题:到底是什么决定了老师把注意力分给谁?
S-Researcher 自动提出三个竞争假说:表达假说(课堂发言活跃度主导)、成绩假说(学习成绩主导)、精英假说(家庭背景主导),然后启动三组平行模拟。
规模:221 个模拟课堂、5525 个学生 Agent,每个学生的画像直接来自中国教育追踪调查(CEPS)的真实数据。
结果:表达假说完胜。与 CEPS 实际数据的 Spearman 相关系数,表达假说(ρ = 0.152)显著高于成绩假说(0.122)和精英假说(0.113)。独立验证中,CEPS 回归分析显示沟通能力对教师注意力的解释力(β = 0.349,R² = 12.1%)约是学业成绩的 20 倍(β = 0.034),与模拟结论完全一致。
更重要的是,模拟给出了回归分析给不了的东西:表达能力强的学生是如何一轮轮积累起注意力优势的 —— 这种过程层面的解释力,正是模拟研究相比统计分析的独特价值。
溯因:AI 发现新机制,120 人真人实验独立验证
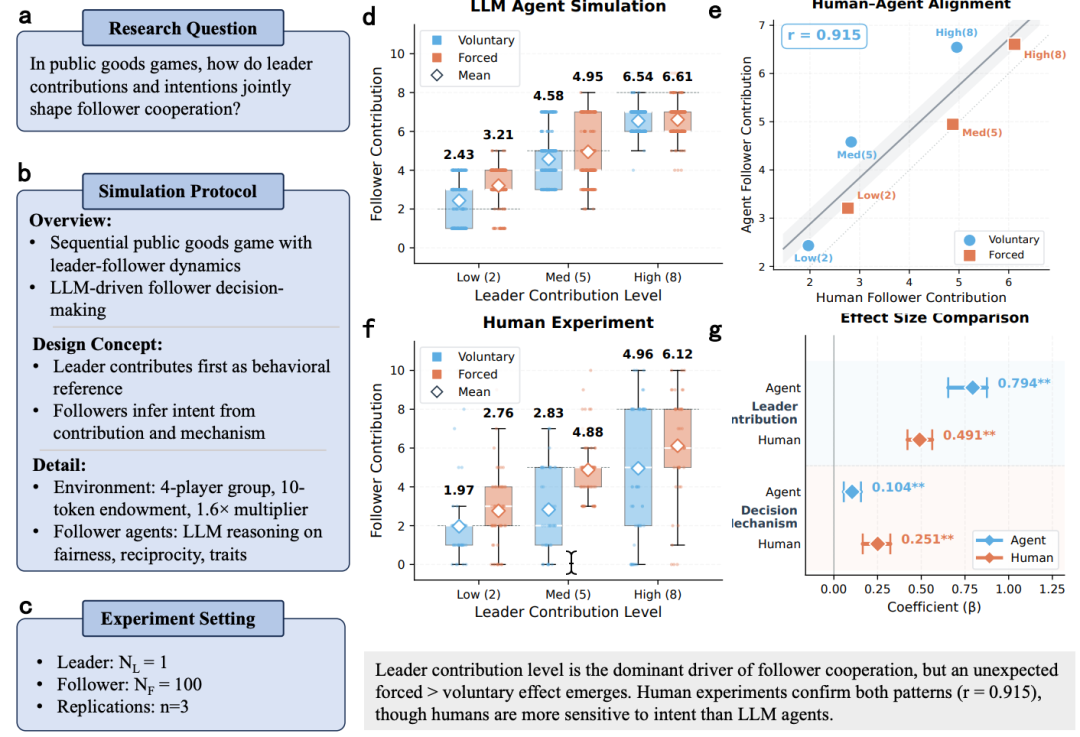
这是整篇论文最有看点的部分。
研究问题:在公共品博弈中,领导者的贡献金额和背后的意图(自愿还是被迫),如何影响追随者的合作意愿?
S-Researcher 自动设计了一个 2×3 被试间实验:决策机制(自愿 / 强制)× 贡献水平(低 2 / 中 5 / 高 8 token),每个条件 100 个 Agent 追随者。
模拟揭示了两个发现。第一,追随者的合作主要被贡献金额「锚定」(β = 0.794),这不意外。第二,出人意料的是,强制条件下追随者反而贡献更多(β = 0.104)。Agent 似乎对自愿做出低贡献的领导者进行了「意图惩罚」:你本来可以多给但选择不给,那我也减少合作。
为了验证,团队同步开展了平行人类实验(N = 120,3 轮),实验设置完全相同。结果令人振奋:人类同样表现出「强制 > 自愿」的模式,6 个条件下人机均值的 Pearson 相关系数达到 r = 0.915。不过差异也存在:人类对意图的敏感度明显更高(β_human = 0.251 vs. β_agent = 0.104),LLM Agent 则更依赖金额本身。
AI 自动科研的社会科学路线
当研究对象是「人」的时候,没有简洁的目标函数可以优化。文化怎么传播、老师怎么分配注意力、人们为什么合作 —— 这些问题需要的是理论发现和机制解释,而非指标优化。S-Researcher 的做法是让 LLM Agent 本身成为研究对象,用模拟来替代或预筛选昂贵的真人实验。
当然,这条路也有边界。LLM Agent 的行为异质性比真人低,对意图等高阶线索的敏感度不足,仍然离不开真人被试。
正因如此,S-Researcher 从一开始就把人机协作作为核心设计。AI 负责快速探索方案空间,人负责在关键节点做判断和干预。一旦涉及理论判断、伦理审查、领域知识这些「软」要素,人的参与不是可选项,而是必选项 —— 而这,恰恰揭示了当下 AI 科研工具必须正视的核心边界。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。





