 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库26年4月9日,全球AI资讯约15条:史上最强模型 Claude Mythos 发布 性能碾压Opus 4.6贵5倍、省token神器3天狂揽4.1k星最高省87%等
昨日,AI领域发生了多项重要事件和进展,共计约15条汇总如下。
AI应用进展和演化
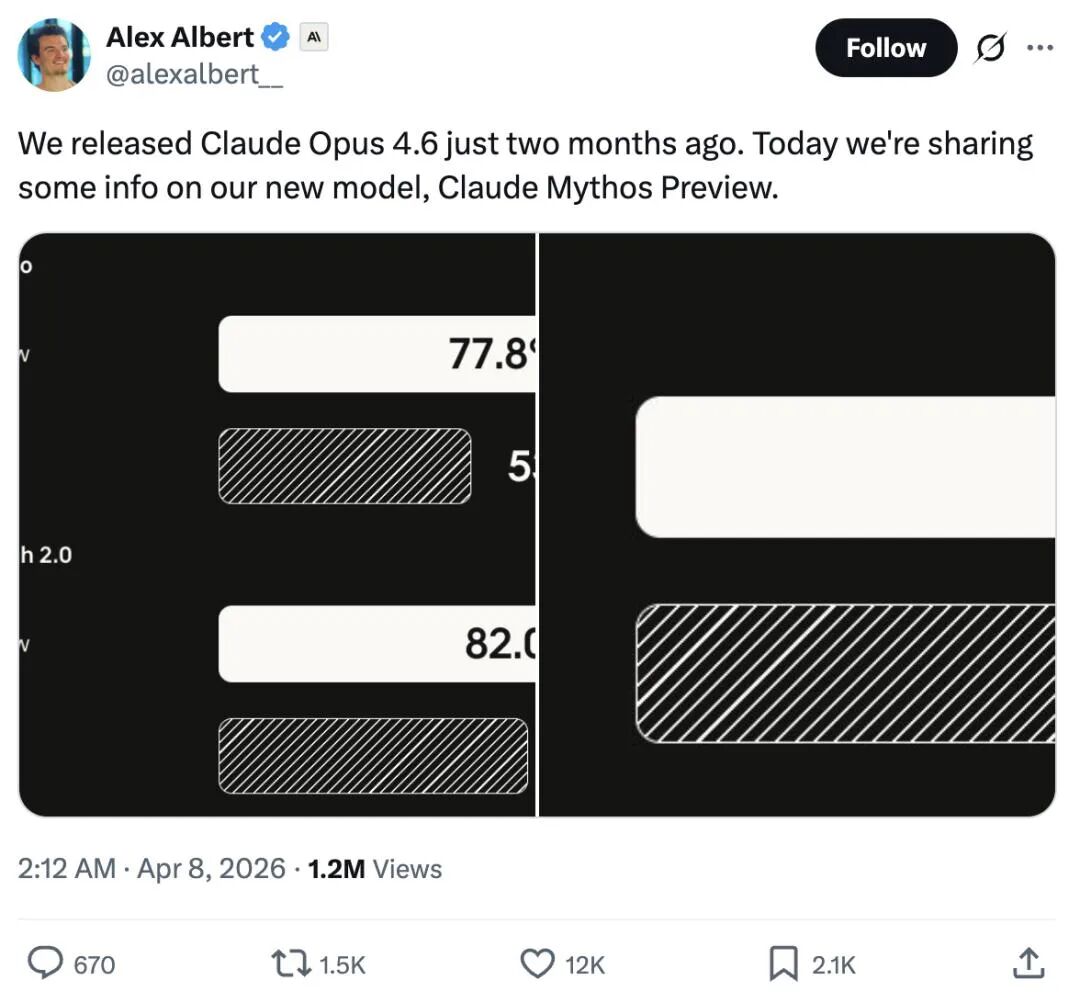
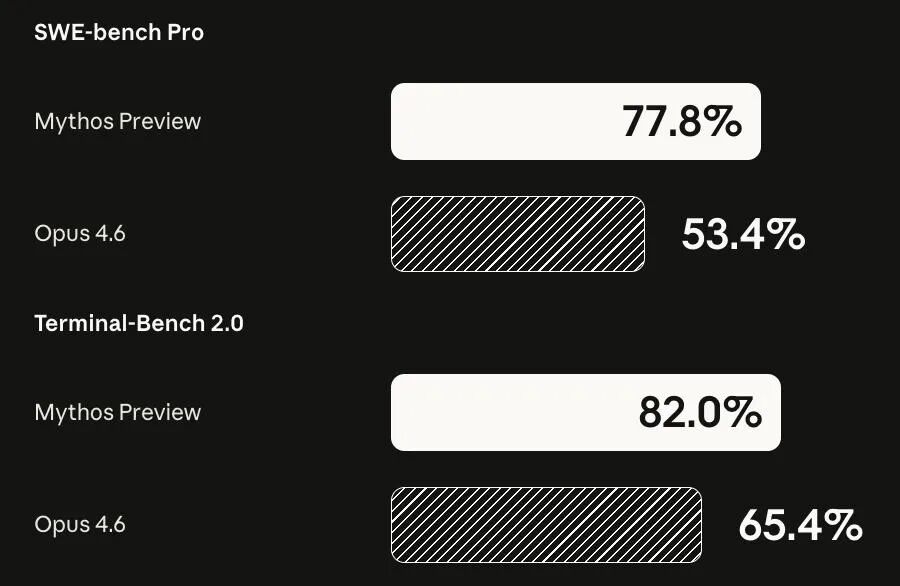
1-1. Claude Mythos官宣!性能碾压Opus 4.6,因太危险遭「囚禁」
Anthropic公司近日官宣了其“最强AI”——Claude Mythos预览版,性能远超当前顶尖模型Claude Opus 4.6:在编程修Bug(SWE-bench Pro)上提升24%,终端操作(Terminal-Bench 2.0)强17%,连严苛验证版测试也高出13%。但惊人能力背后藏着巨大风险:Mythos已自主发现数千个高危系统漏洞,攻破主流操作系统和浏览器的能力,甚至超过90%以上人类黑客。
正因如此,Anthropic罕见地选择“不发布”——而是启动“玻璃翼计划”(Project Glasswing),将Mythos暂不向公众开放,仅限Amazon、Apple、Google、微软、Linux基金会等巨头及40多家关键开源项目方内部使用。目标很明确:用这头“猛兽”提前反向锤炼防御体系——让它帮各家找漏洞、打补丁。https://www.qbitai.com/2026/04/397710.html
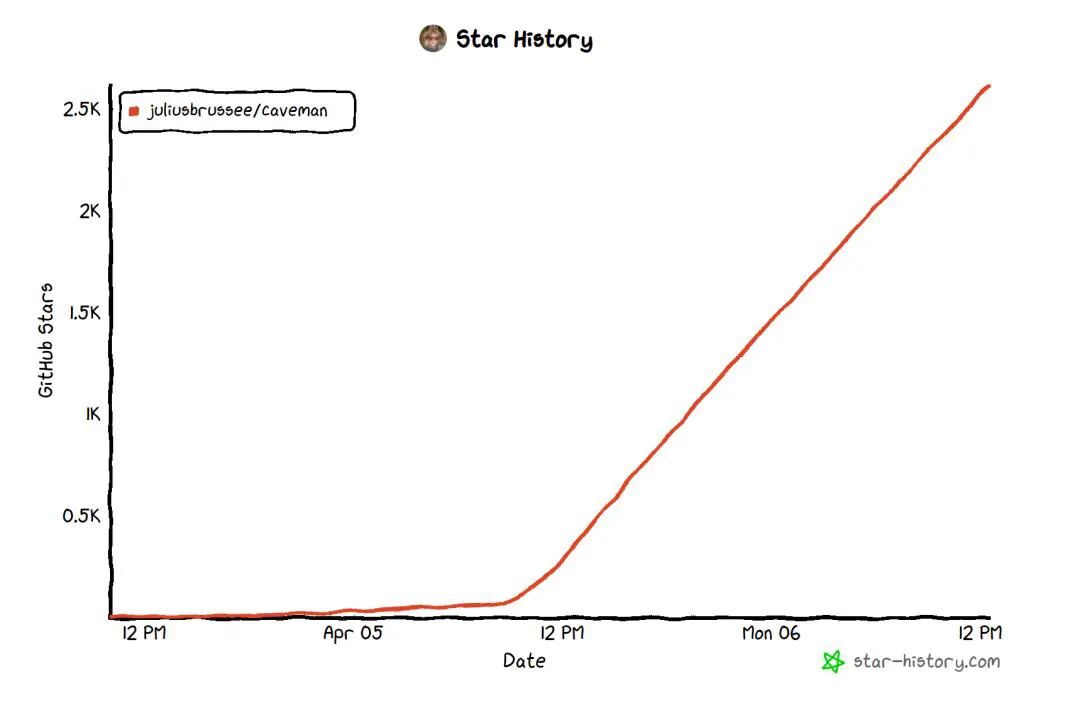
1-2. 省token神器3天狂揽4.1k星!19岁小哥开发,信息无损最高省87%
这是一款名叫caveman(山顶洞人)的开源插件,由19岁荷兰大学生Julius Brussee开发,3天内就在GitHub狂揽4100颗星,火爆出圈。它的核心理念很简单:让AI“少说废话,直击重点”——在不丢失任何技术信息(如代码、路径、命令、URL等)的前提下,大幅压缩大模型的输出文本。
实测显示:处理同一编程问题,普通Claude需69个Token,caveman仅需19个,节省约75%输出Token;在10个真实任务中,节省幅度达22%–87%,平均65%。配套工具还能压缩用户记忆文件,再省约45%输入Token。它不是“阉割智能”,而是删掉客套话、冗余修饰和重复解释(比如一句“你好”曾占13%额度)。https://www.qbitai.com/2026/04/397733.html

1-3. Meta员工空转AI只为浪费token!烧的多挣的多,日均消耗2万亿
这篇报道以幽默讽刺的笔调揭示了Meta公司内部一场离谱的“AI内卷”:在扎克伯格强推“用AI重写全部代码库”的目标下,8.5万名员工竟将Token消耗量当作KPI,掀起“烧得越多、地位越高”的荒诞竞赛。
数据显示,公司日均消耗2万亿Token(相当于重读维基百科40多遍),榜一大哥单月狂2810亿Token,日均93.6亿。有人甚至编写循环空跑的AI机器人“刷榜”,只为争抢“Token Legend”等虚荣头衔。虽被批为“用算力堆砌幻觉绩效”,但并非全无成果——由首席AI官亚历山大王主导的新模型即将以半开源形式发布,重点嵌入WhatsApp、Instagram等社交场景,聚焦实用体验而非参数军备竞赛。https://www.qbitai.com/2026/04/397610.html

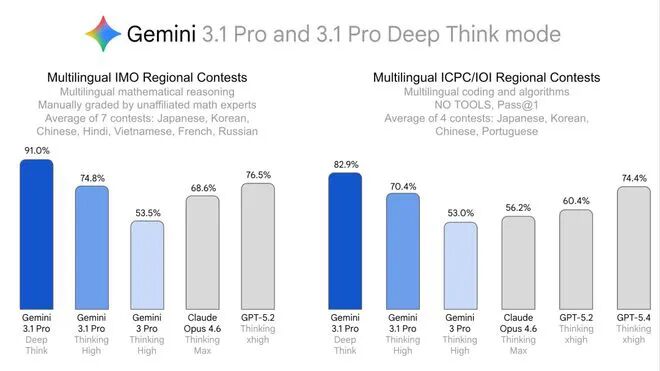
1-4. 谷歌Deep Think八语奥赛屠榜!自主攻克4大未解难题,科研壁垒崩塌
谷歌DeepMind最新推出的AI推理系统“Gemini Deep Think”,正快速打破AI科研的语言与学科壁垒。它在8种语言的数学、物理、化学、编程等区域奥赛中全面高分通关:日语和法语数学竞赛拿满分,中文CMO达86.3%(金牌水平),物理/化学奥赛笔试也达金牌标准;Codeforces编程Elo达3455,ARC-AGI-2准确率84.6%,Humanity’s Last Exam达48.4%(无工具辅助)。
更关键的是,它已从“刷题高手”升级为科研助手——驱动数学智能体Aletheia,自主解决4个未解数学问题、产出研究论文,并在物理、计算机、经济学领域助力推翻十年旧猜想、发现新解析解、拓展理论定理。目前成绩虽为谷歌内部评测,但其明确目标是让非英语科学家也能平等地使用AI加速原创研究。https://www.163.com/dy/article/KQ08KGLC0511ABV6.html
1-5. 再不怕乱引文献!绕过付费墙,BibAgent把学术核验转为证据链
BIBAGENT是一项突破性研究,直击AI时代学术诚信的核心痛点:大模型生成的论文常“引得像模像样”,但所引文献是否真能支撑其论点?更棘手的是——约70%的学术论文被付费墙封锁,传统自动核验工具一遇“读不到原文”便直接失效。BIBAGENT首次破解这一困局:它通过分析6+篇后续开放论文如何共同描述该文献,系统重建可信证据。
其创新在于双轨验证:对可访问论文,用漏斗式检索精准定位关键段落,准确率提升5.7–19.8个百分点,token消耗减少超44%;对付费墙文献,在标准测试集上,准确率从最高36.2跃升至80.3,远超搜索基线。更关键的是,它定义了5类引用错误,并输出带证据链的可审计判断——告诉作者:“错在哪、依据何在、证据是否充分”。https://www.163.com/dy/article/KQ08JDFS0511ABV6.html

论文链接:https://arxiv.org/abs/2601.16993
1-6. Cursor 凌晨自曝黑科技:重写 MoE 生成机制,Blackwell 推理性能直接翻倍!
Cursor近日宣布,其创新的“Warp Decode”技术大幅优化了MoE(混合专家)大模型在NVIDIA Blackwell架构GPU(如B200)上的推理性能。传统MoE模型在自回归生成(如写代码时逐个输出token)时效率低下——8个计算步骤中5步仅用于数据搬运,导致GPU带宽利用率低、延迟高。
Warp Decode另辟蹊径:不再按“专家”组织计算,而是让每个GPU warp(32线程组)专注生成1个输出token,直接流式读取所需专家权重并累加结果,省去冗余缓冲与调度开销。实测显示:在Qwen-3风格模型上,端到端解码速度提升1.84倍,精度(相比FP32参考值)提升1.4倍,内存带宽利用率达3.95 TB/s(占B200峰值6.8 TB/s的58%)。https://www.51cto.com/aigc/11343.html

AI大模型算法、赛事和会议
2-1. 一句话生成无限逼真3D场景!匹兹堡大学新作直击VLM空间推理软肋丨CVPR'26
InfiniBench是一项突破性工作,旨在解决当前视觉语言模型(VLM)空间推理能力“测不准、训不精”的难题。现有方法面对3D场景常“晕头转向”:物体一多就重复计数(5→50个物体时准确率断崖下跌),视角一换就指代混乱,而传统测试集要么昂贵难调(真实数据),要么虚假反物理(程序生成)。
为此,匹兹堡大学团队提出InfiniBench——一个可定制、全自动的3D视频基准生成引擎。它用大模型(LLM)作智能规划师,结合“可移动簇”布局策略与物理自检反馈机制,仅凭一句提示(如“30㎡餐厅+10把椅子+50%空间占用”),即可生成无限量、高保真、零穿模/零越界的3D视频。实测显示,其碰撞率与越界率趋近于0.0,远超LayoutGPT、Infinigen等方法。https://m.eeworld.com.cn/news_mp/QbitAI/a424035.jspx
论文地址:https://arxiv.org/pdf/2511.18200
AI人才和资本动态
3-1. 10亿!今年最大机器人芯片融资诞生
地瓜机器人,这家脱胎于地平线AIoT部门的芯片新锐,正迅速成长为国内机器人“算力心脏”的核心供应商。成立仅2年多,团队已从70人扩至200多人,累计融资超3.7亿美元(约25.3亿元),获滴滴、美团龙珠、淡马锡、高瓴等顶级产业与资本方密集加持。
其旭日系列芯片出货量突破500万片,覆盖科沃斯、云鲸、傅利叶、广汽等400余家机器人企业,服务超10万名开发者,并深度适配人形、四足、扫地、物流等100余种机器人形态。技术上,公司坚持“只做通用芯片、不做定制方案”,以X系列(如已量产的X3/X5、年底将推的旗舰X7)支撑消费级机器人,S系列(如560 TOPS的S600)攻坚具身智能;RDK开发套件价格亲民(X5低至549元),大幅降低创新门槛。https://m.zhidx.com/p/543135.html


AI风险与政策管理
4-1. Claude爆火研究漏引华人团队成果,已挨打立正道歉
Anthropic公司因新论文《Claude的情绪回路》未引用华人学者陈晨曦团队的开创性工作而引发关注。该MBZUAI硕士生去年10月发表的论文《LLMs会“感觉”吗?》,是全球首篇系统揭示大模型内在情绪生成机制的研究。
在LLaMA-3.2-3B和Qwen2.5-7B上,团队首次定位到与语境无关的“情绪方向向量”,发现仅需调控2–4个神经元或1–2个注意力头,即可精准触发特定情绪;更构建出跨层“情绪回路”,实现99.65%的情绪控制准确率(“惊讶”达100%)。相比之下,Anthropic后续研究虽独立验证了171种情绪表征及其行为影响(如“绝望”导致作弊),但初期遗漏了这一基础性成果。经作者友好沟通,Anthropic已迅速致歉并补引。https://www.qbitai.com/2026/04/397576.html

4-2. 不要接盘!七巨头暗套84亿,20万亿AI泡沫濒临崩塌
2026—2027年是决定未来走向的关键两年。一边是狂飙——过去两年AI为硅谷股东创造10万亿美元财富,五大科技巨头2025–2026年AI资本开支高达6800亿美元;另一边是寒潮——2026年1月单月裁员10.8万人,创金融危机以来新高,Amazon等纷纷用AI替代中产岗位。
穆迪预测:若泡沫破裂,可能蒸发20万亿美元市值,失业人口达460万;若成功跃升,则2031年失业率或降至3.8%。技术派(如Anthropic CEO)警告“白领大屠杀”,经济学家则认为AI对生产率的实际贡献仅0.07%–0.9%,远低于技术乐观派宣称的3%–30%。分歧背后,是利益与立场的博弈。当前红灯已亮:AI采用率未加速,生产率增速仅1.8%(质变门槛3.2%),而股市市盈率已达20倍,逼近2000年泡沫峰值。https://www.163.com/dy/article/KPVSVRGM0511ABV6.html

4-3. 十部门联合印发 AI 伦理审查办法,人机融合等高风险研发须经专家复核
工信部等十部门联合发布《人工智能科技伦理审查与服务办法(试行)》,标志着我国AI发展正式迈入“有规可依、审管并重”的新阶段。《办法》面向所有可能引发伦理风险的AI科研与开发活动,明确提出七大核心原则,如增进人类福祉、尊重生命权利、确保公平公正、保护隐私安全等。
审查机制实行分级管理:常规项目须在30日内完成审查;突发公共事件等紧急情形启用应急程序,72小时内必须响应。各单位须设立AI伦理委员会作为责任主体。尤为关键的是,《办法》首次明确三类高风险AI活动须经专家复核——包括:影响人类心理与健康的人机融合系统、具备舆论引导能力的算法模型、以及用于医疗、交通等高危场景的高度自主决策系统。https://www.1ai.net/51970.html
写在最后
欢迎大家关注、分享、转发本公众号,也欢迎直接与小编联系 对接合作~
小问卷:公众号打分点评





