 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库具身智能桌面操作场景统一评测:基准能力、中文支持与综合评分|EmbodiedCLUE


在上一阶段快报中,RoboCasa-GR1-Tabletop 场景下六个公开模型的统一接入、统一评测配置与首轮标准化结果已经完成,基准环境、任务设置与主要指标体系也已初步建立。在此基础上,EmbodiedCLUE-VLA 具身智能评测基准进一步从“评测链路打通”推进到“结果分析与能力比较”阶段,重点围绕六个模型在统一 benchmark 下的整体表现、任务分布差异、中文支持情况以及综合评分方式展开系统整理。
SuperCLUE,公众号:CLUE中文语言理解测评基准具身智能(大脑)桌面操作场景模型统一评测进展快报 | EmbodiedCLUE
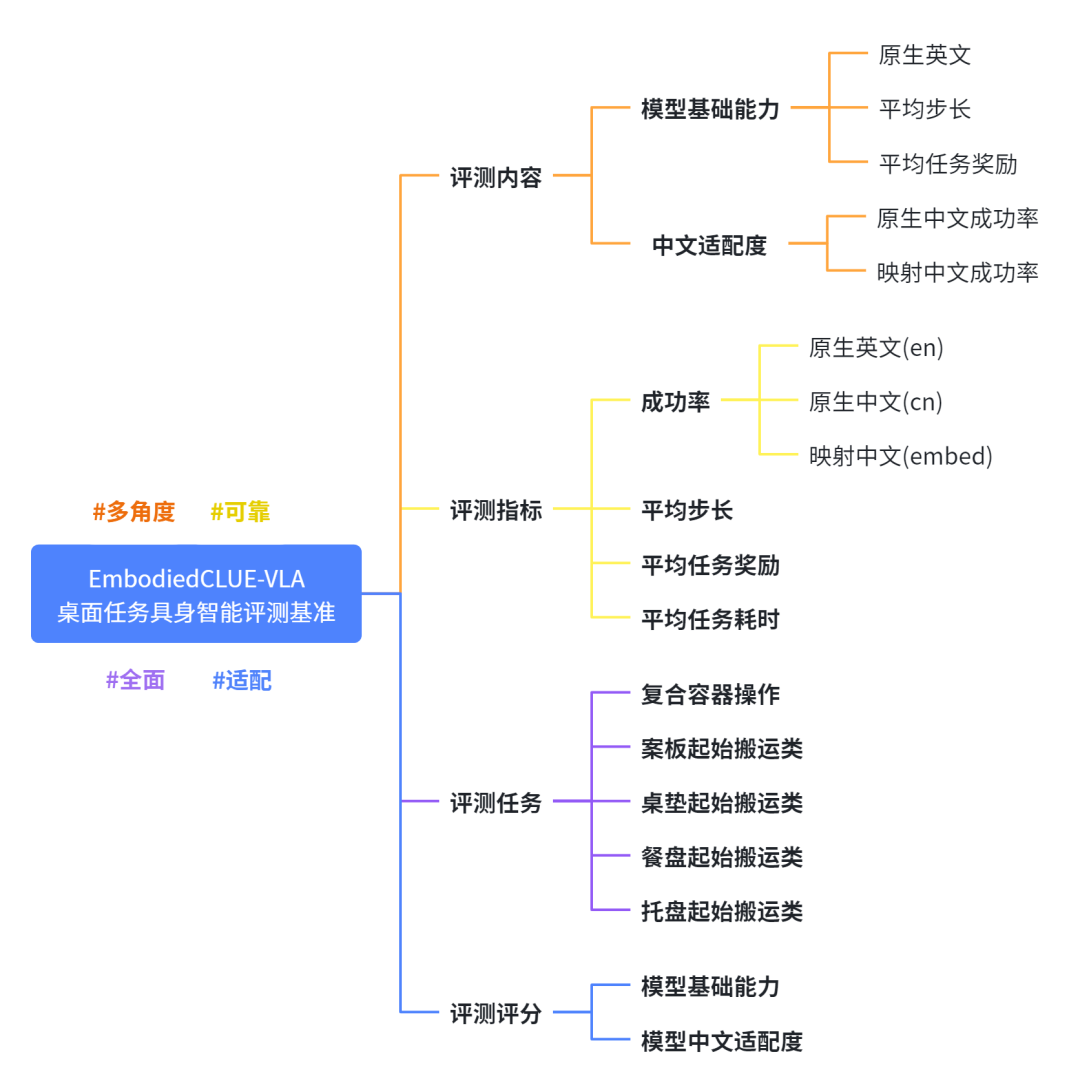
# 评测概览
1.模型评测总表
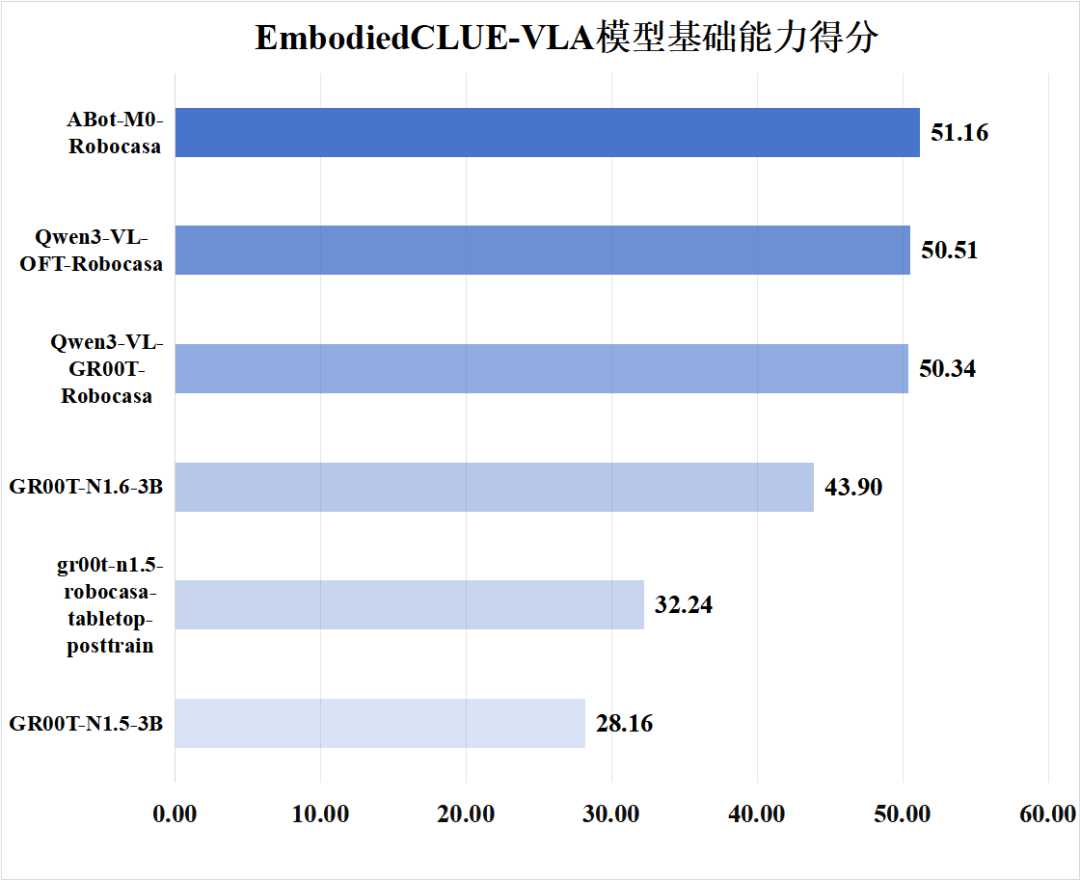
2.基础能力评分
4.象限图

一、评测内容


成功率,记为 (p ),包含原生英文成功率(p_en)、原生中文成功率(p_cn)、转换中文成功率(p_embed):

平均步长,记为(l ),范围为:
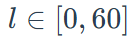
平均任务奖励,记为 (r ),范围为:
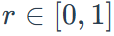
平均耗时,单个episode在评测环境下的平均运行时间,单位为(s)。
从总体上看,上述四类指标分别对应四个维度:完成性、效率、过程质量与运行开销。其中,成功率与平均步长共同构成对“任务完成能力”的核心描述;平均任务奖励用于补充过程质量信息;平均耗时则用于反映评测成本。
三、评测任务
1.评测总表
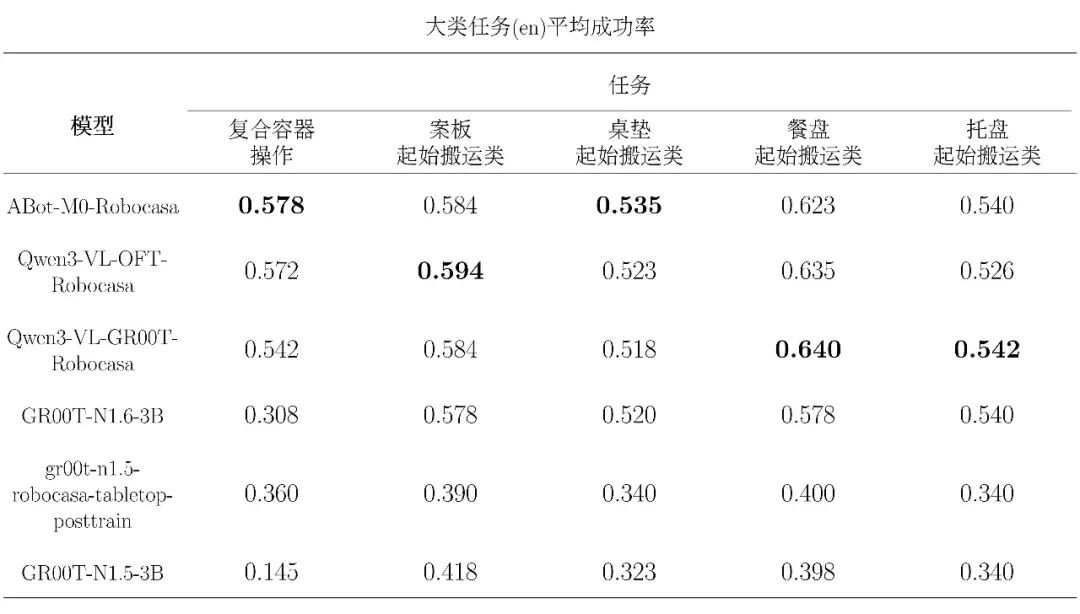
下附原生中文 cn 大类任务模型评测表:
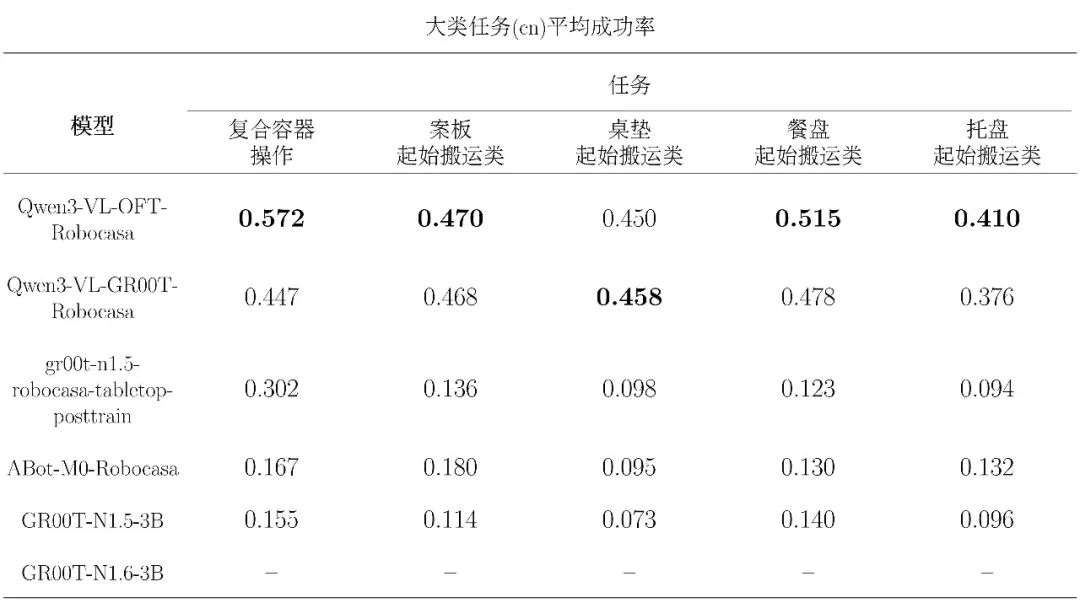
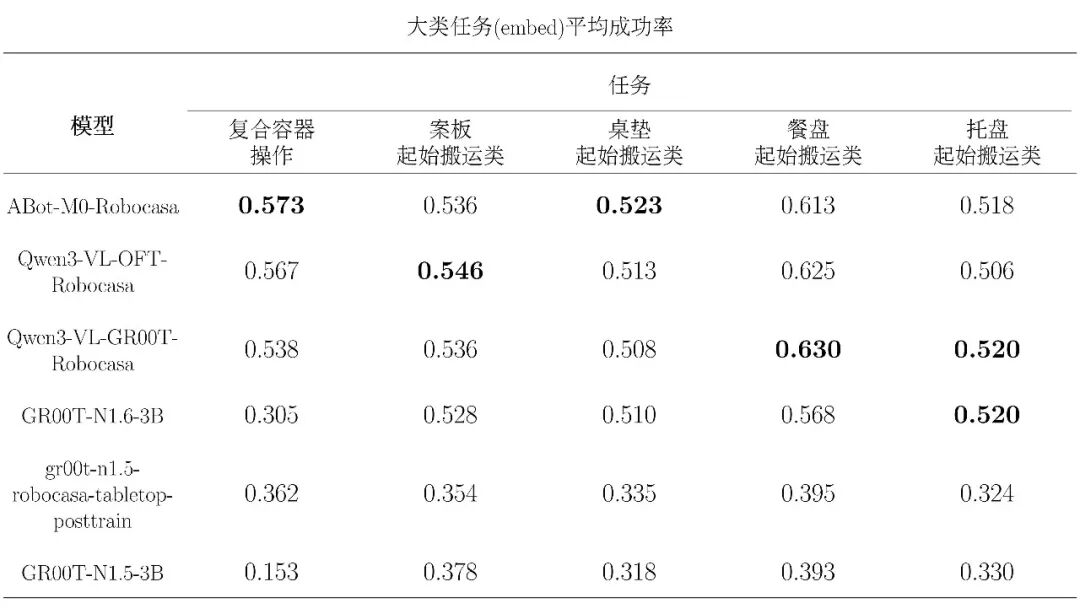
下附转换中文 embed 大类任务平均评测表:





四、评测评分
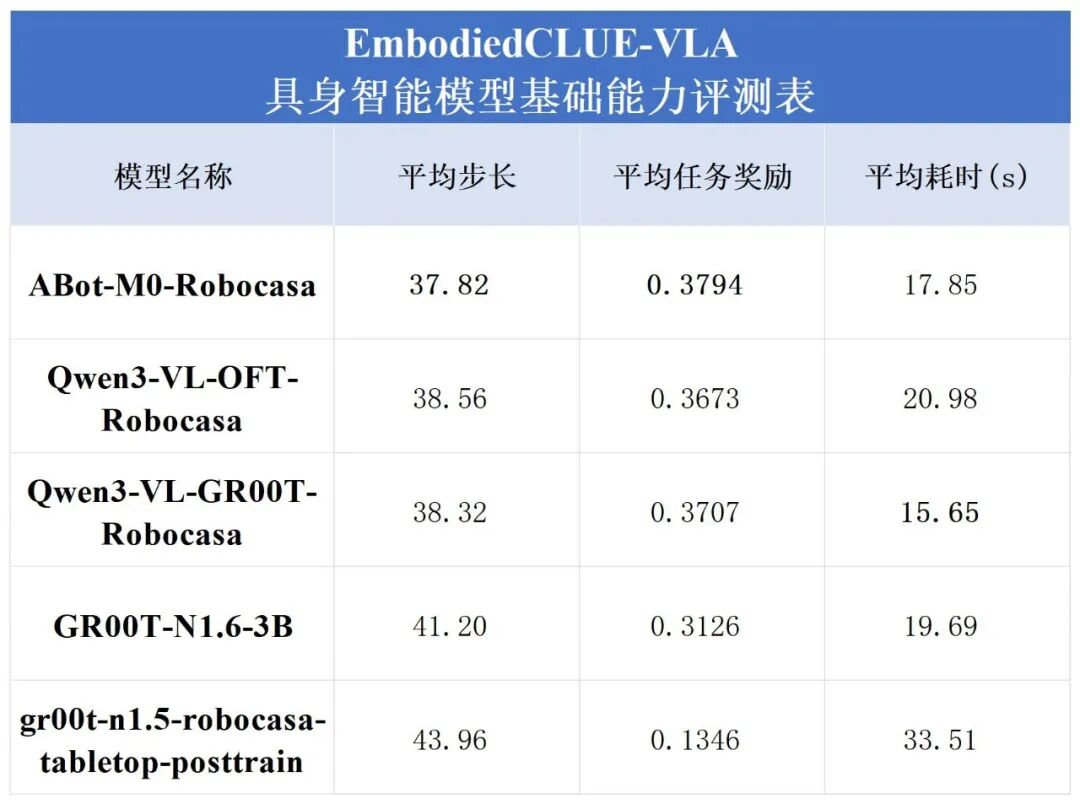
1. 模型基础能力评分
综合考虑完成性、效率与过程质量三项信息后,评测基准给出模型基础能力评分线性加权计算公式:
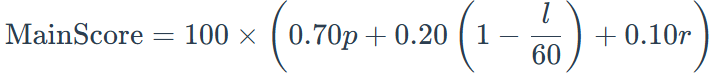
其中:(p):成功率;(l ):平均步长;(r ):平均任务奖励。采用 0.70 / 0.20 / 0.10 的权重组合,主要基于以下三条原则:
(1)完成任务优先于完成得是否高效。
(2)平均步长比平均任务奖励更能直接反映效率差异。
(3)平均任务奖励与成功率、步长之间存在一定相关性。
基于上述考虑,这一权重组合可以概括为:完成性 > 效率 > 过程质量这一排序与桌面操作任务的评测逻辑是相一致的。
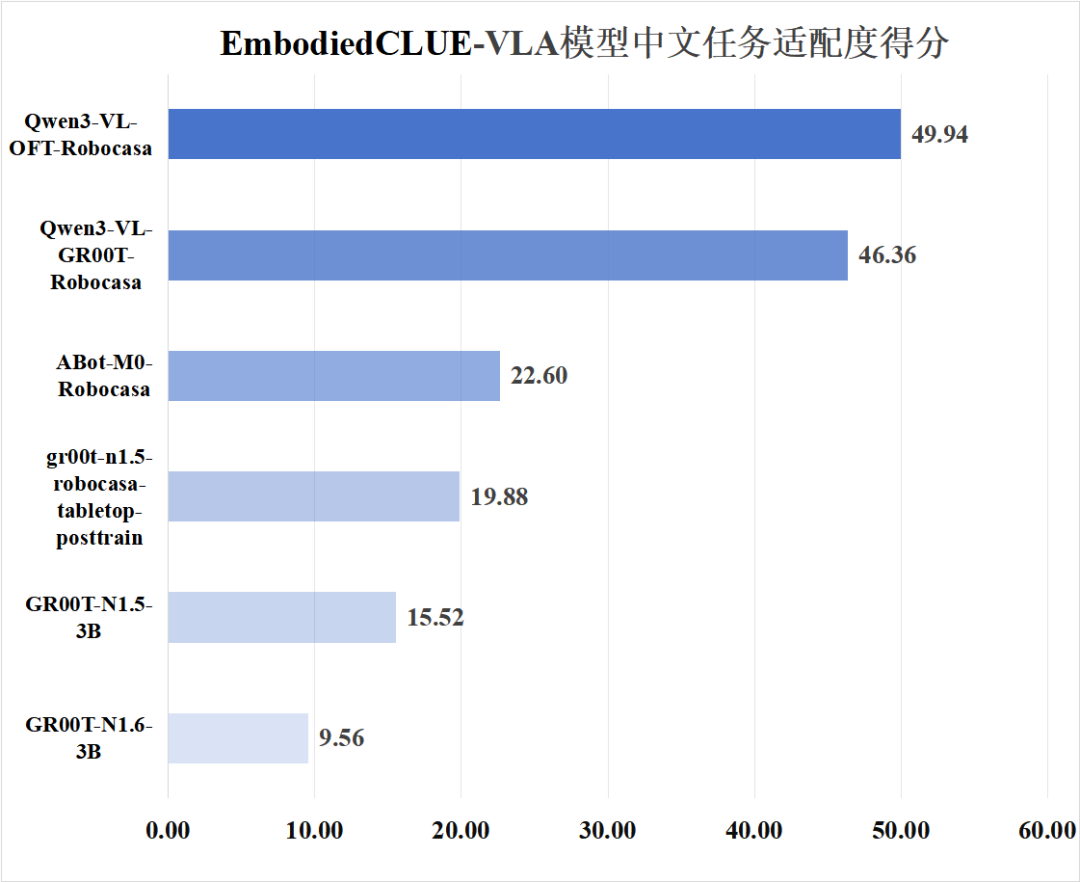
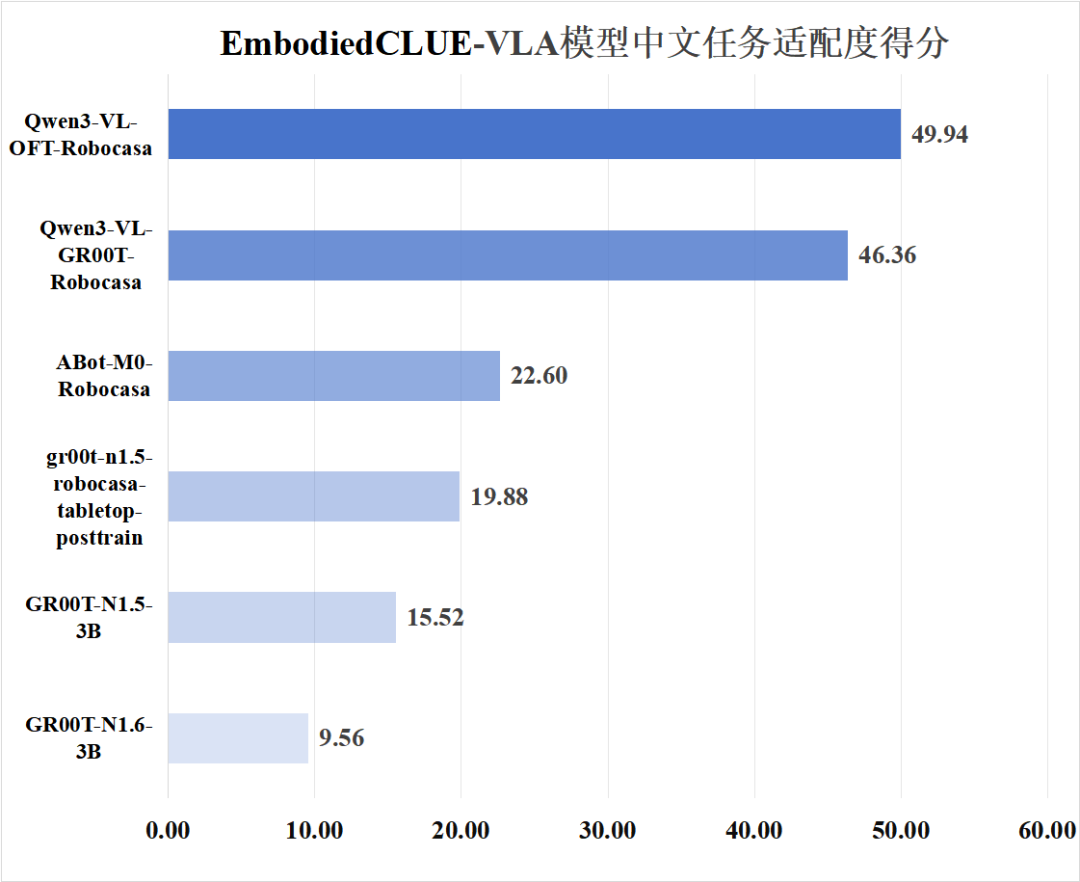
2. 模型中文适配度评分
综合考虑原生中文、转换中文能力,评测基准给出模型中文适配度评分线性加权计算公式:
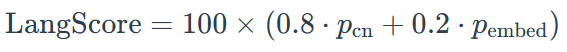
(2)embedding 路由模块更多侧重于工程上的支持。这一模块本质上是为了说明模型除了 backbone 之外的动作执行层仍然有效,可以选择性适配中文。
基于上述考虑,这一权重组合可以概括为:原生中文 > 转换中文,这一排序与中文适配度的评测逻辑是一致的。
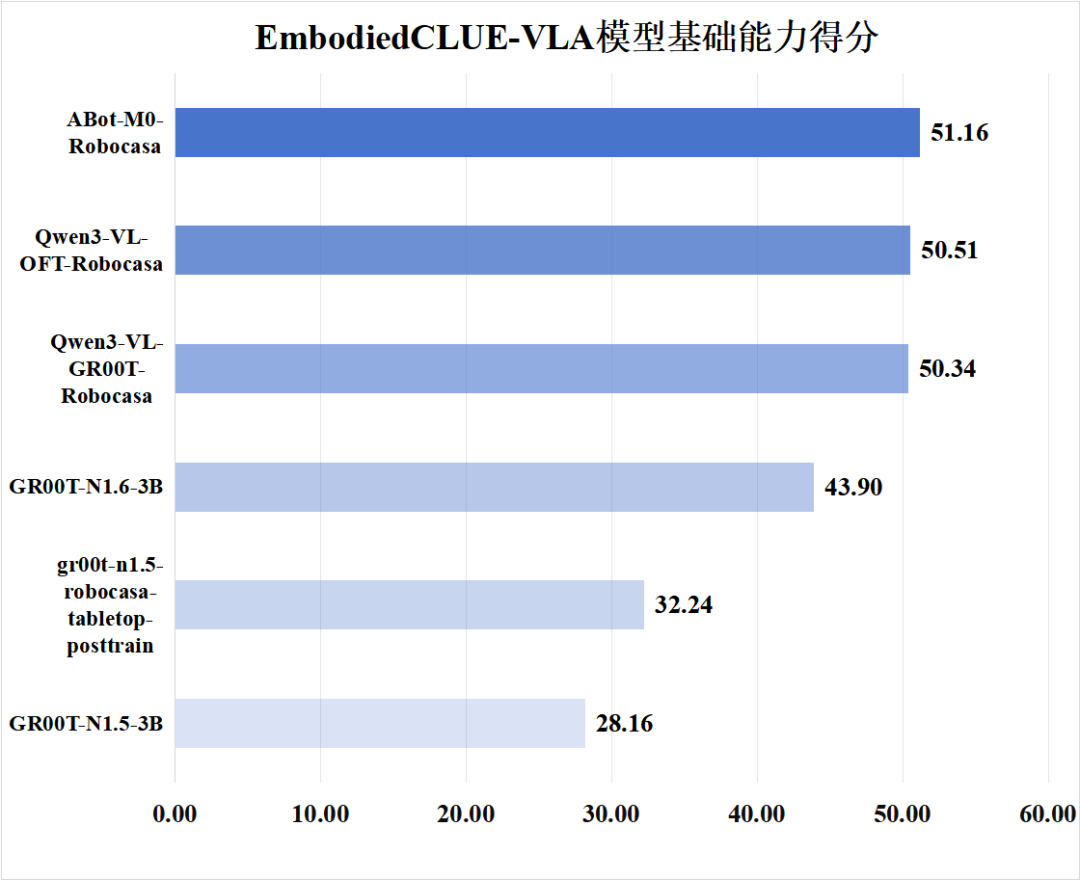
3.评分排行
为了方便可视化评分信息,下附模型基础能力得分、模型中文适配度得分图:
为了进一步反映模型总体得分情况,下附模型评分总分象限图:

一、评测统一实验设置
1.基础评测设置
本次评测统一基于robocasa-gr1-tabletop-tasks场景进行。该场景建立在 RoboCasa 与 robosuite 之上,在MuJoCo仿真环境中提供标准化的桌面操作任务、机器人配置、观测接口与动作下发协议,从而保证不同模型面对的是相同的任务定义、相同的观测形式、统一的动作空间与一致的终止条件。
在实验设置上,所有模型均采用相同的测试任务集与随机种子设置。具体而言:
n_steps(最大步长)= 60;n_envs(并行环境数)= 5;max_episode_steps(最大交互动作数)= 720;n_action_steps(单步推理执行动作数)= 12;
所有模型均通过统一环境接口完成推理、动作下发与结果统计。
这一设置的意义在于:评测结果不再依赖单次 demo 是否“跑得漂亮”,而是建立在统一任务、统一 seed、统一终止条件和统一日志统计之上,从而使不同模型之间的横向比较具备更强的公平性与可复现性。
2.中文评测设置
围绕 RoboCasa-GR1-Tabletop 的中文能力评测,本评测采用两条并行路线:其一是原生中文直传,其二是基于 embedding 的中英文文路由转换。
原生中文直传是指直接将中文任务指令输入模型,观察模型在不借助外部显式翻译模块时的任务执行表现。该测试更接近模型本体的原生中文能力,它直接考察中文输入是否能够通过模型内部表示,继续被正确转化为动作决策。在下文的评测表中标记为(cn)。
与原生中文直传不同,embedding 路由转换并不要求模型本体直接“理解任意中文”,而是通过独立的中文语义匹配模块,将自由中文表达自动转换到标准任务模板,再交由策略模型执行。在下文的评测表中标记为(embed)。在输入接口补齐的基础上,本评测进一步构建了面向 24 个 RoboCasa GR1 Tabletop 任务的中英文任务模板注册表。对于每个任务,系统均定义了标准英文任务描述、标准中文任务描述,并建立了任务环境名、任务名与双语模板之间的一一对应关系:
ENV_TO_EN_INSTRUCTION: Dict[str, str] = { "gr1_unified/PnPCupToDrawerClose_GR1ArmsAndWaistFourierHands_Env": "pick up the cup, place it into the drawer and close the drawer.", "gr1_unified/PnPPotatoToMicrowaveClose_GR1ArmsAndWaistFourierHands_Env": "pick up the potato, place it into the microwave and close the microwave.", "gr1_unified/PnPMilkToMicrowaveClose_GR1ArmsAndWaistFourierHands_Env": "pick up the milk, place it into the microwave and close the microwave.", "……": "……", }ENV_TO_ZH_INSTRUCTION: Dict[str, str] = { "gr1_unified/PnPCupToDrawerClose_GR1ArmsAndWaistFourierHands_Env": "拿起杯子,把它放进抽屉里,并关上抽屉。", "gr1_unified/PnPPotatoToMicrowaveClose_GR1ArmsAndWaistFourierHands_Env": "拿起土豆,把它放进微波炉里,并关上微波炉门。", "gr1_unified/PnPMilkToMicrowaveClose_GR1ArmsAndWaistFourierHands_Env": "拿起牛奶,把它放进微波炉里,并关上微波炉门。", "……": "……",}
为了避免将“中文理解误差”与“策略执行误差”混在一起,本文没有直接使用端到端 rollout 结果来评价中文支持,而是单独构建了一套面向中文 embedding 的离线泛化测试集。该测试集覆盖 24 个任务,每个任务设计 30 条未出现在 embedding 候选库中的中文描述,总计 720 条中文测试样本。
这些测试样本不仅覆盖标准表达,还进一步包含口语化表达、简单句表达和长难句表达等多种语言风格,从而使评测结果不仅反映“中文能否匹配任务”,也能够反映“中文语义路由在不同语言风格下的稳定性”。这种测试集构建方式,使中文支持具备了独立评测和独立分析的条件。以下为其中一个任务的测试样本示例:
"gr1_unified/PnPCupToDrawerClose_GR1ArmsAndWaistFourierHands_Env": { "task_name": "PnPCupToDrawerClose", "instruction_en": "pick up the cup, place it into the drawer and close the drawer", "instruction_zh": "请把杯子放进抽屉里并关上抽屉。", "zh_candidates": [ "请将杯子放入抽屉内并关上抽屉。", "拿起杯子,放进抽屉,再把抽屉关上。", "把杯子拿起来放入抽屉,然后关闭抽屉。", "请拾起杯子,置于抽屉中,随后关上抽屉。", "需要你把杯子放进抽屉,并关好抽屉。", "请执行:取杯子,放抽屉,关抽屉。", "把杯子放到抽屉里,再将抽屉合上。", "请你把杯子收纳进抽屉,然后关上。", "杯子放抽屉里,再关上。", "把杯子搁抽屉,关门。", "杯子放进去,关抽屉就行。", "把杯子放抽屉,顺手关上。", "杯子放抽屉里,关好它。", "放杯子,关抽屉。", "杯子搁里头,门带上。", "把杯子收抽屉,关。", "请你小心地拿起那个杯子,然后平稳地放入抽屉内部,最后轻轻地将抽屉推回去并确保完全关闭。", "请先取杯子,再将其稳妥地放置于抽屉之中,随后缓缓推合抽屉直至关严。", "需要你完成以下动作:拾起杯子,放入抽屉,再将抽屉门关闭,整个过程需保持稳定。", "麻烦你把杯子从桌面上拿起来,放进抽屉的适当位置,之后把抽屉关好,不要留缝隙。", "请你以轻柔的动作拿起杯子,放入抽屉内,然后用手将抽屉推入,直到听到咔哒一声关好。", "请执行如下操作:拿起杯子,置入抽屉,关闭抽屉,动作连贯且平稳。", "你需要将杯子从原处拿起,放入抽屉内,随后关闭抽屉,确保抽屉完全合上。", "请你先拾取杯子,再放入抽屉,最后关上抽屉,整个过程要细致。", "杯子放抽屉里,门关上。", "把那个杯子搁进抽屉,再把抽屉推上。", "关抽屉前,先把杯子放进去。", "劳驾您把杯子放进抽屉,再帮忙关一下门。", "杯子放抽屉,完了关门。", "把杯子放到抽屉里面去,然后记得把抽屉关上啊。" ] },
为了区分差异度,后续评测时每个模型从每个任务的泛化中文测试样例中随机抽取10条(共240条)用于反应 embed 评测指标。
二、细分任务评测
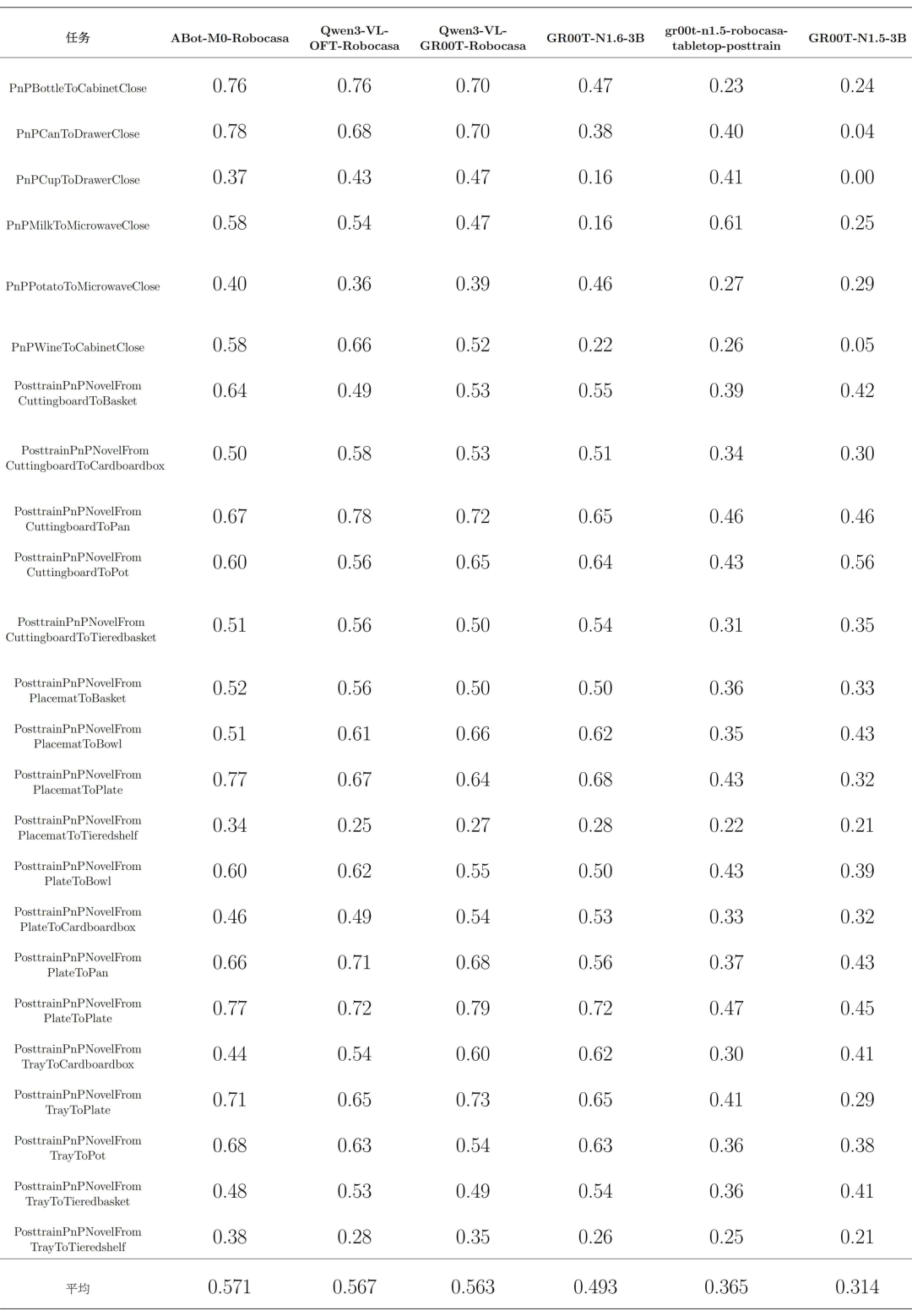
1.原生英文评测结果
进一步下沉到任务级别,可以看到不同模型之间并不存在“全任务完全一致的绝对排序”,而是表现出较为鲜明的任务偏好。例如,在复合容器关闭类任务中,不同模型对“放置—关闭”这一连续动作链的稳定性存在明显差异;在案板、桌垫、餐盘、托盘等不同起始容器条件下,模型对目标物体抓取、搬运及放置路径的稳定性也并不相同。
在第一梯队内部,Qwen3-VL-OFT-Robocasa与Qwen3-VL-GR00T-Robocasa虽然总体成功率接近,但在若干细分任务上分别具有更突出的局部优势;ABot-M0-Robocasa则更偏向整体均衡型,在多数任务上不一定都是第一,但整体波动更小、综合表现更稳。
对于GR00T-N1.6-3B而言,任务级结果显示该模型并非全面失效,而是在一部分搬运类任务上具备中等水平的可用性;问题主要在于其跨任务一致性和整体完成度仍与第一梯队存在差距。至于GR00T-N1.5-3B及其 posttrain 版本,虽然在个别任务上能够给出相对可观的成功率,但在全任务范围内尚未形成足够稳定的高水平表现。下附原生英文 en 细分任务模型评测表:
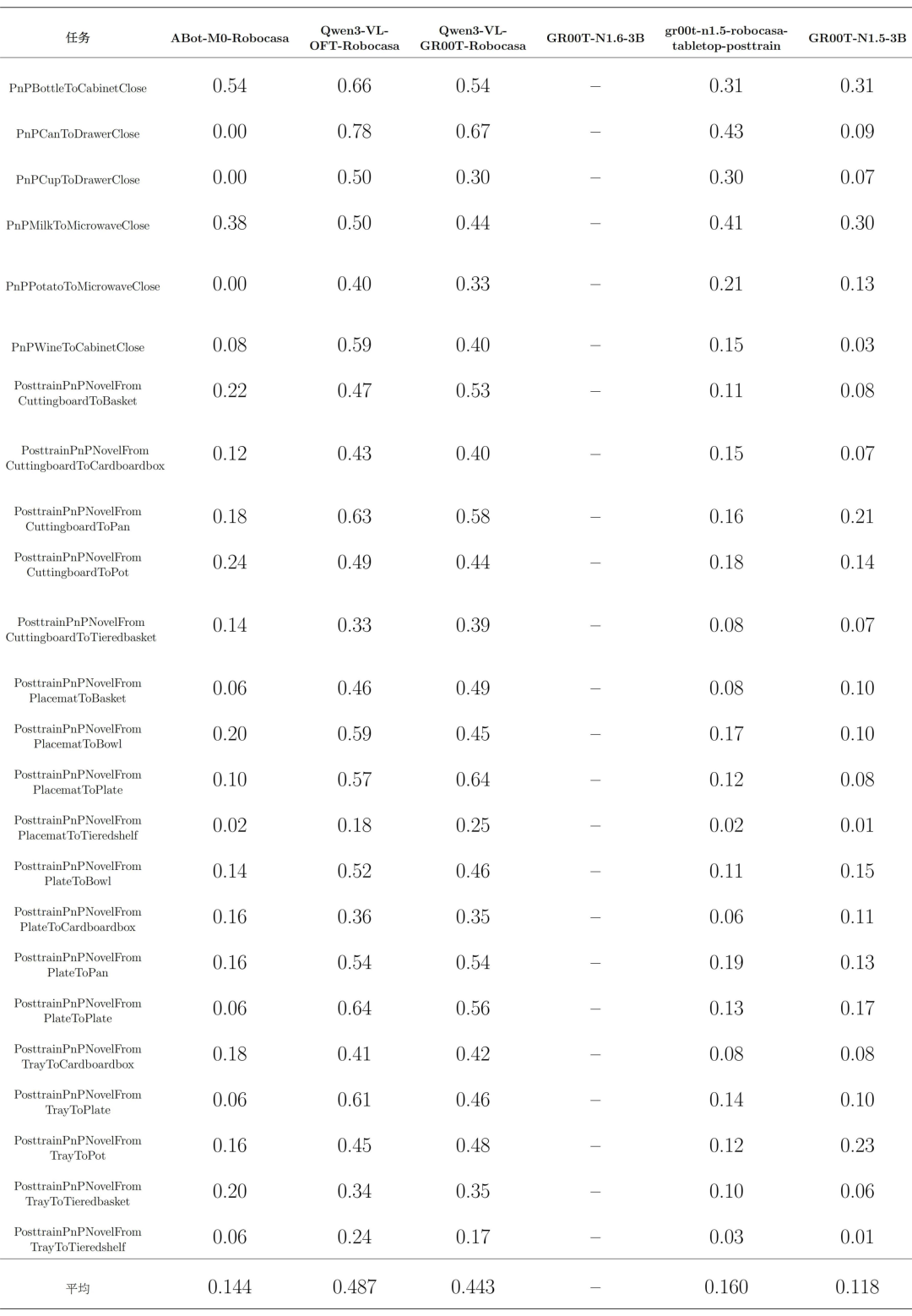
2.原生中文评测结果
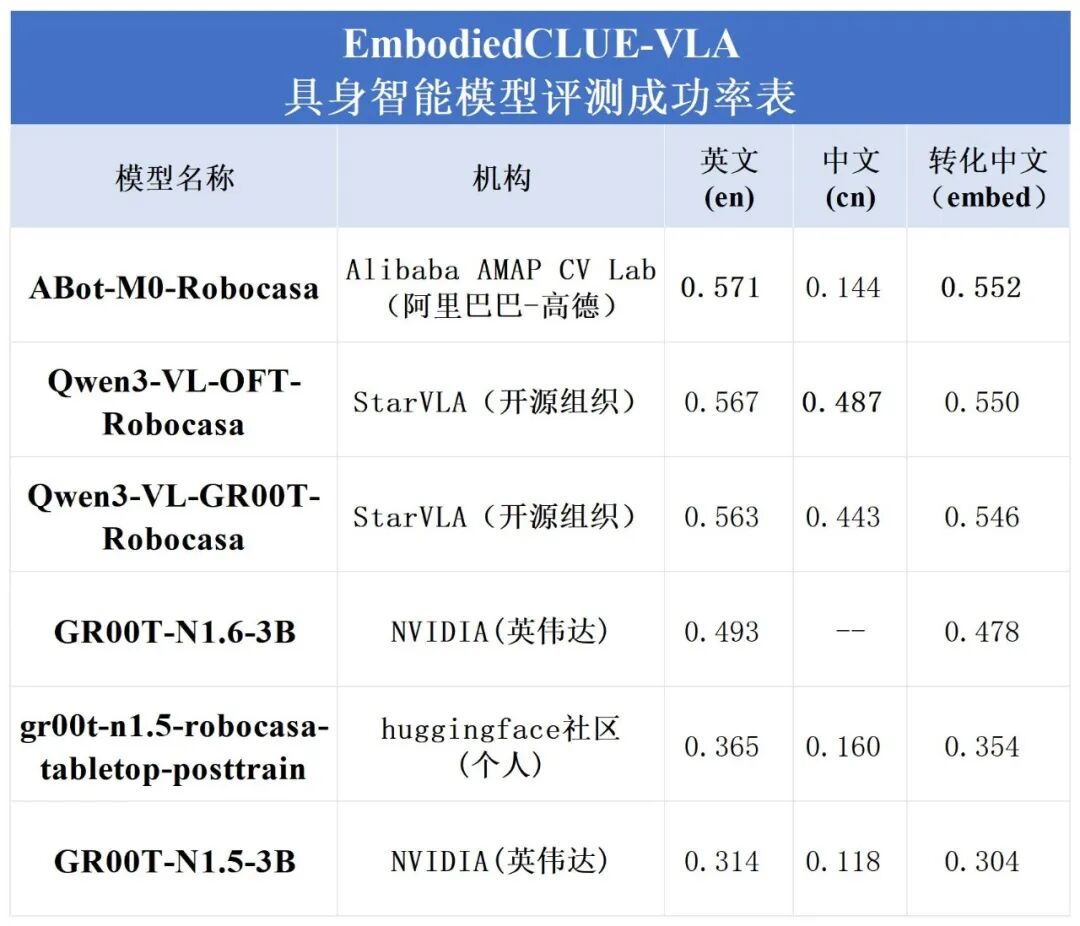
从整体结果来看,六个模型在原生中文条件下的差异远大于原生英文条件下的差异。
Qwen3-VL-OFT-Robocasa取得了最高的原生中文平均成功率,Qwen3-VL-GR00T-Robocasa次之,二者与其他模型之间形成了较清晰的领先优势。这说明Qwen3-VL-4B-Action 这一 backbone 对中文的支持能力较强,切换语言后语义损失较小。
ABot-M0-Robocasa 在原生中文直传场景中成功率显著下降,并非完全偶然。从公开论文描述看,其数据清洗与统一过程将非英文内容(包括中文)视为会干扰意图解析与语言—动作对齐的因素,因此模型整体更偏向围绕规范英文任务指令建立稳定对齐机制。这使其在标准英文 benchmark 下表现突出,但在中文直传条件下,中文语义难以像英文模板那样稳定映射到既有任务分布,进而导致成功率明显下降。
相比之下,GR00T-N1.6-3B 对中文直传的削弱更为彻底,因此在当前统计中基本不支持中文 instruction 直接传入。下附原生中文 cn细分任务模型评测表:
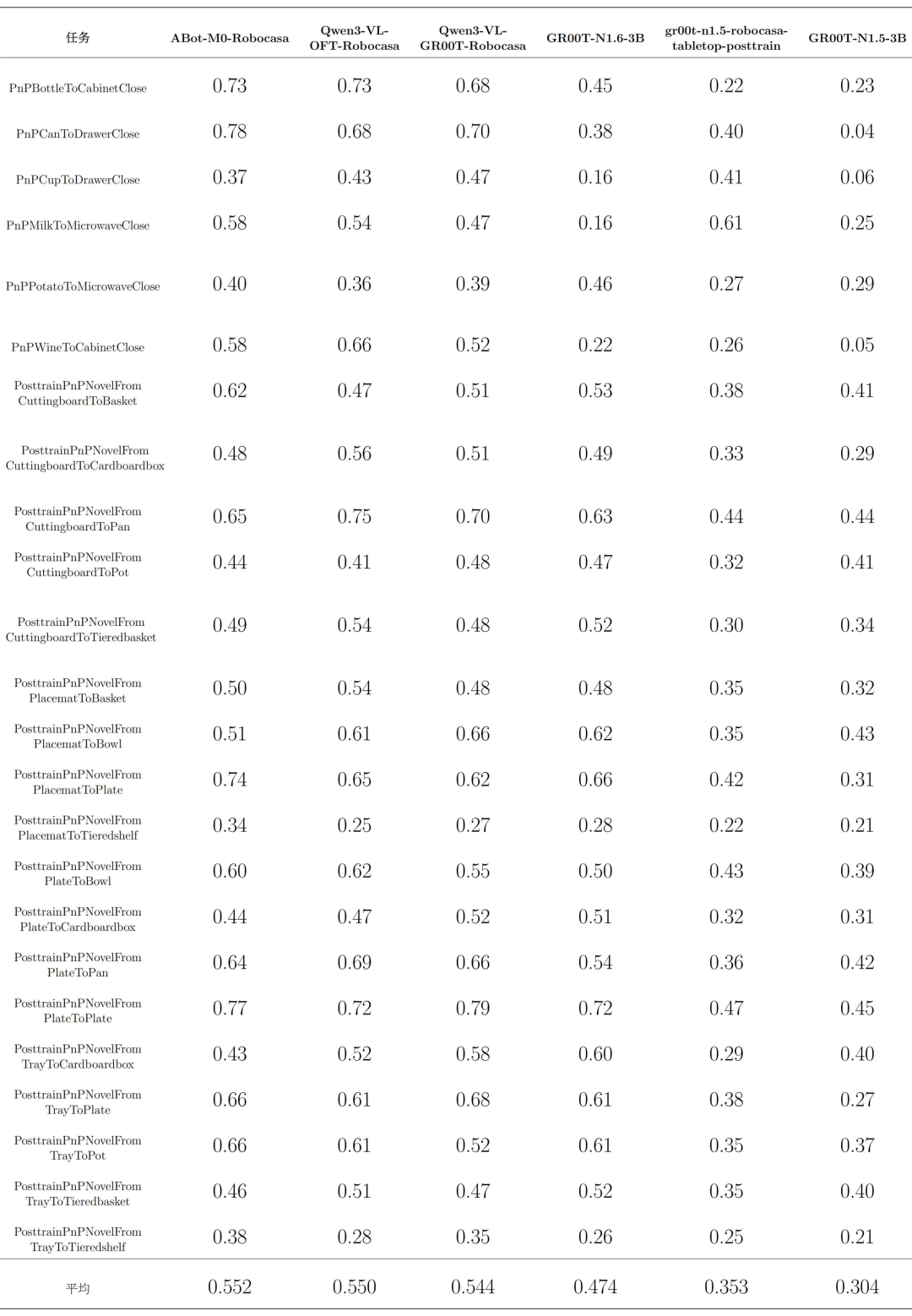
3. embedding 的中文路由映射评测结果
从总体结果来看,embedding 路由转换后,各模型的中文任务成功率普遍高于原生中文直传结果,且整体排序更加接近英文 benchmark 的排序。这说明:在当前阶段,中文路由转换能够有效缓解部分模型原生中文理解不足的问题,使系统在中文输入条件下恢复到更接近英文标准任务的能力水平。下附转换中文 embed 细分任务模型评测表:
更多评测可视化数据和图表信息,请扫码或长按查看:






