 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
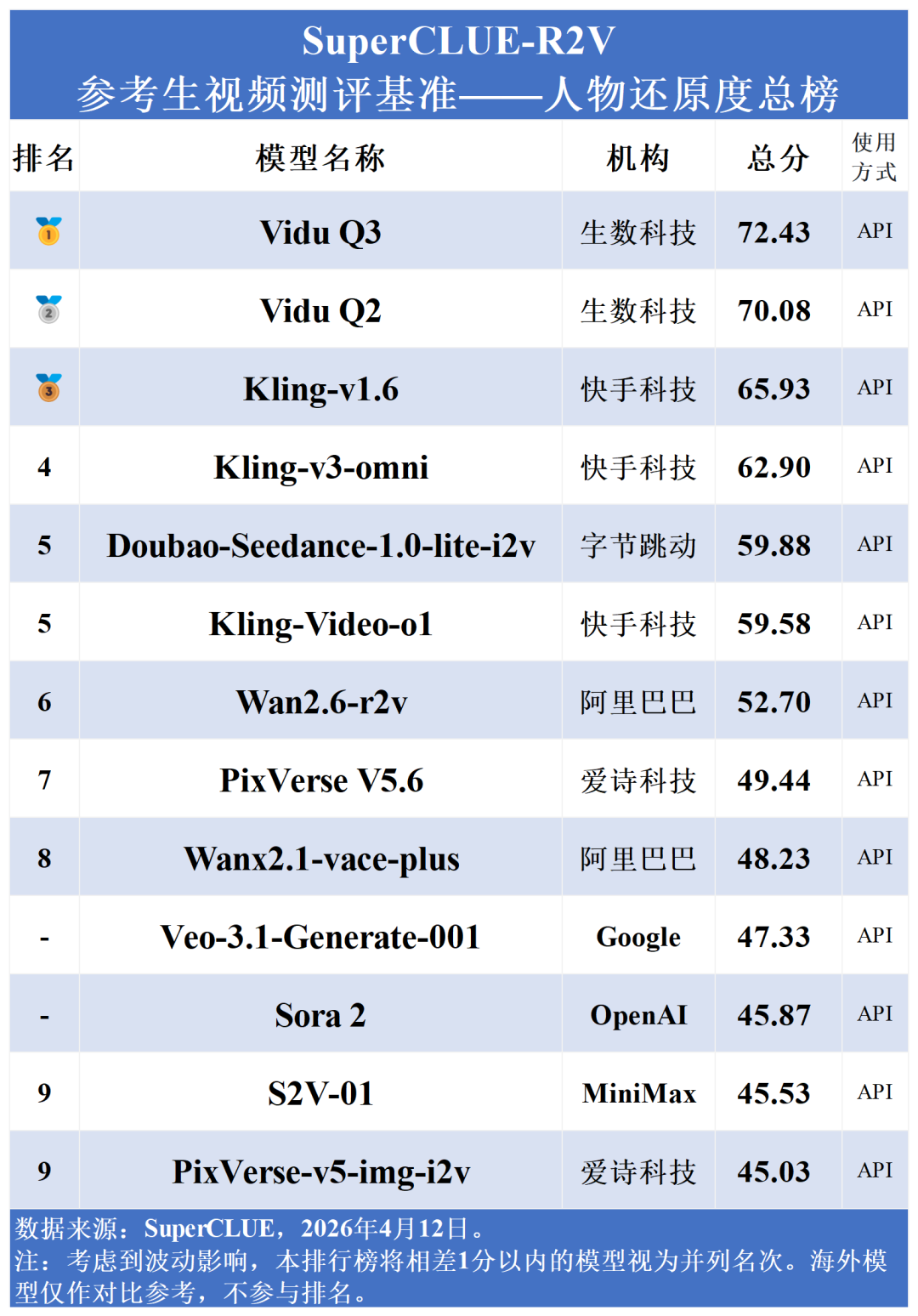
数据库全球首个参考生榜单首期发布|Vidu Q3强势登顶!

2026年4月,中文原生参考生视频模型测评基准(SuperCLUE-R2V)4月首期榜单正式发布。该基准作为全球首个参考生视频榜单,秉承创新性、紧跟前沿、客观性与综合全面的核心理念,立足于中文语境对模型展开深度评测。为精准衡量模型在不同输入条件下的真实水平,本次测评核心划分为以下两大模块:
多图参考任务:评估模型在物理真实性、主体一致性、画面流畅度、场景一致性、指令执行度及运动表现性等六大基础能力表现;更考察在影视创作、商业广告、电商运营及泛互娱等四大核心场景中的实际应用能力。
单图参考任务:单独设立人物还原度专项基础能力测试,用以评估在主流需求下模型对特定人物特征的精准保持与还原能力。
本次测评涵盖国内外共13个具有代表性的参考生视频模型,对各模型综合生成能力开展全面深度评估。以下为详细测评细则与结果报告。
提示词:@图1在奔跑着,@图2在后面紧追不舍。最后老虎把鹿扑倒,咬住喉咙。

各头部模型效果展示
参考生视频测评摘要
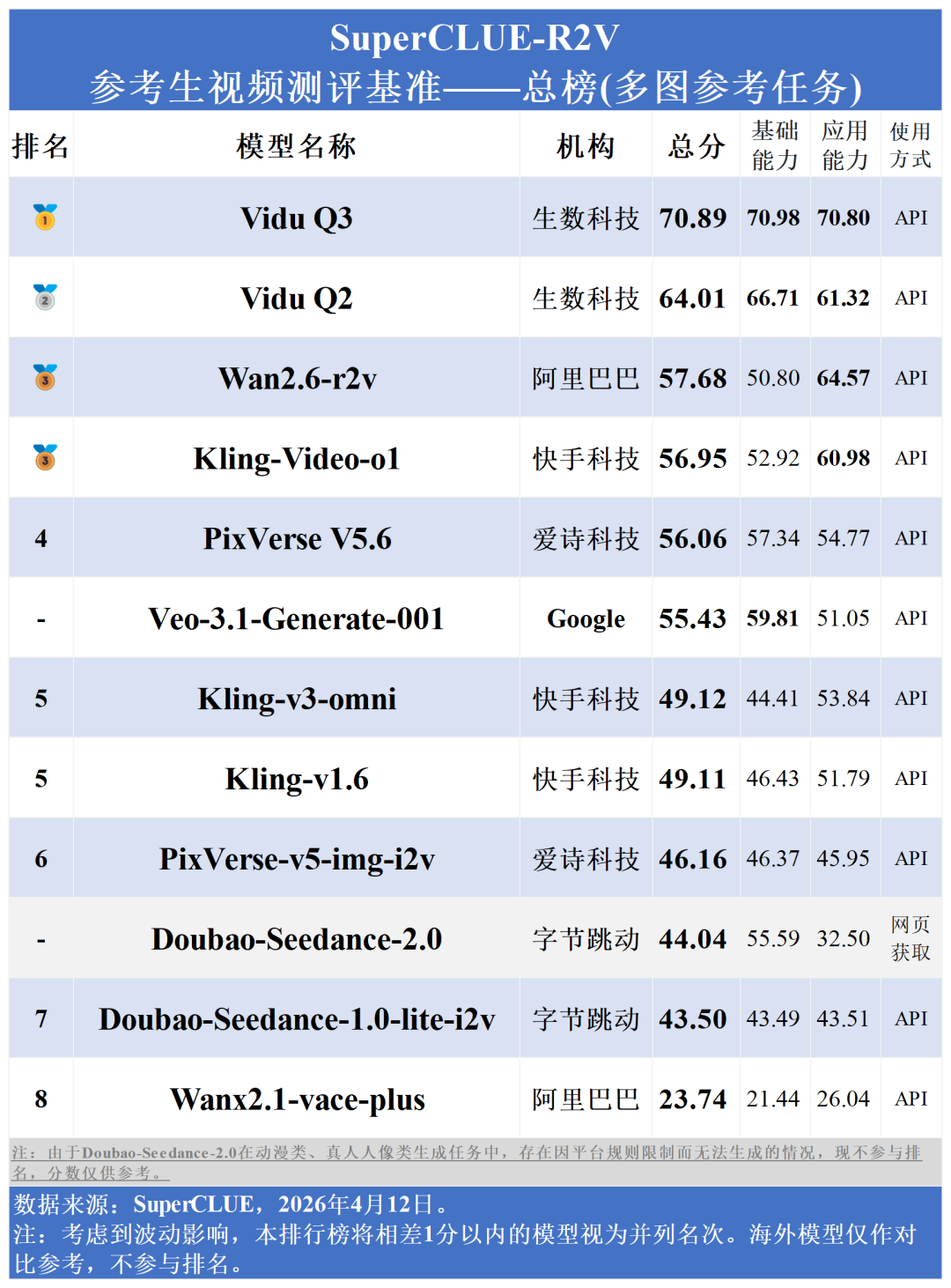
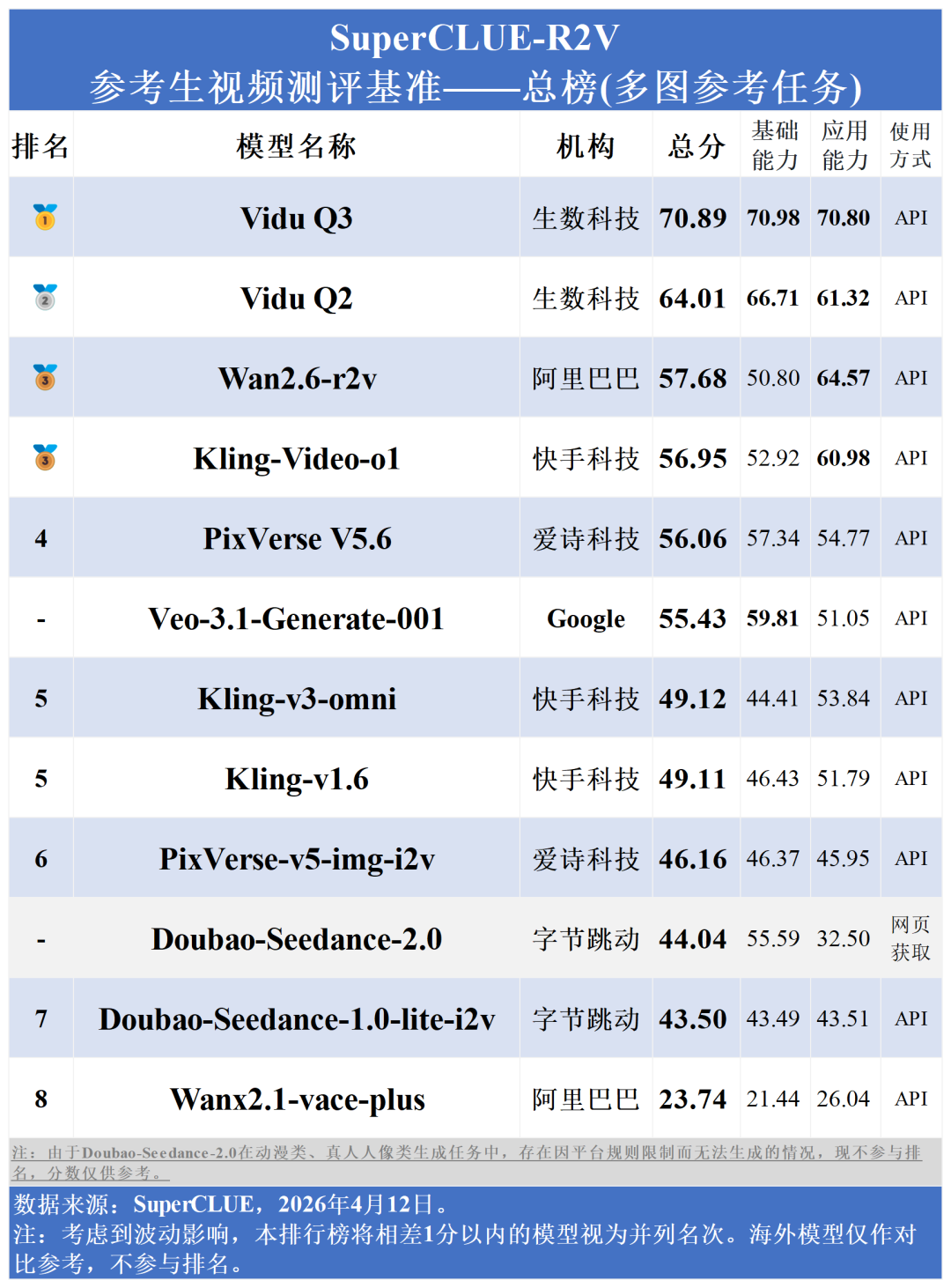
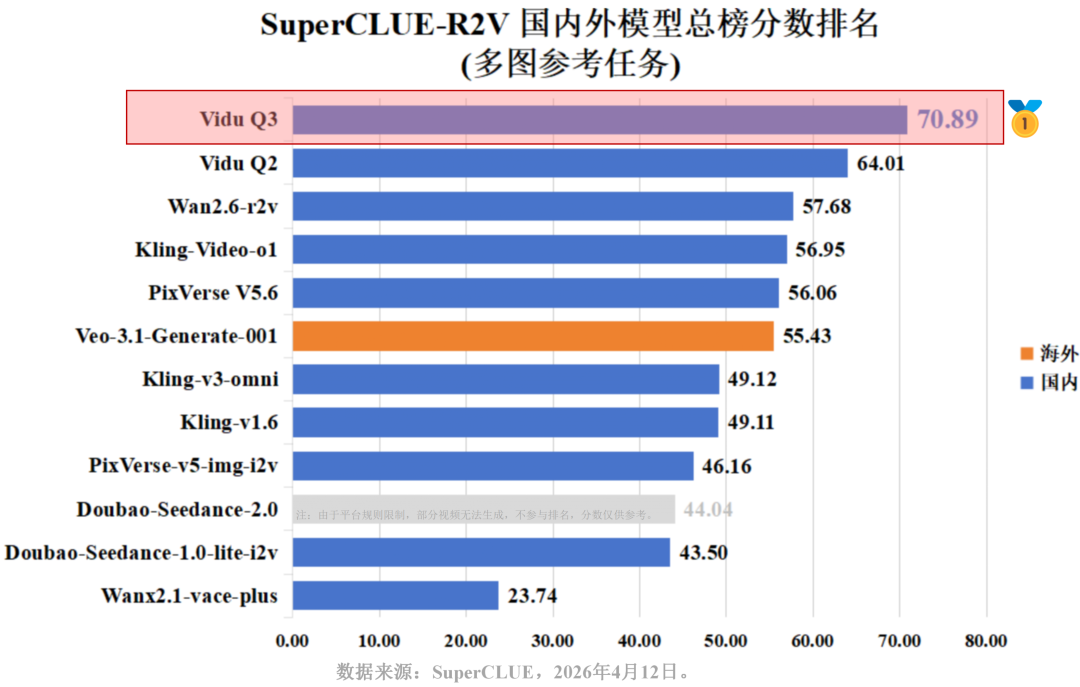
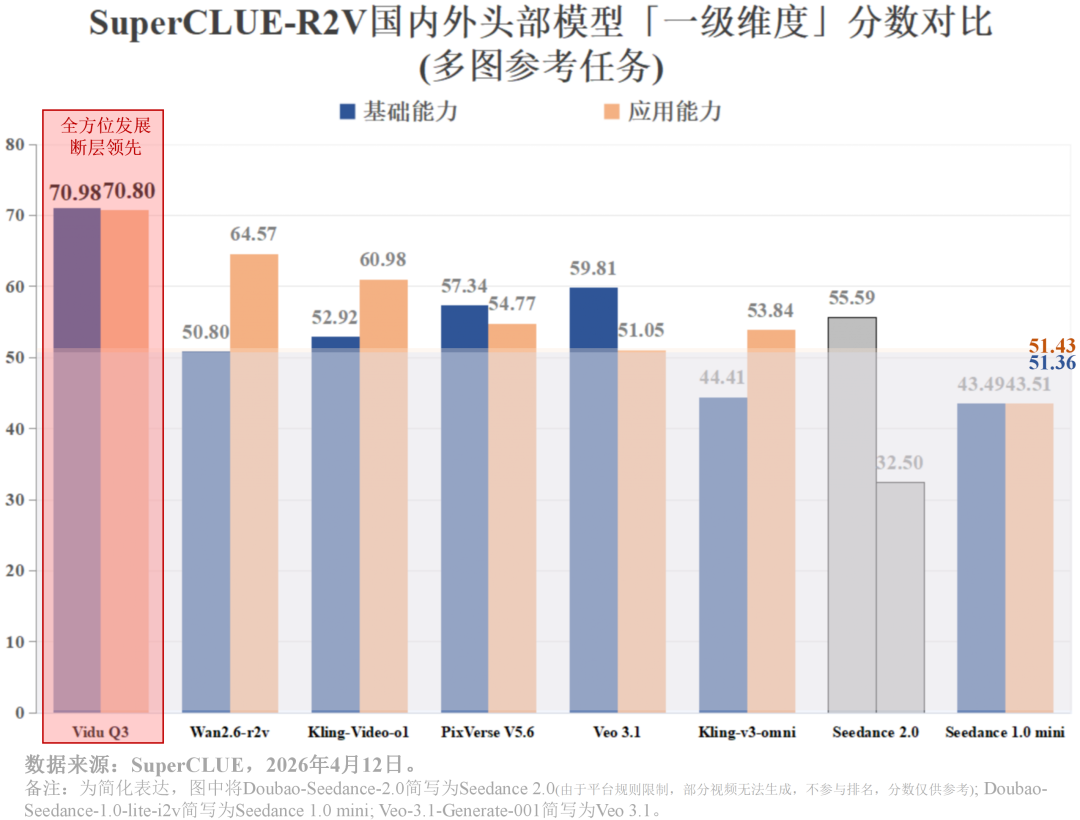
生数科技的Vidu Q3以70.89分强势登顶多图参考总榜、以72.43分登顶单图参考-人物还原度总榜榜首。同门模型Vidu Q2 (多图64.01,单图70.08)紧随其后。相比之下,Veo-3.1-Generate-001 (多图55.43,单图47.33)位列中下游。
测评要点2:基础能力突破:一致性技术成熟,流畅度仍为行业瓶颈。
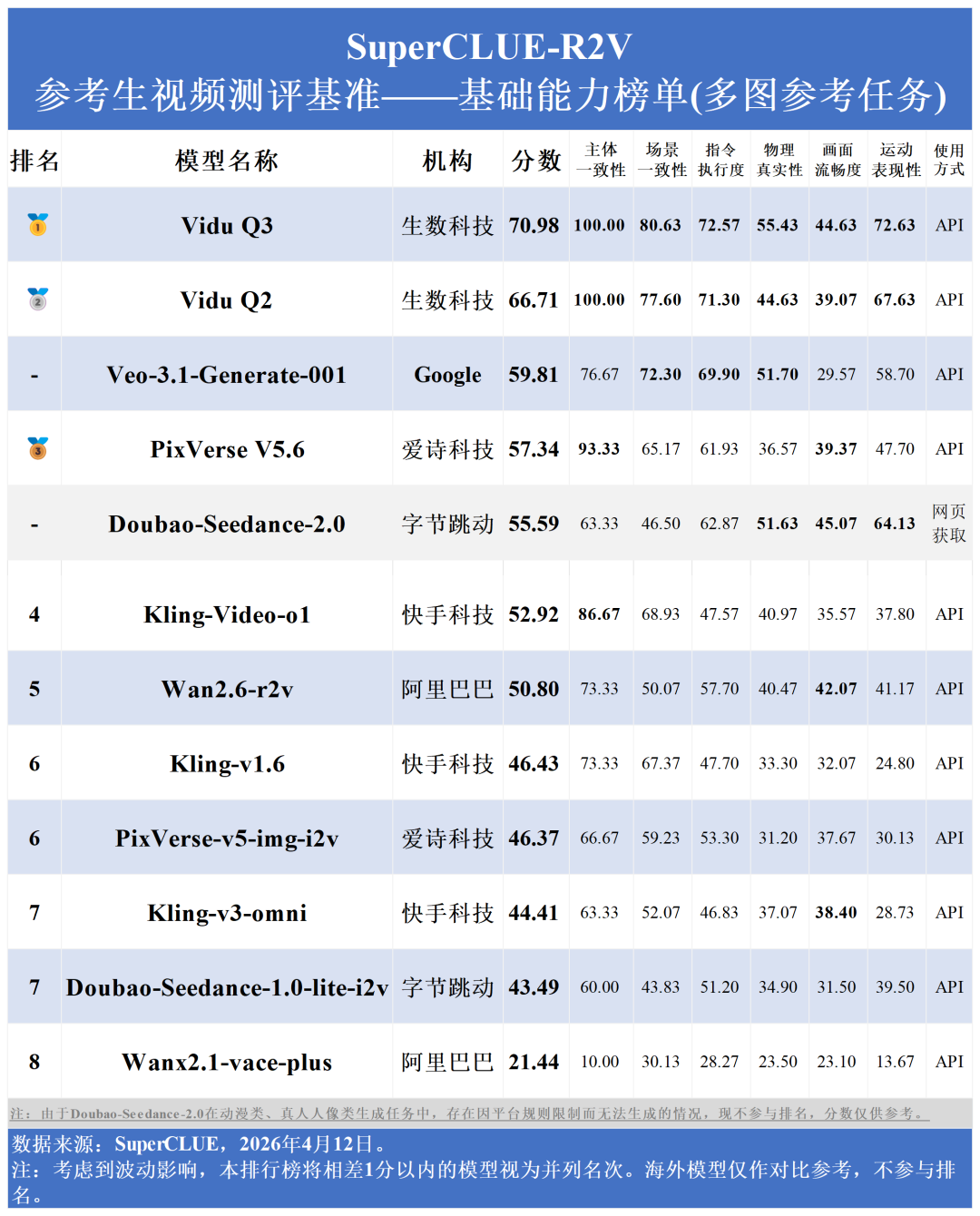
主体一致性上,Vidu Q3与Vidu Q2斩获100分,PixVerse V5.6 (93.33) 及Kling-Video-01 (86.67) 紧随其后,显示特征维持技术已趋于成熟。但在画面流畅度上,全行业得分普遍处于30-45分的较低区间,面临共同技术瓶颈。
测评要点3:应用场景加速落地:商业化能力优势明显,深度赋能行业生产。
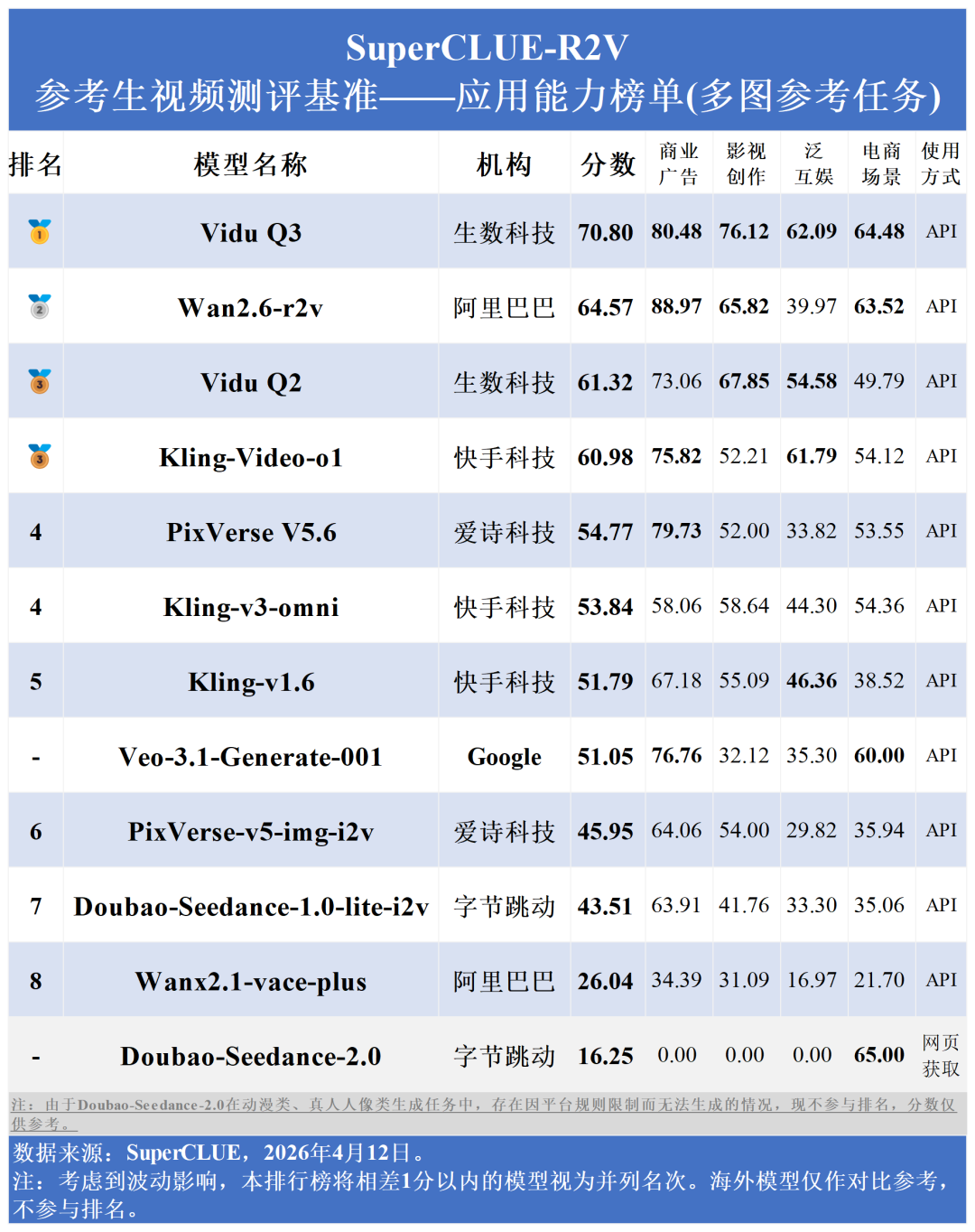
Vidu Q3以70.80分斩获第一,Wan2.6-r2v以64.57分位居国内第二。国内模型在影视创作、商业广告等垂直领域的得分普遍在60-80分区间,展现了更强的行业应用适配度。
注:由于Doubao-Seedance-2.0在动漫类、真人人像类生成任务中,存在因平台规则限制而无法生成的情况,现不参与排名,分数仅供参考。
# 榜单概览
一、多图参考任务
二、单图参考任务
榜单地址:www.superclueai.com
#SuperCLUE-R2V介绍
SuperCLUE-R2V 是一个专为参考生视频产品设计的评测基准,旨在为参考生视频领域提供全面且多维的能力评估参考。基准包括基础能力与应用能力两大核心维度,涵盖11个二级维度。
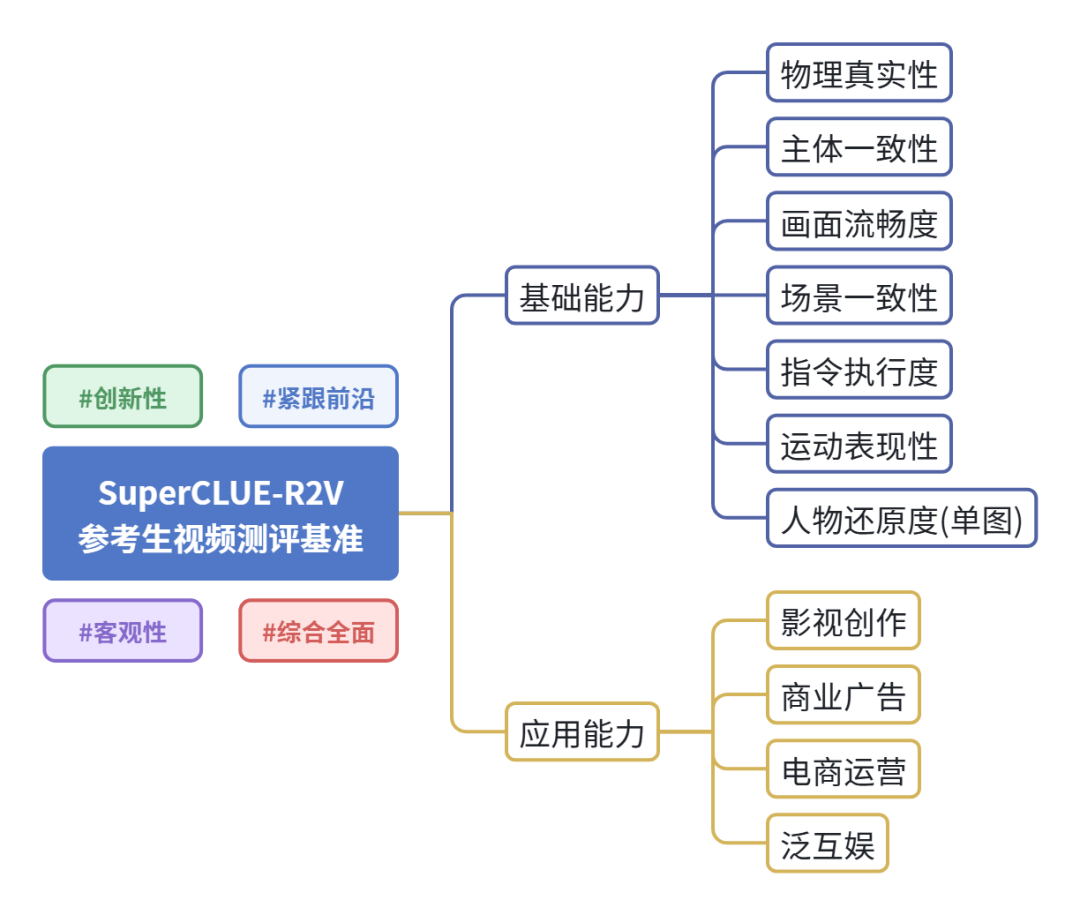
SuperCLUE-R2V立足于中文语境,不仅衡量模型在多图参考下的物理真实性、主体与场景一致性、画面流畅度、质量执行度与运动表现性六大基础能力表现,还考察在影视创作、商业广告、电商运营和泛互娱四大应用能力。同时,本次测评还单独设置了单图参考任务,考察在主流应用需求下模型的人物还原度表现,用以评估其对特定人物特征的精准保持与还原能力。

因部分模型支持的最大参考图数量少于测评传入数量,将重点核验参考图还原效果,生成视频与参考图不符时将予以扣分。现新增多图输入适配性专项规则如下:
若本次测评传入的参考素材数量为 {N} 张,但参测模型最大支持为 {M} 张,且 {M} < {N}时,需按以下规则专项降分:
若生成视频仅匹配 {M} 张参考图特征,完全未体现剩余 {N-M} 张参考图核心元素 → 综合得分下调0.2-0.3 分(下调幅度根据未体现元素的核心程度判定,核心主体 / 关键风格元素缺失取高值,次要细节缺失取低值);
若生成视频匹配 {M} 张参考图特征,部分体现未输入的 {N-M} 张参考图核心元素 → 综合得分下调0.1-0.2 分;
若生成视频完美匹配 {M} 张输入参考图特征,且完全复现未输入的 {N-M} 张参考图的核心元素 → 豁免专项降分,不额外加分。
SuperCLUE-R2V参考SuperCLUE细粒度评估方式,采用 Gemini-3-Flash-Preview 作为裁判模型,每个维度进行细粒度的评估并可以提供详细的反馈信息。该评估流程分为以下几个步骤:

1)测评集构建

2)评分标准
裁判模型根据预先定义的评测流程进行评估。评测流程涵盖了评价流程的说明、评价标准、打分细则、以及数据格式要求,确保评分的一致性、稳定性与公正性。
3)自动化评价
裁判模型将根据具体的任务类型结合相关标准进行自动化评分。此外,SuperCLUE-R2V 将采用多轮测评方案,即针对同一个模型生成的全部视频均将采取相同的评价流程进行前后三次测评,并将三次结果的平均值作为每个视频的最终分数参与后续计算与排名。
4)综合评分与反馈
【测评维度】:应用能力—商业广告
【提示词】:@图1的女生戴着@图2那顶缀着羽毛装饰的红色礼帽,站在@图3那对舒展的白色翅膀雕塑旁,指尖轻拂着连衣裙的裙摆,日落的橘光漫过帽檐的羽尖落在她的肩头,神情温柔又松弛,背景里海面漾着金红的余晖,整个画面浸着海边黄昏的浪漫氛围感。
【参考图片】

【裁判模型——第一轮打分】
1. **多图适配性专项说明**:
本次传入参考素材数量:3 张 | 被测模型最大支持数量:3 张
适配性判定:无需专项调整
判定依据:生成视频完整且精准地融合了图1的人物形象(白裙女生)、图2的特定装饰(缀羽毛红色礼帽)以及图3的特定场景(白色翅膀雕塑及海边日落),模型成功接收并处理了所有参考素材。
2. **初步质量定性 (0.0-1.0 分档)**:
优秀(0.8-1.0档)
3. **我的思考与总体评价(重点列举缺陷)**:
**主要优点**:
- 优点1:**素材还原度极高**。视频精准复现了图2红色礼帽上的羽毛纹理特征,以及图3雕塑特有的镂空圆点质感,这在多图参考任务中属于极高水平的还原。
- 优点2:**光影融合极其出色**。日落的金红色余晖不仅映照在背景海面上,还自然地勾勒出人物白裙的边缘和帽檐,完美契合了文本指令中“橘光漫过帽檐”的氛围描述。
- 优点3:**构图与氛围感强**。人物处于雕塑羽翼之间,海边黄昏的浪漫色彩饱和度适中,具有很强的商业广告美感。
**必须详细列出的缺点、不足、与任务要求偏差之处**:
- 缺点1:**动态程度不足**。视频的动态表现较为保守,更接近于带有微动效果的静态海报,人物的“指尖轻拂裙摆”动作幅度极小,缺乏流畅的交互感。
- 缺点2:**人物特征漂移**。虽然保留了图1女生的长黑发和白裙特征,但侧脸的面部轮廓与图1参考人物存在一定的AI美化导致的偏差(识别度略有下降)。
- 缺点3:**细节逻辑微瑕**。由于镜头微小的位移,人物持握裙摆的手指部位在最后几帧出现了轻微的结构模糊。
4. **逐项打分与评价(严格区分)**:
**(一)离散标准评分 (0/1)**:
1. 标准1 <主体信息还原度> 的评价:人物形象(白裙、长发)、核心商品(红礼帽、特定羽毛装饰)及场景主体(白色羽翼雕塑)均得到了清晰且准确的还原,满足商业广告对主体识别度的核心要求。
基于标准1的得分:【1】
2. 标准2 <画面质量合规性> 的评价:视频分辨率高,色调统一且具有艺术美感,主体与背景比例协调,无明显的边缘抠图感或画面破碎。
基于标准2的得分:【1】
**(二)连续标准评分 (0.0-1.0)**:
1. 标准1 <元素融合自然度> 的评价:光影处理是最大的亮点,夕阳的漫反射在人物、帽檐和雕塑上的分布极其协调,营造出了浓郁的黄昏氛围。然而,人物手指与裙摆的交互动作较为僵硬,缺乏真实的布料物理反馈,且视频整体动态感过弱,拉低了其作为“视频”的质感。
基于标准1的得分:【0.85】
5. **综合得分计算**:
计算过程:(1 + 1 + 0.85) / 3 = 0.95
连续项调整说明:无调整
综合得分:【0.95】
【裁判模型——第二轮打分】
1. **多图适配性专项说明**:
本次传入参考素材数量:3 张 | 被测模型最大支持数量:3 张
适配性判定:无需专项调整
2. **初步质量定性 (0.0-1.0 分档)**:
< 优秀(0.8-1.0档) >
3. **我的思考与总体评价(重点列举缺陷)**:
<评价过程与第一轮类似,此处略......>
4. **逐项打分与评价(严格区分)**:
**(一)离散标准评分 (0/1)**:
1. 标准1 <主体信息还原度> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准1的得分:【1】
2. 标准2 <画面质量合规性> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准2的得分:【1】
**(二)连续标准评分 (0.0-1.0)**:
1. 标准1 <元素融合自然度> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准1的得分:【0.70】
5. **综合得分计算**:
计算过程:(2 + 0.70) / 3 = 0.90
连续项调整说明:无调整
综合得分:【0.90】
【裁判模型——第三轮打分】
1. **多图适配性专项说明**:
本次传入参考素材数量:3 张 | 被测模型最大支持数量:3 张
适配性判定:[无需专项调整]
2. **初步质量定性 (0.0-1.0 分档)**:
< 优秀(0.8-1.0档) >
3. **我的思考与总体评价(重点列举缺陷)**:
<评价过程与第一轮类似,此处略......>4. **逐项打分与评价(严格区分)**:
**(一)离散标准评分 (0/1)**:
1. 标准1 <主体信息还原度> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准1的得分:【1】
2. 标准2 <画面质量合规性> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准2的得分:【1】
**(二)连续标准评分 (0.0-1.0)**:
1. 标准1 <元素融合自然度> 的评价:
<评价过程与第一轮类似,此处略......>
基于标准1的得分:【0.9】
5. **综合得分计算**:
计算过程:(1 + 1 + 0.9) / 3 = 0.9666...
连续项调整说明:[无调整]
综合得分:【0.97】
【综合得分】:(0.95+0.90+0.97)/3=0.94
# 参评模型
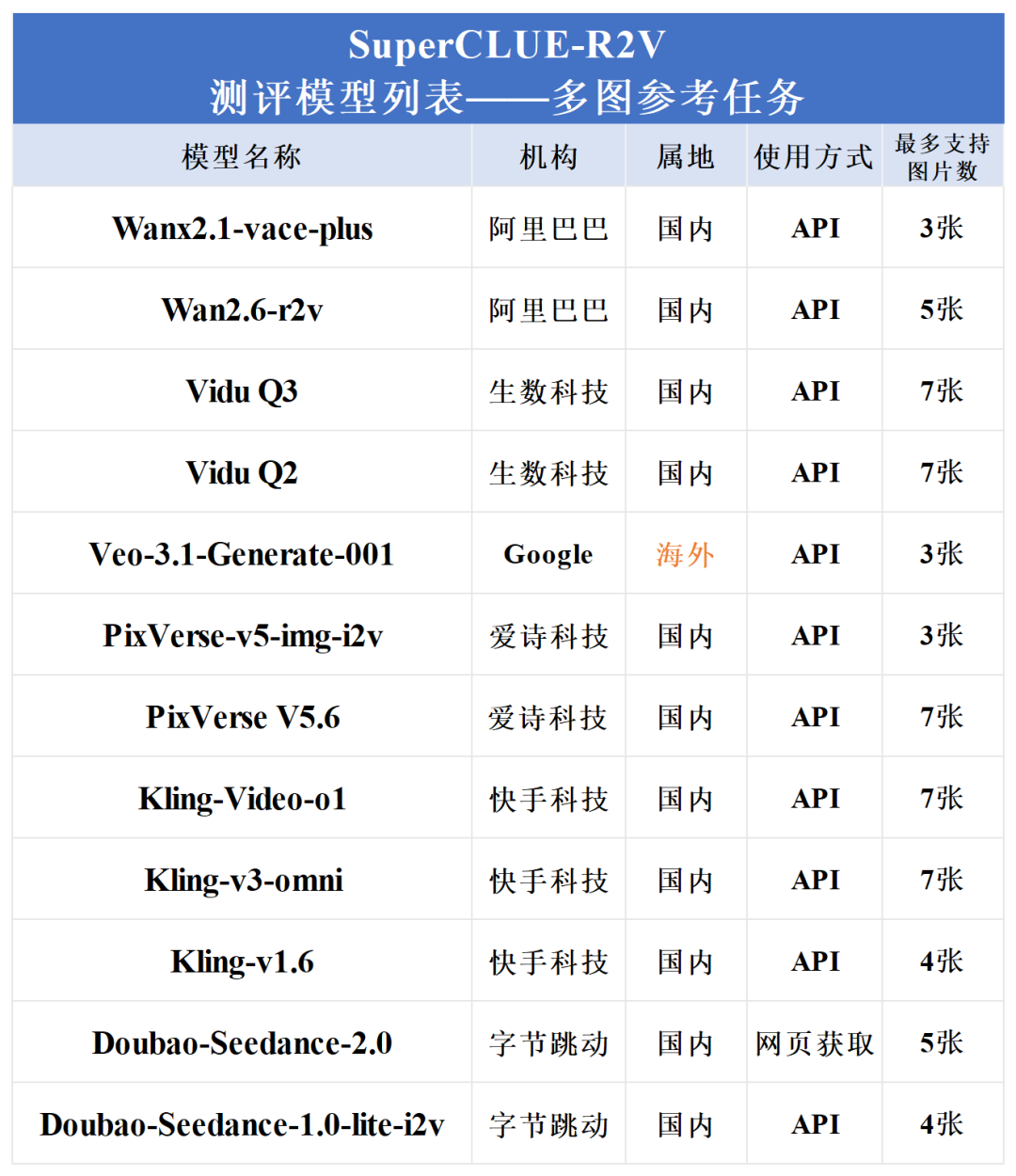
为综合衡量国内外参考生视频模型的发展水平,本次测评分别选取支持多图参考与单图参考任务的两类模型参与参评,具体名单如下:
一、多图参考任务
选取了代表性的1款海外模型和11款国内模型,共12款主流模型。
二、单图参考任务
新增只支持单图参考的模型,最终13款参测模型包括2款海外模型和11款国内模型。
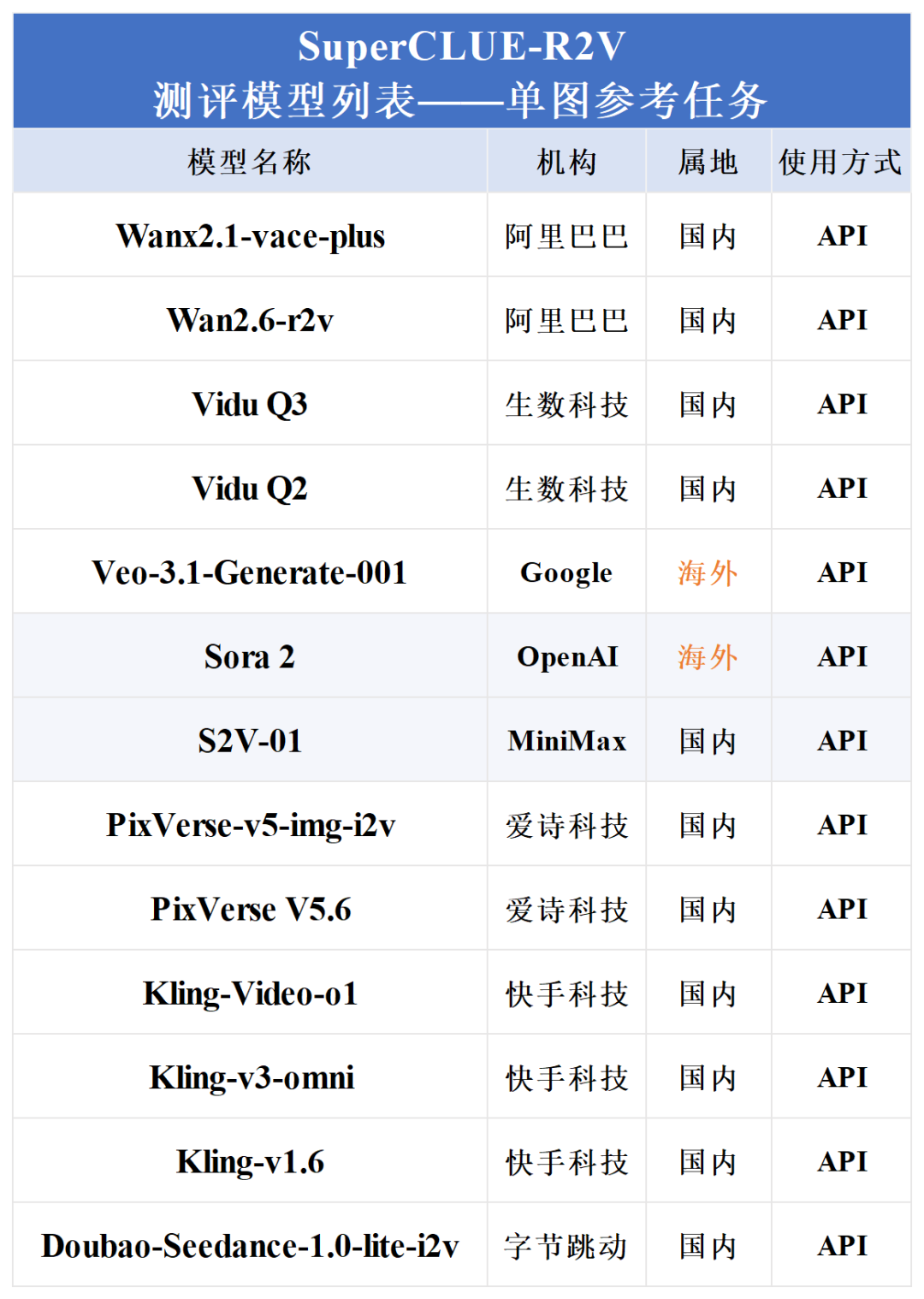
注:由于Doubao-Seedance-2.0不支持真人人像输入,故不参与单图的人物还原度榜单。
一、多图参考任务
总榜单

基础能力榜单
二、单图参考任务
总榜单
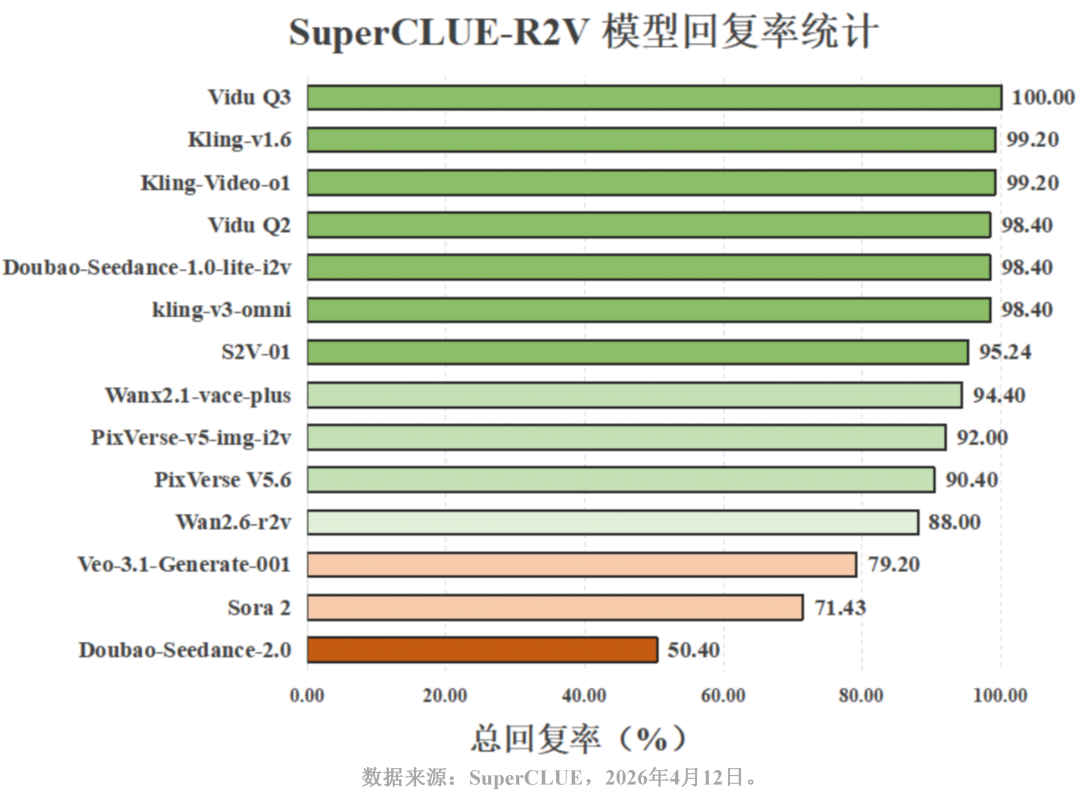
三、模型回复率统计
本次测评中,由于不同模型存在各自的规则约束与内容安全限制,模型有效回复率存在明显差异:
1. Vidu Q3表现最佳,回复率为100%,能适配多场景、多风格的视频生成要求;
2. Veo-3.1-Generate-Preview 因内容风控与生成限制,在部分题材下出现生成失败或无法输出的问题;
3. Doubao-Seedance-2.0 在动漫类、真人人像生成场景中,存在大部分内容不符合平台规范的情况,回复率仅为50.40%;
4. 其余模型几乎均存在因平台内容限制问题,部分题目无法生成的情况。
# 模型对比示例
# 示例1 基础能力—主体一致性
【提示词】在@图4阳光照射的房间内,展示@图1桌上摆放@图2花瓶和@图3书本由远及近的画面。

【各模型回答对比】
# 示例2 基础能力—动作表现性
【提示词】把@图1的素描画从@图2的画架上面取下来,平坦开放在画架下方的地面上。

【各模型回答对比】
# 重点模型分析
在本次测评中,生数科技的Vidu系列模型表现亮眼,最新迭代模型
提示词:@图2拿着@图1的杯子,在咖啡厅中制作一杯拿铁,展现拉花细节及过程。

各头部模型效果展示
1. 综合实力断层领先,实现对海外巨头的全面包抄
Vidu Q3在多图参考任务的各项核心指标上,实现对Veo-3.1-Generate-001的全覆盖超越。在基础能力的“主体一致性” (100 vs 76.67)、“场景一致性” (80.63 vs 72.30),还是在应用能力的“商业广告” (80.48 vs 76.76)、“影视创作” (76.12 vs 32.12)上,Vidu Q3都呈现出超强优势。
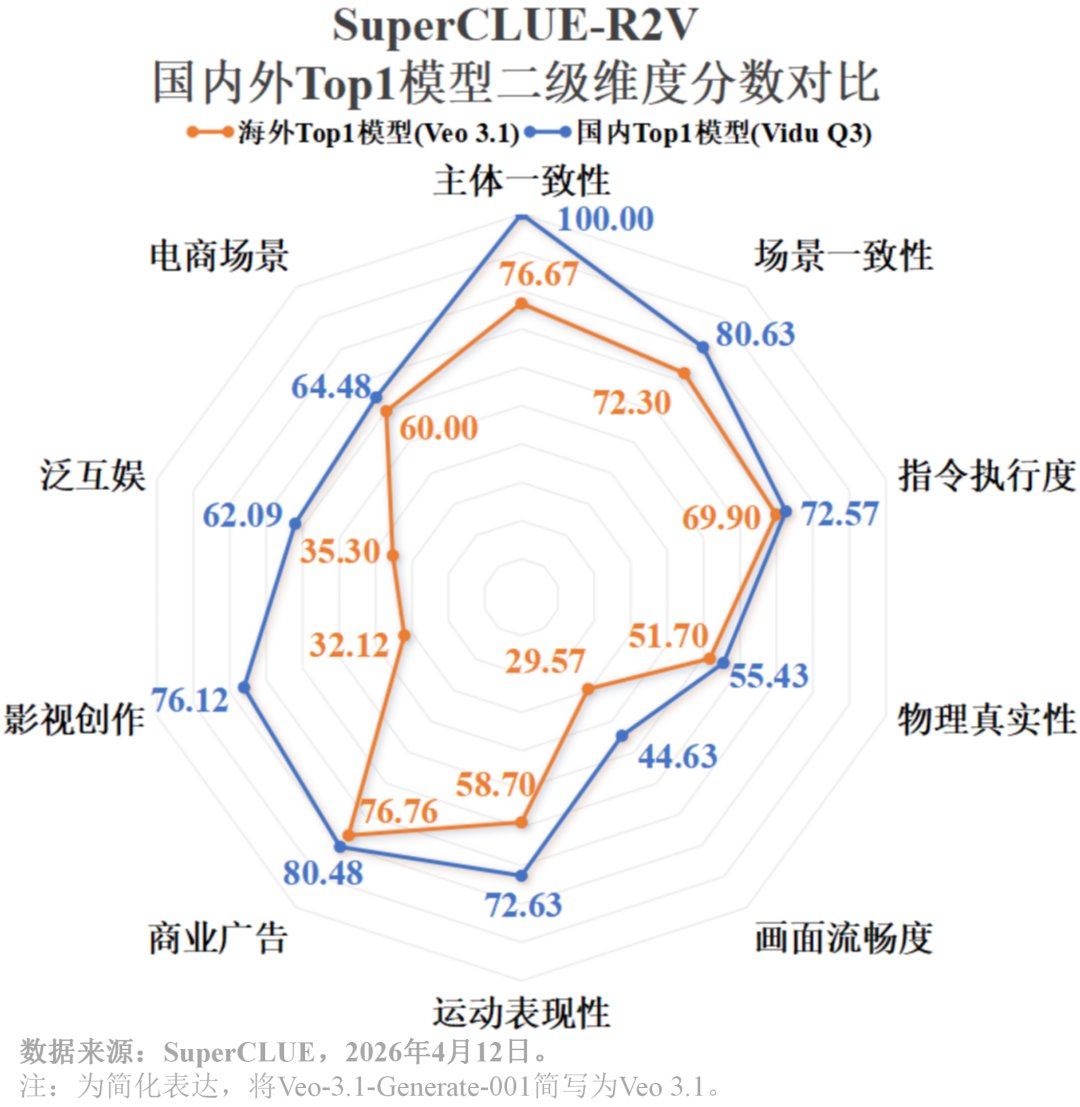
2. 卓越的单图/多图处理能力与人物还原技术
多图能力强劲,性能迭代迅速
上一代模型Vidu Q2已然以64.01分占据多图参考总榜第二,Vidu Q3在此基础上拔高了近7分 (总分70.89)。同时,Vidu Q3在基础能力(70.98)与应用能力(70.80)也同时保持霸榜领先的位置。
此外,Vidu Q3最大支持高达7张图片的参考输入。在输入元素繁杂的情况下,“主体一致性”保持100分的领先,表明其模型具备强劲的信息提取与组合能力。
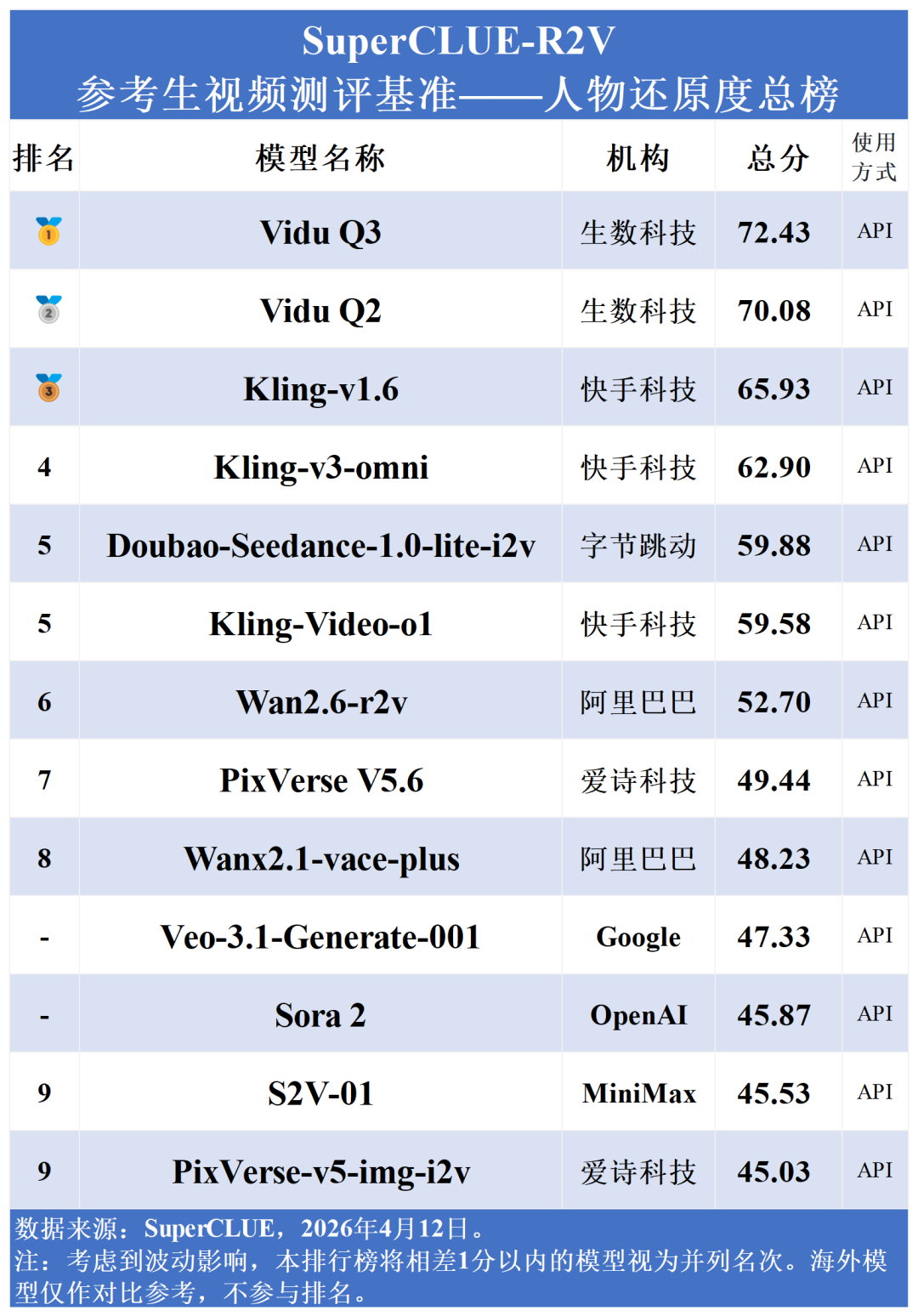
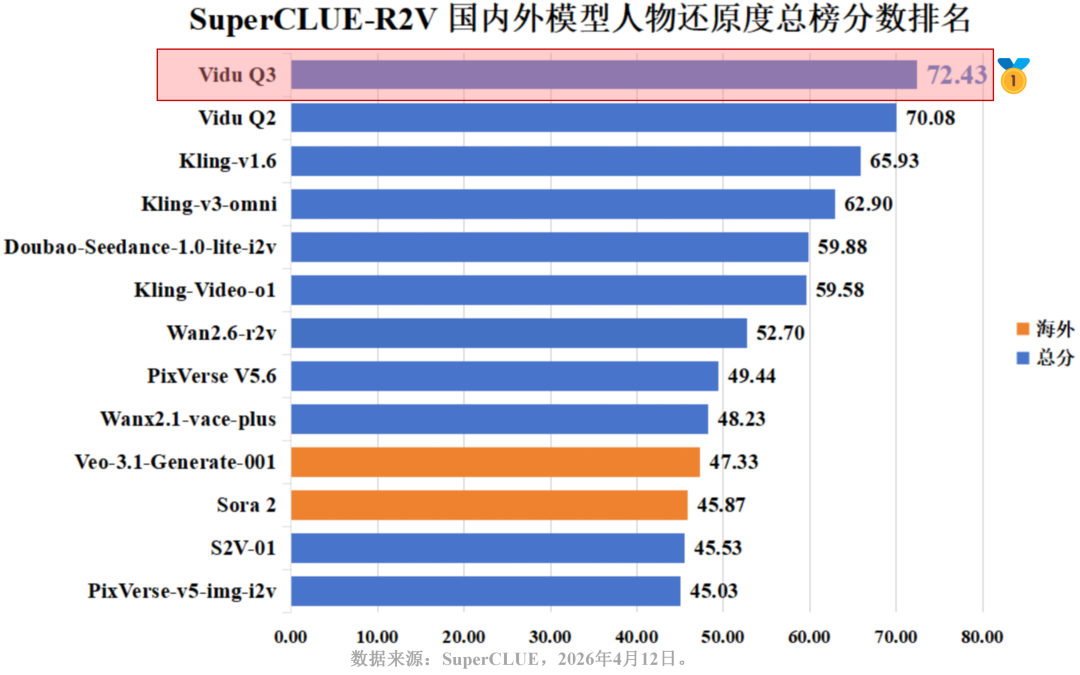
单图人物还原真实
在单图参考-人物还原度总榜上,Vidu Q3以72.43分遥遥领先。这表明其在人物面部特征、肢体细节等方面的还原能力领先,能精准复刻参考人物的核心元素,满足高保真还原的应用需求。
3. 场景泛化能力强,赋能千行百业
在应用能力榜单中,Vidu Q3在影视创作(76.12)、泛互娱(62.09)上保持领先,在电商场景(64.48)、商业广告(80.48)上表现不俗。说明其具备极强的场景适配性,能够匹配不同行业的应用需求。同时,在多场景、多维度的复杂测试环境中,Vidu Q3仍能保持100%的模型回复率,稳定性拉满,可满足主流应用的核心诉求。
提示词:以黑幕开场,参考@图2的粒子特效和材质,金色鎏金材质的沙砾从画面左边飘入并向右覆盖,逐渐形成@图1中的文字。音效:低沉的中国大鼓 + 空间混响的古筝泛音。磅礴、震撼,旁白:“历史的长河在此刻奔涌而出。”

各头部模型效果展示
# 总体测评分析及结论
一、多图参考任务
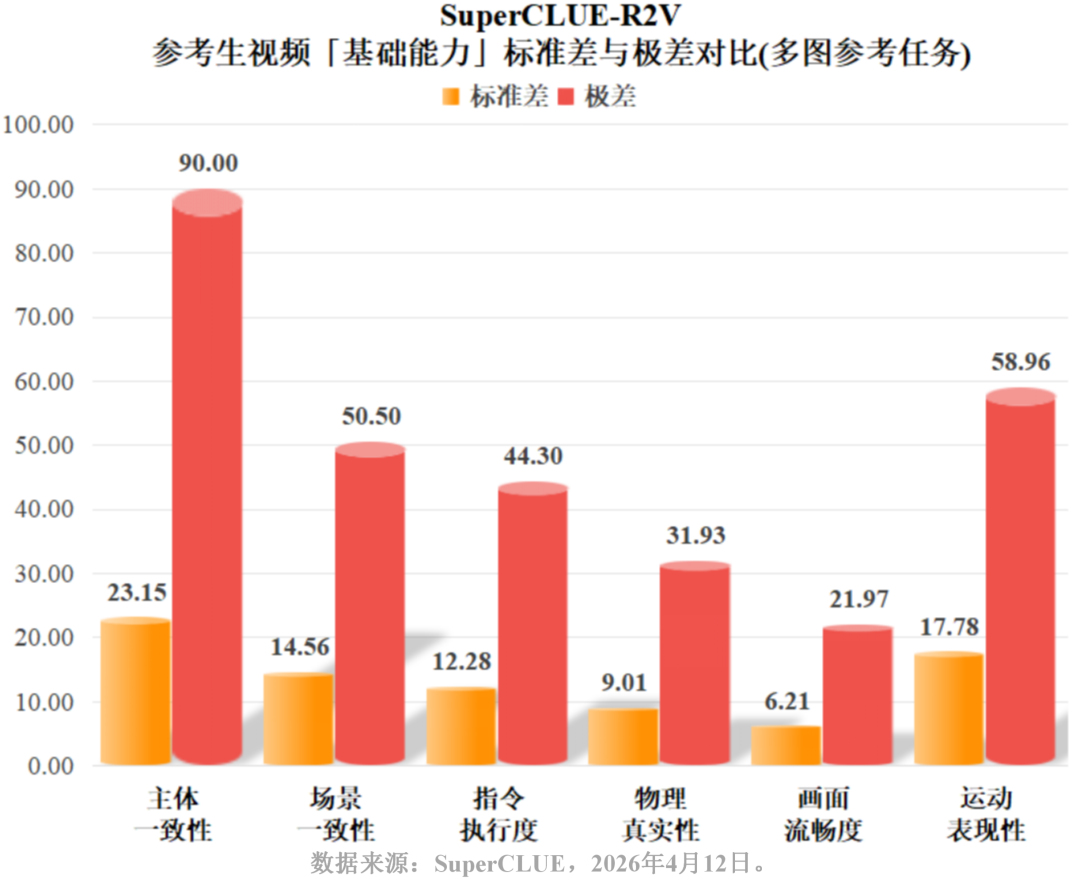
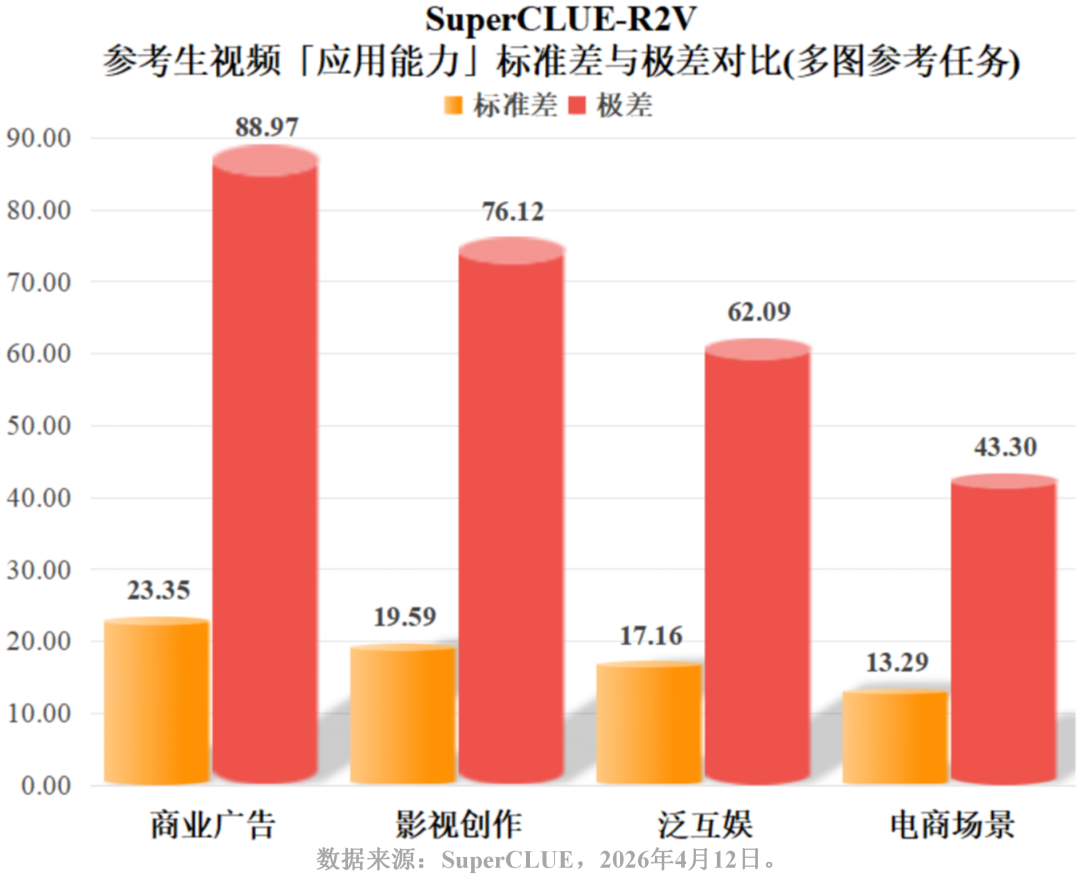
二、单图参考任务
在人物还原度总榜中,国内梯队包揽榜单前六名。其中,生数科技的Vidu系列表现尤为抢眼,Vidu Q3以72.43分强势登顶,其同门模型Vidu Q2也以70.08分位列第二;同时,Kling-v1.6 (65.93)与Kling-v3-omni (62.90)分列第三、第四。相比之下,Veo-3.1-Generate-001 (47.33)与OpenAI的Sora 2 (45.87)排名均处中下游。分数差距表明:在精准捕捉、解析并稳定还原特定人物面貌及物理特征上,国内头部模型已经实现了从算法到实际效果的全面反超。


扩展阅读
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark





