 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库美国ATOM报告:Qwen称霸武林,中国统治开源世界
“美国真正开源模型”计划(American Truly Open Models,简称ATOM)项目发布了一份报告。

ATOM旨在建立一个美国本土AI实验室,专注于开发可供开发者自由访问和修改的模型。
为实现目标,该计划要求获得强大的算力支持,包括多达一万个用于企业级AI开发的尖端GPU芯片。
这项计划于去年8月4日正式启动,获得包括开源平台Hugging Face首席执行官克Clément Delangue、英伟达应用研究总监Oleksii Kuchaiev、OpenAI首席战略官Jason Kwon等十余位行业领袖的联署支持。
这两年,开源AI模型已逐渐成为支撑整个科技行业的无形基石。
无论是忙于验证新想法的初创团队,还是需要处理海量数据的跨国机构,都在频繁下载和调用这些公开的模型权重。
ATOM的报告显示,2025年夏天,中国开源语言模型已全面超越美国同行,累积下载量和真实推理使用率双双拉开显著差距。
报告基于海量客观数据观察,呈现了一个正在剧烈重构的开源技术生态圈。
势力版图的交替
审视超过1500个主流开源语言模型的下载与使用数据,整个行业格局的演变轨迹非常清晰。
以美国、中国和欧洲三大核心技术发源地为观察切口,开源生态的重心经历了三次明显的转移。
ChatGPT发布后的早期阶段,欧洲凭借Mistral AI的系列模型占据绝对优势,其早期的7B和8x7B模型成为全行业争相研究的基础底座。
局势在2024年发生逆转,Meta推出Llama 3系列,凭借极高的可用性和丰富的尺寸分类,迅速将主导权夺回美国手中。美国在此期间贡献了全球一半以上的模型下载量和微调衍生模型。
时间来到2025年夏天,风向再次发生根本性转变。
DeepSeek、Qwen等系列推出新一代模型后,中国技术团队的使用量和影响力开始呈现爆发式增长。
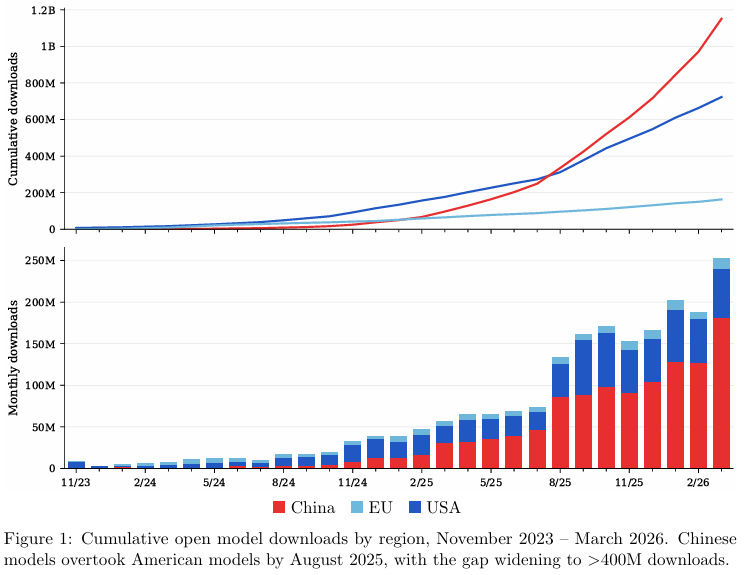
截至2026年3月,追踪的开源模型总下载量达到20.4亿次,相比上一年同期的3.39亿次暴增6倍。
在这场激增中,中国模型的增长曲线最为陡峭,年度同比增长高达11.9倍,总下载量从9700万跃升至11.5亿次。
美国模型体量虽然也在增长,同比增长4.1倍,但总计7.23亿次的体量已被赶超。
欧洲模型的总下载量则停留在1.63亿次,增速相对迟缓。
下载量只代表静态的获取,二次开发的热度更能体现一个模型的生命力。
开发者们在基础模型之上进行微调和适配,形成了庞大的衍生模型网络。
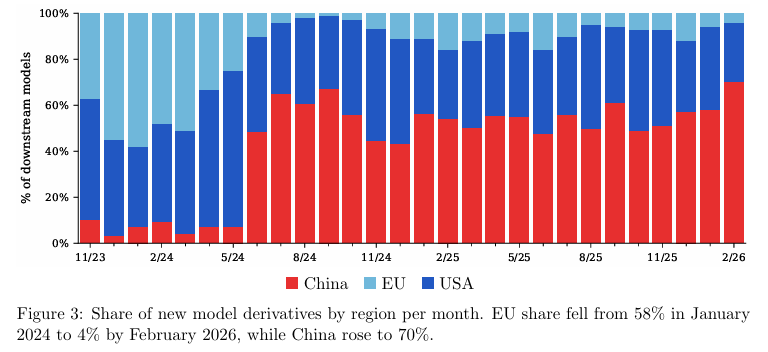
2023年11月,以中国模型为基础的衍生模型占比仅为10%,到2026年2月,这个数字飙升至70%。
欧洲模型的衍生占比则从最高峰的58%滑落至仅剩4%。
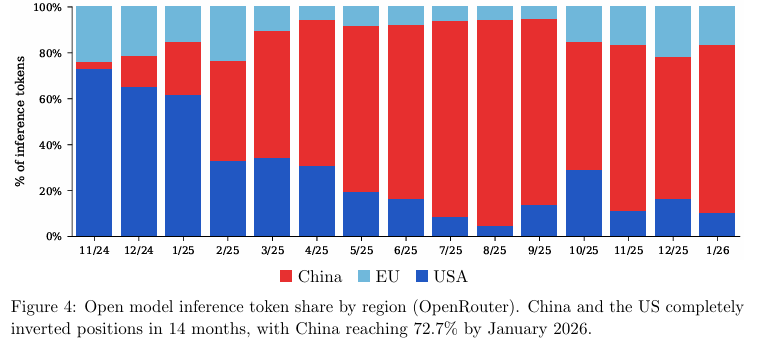
实际运算中的流量数据给出了同样的答案。
在OpenRouter的后台统计中,各家模型的被调用代币比例反映了开发者的真实偏好。
短短14个月内,中国模型的流量占比从微不足道的2.8%一路攀升,到2026年1月已超过70%,与美国模型完全互换了行业生态位。
基础能力的提升是驱动这次版图大迁移的核心动力。
综合Arena(竞技场评测平台)的人类盲测评分与Artificial Analysis(AI分析机构)的综合基准测试指数,中国头部开源模型的综合能力在2024年底实现了对美国头部模型的反超,并将领先优势保持至今。
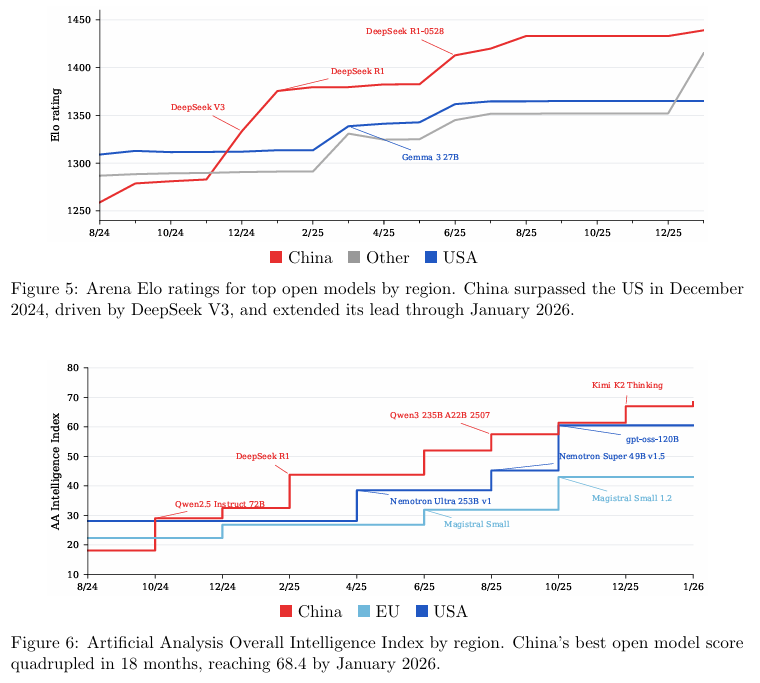
在高度透明的开源社区,微弱的性能优势常常能转化为巨大的市占率胜势,开发者总是会本能地向性能最强、成本最优的选择靠拢。
巨头们的起落
将目光从宏观区域聚焦到具体的模型家族,各家科技巨头的兴衰更替更为具体。
整个开源生态正呈现出极度集中的头部效应,几家明星企业吸纳了绝大部分的注意力。
在这场角逐中,阿里巴巴的Qwen系列是当之无愧的绝对王者。
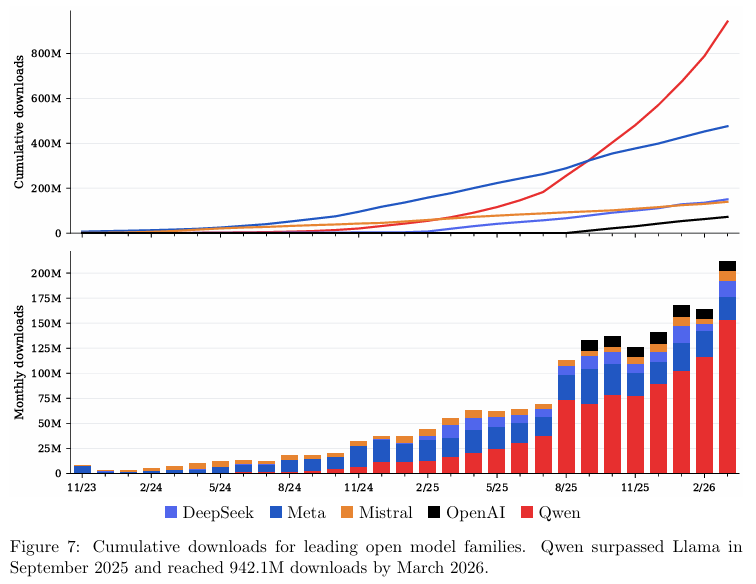
2025年9月,Qwen的总下载量达到3.25亿次,正式超越Meta的Llama系列。
半年后的2026年3月,Qwen的累计下载量冲上9.42亿次,几乎是Llama系列4.76亿次的两倍。
在衍生开发领域,Qwen更是确立了垄断级的地位。
从2024年6月开始,它取代Llama成为全球开发者首选的微调基座,其在新增衍生模型中的份额一路高歌猛进,到2026年2月达到69%。
相比之下,Meta在该领域的份额曾一度触及44%的高点,随后不断流失,跌至11%。
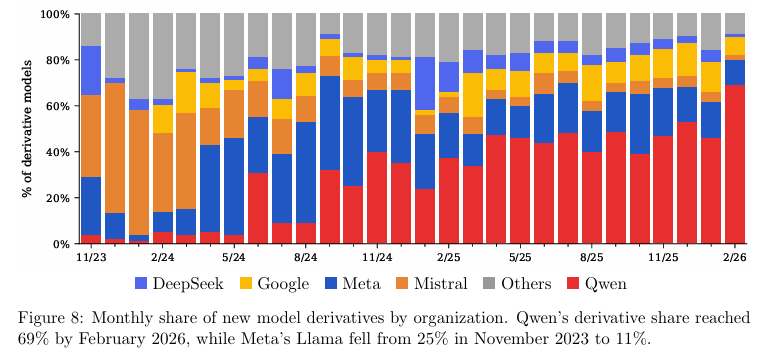
Qwen能取得如此庞大的体量,归功于其极其全面且高密度的模型发布策略。
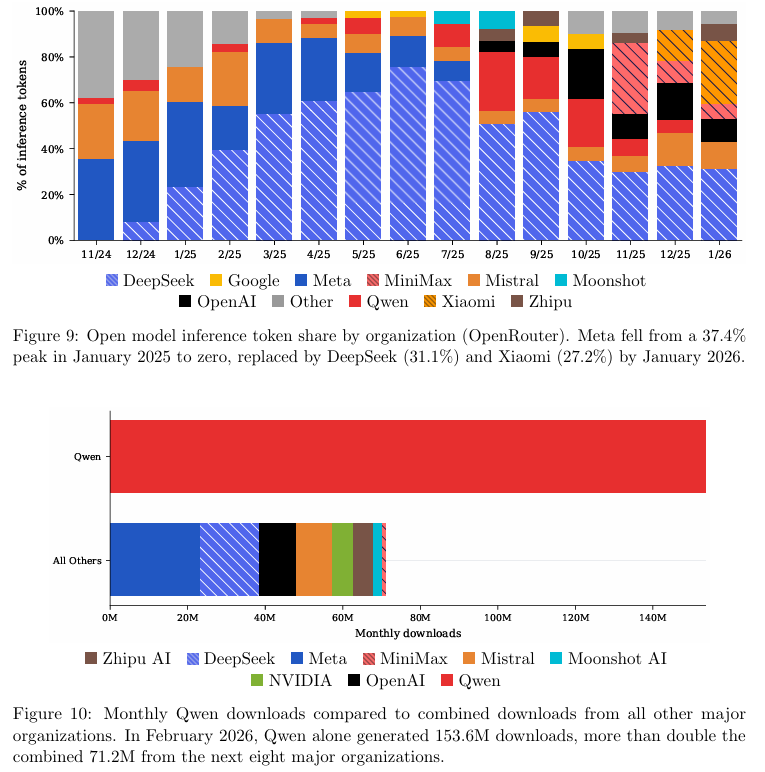
仅在2026年2月单月,Qwen系列就产生了1.536亿次下载,比紧随其后的8家主流机构下载量总和还要多出一倍。
这种体量优势很大程度上由小尺寸模型驱动。Qwen3系列中仅仅6款10亿到80亿参数的小模型,单月下载量就达到3290万次,相当于6家竞争对手全部模型的下载量总和。
DeepSeek走出了一条完全不同的成功路径。它将全部精力投入到超大参数的混合专家模型研发中。
在2500亿参数以上的巨型开源模型领域,DeepSeek占据了47%的历史下载量份额,是目前唯一能在细分赛道压制Qwen的厂商。
它的影响力在实际推理环节展现得淋漓尽致,仅凭极少数几款旗舰模型,DeepSeek在2025年6月一度吃下了全网75.6%的推理流量,直到2026年1月依然维持在31.1%的高位。
早期的开路先锋Mistral如今显得有些力不从心。
虽然它在2023年底曾占据过57%的衍生模型份额,但后续乏力,历史累计下载量在2026年1月被DeepSeek以1.28亿次反超。
Meta的Llama系列同样面临瓶颈,在推出Llama 4之后,其在推理平台的市占率从37.4%的高点迅速崩塌,到2025年8月甚至一度归零,空出的流量被源源不断的中国模型迅速瓜分。
新生力量的追赶
除了牢牢占据舞台中心的几家头部机构,开源生态中正涌现出一批不容忽视的新生力量。他们目前的市占率或许只是巨头们的零头,但高速攀升的曲线揭示了惊人的潜力。
面对2025年夏天中国模型掀起的技术浪潮,美国科技企业迅速组织反击。
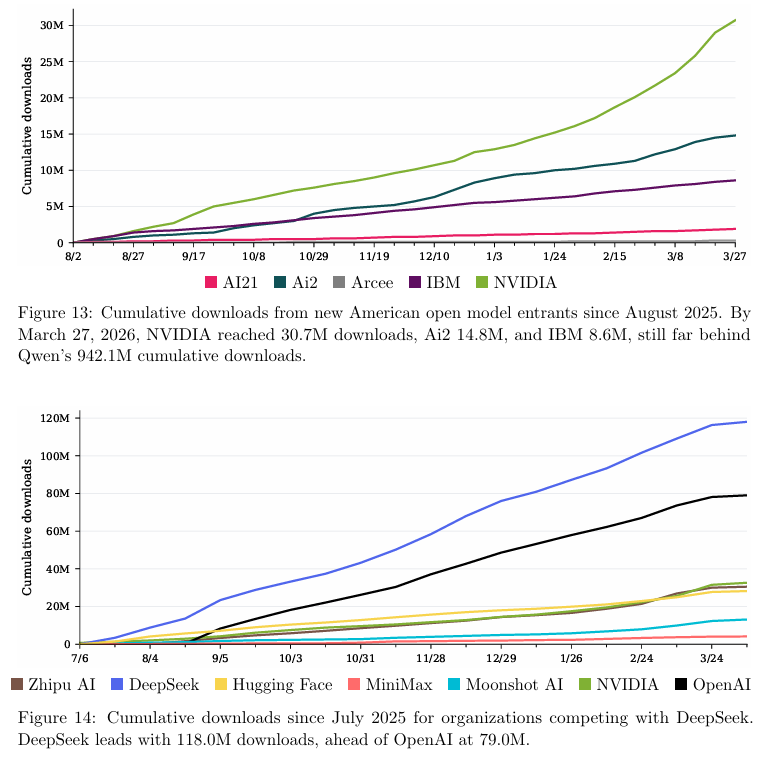
Nvidia凭借Nemotron系列模型,在短期内斩获3070万次累计下载,成为新一代美国开源阵营的领跑者。
Ai2(艾伦AI研究所)的OLMo系列也拿下了1480万次下载,IBM的Granite系列取得860万次。
这些新秀合并拥有约5600万次下载,虽然距离Qwen近十亿的体量仍有天壤之别,但稳定的增长轨迹证明了他们依然留在牌桌上。
最值得关注的新变数来自OpenAI。
这家长期坚持闭源路线的巨头在2025年9月突然杀入开源赛道,发布了GPT-OSS系列。
凭借深厚的技术积累与品牌号召力,OpenAI仅靠屈指可数的几款开源模型,在几个月内的月度下载量就超越了Mistral多年积累的全部历史模型家族,总下载量迅速攀升至7900万次。
推理平台的流量分布往往能捕捉到比下载榜单更敏锐的生态异动。
Xiaomi在2025年底发布了具有3090亿参数的MiMo-V2-Flash模型,在没有任何前期预热和庞大代码托管下载量支撑的情况下,这款模型在极短时间内直接抢占了27.2%的真实推理代币份额。
极高的性价比与优秀的推理表现,让优秀模型绕过传统分发渠道直接触达终端用户的路径成为可能。
衡量热度的新尺子
单纯计算总下载量存在局限性。
一个只有15亿参数的小型模型,因为运行成本极低,常常被嵌入各种自动化测试和流水线中,其下载量动辄是一个4000亿参数超大模型的几十倍。
为了更公允地评价不同体量模型的真实受欢迎程度,引入了相对采用率指标。
将所有模型按参数规模划分为七个区间,分别提取每个区间内历史下载量最高的十款模型作为标杆。
当一款新模型发布后,在其发布后的第7天、14天直到一周年等固定节点,将其下载量与同等规模标杆模型在该节点的下载量中位数进行比对。
如果得分为1.0倍,证明其热度符合头部模型的平均水准,分数越高则表明该模型获得了远超预期的破圈级关注。
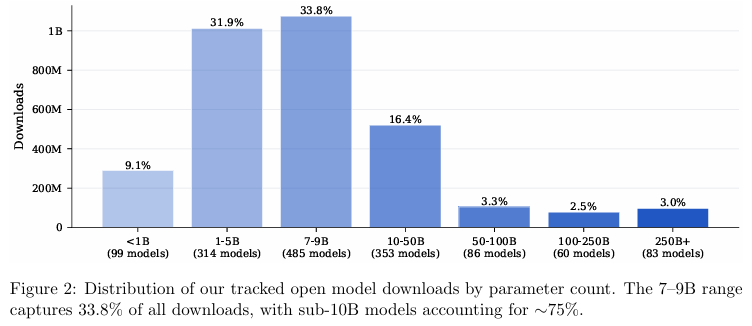
数据分布显示,70亿到90亿参数是当前业界最黄金的尺寸,吃下了全网33.8%的下载份额,而百亿参数以下的轻量级模型总共包揽了75%的流量。
在这样极高的基数下,想要在小尺寸赛道跑出高分非常困难。
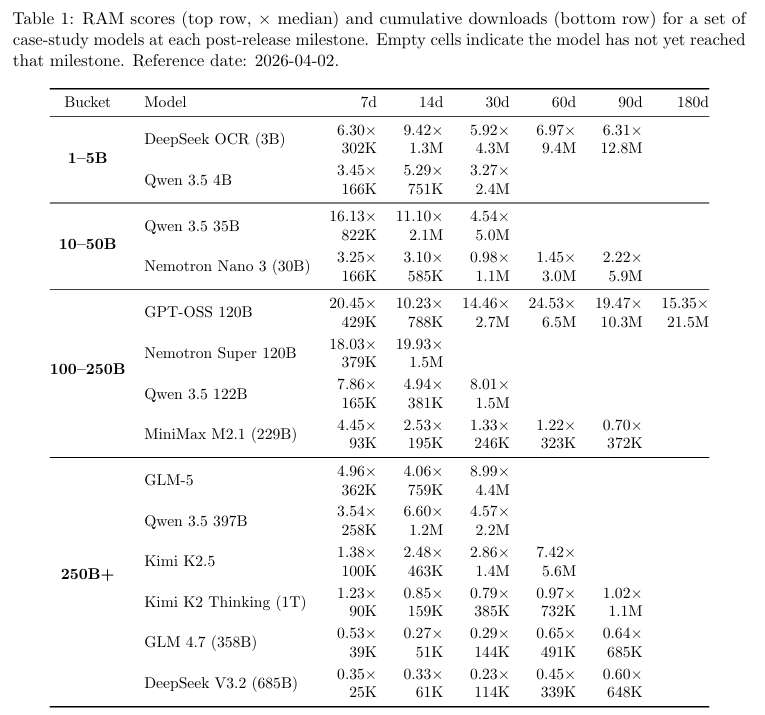
Qwen 3.5的4B参数模型在发布14天后,拿到了5.29倍的高分,表现已属惊艳,但DeepSeek发布的OCR专属3B模型更是爆发出惊人的热度,上线14天冲到了9.42倍。
中大尺寸赛道则见证了多款现象级产品的诞生。在1000亿到2500亿参数区间,OpenAI的GPT-OSS 120B创下了不可思议的首发成绩,上线7天便达到同级别基准的20.45倍,并在半年后依然维持着15.35倍的恐怖热度。
同区间的Nvidia Nemotron Super 120B不甘示弱,前两周分别拿到了18.03倍和19.93倍的成绩。
相比之下,MiniMax的M2.1模型虽然首周拿到了4.45倍的不错开局,但在三个月后热度迅速衰减至0.7倍,滑落至标杆线以下。
在2500亿参数以上的巨型模型深水区,GLM-5展现出强大的号召力,首月稳定在标杆线近9倍的位置。
这份报告使用数据均来自HuggingFace下载量趋势,但其实中国还有ModelScope。
参考资料:
https://atomproject.ai/atom_report.pdf
https://atomproject.ai/
END
点击图片立即报名👇️










