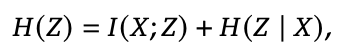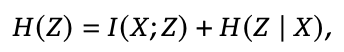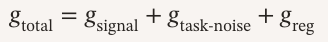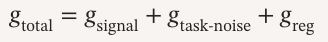最近的 AI 研究圈有一个明显的风向变化。大家不再满足于“让大模型说得对”,而是开始追问“让大模型想得对”。尤其是当 LLM 被塞进多轮交互的Agent 框架里,模型不再是一次性输出答案,而是要像人一样观察、思考、行动、再思考。这个过程一旦进入强化学习(RL)阶段,训练就变成了一场“推理质量的持久战”。李飞飞团队最近在做的,就是把这场持久战里最隐蔽、最危险的问题挖了出来。01 为什么RAGEN‑2值得被重写一遍
过去几年,Agent 训练的稳定性几乎完全依赖两个指标:奖励(reward)和熵(entropy)。奖励代表结果好不好,熵代表推理过程是不是多样。大家默认这两个指标稳定,就意味着模型训练健康。研究团队告诉我们:熵其实是一个非常迷惑人的幻觉。模型的推理过程可以在“熵看起来很正常”的情况下,悄悄地、系统性地崩溃。你看到的是模型在认真“思考”,但它实际上已经不再听输入了,只是在重复一套固定模板。这就是 RAGEN‑2 提出的核心问题:推理崩溃(Reasoning Collapse)。为了抓住这种隐蔽的崩溃,研究团队提出了两个关键工具。一个是互信息代理(MI Proxy),用来判断模型的推理是否真的依赖输入。另一个是信噪比理论(SNR View),用来解释为什么 RL 会把模型推向“模板化推理”。这个项目的团队阵容也非常豪华。核心来自 Northwestern University,联合了斯坦福(李飞飞、Yejin Choi、Jiajun Wu)、Microsoft、Oxford、Imperial、UIUC等机构。项目主页在这里,可以看到完整资料与代码:https://ragen-ai.github.io/v2/02 推理崩溃是什么?为什么以前没人发现?
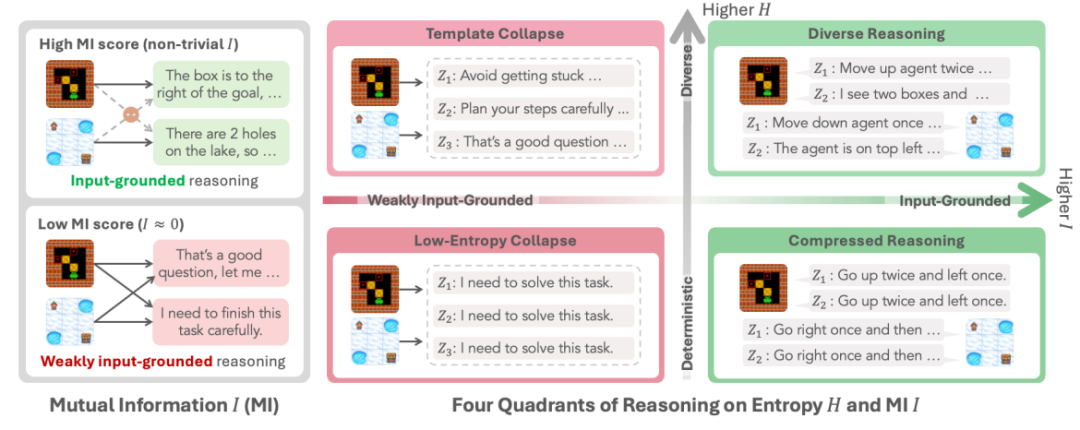
推理崩溃这个词听起来有点抽象,但它其实描述的是一种非常直观的现象:模型看起来在认真思考,但它的思考内容和输入毫无关系。就像你问一个人“今天上海天气怎么样”,对方却每次都回答“让我一步一步想清楚这个任务”。你会觉得他在思考,但其实他根本没在听你说什么。RAGEN‑2 就是把这种“假思考”现象系统性地揭露出来。熵 H(Z|X) 这个指标,只能看到“同一个输入内部,模型的推理是不是多样”。如果模型在同一个输入下生成了很多不同的推理链,熵就会很高。问题是,熵完全不知道这些推理链是不是真的和输入有关。这就导致一个非常危险的情况: 模型的熵看起来很健康,但它的推理已经完全脱离输入,进入一种“模板化自言自语”的状态。熵只是右边的第二项。真正衡量“推理是否依赖输入”的,是互信息I(X;Z)。也就是说,熵高不代表推理好,甚至可能掩盖推理正在崩溃。RAGEN‑2 把这种现象命名为“模板崩溃(Template Collapse)”。它的特征非常鲜明,推理链条看起来很丰富 但不同输入之间几乎一模一样 模型像是背了一套“万能推理模板”,无论你问什么,它都先来一句:“Let me think step by step…”或者“I need to solve this task carefully.”这不是偶然,而是多轮 Agent RL 的系统性失败模式。当熵高、互信息也高时,模型的推理既多样又依赖输入,这是理想状态。当熵高、互信息低时,就是模板崩溃。模型看起来在思考,但其实在“背稿子”。当熵低、互信息高时,模型推理很依赖输入,但过于确定,像是死记硬背。当熵低、互信息也低时,就是完全退化,模型既不多样也不听输入。这四种状态里,最危险的就是模板崩溃,因为它最容易被熵“伪装”成健康状态。图1|左:输入驱动推理适应当前状态;模板推理在不同的输入中产生几乎相同的响应。右:四种推理机制,沿两个轴进行描述:条件熵𝐻(𝑍 | 𝑋) (在输入多样性范围内)和相互信息𝐼(𝑋; 𝑍) (输入依赖性)。03 RAGEN‑2:互信息视角重构推理质量
如果说 RAGEN‑2 的第一重贡献是“发现问题”,那么第二重贡献就是“重新定义什么叫推理质量”。过去我们太依赖熵了,觉得推理多样就代表模型在认真思考。但 RAGEN‑2 告诉我们,推理多样不等于推理有效,甚至可能是推理正在崩溃的假象。这一点在研究中被用一个非常经典的信息论公式点破了:这行公式的意义非常直白。 左边是推理的总熵,右边分成两部分。H(Z|X) 代表“同一个输入内部的多样性” I(X;Z) 代表“推理是否真的依赖输入”,过去大家只看H(Z|X),也就是“推理是不是多样”。 但真正重要的是 I(X;Z),也就是“推理是不是听输入的”。这就像你看一个学生写作文,写得花里胡哨不代表他理解题目。 MI 才是判断他有没有读懂题目的关键。RAGEN‑2 的贡献,就是把 MI 从理论里拉出来,变成一个可以在训练中实时监控的指标。互信息本身很难直接算,因为推理链是高维离散序列。 RAGEN‑2 的聪明之处在于,它没有硬算 MI,而是设计了一套“互信息代理指标”,用训练过程中的数据就能估出来。核心方法叫 In‑Batch Cross‑Scoring。简单说,就是把每条推理链 Zᵢ,k拿去和所有输入 Xⱼ做一次“匹配度评分”,看看它到底更像是从哪个输入生成的。如果推理真的依赖输入,那么 Zᵢ,k在自己的输入 Xᵢ上得分最高。 如果推理已经模板化,那么它在所有输入上得分都差不多。研究团队把这个评分拆成两个量:matched:推理在真实输入上的 log‑prob ;marginal:推理在所有输入混合上的 log‑prob。Retrieval‑Accuracy 看推理链能不能“认回自己的输入”。 如果模型崩溃,这个准确率会掉到随机水平。MI‑ZScore‑EMA 把 matched − marginal 做成连续指标,再加上 z‑score 和 EMA 平滑。 更稳定,也更适合训练监控。最关键的是,这些指标不需要额外模型,不需要额外推理,训练过程本身就能算出来。这让 MI 从一个“理论概念”变成了一个“工程可用的监控信号”。MI 和最终任务成功率的相关性非常高。 熵和任务成功率的相关性不仅低,甚至是负的。换句话说,熵越高,任务可能越差。 这就像你看到一个人说话越来越流利,但内容越来越离谱。这说明熵不仅不可靠,还可能误导训练判断。 而 MI 才是那个真正能告诉你“模型有没有在认真思考”的指标。RAGEN‑2 在这里做的事情,本质上是把“推理质量”从一个模糊概念,变成了一个可量化、可监控、可优化的指标体系。04 推理崩溃的根因:SNR(信噪比)机制
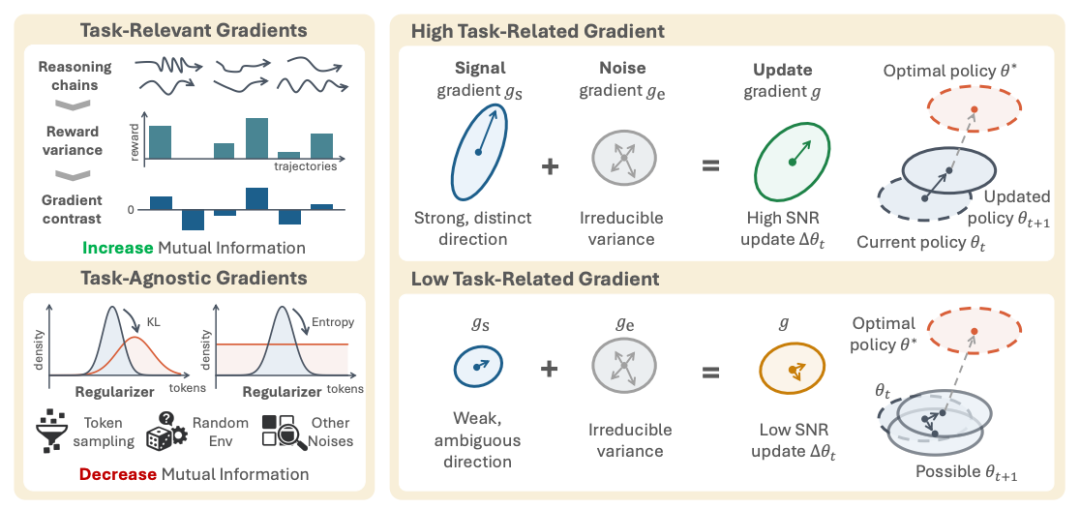
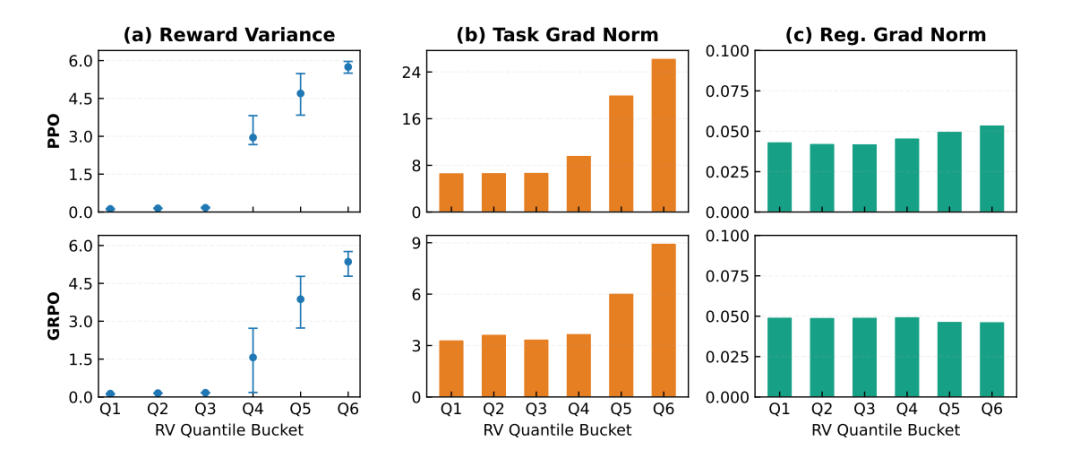
如果说 MI Proxy 是“诊断工具”,那么 SNR 理论就是“病因分析”。 RAGEN‑2 的第三个重大贡献,就是解释了为什么 RL 会让模型推理崩溃。图2|RL更新的信噪比(SNR)示意图。左:总梯度分解为任务梯度(随着输入奖励方差的增加而锐化)和正则化梯度。正确的高奖励方差产生强任务梯度和更好的收敛性(高信噪比);低奖励方差使正则化梯度占主导地位,产生不稳定的更新和输入无关的推理(低信噪比)。当一个输入的奖励方差高时,模型能从不同轨迹里学到有用的信号,任务梯度强,推理自然会依赖输入。当奖励方差低时,模型几乎学不到什么有用差异,任务梯度弱,正则项(KL + 熵)就会成为主导力量。高奖励方差 → 强任务信号 → 推理依赖输入 低奖励方差 → 任务信号弱 → 正则项主导 → 推理模板化。梯度分解:任务信号 vs 任务噪声 vs 正则噪声gsignal 是真正有用的任务信号, gtask-noise 是采样噪声, greg 是 KL 和熵正则项。当奖励方差低时,gsignal 会趋近于 0。 但greg 完全不会变小,它是输入无关的“统一收缩力”。于是 greg 就成了主导力量,把推理往“输入无关的模板”方向拉。这就是为什么模型会出现“看起来在思考,但其实在背模板”的现象。图3|提示分为六个大小相等的奖励方差桶Q1-Q6。我们发现:(a)任务梯度范数随桶RV单调增加;(b)当RV接近0时,尽管几乎没有携带有用信号,但任务梯度仍然存在;(c)正则化器梯度范数(KL+熵)在桶内是平坦的。这直接支持两种算法下的信噪比机制。最危险的地方在于,即使奖励方差接近 0,梯度范数仍然不为 0。这意味着模型会持续更新,但更新方向完全与任务无关。 推理就会越来越偏离输入,越来越模板化。这就是推理崩溃的根本原因,也是为什么熵会误导训练判断。05 解决方案:SNR‑Aware Filtering
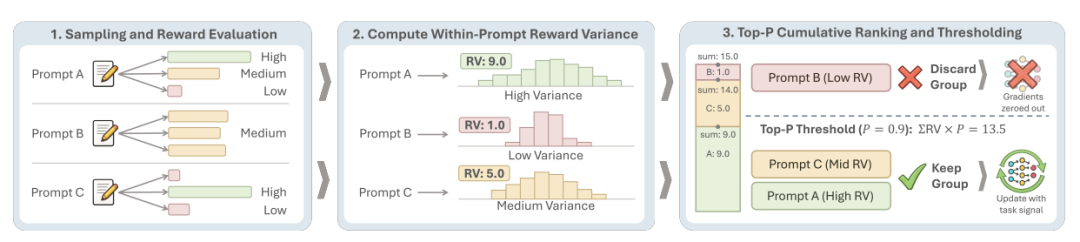
当 RAGEN‑2 把“推理崩溃”这个隐蔽问题挖出来之后,接下来最关键的问题就是怎么解决。研究团队给出的答案非常工程化,它没有引入复杂的新模型,也没有修改 RL 的核心结构,而是提出了一个轻量级、几乎零成本的策略——SNR‑Aware Filtering。图4|信噪比感知滤波工作流程。在每次训练迭代中:(1)滚动生成收集轨迹;(2)将即时奖励内方差作为信噪比代理计算;(3)提示按RV排名,保留top-p分数,仅对高信号子集执行策略更新。这种过滤循环可以防止对嘈杂的展开进行更新,并且不需要标准RL之外的额外模型/展开。这个方法的核心思想其实很朴素。既然推理崩溃的根因是“低奖励方差导致任务信号弱、正则项主导更新”,那就让模型尽量只从“高奖励方差”的样本里学习。每次训练都只保留那些真正能提供任务信号的 prompts,把那些奖励方差几乎为零、只会带来正则噪声的 prompts 过滤掉。这就像你在嘈杂的房间里想听清一个人的讲话,你会靠近那个声音更清晰的人,而不是让所有噪声一起灌进耳朵。SNR‑Aware Filtering 做的,就是让模型“靠近信号,远离噪声”。训练时的每一批数据里,都会包含一些“高方差、高信号”的 prompts,也会包含一些“低方差、低信号”的 prompts。后者的问题在于,它们的奖励几乎没有差异,导致任务梯度几乎为零,但正则项仍然在强推,于是模型就被往“模板化推理”方向拉。SNR‑Aware Filtering 的做法,就是每次训练只保留奖励方差最高的 top‑p prompts,把低方差的 prompts 全部过滤掉。过滤掉噪声,保留信号,推理结构自然就能保持输入依赖。研究团队图 4 把整个流程画得非常清楚,但我们可以用更大白话的方式讲一遍。训练开始时,模型会像往常一样采样多条轨迹。 每个 prompt 都会得到一组奖励值。 然后计算每个 prompt 的奖励方差。 把所有 prompts 按方差从高到低排序。 保留 top‑p 的那一部分,其余全部丢弃。 最后只用这些“高信号 prompts”来更新模型参数。整个过程不需要额外模型,不需要额外推理,不需要额外算力。 只是把训练数据做了一次“按信号强度排序的筛选”。SNR‑Aware Filtering 的有效性来自一个非常直观的数学事实。当奖励方差低时,gsignal 会趋近于 0。 但greg 完全不会变小,它是输入无关的“统一收缩力”。 于是 greg 就成了主导力量,把推理往“输入无关的模板”方向拉。SNR‑Aware Filtering 的作用,就是把那些 gsignal ≈ 0 的 prompts 全部过滤掉,让模型只在 g_signal 足够强的样本上更新。梯度 SNR 被显著提升 任务信号被保留下来 正则噪声被抑制最终的结果,就是模型的推理重新变得“听输入的”,互信息 MI 上升,模板化推理被抑制。这是一种非常“工程友好”的解决方案,不需要改模型、不需要改算法,只需要改训练数据的选择方式。06 实验:跨任务、跨算法、跨规模的验证
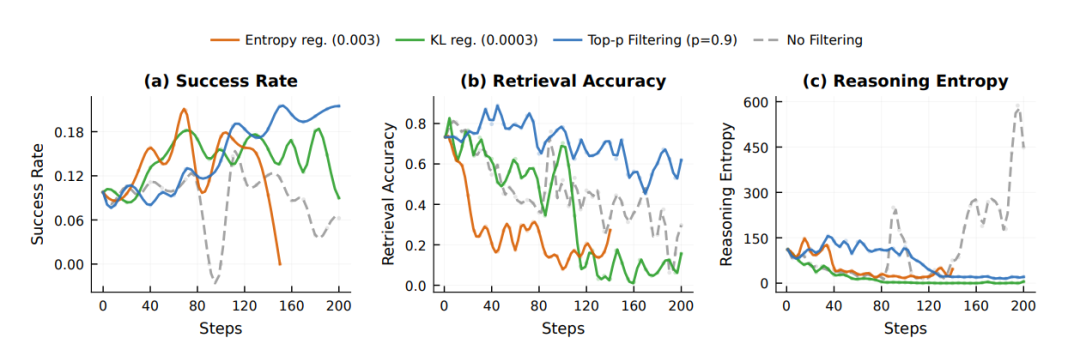
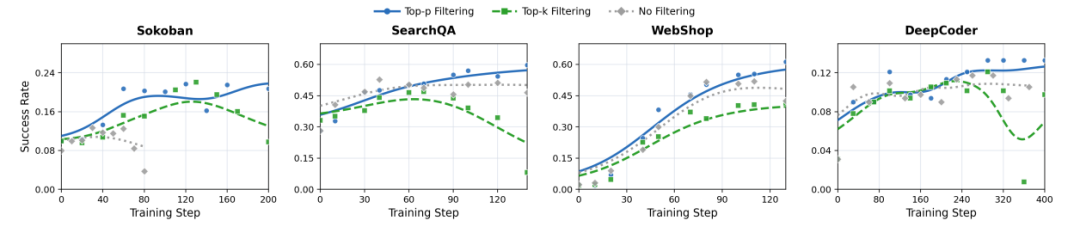
RAGEN‑2 的实验部分非常扎实,覆盖了七大环境、四类 RL 算法、多个模型规模。它不是在一个小玩具任务上证明自己的方法有效,而是在一整套真实的、多模态、多轮、多决策环境里验证推理崩溃的普遍性和 SNR Filtering 的有效性。图5 |不同干预策略下的训练动态。(a)任务成功率,(b)MI代理(检索准确性),以及(c)推理熵。如果不进行过滤,MI会在熵峰值时早期降解,信号模板会崩溃。滤波有效地缓解了检索准确性的下降,top-p SNR Aware滤波最好地保留了任务性能和推理多样性。研究团队选取的七个环境非常有代表性,几乎覆盖了当前 Agent 研究的所有关键场景。Sokoban 是不可逆规划任务,考验模型的长期推理能力 FrozenLake 是随机导航任务,考验模型在不确定环境下的策略稳定性MetaMathQA 是数学推理任务,考验模型的符号推理能力 Countdown 是算式构造任务,考验模型的组合推理能力 SearchQA 是多轮检索任务,考验模型的信息整合能力 WebShop 是网页导航任务,考验模型的工具使用与决策能力 DeepCoder 是代码合成任务,考验模型的程序推理能力这些任务的共同点是都需要模型在多轮交互中保持稳定、输入依赖的推理结构。RAGEN‑2 的实验显示,推理崩溃在这些任务中普遍存在,而 SNR Filtering 在这些任务中普遍有效。互信息 MI 的下降早于性能下降,是更敏感的诊断指标,熵在崩溃过程中保持高位,完全无法反映问题,SNR Filtering 显著提升 MI 与任务成功率。这说明 MI Proxy 不只是一个“好看的指标”,而是真正能提前预警推理崩溃的信号。而 SNR Filtering 则是一个真正能阻止崩溃、恢复推理质量的解决方案。研究团队还在 PPO、GRPO、DAPO、Dr.GRPO 四种 RL 算法上验证了推理崩溃的普遍性。推理崩溃是算法无关的系统性问题,SNR Filtering 是普适解决方案。这意味着推理崩溃不是某个算法的 bug,而是多轮 Agent RL 的结构性风险。而 SNR Filtering 则是一个结构性修复。图6 |显示顶部的过滤策略比较-𝑝持续超越Top-𝑘并且在四个环境中没有过滤器基线。07 Agentic RL的新范式
RAGEN‑2 的意义远不止提出一个新指标或一个新技巧。它实际上重塑了我们理解 Agent 推理质量的方式,也重塑了我们训练 Agent 的范式。RAGEN‑2 把推理质量的衡量从“熵”转向“互信息”。 把 RL 训练稳定性的理解从“奖励”转向“SNR”。 把推理崩溃从一个模糊现象变成一个可解释、可诊断、可干预的机制。这为未来的 Agentic RL 提供了一个新的理论框架。MI Proxy 可以直接集成到现有的 RLHF、GRPO、PPO 训练管线里。 SNR Filtering 是一个轻量级、几乎零成本的增强方法。 对多模态 Agent、工具使用 Agent、Web Agent 都有价值。这意味着 RAGEN‑2 的方法不是“只能在研究团队里跑”,而是可以直接落地到真实系统里。Agent 时代的核心问题不是“模型能力”,而是“推理稳定性”。 RAGEN‑2 提供了稳定性评估与训练的新标准。 对 AI Agent 的产品化具有直接影响。未来的 Agent 系统,不再只是比谁能调用更多工具、执行更多步骤,而是比谁能在多轮推理中保持稳定、可靠、输入依赖的思考结构。RAGEN‑2 给了我们一套方法,让这种稳定性变得可控。(END)参考资料:https://arxiv.org/pdf/2604.06268关于波动智能——
波动智能旨在建立一个基于人类意图与反应的真实需求洞察及满足的价值体系,融合人工智能与意识科学,构建覆盖情绪识别、建模与推荐的智能引擎,自主研发面向社交、电商等场景的多模态意图识别引擎、意图标签系统及意图智能推荐算法,形成从情绪采集、意图建模到商业转化的完整解决方案。波动智能提出“意图是连接人、物与内容的新型接口”,其产品广泛应用于AI社交、个性化内容推荐、虚拟陪伴、电商体验优化等领域。波动智能正在探索“EMO-as-a-Service”技术服务架构,赋能企业实现更高效的用户洞察与精准情绪交互,推动从功能驱动到意图驱动的产业范式升级。
亲爱的人工智能研究者,为了确保您不会错过*波动智能*的最新推送,请星标*波动智能*。我们倾心打造并精选每篇内容,只为为您带来启发和深思,希望能成为您理性思考路上的伙伴!
加入AI交流群请扫码加微信
 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库