五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
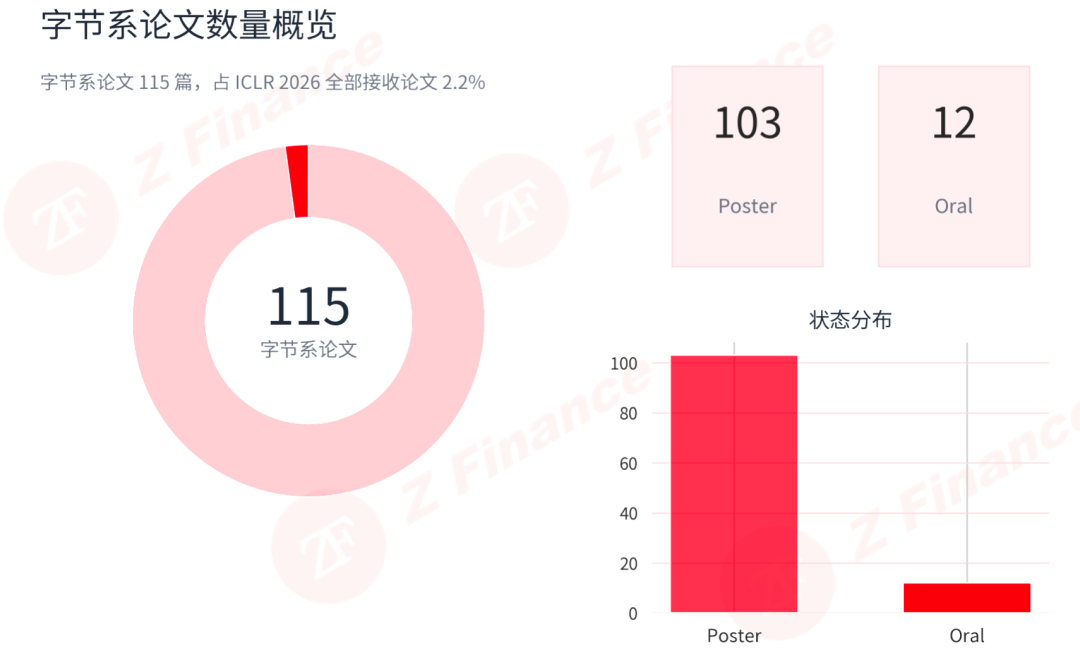
数据库深度|115 篇接收、12 篇 Oral!字节跳动 ICLR 2026 成绩单刷屏,基座+多模态火力集中

图片来源:字节跳动
Z Highlights
实现了规模与质量的双重爆发: 字节共计 115 篇论文被接收,其中 Oral 占比高达 10.4%,远超大会 4.2% 的平均水平,证明其研究精品率极高。
火力高度聚焦“基座+多模态”: 字节 84.3% 的论文集中在基座大模型与多模态感知方向,这反映出一种典型的重仓式布局,而非均衡配置。
呈现显著的领域“超配”特征: 字节在基座大模型和多模态方向的投入强度分别是大会平均水平的 1.47 倍和 1.79 倍,战略重心极其明确。
从单点突破转向全栈 AI 平台化: 字节正系统性构建从底层基座、核心能力、应用场景到数据评测标准的完整体系,意在掌握 AI 话语权与标准定义权。
构建了极高强度的全球科研联盟: 外部协作占比高达 90.4%,通过深度链接全球顶级高校和研究机构,将自身的研究规模放大了近 30 倍。
ICLR 2026 的最终接收论文名单刚刚公布,一份来自字节系的成绩单,已经在圈内悄然传开。
115 篇接收论文,占大会总量的 2.2%。单看数量,这已经是一支相当稳定的产业研究力量。但真正让同行关注的,是另外几个数字:12 篇 Oral,占比 10.4%,而 ICLR 整体的 Oral 占比为 4.2%,高出 6.2 个百分点;以及 90.4%的论文都带有外部合作。
字节系论文数量概览
这组数据放在一起,勾勒出的是一个已经形成稳定产出主线、并能在顶会前排持续输出的研究体系。
双核重仓:84.3%的火力集中在基座模型与多模态感知方向
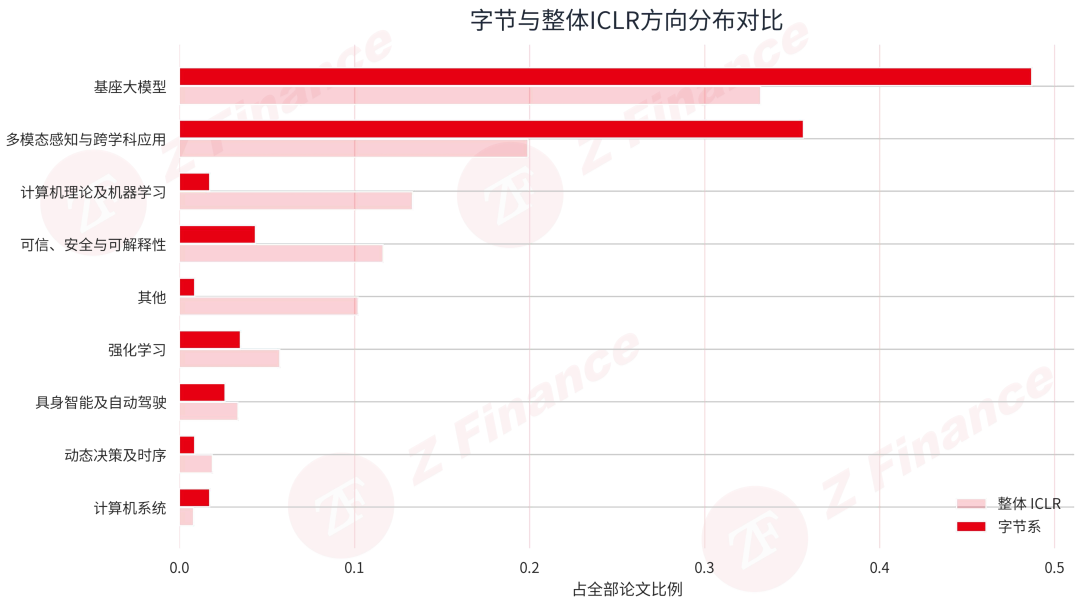
如果说论文数量代表的是体量,那方向结构体现的就是布局思路。字节系在 ICLR 2026 上最鲜明的特征,是火力高度集中在两个方向。基座大模型共 56 篇,占比 48.7%;多模态感知与跨学科应用共 41 篇,占比 35.7%。两者相加共 97 篇,占全部字节系论文的 84.3%。这不是均衡配置,甚至不只是重点倾斜,而是一种典型的重仓式布局。
剩下的方向则更像是外围梯队。计算机理论与机器学习 2 篇,强化学习、可信与安全可解释性各 4 篇,具身智能与自动驾驶 3 篇,系统方向 2 篇。这个结构释放的信号很清晰:对字节而言,ICLR 2026 的主战场仍然集中在基座大模型与多模态能力本身。
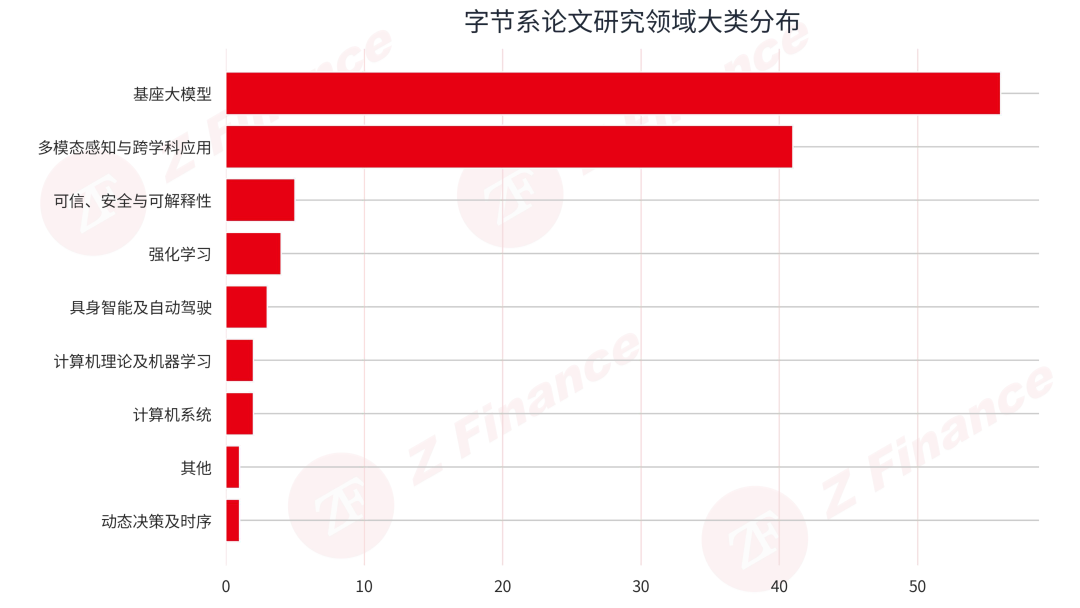
字节系论文研究领域大类分布
进一步拆解一级研究方向,字节的技术重心将暴露得更清楚。排在第一位的是“applications to computer vision, audio, language, and other modalities”,共 38 篇,占比 33.6%;随后是“foundation or frontier models, including LLMs”(21 篇)、“generative models”(20 篇)和“datasets and benchmarks”(15 篇)。
这个结构很有意思,说明字节的 AI 研究呈现出鲜明的平台化战略:38 篇多模态应用(33.6%)占据首位,凸显以视觉、音频、语言等全模态驱动产品落地的优先导向;基础模型与生成模型分别以 21 篇和 20 篇紧随其后,构成底座能力+内容生产的双轮闭环;而 15 篇数据与评测的投入,则超越了单纯的模型研发,意在掌握数据源头与标准定义权。四者共同构建起从底层基座、核心能力、应用场景到基础设施的系统性技术体系,反映出字节跳动正从单点模型突破转向全栈自主的 AI 平台化布局。
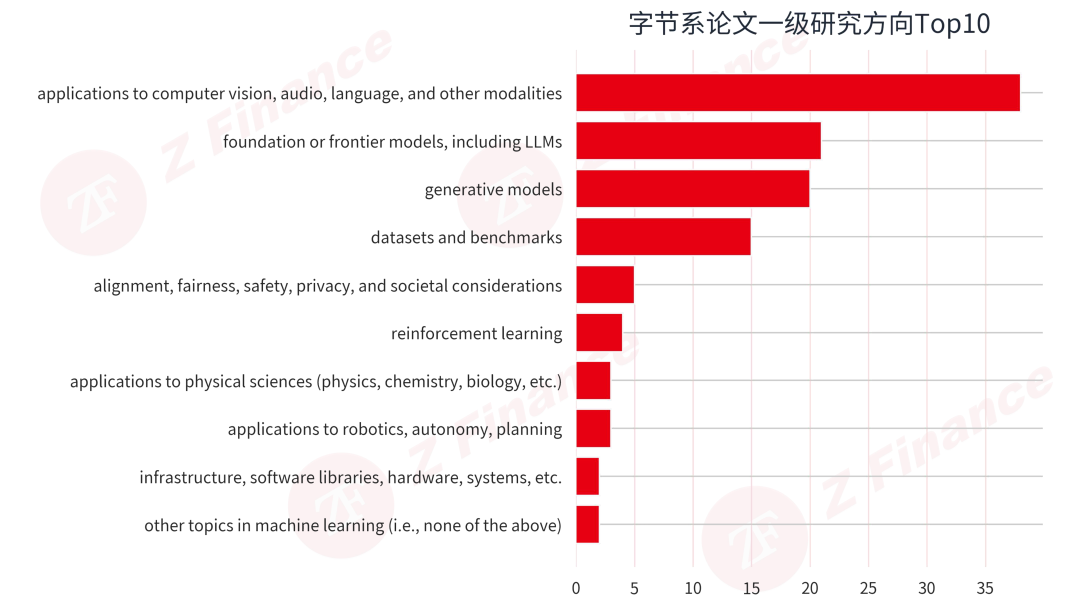
字节系论文一级研究方向 Top 10
如果只看 12 篇 Oral,方向集中度会更高。按研究大类统计,7 篇来自基座大模型,4 篇来自多模态感知与跨学科应用,另外 1 篇来自强化学习。也就是说,首页机构口径下的字节 Oral,几乎全部仍然落在“大模型 + 多模态”这条主轴上。在这两个方向上,字节已经具备了持续产出高质量成果的能力。
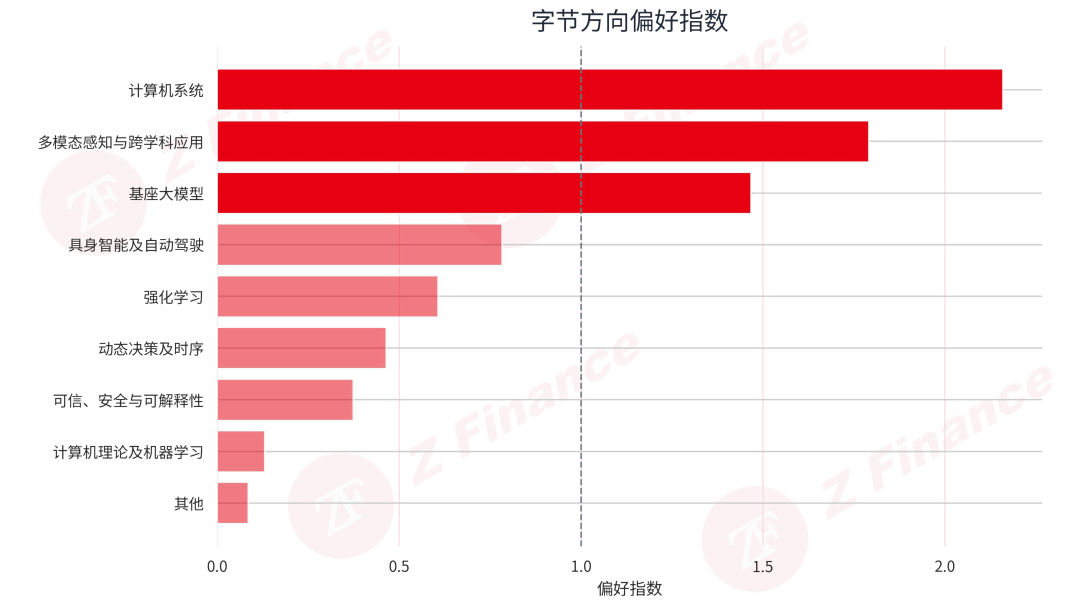
与大盘对比,超配信号明显:偏好指数 1.49 意味着什么?
把字节放回整场 ICLR 里看,结构差异会更明显。
基座大模型是字节典型的超配方向。字节系在这一方向上的占比达到 48.7%,而整体 ICLR 的占比是 33.2%,占比差值达到 15.5 个百分点。如果用偏好指数来衡量,字节在基座大模型上的偏好指数达到 1.47。也就是说,字节在这个方向上的配置强度,大约是大会平均水平的 1.5 倍。
字节与整体 ICLR 方向分布对比
字节方向偏好指数
多模态感知与跨学科应用方向也不甘示弱,同样成为了典型的超配方向。字节在这一方向上的占比为 35.7%,整体 ICLR 为 19.9%,偏好指数 1.79。这进一步印证了字节的主线布局:将资源明显集中在“基座+多模态”两块。
一个容易被忽略的细节是计算机系统。它只有 2 篇论文,但由于整个 ICLR 系统方向本身也只占 0.8%,字节在这一方向上的偏好指数仍达到 2.16。这说明系统虽然不是字节的主要叙事,但也没有完全缺席。这种主线清晰、支线有选择跟进的布局,正体现了一家成熟研究机构的战略定力。
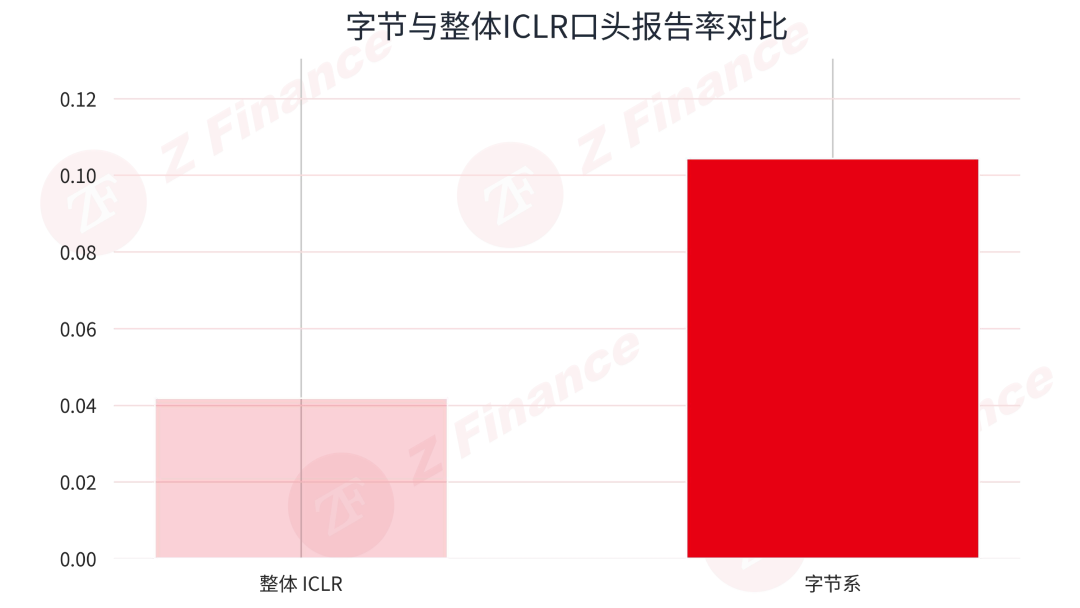
最后看一个最硬的结果指标:Oral 占比。字节系 Oral 占比为 10.4%,整体 ICLR 为 4.2%,相差约 6.2 个百分点。与许多靠规模取胜的产业队伍不同,字节这次不只是论文数量多,精品率也确实跑在了前面。这意味着,字节的研究质量并未因规模扩张而被稀释,反而在更高水平的竞争中保持了产出效率。
字节与整体 ICLR Oral占比对比
注:偏好指数 = 字节在某方向的论文占比 / 整体 ICLR 在该方向的论文占比。偏好指数大于 1 表示字节在该方向相对超配,小于 1 表示相对低配。 占比差值 = 字节在某方向的论文占比 - 整体 ICLR 在该方向的论文占比,用于直观看结构差异。本文新增指标属于描述性统计,用于说明方向结构,不做显著性检验。
90.4%的协作率:一张覆盖头部高校的隐形联盟
如果说方向结构体现的是字节将研究资源押注在哪些领域,那么合作结构则反映了字节通过什么方式将这些论文落地。答案很明确:靠合作,而且是高强度合作。
字节系论文合作版图发布
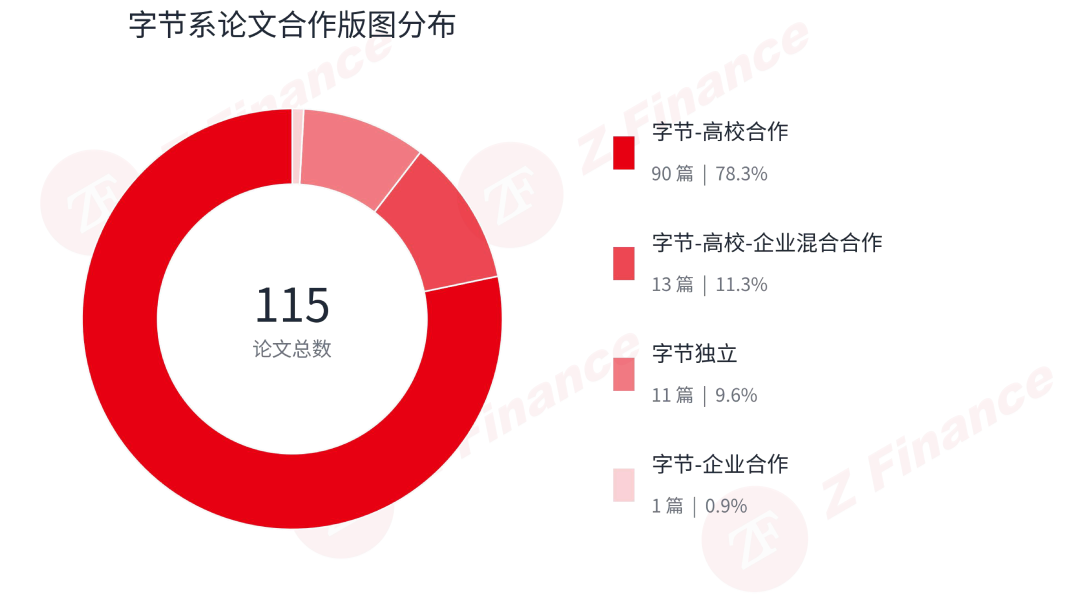
115 篇字节系论文中,纯字节独立完成的只有 11 篇,占比 9.6%;其余 104 篇均有外部合作,外部协作占比达到 90.4%。在顶会语境下,这个数字几乎可以被视作平台型研究机构的典型特征——它通过一张高度成熟的合作网络,将研究规模放大了近 30 倍。
从细分结构看,字节-高校合作有 90 篇,占比 78.3%;字节-高校-企业混合合作有 13 篇,占比 11.3%。两者合计已覆盖绝大多数样本。纯字节-企业合作只有 1 篇,说明字节在 ICLR 这类顶会上的合作逻辑,仍以高校/研究机构牵引为主导,而非单纯的产业间联名。这种选择有其内在逻辑:高校和研究机构在基础研究、人才培养和学术影响力上具有天然优势,而产业方的优势在于场景、数据和工程化能力。字节选择的,正是高校做深、产业做宽的互补模式。
研究机构方面,前五名分别是 Data61 CSIRO(2 篇)、Georgia Institute of Technology(2 篇)、Institute of Automation, Chinese Academy of Sciences(2 篇)、Shanghai Collaborative Innovation Center of Intelligent Visual Computing(2 篇)和 Shanghai Key Laboratory of Multimodal Embodied AI(2 篇)。
这说明字节并不是只围绕高校展开合作,同时也在和最强的一批研究平台形成稳定共研。这些平台往往介于学术界和产业界之间,既有学术深度,又具备一定的工程化能力,恰好是字节理想的合作伙伴。

字节合作研究机构 Top 5
企业方面,字节与 M-A-P 合作 3 篇,与 OPPO 合作 3 篇。这部分样本规模不如高校合作,但它反映出的信号很直接:在前沿议题上,字节也在和其他产业玩家发生交叉联动。这些合作可能集中在某些需要多方数据或多方能力的特定议题上,比如多模态、端侧 AI 等。
注:合作机构计数采用“论文共现次数”口径,同一篇论文内同一机构只计 1 次,不按作者人数或作者排序加权。因此,这里的“合作最多”应理解为共同署名最频繁,而不是作者贡献权重最高。
迈向下一代智能系统
字节在 ICLR 2026 上围绕多模态生成、视觉验证、强化学习驱动的主动推理、长上下文建模、高效模型训练与结构优化等方向集中发布的一系列工作,本质上是在系统性地构建下一代智能系统的技术底座。这些研究既涵盖视频 avatar、视觉几何、蛋白质结构生成等具体任务,也深入到混合专家路由、偏好优化、测试时训练、记忆机制与 agent 强化学习等基础性问题。再把视线拉回到这 115 篇论文中最具分量的 oral 部分,其中字节跳动多模态和世界模型负责人时光挂名的有两篇,分别是 OmniVerifier 和 Deep Anything3。
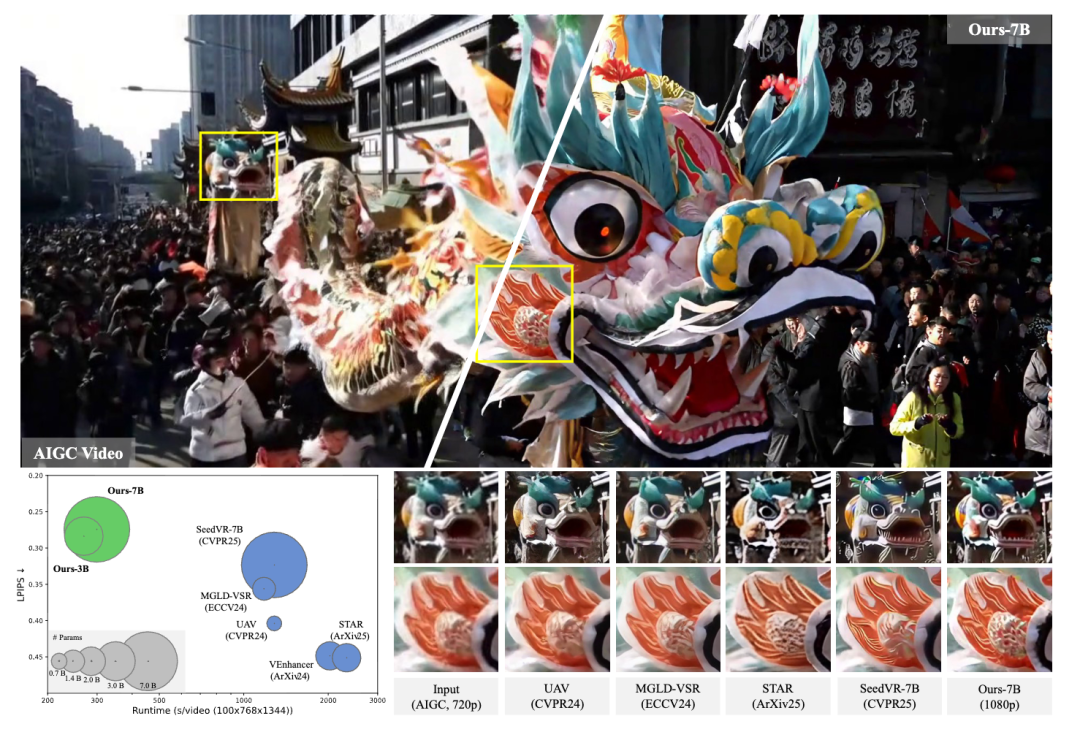
SEEDVR2
视频生成方面,字节在 ICLR 上的文章侧重于生成过程如何被稳定控制、生成主体如何保持一致、生成系统如何走向高效部署。其中,Video-As-Prompt 将参考视频本身转化为统一语义提示,把风格、动作、运镜等不同控制条件纳入同一生成框架,本质上推动了视频生成从任务特定控制向上下文驱动生成的演进;BindWeave 则进一步聚焦主体一致性,通过多模态语言模型与扩散 Transformer 的跨模态耦合,在单主体与多主体场景下实现更稳定的实体对齐与身份保持,使视频生成具备了更强的角色约束能力;而 SeedVR2 则从效率侧切入,以单步视频恢复替代传统多步扩散过程,显著降低高分辨率视频处理的推理成本。整体来看,这三项工作并不是彼此孤立的任务改进,而是分别对应视频生成系统走向实用化所必需的控制能力、一致性能力与部署效率,体现出字节在该方向上已开始从“生成效果提升”转向“生成系统完善”的整体布局。
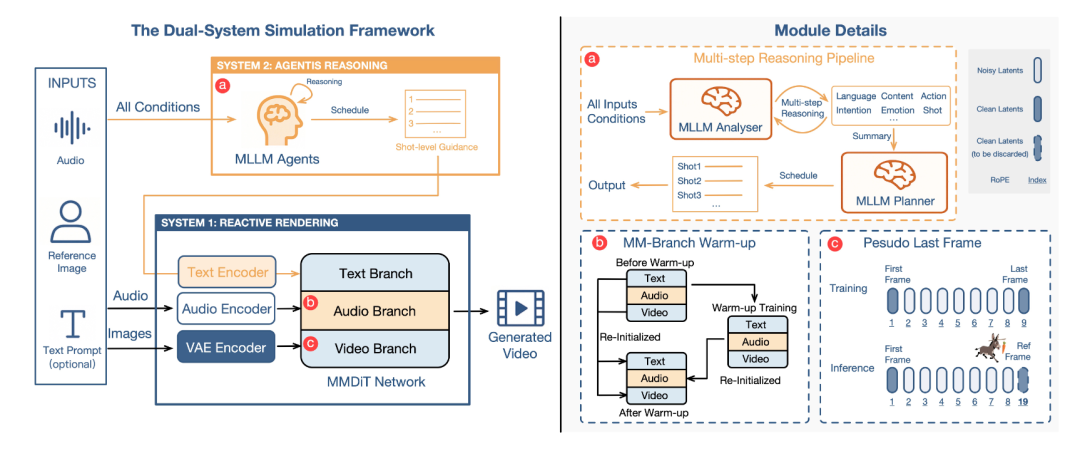
OmniHuman-1.5
多模态生成方面,AvatarMind 的切入角度很清晰——传统数字人方法过度依赖低层音频驱动,缺乏对角色的语义表达与意图理解。该工作引入多模态大模型生成结构化语义表示,并结合多模态扩散 Transformer 完成动作生成,将 avatar 建模从口型同步推进至认知状态驱动,使情绪、意图与语境在角色动画中真正成为主导因素。
视觉几何建模领域,RoSE 与 Deep Anything 3 呈现出相似的技术路径。RoSE 不再直接从单张图像回归法向图,而是先预测对几何信息更为敏感的 shading sequence,再通过解析方式恢复法向图;Deep Anything 3 则尝试用统一的 Transformer 框架处理任意视角、任意数量输入条件下的三维恢复问题,体现出从单一任务求解向统一视觉空间建模演进的技术趋势。字节还在 GUI agent 方向还推进了以 UI-TARS 为代表的原生界面智能体路线,其核心意义在于让模型直接基于截图理解并操作软件界面,并借助强化学习增强长程交互中的规划与执行能力,这也使豆包手机一类终端交互产品具备了更强的落地基础。
在多模态可靠性方向,OmniVerifier 提出了通用视觉验证器这一重要范式,指出现有多模态模型虽然具备较强的生成能力,但在视觉结果的检查、反思与修正方面存在明显短板。为此,研究团队构建了专门的验证基准,并训练生成式 verifier,在图像生成与编辑过程中实时判断输出是否符合目标要求,进一步通过测试时迭代优化机制将验证环节嵌入生成闭环。
强化学习与 agent 方向的多篇工作共同指向一个判断:智能体能力的提升,既依赖于更长的推理链,也取决于更优的表示学习、更强的外部交互能力以及更稳定的内部状态管理。ReTool 重点研究了如何在结果反馈驱动下,自主摸索出更优的工具使用策略,用强化学习让模型学会什么时候该调用工具、怎样调用工具、以及在工具反馈后如何继续推进推理。RALI 通过图像质量评估任务发现,强化学习带来的泛化收益并不完全来自显式推理过程,而更多源于推理过程中形成的紧凑、可迁移表征。基于这一发现,该工作利用对比学习直接对齐图像与这类表征,以更低的成本逼近推理模型的效果——这意味着推理的价值在诸多场景下可以被转化为更高效的表示学习机制。
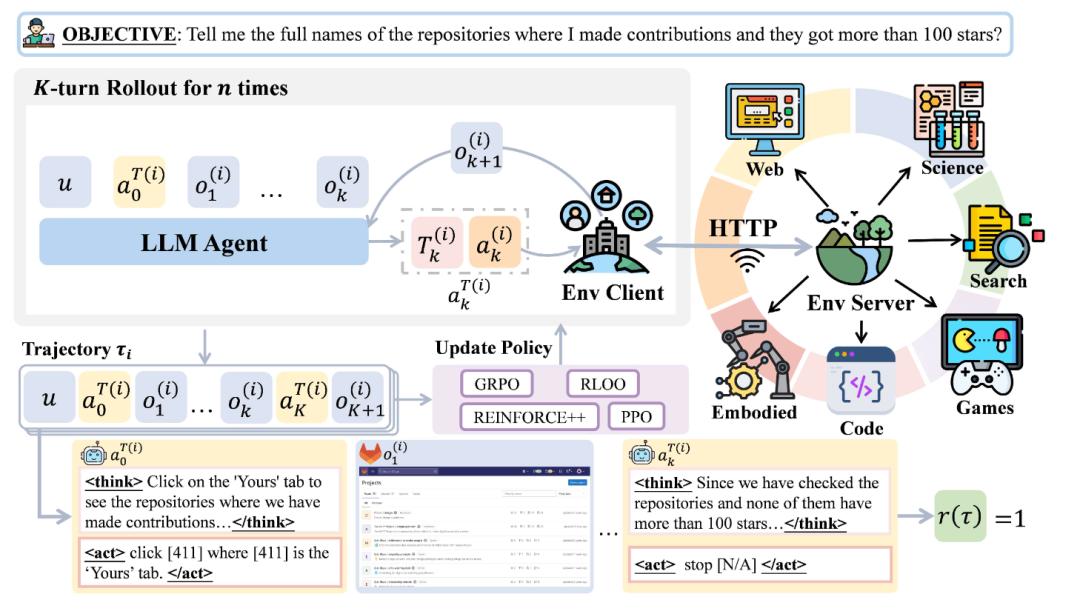
AgentGym
AgentGym 则从系统层面提出了统一的 agent 强化学习框架,通过分阶段交互训练提升模型在长时程任务中的稳定性。其核心观点在于,复杂 agent 的能力不应仅依赖内部 token 推理的扩展,更有赖于与外部环境的高效交互。
长上下文建模方向,MemAgent 与 InPlaceTTT 分别代表了两条互补的技术路径。MemAgent 将超长文本处理重构为显式记忆管理问题,通过分段处理、记忆覆盖与强化学习优化,使模型在极长输入条件下仍能维持有效信息的提取与保留;InPlaceTTT 则从参数更新角度切入,在测试时对部分 fast weights 进行原地更新,赋予模型在线适应能力。二者分别从记忆管理与参数更新的维度,为长上下文场景提供了系统性的解决方案。
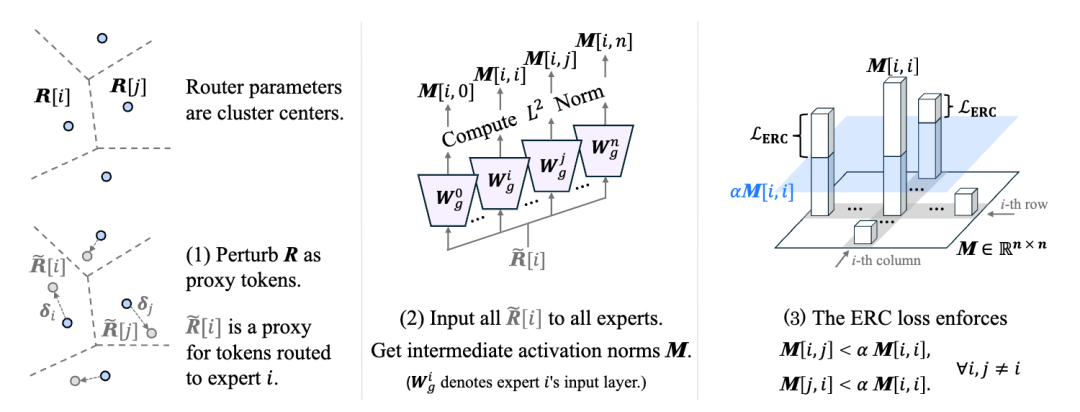
ERC-MoE
模型效率与训练机制方面,字节的多项工作体现出从规模扩张向机制优化转变的清晰趋势。DCFold 采用单步生成替代扩散模型的多步迭代,在蛋白质结构生成任务中显著提升了推理效率;ERC-MoE 针对混合专家模型中路由与专家匹配不足的问题,引入辅助耦合损失以强化专家分工的专业性;TI-DPO 则将偏好优化从序列级推进至 token 级,通过重要性建模实现了更为精细的对齐控制。
总体而言,字节在 ICLR 2026 的这组工作呈现出高度的战略一致性。其研究重点并非聚焦于单一任务的局部领先,而是在更高维度上系统性地探索下一代智能系统的关键能力:高层语义驱动的生成能力、生成结果的验证与反思能力、长时程交互中的状态管理能力、超长上下文场景下的记忆与适应能力,以及面向实际部署的高效训练与推理能力。
字节在 ICLR 2026 上的表现,或许会成为未来几年产业界参与顶会的一个参考样本。它不是最卷的那一个,但可能是结构最清晰的那一个。
作者: Cheng Gao, Wang Shijie, Wang Jiawen
*排名不分先后,按照首字母排序
Ref.
数据来自 openreview 公开信息及对应 ICLR 已接收论文

稿件经采用可获邀进入Z Finance内部社群,优秀者将成为签约作者,00后更有机会成为Z Finance的早期共创成员。