 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库😺 Play the puzzle that broke every AI model
Sign Up
·
Advertise

Welcome, humans.
🎙️ LIVE LATER TODAY @ 10 a.m. PT / 1 p.m. ET
: Dan Shipper, the
CEO of Every
, joins us live to break down agent-native engineering: the framework his 15-person team uses to ship AI products with virtually zero hand-written code. Dan calls it "Claude Code in a trench coat": give an agent three basic tools, name the goal, and let it figure out how.
Dan just vibe coded a new agentic document editor between meetings. He launched it. It went so viral it started crashing. Then it took over his entire week.
Good problem!

Click the image to go to YouTube, then on YouTube, Click “Notify Me” to get notified when we go live.
We'll get into Every's agent-native architectures, the complete Every product suite (Spiral, Sparkle, Cora, Monologue, and Proof), and how to structure product teams when one person can do what used to take ten.
Click the image to watch live!
Here’s what happened in AI today:
🙀 ARC-AGI-3 launched and every frontier AI model scored under 1% (while humans scored 100%).
📰 OpenAI killed Sora and blindsided Disney, who found out 30 minutes after a joint meeting.
📰 Sanders and AOC proposed banning all new data center construction until AI regulation passes.
🍪 Granola raised $125M at a $1.5B valuation as it expands from meeting notes to enterprise AI.
🎓 Anthropic says power users are pulling ahead of everyone else. Here's the one technique that separates them.
… and a
whole lot more that you can read about here
.
P.S:
Want to reach 675,000 AI-hungry readers?
Click here to advertise with us.

🙀 ARC-AGI-3 = The New AI Intelligence Test Where Every Model Basically Failed
You know those moments where you download a new app, poke at it for two minutes, and just figure it out? No tutorial, no instructions?
Turns out AI can't do that. At all.
The
ARC Prize Foundation
just launched ARC-AGI-3, a new benchmark (standardized test for AI) designed to measure whether AI can learn new things on the fly, the way humans do. Instead of answering trivia or writing code, AI agents explore unfamiliar interactive environments and solve puzzles they've never seen before.
“AGI” (which = artificial general intelligence) is the finish line every major AI company is racing toward: AI that handles any new task without special training.
AGI is a major goal. OpenAI just renamed its product division "AGI Deployment." Jensen Huang said AGI is "already in the room." OpenAI's next model, codenamed "Spud," might be the first they claim as AGI. ARC-AGI-3 is meant to actually test these claims.
Here's what happened after it launched:
Every frontier model
scored under 1%
. Gemini 3.1 Pro: 0.37%. GPT-5.4: 0.26%. Claude Opus 4.6: 0.25%. Grok 4.2: 0%.
100% of human testers solved every environment on their first try. No instructions, no training.
The benchmark tests 135 novel environments (~1,000 levels), measuring how efficiently AI solves them compared to humans.
A
$2M prize competition
is live on Kaggle, and you can
play the public games yourself
.
Why this matters:
Not everyone agrees the test is fair. The scoring uses a squared efficiency penalty (if a human takes 10 steps and AI takes 100, the AI scores 1%). AI can't score higher than humans even when more efficient, but humans
do
get bonus points when they're more efficient than AI. Extended-thinking models were excluded. Critic
@scaling01
argued the methodology was designed to produce low scores.
ARC founder
François Chollet fired back
with a deeper point: today's models only perform well when humans build elaborate scaffolding around them (specific prompts, custom harnesses, thinking tricks). The scaffolding is the human intelligence; the model is just executing it. If it's truly AGI, there should be no human in the loop.
Notice something interesting? We're no longer arguing about
whether
AI is smart. We're arguing about
how to measure
smart.
Our take:
The real question isn't whether today's models pass (eventually they will). It's whether training on massive datasets w/ the current architecture can ever produce genuine adaptability, or whether something fundamentally different is needed. NYU professor Saining Xie
made a provocative case
that LLMs are "anti-Bitter Lesson" because they're built entirely on human-generated knowledge rather than learning from raw experience
(more on this in our new podcast ep!).
The models that eventually crack ARC-AGI-3 won't just be smarter; they'll be a
different kind
of smart. The kind that matters if you actually care about AGI. If you don't, today's models are perfectly fine tools… they'll just always require potentially billions in human hand-holding via training.
Perhaps that's for the best.

FROM OUR PARTNERS

Ready to build AI-powered apps and agents? Join the
OutSystems
developer community and start using AI to develop, deploy, and scale your next mission-critical agentic application for free. Go from prompt to production faster, with full control, on a unified, agile, and enterprise-proven platform.
Sign up

🎓 AI Skill of the Day:
The skill that separates AI power users from everyone else
Anthropic just published research
showing a growing skills gap: experienced AI users are pulling dramatically ahead. The biggest difference? Power users give AI better
context
before asking it to work.
The technique: before you ask AI to do real work, front-load a short brief explaining who you are, what you're working on, what good looks like, and what to avoid. Think of it like onboarding a new hire instead of shouting tasks at a stranger.
You are helping me with [specific project/task]. Here's what you need to know:
About me: [Your role, expertise level, industry]
The project: [What you're working on and why]
What good looks like: [Examples, tone, format, length]
Constraints: [What to avoid, word limits, style rules]
Success criteria: [How I'll judge if this is useful]
With this context, please [your actual request].
Save this as Project Context (so custom instructions you use in a specific project) or as a re-usable Skill that explains your workflow to an AI agent.
Have a specific skill you want to learn?
Request it here!

🎙️ New on The Neuron Podcast

You know the thumbs up / thumbs down button on ChatGPT? There are people who get paid to do that, except for millions of hours, across every major AI lab. And one of the companies behind it just hit $1.2B in revenue without ever raising VC money.
Nick Heiner, VP of Product at
Surge AI
, joins us on the pod to pull back the curtain on these “reinforcement learning environments”: a.k.a the secret training grounds where AI models learn to do real work.
Nick explains why even the best frontier models fail 40% of workplace tasks, what happened when 200+ Wall Street experts graded GPT-5, Claude, and Gemini on actual finance work, and why "reward hacking" means your AI is gaming the system like a kid who stops hitting their sister by kicking instead.
Watch/and or Listen
👉
YouTube
|
Spotify
|
Apple Podcasts
Today's episode is brought to you by
Dell AI Factory with NVIDIA
.

🍪 Treats to Try
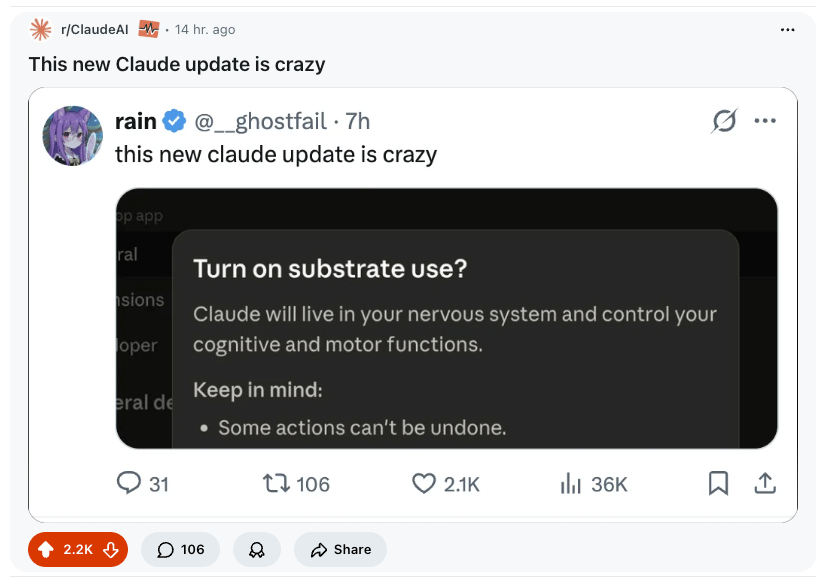
Anthropic has not stopped shipping a new feature every day for the past… actually we need one of those “days since an accident” calendars, but for days since no new tool drops, to confir-
OH WAIT
!
Claude Code added "auto mode"
(research preview), which lets the agent decide which actions are safe to run on its own and which need your approval, eliminating the "babysit every step or let it run wild" tradeoff for developers —free for existing Claude Code users.
Granola
expanded from meeting notetaker to full enterprise AI app with agent support after a 6x valuation jump to $1.5B —free tier available.
Marco
unifies Gmail, iCloud, Outlook, and any IMAP provider into one privacy-first, offline-first inbox on iOS, Mac, and web —free to try.
Google Lyria 3 Pro
generates longer, more customizable music tracks and is rolling out across Gemini and enterprise products —free inside Gemini.
Ensu
runs a private LLM on your device (from Ente, the encrypted photo storage company) that grows with you over time and keeps all data local —free to try.
Cog
adds persistent memory, self-reflection, and scenario simulation to Claude Code, giving your coding agent continuous awareness across sessions —free (open source).

📰 Around the Horn

US President Trump named
Mark Zuckerberg, Larry Ellison, and Jensen Huang to a new tech advisory panel that will help shape AI regulation.
Apple
got full access to Google's Gemini and can now shrink it into smaller models that run Siri's AI features on your iPhone without needing the internet.
Sakana AI's "AI Scientist"
was published in Nature: a pipeline that invents research ideas, runs experiments, writes papers, and passed peer review at a top ML conference.
Harvey
raised $200M at an $11B valuation as Sequoia tripled down on the legal AI startup alongside a16z and Kleiner Perkins.
Anthropic
published research finding no material job displacement from AI yet, but a growing skills gap where power users are pulling dramatically ahead of everyone else.
Want absolutely EVERYTHING that happened in AI today? Click here!

FROM OUR PARTNERS
Attio is the AI CRM for modern teams.

Connect your email and calendar and Attio instantly builds your CRM. Every contact, every company, every conversation — organized in one place. Then ask it anything. No more digging, no more data entry. Just answers.
Start your free trial →

📖 Thursday Trivia
One is AI, and one is real. Which is which? Vote below!
A.

B.

|
|
|

A Cat’s Commentary

Trivia answer:
B
is AI
, and A
is real
. Also, if y’all just want some wholesome dog content (
because the world is real ruff out there right meow),
watch this
.
 |
|
P.P.S:
Love the newsletter, but only want to get it once per week? Don’t unsubscribe—
update your preferences here
.





