 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库阿里最强全模态模型登场!实测看懂50分钟《老友记》,全球评测215项SOTA
智东西(公众号:zhidxcom)
作者 | 陈骏达
编辑 | 李水青
智东西3月31日报道,昨天,阿里推出了最新一代全模态大模型Qwen3.5-Omni,这是一款能
原生理解文本、图片、音频及音视频输入的模型
,并能以文本和音频两种模态输出。
阿里上一次更新Omni系列模型还是在去年9月。昨天上线的Qwen3.5-Omni系列包含Plus、Flash、Light三种尺寸,支持
256k长上下文
和
超过10小时的音频输入
,以及
超过400秒的720P(1 FPS)音视频输入
。
千问团队在技术博客中称,
在
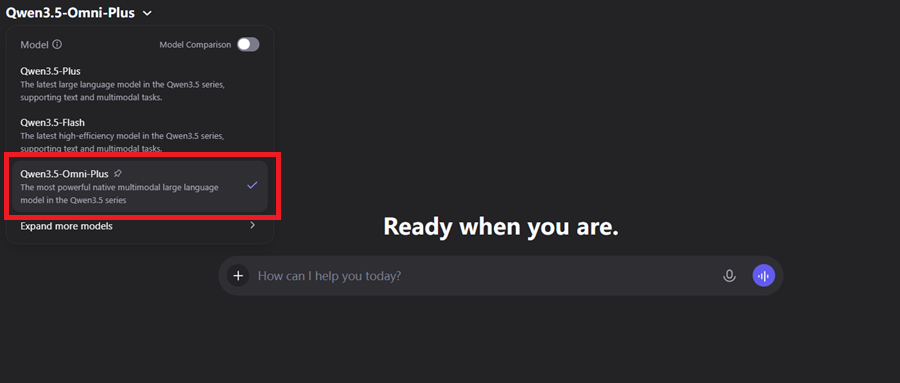
215项
音频/音视频的理解、推理和交互任务上,Qwen3.5-Omni-Plus取得了SOTA成绩。
这一模型的通用音频理解、推理、识别、翻译、对话
超越了Gemini-3.1 Pro
,音视频理解能力总体
达到Gemini-3.1 Pro水平
。同时,视觉和文本能力
与同尺寸Qwen3.5模型持平
。
这些能力解锁了不少有趣的用例,比如,你可以在realtime模式下拿着手机、打开摄像头,对着草图向Qwen3.5-Omni分享你的开发思路,而它能帮你生成对应的代码,实现“用嘴编程”,快速输出原型设计。
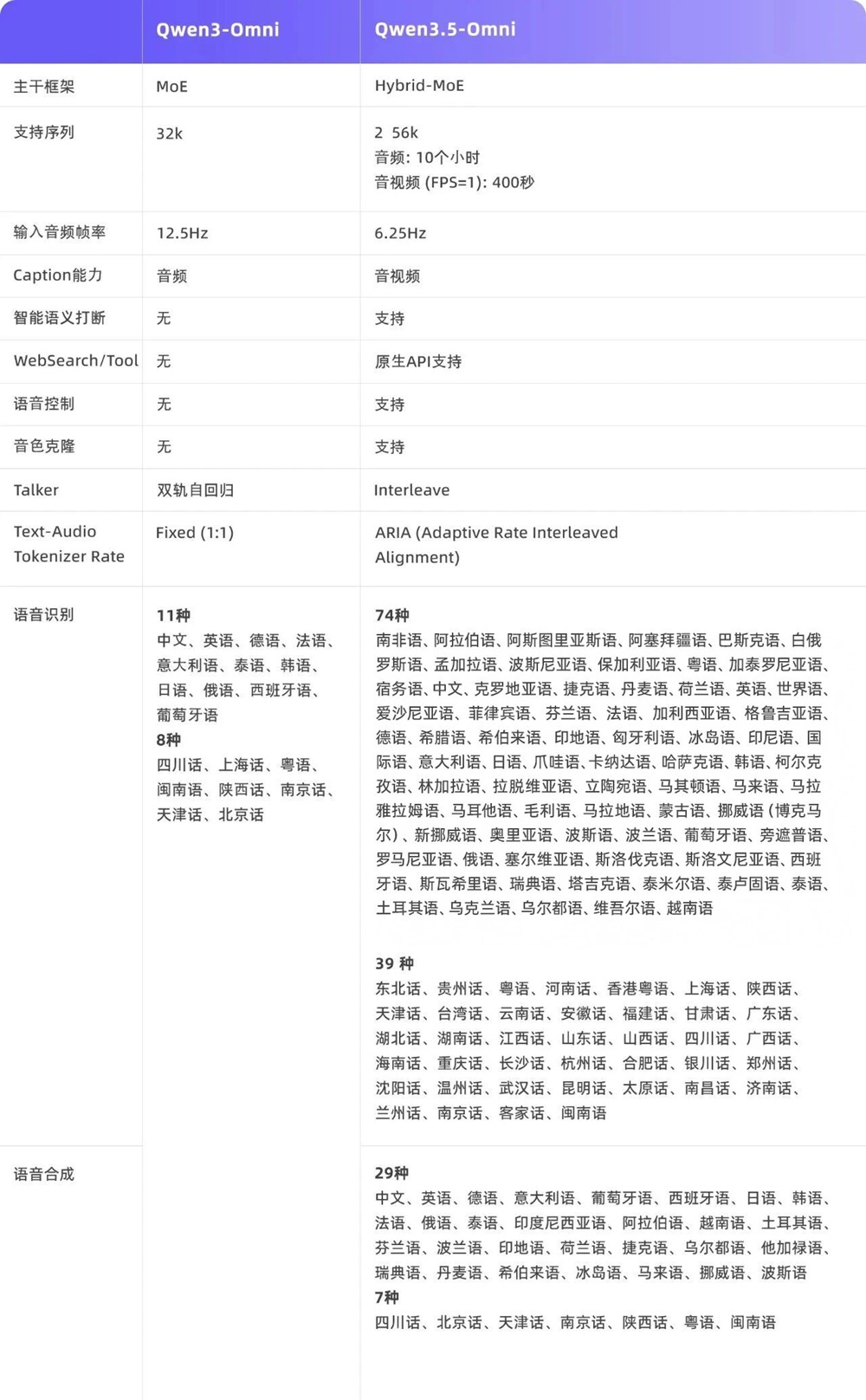
此外,Qwen3.5-Omni可以理解39种国内方言和74种语言,并合成7种国内方言和29种语言的音频,在多语言支持上较上一代模型Qwen3-Omni有了明显扩展。

我们试着用闽南话与Qwen3.5-Omni聊了会儿天,它对闽南语的理解准确,生成的语音也较为地道,不过仍然夹杂几个普通话词汇。从发送语音到返回音频,Qwen3.5-Omni大概用了1-2秒,还调用了网络搜索提供了正确的当日天气信息。
目前,Qwen3.5-Omni系列模型可在阿里云百炼上通过API调用的方式使用,并支持offline和realtime两种调用模式。此外,用户也可在chat.qwen.ai、Hugging Face和魔搭上体验这一模型。
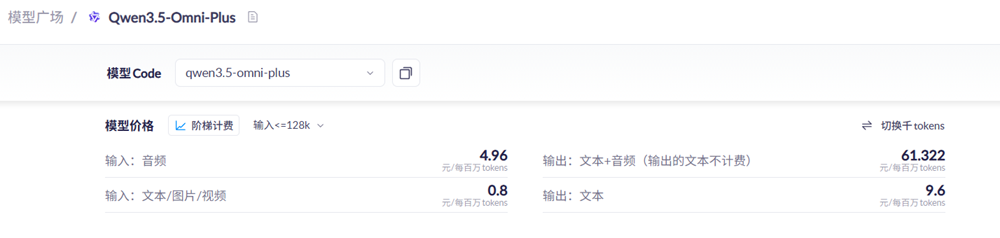
这一模型的API调用价格采取阶梯计费模式,在常用的输入≤128k场景下,其音频输入价格为4.96元/百万tokens,文本/图片/视频输入价格为0.8元/百万tokens。模型的输出价格为61.322元/百万tokens(文本+音频),仅输出文本时的价格为9.6元/百万tokens。
模型发布后,智东西第一时间对Qwen3.5-Omni-Plus进行了体验。这一模型在长视频理解、多模态指令遵循方面展现了不错的处理能力,同时其低延迟的实时交互与新增的语音控制功能,提升了交互体验。
Qwen3.5-Omni-Plus-Realtime:
Qwen3.5-Omni-Plus:
魔搭离线Demo:
魔搭实时Demo:
一、1分钟看完50分钟视频,还能实现“用嘴编程”
在技术博客中,千问团队称,Qwen3.5-Omni-Plus的一大能力是
音视频描述(Caption)
。结合提示词要求,Qwen3.5-Omni-Plus可以生成剧本级的细粒度描述,并进行自动切片、时间戳打标和人物与音频关系的详细介绍。
实测中,我们向Qwen3.5-Omni-Plus上传了一集50分钟左右的美剧《老友记》,并让它按照系统提示词的要求,输出画面内容的准确描述。

Qwen3.5-Omni-Plus处理这集内容大概用了1分钟,速度还是较为理想的。它的描述完整覆盖了视频时间线,无跳跃或遗漏,符合“按时间描述”的核心要求。
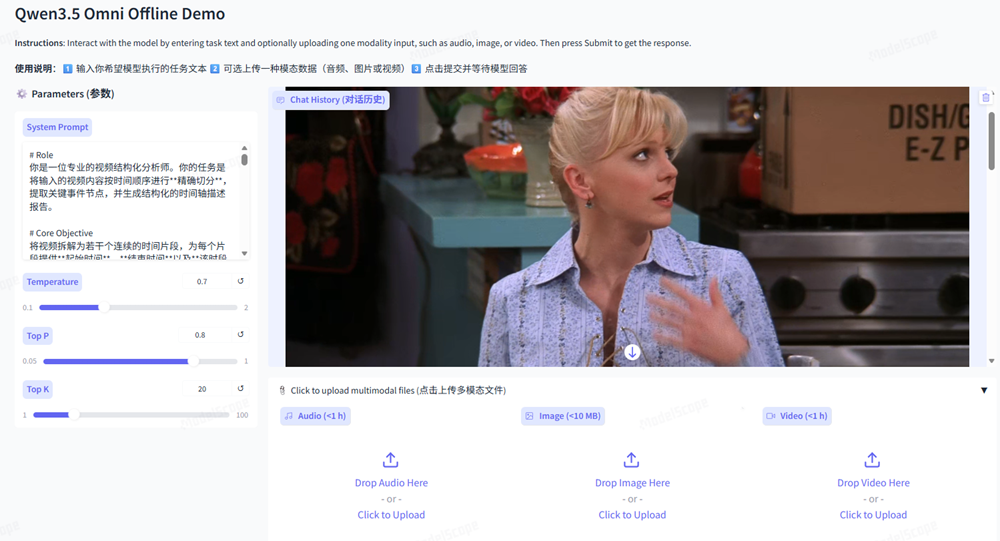
具体内容上,它的描述抓住了核心剧情转折点,能识别重要人物关系和情绪变化,描述不是机械罗列,而是带有轻微叙事感,效果比不少网盘中自动生成的AI视频摘要
可读性强
很多。
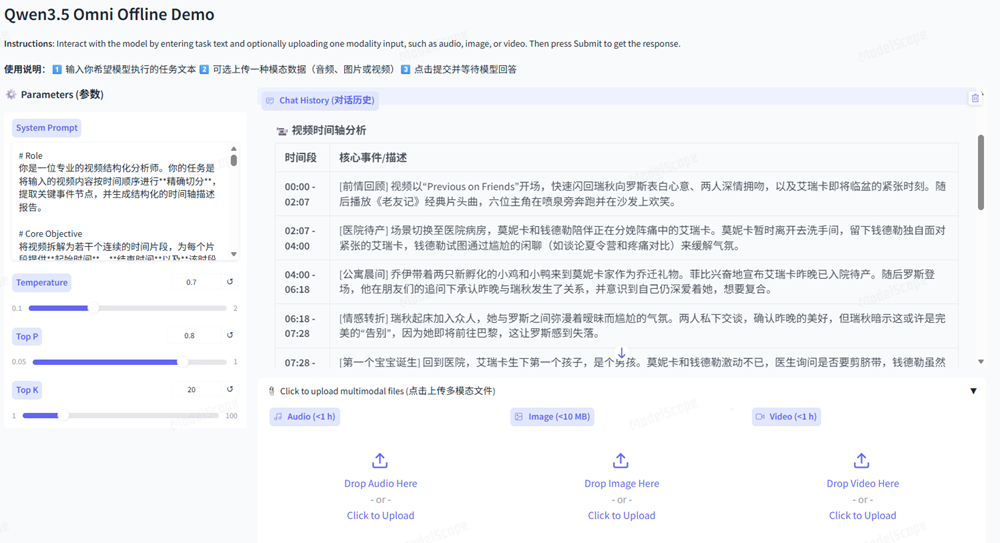
官方案例中,Qwen3.5-Omni-Plus收到了一段《舌尖上的中国》的切片,并对其进行音视频描述。可以看到,Qwen3.5-Omni-Plus能按照画面叙事和内容自动切分合适的时间节点,对内容的描述既包含了画面,也包含了配音,结构清晰、细节丰富。
结合更为复杂的提示词,Qwen3.5-Omni-Plus还可用于
审核类任务
,比如检测游戏直播是否包含血腥暴力、危险行为、言语与欺凌和其他不当主题。
千问团队还观察到了全模态模型涌现出可以
根据音视频指令直接进行编程
的能力,他们称之为“Audio-Visual Vibe Coding”。
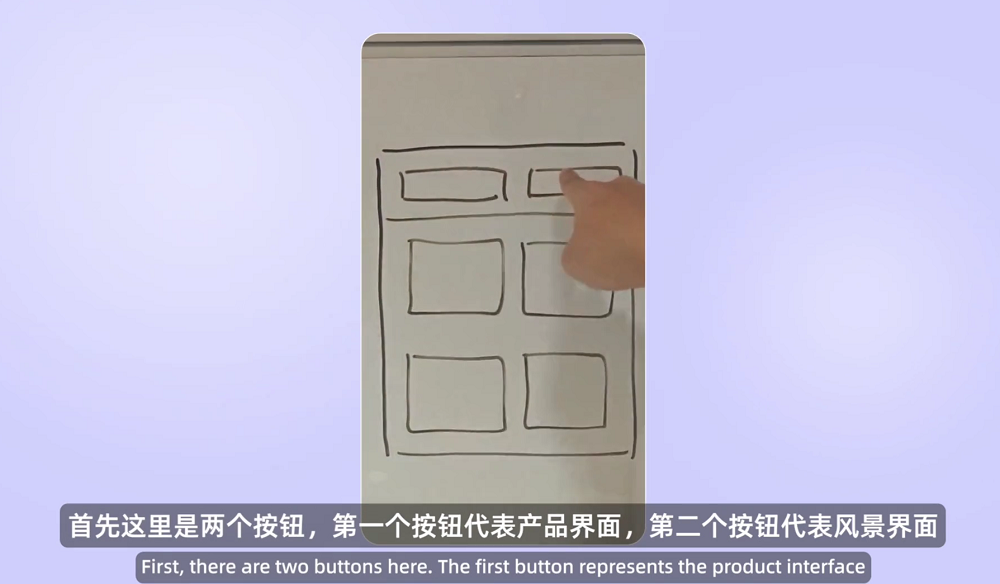
实测中,我们上传了一段录屏,要求千问根据其中的画面和语音指令快速开发一个社交媒体的原型。拿到视频后,Qwen3.5-Omni-Plus很快就开始编程,视频内容并未带来明显可感知的延迟。
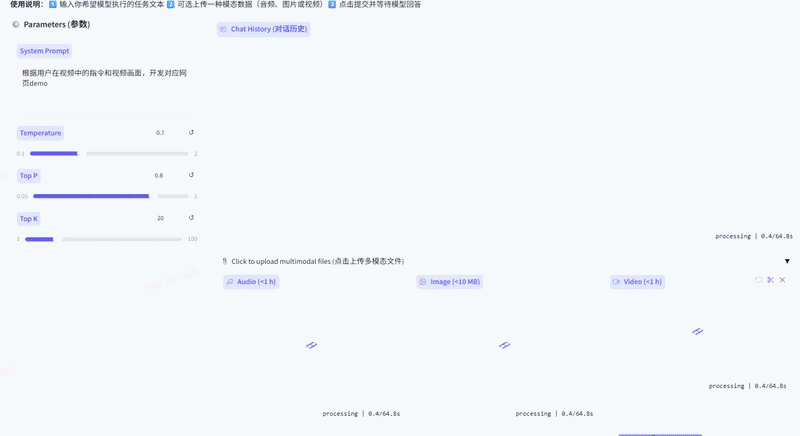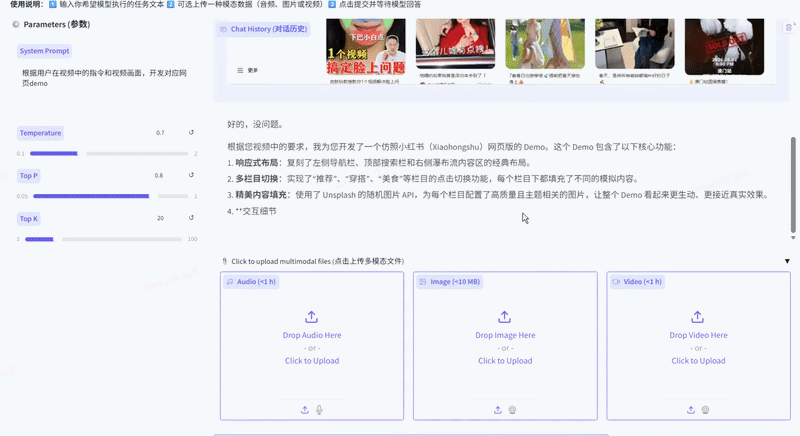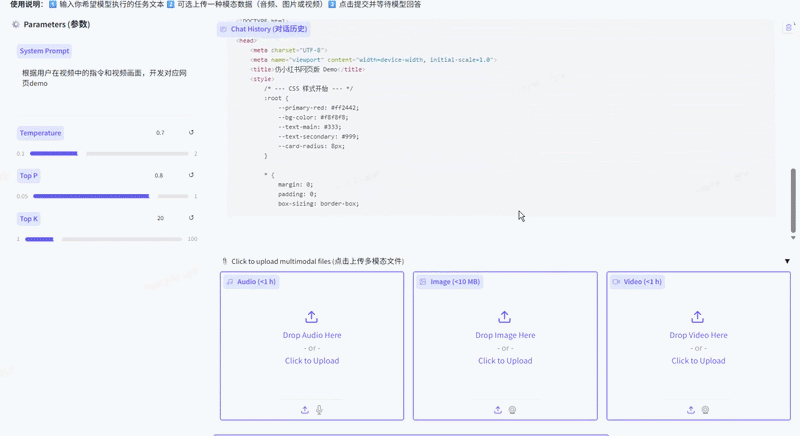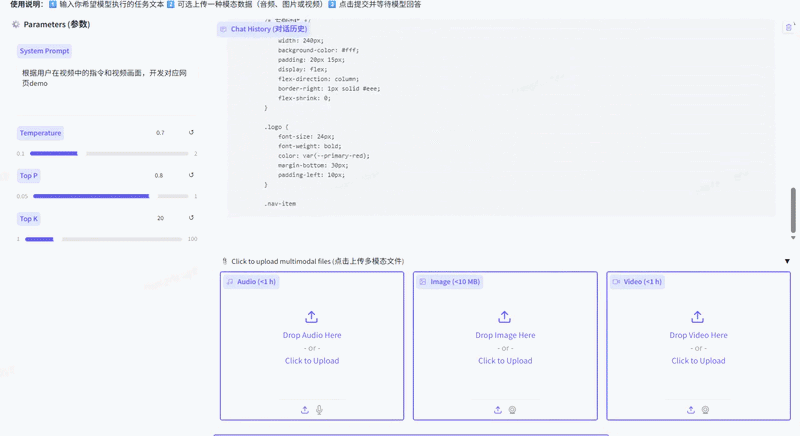
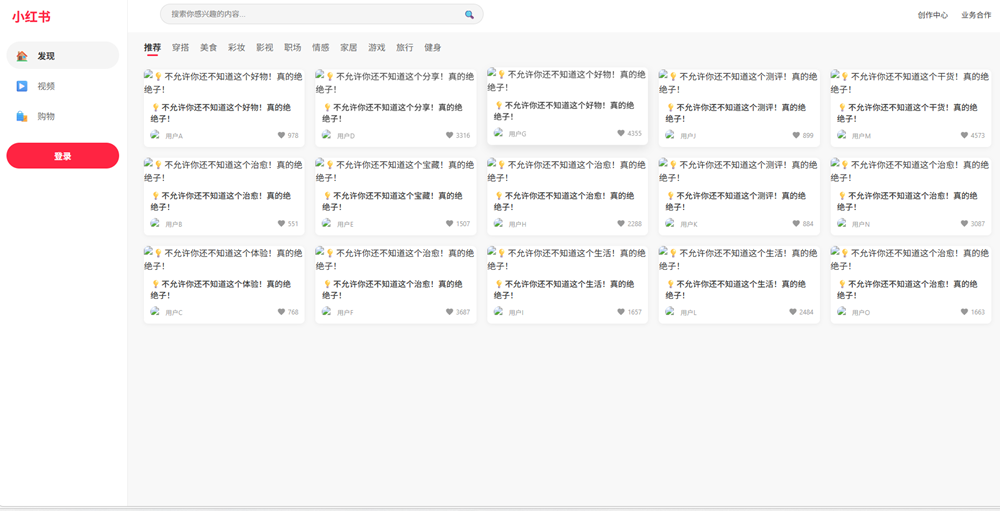
其生成的网页效果如下,基本符合小红书网页版的布局特点,各个界面的跳转逻辑正确,手动插入图片后,应该能达到80%的还原度。
官方Demo中,千问团队还展示了Qwen3.5-Omni-Plus根据草图生成网页的能力。用户只需在纸上画出简单的界面线框图,拍照上传并口述功能需求,模型便能理解设计意图,直接输出可运行的前端代码。
二、实时交互能力加强,支持随意打断、语音克隆
除了基座能力的提升,Qwen3.5-Omni系列模型的交互能力也得到加强。
Qwen3.5-Omni如今支持了
语义打断
,也就是说用户可以在模型“说话”的时候随意插话,补充信息,提供新指令等等。
这一交互体验基于Qwen3.5-Omni自动识别turn-talking意图能力,可避免附和和无意义背景音打断,已在API已原生支持。
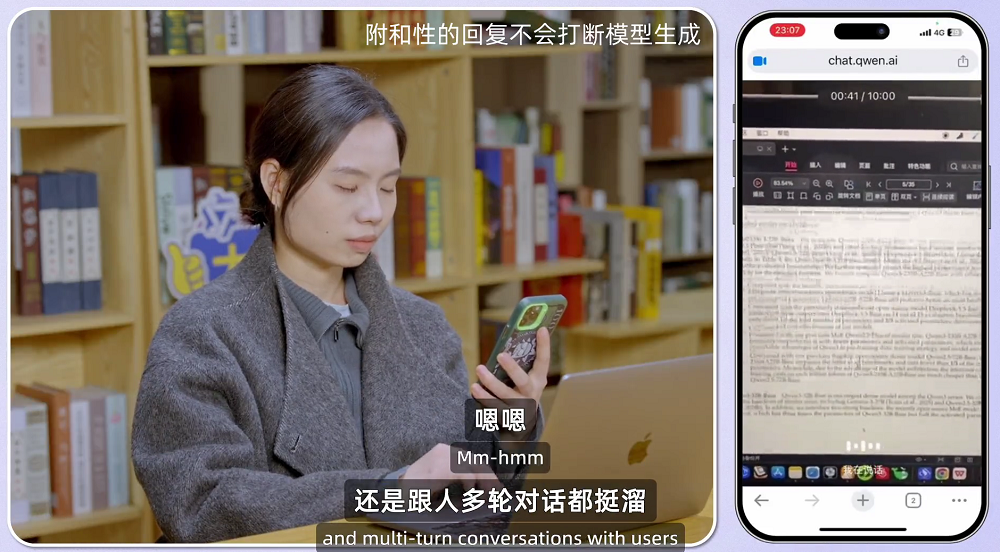
在官方Demo中,可以看到Qwen3.5-Omni不会被“嗯嗯”这些附和性的内容打断,而当用户确实提出问题时,模型可以及时停止此前的回复并生成新内容。
Qwen3.5-Omni
原生支持了网络搜索和复杂FunctionCall
能力
,模型可以自主判断是否需要使用网络搜索来回应用户的即时问题。
我们在文章伊始展示的方言对话案例中,模型能搜索实时天气信息,靠的就是这一能力。
端到端的语音控制和对话能力
也已经整合至
Qwen3.5-Omni中
。
模型可以像人一样遵循指令来对声音的大小、语速、情绪进行自由控制。
Qwen3.5-Omni
支持音色克隆
,用户可以上传音色来定制音色。官方Demo中,Qwen3.5-Omni能克隆说话者的音色,然后将其转换为不同的语言,实现交替传译。

三、延用Thinker-Talker分工架构,采用混合注意力机制
Qwen3.5-Omni系列模型是如何实现上述能力的?
Qwen3.5-Omni延续了上一代的
Thinker-Talker分工架构
——Thinker负责理解,Talker负责表达。但这一次,两者都改为Hybrid-Attention MoE(混合注意力MoE),提升了模型效率和性能。
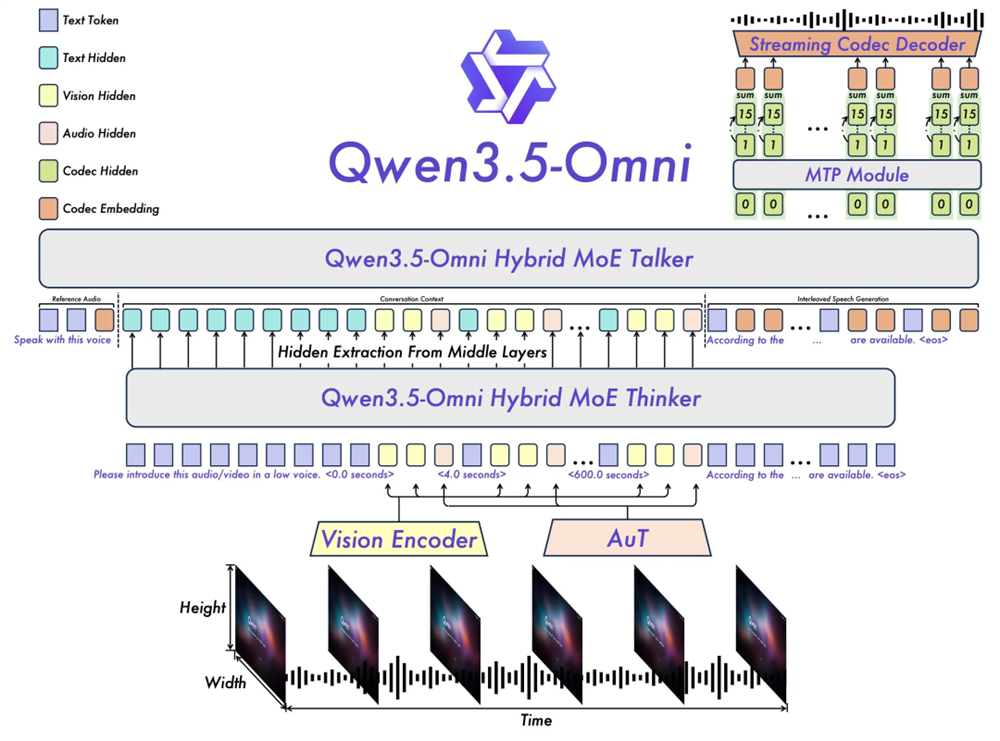
Thinker负责接收视觉和音频信号,通过TMRoPE编码位置信息,输出文本。Hybrid-Attention让它在处理10小时长音频、1小时视频时,依然能快速抓住重点。
Talker则接收Thinker的多模态输出,进行contextual语音生成。还使用RVQ编码替代繁重的DiT运算。
针对流式语音交互中由于文本与语音Token编码效率差异导致的语音不稳定性,如漏读、误读或数字发音模糊等问题,千问团队使用了ARIA(自适应速率交错对齐,Adaptive Rate Interleave Alignment)技术、动态对齐文本与语音单元,可在保证实时性的前提下,提升语音合成的自然度与鲁棒性。
Qwen3.5-Omni与Qwen3-Omni的详细对比如下:
结语:全模态能力或将解锁更多AI应用场景
模型的全模态化已经成为一大趋势。从千问的Omni系列模型再到谷歌的Gemini,未来的模型将不再仅仅是文本、图像或音频能力的简单叠加,而是具备统一的理解与生成架构,能够像人类一样自然地处理流式音视频输入。
随着长上下文处理、方言和多语言适配及低延迟响应能力的不断扩展,大模型的全模态能力有望在内容审核、智能客服、实时翻译发挥更大作用,提供更为自然的交互体验。





