 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库Arcee AI Releases Trinity Large Thinking: An Apache 2.0 Open Reasoning Model for Long-Horizon Agents and Tool Use
The landscape of open-source artificial intelligence has shifted from purely generative models toward systems capable of complex, multi-step reasoning. While proprietary ‘reasoning’ models have dominated the conversation,
Arcee AI
has released
Trinity Large Thinking
.
This release is an open-weight reasoning model distributed under the
Apache 2.0 license
, positioning it as a transparent alternative for developers building autonomous agents. Unlike models optimized solely for conversational chat, Trinity Large Thinking is specifically developed for long-horizon agents, multi-turn tool calling, and maintaining context coherence over extended workflows.
Architecture: Sparse MoE at Frontier Scale
Trinity Large Thinking is the reasoning-oriented iteration of Arcee’s Trinity Large series.
Technically, it is a
sparse Mixture-of-Experts (MoE)
model with
400 billion total parameters
.
However, its architecture is designed for inference efficiency; it activates only
13 billion parameters per token
using a 4-of-256 expert routing strategy.
This sparsity provides the world-knowledge density of a massive model without the prohibitive latency typical of dense 400B architectures. Key technical innovations in the Trinity Large family include:
SMEBU (Soft-clamped Momentum Expert Bias Updates):
A new MoE load balancing strategy that prevents expert collapse and ensures more uniform utilization of the model’s specialized pathways.
Muon Optimizer:
Arcee utilized the Muon optimizer during the training of the 17-trillion-token pre-training phase, which allows for higher capital and sample efficiency compared to standard AdamW implementations.
Attention Mechanism:
The model features interleaved local and global attention alongside gated attention to enhance its ability to comprehend and recall details within large contexts.
Reasoning
A core differentiator of Trinity Large Thinking is its behavior during the inference phase. Arcee team in their
docs
state that the model utilizes a ‘thinking’ process prior to delivering its final response. This internal reasoning allows the model to plan multi-step tasks and verify its logic before generating an answer.
Performance: Agents, Tools, and Context
Trinity Large Thinking is optimized for the ‘Agentic’ era. Rather than competing purely on general-knowledge trivia, its performance is measured by its reliability in complex software environments.
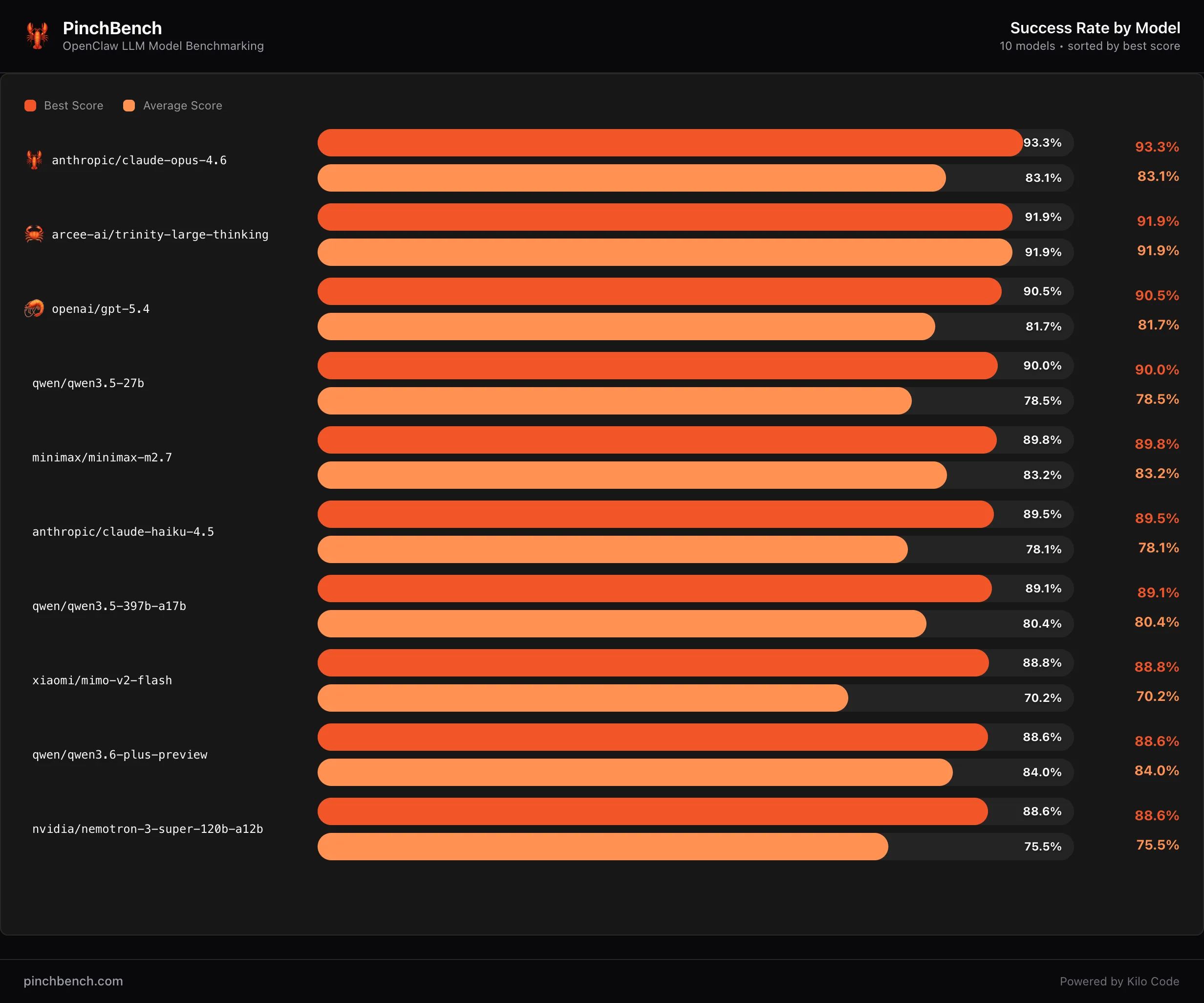
Benchmarks and Rankings
The model has demonstrated strong performance in
PinchBench
, a benchmark designed to evaluate model capability in environments relevant to autonomous agents.
Currently, Trinity Large Thinking holds the
#2 spot
on PinchBench, trailing only behind
Claude Opus-4.6
.
Technical Specifications
Context Window:
The model supports a
262,144-token context window
(as listed on
OpenRouter
), making it capable of processing massive datasets or long conversational histories for agentic loops.
Multi-Turn Reliability:
The training focused heavily on multi-turn tool use and structured outputs, ensuring that the model can call APIs and extract parameters with high precision over many turns.
Key Takeaways
High-Efficiency Sparse MoE Architecture
: Trinity Large Thinking is a 400B-parameter sparse Mixture-of-Experts (MoE) model. It utilizes a 4-of-256 routing strategy, activating only
13B parameters per token
during inference to provide frontier-scale intelligence with the speed and throughput of a much smaller model.
Optimized for Agentic Workflows
: Unlike standard chat models, this release is specifically tuned for
long-horizon tasks
, multi-turn tool calling, and high instruction-following accuracy. It currently ranks
#2 on PinchBench
, a benchmark for autonomous agent capabilities, trailing only behind Claude 3.5 Opus.
Expanded Context Window
: The model supports an extensive context window of
262,144 tokens
(on OpenRouter). This allows it to maintain coherence across massive technical documents, complex codebases, and extended multi-step reasoning chains without losing track of early instructions.
True Open Ownership
: Distributed under the
Apache 2.0 license
, Trinity Large Thinking offers ‘True Open’ weights available on Hugging Face. This permits enterprises to audit, fine-tune, and self-host the model within their own infrastructure, ensuring data sovereignty and regulatory compliance.
Advanced Training Stability
: To achieve frontier-class performance with high capital efficiency, Arcee employed the
Muon optimizer
and a proprietary load-balancing technique called
SMEBU
(Soft-clamped Momentum Expert Bias Updates), which ensures stable expert utilization and prevents performance degradation during complex reasoning tasks.
Check out the
Technical details
and
Model Weight
.
Also, feel free to follow us on
Twitter
and don’t forget to join our
120k+ ML SubReddit
and Subscribe to
our Newsletter
. Wait! are you on telegram?
now you can join us on telegram as well.





