五度妙笔
五度妙笔 API商城
API商城
 数据库
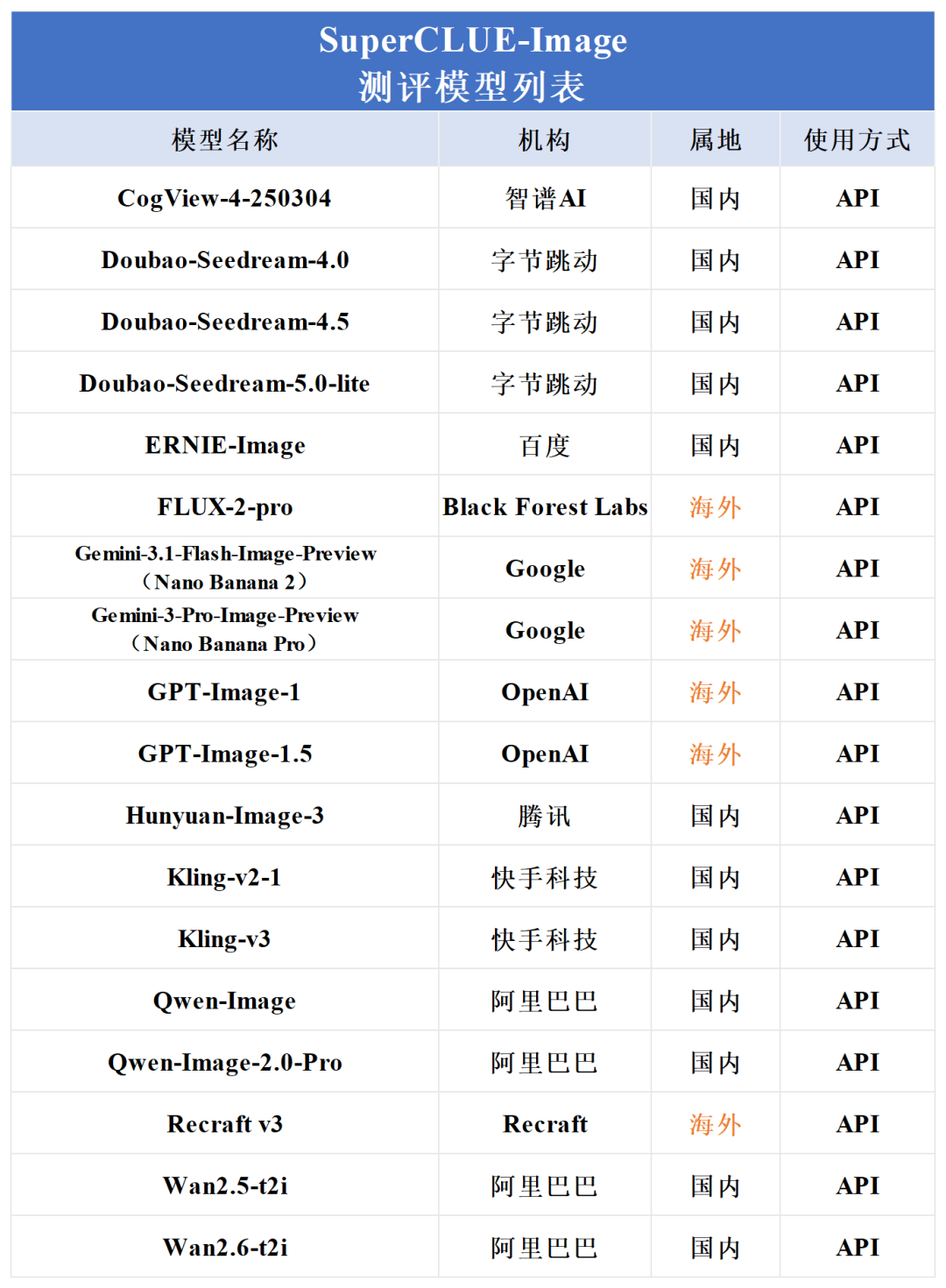
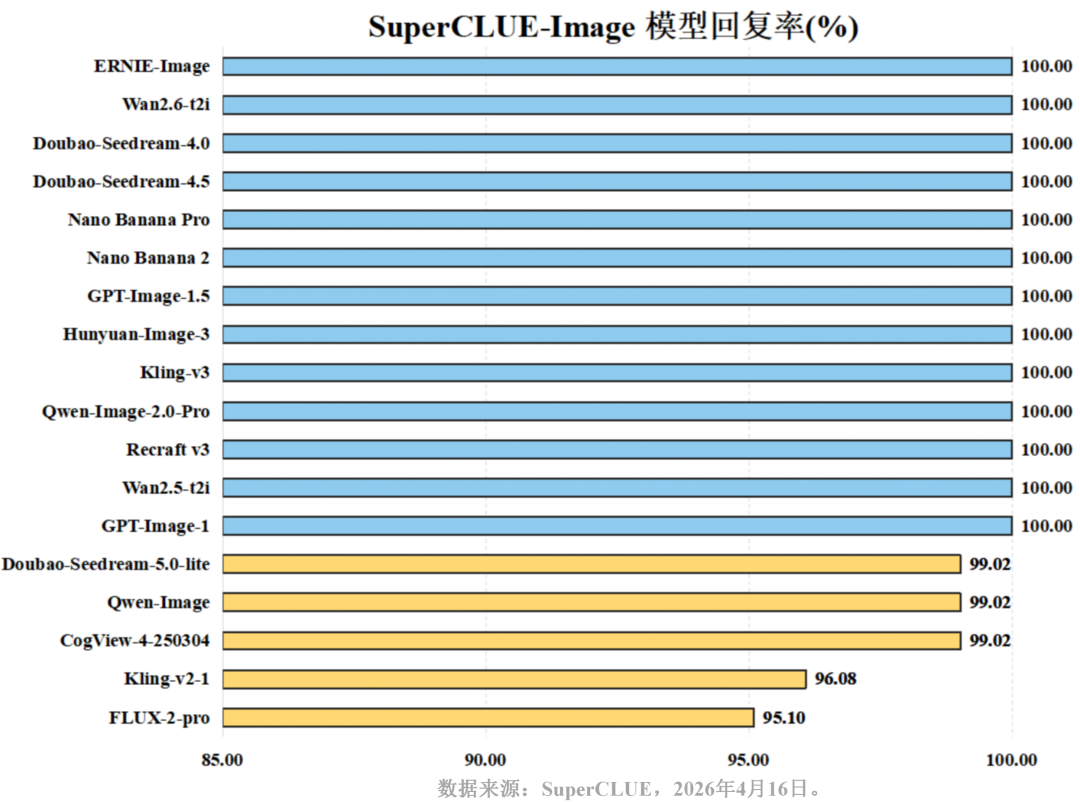
数据库4月文生图中文榜单发布 | 百度ERNIE-Image登顶国内第一,Nano Banana2保持领跑!

2026年4月,SuperCLUE-Image 中文原生文生图最新测评榜单发布。本次沿用SuperCLUE-Image最新测评基准,在 “基础能力 + 应用能力” 多维测评框架下,覆盖图像质量、现实复现、创作与推理等关键维度,并进行人类一致性评估。
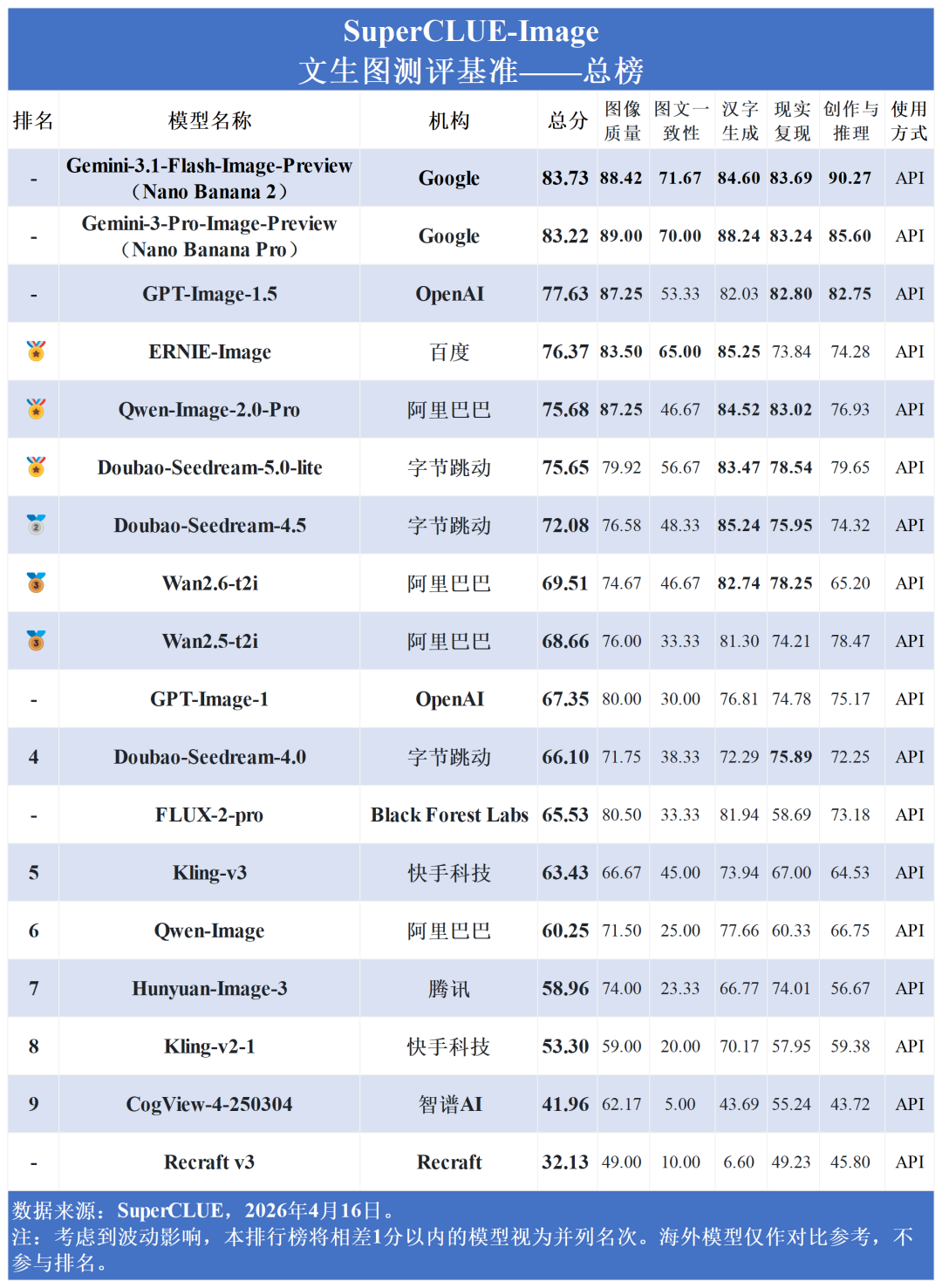
本次评测涵盖了国内外18个具有代表性的文生图模型,并对其综合能力进行了深入测评。以下为详细测评报告:
「过往文章介绍」
1.【2026年3月SuperCLUE-Image 文生图测评榜单参考文章】3月文生图榜单发布!Nano Banana2断层领跑,千问、字节强势追赶!
2.【2025年11月SuperCLUE-Image 文生图测评榜单参考文章】11月文生图月榜:Nano Banana Pro 领跑,国内头部厂商跻身前五
提示词:以 “麦浪载旧梦” 为核心意象,创作一幅复古胶片风格的画面:微风拂过麦田时麦浪起伏的弧度,裹挟着童年奔跑时扬起的麦香,傍晚橘粉色霞光漫过麦穗的顶端,光影在饱满麦粒上流动的轨迹,像被岁月磨洗过的旧相册里泛着暖黄的一页。

国内头部模型生成(创作与推理—意象表达)
测评核心内容摘要
摘要1:海外领先,国内厂商强力追赶!
摘要2:各能力分化明显:基础画质内卷,语义理解仍是行业分水岭。
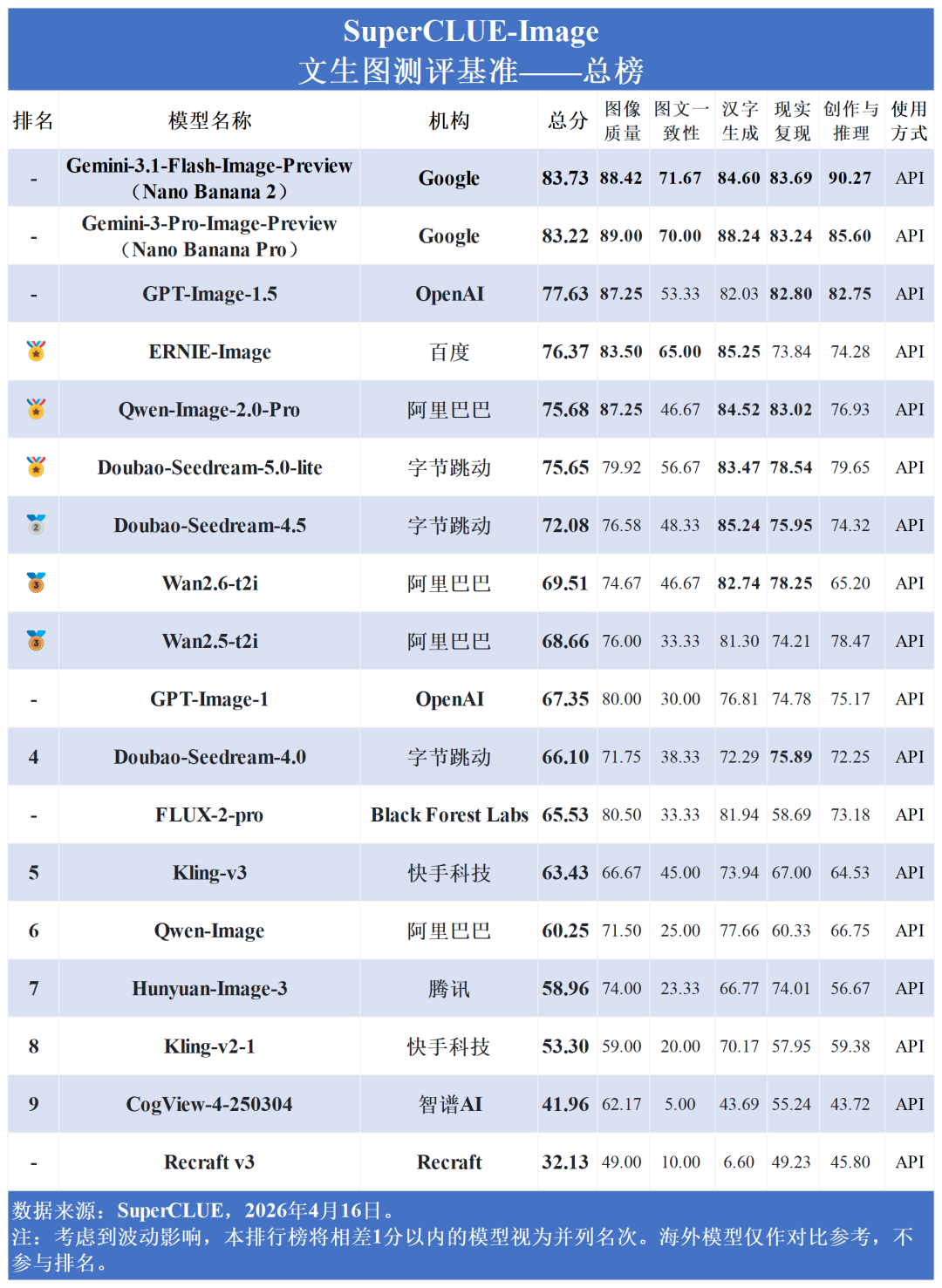
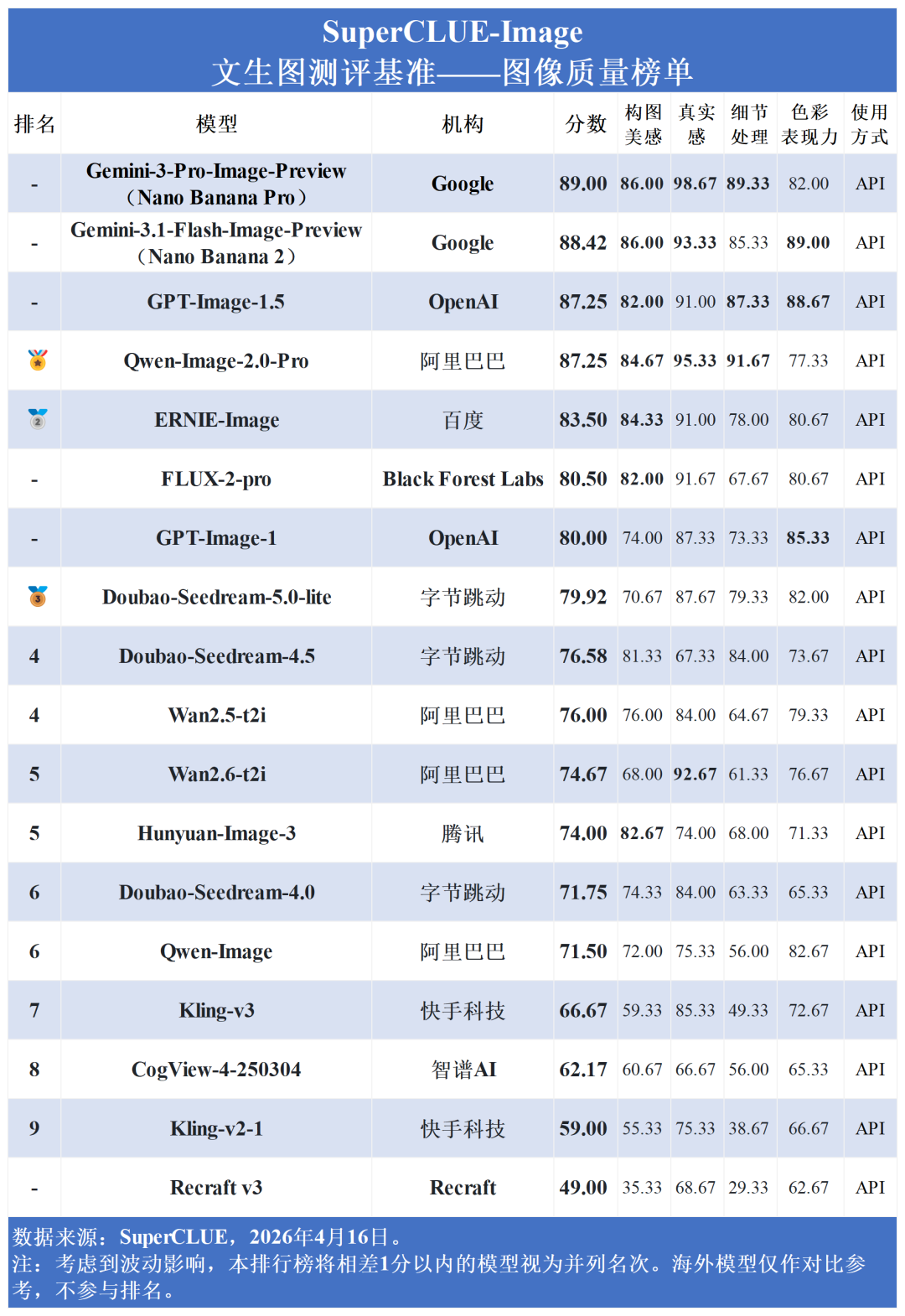
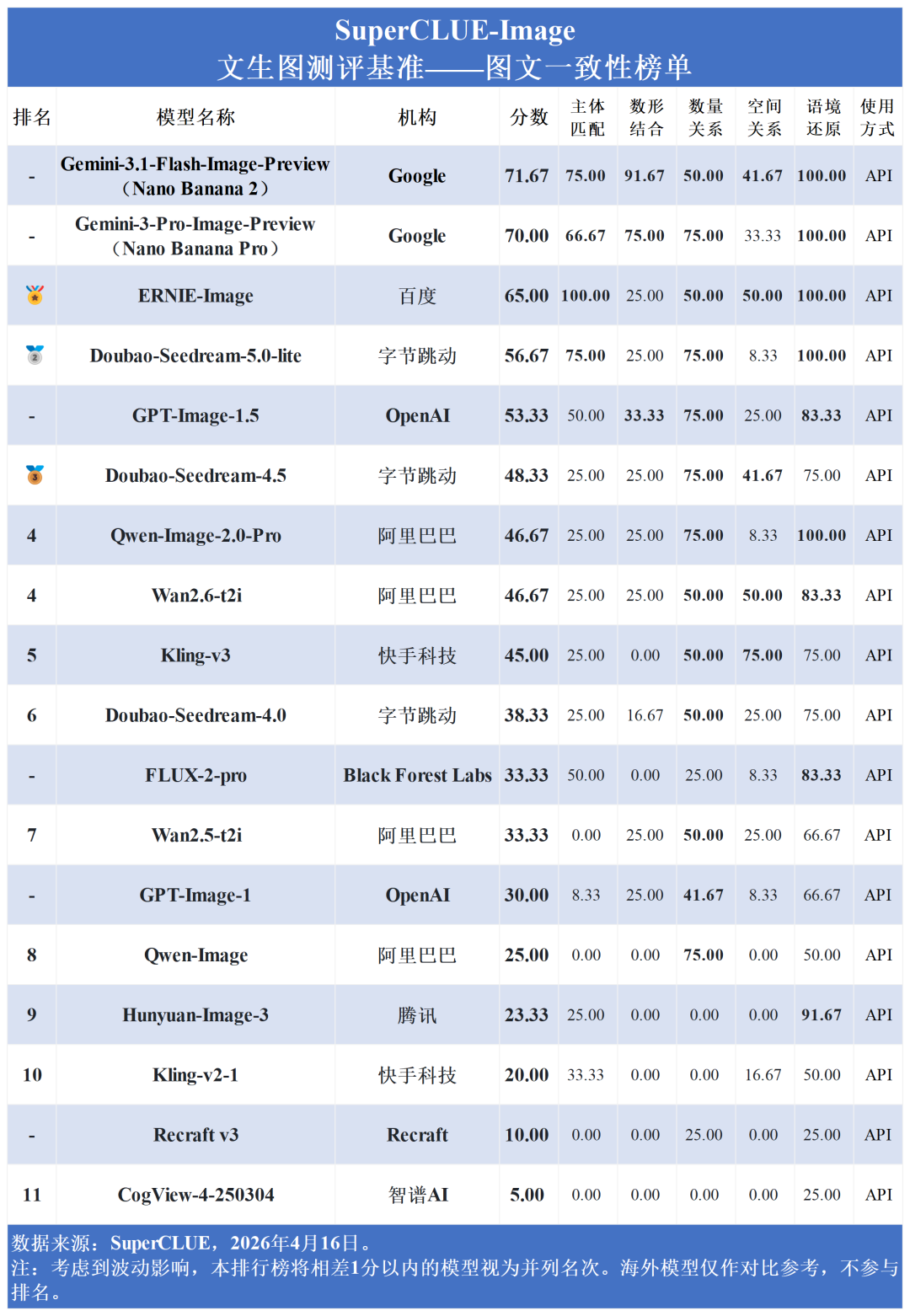
在图像质量上,Gemini系列最高达 89.00 分,GPT-Image-1.5 与阿里的 Qwen-Image-2.0-Pro 均以 87.25 分紧随其后;然而在图文一致性上,行业整体出现明显断层,除 Gemini 系列(最高71.67分) 与 ERNIE-Image (65.00分) 表现较好外,其余模型如 Doubao-Seedream-5.0-lite (56.67分) 和 GPT-Image-1.5 (53.33分) 均出现明显掉队。
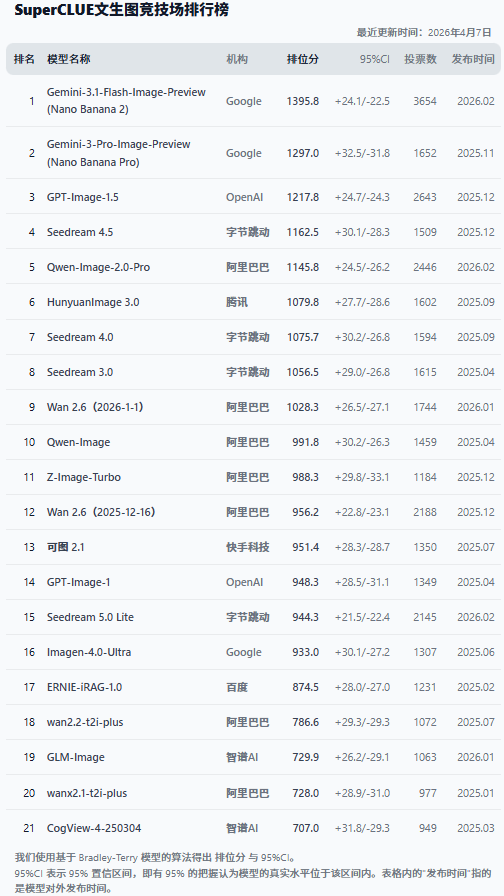
# SuperCLUE 文生图中文竞技场排行榜
本竞技场是一个大众投票的匿名评测平台,榜单汇聚最新投票数据,定期更新排名。诚邀您参与评测,在原生中文语境下用实际体验为模型能力提供真实反馈,共同完善文生图模型的评估标准。
访问地址:https://www.superclueai.com
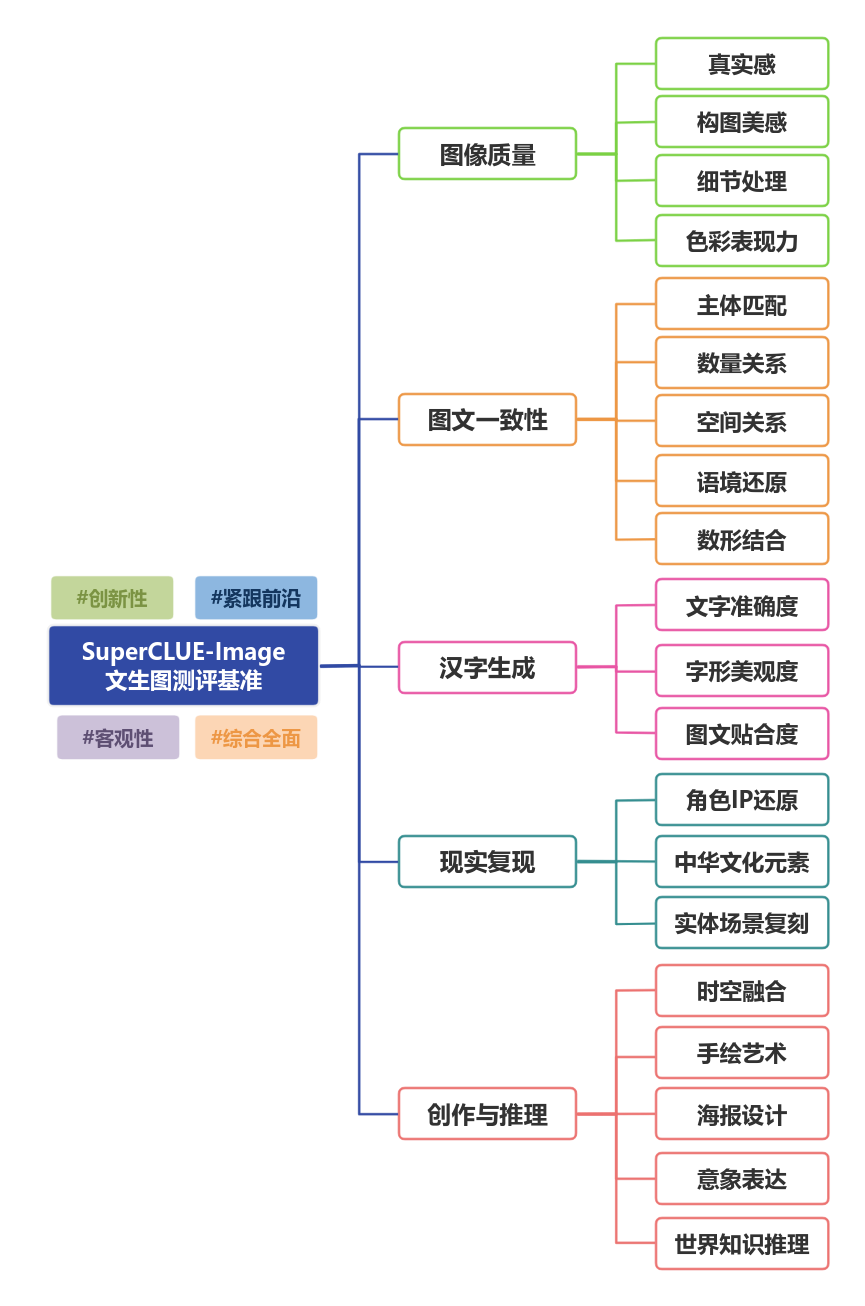
SuperCLUE-Image 是一个专为文生图模型设计的评测基准,旨在为文生图领域提供全面且多维的能力评估参考。
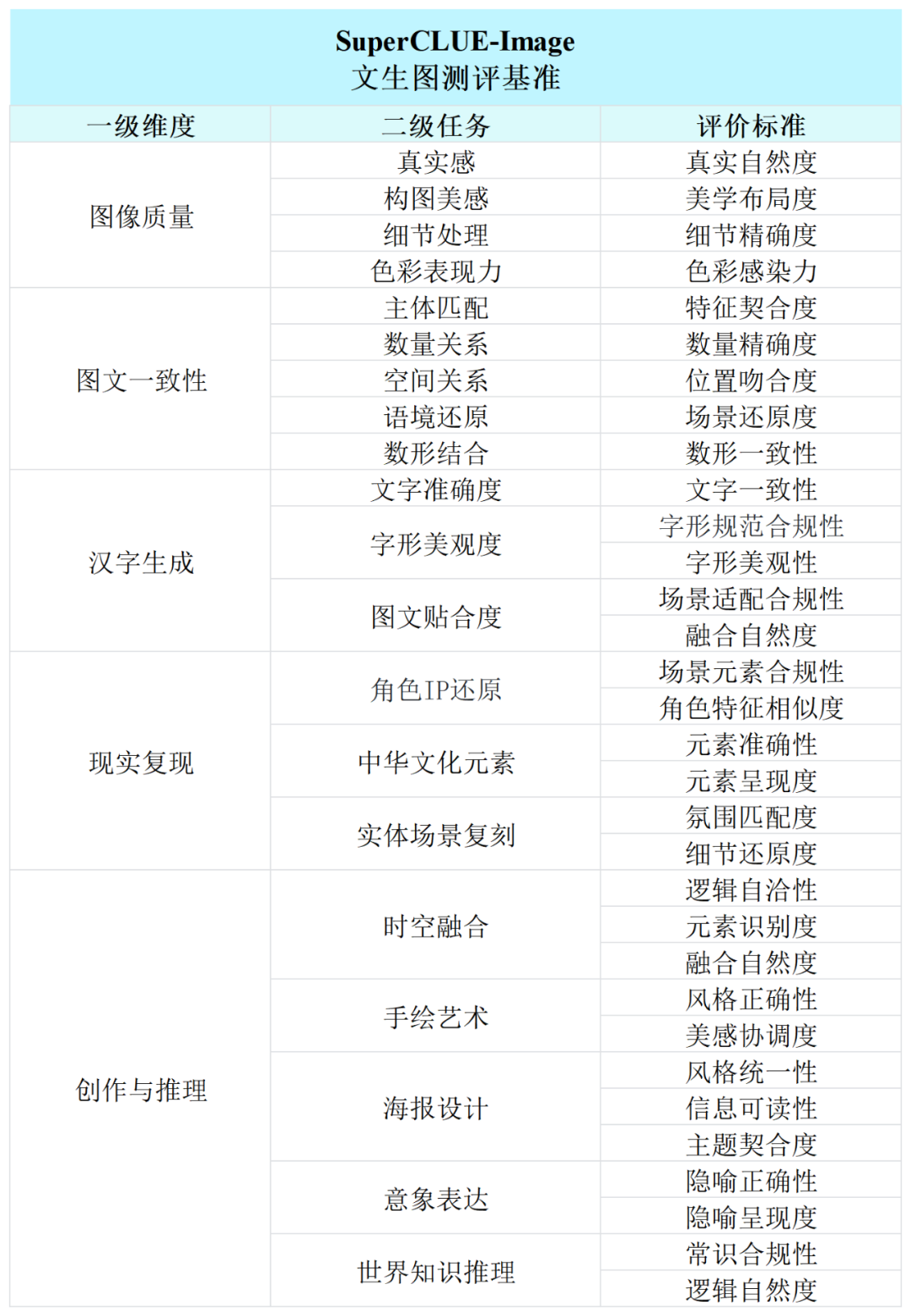
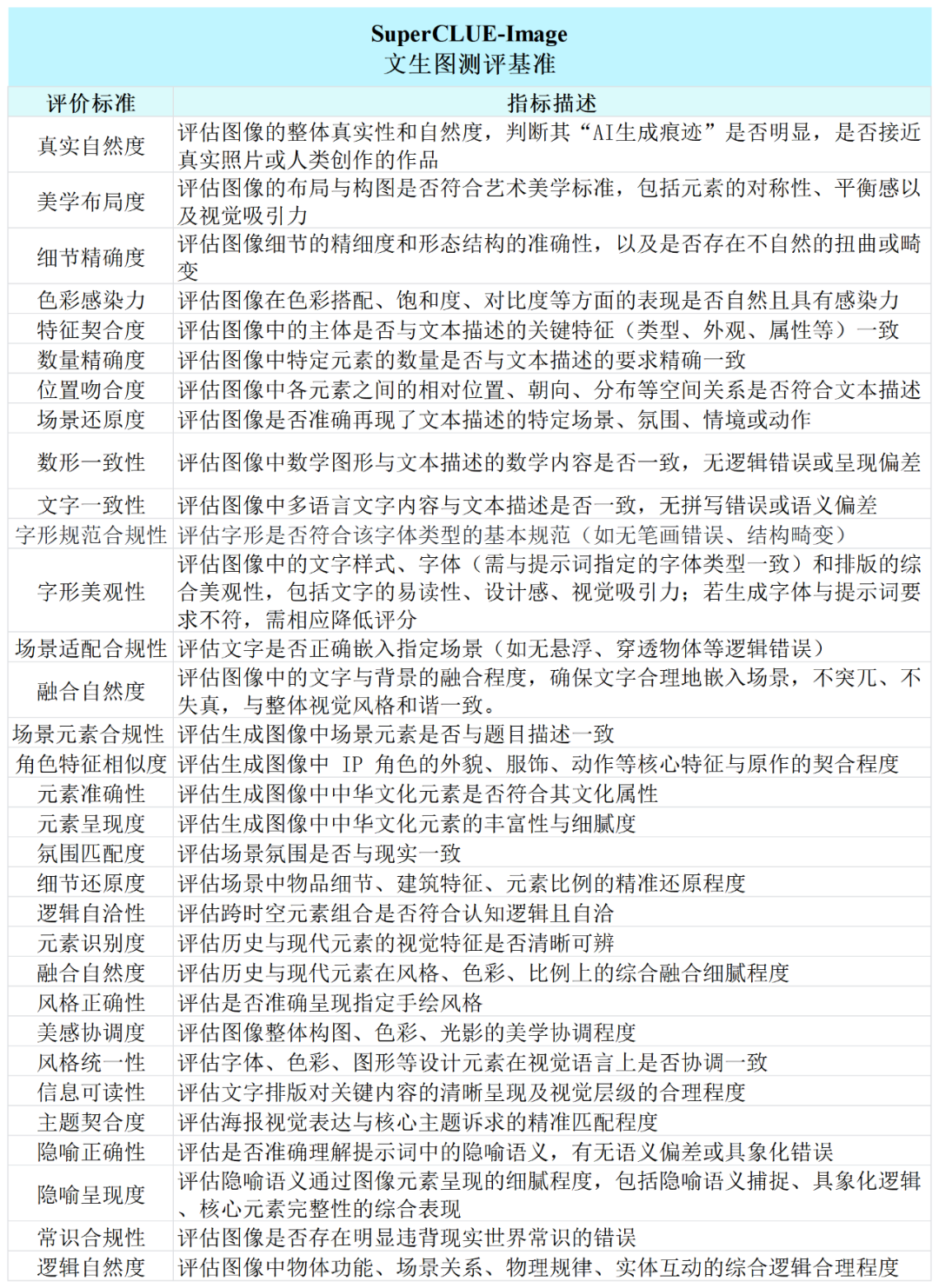
# 测评方法和评估示例
评估示例

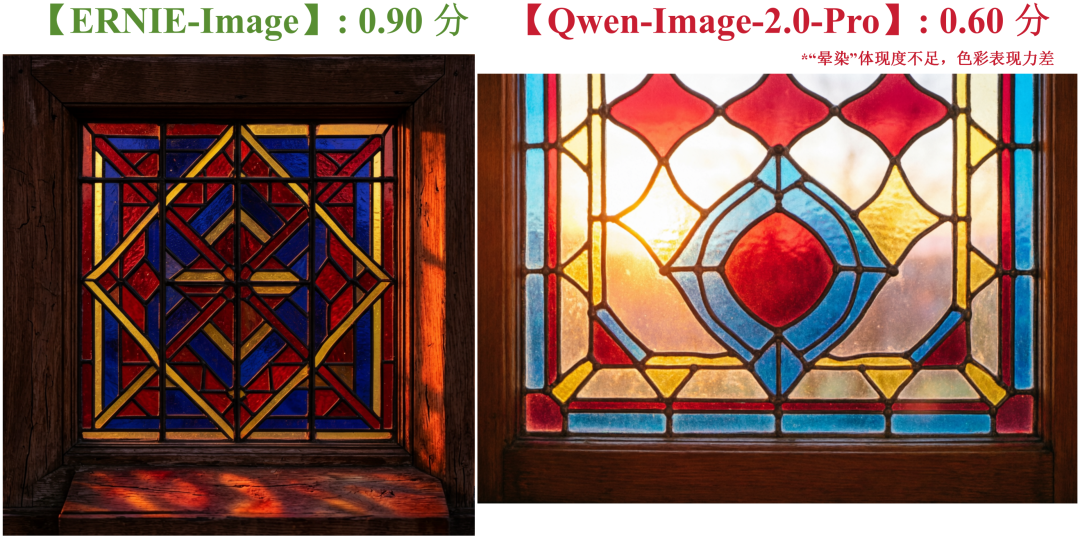
-----评价开始----- **初步质量定性 (0.0-1.0分档):** 优秀(0.8-1.0档) 1. **标准1 <色彩感染力> 的评价:** 图像在色彩感染力方面表现卓越。它成功地营造了一种柔和、明媚的午后阳光氛围。粉色和绿色的马卡龙色彩饱和度适中,显得非常自然可口,而非廉价的工业色素感。夹馅的焦糖色与饼壳形成了温暖的对比,金箔碎屑的金色在柔光下闪烁,起到了画龙点睛的作用,提升了画面的精致感。整个画面的色彩组合不仅美观,而且极具感染力,能够唤起观众对美味和闲适生活的美好联想。 然而,基于极度严格的评估标准,必须指出其与Prompt描述的细微色彩偏差。夹馅的颜色更接近焦糖色而非“杏色”,托盘为米白而非“白色”。这些偏差虽然不影响整体美感,甚至可能是一种更优的艺术处理,但构成了与指令的不完全吻合。因此,无法给予满分。 - **为何不能给更高分(如1.0)**:因为在“杏色”夹馅和“白色”托盘这两个具体的色彩指令上,执行得不够精确,存在可感知的偏差。 - **为何比更低分要好(如0.8)**:尽管存在细微偏差,但图像整体的色彩和谐度、光影表现以及由此营造出的强大氛围感染力,已经达到了顶尖水平,远超“优秀”的门槛,接近完美。 基于标准1的得分:【0.9】 **综合得分计算:** 计算过程:(0.9) / 1 = 0.90 综合得分:【0.90】 -----评价结束----- 第二轮评价: -----评价开始----- **初步质量定性 (0.0-1.0分档):** 优秀(0.8-1.0档) 1. **标准1 <色彩感染力> 的评价:** 与<第一轮评价>类似,此略... 基于标准1的得分:【0.9】 **综合得分计算:** 计算过程:(0.9) / 1 = 0.90 综合得分:【0.90】 -----评价结束----- 第三轮评价: -----评价开始----- **初步质量定性 (0.0-1.0分档):** 优秀(0.8-1.0档) 1. **标准1 <色彩感染力> 的评价:** 与<第一轮评价>类似,此略... 基于标准1的得分:【0.9】 **综合得分计算:** 计算过程:(0.9) / 1 = 0.90 综合得分:【0.90】 -----评价结束-----
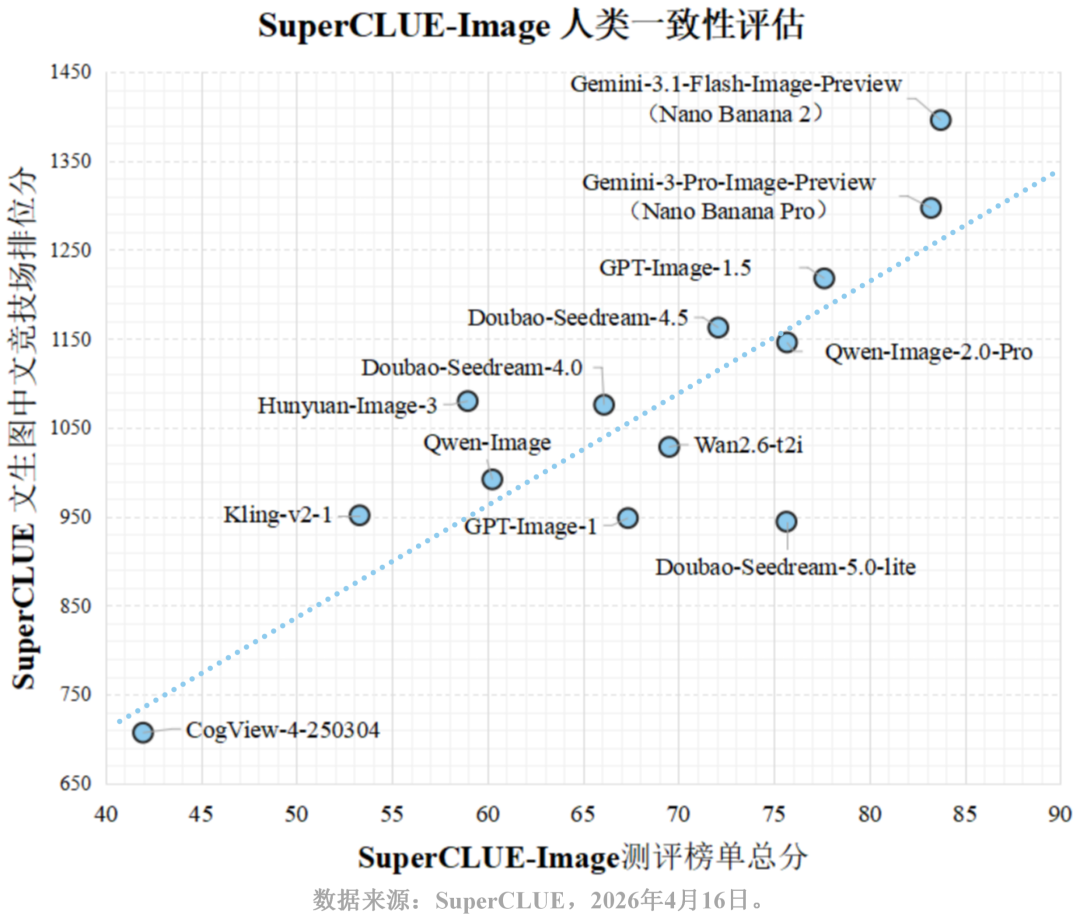
# 人类一致性评估
# SuperCLUE 文生图中文竞技场排行榜
为验证测评体系的公信力,我们将SuperCLUE文生图中文竞技场排位分与本次SuperCLUE-Image测评榜单总分进行交叉分析。结果显示,客观测评体系精准反映了真实用户的感官体验,具体统计指标如下:
皮尔逊(Pearson)相关系数: 0.8432,P值: 2.82e-04。表明测评分与排位分存在很强的正线性相关性,P值远小于0.05说明相关性极其显著。
斯皮尔曼(Spearman)相关系数: 0.7308,P值: 4.56e-03。表明测评分与整体保持高度一致,榜单排位具有较高可信度。




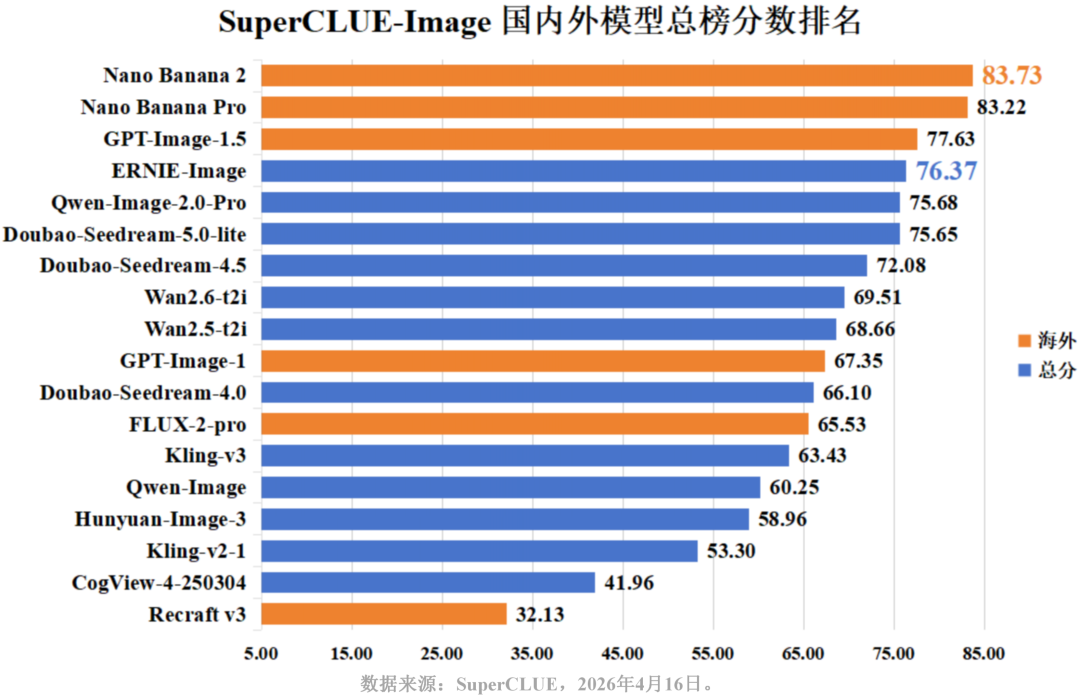
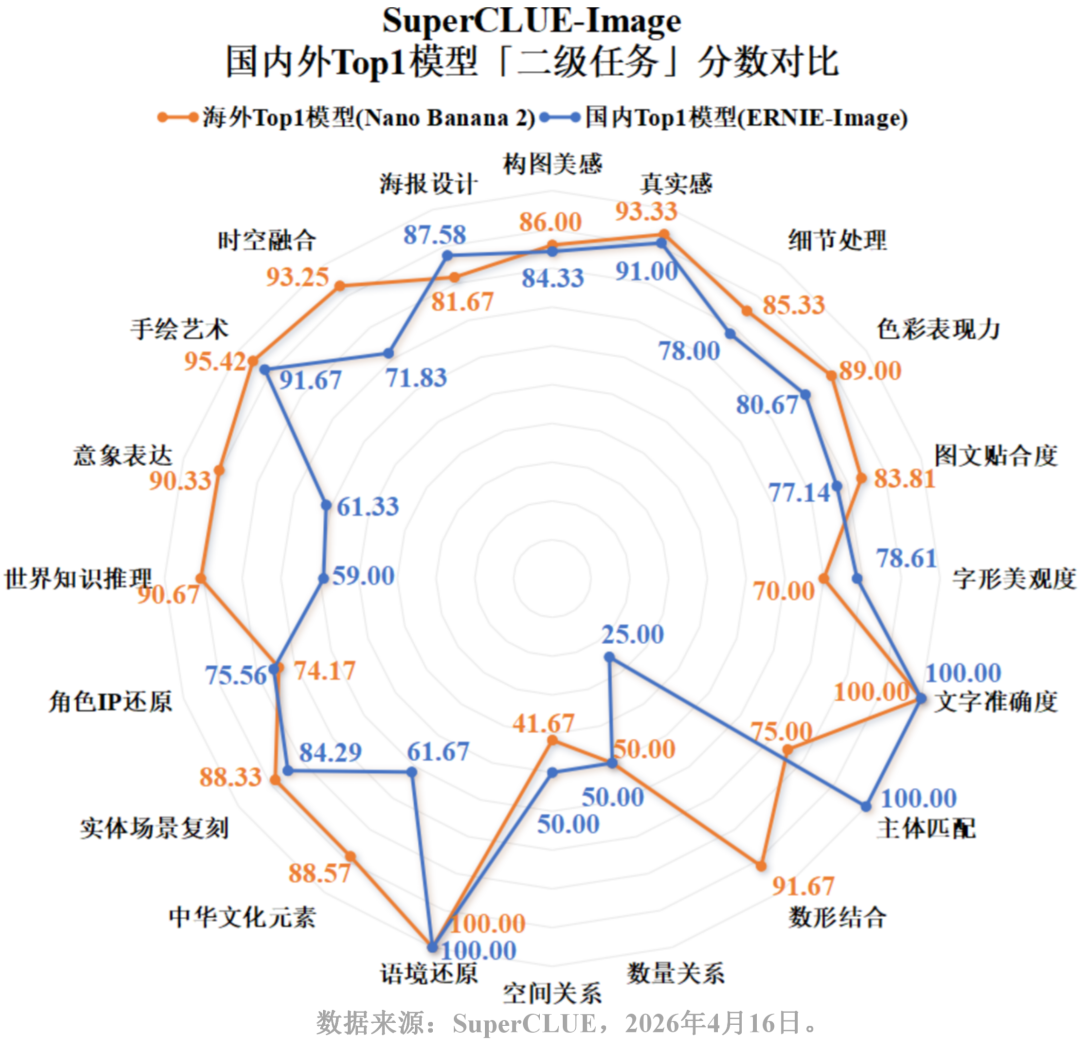
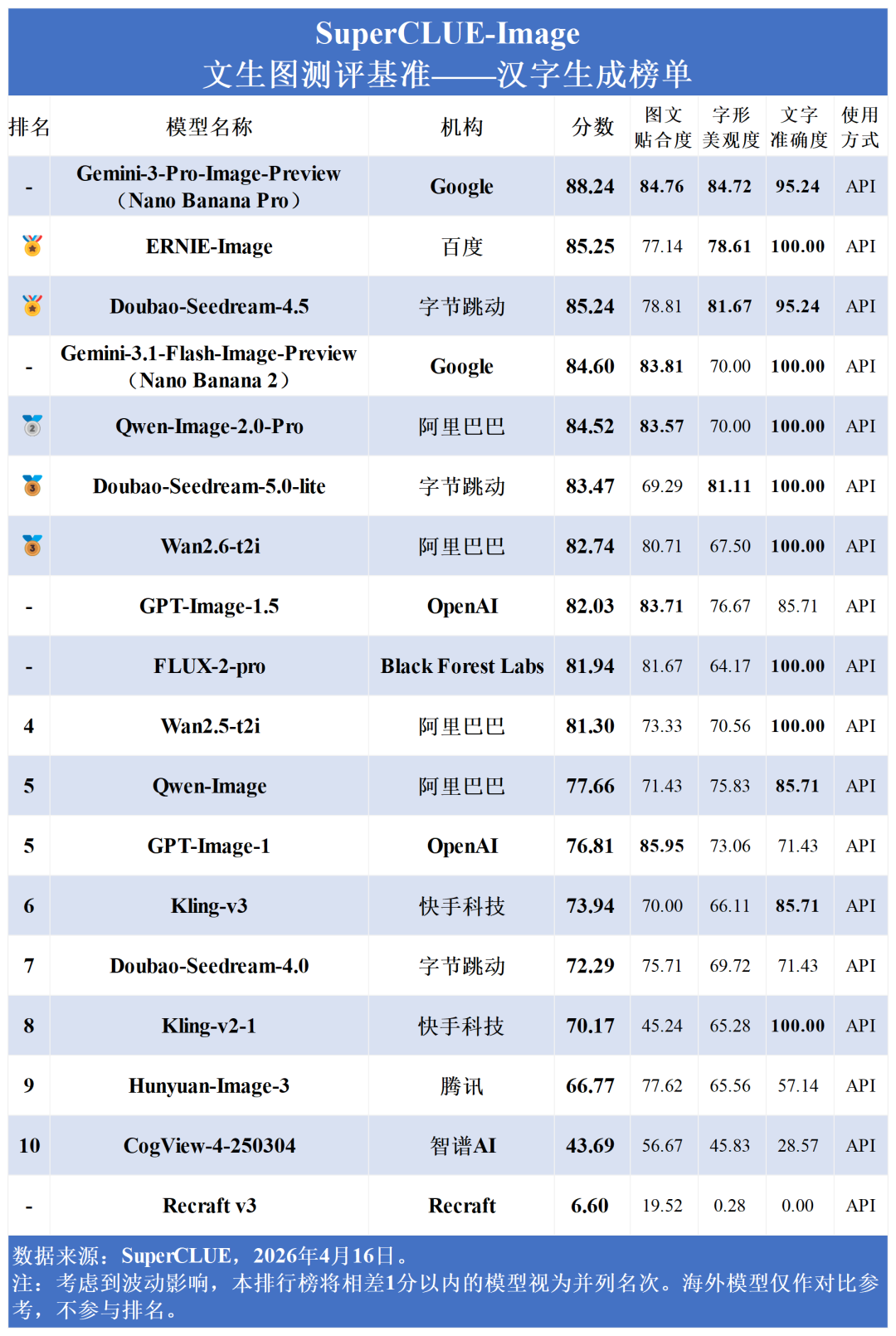
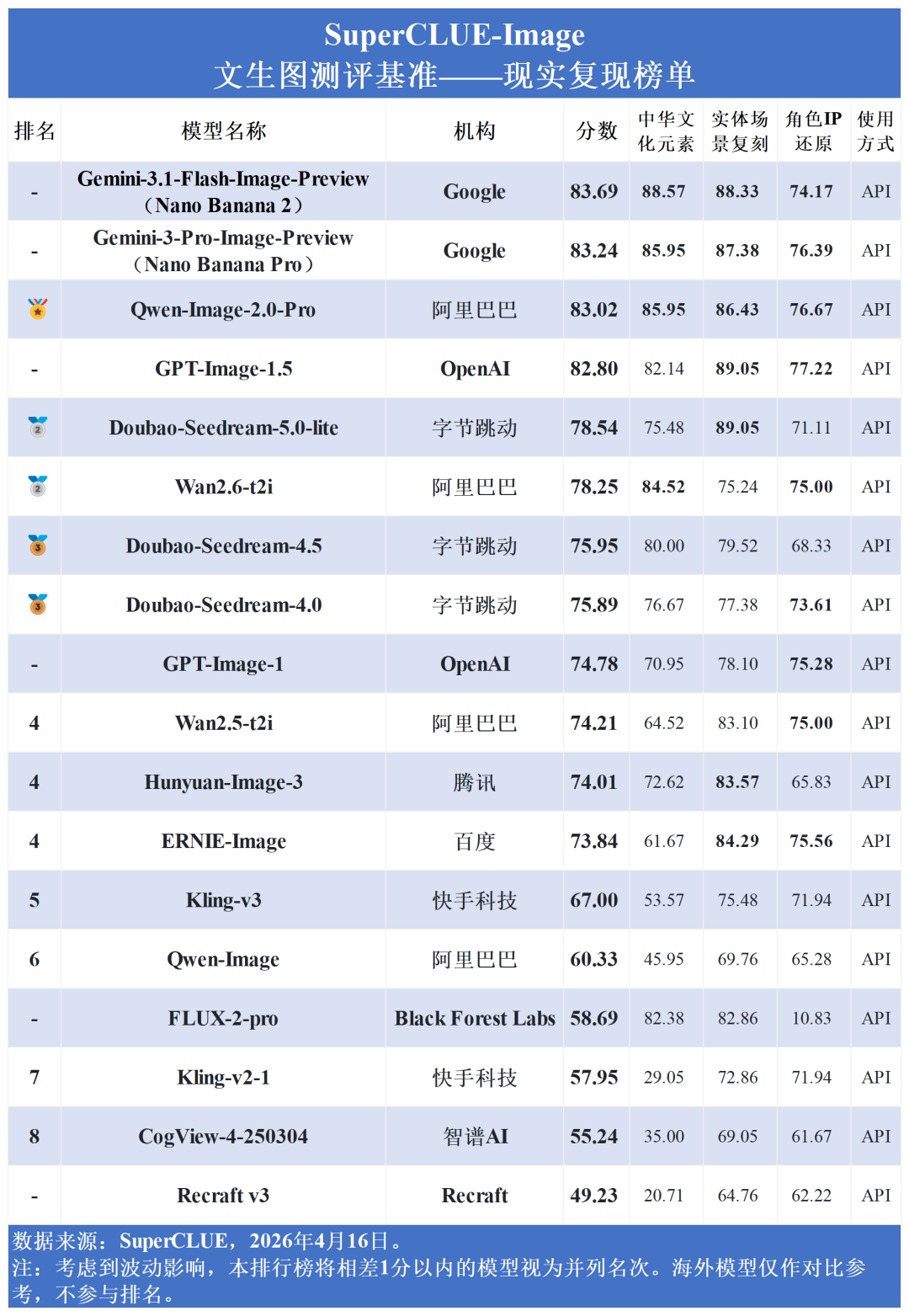
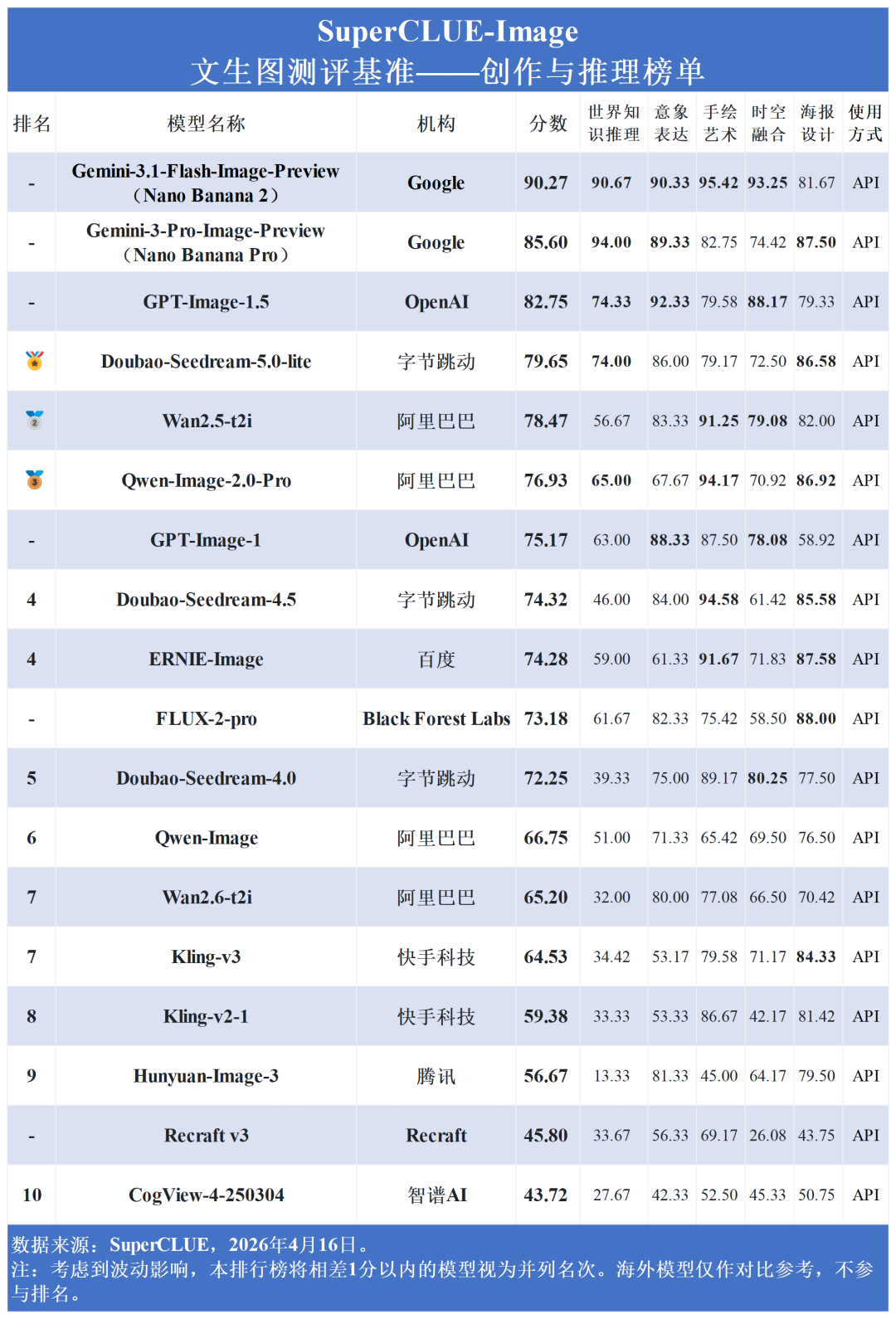
从国内外对比来看,国内大模型在汉字生成上稳稳压制海外(75.59 > 70.04);在现实复现 (71.19 vs 72.07) 上,国内外差距已压缩至不足1分;而在图像质量 (73.58 vs 79.03) 、创作与推理(67.68 vs 75.46) 上,国内模型正稳步缩小差距。然而,在图文一致性上,国内平均分 (37.78) 显著落后于海外 (44.72),说明在复杂语义的精准理解上,国内模型仍有较大进步空间。
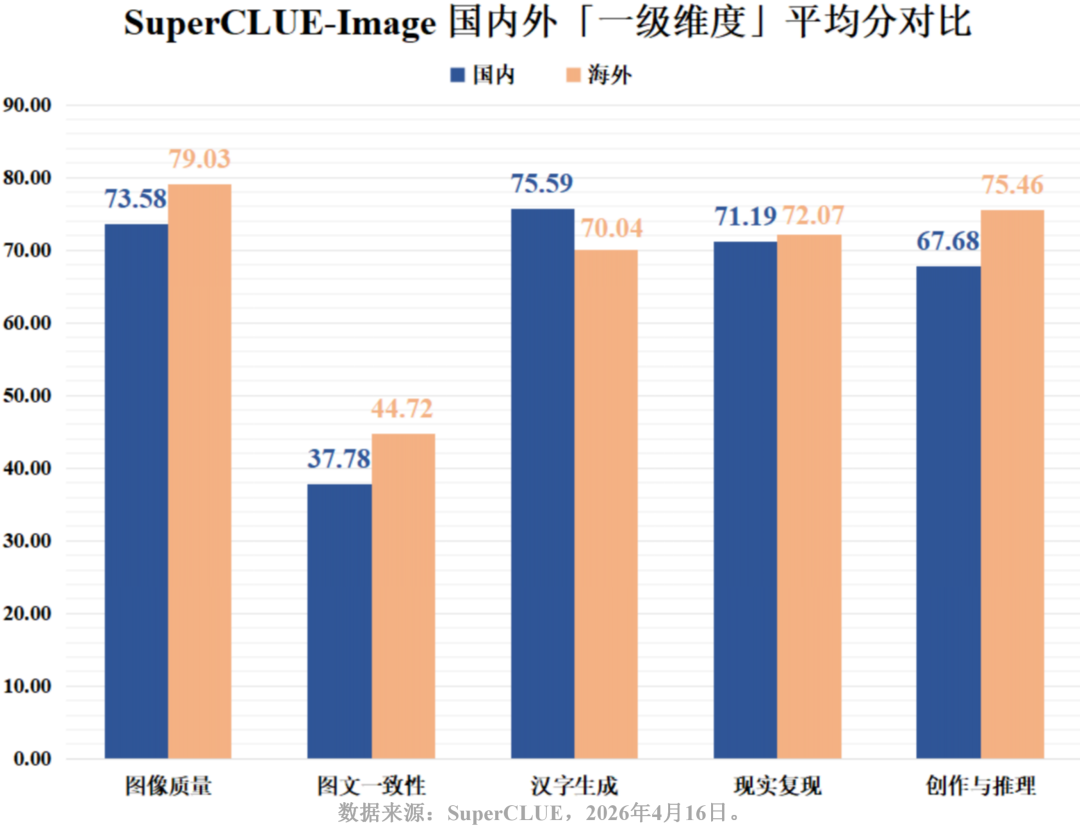
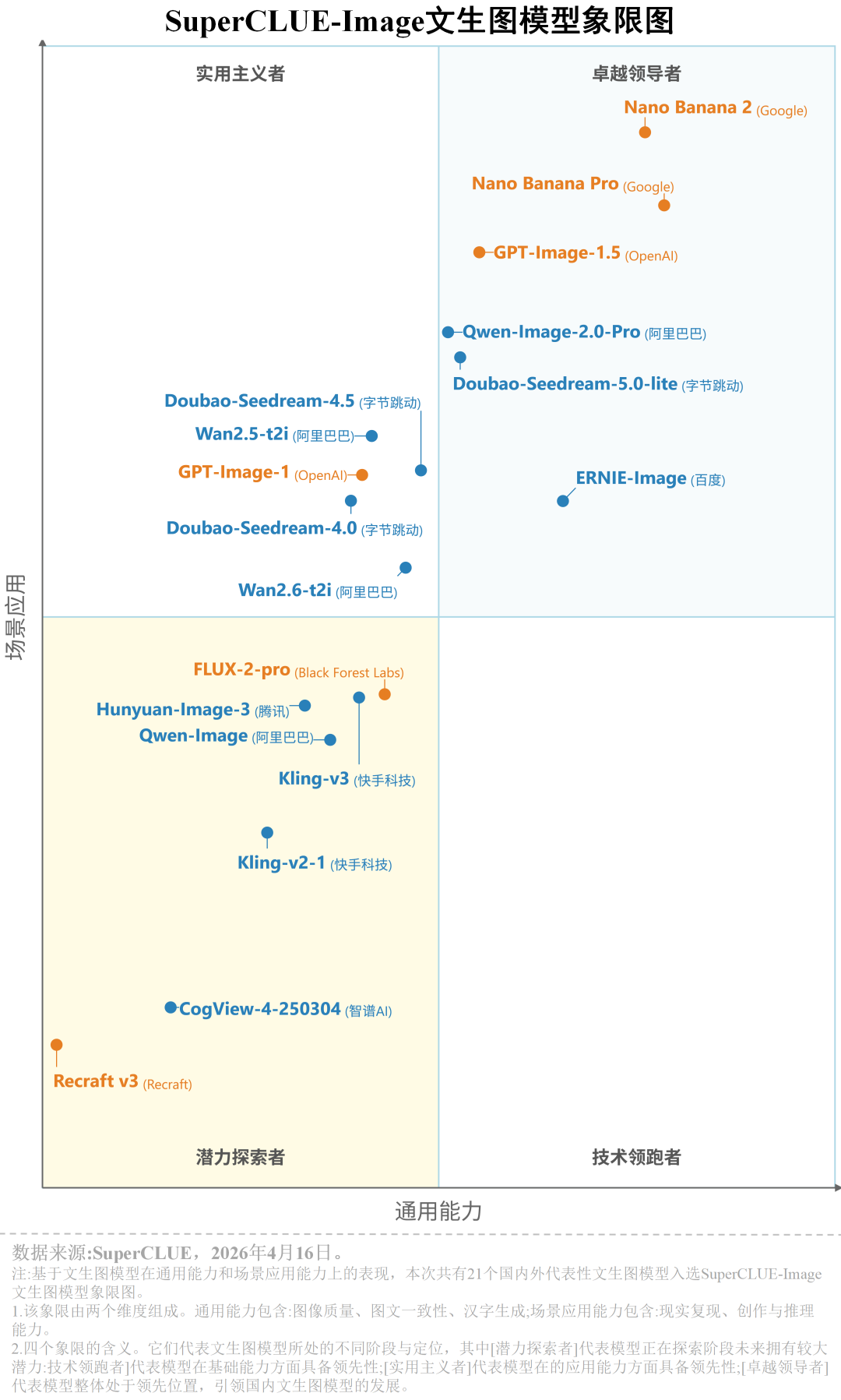
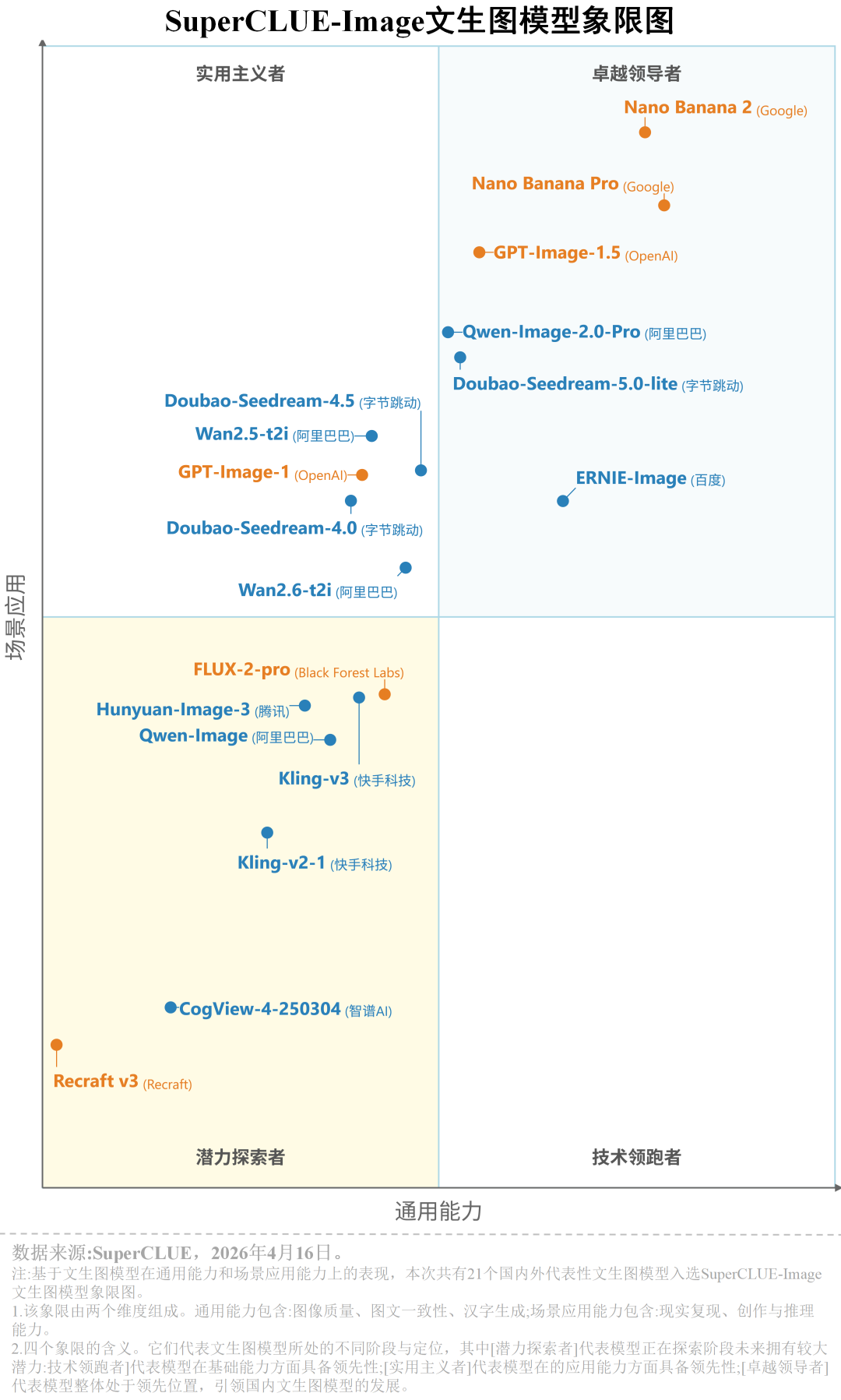
综合各维度头部排名与行业二级任务得分来看,当前文生图模型的发展呈现出极其严重的“偏科”现象,各维度领跑者分化明显:
图像质量与创作推理:海外模型占据统治地位。Gemini系列在两项均包揽前两名 (最高分别达89.00分与90.27分),GPT-Image-1.5稳居第三。国内ERNIE、Qwen与Doubao紧随其后。
汉字生成:国内外同台竞技,高内卷。海外Gemini 3 Pro(88.24分)领跑,国内ERNIE-Image (85.25分) 与 Doubao-Seedream-4.5 (85.24分) 紧咬比分。
图文一致性:行业难点。除Gemini系列维持在70分以上、国内ERNIE-Image以65.00分逆势破局杀入前三外,其余国内外主流模型均在50分左右徘徊,部分甚至跌破30分。
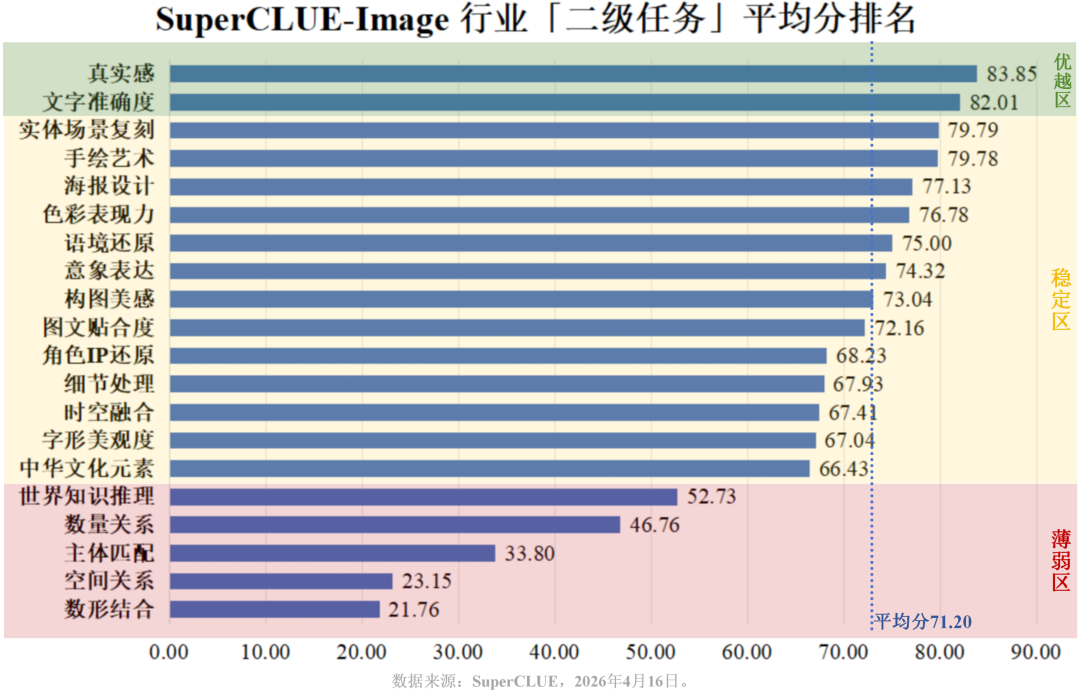
从行业二级任务平均分排名图可以看出,优越区的能力主要为纯视觉、具象特征任务,如“真实感”(83.85)与“文字准确度”(82.01)均超80分;然而,在严谨逻辑约束的薄弱区,分数呈现断崖式下跌:“世界知识推理”(52.73)、“数量关系”(46.76),直至垫底的“主体匹配”(33.80)、“空间关系”(23.15)与“数形结合”(21.76)。