 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库刚刚,Claude Opus 4.7 发布!复杂Coding+视觉能力显著升级

Opus 4.6 苦主有救了。
这几天,打开 Claude 是一件需要勇气的事。
一边是模型降智,2 月 9 日 Opus 4.6 默认改成 adaptive thinking,3 月 3 日默认 effort 从满格降到 85,3 月 26 日 5 小时限额被偷偷加速消耗。另一边是服务宕机:3 月 17 日到 19 日连续三天出事故、4 月 4 日、6 日、一直到昨天 4 月 15 日全球大宕机,Anthropic 从美东时间 10:53 开始连发三次状态更新,拖到下午 1:42 才恢复。
新发的 Mythos 还不让人用,我半步都快踏入国产御三家之际,Opus 4.7 终于来了!
刚刚,Claude Opus 4.7 全面上线。Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 四大平台同步开放。价格不变,输入 5 美元、输出 25 美元每百万 token。
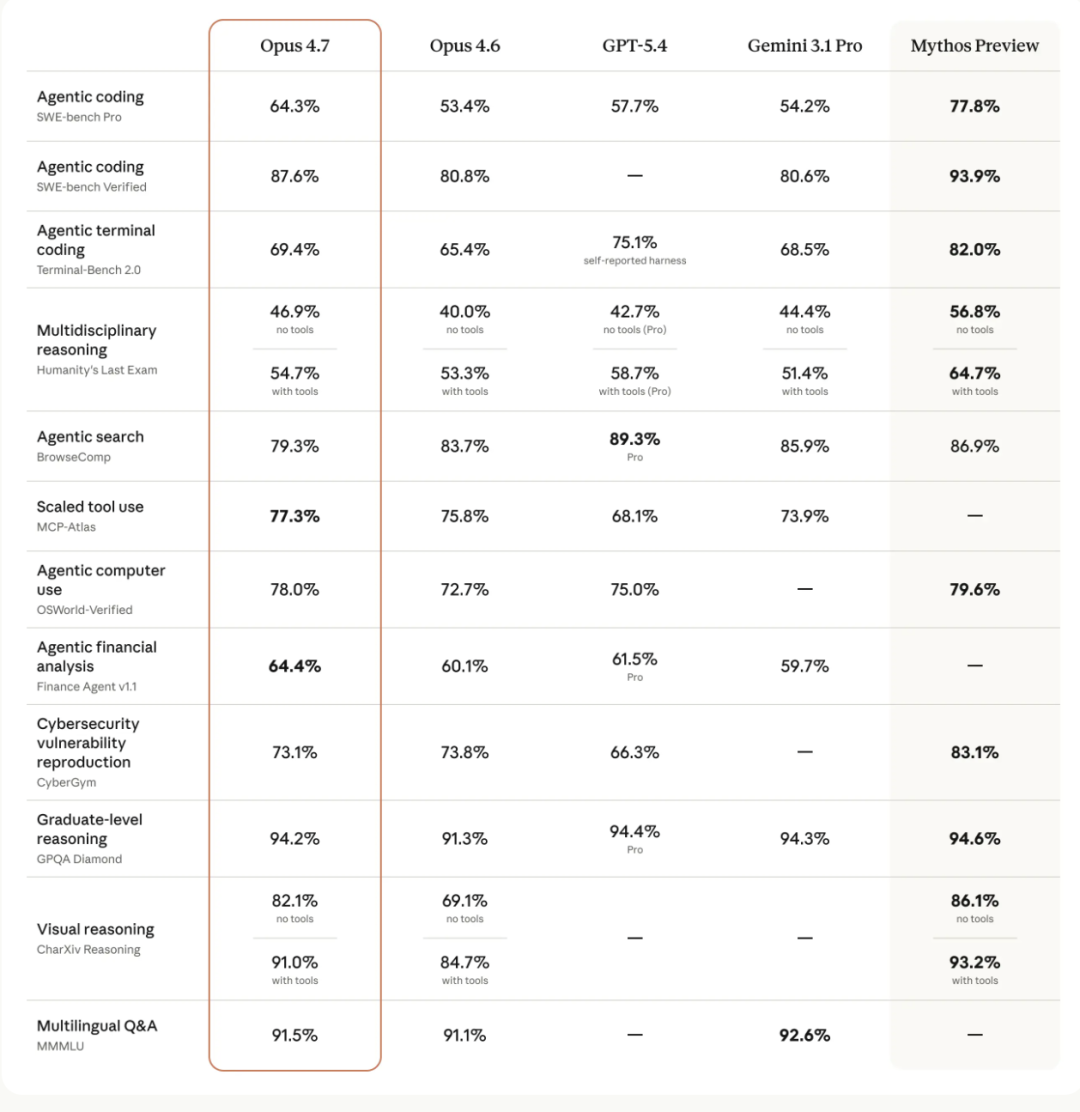
1、高级软件工程显著提升
Opus 4.7 在高级软件工程方面较 Opus 4.6 有了显著提升,尤其是在处理最困难的任务时表现尤为突出。
据用户反馈,他们现在可以放心地将以前需要密切监督的任务,交给 Opus 4.7 处理。Opus 4.7 能够严谨且一致地处理复杂的长期任务,精准遵循指令,并能在汇报结果前自行设计验证输出的方法。
长程任务上,Anthropic 拎出了 Vending-Bench 2 评测,让模型自己经营一家自动售货机,模拟真实的长期决策。最后,Opus 4.7 账上余额 10937 美元,Opus 4.6 只剩 8018 美元。
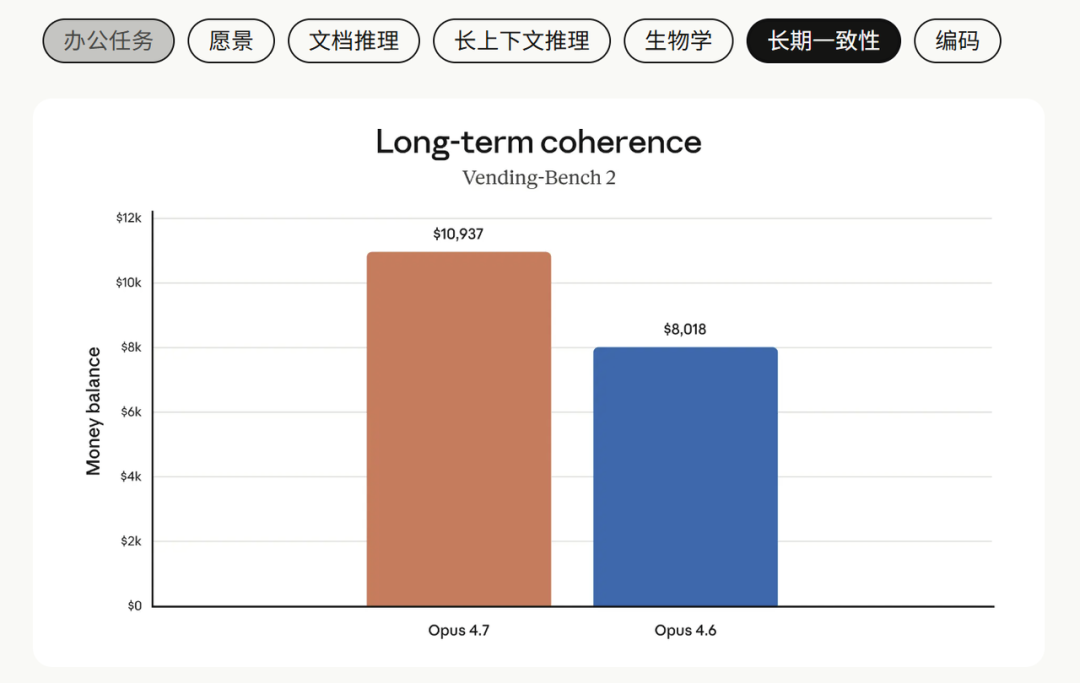
另外,长上下文推理上,新模型进步更明显。Parents 任务 75.1 对 71.1,BFS 任务 58.6 对 41.2。
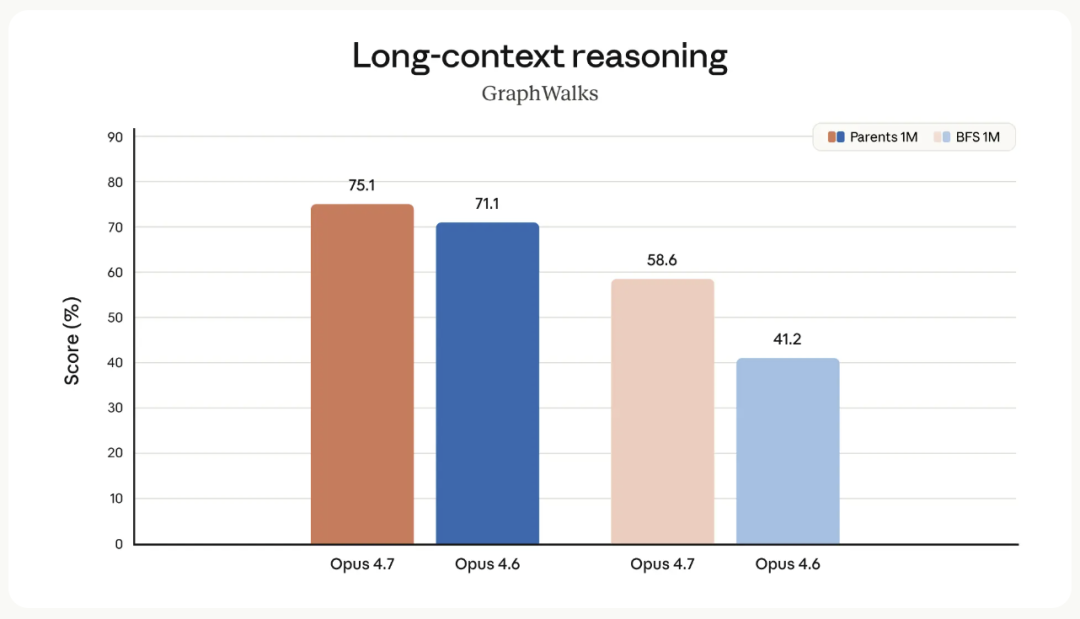
BFS 那一项,Opus 4.6 在 100 万 token 长度下已经掉到接近不及格,Opus 4.7 还能维持 58.6%。
算是刚需升级了。不过这次发布博客里还有一个细节:Opus 4.7 在 CyberGym(自主复现安全漏洞的评测)上,反而降低了。。Anthropic 承认这是训练时主动做的。
网安能力砍了一刀,认知能力有了提升。
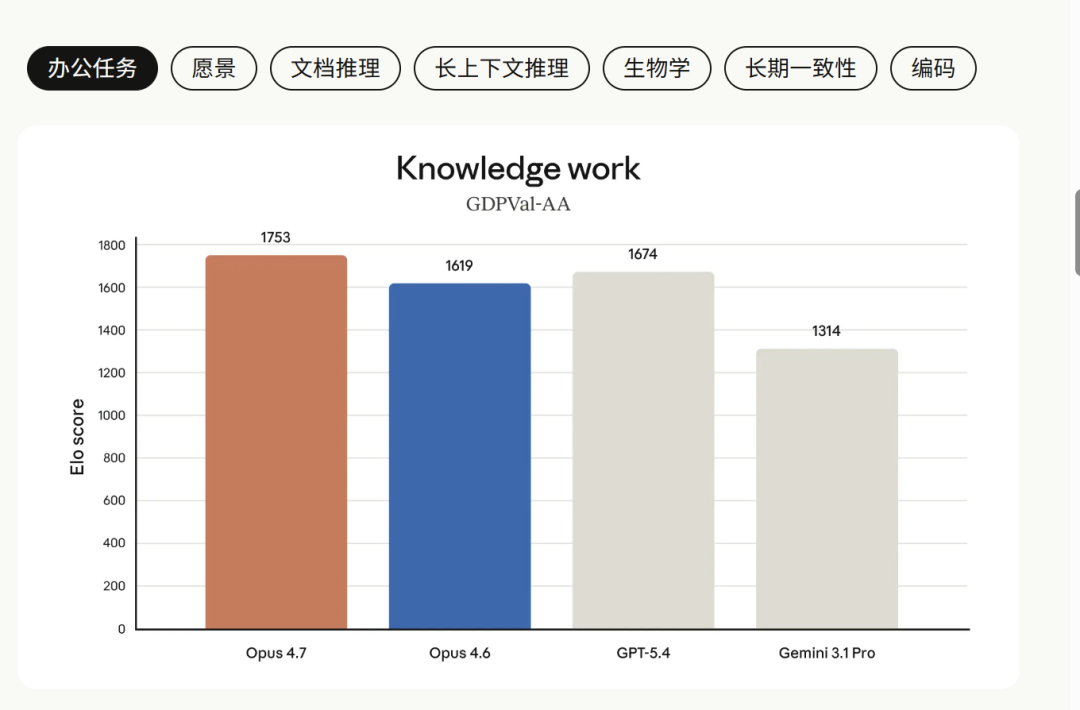
GDPval-AA 是第三方做的“经济价值知识工作”评测,Gemini 3.1 Pro 被 Opus 4.7 拉开了 439 分。Elo 分差超过 400 分意味着什么?在对弈评测里,前者胜率超过 90%。
OfficeQA Pro 这张图更离谱。Opus 4.7 拿到 80.6%,Opus 4.6 57.1%,GPT-5.4 51.1%,Gemini 3.1 Pro 42.9%。
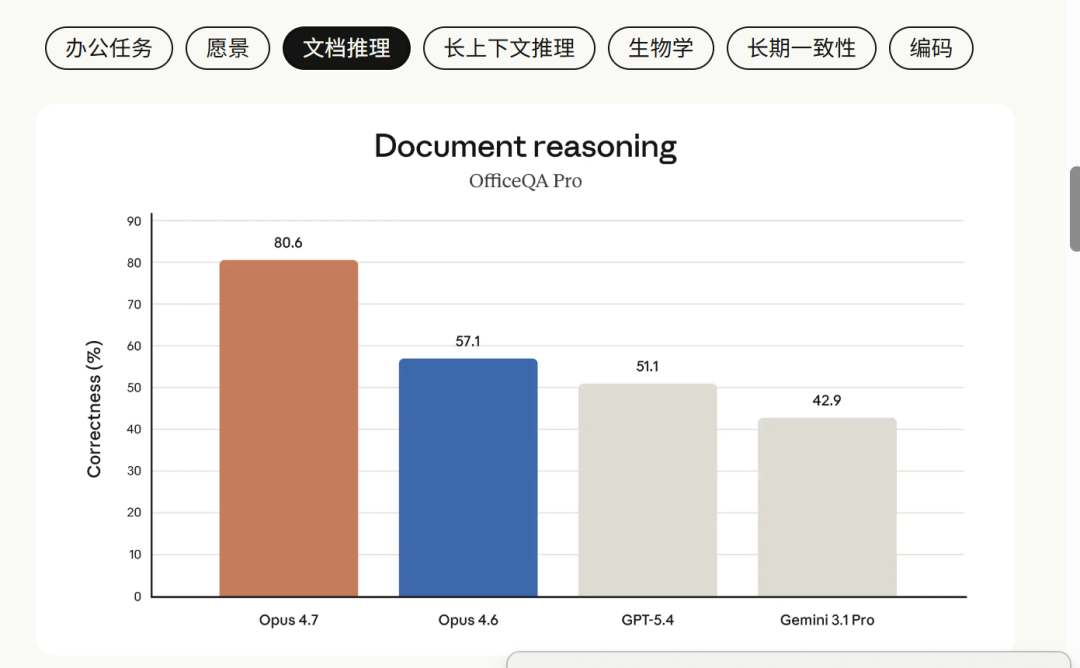
Gemini 3.1 Pro 连一半都没摸到,和 Opus 4.7 差了接近一倍。
所以写 PPT、搞财报模型、读复杂合同、做跨文档整合,这些听起来没什么新意的打工人日常,是能力提升最大的维度。
2、视觉能力大幅提升
上次,Anthropic 重点升级了计算机使用。这次,Opus 4.7 还把视觉模块大升级了一次。
Opus 4.7 支持识别长边 2576 像素的图片,约 3.75 百万像素——是之前 Claude 模型的 3 倍以上。
过去,AI 想看懂一张密密麻麻的截图、一份复杂的数据图表、一页带小字的 PDF,经常是“看得见,看不清”。3 倍分辨率上来之后,Computer Use Agent 就能真的能读到屏幕上的每一个按钮、每一行小字。
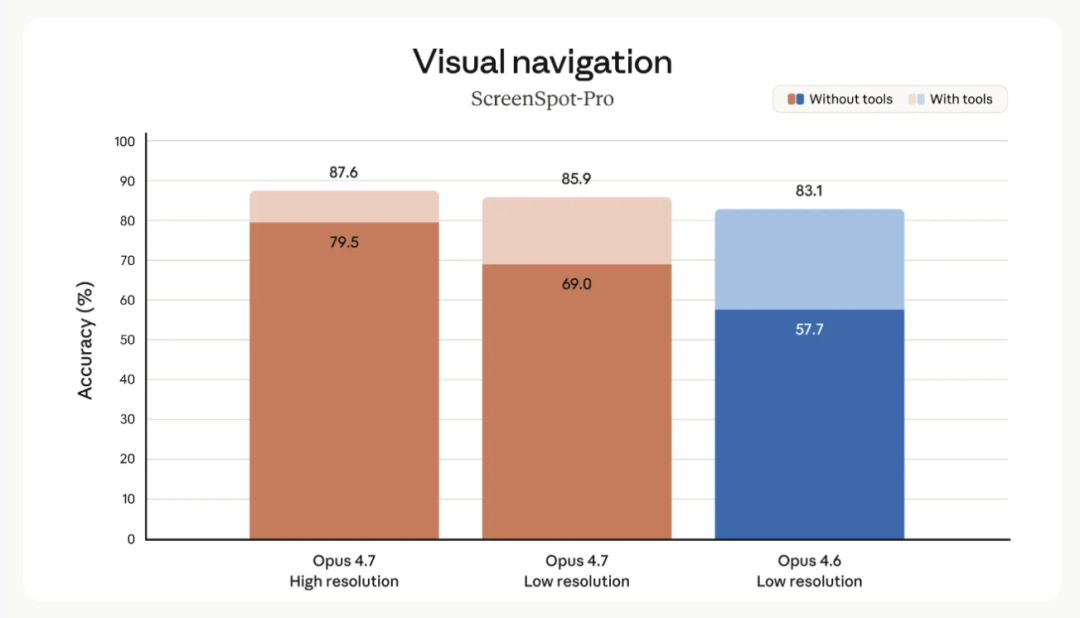
数据摆在这里:ScreenSpot-Pro 视觉导航,Opus 4.7 高分辨率下拿到 87.6%(with tools),低分辨率 85.9%,Opus 4.6 只有 83.1%。OSWorld-Verified 78.0% 对 72.7%。
这一刀下去,真正可用的屏幕 Agent,可能真要来。
3、Claude Code 升档,附带三件套
跟 Opus 4.7 一起上线的还有一批产品层的动作:
一是新的 xhigh 努力级别。夹在 high 和 max 之间,Claude Code 里所有 plan 默认已经调到 xhigh。官方推荐编码和 agent 场景从 high 或 xhigh 起步。
二是 /ultrareview 斜杠命令。专门开一个独立 review 会话,读完所有改动后给你挑出 bug 和设计问题。Pro 和 Max 用户免费送 3 次试用。
三是 auto mode 扩展到 Max 用户。Claude 替你做决策,长任务跑起来更少打断,但风险比"跳过所有权限"可控。
四是 task budgets 公测。API 层面给开发者一个工具,让 Claude 在长 run 里自己管 token 预算。
但迁移有一个坑要提前说。
Opus 4.7 换了新 tokenizer,同一段文字映射到的 token 数量大约是原来的 1.0 到 1.35 倍,高难度档位下模型还会多想一些。两个因素叠加,单次请求的 token 消耗大概率会涨。
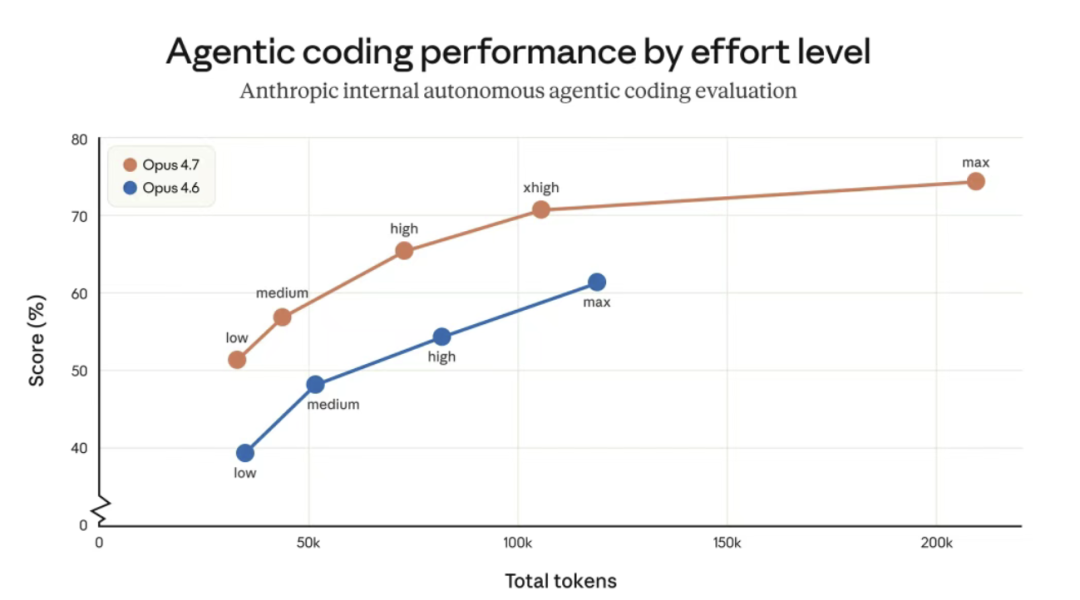
不过在同等任务得分下,Opus 4.7 各个 effort 级别的总 token 消耗反而更低。意思是模型虽然每次输入吃得多了,但干活更利索,总账算下来可能更划算。他们自己也加了一句实话:“建议在真实流量上实测一遍。”
还有一个变化:Opus 4.7 指令遵循能力大幅提升,代价是它会非常字面地执行指令。以前 Opus 4.6 会对模糊指令自己脑补,现在不脑补了。如果你有一套跑了很久的 prompt,升级后可能要重新调一轮。

最后最后,博客埋了一行容易漏掉的话:Opus 4.7 更擅长用文件系统做跨会话记忆。
它能在跨会话的长期工作里,把重要笔记存下来、读回来,然后用来推进新任务,需要用户事先喂给它的上下文更少。
算是在给 agent 系统铺长期记忆层了。
过去两个月,明明付了 Opus 的钱,我真的一直怀疑自己用的是不是 Sonnet。
不说了,我要去用新模型了,省得白天排队。







