 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库【技术综述与趋势】从 51 万行泄露源码,看 Anthropic 如何工程化落地 Agent 路由

摘要:2026 年 3 月 31 日,Anthropic 因一次发布流程中的配置失误,将 Claude Code 的 51.2 万行 TypeScript 源码意外公开。这次事件首次让外界完整看到,一个年收入 25 亿美元级别的 AI Agent 产品,在工程层面究竟是如何构建的。本文聚焦于其中最具学习价值的部分:路由设计。我们将从入口层到多智能体委派层逐层拆解,并与学界主流框架对照,最终回答一个核心问题:Claude Code 的路由设计里,有多少是新技术,有多少是工程化沉淀。答案对正在构建企业 AI 系统的团队,具有直接参考价值。
2026 年 3 月,Claude Code 因一次 .npmignore 配置遗漏,导致大规模工程源码外泄。Anthropic 将其定性为打包失误,而非安全攻击。围绕功能细节和彩蛋的讨论已相当充分,本文不再重复。我们更关注的是另一层价值:这套源码是否揭示了一种可复制的 Agent 架构范式?
五层架构全景
Claude Code 是一个完整的五层系统:
入口层(Entrypoints):CLI / Desktop / Web / IDE / SDK
运行层(Runtime):REPL 循环、状态机、Hook 系统
引擎层(Engine):QueryEngine、动态 Prompt 组装、上下文压缩
工具与能力层(Tools & Caps):40+ 权限受控工具、ToolSearch、MCP
基础设施层(Infrastructure):认证、缓存、遥测、远程控制
各层之间通过双向数据/控制流连接,形成一个闭环运行系统,而非线性流水线。
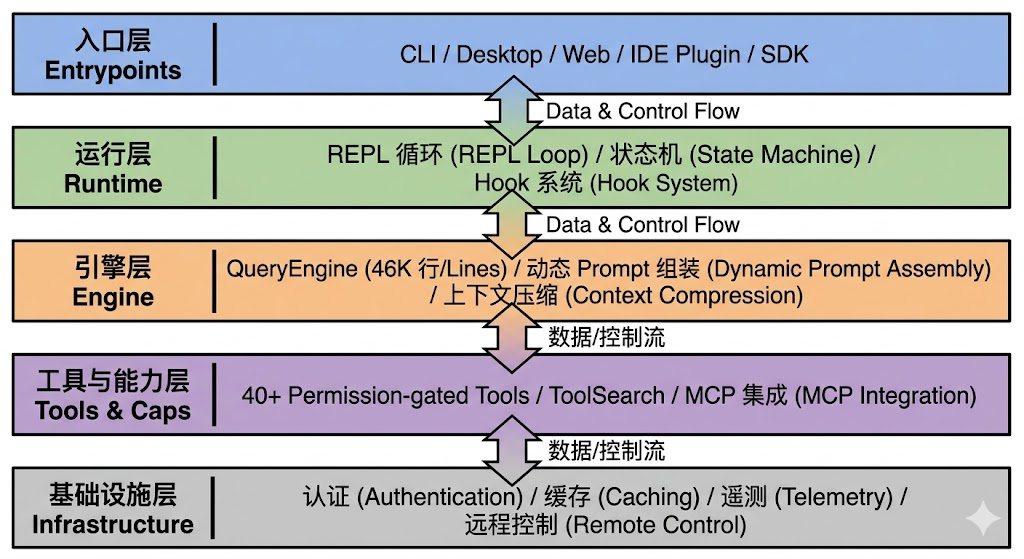
图 1. 路由视角下的Claude Code 架构分层图。
第一层路由:入口层的统一收口设计
Claude Code 同时支持 CLI、桌面端、Web、IDE 插件和 SDK。每种入口的输入形态、权限模型都不同。如果每个入口维护一套 Agent 逻辑,系统必然分裂。
源码显示,main.tsx 并非简单启动脚本,而是一个运行时装配器。在进入 REPL 前,它完成:
环境与凭证预热
会话类型判定
上下文、命令、工具收集
LSP / MCP 初始化
REPL 面对的不是“裸模型”,而是一个能力已完全装配的运行时。MDM 读取与 Keychain 预取被异步启动,体现了典型的延迟隐藏(latency hiding)思路:首轮交互延迟本身就是一等工程问题。main.tsx 最关键的判断是:这次启动是什么类型的会话?
交互式 REPL?
Pipe 批处理?
SDK 远程调用?
是否恢复历史会话?
这个判断直接决定后续的工具集合、上下文注入与权限策略。先路由运行形态,再处理用户任务,这就是入口级路由的本质。对于正在构建企业 AI 系统的团队,入口层的设计思路可以直接类比:钉钉、飞书、Web 端、小程序,本质上都是不同形态的"入口"。如果每个入口都自己维护一套 Agent 逻辑,代码分裂是必然结局。Claude Code 的答案是:用一个装配器在启动时就把差异消化掉,让后续核心逻辑只看标准化的输入和统一的运行时环境。对于企业团队来说,这种思路的价值非常直接:入口可以多样,运行时必须收敛。只有把路由前移到入口层,把差异吸收在装配阶段,后续的 Agent 编排、工具调用和任务执行才能真正做到可复用、可治理、可扩展。
第二层路由:TAOR 循环——嵌在 Agent 执行里的动态调度
Claude Code 的运行层核心是一个 TAOR 循环(Think → Act → Observe → Repeat),这是学术界 ReAct 模式(Yao et al., 2022)的直接工程化实现。
每一轮循环都隐含一次路由判断:
是否继续执行(工具调用)
是否终止输出
这个路由由模型输出隐式决定,而非外部调度器。也正因如此,Claude Code 的路由不是“循环前的一次性决策”,而是嵌入在 Agent 执行过程中的连续动态调度。在 TAOR 循环之上,Claude Code 还引入了执行模式层面的路由。从源码角度看,Claude Code 至少区分了三种语义完全不同的执行模式:
普通模式(Default Mode):标准的 TAOR 循环,推理与执行交替进行,工具调用会实时产生真实副作用(文件修改、命令执行等)。这是绝大多数用户交互发生的模式。
只读规划模式(Plan Mode):
只允许使用只读工具(FileReadTool、GlobTool、GrepTool 等)
显式禁用所有有副作用的工具(BashTool、FileEditTool 等)
输出一份可供用户审查的执行计划,而非直接执行
进入和退出 Plan Mode 分别通过 EnterPlanModeTool 和 ExitPlanModeTool 完成,这意味着 Plan Mode 本身也是通过工具调用触发的——模型可以在推理中自主决定"我需要先规划再执行"。Plan Mode 是一种执行风险路由机制。高风险、不可逆操作(大规模文件改动、危险的 Bash 命令)在 Plan Mode 下只会生成计划文本,人类在看到计划后可以选择确认或拒绝再执行,从而在路由层面阻断了危险操作的直接触发路径。
3.Coordinator Mode(多Agent):
一个 Claude 实例扮演协调者(Coordinator)角色
协调者通过
TeamCreateTool 和 SendMessageTool 创建并管理多个 Worker Agent
每个 Worker 在独立的 git worktree 中执行,彼此上下文隔离
Coordinator 不直接编写代码,只负责任务拆分、分配和结果汇总
Worker 与 Coordinator 的通信方式是结构化文本结果回填上下文,不存在独立的 Agent-to-Agent 消息总线
学界的多 Agent 通信拓扑研究(如 G-Designer,2024)关注的是如何在 Agent 图中自动化设计最优的通信结构,涉及图神经网络生成动态拓扑。Claude Code 的实现要简单得多——它是固定的 Hub-and-Spoke(中心辐射)拓扑,协调者永远是中心节点。这意味着通信复杂度更低、可预测性更强,代价是失去了 Agent 间点对点通信的灵活性。这是一个典型的工程权衡:在生产系统里,可预测性比理论最优更重要。
在 Coordinator Mode 下,路由决策链是:
用户复杂任务 ↓Coordinator 分析任务结构 ↓判断:哪些子任务可以并行?哪些有顺序依赖? ↓通过 TeamCreateTool 创建 Worker A、Worker B、Worker C ↓通过 SendMessageTool 分配具体子任务(含工具访问权限) ↓Worker 在各自隔离的 worktree 中执行 ↓Worker 完成后将结果通过结构化文本回传 Coordinator ↓Coordinator 汇总,输出最终结果
用企业路由语言表达:这是一个典型的 Task Router + Worker Pool 模式,与消息队列系统(如 Kafka + Consumer Group)或任务调度系统(如 Celery + Worker)的设计逻辑高度相似,只不过"Worker"是 Claude 实例而不是计算节点。
泄露代码还显示,Claude Code 在每轮 Act 完成后、下一轮 Think 开始前,插入了一个 Reflection 环节:
检验刚才的操作是否达到预期
检测是否陷入了重复执行循环
检查是否遗漏了约束条件
这与 Shinn et al.(2023)提出的 Reflexion 框架高度一致。社区测试结果显示,引入 Reflection 后,Agent 在复杂编程任务中的成功率显著提升,但代价是额外的模型调用成本。从路由视角看,Reflection 并不是单纯的“质量检测”,而是一个隐式的自适应路由节点:如果检测到循环或偏差,系统会修正下一轮的执行路径,而不是继续沿原路径盲目推进。
第三层路由:引擎层的动态提示词调度
QueryEngine.ts 是整个系统最核心的单个文件,代码量接近 46,000 行。它负责:
上下文窗口的拼接与管理
提示缓存(Prompt Cache)的命中与更新
流式响应(Streaming)的处理
对话历史的压缩
把这些逻辑集中在一个文件而不是拆散,有其工程理由:所有涉及模型 API 调用的逻辑——重试策略、限速处理、上下文预算——都在同一处推理,避免了跨模块的状态不一致问题。
Claude Code 路由设计里最具特色、也最反直觉的部分:Claude Code 没有一个固定的"系统提示词"。它有数百个提示词碎片,在运行时根据当前的模式、工具集合和上下文,动态组装出最终注入的系统提示。以下是几个已知的组装触发条件:
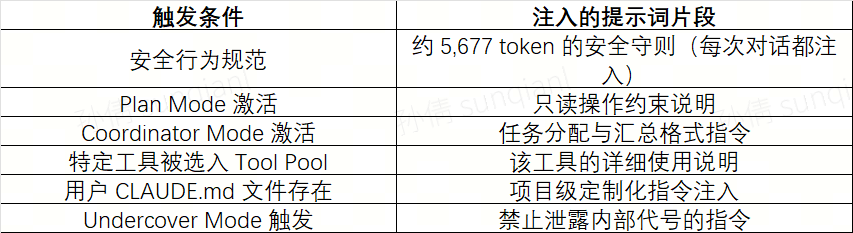
这套设计本质上是一个提示词级别的路由系统:请求的上下文特征(模式、工具、项目配置)决定了哪些提示词片段被"路由激活",最终拼出一个专属于这次会话的系统提示。此外,提示缓存(Prompt Caching)是 Anthropic API 的一项功能,允许将重复的提示词前缀缓存起来,后续调用命中缓存则大幅降低 Token 计算成本。Claude Code 在工程实现上用了 14 个缓存断点,配合粘性锁存器(Sticky Latch)管理,防止模式切换导致缓存失效。每次缓存失效都意味着真实的 API 成本增加,所以提示词片段的"拼接顺序"和"断点位置"也是一种路由优化:把不变的内容放在缓存断点之前,把动态变化的内容放在断点之后,最大化缓存命中率。
第四层路由:工具层的按需曝光与权限门控
Claude Code 内置约 40 个工具,每一个工具都是自我完备的独立模块,包含:
Zod v4 定义的输入 Schema
权限级别声明
执行逻辑
错误处理
工具列表涵盖文件操作、Shell 执行、信息检索、Agent 协作、任务管理以及 MCP 集成等类别。工具基类的定义就有约 29,000 行 TypeScript,这是工程严谨性的体现。40+ 工具的完整描述全量注入上下文,对 Token 预算来说是一种浪费,对模型的工具选择推理也是干扰。Claude Code 的解法是 Progressive Disclosure(渐进式曝光):
工具池组装(assembleToolPool()):根据当前会话的上下文特征,只选出"当前可能相关"的工具子集放入 Tool Pool;
延迟加载(defer_loading: true):部分工具的详细描述不在初始提示词里,而是按需注入;
ToolSearch:模型可以主动搜索工具注册表,相当于"先知道有哪些大类能力,再具体找工具"。
这本质上是一种工具级的粗粒度到细粒度的两阶段路由:
第一阶段(粗路由):能力大类感知
用户请求 → 确定大类(文件操作?搜索?执行命令?)
第二阶段(细路由):精确工具选择
大类确定后 → 注入该类工具的详细 Schema → 模型精确选择具体工具
与直接把所有工具塞给模型相比,这种设计在长会话场景下可以显著减少 prompt 体积(从全量工具描述到按需注入,Token 节省可达数千甚至数万),同时降低模型在过多选择中产生误选的概率。
遥测与隐式反馈路由:用行为信号驱动系统改进
泄露代码里有两个不显眼但极具价值的遥测设计:
挫败感指标(Frustration Metric):系统实时追踪用户在对话中出现骂人词汇的频率,将其作为 UX 质量的代理指标。当用户开始骂人,大概率意味着 Agent 的行为与预期严重偏离。这是一种情绪信号驱动的行为路由反馈——不需要用户主动填问卷,情绪本身就是最真实的系统评分。
"continue"计数器:追踪用户在会话中输入"continue"的频率。对于一个应该自主推进的 Coding Agent,用户频繁输入"continue"意味着 Agent 在不该停下来的地方停了——这是"主动性不足"故障模式的量化信号。
这两个指标的工程意义在于:它们不是用来展示在 Dashboard 上的虚荣指标,而是可以驱动具体路由改进决策的行为数据:
挫败感高发的任务类型 → 提示词调整或工具行为修正
"continue"高频的会话模式 → Agent Loop 的停止条件需要重新标定
这是一种隐式的自适应路由反馈机制:用户行为信号 → 系统行为分析 → 路由策略调整,形成闭环。
对企业 AI 系统建设者的落地建议
核心技术/商业价值总结
Claude Code 的泄露对企业 AI 系统建设者的价值,不在于"我要抄它的代码",而在于:
验证了分层路由架构的可行性:一个商业成功、生产稳定的系统,用的就是分层路由 + 权限门控 + 上下文压缩这套组合,没有神秘的黑盒算法;
提供了具体的工程参考系:哪些组件需要多少代码(工具基类 29K 行、QueryEngine 46K 行),帮助团队做出更准确的工程估算;
明确了关键的非功能性需求:六层权限门控、三层压缩、断路器保护——这些在 Demo 阶段往往被忽略,但是生产稳定性的真正来源。
针对不同角色的行动建议
对于 AI Agent 系统架构师:
不要在早期设计阶段就追求动态拓扑的灵活性;先用固定的 Hub-and-Spoke,把任务路由逻辑跑通再考虑扩展
把权限门控从"功能列表里的一项"提升到"架构设计的一等公民",参照六层门控思路,逐步实现从配置白名单到自动分类的完整链路
上下文压缩不是优化项,是生产必需项;在第一版就设计压缩触发点,哪怕先只实现最简单的截断策略
对于 NLU/意图路由模型研究者:
Claude Code 的工具路由(渐进式曝光 + 按需加载)对意图识别的启发:在企业多意图场景下,不需要让模型同时感知所有意图类别,先粗分大类,再在大类内部做精细分类,可以显著降低误分类率
QueryEngine 的动态提示词组装,对应意图分类系统的"动态 prompt 调度":不同业务场景注入不同的分类约束,比一个通用分类器处理所有场景效果更稳定
对于企业 AI 产品经理:
Claude Code 的两个遥测指标(挫败感指标 + continue 计数器)值得直接借鉴:用户行为信号比满意度问卷更能反映 Agent 的真实表现;在产品埋点时加入"用户重复触发同一操作"、"会话中途中断"等行为指标
多端入口统一收口的架构选择,意味着你只需要维护一套核心逻辑,但需要在入口层做好差异适配,这个工程成本应该在排期时被提前估算
结语:工程化,才是真正的护城河
Claude Code 的源码告诉我们,当今最成功的商业 AI Agent 产品,它的核心技术竞争力不是一个没人见过的路由算法,而是:
把 ReAct 这个 2022 年的学术 idea,工程化成 46,000 行稳定运行的 QueryEngine
把"分层权限"这个安全工程常识,工程化成针对 AI 特定风险的 6 层独立门控
把"按需加载"这个 UI 设计原则,工程化成工具注册表的渐进式曝光机制
把"任务分发"这个分布式系统常识,工程化成 Claude 实例之间的结构化文本 pipe
没有新算法。只有深厚的工程沉淀。
这对于正处于"从 Demo 到生产"阶段的企业 AI 团队,是一个重要的信号:你的技术差距不在于你没有独特的路由算法,而在于你还没有把那些已知的好想法,以 Claude Code 这样的密度和质量工程化出来。
泄露的代码可以被 DMCA 下架,但工程化的设计思路,一旦公开,就属于整个行业了。
参考资料
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629.
https://arxiv.org/abs/2210.03629
Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv preprint arXiv:2303.11366.
https://arxiv.org/abs/2303.11366
Chen, L., Zaharia, M., & Zou, J. (2023). FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv preprint arXiv:2305.05176.
https://arxiv.org/abs/2305.05176
Ong, I., Almahairi, A., Wu, V., Chiang, W. L., Wu, T., Gonzalez, J. E., Kadous, M. W., & Stoica, I. (2024). RouteLLM: Learning to Route LLMs with Preference Data. arXiv preprint arXiv:2406.18665.
https://arxiv.org/abs/2406.18665





