 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库这样用 Opus 4.7,才能发挥实力
How & Why
Opus 4.7 发了两天,反馈褒贬不一
一部分人说手感不如 4.6,同样的 prompt 跑出来感觉不对,长 session 里 token 烧得比以前凶。另一部分人,包括我自己,反而觉得这版比 4.6 更顺,长任务稳,code review 更准,做模糊调试不用手把手带
Anthropic 显然也看到了这个分化。4 月 15 日和 16 日连发两篇 Claude Code 的使用指南,一篇讲 Opus 4.7 的最佳实践,一篇讲 1M context 下的 session 管理。两篇合起来正好回答了「为什么手感变了」和「怎么用才对」
我把两篇整合起来讲
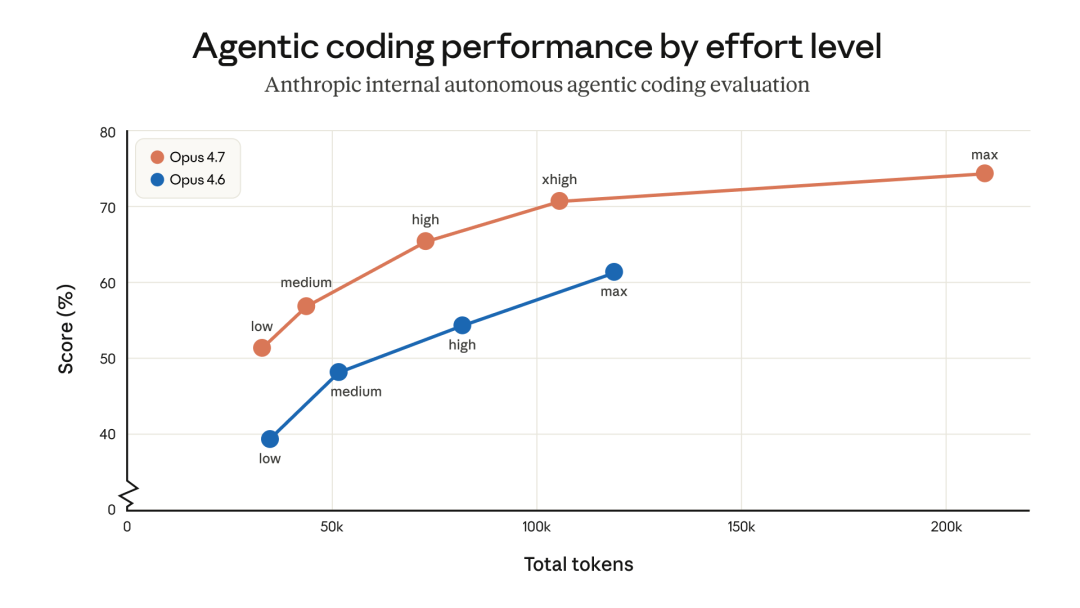
Opus 4.7 各 effort 档位在 agentic coding 上的表现
一、为什么手感变了
Anthropic 官方在最佳实践那篇里,点了五条和 4.6 不同的地方。这五条合起来,就是「手感变了」的全部原因
第一条,tokenizer 换了
同样一段文本,Opus 4.7 算出来的 token 数是 4.6 的 1 到 1.35 倍。如果之前按 token 用量做过预算或者 harness,现在会发现数字对不上。价格本身没变,换了计数方式而已
第二条,默认 effort 档位升到了 xhigh
Opus 4.7 引入了一个新档位 xhigh,介于 high 和 max 之间。Claude Code 已经把默认档位从原来的 high 自动升到 xhigh,老用户没手动设过的话,升级后会自动切。Xhigh 比 high 想得多、token 用得多,所以会觉得「反应变慢了」「token 烧得凶了」
第三条,高 effort 档位下更倾向于多思考,尤其在长 session 后期
官方原文说,Opus 4.7 在 higher effort levels, especially on later turns in longer sessions 会主动多想。长 session 里这一条会叠加 context rot 效应,放大 token 波动
第四条,三个默认行为改了
→ 回答长度按任务复杂度走。简单查询更短,开放分析更长。Opus 4.6 默认偏啰嗦,4.7 收敛
→ 工具调用变少,推理变多。大多数场景结果更好,但习惯了 4.6 狂读文件的用户会觉得「怎么不主动搜了」
→ Spawn subagent 变少。4.7 对是否委派给子 agent 更审慎
第五条,Extended Thinking 的固定 thinking budget 模式不支持了
换成了 adaptive thinking。每一步 thinking 是可选的,模型自己判断要不要深入想。简单的问题直接答,没必要想的跳过。官方说 overthinking 改善明显
这五条加起来,如果 prompt 和 harness 原封不动从 4.6 搬过来,就会感觉「手感不对」。事实上模型没变糟,只是默认变了
二、怎么用才能发挥最大实力
手感变了的部分,正好对应新的使用方式。官方这两篇博客其实分了两个层面讲,一是单次交互怎么写 prompt,二是长 session 怎么管 context。下面按这两个层面走
单次交互:把任务一次说清楚
官方第一条建议,也是整篇最重要的一条
把 Claude 当有能力的工程师,不是结对编程的同伴
第一轮就给全 context。 意图、约束、验收标准、相关文件位置,一次性说清。模糊的 prompt 分多轮渐进给,token 效率和结果质量都会掉
减少用户交互轮数。 每一轮用户消息都会增加 reasoning 开销。问题批量问,该给的 context 一次给足
合适时用 auto mode。 Claude Code Max 用户可以用研究预览版的 auto mode,Shift+Tab 切换。长任务且前期 context 给足的时候特别合适
任务完成时加通知。 可以让 Claude 在任务结束时播放一个声音,它会用 hook 机制自己创建通知
Effort 五档怎么选
官方给的建议
low / medium成本或延迟敏感、任务范围清楚的时候用。硬任务上会弱一些,但同档位下比 Opus 4.6 强
high平衡智能和成本。多 session 并发或者想省钱时用
xhigh(默认)大部分编码和 agent 任务的最佳档位。智能和自主性接近 max,但不会像 max 那样在长 agent 跑动时 token 失控
max真正困难的问题才用,边际收益递减,而且容易过度思考。适合跑 eval 测模型上限,或者极端 intelligence-sensitive 的场景
官方特别提醒,不要把 4.6 的档位原封不动搬过来。同一个任务里也可以手动切档位管 token
Adaptive thinking 怎么引导
固定预算不再支持之后,想控制 thinking 频率只能在 prompt 里写
→想多想Think carefully and step-by-step before responding. This problem is harder than it looks.
→想少想Prioritize responding quickly rather than thinking deeply. When in doubt, respond directly.
需要更多工具调用或 subagent 时怎么写
Opus 4.7 默认调工具少、spawn subagent 少,如果场景需要更激进地读文件、搜索、或者并行处理,必须在 prompt 里明确写清楚什么时候用、为什么用
官方给的 subagent 示范 prompt 是这样
不要为单轮就能完成的工作 spawn subagent(比如改一个已经看到的函数)。扇出多个文件或独立项时,在同一轮里 spawn 多个 subagent
官方还提醒一件事,用正面例子(想要什么样的)比 don't do this 这种负面指示更管用
长 session:1M context 不等于省心
Opus 4.7 的长任务能力提升了,1M context window 也扩出来了。但这两件事叠加的结果,是用户在 session 管理上的差异变得比以前更大
有人一直开着一两个 session,有人每条 prompt 都开新的。什么时候 /compact、什么时候 /clear、什么时候 /rewind、什么时候上 subagent,这一块是 4.7 之后最值得重新理一遍的
先把三个概念对齐
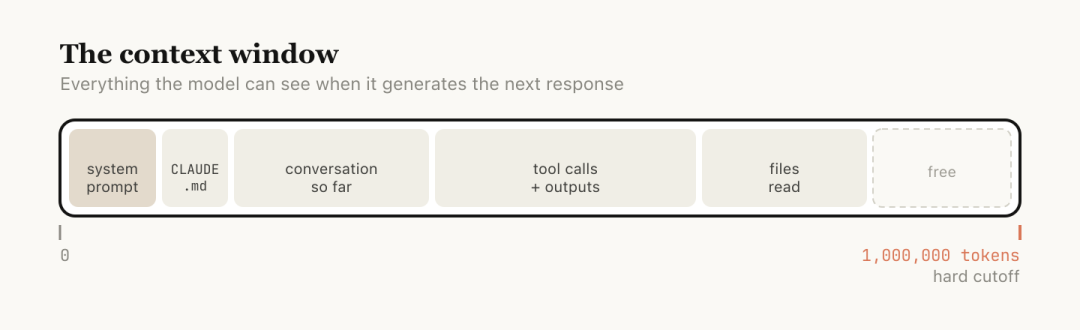
context window 是模型一次能看到的全部
Context window: 模型生成下一条回答时能看到的全部内容。系统 prompt、对话历史、每个工具调用和输出、每个读过的文件,都算进去。Claude Code 的 context window 是 100 万 token
Context rot: 模型表现会随 context 变大而下降。原因是 attention 被摊薄,老的无关内容开始干扰当前任务
Compaction: context 快到上限时,Claude Code 会自动把已完成的任务总结成一段描述,然后在新 context window 里接着做。也可以手动触发

Compaction 把旧内容压缩成摘要,腾出空间继续
每一轮交互都是一个分叉点
Claude 刚做完一件事,context 里留下了工具调用、工具输出、你的指令。下一步的选择其实不止「继续」一个
官方给了五个选项
Continue同 session 发下一条消息
/rewind(连按两下 Esc)跳回之前某条消息,从那里重新 prompt。之后的消息全部从 context 里丢掉
/clear开新 session,通常带一段自己总结好的简要
Compact总结当前 session,在总结之上继续
Subagents把下一段工作委派给一个独立 context 的 agent,只把最终结果拉回来
最自然的是 continue,另外四个都是为了管 context

每一轮之后,有五条路可以走
开新 session 的判断
基本原则:开新任务时,也开新 session
1M context 让长任务更稳,比如从零搭一个全栈应用,现在能在一个 session 里完成。但 context rot 依然存在
有些相关任务,比如刚实现一个 feature 之后写文档,开新 session 的话 Claude 要重新读这些文件,慢且贵。这种情况留在旧 session 更合适
Rewind 比 Correct 好
这是整套里最反直觉的一条
Claude 读了五个文件,试了一种方法不 work。大多数人的直觉是接着打「刚才那个不行,试试 X」。但更好的做法是 rewind 回文件读取之后那一步,带着学到的东西重新 prompt,类似「别用 A 方案,foo 模块没这个接口,直接用 B」
文件读取的成果保留下来,失败的尝试从 context 里清掉。context 里只剩有用的东西
还有一个用法是 summarize from here 或 /rewind,让 Claude 自己写一段 handoff 消息,类似给上一个版本的自己留个纸条
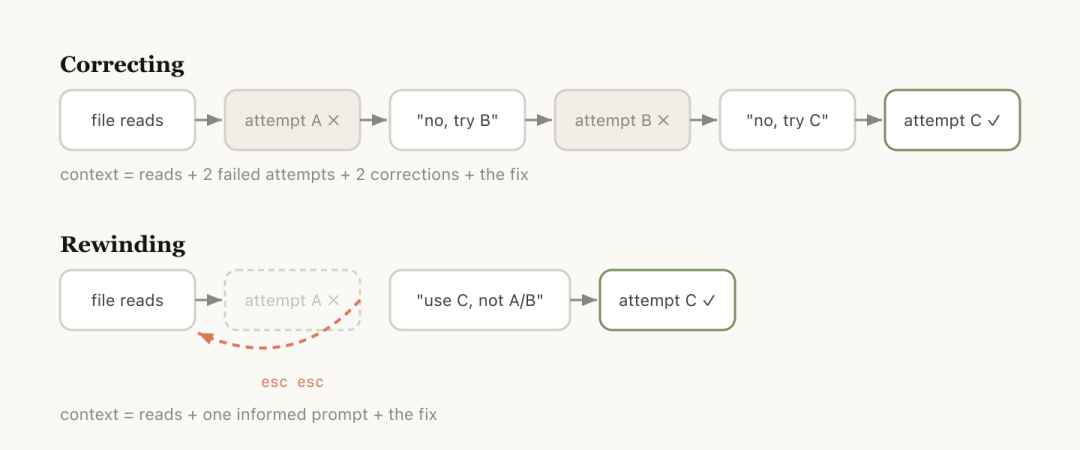
Rewind 跳回早前某条消息,带着学到的东西重来
Compact 和 /clear 不是一回事
Session 变长之后,想卸掉陈旧 context,有两种办法。/compact 和 /clear,用起来感觉相似,实际差别很大
Compact 让模型自己总结,然后用总结替换对话历史。有损,但不用自己动手,Claude 可能还更周全地把重要学习和文件都留住。可以用指令引导,比如 /compact focus on the auth refactor, drop the test debugging
/clear 是自己写下什么重要。「我们在重构 auth middleware,约束是 X,重要文件是 A 和 B,方案 Y 已经排除」这种。工作量大一些,但留下的 context 完全由你决定
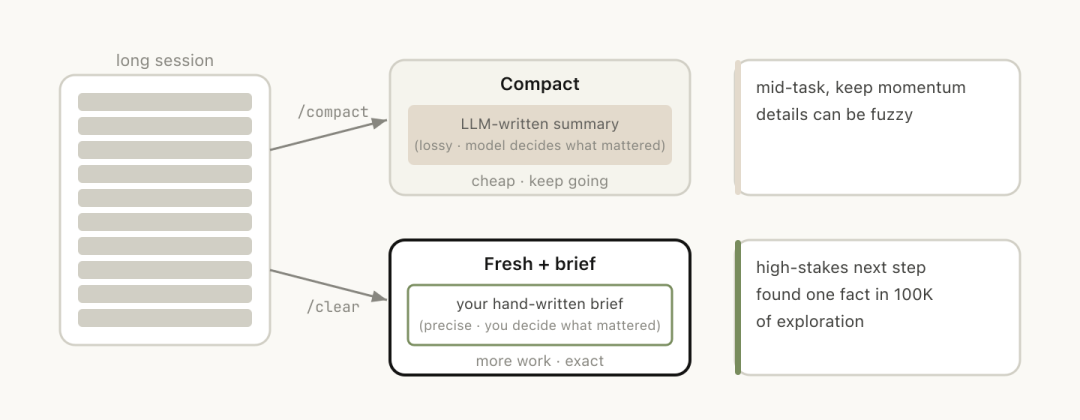
Compact 把对话压成摘要,/clear 直接开新局
官方还点了一个坏 autocompact 的常见场景:模型预测不出你下一步要干什么的时候
比如长 debug session 之后 autocompact 触发,总结了整个调试过程。你下一条消息是「那现在修一下 bar.ts 里另一个 warning」。但 session 专注在 debug 上,那个 warning 可能根本没被总结进来
更棘手的是 context rot 下,模型在 compact 的那一刻,恰好是最不聪明的时候。1M context 多出来的余地,正好可以用来提前主动 /compact,用一段描述告诉 Claude 接下来要做什么
Subagent 的判断标准
Subagent 适合的场景:提前就知道这段工作会产生大量中间输出,但之后用不到
Claude 通过 Agent 工具 spawn subagent,子 agent 自己有一个新的 context window,能做多少做多少,最后把结果综合成一段 report 发回父 session
Anthropic 内部用一句话来判断
我还会再用到这个工具输出吗,还是只要结论就够?
Claude Code 会自动调 subagent,也可以主动要求。官方给了三个示范 prompt
→Spin up a subagent to verify the result of this work based on the following spec file
→Spin off a subagent to read through this other codebase and summarize how it implemented the auth flow, then implement it yourself in the same way
→Spin off a subagent to write the docs on this feature based on my git changes
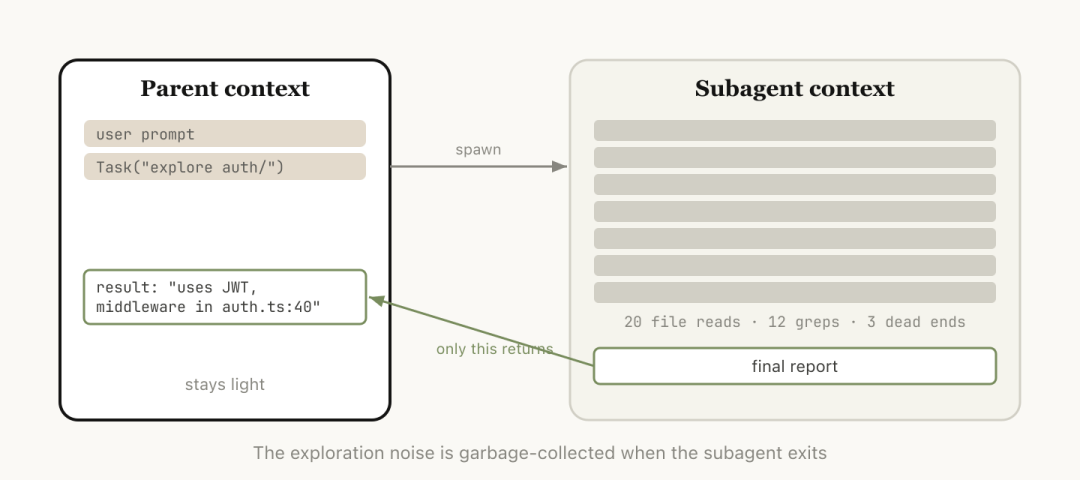
Subagent 拥有独立 context,只把结果返回父 session
一张实用对照表
官方在文末给了一张表,把情境、选项、原因对应起来
同一任务,context 仍然相关选 Continue。窗口里的内容都在起作用,没必要重建
Claude 走错路了选 Rewind(连按两下 Esc)。保留有用的文件读取,丢掉失败尝试,带着学到的东西重新 prompt
任务还没完,但 session 被陈旧的调试填满选 /compact <hint>。成本低,Claude 判断什么重要,必要时用指令引导
开始一个真正的新任务选 /clear。零 rot,延续什么完全由你决定
下一步会产生大量输出但只需要结论选 Subagent。中间工具噪音留在子 context,只有结果返回
回到开头那个分化
说手感变了的朋友没感觉错,默认行为确实调了不少。说更好用的朋友(包括我)也没夸张。4.7 的新默认刚好贴合自己的用法
Opus 4.7 更聪明、更克制,Claude Code 的默认也调得更激进。想让它好用,第一轮把任务说清楚,effort 留在 xhigh,长会话里主动管 context,该 rewind 就 rewind,该 subagent 就 subagent
比以前要多操一点心,但一旦上道,结果会更好
两篇原文都来自 Anthropic 官方博客
→ Best practices:claude.com/blog/best-practices-for-using-claude-opus-4-7-with-claude-code
→ Session management:claude.com/blog/using-claude-code-session-management-and-1m-context





