 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库MCP:让AI从“会说话”变成“会办事”的那根关键纽带
Anthropic 技术团队成员David Soria Parra 探讨了模型上下文协议 (MCP) 的演变及其在 2026 年代理连接中的关键作用。本次演讲涵盖了渐进式发现、程序化工具调用以及设计有效的以代理为中心的服务器的策略,以弥合人工智能能力与实际生产环境之间的差距。
以下是对原演讲内容的编译,原视频链接:https://www.youtube.com/watch?v=v3Fr2JR47KA

MCP 应用愿景
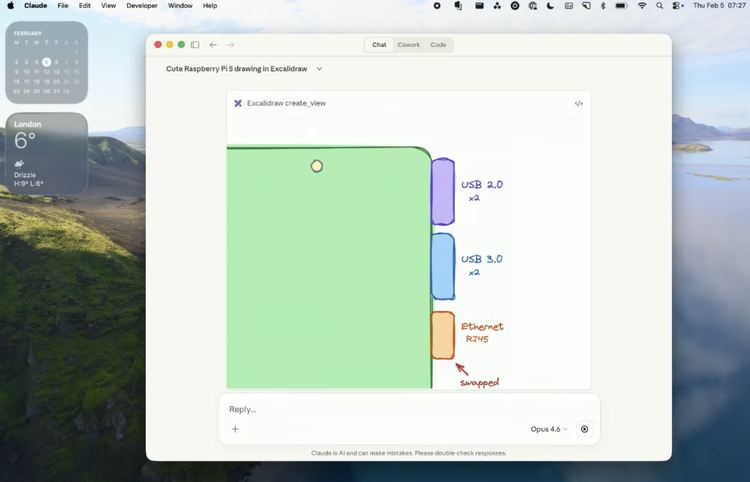
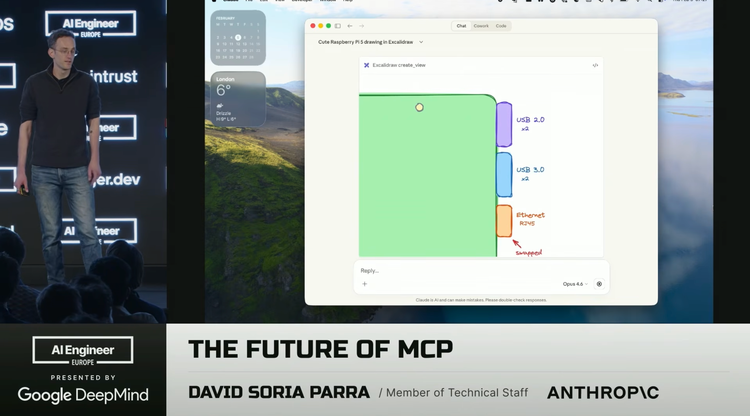
欢迎大家,我们开始吧。这是一个 MCP 应用。它的意义在于:一个智能体不仅能提供能力,还能自带界面,而且这个界面不是通过插件接入的,不是依赖某个 SDK 临时渲染出来的,也不是在客户端由模型实时拼出来、或者提前硬编码到产品里的。它是由 MCP 服务器直接提供的。你可以把这个服务器部署到云端,也可以接入 Chatbot、VS Code、Cursor 等不同环境里,它都能够直接工作。这件事很有意思,因为要做到这一点,单靠很多现有生态里的常见方案其实是不够的。你需要“语义”,也就是客户端和服务器两端都必须真正理解彼此在说什么,理解该如何渲染界面,理解接下来会有一个 UI 出现。而要实现这种互相理解,就需要一个协议。
更精彩的是,MCP 服务器不只是能交付一个应用,或者说它具备交付应用的能力;它还可以把工具一并交付出去。这样一来,人类用户可以通过这个应用与它交互,而模型也可以通过工具去调用它。我认为这是非常独特的一点,也是我们目前还远远没有挖掘充分的一种能力。
过去 18 个月 MCP 生态系统的发展历程
不过,在继续往前看之前,我想先把时间稍微往回拨一点。回到一年多以前,差不多 18 个月前——在 AI 的生命周期里,这已经算得上非常漫长了。那时候,今天你们看到的这些东西基本都还不存在。当时只有一份很小的协议文档、少量 SDK,而且大多数还是 Claude 帮忙写出来的;整体上也仅限于本地使用,能力几乎只有“工具”这一层。但就在过去这 18 个月里,大家疯狂地开始构建:建服务器、建生态、建各种各样围绕 MCP 的东西。与此同时,我们也一直在推进这套协议:把它从“只能本地使用”扩展到支持远程能力,加入集中式授权机制,增加了 elicitation、tasks 等新的原语,最后还把像 MCP applications 这样的实验性特性也带进了协议之中。
应用里程碑
在这个过程中,我们也达成了一个非常重要的里程碑。现在整个生态每个月大约已经有 1.1 亿次下载量。这里面当然不只是我们自己的客户端和服务器,还包括 OpenAI、Google ADK、LangChain,以及成千上万你可能从没听说过的框架和工具,它们都把 MCP 作为依赖接入进来。这意味着,我们终于拥有了一种所有人都能共同使用的标准语言,让不同系统之间可以彼此“说话”。为了帮助大家理解这个速度有多快,我举个例子:React 作为过去十几年最成功的开源项目之一,大约花了两倍左右的时间,才达到相似的下载规模。与此同时,大家还构建了很多非常酷的 MCP 服务器:从 WhatsApp、Blender 这样的玩具型项目,到 Linear、Slack、Notion 这样的 SaaS 集成,甚至更重要的是,绝大多数 MCP 服务器其实都在“看不见”的地方——部署在企业内部,用来把公司的各种系统连接到智能体和 AI 应用上。
从 2025 年的探索阶段过渡到 2026 年的生产阶段
但我依然认为,这一切都还只是刚刚开始。因为在我看来,2025 年更多是在“探索”,而 2026 年将会是把智能体真正推向“生产环境”的一年。回头看,2024 年我们更多是在做 Demo,展示一些很酷的东西;2025 年则主要是在做编码智能体。编码智能体其实是最理想的一类智能体场景:它运行在本地,可验证,能调用编译器,出问题了开发者还能立刻坐在电脑前修复,而且它还有一个相对清晰的交互界面,用户也比较容易接受。
但现在,随着模型能力不断增强,我们正在进入一个新的阶段。今年开始,我们会看到智能体不再只是“写代码”,而是逐步进入真正的知识工作领域,去做金融分析师、市场人员等知识工作者真正需要完成的事情。而这类智能体最关键的需求,不是一个能在本地调用编译器的代理,而是能够连接五六个 SaaS 应用,再加上共享网盘或共享文档系统。因为对于知识工作者来说,智能体最重要的不是本地执行,而是“连接能力”。而且在我看来,连接能力从来都不是某一种单一技术能够全部解决的。如果有人告诉你,有一种方案能一劳永逸地解决所有连接问题,无论是 computer use、MCP 还是别的什么,那大概率是不对的。正确答案永远是:要看具体场景,要按需选择。
所以,在我看来,2026 年构建智能体时,有三类最值得重点考虑的连接能力:Skills、MCP,以及 CLI 或 computer use。它们三者各自擅长的事情完全不同。首先,Skills 本质上就是领域知识,是把特定能力封装到一个非常简单的文件里,通常具备较强的复用性,只是在不同平台之间会有一些细微差别。其次,CLI 在本地编码智能体场景里非常流行,它是一个极其好用的起点:你可以很容易把各种能力串到 bash 里,让模型自动发现 CLI 能做什么。尤其是像 GitHub、Git 这类已经在预训练里大量出现过的工具,CLI 作为连接层其实非常优秀。而且,当你有一个本地智能体、有沙箱环境、有代码执行环境的时候,CLI 几乎是天然合适的选择。
但如果你没有沙箱环境,或者你需要更丰富的语义能力,需要能展示 UI,需要支持长时间运行的任务,需要资源访问,需要真正彻底解耦、且平台无关的架构,又或者你需要授权、治理策略这些“看起来不酷、但企业里极其重要”的能力,那么 MCP 就会成为那个额外的“连接组织层”。再进一步,如果你还想做 MCP applications,或者未来的 skills over MCP 这类实验性能力,那么 MCP 的价值就会更加明显。所以我想表达的是:到了 2026 年,优秀的智能体不会只依赖其中一种方式,而是会把这三种能力都结合起来,并且无缝协同使用。
不过,我们距离那个阶段还没有真正到来,因为还有很多基础工作需要补。部分原因是,现在的智能体整体上其实还不够成熟;另一部分原因则是,我们对“怎样把这层连接组织起来”这件事,讨论得还远远不够。
改进客户端框架:渐进式发现
我认为首先要改进的,是客户端一侧,也就是智能体运行框架、agent harness 这一层——无论它最终体现在 cloud code、API,还是别的什么产品里。这里最关键的一件事,就是要开始构建一种叫作“渐进式发现”(progressive discovery)的能力。很多人一提到 MCP,就会担心上下文膨胀。但如果你认真看协议的职责,协议本身只是把信息通过线路传递过去,真正负责处理这些信息的是客户端。可到目前为止,很多人因为还处在早期实验阶段,做法都非常直接:把所有工具一次性塞进上下文窗口,然后再惊讶地发现上下文怎么变得这么大。其实,更合理的办法是做渐进式发现:通过 tool search 这样的机制延迟加载工具,等模型真正需要时再去加载。Anthropic 的产品和 API 里已经有这种能力,其他厂商的 API 也同样能这么做;当然,你完全也可以自己实现。只要你给模型一个“加载工具的工具”,模型在需要时就会主动去搜索、再按需加载。这样一来,工具相关的上下文占用就会大幅下降。
程序化工具调用和代理编排
第二件事,我认为非常重要,叫作“程序化工具调用”(programmatic tool calling),也有人把它叫作 code mode。核心思想是:你不应该总让模型自己一步一步去编排流程——先调用一个工具,拿到结果,再调用第二个工具,再拿结果,再继续下一个。因为这样做,本质上是在让模型用推理过程去承担编排工作,而这个过程对延迟极其敏感,而且很多事情本来完全可以通过一段脚本更高效地完成。实际上,我们平时看到像 cloud code 自动写 bash 命令,本质上就在做这件事。你当然也可以把这种方式用到 MCP 上,而且也应该这么做。正确的方向不是让模型一层套一层地调工具,而是给它一个执行环境,比如 V8 isolate、Monty、Lua interpreter 之类,让模型直接为你写代码,再执行这段代码来完成组合。MCP 里有一个很实用的特性,叫 structured output,它能够明确告诉你输出值的返回类型,模型就可以基于这些类型信息更优雅地把多个能力组合起来。如果没有 structured output,也没关系,你依然可以让模型把结果整理成结构化输出,或者调用一个更便宜的模型帮你抽取成目标类型。总之,关键不是让模型来“聊天式串工具”,而是让模型写出可执行的组合逻辑,这样延迟更低、token 更省,组合能力也更强。
设计代理和服务器编写器的最佳实践
除了客户端这一侧,我们还必须开始真正“为智能体而设计”。这意味着,我们必须停止那种把 REST API 一比一原样包成 MCP server 的做法。每次我看到有人又在做一个“REST 转 MCP”的自动转换工具,我都会觉得有点别扭,因为这种方式最终通常只会制造出非常糟糕的结果。更好的做法是:从智能体的使用方式出发去设计。其实你完全可以先从“如果是你自己作为人类,会希望怎么和这个系统交互”开始设计,这往往就是一个非常好的起点。如果你想做更强的编排能力,可以在客户端做程序化调用;当然,也可以在服务器端做。像 Cloudflare MCP server 这一类例子就很有代表性:它不是简单地提供一堆工具,而是直接提供一个执行环境,让模型在里面把各种能力编排组合起来。这样不仅能减少 token 消耗、降低延迟,而且组合能力也会强得多。再往前一步,作为服务器作者,我们还应该真正把 MCP 相比其他方案更强的“丰富语义”用起来:比如交付 MCP applications、通过 MCP 交付 skills、用 tasks、elicitations 等协议已经提供、但目前还没有被充分利用的能力。
MCP 协议的未来路线图和核心改进
当然,除了生态和开发者需要努力,MCP 协议本身也还有很多要继续完善的地方。首先,核心层面需要继续加强。过去一年里,随着协议不断发展,我们已经看到有些部分确实还不够理想。举例来说,当前的 streamable HTTP 对于超大规模平台来说并不容易扩展。所以,我们和 Google 的朋友们一起推进了一个新的方向,也就是无状态传输协议(stateless transport protocol)。它会让 MCP server 更像普通的无状态 REST 服务那样容易部署到 Cloud Run、Kubernetes 之类的平台上。这项改进预计会在 6 月落地,并尽快进入各个 SDK。除此之外,我们还需要改进异步任务原语,也就是更接近“agent-to-agent communication”的能力。现在虽然已经有一个很实验性的版本,但支持它的客户端还很少,因此接下来也会有更多客户端开始补上这一块。同时,我们也会继续修补协议中的一些细节语义,并推出 TypeScript SDK V2 和 Python SDK V2,把过去一年踩过的坑真正沉淀成更成熟的工程体验。甚至连我自己也得承认,社区里的 FastMCP 在很多方面都比我们最初发布的 Python SDK 做得更好——毕竟最初那个 Python SDK 是我写的,而现在我们已经找来了更擅长 Python 的人,把这件事重写得更好。
战略集成和企业功能
再往后,就是要把 MCP 集成到更多地方,尤其是企业场景。我们会推出一个叫 cross-app access 的能力,它本质上是在和企业身份提供商合作:当你已经通过公司身份系统登录过一次,无论是 Google、Okta 还是别的身份系统,之后你再访问 MCP server 时,就不需要反复重新登录了,整个过程会顺滑得多。与此同时,我们还会引入 server discovery,也就是通过 well-known URL 自动发现 MCP server。这样一来,爬虫、浏览器、智能体访问一个网站时,就不只是去解析网页内容,还可以先问一句:“这个站点有没有 MCP server 可以直接使用?”这项能力同样预计会在 6 月的新规范里推出。最后,我们也会更系统地使用扩展机制。比如 MCP applications 本身就只适合在 Web 界面里呈现,因为 CLI 环境没法优雅地渲染 HTML;以后我们会有更多类似的扩展能力。
即将推出的 MCP 扩展机制和技能
其中一个我个人非常期待的扩展,就是把 Skills 通过 MCP 直接交付出去。这个方向其实非常自然:如果你有一个规模很大的 MCP server,里面挂了大量工具,那么你一定希望同时把“领域知识”和“使用方法”一并交付给模型,告诉它哪些能力该怎么用、在什么情况下该怎么调。这样,作为服务器作者,你就能持续更新这些 skills,而不必依赖各种插件机制、注册中心或者别的外围体系。其实今天你就已经可以通过一个 load skills tool 来模拟一部分能力,但未来我们会把对应的协议语义正式定义出来。
总结来说,我认为 MCP 目前其实已经处在一个相当不错的状态。今年,我们会继续把智能体推向真正的“全连接”阶段,MCP 仍然会在其中扮演非常核心的角色。当然,我们也非常需要社区的反馈。我们现在已经成立了基金会,整个项目也在以开源社区的方式运转,有 Discord、有 issue、有各种公开讨论。希望大家直接来告诉我们:我们哪里做错了,哪里做对了,还应该怎么继续改进。因为在我看来,2026 年最核心的关键词就是“连接性”。最好的智能体不会只依赖一种方式,它们会同时使用 computer use、CLI、MCP 和 skills——只要哪种方式最适合当前任务,就用哪一种。正因为如此,我们才有机会真正做出那些让人眼前一亮的应用,而这些应用在底层,本质上都只是一个 MCP application 在发挥作用。


AI 时代,产品经理这个岗位正在失去意义





