 五度妙笔
五度妙笔 API商城
API商城
 数据库
数据库Kimi K2.6 开源:一个人,和他的 300 Agents
ESSAY

《企鹅月下追 Kimi》,之前文章的封面
之前画过一张图,叫「企鹅月下追 Kimi」... Moonshot 也是月下,但在看完 Kimi 的最新发布后,觉得下半句有了
Kimi 点兵,多多益善
Kimi 今天发了 K2.6,开源在 HuggingFace:Kimi K2.6 发布并开源,全面精进代码和 Agent 集群能力

K2.6 对外的全面 benchmark,对手是 GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro
横向看,Humanity's Last Exam、DeepSearchQA、SWE-Bench Pro 三项跑赢三家旗舰。其余多数 benchmark 也贴在第一档
除此之外,还带来了这些东西,是我想重点说的:
→ Agent 集群
→ Claw 群组
→ 一篇叫 Attention Residuals 的论文
合在一起,指向了群体智能
先说 K2.6 的 Agent 集群
先看 K2.6 本身。代码能力比 K2.5 提升近 20%,任务步骤数平均少了 35%。跨语言泛化也在涨,Rust、Go、Python、前端、DevOps 都更稳
作为全天候 Agent 的底层模型,K2.6 的内部 Claw-bench 比 K2.5 涨了 10%。长程任务里,指令遵循和自我纠错的表现都上来了
按 Kimi 自己的定位,K2.6 在 Agent 场景对标 Claude Opus 4.6,价格是 Opus 的 1/8
但集群的重点不在单兵,过去调 AI 干活,一次只能要一个东西。要 PPT 换 prompt 重开,要 Excel 再换一次
K2.6 的集群改了这条规则,一次跑完,一整套产物同时出。Kimi 给这套起名 AgentSwarm,一次能拉 100 个不同专长的分身。分身用的都是 K2.6 底座,挂不同的 Skill 就分化出不同的专长
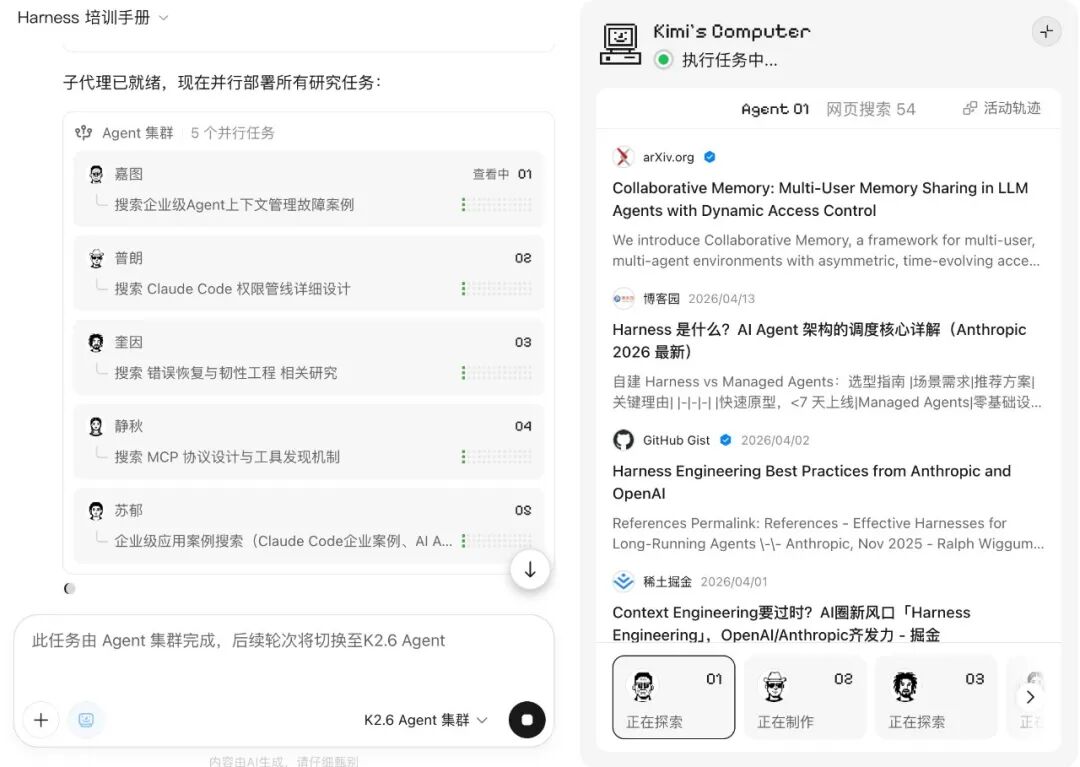
一个 Coordinator 在上面派活,下面挂几个各有专长的 subagent
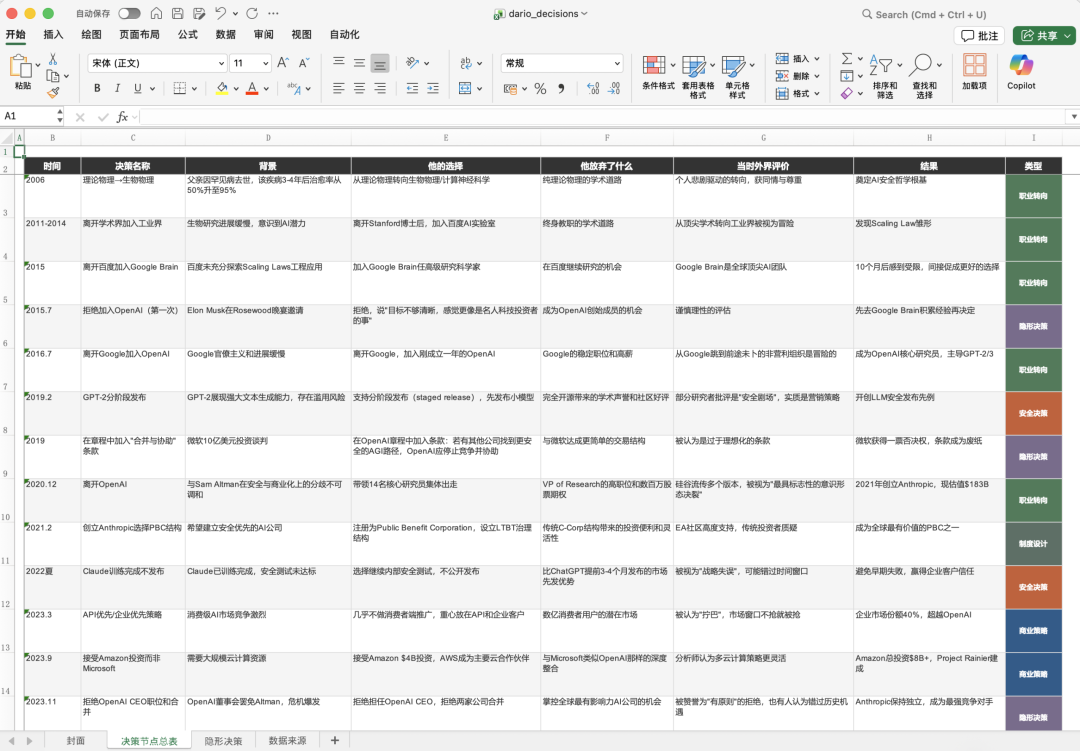
比如我让 Kimi 给 Anthropic CEO 阿莫迪做一本画册,记录他从普林斯顿物理博士一路到 2021 带人分叉出 Anthropic 的全过程。Kimi 把任务拆成九个阶段,研究的子代理扒 Dario 的全部公开资料,排版的子代理把 PDF 做成画册,做表的子代理整理出他每一次离开和加入的决策节点 Excel,写稿的子代理用第一人称写一封《Dear 2008》。同时跑完
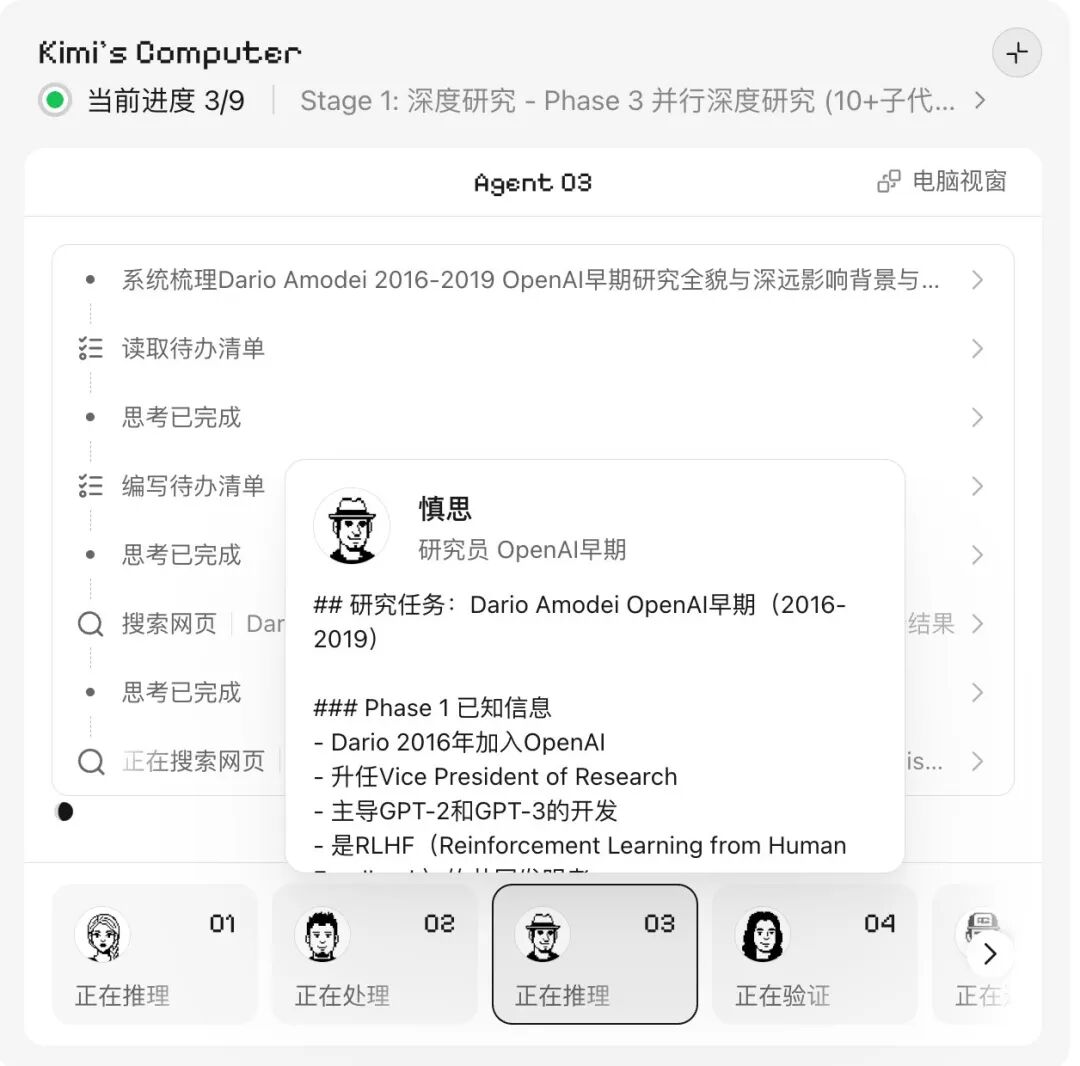
九个分身各管一段时间。慎思这只,专研 Dario 的 OpenAI 那几年
在这个集群里,常驻一个 Coordinator,拆任务、派角色、审成果都归它
而在这里,Skill 是给 AI 的工作说明书。把一份你认可的产物丢给 Kimi,研报、论文、商业计划书都行,它会把里面的分析框架、语言风格、排版结构学下来,存成一个 Skill
比如你找到一份 20 年前高盛写的并购白皮书,扔给 Kimi,20 分钟后你有一个「高盛并购方法论」的 Skill。下次 Agent 集群做并购分析,挂上就行
集群解决产能,Skill 解决标准
这里,我让他帮我去给阿莫迪来写一个深度研究,
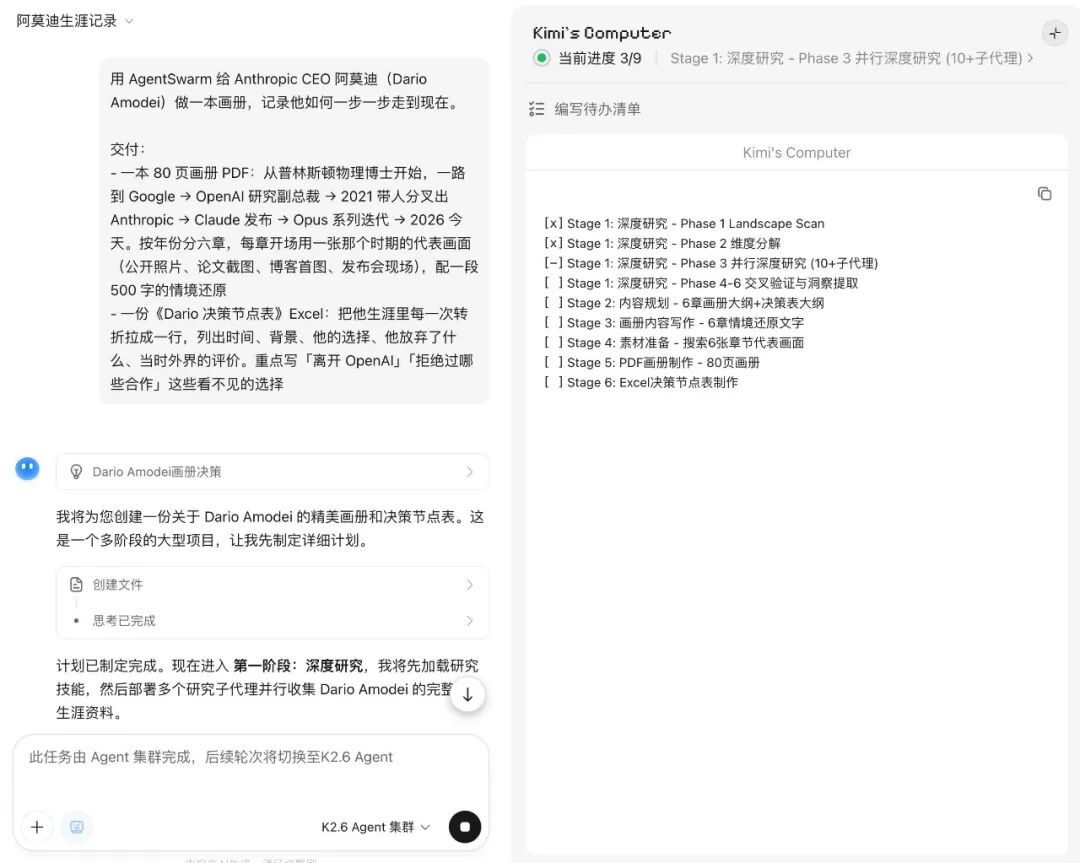
然后他给我做出了一份 80 页的 PPT,还有各种深度材料
这里,Kimi 以 Agent 集群点专长
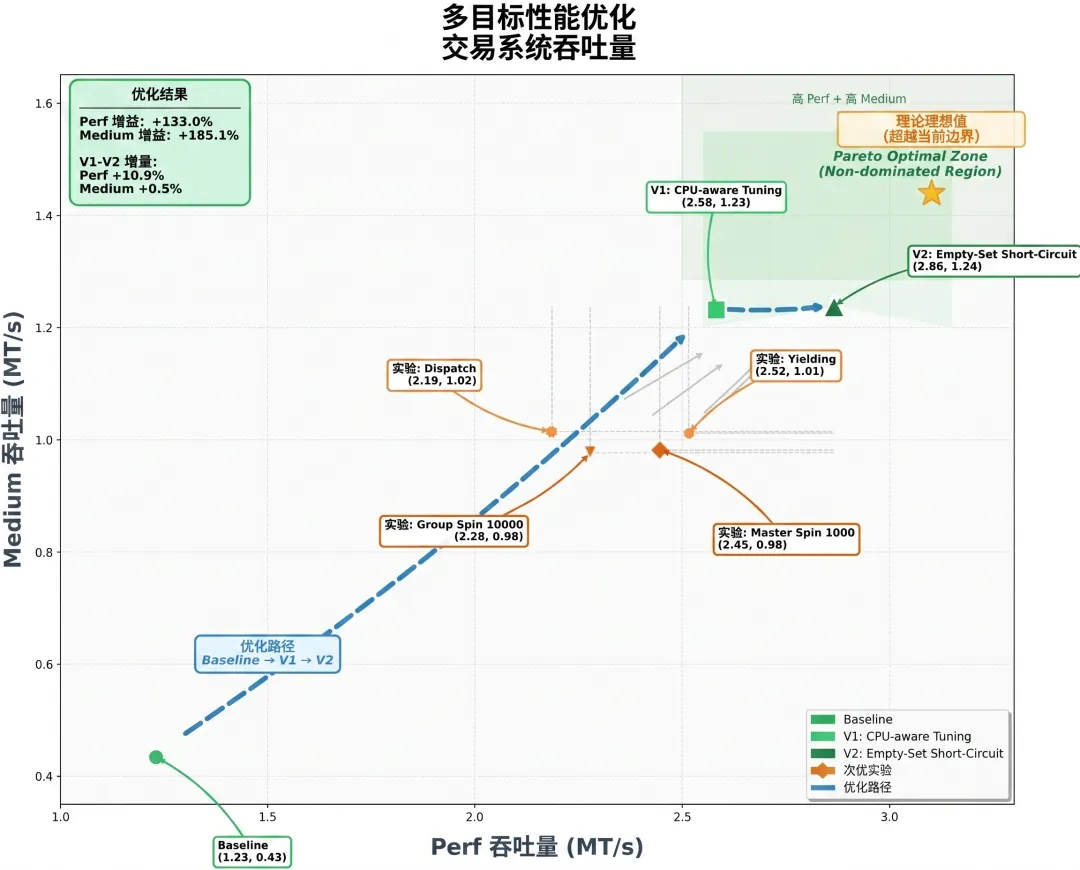
AgentSwarm 跑出的交易系统多目标性能优化路径图
再看 Claw 群组
Kimi Claw 是 Kimi 的龙虾 Agent:龙虾大逃杀:存活下来的,拿 Mac mini|群里有只会踢人的龙虾
Claw 群组,则是让这些龙虾进同一个群聊一起干活,组织协作,一键出道
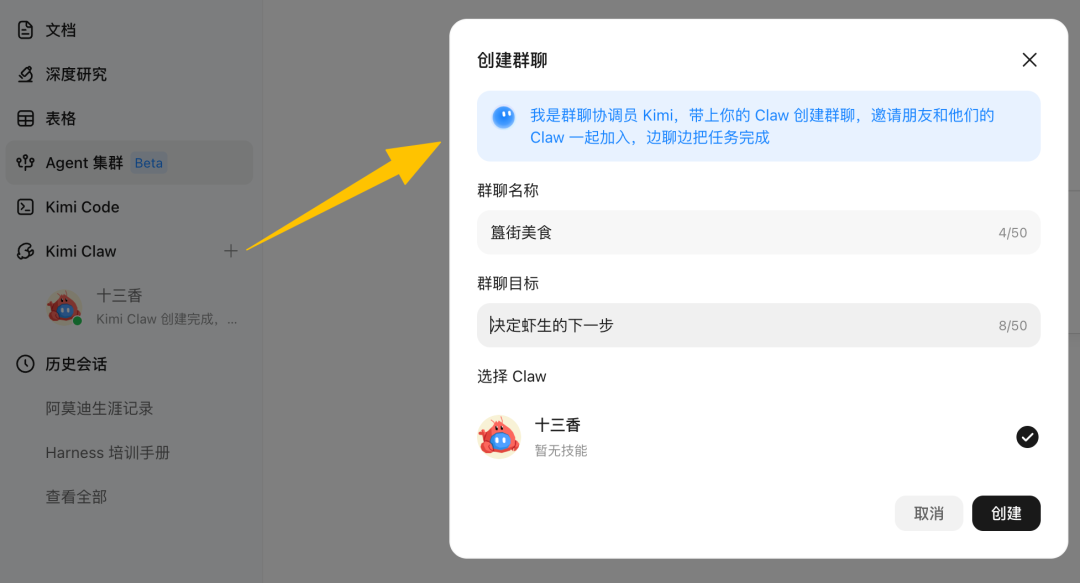
建群入口,Kimi 自己来当群聊协调员。十三香进簋街美食群,决定虾生的下一步
作为用户,可以新建一个群,能把自己的龙虾、朋友的龙虾、阿里腾讯 MiniMax 别家模型的龙虾都拉进来。自己训过的 OpenClaw 关联到 Kimi 账户后也能拉进群。单群最多 50 个成员,人和虾合起来算
过去的 Agent 框架,解决的是人怎么指挥 Agent。Agent 之间怎么说话、怎么分工、怎么互相引用对方的结果,没人管过
你来旁观一支 AI 队伍为你干活
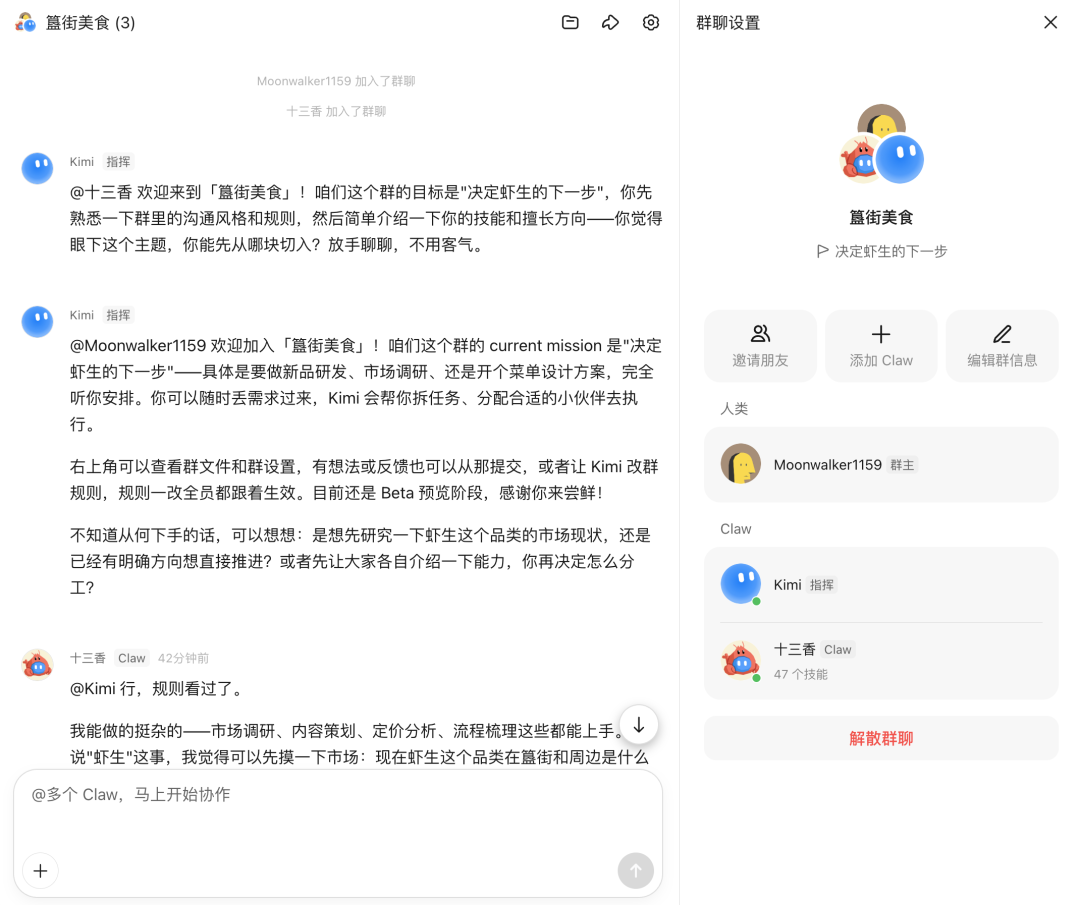
簋街美食群里,Kimi 当协调员,十三香开始做市场调研。这只虾正在认真讨论自己的下一步
集群是并行分工,一个用户派 N 个 subagent 干活。群聊是多实体对话,N 个用户、N 只虾,里面有对抗、有信息不对称、有涌现
一个新闻抛进群,几只不同角色的虾同时给判断。审计的挑风险,风控的算回撤,分析师的拉历史对比。用户最后决定听哪一只
AI 到这一步第一次有了社交关系
你的虾可以借给朋友,朋友的虾也可以进你的群。比如你朋友是会计,他训过的会计虾拉进来用一次就好
连订阅额度也跟着一起流转。你没买 Kimi Pro,朋友的虾进你群,他的 Pro 能力自然带过来
专家把自己训过的虾开放给付费用户,知识付费就从「买内容」变成「租一个专家助手」
这里,Kimi 拿 Claw 群组点人脉
第三件藏得最深

https://arxiv.org/abs/2603.15031
Kimi 在 arXiv 挂了一篇论文,叫 Attention Residuals:把所有 LLM 都在用的残差连接,从每一层按固定方式往后传,改成每一层自己学一个权重,决定前面哪些层该听、哪些少听
这里先说残差连接这个老结构,是 2015 年何恺明提出,之后被所有 LLM 继承。在它之前,深度学习训不动超过 30 层,有了它,百层也能训
残差的默认做法是加。第 1 层的输出、第 2 层的输出、一直到第 29 层的输出,到了第 30 层,全部等权相加。每一层对后面层的贡献是固定的,模型训练过程中调整不了
问题就出在这个等权。第 30 层收到的是一锅端进来的 29 层总和,哪一层对当前任务关键、哪一层是杂音,它自己分不出来
还有一个副作用,论文里叫 dilution。深层要想让自己的信号不被前面几十层盖过去,只能把输出幅度写大。训练到后期,PreNorm 架构的 LLM 各层输出的数值量级会随着深度线性涨,这一现象在多个开源模型上被观察到过
Kimi 的做法,是给每一层加一组可学习的权重,用 softmax 归一。训练时,第 30 层会学出一个分布,告诉自己前面 29 层里哪些该多听、哪些少听。dilution 跟着消失,深层的输出量级有界,反向传播的梯度在各层分布也更均匀
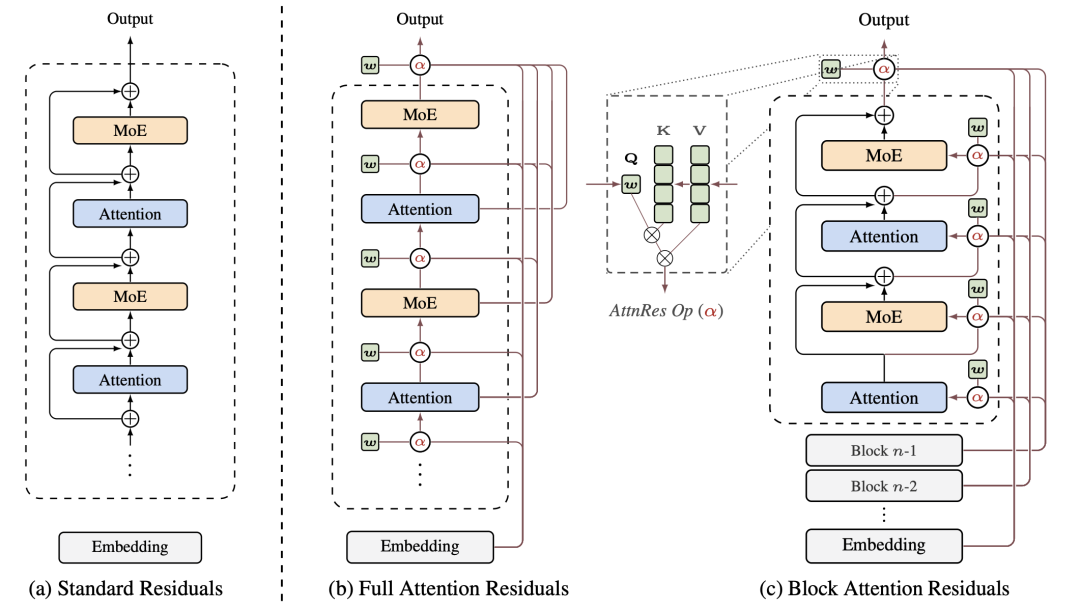
论文 Figure 1:Standard Residuals / Full AttnRes / Block AttnRes
论文里把这个对应关系叫 sequence-depth duality。时间维度上 Transformer 替代了 RNN,深度维度上 AttnRes 替代残差,是同构的两步
论文附录里有张权重热力图,每一个深色格子,都是一次学会的选择
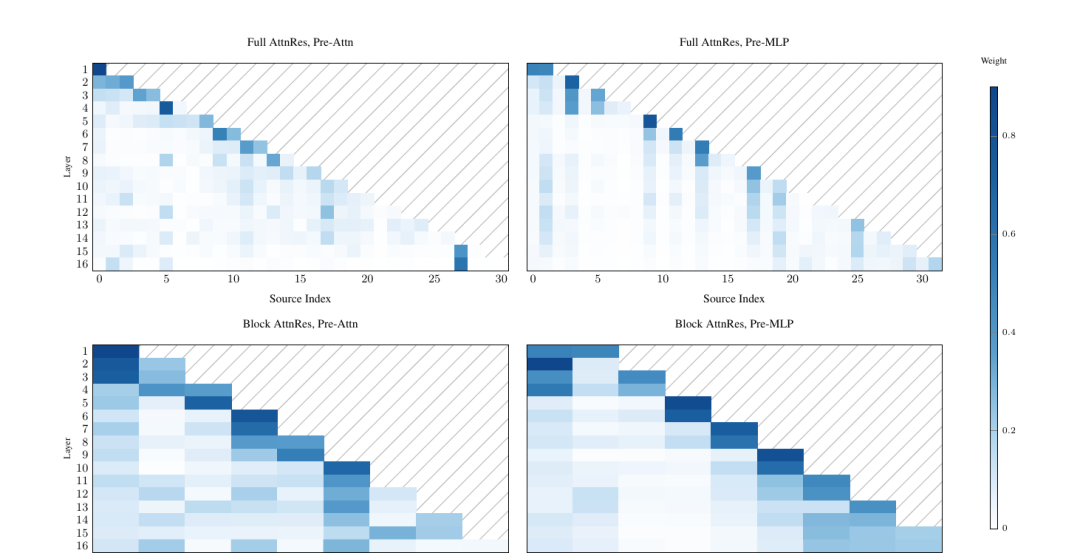
训练完之后,每一层听前面哪些层、分别听多重
Attention 层和 MLP 层的风格不一样。Attention 层分布更散,会跨几层往早期借信息,有的甚至绕回最早那一层。MLP 层几乎只看上一层
论文里的 Block AttnRes 是工程折中。理论上最理想的,是每一层注意到前面所有层。但大规模分布式训练下通信量会爆炸。Block 把层打成 8 个 block,只传 block 级的表示,通信量从 O(Ld) 降到 O(Nd)
工程效果直给:Block AttnRes 的 8 块方案,在同样算力下,验证 loss 等价于基线的 1.25 倍算力。Kimi 把这组实验在不同模型规模上都跑了一遍,每一档都成立。这套已经合进 Kimi Linear 的 48B 总参 / 3B 激活模型,跑了 1.4T token,下游任务全面涨点
而在这里,Kimi 用 AttnRes 点的推理
同一个指向
任务层的点兵是 Agent 集群,社交层的点兵是 Claw 群组,模型内部的点兵是 AttnRes
群体智能的关键词落在智能上:每个兵长什么样、该派去哪,模型得看得清
Kimi 点兵,能多多,更益善





