 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库Kimi K2.6来了:300个Agent优雅并行4000步,它就是Agent的OS|附一手实测

邮箱|dongdaoli@pingwest.com
4 月 20 日,月之暗面发布了新模型 Kimi K2.6,并同步开源。
从官方展示来看,这次更新重点有三块:长周期 coding、网页设计生成,以及更大规模的 Agent Swarm。
把三项能力放在一起看,会发现 Kimi 想强化的,已经不只是模型本身,而是模型调度 agent、接管任务流程的能力。它要做的就是一个能最终成为Agent的OS的模型。

长周期 Coding 能力
K2.6 在内部基准 Kimi Code Bench 上较 K2.5 有明显提升,覆盖 Rust、Go、Python 等多语言,以及前端、DevOps、性能优化等场景。
官方给出两个 demo:一是用 Zig 语言在 Mac 上优化 Qwen3.5-0.8B 的本地推理,连续执行 12 小时、4000 余次工具调用,推理吞吐量从 15 tokens/s 提升至 193 tokens/s。
二是自主重构开源金融撮合引擎 exchange-core,历时 13 小时、1000 余次工具调用,中值吞吐提升 185%,峰值吞吐提升 133%。
两个案例指向同一个问题,在超出常规训练分布的任务里,冷门语言、接近性能上限的存量项目,模型能否长时间稳定执行而不漂移。
长周期稳定性是目前行业普遍在攻的方向,改进路径主要集中在三个层面:错误恢复能力、长程可靠性,以及工具调用逻辑。
各家的解法有所不同,Anthropic 近几个月公开强调的重点,是 harness 与 context engineering,而不只是单纯拉模型分数。Google 的思路是用超长上下文窗口来对抗长程漂移,Gemini 提供最高 100 万 token 的上下文窗口。K2.6 的应对方式是将可靠性直接压在模型层,据 CodeBuddy 内测数据,工具调用成功率达 96.60%,factory.ai 的独立评估显示,K2.6 整体较 K2.5 提升约 15%。
网页设计生成能力
Kimi 建立了内部基准 Kimi Design Bench,从视觉输入、落地页生成、全栈应用、创意编程四个维度与 Google AI Studio 进行对比,K2.6 表现更优。
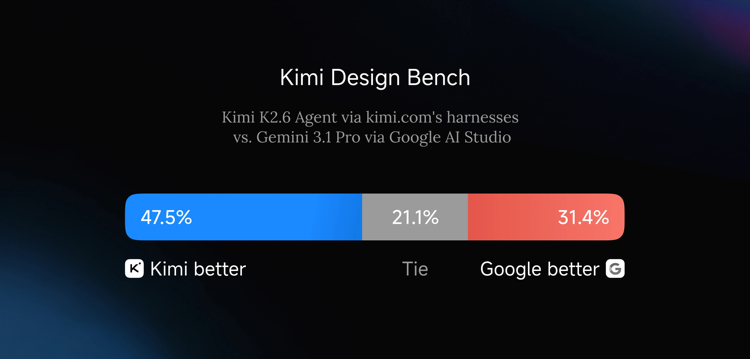
具体能力包括:从单条 prompt 生成带动效的前端界面、调用图片/视频生成工具输出视觉素材,以及覆盖登录、数据库等基础全栈功能。
视觉转代码这个方向,行业竞争格局相对清晰。Gemini 凭借原生多模态架构在视觉理解上具有结构性优势,Google AI Studio 也是目前最主流的前端生成测试平台之一。
K2.5 发布时就有评测将其定位为"中国首个在前端设计和视觉理解上与 Gemini 2.5 Pro 形成真实竞争的模型",K2.6 是在此基础上的延续。
Agent Swarm 扩容
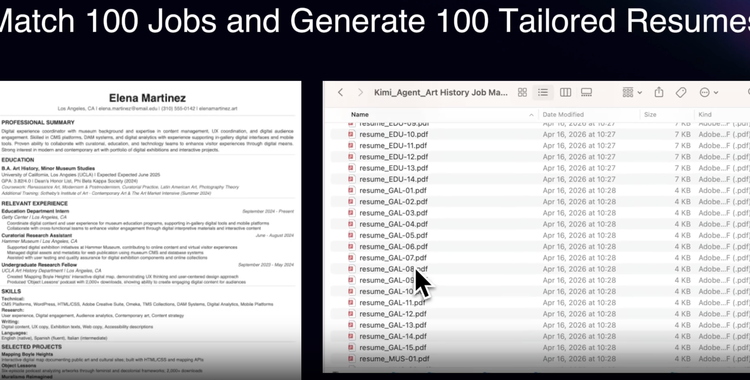
相比 K2.5,Agent Swarm 的规模从 100 个子 agent、1500 步,扩展至 300 个子 agent、4000 步并行执行,K2.6 负责调度与任务失败后的自动重分配。
官方 demo 展示了 100 个子 agent 同时生成 100 份定制简历,以及批量为 30 家无官网零售店生成落地页等场景。Kimi 内部也已采用这套系统,内容团队通过 Claw Groups 跑发布流程,Demo 制作、基准测试、社媒发布各有专属 agent 分工。
多 agent 协作是目前各家竞争最激烈的方向之一,但路线分歧明显。OpenAI 的方向是在产品层做深度集成,将 agent 能力封装进 ChatGPT 的工作流。Kimi 的差异化在于开放性,Claw Groups 不绑定自家模型,允许接入任意第三方 agent,这一设计更接近 agent OS 的定位,而非封闭的产品生态。
Benchmark 环节
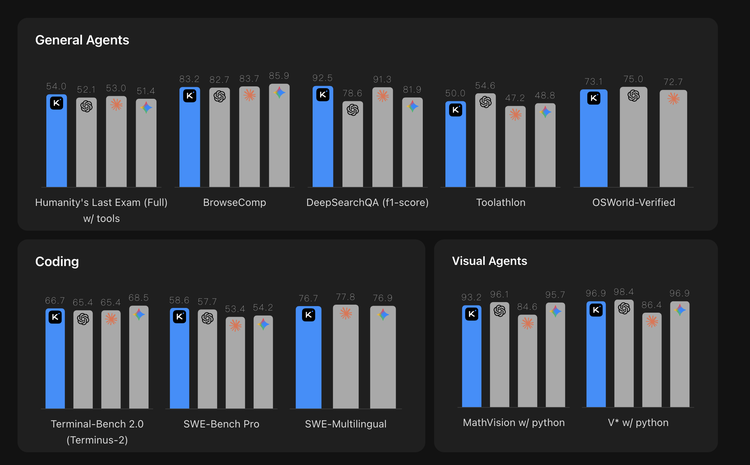
K2.6 在基准测试中最突出的方向是 agent 搜索和实际工程 coding。
DeepSearchQA f1-score 达到 92.5,领先 GPT-5.4 的 78.6 超过 13 分;SWE-Bench Pro 以 58.6 排在四家第一。
但在同类工具调用测试中,Toolathlon 和 MCPMark 分别以 50.0 和 55.9 落后于 GPT-5.4 的 54.6 和 62.5,说明 K2.6 在信息检索类 agent 任务上有优势,在第三方工具调用质量上仍有差距。
coding 方向整体处于第一梯队,但未能全面领先:Terminal-Bench 2.0 落后于 Gemini,SWE-Bench Verified 三家几乎打平。
推理和数学是明显短板:HLE-Full 不带工具仅得 34.7,比 Gemini 低近 10 分;AIME 2026、GPQA-Diamond 均落后 2—4 分。视觉方向与 Gemini 基本持平,但整体落后于 GPT-4.5。
实测 K2.6
编程能力
4 月 14 日,K2.6 Preview 上线后,我把它接进 Claude Code,拿来做一个社区官网项目。项目内容不算简单,既有文章迁移、历史图片处理,也有全栈开发。整个过程断断续续跑了 6 天,最长一次任务跑了3小时,前后分成 6 个彼此独立的会话。
这轮测试里,K2.6 有两个表现尤其值得记下来。
先说长周期可靠性。现在很多 AI 编程助手都有一个很明显的问题:会话一断,上下文就像被清空了一遍,下次重新打开,往往还得从头对齐背景、技术栈和代码规范。但这次测试中,我在每次新会话开始时都没有额外交代项目背景,K2.6 依然能延续第一天确定下来的技术选型和设计规范,6 天里产出的代码风格也基本保持一致。对于一个持续推进、不断迭代的真实项目来说,这种稳定性比单次输出的惊艳更重要。
再说指令遵循。我给它的指令其实很简单,只有一句:“优化 CMS UI。” 但 K2.6 没有停在表层执行,而是先回看已有设计规范,确认技术约束,再自己拆计划、往下推进,整个过程几乎没有额外追问。
在处理业务约束时,它也不是机械照做。比如迁移脚本会主动保留原始 URL,并在 README 里补上潜在风险说明。这说明它理解的不是一句命令本身,而是命令背后的含义。
网页编程能力
测试 1:动效交互
promtps:为一家叫 PW 的 AI 写作工具设计一个产品落地页,要有科技感。需要包含:首屏 hero 区块、功能介绍区、用户评价区。滚动到不同区块时有入场动画,hero 区有视差效果,CTA 按钮有 hover 动效。
K2.6 生成的整体水准很高。配色用了 oklch 色彩空间,间距和字体用 clamp() 响应式缩放,设计 token 抽得很系统,说明不是随手填的。
动效有层次,视差用鼠标位置 + 滚动双驱动加 lerp 插值,GSAP 入场用了 stagger 错开时序,feature card hover 做了跟手光效,这些细节大多数输出不会主动加。
弱的地方是内容层,三张功能卡片的图标都是通用 SVG,用户评价头像只用了汉字首字,视觉上偏模板化。结构和动效的完成度高,内容设计的差异化不足。
测试 2:视觉输入
那些眼花缭乱的特效,很难用语言描述出来,这时候,多模态视频就是一个很好的输入方式。
我们录屏了 lusion.co 网页的交互,滚动特效相当复杂,我们让 K2.6 根据视频写一个网页。(在 Claude Code 环境中)
prompts:根据视频,做一个特效一样的网页。
我们先看一下原网站。
第一次生成时,K2.6 只看了 17 帧的视频,做出来的效果并不好,经过第二轮对话,K2.6 页看到了更多细节。

我们可以看一下 K2.6 仅仅通过视频生成的网页,虽然和原网页的动效还有差距,但网页的元素结构,尤其是宇航员滑动效果基本都有模有样。
分析一下操作流程,可以发现,在 ClaudeCode 环境下,K2.6 只能靠抽帧图片来学习视频,如果 harness 搭建的更加完善,K2.6 可能可以更好还原。
Agent 集群
这一项能力在 Kimi 官网进行测试,采用 K2.6 Agent 集群分析 K2.6 本身的能力。

Kimi 首先对任务做整体判断,分析涉及哪些环节,这一步不联网,因此将 K2.6 识别为 2025 年发布的模型。

初步规划完成后,K2.6 加载相应技能,进入初步研究阶段,并将研究任务拆解成多个维度。


前两步由 K2.6 单一模型执行,第三步则根据拆解出的维度,每个维度派出一个 agent 并行展开研究。
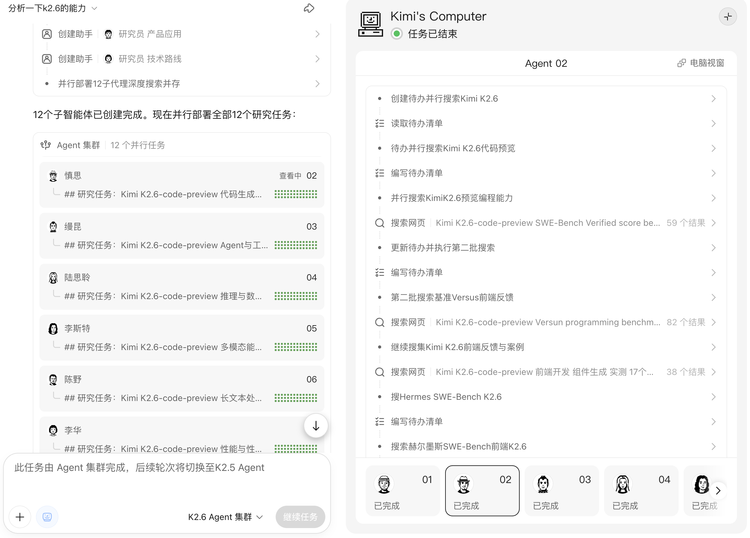
例如,"陆研究员"负责研究 K2.6 的推理能力,"陈研究员"负责研究长文本能力。

每个 agent 可独立调用不同技能、联网搜索,并以 plan 模式生成 todo 推进任务,最后将结果汇总共享。
汇总后,Kimi 会对各 agent 产出的内容进行交叉验证,以纠正类似"K2.6 发布于 2025 年"这类错误。
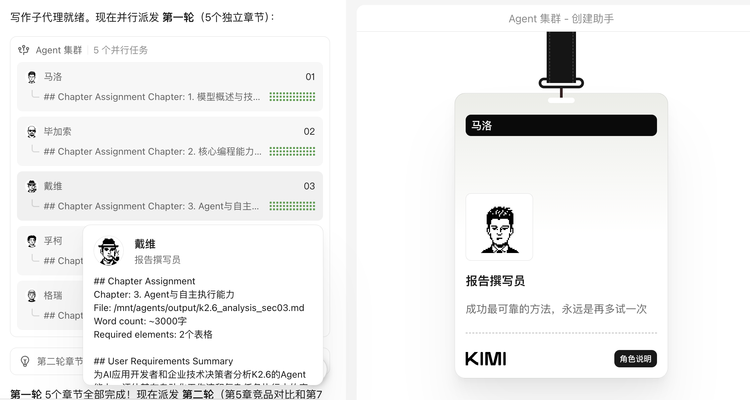
进入报告撰写阶段后,同样派出多个报告撰写员 agent,并行完成各部分内容。
这套流程在工程上有一个值得注意的设计决策,交叉验证不是甩给用户的,而是内嵌在流程里自动完成的。单个 agent 在独立运行时不可避免地会产生幻觉,Kimi 的应对方式不是试图消灭这个问题,而是在架构层接受它的存在,用并行制造冗余,再用验证层消化误差。
这与人类团队的协作逻辑高度相似,分头调研、汇总对齐、分工执笔。更重要的是,这套流程对用户来说是全程透明的,每个 agent 在做什么、发现了什么、被纠正了什么,都可以追溯。
这在当前多 agent 产品普遍是黑箱的背景下,是一个实际的差异点。
DeepSeek 没来,K2.6 先来了
最近一段时间,AI 圈都在等 DeepSeek 的下一张牌。上一次它抬高了国内模型竞争的基准线,这一次,所有人也都默认,下一个高潮还会从“谁的模型更强”开始。
但 K2.6 有意思的地方,恰恰在于它没有只回答这个问题。
长周期 coding、网页生成、Agent Swarm,看上去是三项能力,其实月之暗面已经不满足于把模型做得更聪明,而是想让模型去组织更多 agent、接管更长流程、吞下更完整的任务链条。参数规模、benchmark 排名、单轮对话质量,当然还重要,但它们开始退到第二层。真正被推到台前的,是调度、协作、验证和交付等。
如果说过去的大模型竞争,比的是谁更像一个更强的大脑,那么 K2.6 想证明的,是另一个方向:未来真正有分量的产品,也许不只是一个模型,而是一群 agent,外加一个会指挥它们的中枢。
这个方向最后能不能跑通,现在还不能下结论。但至少,月之暗面已经先把问题改写了。






