 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库小鹏机器人 DIAL 模型评测:让 VLA 学会“先想再做”|EmbodiedCLUE
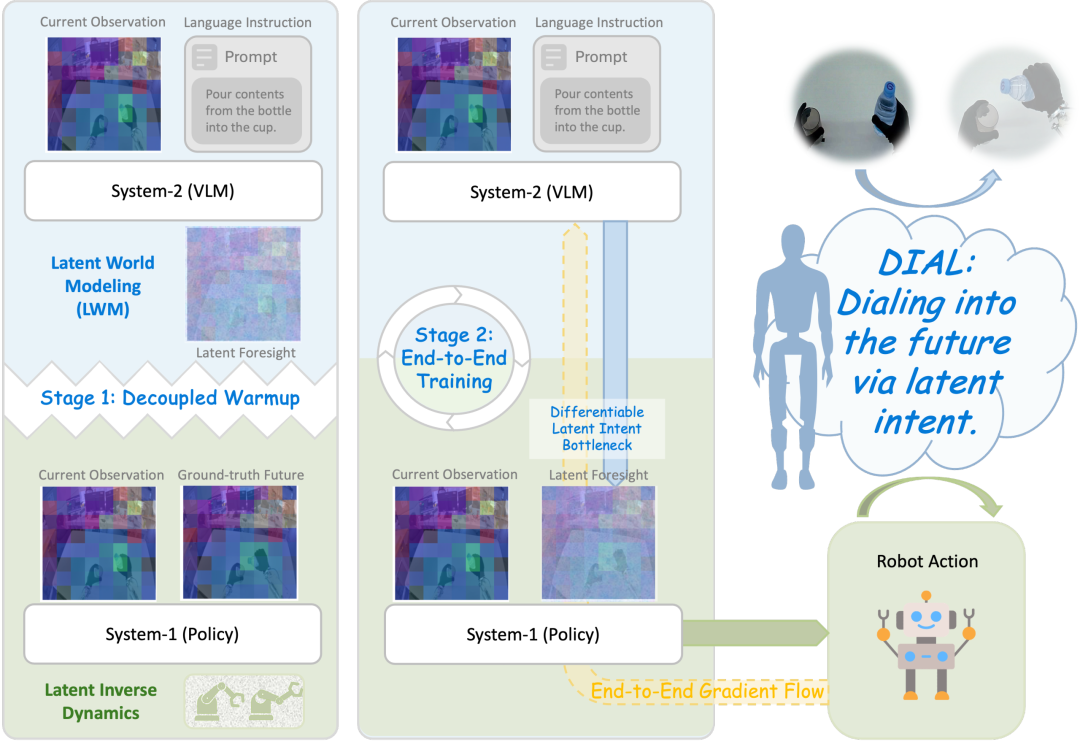

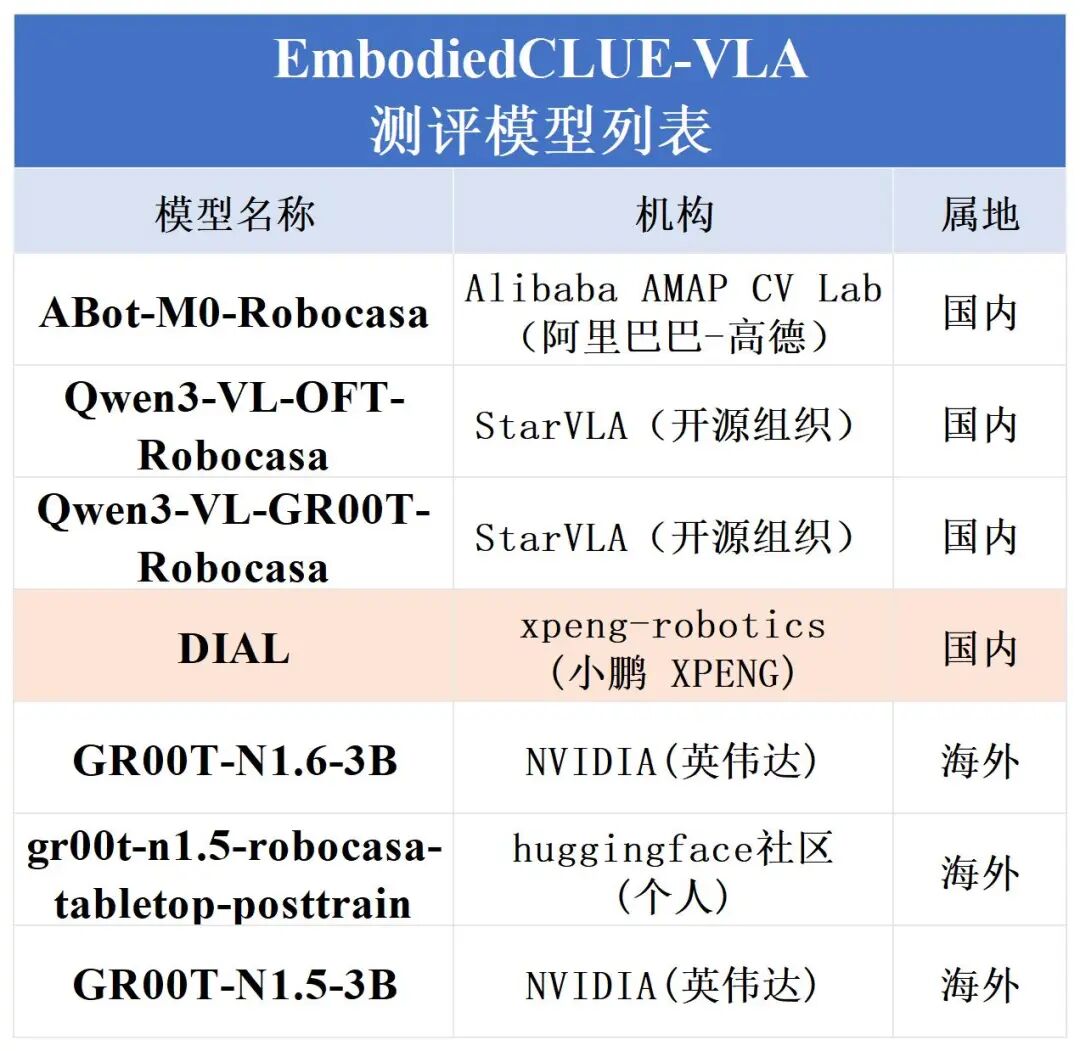
在上一阶段评测中,Robocasa-GR1-Tabletop 场景下六个公开模型的统一接入、统一评测与结果标准化已经完成,基准环境、任务设置与主要指标体系也已初步建立。为完善榜单,EmbodiedCLUE-VLA具身智能评测基准在本次评测中添加了小鹏机器人旗下xpeng-robotics实验室的DIAL模型参与评测。
SuperCLUE,公众号:CLUE中文语言理解测评基准具身智能桌面操作场景统一评测:基准能力、中文支持与综合评分|EmbodiedCLUE
# 评测概览
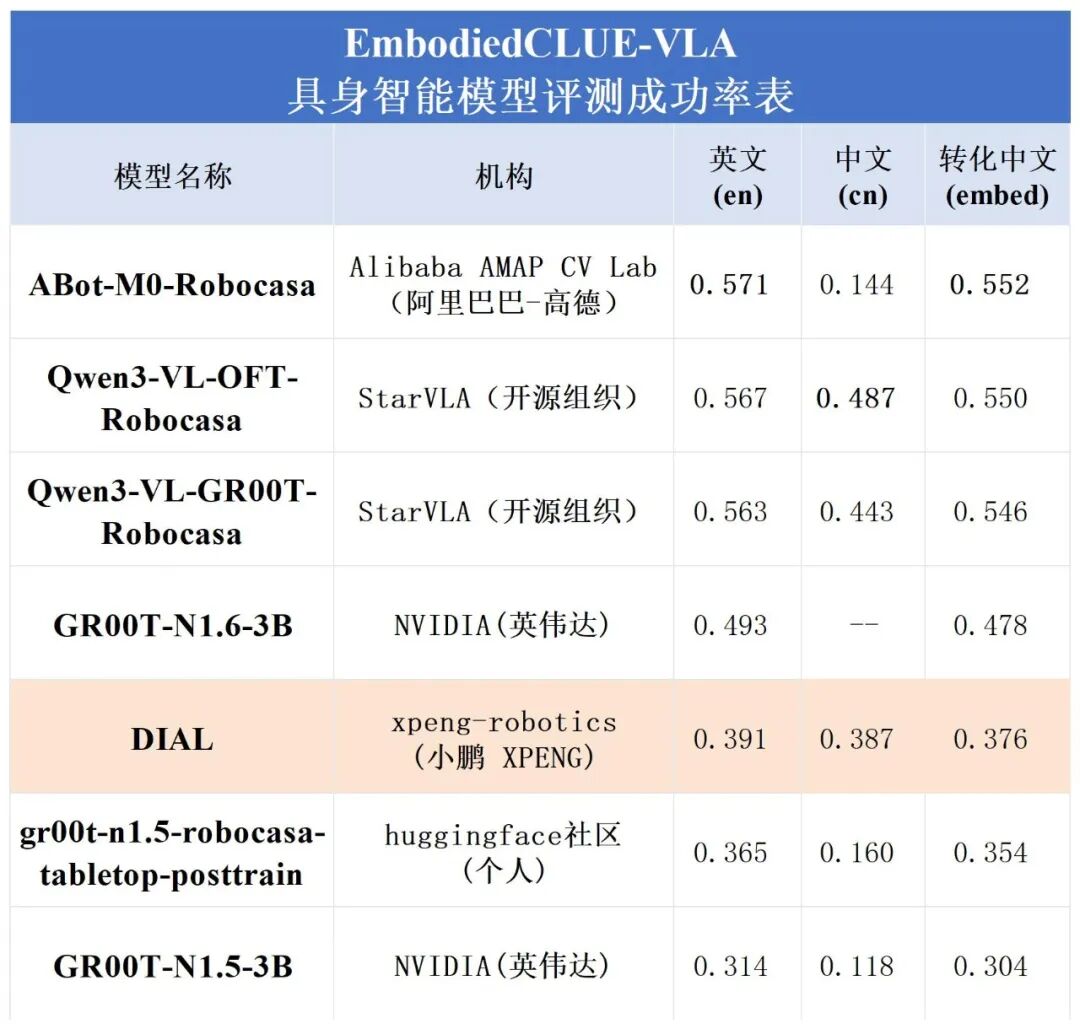
1.模型评测总表
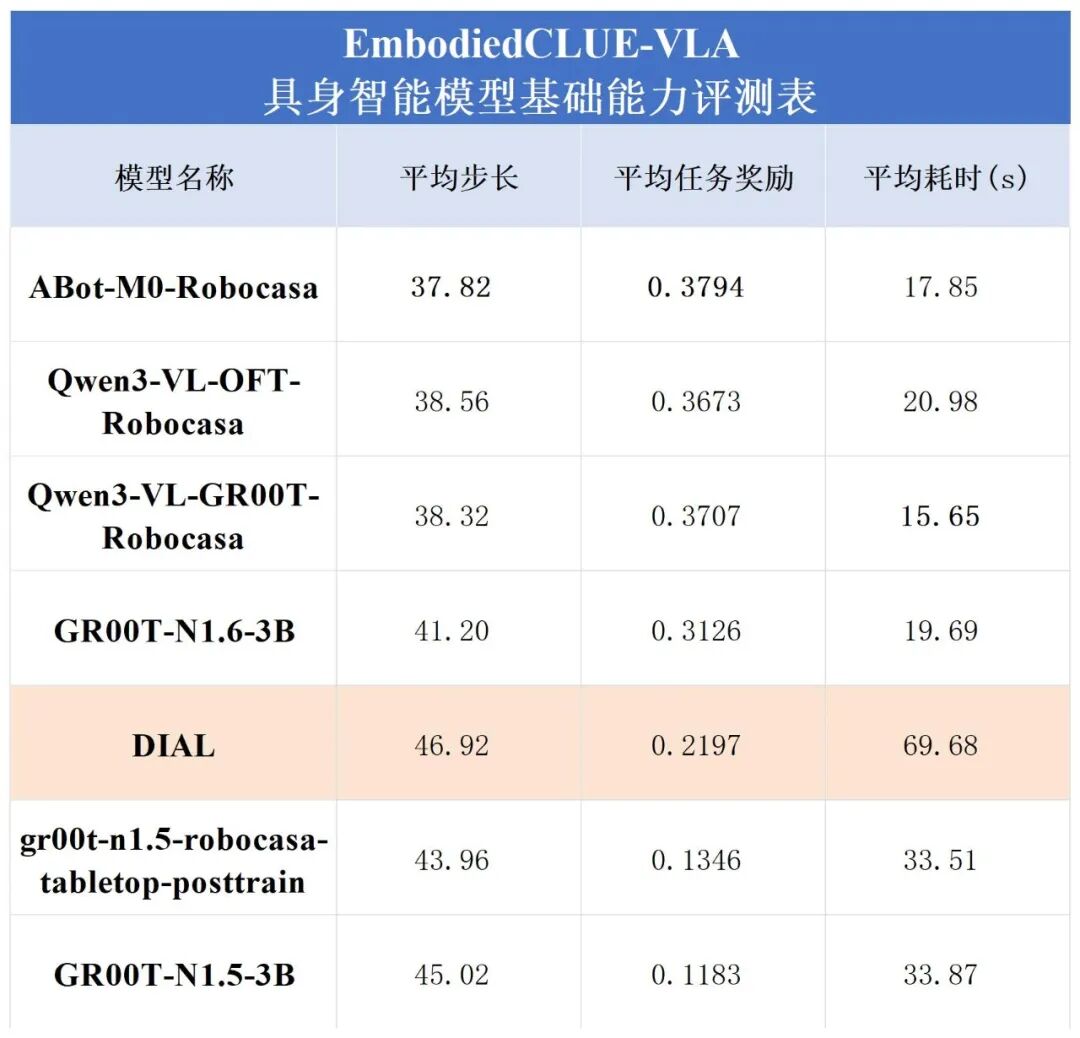
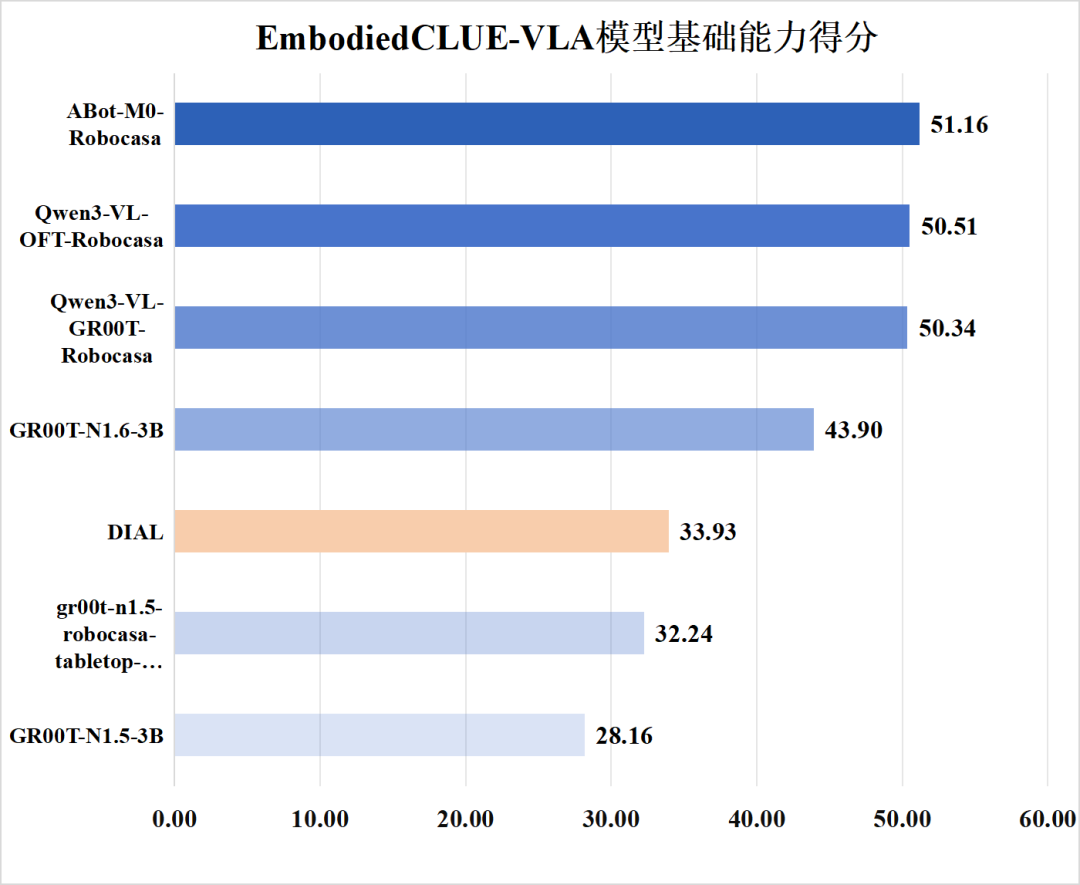
2.基础能力评分
4.象限图
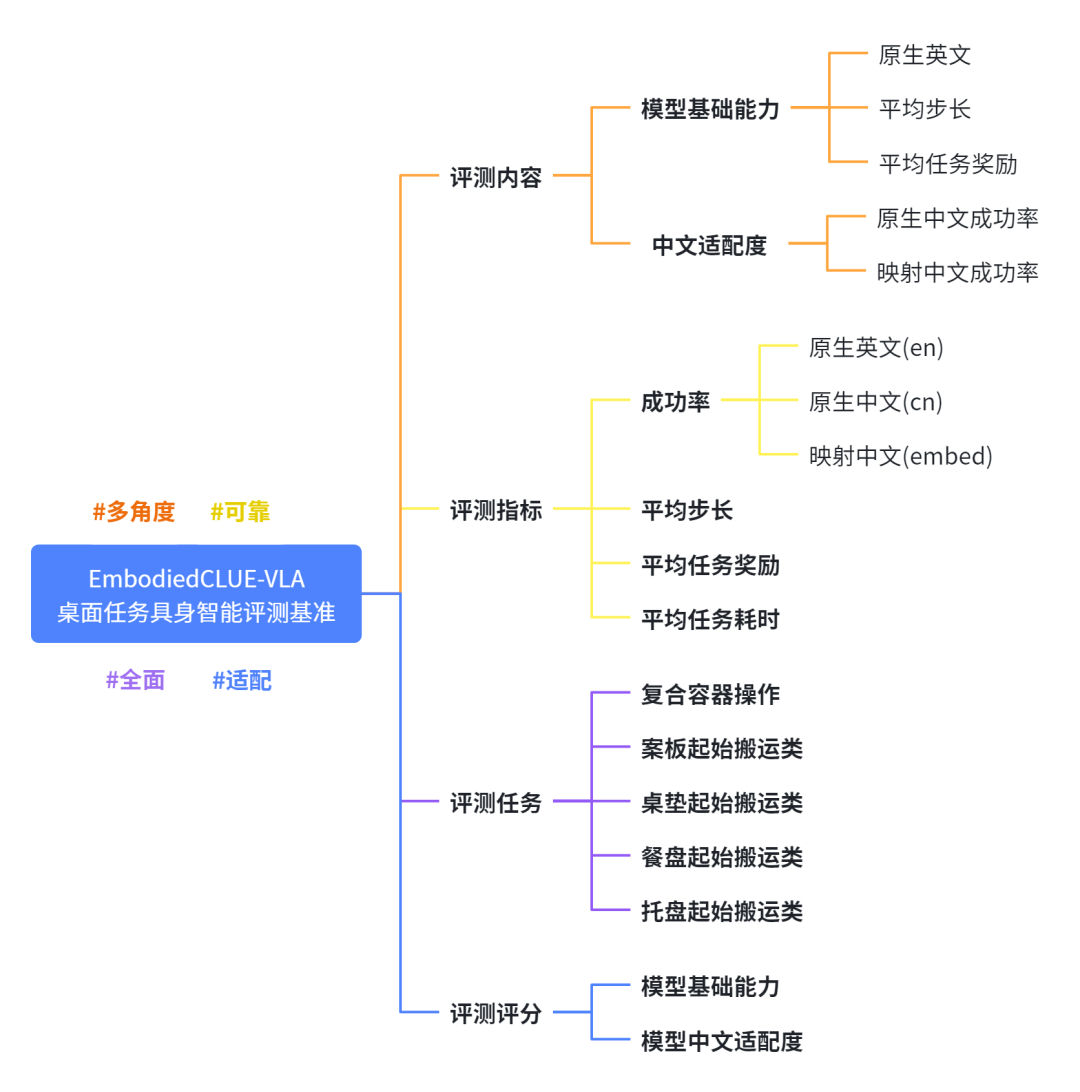
一、评测内容
二、评测任务
1.评测总表
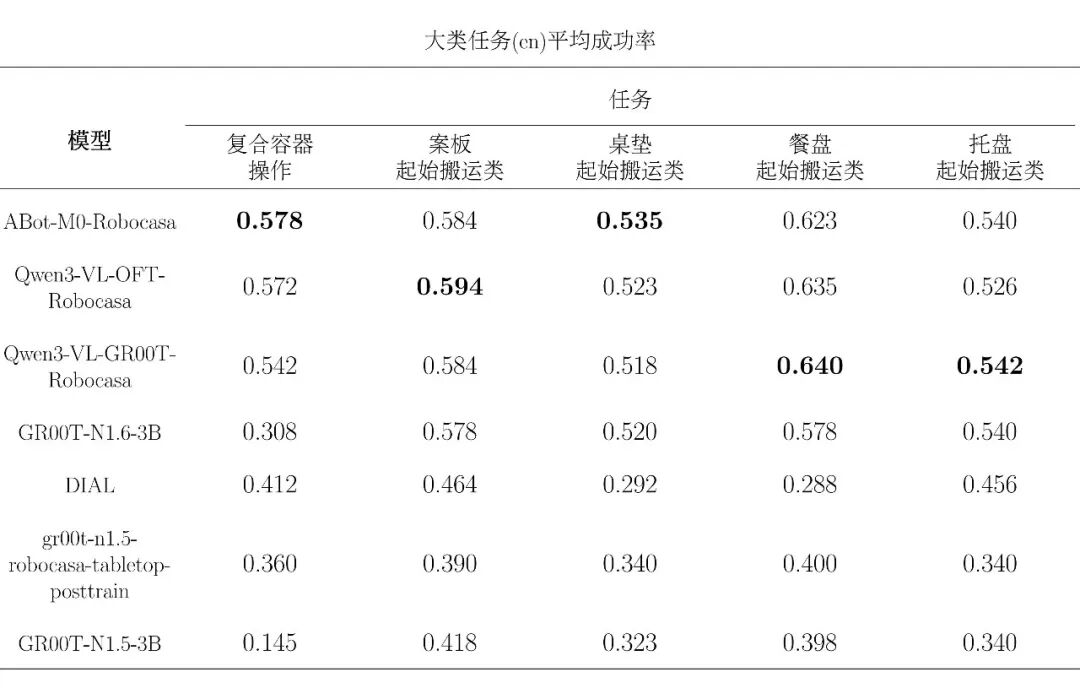
下附原生中文 cn 大类任务模型评测表:
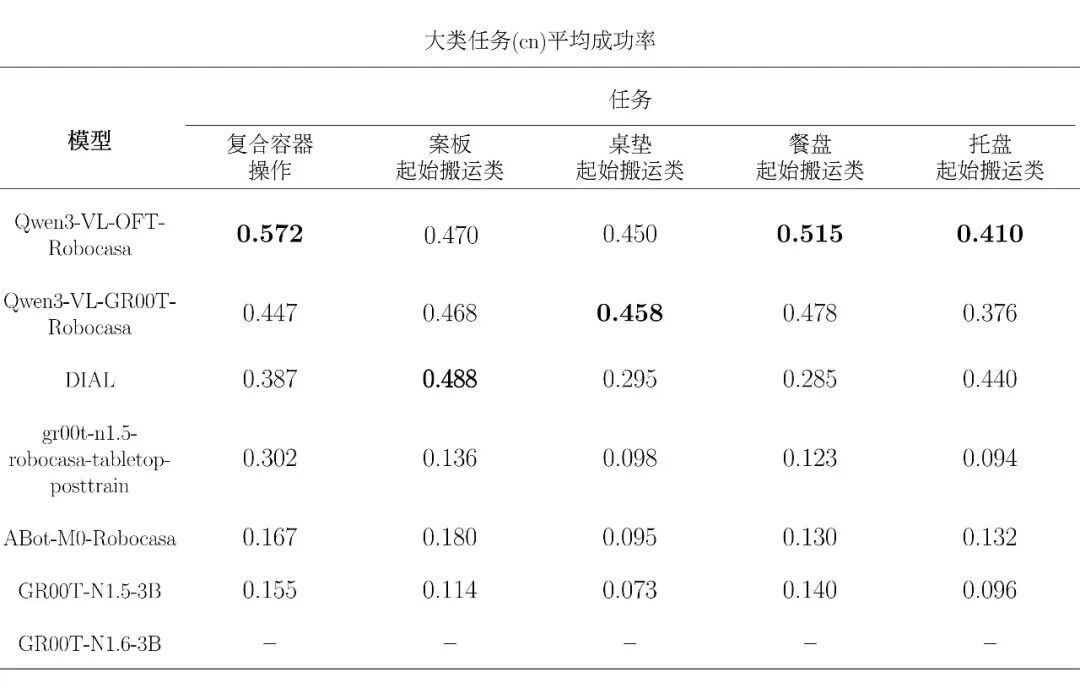
下附转化中文 embed 大类任务平均评测表:
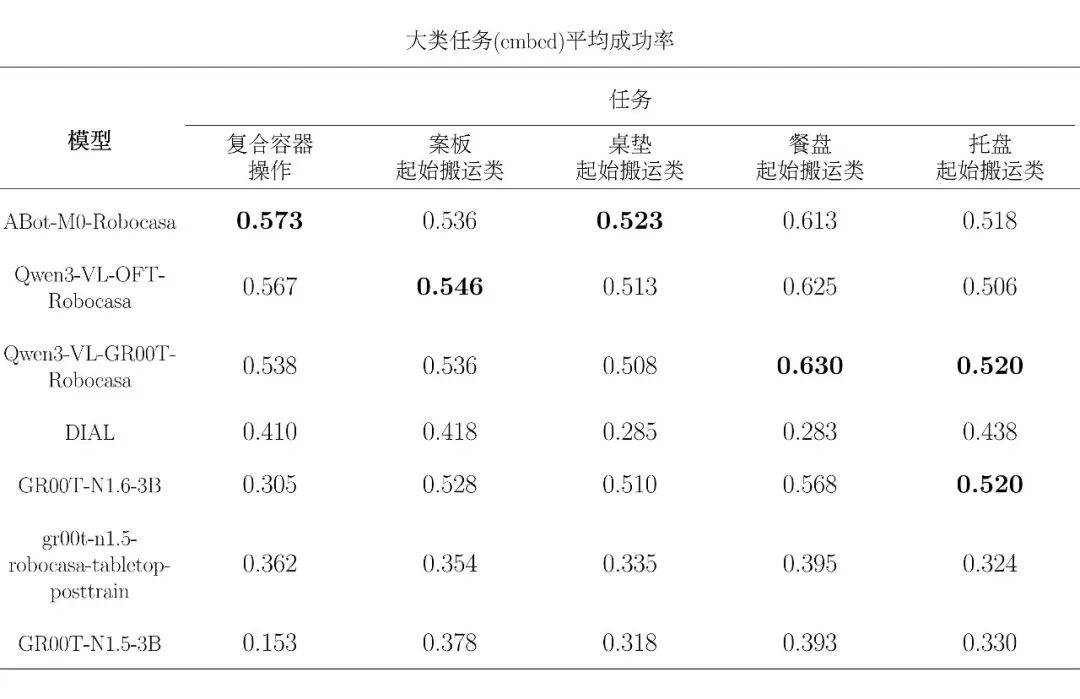





三、评测评分
1.评分排行
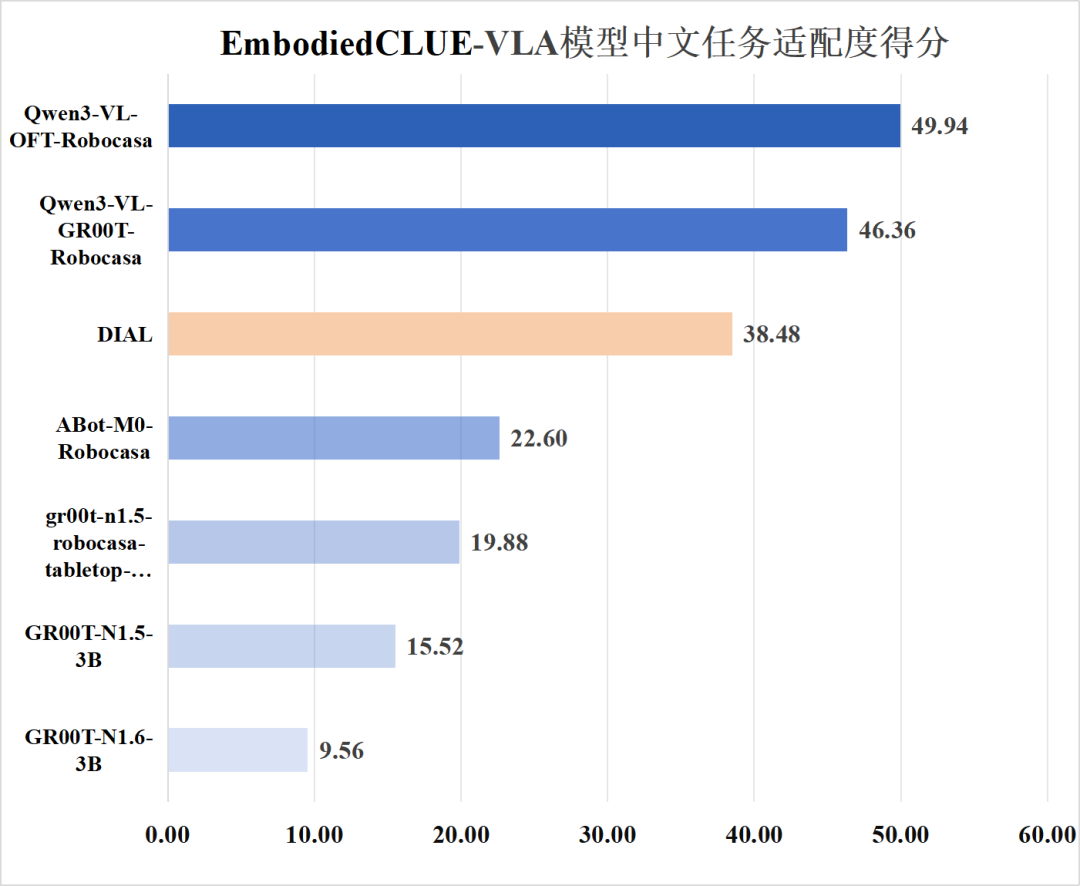
为了方便可视化评分信息,下附模型基础能力得分、模型中文适配度得分图:
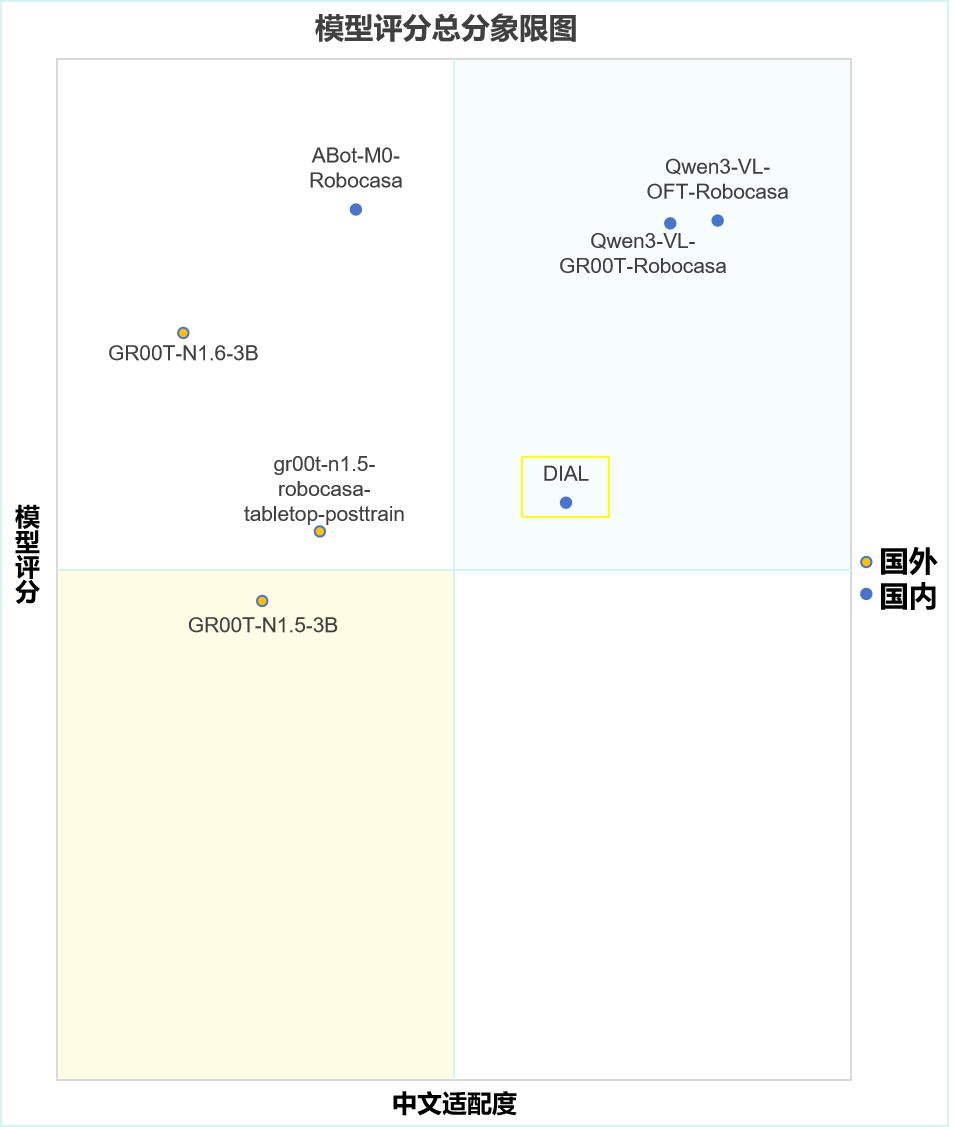
2.评分象限图
为了进一步反映模型总体得分情况,下附模型评分总分象限图:
四、评测总结
1.原生能力
综合来看,在引入 DIAL 模型后,本轮评测不仅完善了榜单结构,也进一步揭示了不同具身智能模型在策略机制上的差异。基础能力上,DIAL 整体表现处于中下游区间,尚未在桌面操作任务中展现出明显优势;同时,其推理耗时显著高于多数模型,反映出其内部决策过程具有更高的计算复杂度。
这一特征与其动作生成方式密切相关:相较于纯 VLA 模型“一次前向输出动作”的直接映射,DIAL 通过多步迭代生成动作,在统一视觉-语言条件表示上进行逐步推理,从而引入了更高的计算开销。然而,DIAL相较于其基础模型GR00T-N1.5来说,综合性能仍有不小的提升。
从结构视角看,当前具身模型大致可分为两类:一类是以纯 VLA 为代表的端到端映射方案,强调“从感知到动作”的直接耦合,具有推理高效但对语言扰动敏感的特点;另一类则引入潜在世界模型或中间表示,通过在 latent 空间中对未来状态进行预测或评估,实现“先推理、再执行”,在一定程度上提升了稳定性,但也带来了额外的计算成本。DIAL 的表现介于两者之间,其多步动作生成机制在效果上体现出一种“弱世界模型化”的特征,即在不显式构建世界模型的前提下,引入隐式的中间推理过程。这里通过几个任务的实际输出来说明其任务稳定性:
2.中文能力
在中文适配方面,本轮评测中一个值得关注的现象是:DIAL 在部分任务上出现了原生中文成功率高于英文的情况。经评测链路逐层核查,可以确认中文指令在系统中被真实传入模型,该现象并非评测误差。进一步分析表明,这一结果并不意味着模型“更擅长中文”,而更可能源于其策略结构对语言变化的相对稳定性。在纯 VLA 模型中,语言差异往往会被直接放大至动作空间;而在 DIAL 中,语言首先被编码为高层语义条件,并通过多步推理过程影响动作生成,使得语言扰动在传递过程中被一定程度缓冲。当中文表达在个别任务中更直接地刻画目标语义时,便可能带来局部性能上的反超。
总体而言,本轮评测表明,模型之间的差异正在从“能力水平”逐步转向“机制结构”。在相似语义能力基础上,不同模型在语言信息的传递方式、误差放大路径以及策略稳定性上的差异,正在成为影响性能表现的关键因素。与此同时,小鹏机器人 DIAL 模型的加入,也为评测体系引入了“系统级具身智能”的代表路径,其在仿真环境中的表现尚未充分体现潜在优势,但其在真实场景中的发展仍值得持续关注。


细分任务评测总表
原生英文细分任务评测总表:
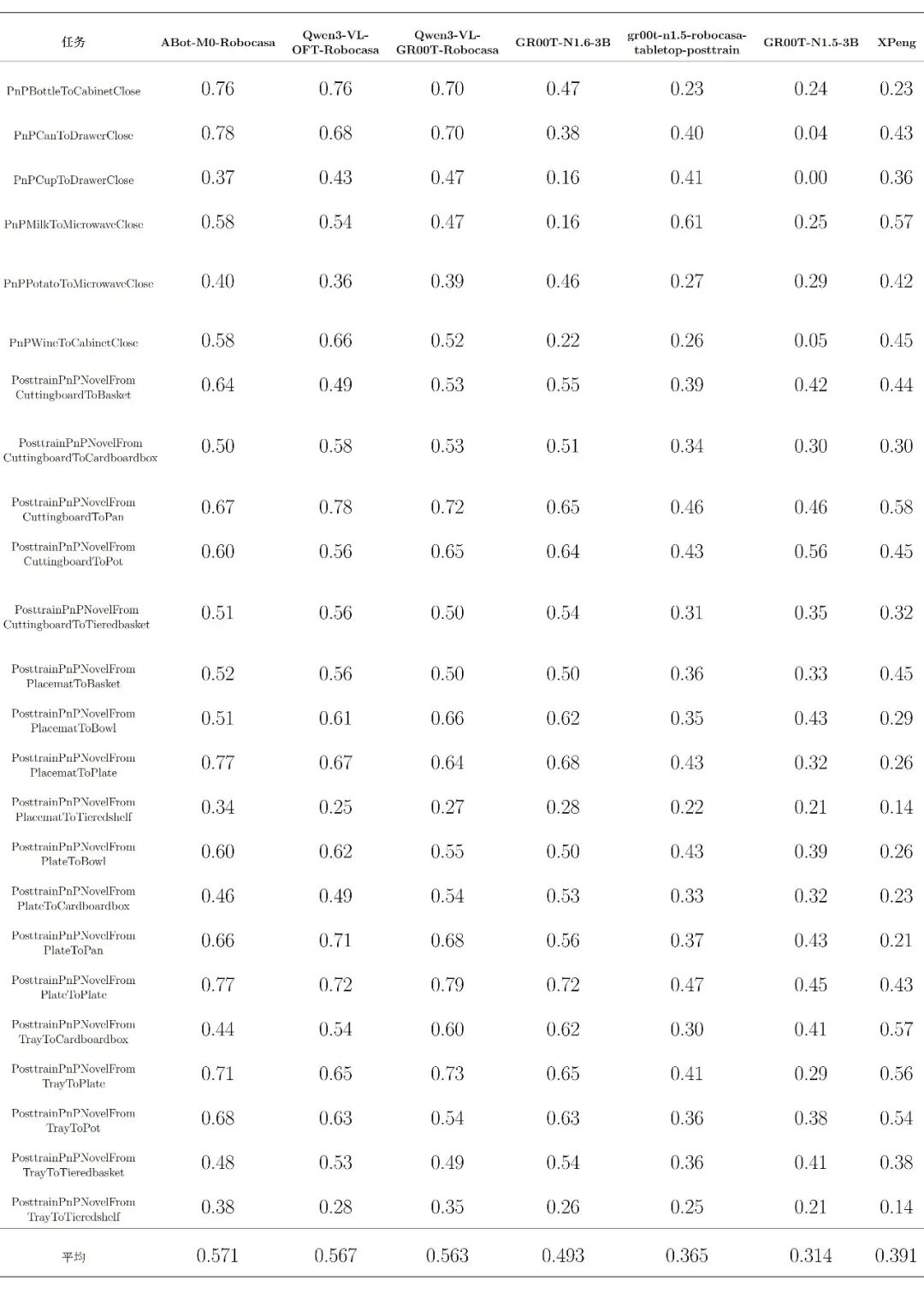
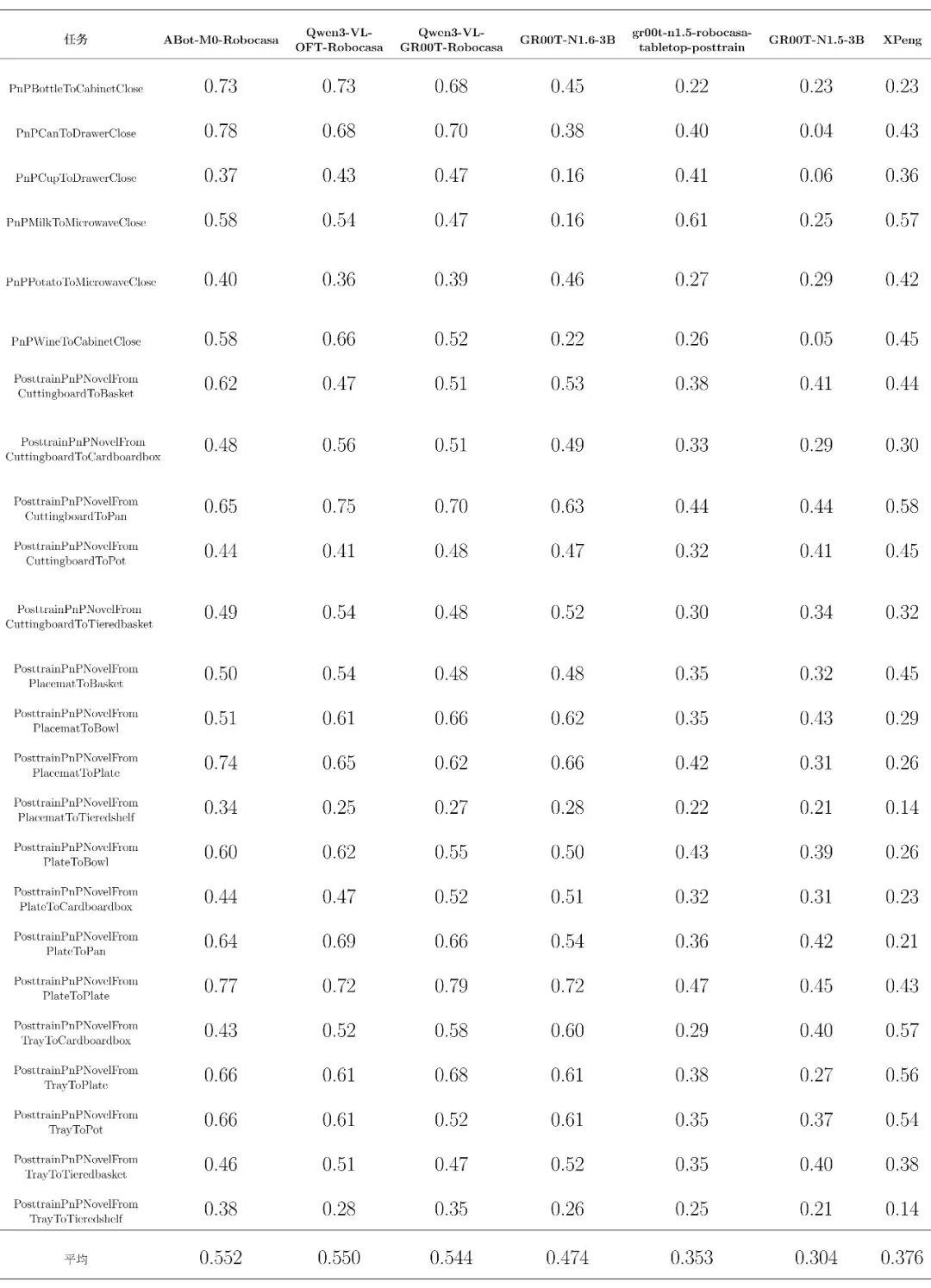
原生中文细分任务评测总表:
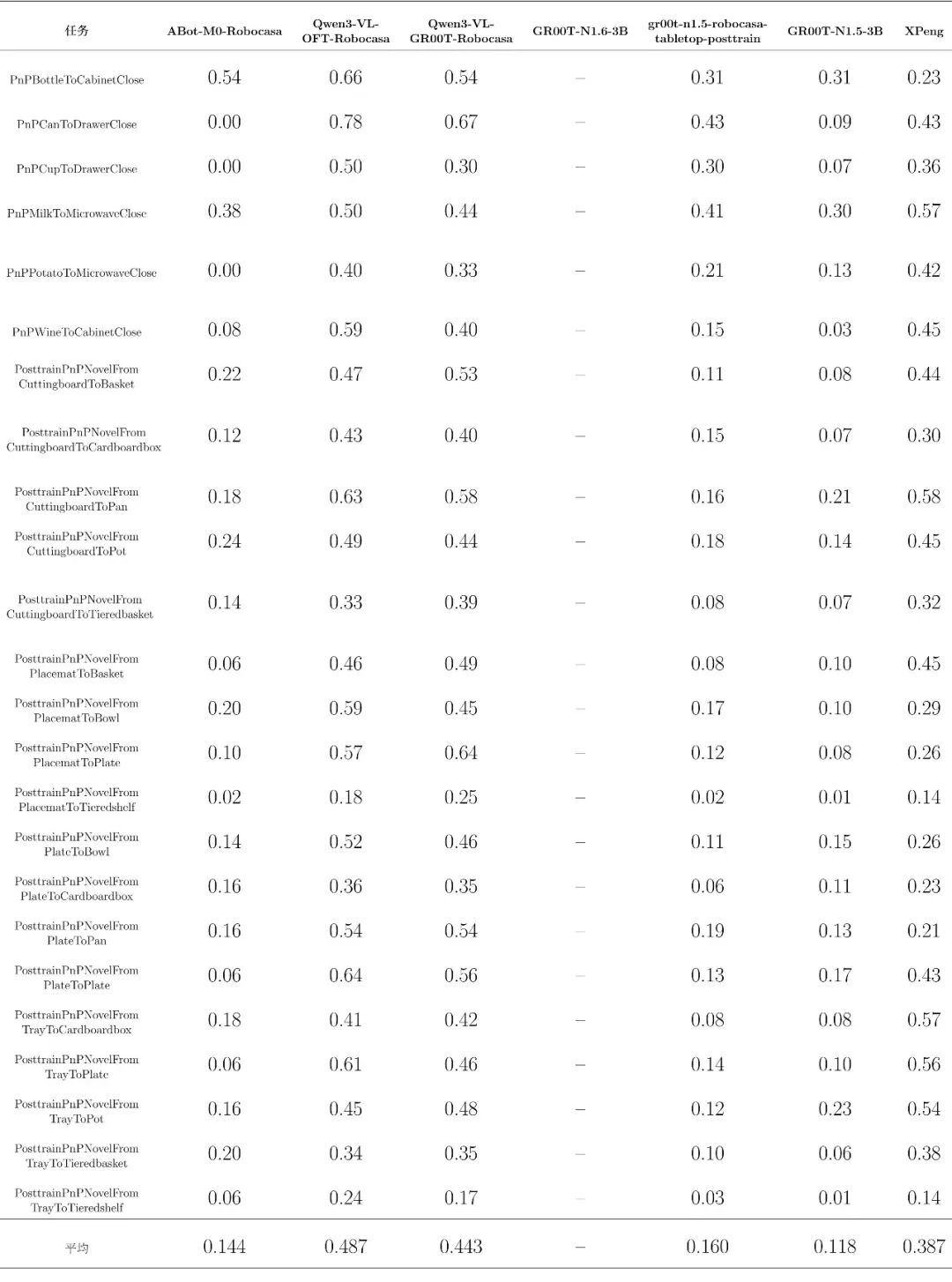
转化中文细分任务评测总表:
更多评测可视化数据和图表信息,请扫码或长按查看:






