 五度妙笔
五度妙笔 企业透视镜
企业透视镜 API商城
API商城
 数据库
数据库从特点到 API,Image2 最完整解读
太牛逼了

本文封面就是 GPT-Image-2 自己画的,非常强大
凌晨,OpenAI 正式发布 ChatGPT Images 2.0,ChatGPT、Codex、API 三端同时全量上线,API 模型名 gpt-image-2

文字精细度,能骗过人眼
在正式发布前,我做了一轮全面实测,简直是效果夯爆了:
GPT-Image-2 全量上线,中文顶到爆,50+ Case 生图实测
同时,OpenAI 在推特上甩了一张截图当预告,配文「This is not a screenshot」,这张截图本身就是 ChatGPT Images 2.0 画的
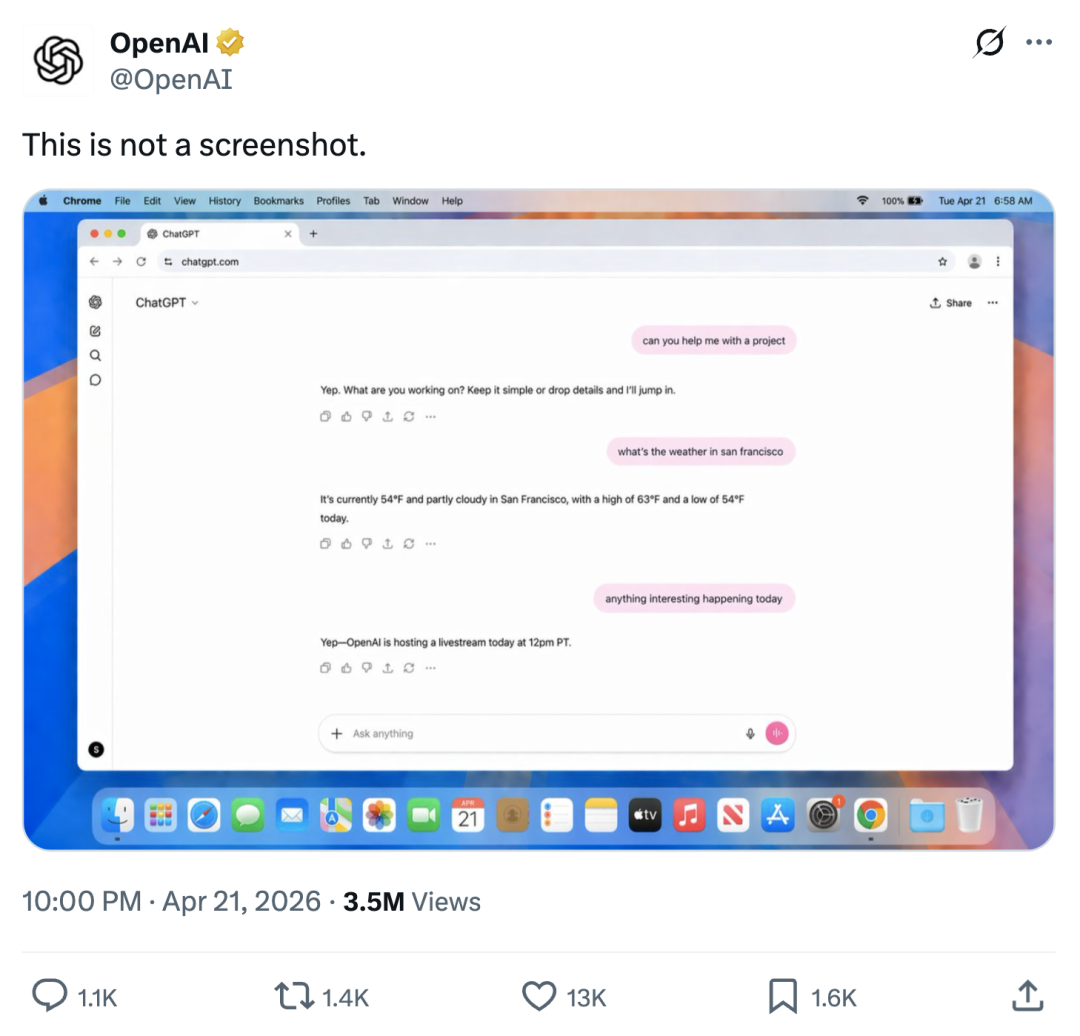
接下来,我会具体说一说这个模型的更多信息、效果以及局限性
这应该是全网最详实的一篇解读
哪里能用 · 价格 · 权限
ChatGPT Images 2.0 今天对所有 ChatGPT 和 Codex 用户开放。带思考模式(Thinking)的进阶版本,仅 ChatGPT Plus、Pro、Business 用户能用
API 端的模型字符串叫 gpt-image-2,通过 Image API(generations / edits)和 Responses API(image_generation 工具)都能调用。Codex 内置了图像生成,不需要单独申请 API key,ChatGPT 订阅直接覆盖
API 价格(按图按尺寸按质量,单位美元)
跟上代 gpt-image-1.5 比,high 档方图从 $0.133 涨到 $0.211(+59%);medium 档方图从 $0.034 涨到 $0.053(+56%);low 档基本持平
尺寸约束
最大边长 ≤ 3840px,长短边比 ≤ 3:1,总像素在 65 万到 829 万之间,每边都是 16px 的倍数。常用的 2K 方图、2K 长方图、4K 横屏、4K 竖屏都能跑,但 2K 以上当前是 beta 阶段,结果可能不稳定
编辑参数变化
gpt-image-2 的图像编辑模式默认对所有参考图按 high fidelity 处理,所以 input_fidelity 这个参数已经移除。带参考图的编辑请求 token 消耗会比上代略高
调用示例
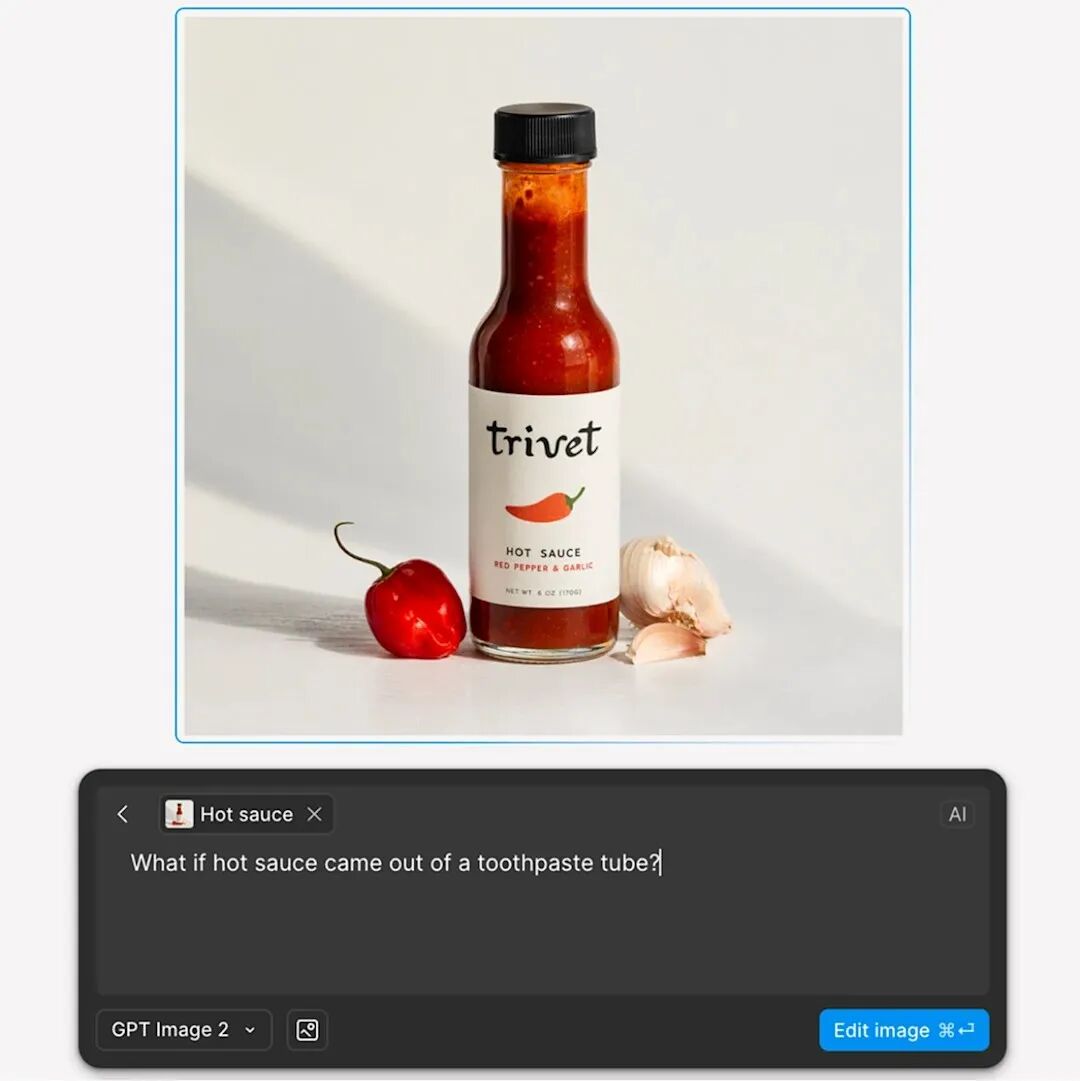
以本文开头那张封面右半边为例,21:9 的横版杂志页,high 档质量。完整调用如下:
from openai import OpenAI
import base64
client = OpenAI(api_key="sk-...")
result = client.images.generate(
model="gpt-image-2",
prompt="A horizontal magazine cover, ...",
size="1920x816",
quality="high",
)
img_bytes = base64.b64decode(result.data[0].b64_json)
open("cover.png", "wb").write(img_bytes)
就这么短。high 档每张图大约 60 秒、$0.165。封面整图分两次画(左 1024×1024 + 右 1920×816),加起来不到三毛钱人民币
第一个会思考的图像模型
这是这次发布最大的范式变化
ChatGPT Images 2.0 是 OpenAI 第一个带思考能力的图像模型。在 ChatGPT 里选 thinking 或 pro 模型时触发,做三件事:联网搜索实时信息、一次产出最多 8 张连贯图、自我检查输出质量
OpenAI 给出五个思考模式的代表演示
演示一扒 OpenAI 官网当前在售的 merch,做一张产品海报

整张海报上的 10 周年球衣、Diagram 帽衫、Chrome Blossom T 恤、Blue Chair 钥匙扣、GPT-5 火焰帽、OpenAI 笔记本、办公咖啡杯、Thinking Deeply 帽子,全是模型实时去 OpenAI Supply Co 网站搜出来的真实在售商品。模型不仅画了图,还知道这些商品在哪、长什么样
演示二在 35mm 黑板照片上证明「奇数之和等于平方数」
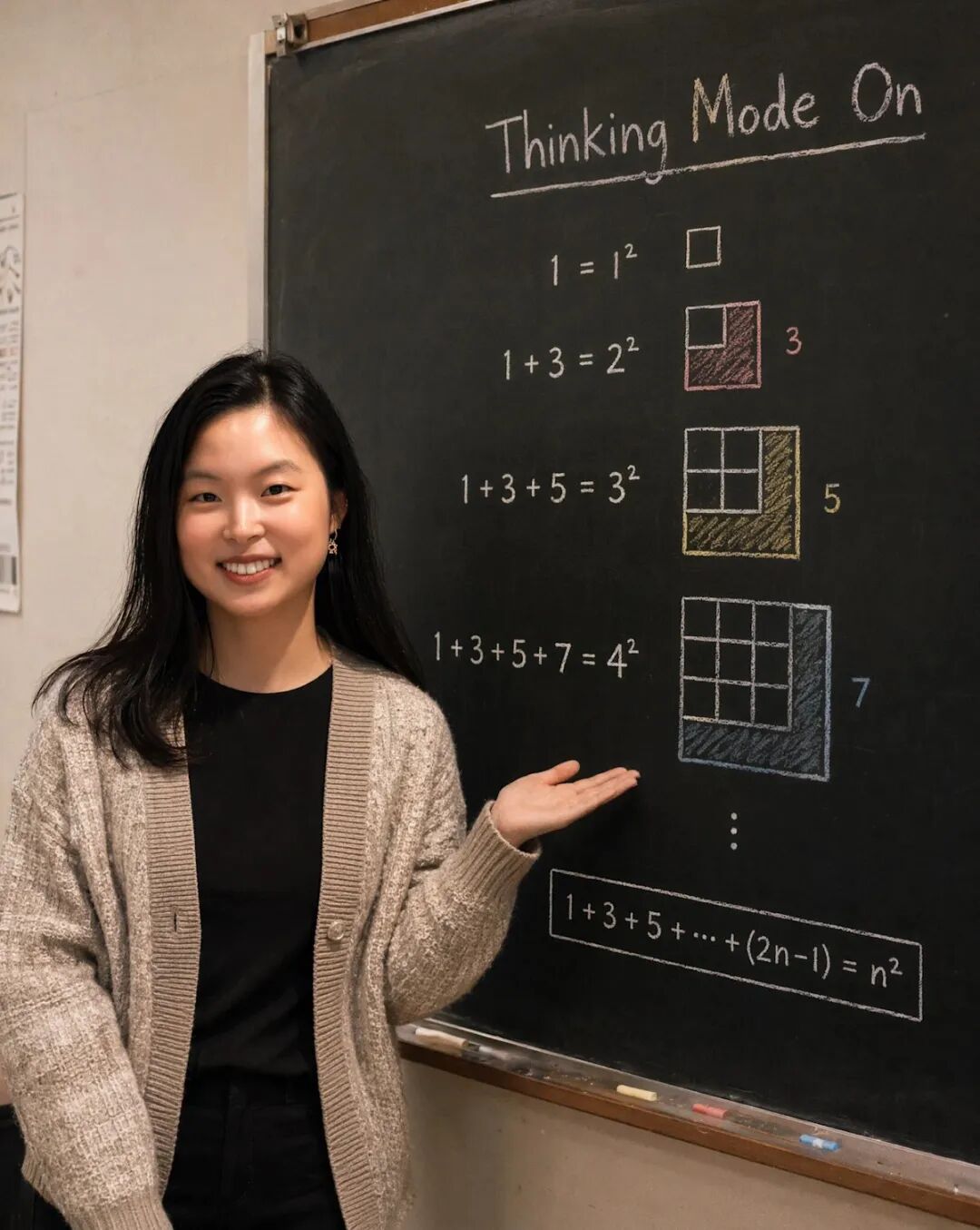
这是数学可视化推理。模型先要算清楚证明步骤,再把推导画进黑板,最后整张图按 35mm 胶片摄影风格输出
演示三一次画完四页连贯漫画

水豚和水獭去南法度假,主角形象在四页漫画里保持稳定。这是漫画工作流第一次跑通的标志
演示四抹茶店在不同社交平台的多尺寸广告

布鲁克林海茨新开的抹茶店 Kizuki,一次出 Twitter、IG 故事、IG 信息流、LinkedIn 四个尺寸的草莓抹茶物料,风格统一。以前要分四次提示词
演示五基于上传的论文 PDF 做学术海报

模型读完整篇 PDF,提取关键图表,按学术海报版式输出
思考模式的核心价值不是「画得更好」,是「替你想清楚」。idea 到成品之间那段繁琐的脑力活,模型自己接下了
文字渲染:从英文跨到非拉丁文字
这是普通用户最直接能感受到的变化
之前的图像模型在英文和拉丁字母语言上一直比较稳,日文、中文、韩文、印地文、孟加拉文一旦密度上来就崩。ChatGPT Images 2.0 在这五种文字上有显著提升
日文连环漫画主角找到一支「GPT 画像生成的羽笔」,戏剧化设定,全篇日文,整张图当物理印刷的漫画书页处理

印度书店印地、孟加拉、马拉地、泰卢固、泰米尔、乌尔都、古吉拉特、卡纳达、奥利亚九种印度语言的书封陈列,所有文字清晰可读,出版社统一标 OpenAI

中文连环漫画研究员陈博远在调试中文渲染,最后被 Sam Altman 发的「稳稳地接住你」式中文气哭。每个汉字都准,包括底部那段超小字号的「(此处为极小字号测试)无锡是作者的故乡,所以做了这幅海报,中文总算是修好了」

韩文广告韩屋酒店预订卡片,三幕场景串联,韩文标题清晰

多语言印刷海报庆祝世界各地语言的字体艺术,日本编辑风格

中文不再是图像模型的二等公民。这是这一代国内用户最该关心的变化
指令服从和细节渲染
ChatGPT Images 2.0 在「按你说的精确去做」这件事上提升明显
特别是图像模型一向头疼的几个细节:小字、图标、UI 元素、密集排版、微妙的风格约束。API 端最高支持 2K 分辨率
狼的科学杂志页「关于北美狼远没有想象中那么危险」的编辑页,光面、流畅、排版克制的科学杂志风

手写棒球史用铅笔在 8.5×11 横线纸上写多伦多棒球史,笔画粗细带人为不均,右上角一块淡淡的咖啡渍

米堆找字上千粒米的特写,其中一粒上刻着「GPT Image 2」,跟其他米粒一样大,远看完全找不到

多元视觉杂志页这次发布的封面海报。主题是「visual polyglot」,把科学图表、元素周期表、太阳系、中世纪手稿、植物插画、解剖图、古地图、气候图、工程示意图、交通指示、漫画格、UI 截图、蝴蝶标本、饼图、建筑蓝图全堆在一张 4:5 海报上,标题「Create Everything at Once」居中
风格保真度
模型在多种视觉风格上的还原度提升明显,包括摄影、电影、像素艺术、漫画。重点是能捕捉到风格里那些微妙的细节,胶片颗粒、镜头眩光、光线的不完美都能保留
海岸边的电影感旁拍35mm 胶片,自然不完美的取景,可见颗粒,乌云早晨的氛围

超现实双胞胎肖像中画幅模拟相机,85mm f/4,雾蒙蒙的美国乡村公路上一对双胞胎的特写

怪诞郊区肖像户外、室内、私密郊区场景,画幅推到中产阶级的奇异感

2015 年 UBC 大学讲堂教授在讲 GPT imagegen 2,幻灯片里又是教授在讲 GPT imagegen 2,无限递归

iPhone 拍的外星人喝咖啡傍晚户外咖啡馆,两个外星人坐在桌边,半空的饮料、不均的阳光、随意的姿势

高级时尚摄影集35mm 拍摄的时尚摄影书

2002 年高中机房架空历史,每个学生都在用 ChatGPT,米色 CRT 显示器、Windows XP 浏览器、球鼠标、缠绕的电缆、地上的双肩包,左下角带橘色日期戳「02 18 04」

70 年代纽约街拍摄影集35mm 胶片书页

风格化方面,从青年漫画到法国新浪潮,从中世纪粉彩到现代独立漫画,模型都能精准捕捉




少年动漫角色设定页基于上传的真人照片,做漫画角色 character sheet,名字叫 Adele

GPT Image 2 工作室物料审稿单、钉在墙上的样张、印刷打样、版式研究、笔记、各种发布前的设计衍生物,看起来像一个严肃创意工作室准备发布前的桌面

宽高比拉到 3:1 到 1:3
之前的图像模型一律以方图为主,这次把宽高比拉开,从 3:1 超宽到 1:3 超高都能跑
3:1 超宽篮球扣篮的连环动作分解

iPhone 全景泰国都市,故意带轻微的拼接错位

iPhone 全景法国南部夏日

Art Deco 风格书签完整带尺寸标注,含出血、裁切、安全边距,可以直接拿去印刷

3:1 横版中国传统山水画

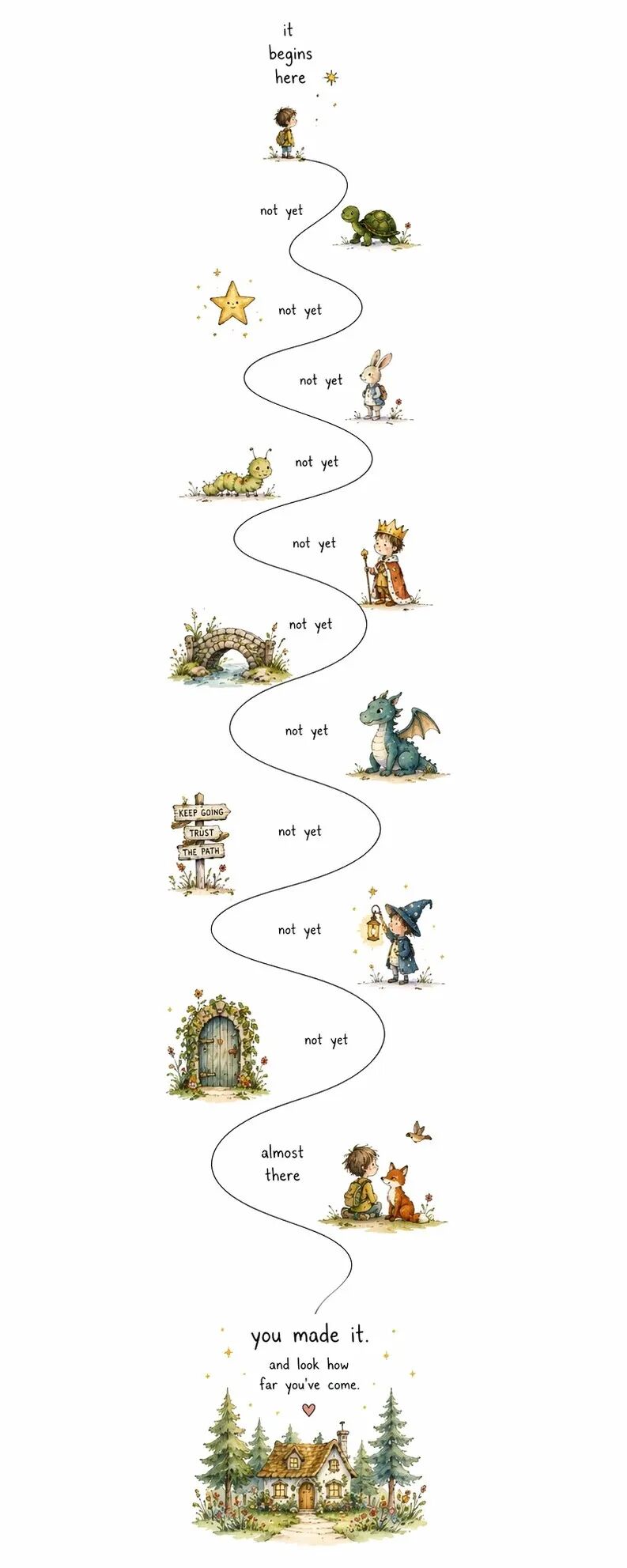
1:3 超高 9 人站位日式漫画长脖子、小脸、最简线稿、围一张大白纸做画
1:3 超高童书风路线图黑色细线在白底上蜿蜒,穿过各种童书角色和「not yet」之类的短语
真实世界的智能
ChatGPT Images 2.0 的知识截止是 2025 年 12 月,比上代新很多
做信息图、教育插画、视觉摘要这类内容时,模型给出的具体内容是 up-to-date 的
康托对角线证明信息图把数学证明从「假设」「对角线」「构造」「矛盾」四步可视化

2025 年六大设计趋势壁画风海报,每个面板尺寸一致

人物色彩分析基于上传的肖像,做个人色彩适配诊断,文字最少化

在 Codex 里直接画图
Codex 现在内置了 ChatGPT Images 2.0
可以在 Codex 工作区直接生成、迭代、ship 应用、做幻灯片,多个 UI 方向、概念、原型一次跑出来对比,挑最好的转成正式产品。不需要单独申请 API key,ChatGPT 订阅直接覆盖
适用场景从设计、营销、产品、销售一直延伸到学习培训
客户验证
API 已经在四家创意软件商手里跑过
Canva用 GPT Image 2 做一支美妆品牌的 lip balm 广告,模型自己加了「viral on TikTok」贴纸,没人提示

模型不只在渲染。它在理解 brief、理解受众,背后做创意决策。我们以前评估 AI 看技术输出,真正的变化是创意推理和设计审美
Dwayne Koh / Canva 创意策略师
Figma从文字密集的视觉到逼真场景的全流程支持
编辑能力和美学层面的提升给设计师更多塑形空间
Loredana Crisan / Figma 首席设计官
Adobe Firefly电影感旅店航拍图,一排粉色海岸 motel,每家有不同形状的泳池,旅店名是「Firefly Motel」「Firefly Lodge」「Firefly Stay」「Casa Firefly」

从单图生成升级到结构化视觉内容
Mike Folgner / Adobe Firefly 产品高级总监
OpenArt用 GPT Image 2 做电影级视频生产 Smart Shot 的「创意总监」,宙斯 vs 黑帝斯的史诗战斗序列分镜
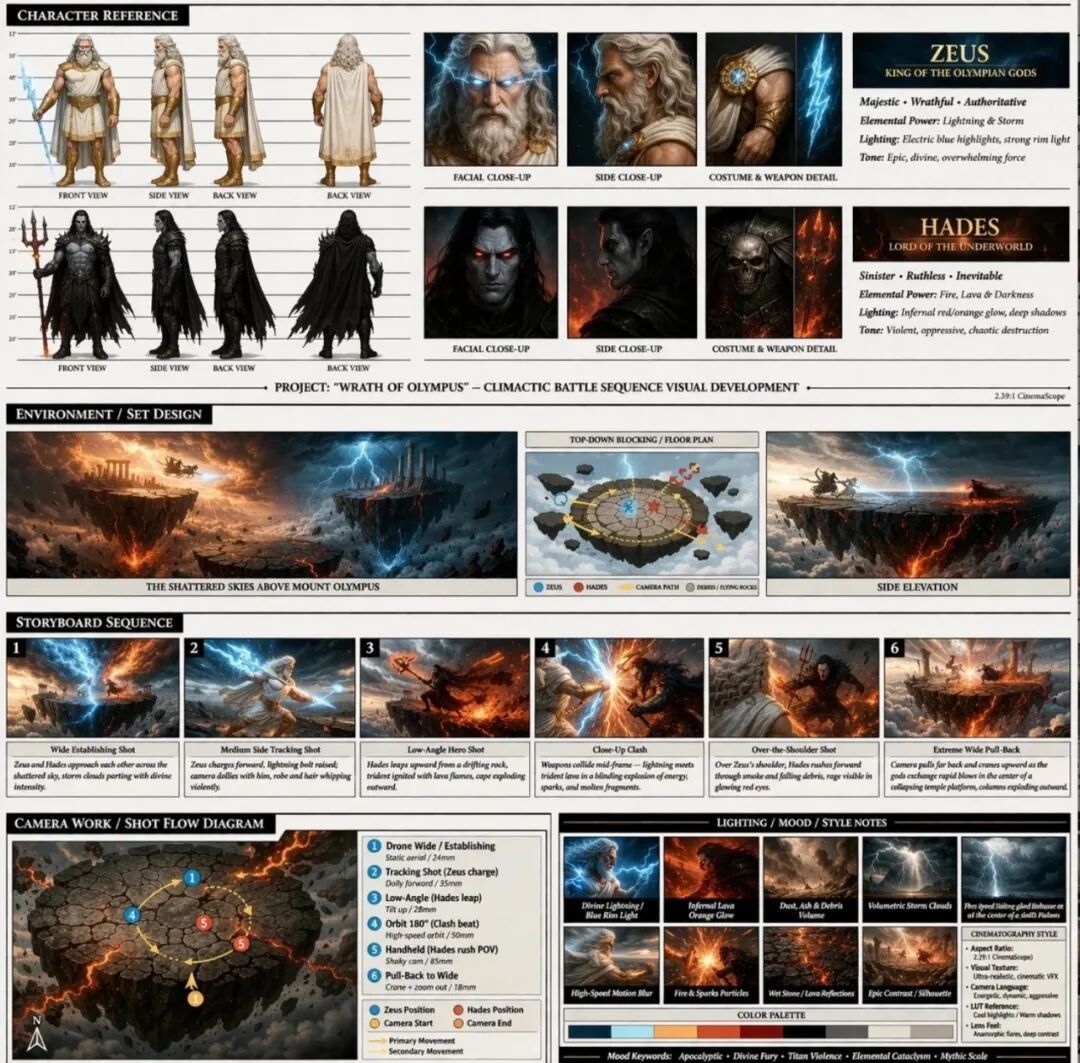
本来需要整个创意团队的工作,现在瞬间完成
Chloe Fang / OpenArt 合作主管
还做不到的事
ChatGPT Images 2.0 不是完美。OpenAI 在博客里把短板单独写了一节,没回避
需要完整、连贯的物理世界模型的任务(折纸指南、魔方拼图)依然吃力
极密、极重复的视觉细节(沙粒级别)会逼到模型上限
带精确箭头和零件标签的标注图、示意图,准确度仍需人工复核
API 端 2K 以上分辨率当前是 beta,结果可能不稳定。复杂提示词的延迟最高可达 2 分钟。重复角色或品牌元素的连续生成偶尔会失稳
安全
ChatGPT Images 2.0 的安全栈延续 1.5 的三层结构:上游文本拒绝、下游图像/输入双重检查、最终输出审查
按照 OpenAI 自己发布的 System Card 数据:
InstantInstant 模式 99.1% 的对抗 prompt 能输出安全图像(3085/3112)
ThinkingThinking 模式 99.2%(6886/6944)
Thinking 模式有个有意思的差异:它从源头产生的违规图本来就少(6.7% vs Instant 的 22.0%),原因是 thinking 模型用 Safe Completions 把对抗 prompt 转译成安全版本,而不是直接拒绝
生物领域单独应用了图像版的生物风险安全策略。OpenAI 找了生物武器专家来评估,结果显示模型在某些场景下输出的信息密度足以「为新手提供帮助」,因此按 high capability 级别配置防护。配套了实时阻断、离线对话审查、账号封禁三道关
继续坚持 C2PA metadata 和不可见水印,便于内容溯源
参考资料
官方发布博客openai.com/index/introducing-chatgpt-images-2-0
API 文档developers.openai.com/api/docs/guides/image-generation
定价说明developers.openai.com/api/docs/pricing
模型卡片deploymentsafety.openai.com/chatgpt-images-2-0
我前两天的 50+ Case 实测mp.weixin.qq.com/s/xHdO3eDSybw5jZC4x4eqag





